
Object-Centric Process Mining: Unraveling the Fabric of Real Processes


Abstract
1. Introduction
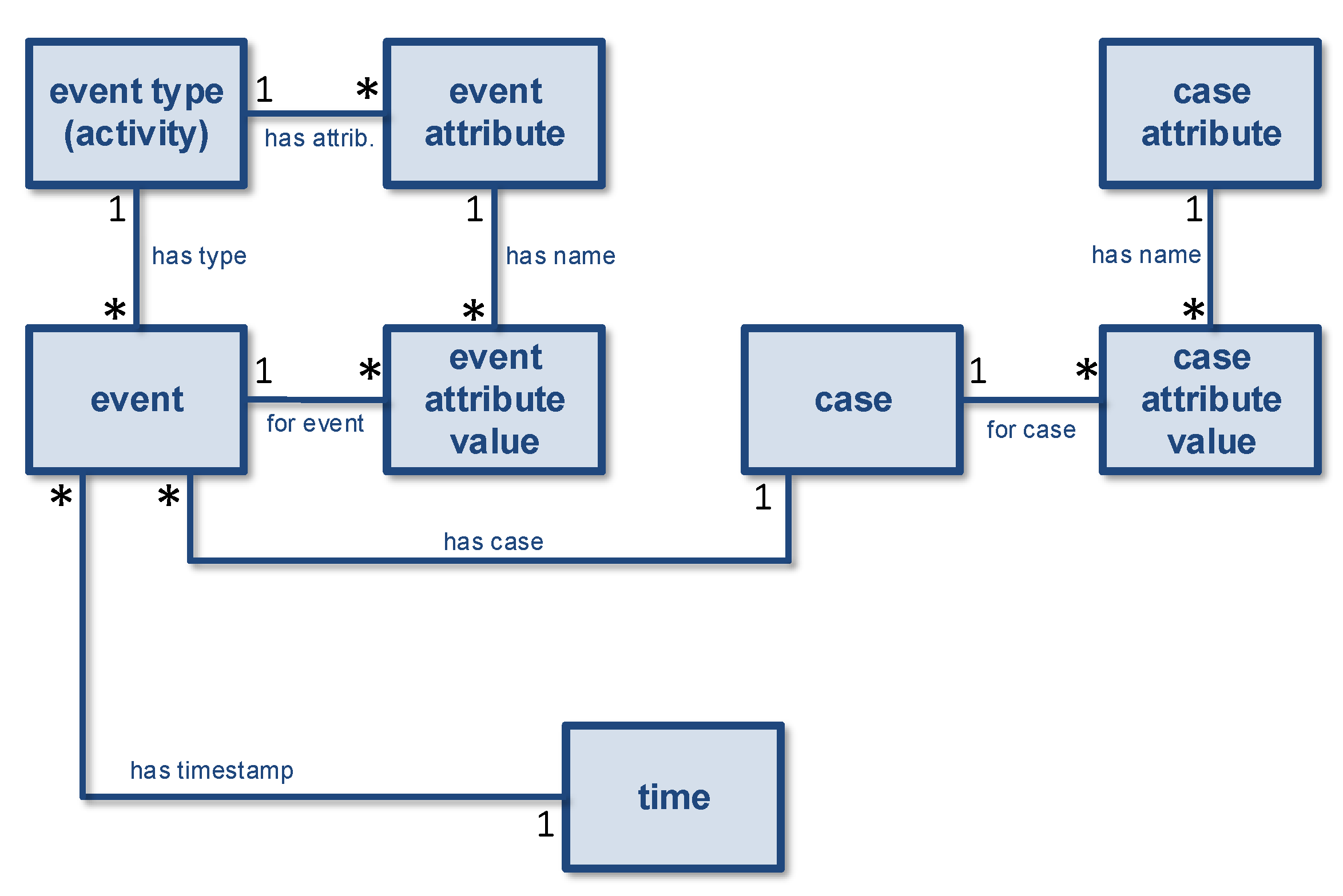
- It is assumed that a process model describes the lifecycle of a single object.
- It is assumed that each event refers to precisely one object (often called case) of a given type.
- Real-life activities may involve multiple objects of different types.
- Objects are not mutually independent and cannot be fully understood by looking at them in isolation.
- Objects may be related, e.g., an order has items and refers to a customer.
- Data extraction is time consuming and needs to be repeated when new questions emerge. This is inflexible and prevents reuse. Additionally, logging is not system agnostic, i.e., the same business process creates different event data depending on the system used (e.g., SAP versus Oracle).
- Interactions between objects are not captured, and objects are analyzed in isolation.
- A 3D reality needs to be squeezed into 2D event logs and models. It is impossible to create views “on demand” when data are stored in 2D rather than 3D format.
2. The Need for Object Centricity
- Data extraction is time consuming and needs to be repeated when new questions emerge. Traditional event logs view event data from one particular angle, i.e., the case notion selected. However, different questions may require different viewpoints. Consider an order-handling process involving customers, suppliers, orders, items, shipments, payments, employees, etc. Each of these object types can be used as a case notion depending on the question. It is very inefficient to extract event data repeatedly using different case notions. Moreover, new questions may require new data extractions and the involvement of IT specialists.
- Interactions between objects are not captured, and objects are analyzed in isolation. Real-life events tend to involve multiple objects. These objects may be of the same type, e.g., multiple items are ordered in one transaction. Moreover, also different types of objects may be involved, e.g., delivering a package to a customer involving items from different orders. When events are only related through a case identifier, interactions between objects get lost. Moreover, it leads to distortions, such as convergence and divergence problems (see Section 3.6).
- A 3D reality needs to be squeezed into 2D event logs and models. Traditional approaches use two-dimensional (2D) event logs and models. The first two dimensions are the activity dimension and the time dimension. The third dimension is the object dimension covering multiple object types. In 2D event logs and models, one focuses on one object (type) at a time. However, to capture reality better, one needs three-dimensional (3D) event logs and models. One needs to add the third dimension considering multiple object types, where one event may refer to any number of objects.
3. Object-Centric Event Data
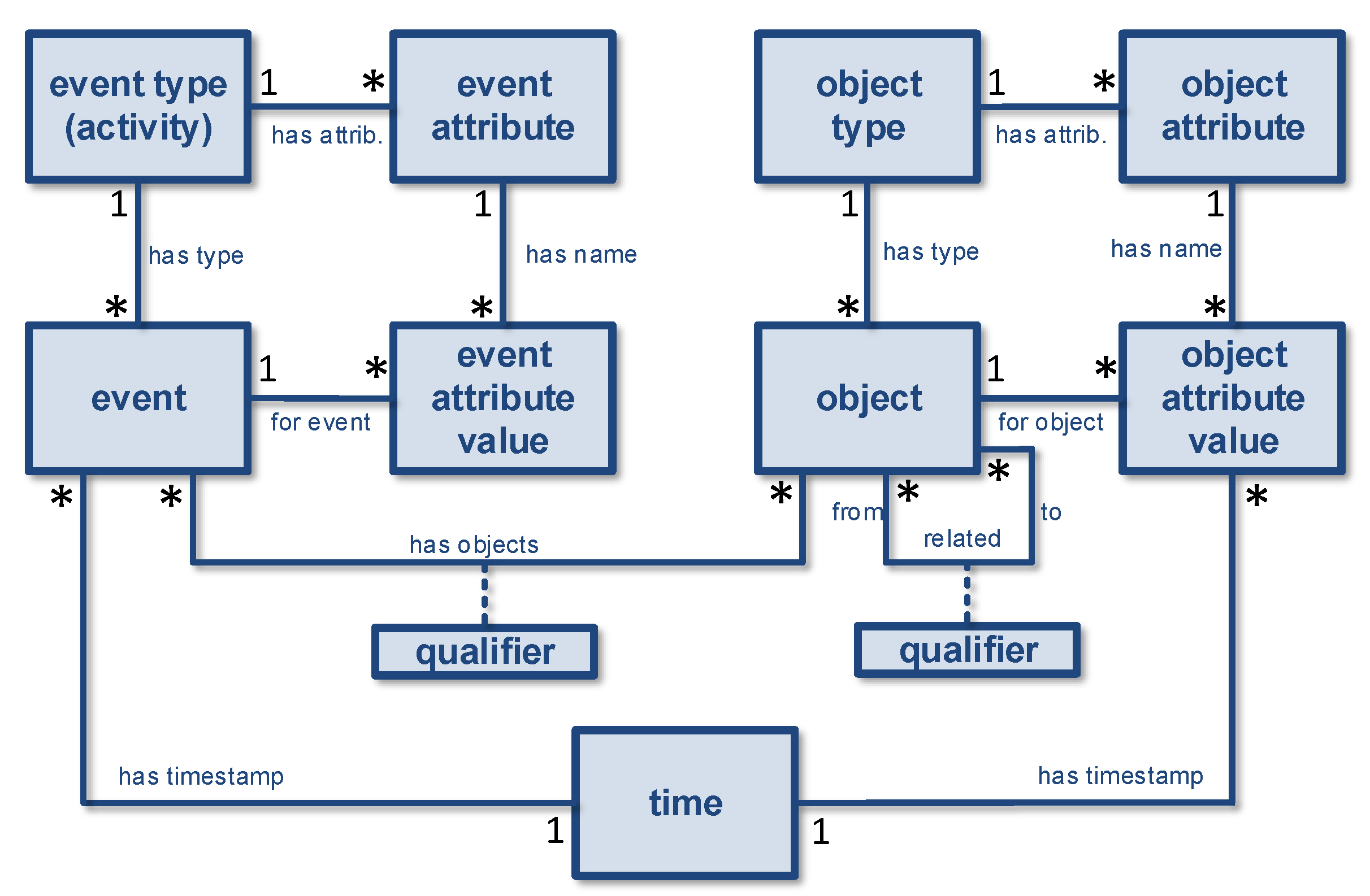
3.1. Objects and Object Types
3.2. Events and Event Types
3.3. Event-to-Object (E2O) Relations
3.4. Object-to-Object (O2O) Relations
3.5. Event and Object Attributes
3.6. Convergence and Divergence
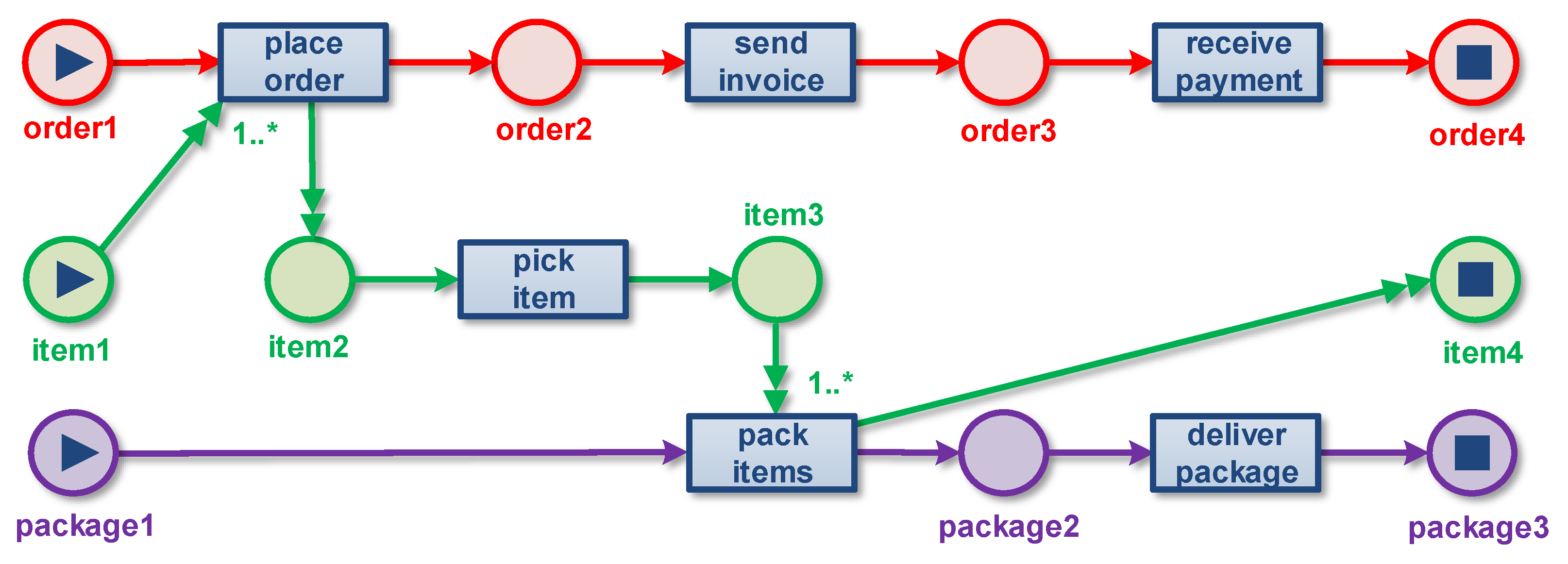
- Pick an object type to serve as the case notion.
- Remove all objects of a different type. The remaining objects are called cases.
- Only keep object attribute values corresponding to cases, and, if there are multiple case attribute values for a case and case attribute combination, keep only the last one. Remove the timestamps of the remaining case attribute values.
- Remove all events that do not have an O2E relation to at least one case (i.e., object of the selected type). Therefore, the remaining events refer to one or more cases.
- If an event refers to multiple cases, then replicate the event once for each case. By replicating events for each case, we can ensure that each resulting event refers to a single case.
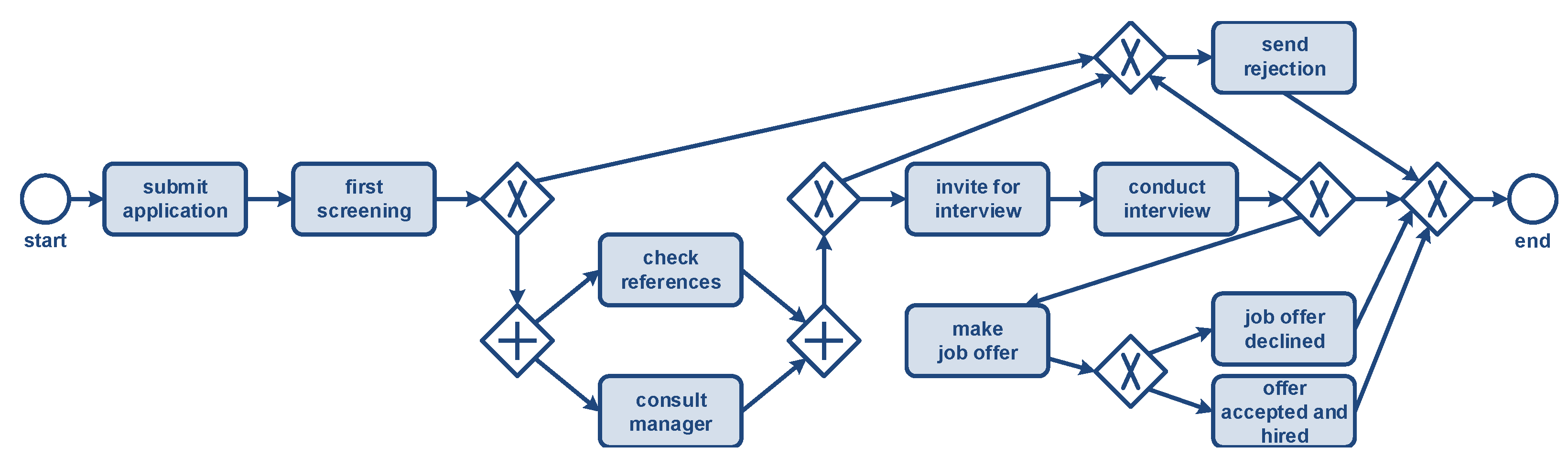
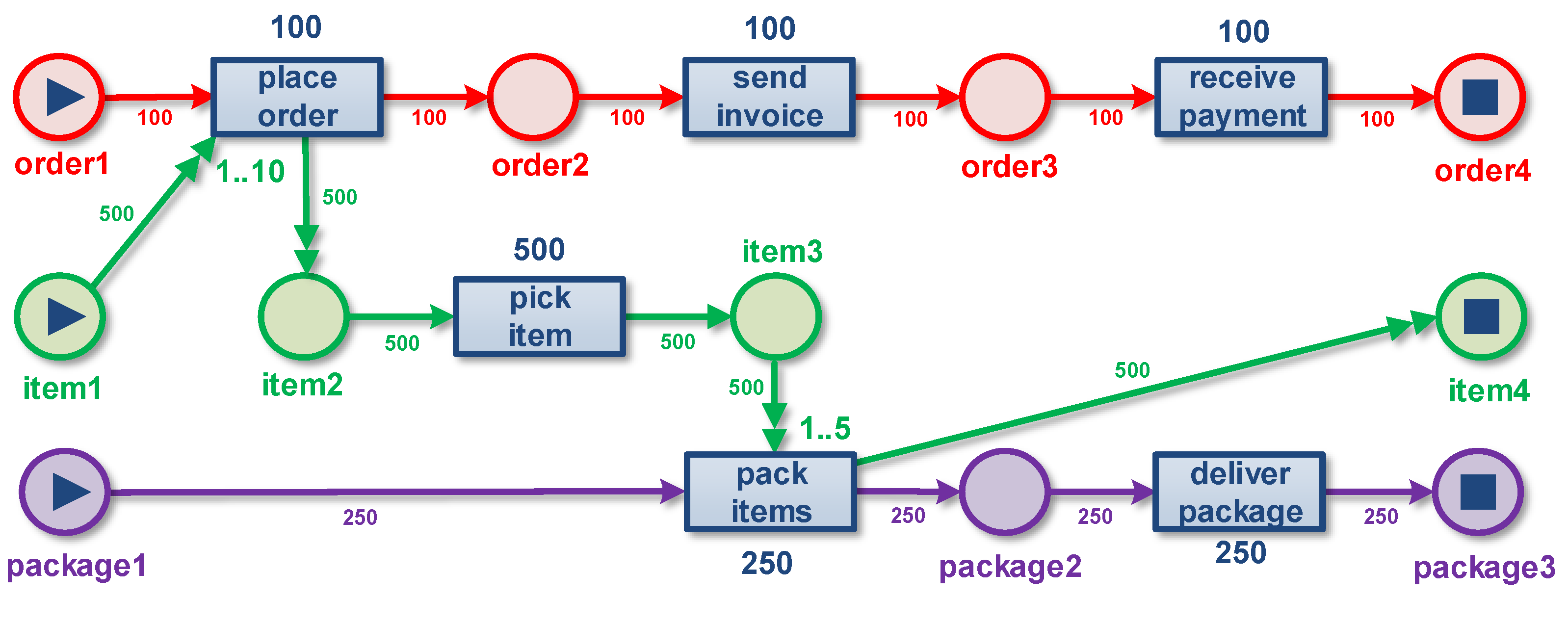
- The convergence problem: Events referring to multiple objects of the selected type are replicated, possibly leading to unintentional duplication. The replication of events can lead to misleading diagnostics.
- The divergence problem: There are multiple events that refer to the same case and activity; however, they differ with respect to one of the not-selected object types. In other words, events referring to different objects of a type not selected as the case notion become indistinguishable, looking only at the case and activity (i.e., event type).
3.7. Example Illustrating Convergence and Divergence
4. Formalizing Object-Centric Event Data
- is the universe of events;
- is the universe of event types (i.e., activities);
- is the universe of objects;
- is the universe of object types;
- is the universe of attribute names;
- is the universe of attribute values;
- is the universe of timestamps (with as the smallest element and as the largest element);
- is the universe of qualifiers.
- is the set of events;
- is the set of objects;
- assigns types to events;
- assigns timestamps to events;
- is the set of event attributes;
- assigns event attributes to event types;
- assigns event attributes to values at specific times;
- assigns types to objects;
- is the set of object attributes;
- assigns object attributes to object types;
- assigns object attributes to values;
- are the qualified event-to-object relations;
- are the qualified object-to-object relations.
- to ensure that only existing event attributes can have values;
- to ensure that only existing object attributes can have values.
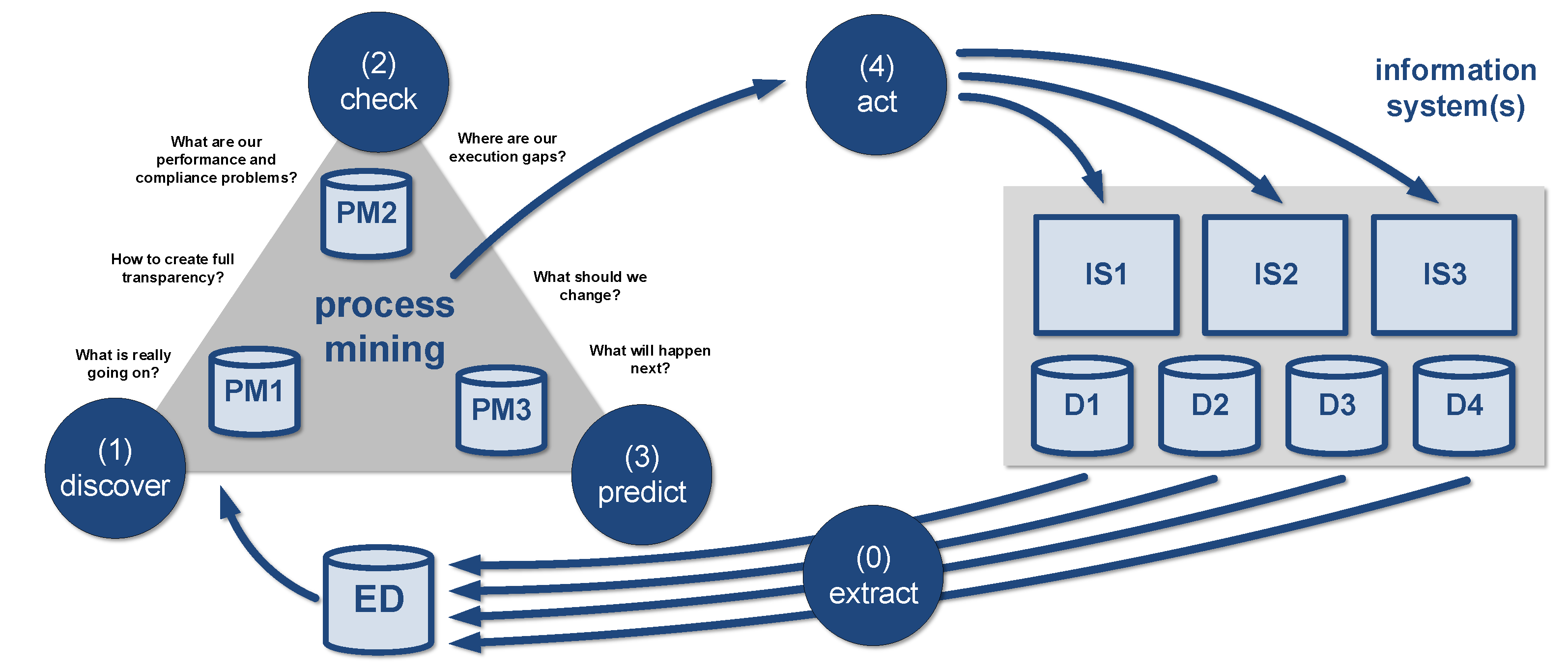
5. Object-Centric Process Mining
5.1. Object-Centric Process Discovery
- What is the average time between placing an order and delivering all the packages that contain items of the order?
- Do people typically pay the order before or after they receive all the items?
- Does the size of an order influence the time until delivery?
5.2. Object-Centric Conformance Checking
5.3. Example Using OC-PM and Process Sphere
5.4. Other Considerations Related to Scalability, Adoption, and New Opportunities
6. Conclusions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Van der Aalst, W. Process Mining: Data Science in Action; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- OMG. Business Process Model and Notation (BPMN); Formal/2011-01-03; Object Management Group: Needham, MA, USA, 2011. [Google Scholar]
- Van der Aalst, W.; Carmona, J. (Eds.) Process Mining Handbook; Lecture Notes in Business Information Processing; Springer: Berlin/Heidelberg, Germany, 2022; Volume 448. [Google Scholar]
- IEEE Task Force on Process Mining. XES Standard Definition. 2016. Available online: www.xes-standard.org (accessed on 1 April 2023).
- Van der Aalst, W.; Berti, A. Discovering Object-Centric Petri Nets. Fundam. Inform. 2020, 175, 1–40. [Google Scholar] [CrossRef]
- Kerremans, M.; Srivastava, T.; Choudhary, F. Gartner Market Guide for Process Mining, Research Note G00737056. 2021. Available online: www.gartner.com (accessed on 1 April 2023).
- Kerremans, M.; Iijima, K.; Sachelarescu, A.; Duffy, N.; Sugden, D. Magic Quadrant for Process Mining Tools, Gartner Research Note GG00774746. 2023. Available online: www.gartner.com (accessed on 1 April 2023).
- Reinkemeyer, L. Process Mining in Action: Principles, Use Cases and Outlook; Springer: Berlin/Heidelberg, Germany, 2020. [Google Scholar]
- Van der Aalst, W. Object-Centric Process Mining: The Next Frontier in Business Performance. 2023. Available online: celon.is/OCPM-Whitepaper (accessed on 1 April 2023).
- Wynn, M.T.; Lebherz, J.; van der Aalst, W.M.P.; Accorsi, R.; Ciccio, C.D.; Jayarathna, L.; Verbeek, H.M.W. Rethinking the Input for Process Mining: Insights from the XES Survey and Workshop. In Process Mining Workshops of the International Conference on Process Mining (Revised Selected Papers); Munoz-Gama, J., Lu, X., Eds.; Lecture Notes in Business Information Processing; Springer: Berlin/Heidelberg, Germany, 2021; Volume 433, pp. 3–16. [Google Scholar]
- Augusto, A.; Conforti, R.; Dumas, M.; Rosa, M.; Maggi, F.; Marrella, A.; Mecella, M.; Soo, A. Automated Discovery of Process Models from Event Logs: Review and Benchmark. IEEE Trans. Knowl. Data Eng. 2019, 31, 686–705. [Google Scholar] [CrossRef]
- Leemans, S.; Fahland, D.; Van der Aalst, W. Scalable Process Discovery and Conformance Checking. Softw. Syst. Model. 2018, 17, 599–631. [Google Scholar] [CrossRef] [PubMed]
- Werf, J.; Van Dongen, B.; Hurkens, C.; Serebrenik, A. Process Discovery using Integer Linear Programming. Fundam. Informaticae 2010, 94, 387–412. [Google Scholar]
- Augusto, A.; Conforti, R.; Marlon, M.; La Rosa, M.; Polyvyanyy, A. Split Miner: Automated Discovery of Accurate and Simple Business Process Models from Event Logs. Knowl. Inf. Syst. 2019, 59, 251–284. [Google Scholar] [CrossRef]
- Carmona, J.; Dongen, B.; Solti, A.; Weidlich, M. Conformance Checking: Relating Processes and Models; Springer: Berlin/Heidelberg, Germany, 2018. [Google Scholar]
- De Leoni, M.; Van der Aalst, W. A General Process Mining Framework For Correlating, Predicting and Clustering Dynamic Behavior Based on Event Logs. Inf. Syst. 2016, 56, 235–257. [Google Scholar] [CrossRef]
- Teinemaa, I.; Dumas, M.; La Rosa, M.; Maggi, F.M. Outcome-Oriented Predictive Process Monitoring: Review and Benchmark. ACM Trans. Knowl. Discov. Data 2019, 13, 17:1–17:57. [Google Scholar] [CrossRef]
- Fahland, D. Describing Behavior of Processes with Many-to-Many Interactions. In Applications and Theory of Petri Nets 2019; Donatelli, S., Haar, S., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2019; Volume 11522, pp. 3–24. [Google Scholar]
- Lu, X.; Nagelkerke, M.; Wiel, D.; Fahland, D. Discovering Interacting Artifacts from ERP Systems. IEEE Trans. Serv. Comput. 2015, 8, 861–873. [Google Scholar] [CrossRef]
- Li, G.; Medeiros de Carvalho, R.; Van der Aalst, W. Automatic Discovery of Object-Centric Behavioral Constraint Models. In Proceedings of the Business Information Systems (BIS 2017), Hannover, Germany, 28–30 June 2017; Abramowicz, W., Ed.; Lecture Notes in Business Information Processing. Springer: Berlin/Heidelberg, Germany, 2017; Volume 288, pp. 43–58. [Google Scholar]
- Artale, A.; Kovtunova, A.; Montali, M.; Van der Aalst, W. Modeling and Reasoning over Declarative Data-Aware Processes with Object-Centric Behavioral Constraints. In Business Process Management: 17th International Conference (BPM 2019), Vienna, Austria, 1–6 September 2019; Hildebrandt, T., van Dongen, B., Röglinger, M., Mendling, J., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2019; Volume 11675, pp. 139–156. [Google Scholar]
- Eck, M.L. Process Mining for Smart Product Design. Ph.D. Thesis, Eindhoven University of Technology, Mathematics and Computer Science, Eindhoven, The Netherlands, 2022. [Google Scholar]
- Li, G. Process Mining Based on Object-Centric Behavioral Constraint (OCBC) Models. Ph.D. Thesis, Eindhoven University of Technology, Mathematics and Computer Science, Eindhoven, The Netherlands, 2019. [Google Scholar]
- Esser, S.; Fahland, D. Multi-Dimensional Event Data in Graph Databases. J. Data Semant. 2021, 10, 109–141. [Google Scholar] [CrossRef]
- Ghilardi, S.; Gianola, A.; Montali, M.; Rivkin, A. Petri net-based object-centric processes with read-only data. Inf. Syst. 2022, 107, 102011. [Google Scholar] [CrossRef]
- Process and Data Science Group. OCEL Standard. 2021. Available online: www.ocel-standard.org (accessed on 1 April 2023).
- OMG Group. Object Constraint Language, Version 2.4. OMG. 2014. Available online: http://www.omg.org/spec/OCL/2.4/ (accessed on 1 April 2023).
- Jensen, K. Coloured Petri Nets. Basic Concepts, Analysis Methods and Practical Use; EATCS monographs on Theoretical Computer Science; Springer: Berlin/Heidelberg, Germany, 1992. [Google Scholar]
- Jensen, K.; Kristensen, L.M. Coloured Petri Nets—Modeling and Validation of Concurrent Systems; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
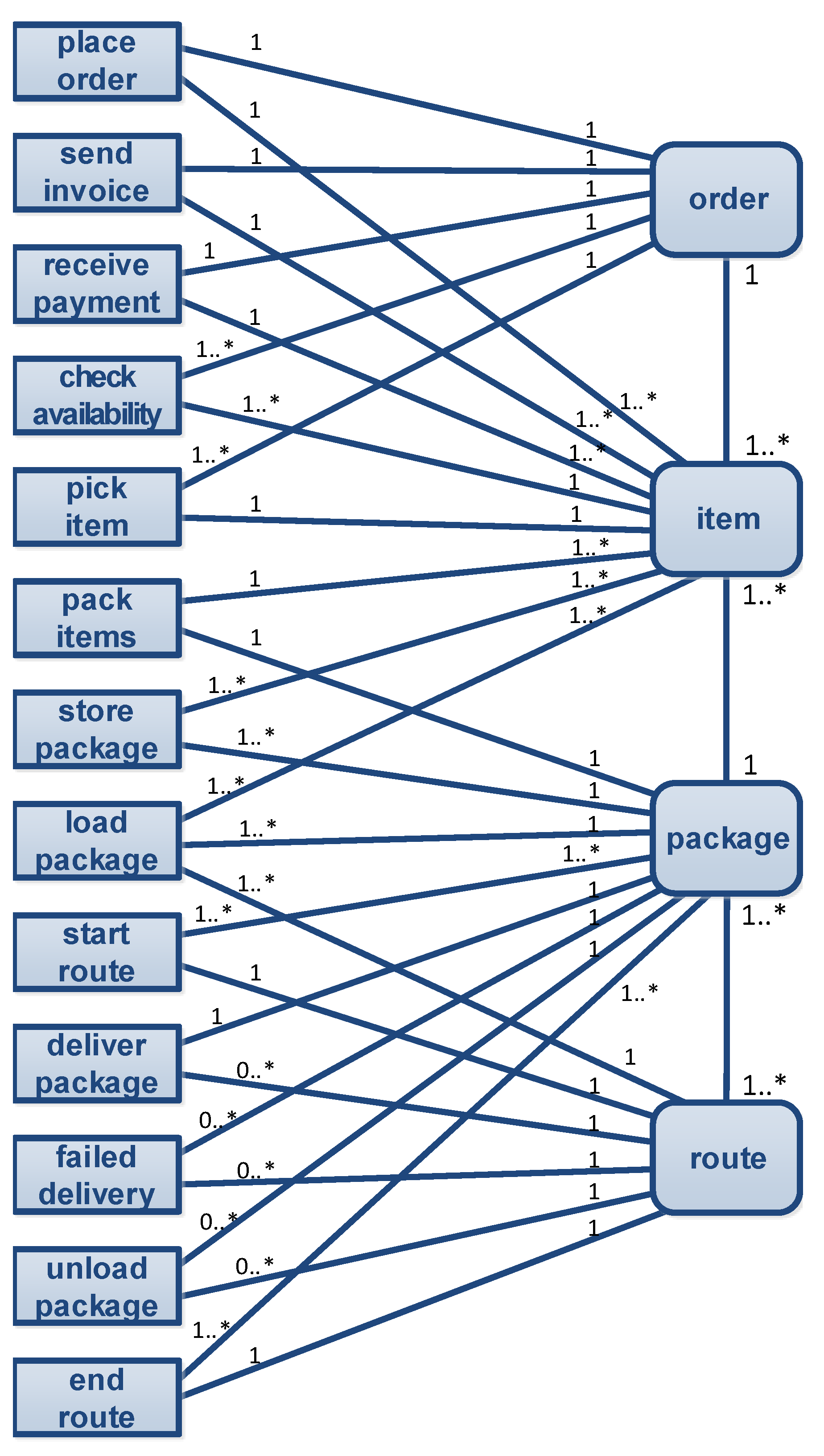
| Order | Item | Package | Route | |
|---|---|---|---|---|
| place order | ✓ | ✓ | ||
| send invoice | ✓ | ✓ | ||
| receive payment | ✓ | ✓ | ||
| check availability | ✓ | ✓ | ||
| pick item | ✓ | ✓ | ||
| pack items | ✓ | ✓ | ||
| store package | ✓ | ✓ | ||
| load package | ✓ | ✓ | ||
| start route | ✓ | ✓ | ||
| deliver package | ✓ | ✓ | ||
| failed delivery | ✓ | ✓ | ||
| unload package | ✓ | ✓ | ||
| end route | ✓ | ✓ |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
van der Aalst, W.M.P. Object-Centric Process Mining: Unraveling the Fabric of Real Processes. Mathematics 2023, 11, 2691. https://doi.org/10.3390/math11122691
van der Aalst WMP. Object-Centric Process Mining: Unraveling the Fabric of Real Processes. Mathematics. 2023; 11(12):2691. https://doi.org/10.3390/math11122691
Chicago/Turabian Stylevan der Aalst, Wil M. P. 2023. "Object-Centric Process Mining: Unraveling the Fabric of Real Processes" Mathematics 11, no. 12: 2691. https://doi.org/10.3390/math11122691
APA Stylevan der Aalst, W. M. P. (2023). Object-Centric Process Mining: Unraveling the Fabric of Real Processes. Mathematics, 11(12), 2691. https://doi.org/10.3390/math11122691