

Quick and Complete Convergence in the Law of Large Numbers with Applications to Statistics

{kind=link}
Abstract
1. Introduction
2. Modes of Convergence and the Law of Large Numbers
2.1. Standard Modes of Convergence
- (i)
- for ;
- (ii)
- .
2.2. Complete and r-Complete Convergence
2.3. r-Quick Convergence
- (i)
- For any and any , the following inequalities hold:
- (ii)
- If is a power function, , , then the finiteness of
2.4. Further Remarks on r-Complete Convergence, r-Quick Convergence, and Rates of Convergence in SLLN
- Strassen [3] proved, in particular, that if in Lemma 2, then for
- 2.
- Lai [8] improved this result, showing that Strassen’s moment condition for can be relaxed. Specifically, he showed that a weaker condition
- 3.
- Let and . Chow and Lai [9] established the following one-sided inequality for tail probabilities:
- (i)
- ;
- (ii)
- ;
- (iii)
- ,
- 4.
- The Marcinkiewicz–Zygmund SLLN states that, for , the following implications hold:
3. Applications of -Complete and -Quick Convergences in Statistics
3.1. Sequential Hypothesis Testing
3.1.1. Asymptotic Optimality of Walds’s SPRT
3.1.2. Asymptotic Optimality of the Multi-hypothesis SPRT
- (i)
- For ,
- (ii)
- If the thresholds are so selected that and , particularly as , then for all
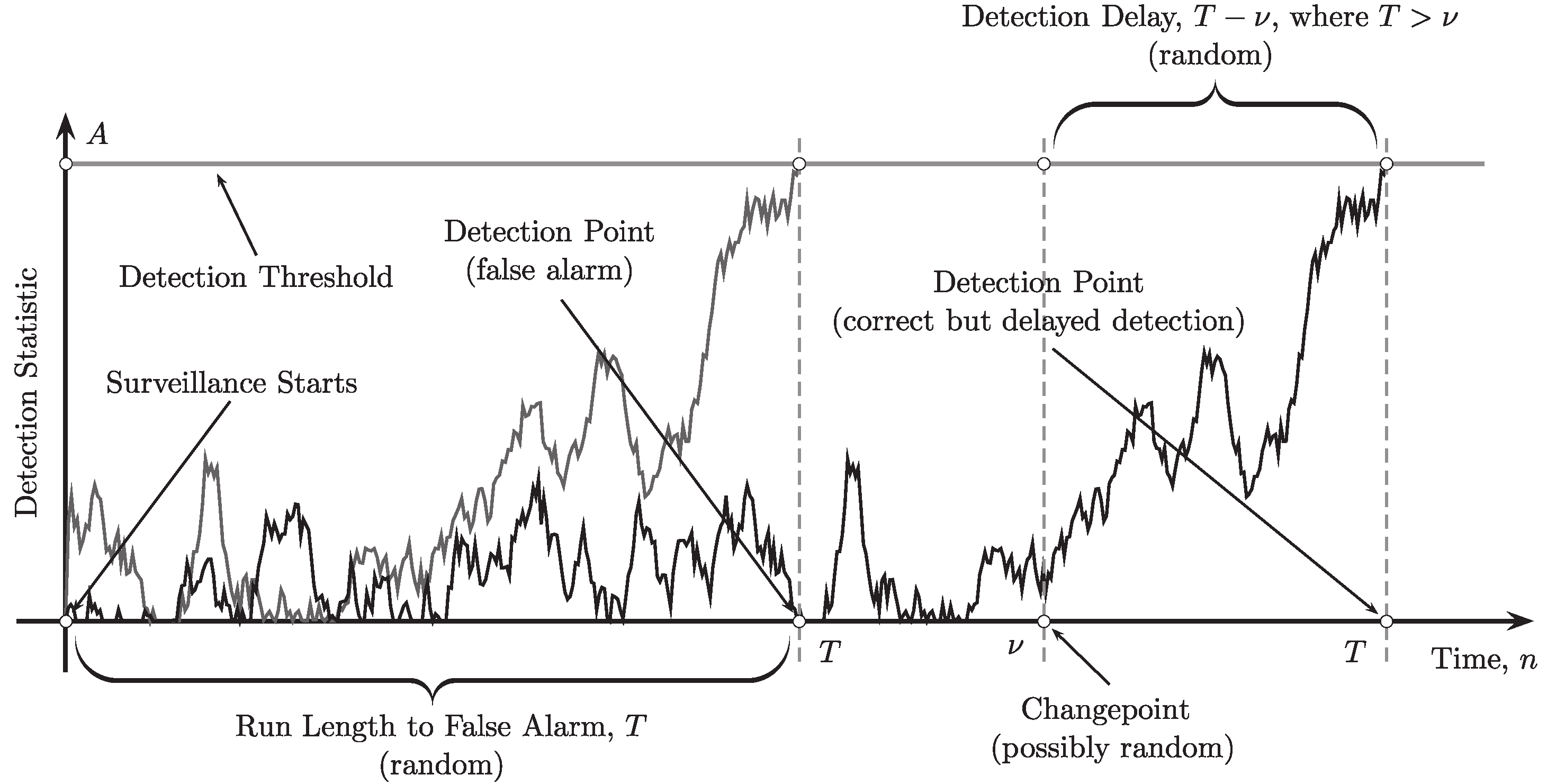
3.2. Sequential Changepoint Detection
3.2.1. Changepoint Models
3.2.2. Popular Changepoint Detection Procedures
The CUSUM Procedure
Shiryaev’s Procedure
Shiryaev–Roberts Procedure
3.2.3. Optimality Criteria
Minimax Changepoint Optimization Criteria
Bayesian Changepoint Optimization Criterion
Uniform Pointwise Optimality Criterion
3.2.4. Asymptotic Optimality for General Non-i.i.d. Models via r-Quick and r-Complete Convergence
Complete Convergence and General Bayesian Changepoint Detection Theory
Complete Convergence and General Non-Bayesian Changepoint Detection Theory
4. Quick and Complete Convergence for Markov and Hidden Markov Models
5. Discussion and Conclusions
Funding
Data Availability Statement
Conflicts of Interest
References
- Hsu, P.L.; Robbins, H. Complete convergence and the law of large numbers. Proc. Natl. Acad. Sci. USA 1947, 33, 25–31. [Google Scholar] [CrossRef] [PubMed]
- Baum, L.E.; Katz, M. Convergence rates in the law of large numbers. Trans. Am. Math. Soc. 1965, 120, 108–123. [Google Scholar] [CrossRef]
- Strassen, V. Almost sure behavior of sums of independent random variables and martingales. In Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability, San Diego, CA, USA, 21 June–18 July 1965 and 27 December 1965–7 January 1966; Le Cam, L.M., Neyman, J., Eds.; Vol. 2: Contributions to Probability Theory. Part 1; University of California Press: Berkeley, CA, USA, 1967; pp. 315–343. [Google Scholar]
- Tartakovsky, A.G. Asymptotic optimality of certain multihypothesis sequential tests: Non-i.i.d. case. Stat. Inference Stoch. Process. 1998, 1, 265–295. [Google Scholar] [CrossRef]
- Tartakovsky, A.G. Sequential Change Detection and Hypothesis Testing: General Non-i.i.d. Stochastic Models and Asymptotically Optimal Rules; Monographs on Statistics and Applied Probability 165; Chapman & Hall/CRC Press, Taylor & Francis Group: Boca Raton, FL, USA; London, UK; New York, NY, USA,, 2020. [Google Scholar]
- Tartakovsky, A.G.; Nikiforov, I.V.; Basseville, M. Sequential Analysis: Hypothesis Testing and Changepoint Detection; Monographs on Statistics and Applied Probability 136; Chapman & Hall/CRC Press, Taylor & Francis Group: Boca Raton, FL, USA; London, UK; New York, NY, USA,, 2015. [Google Scholar]
- Lai, T.L. Asymptotic optimality of invariant sequential probability ratio tests. Ann. Stat. 1981, 9, 318–333. [Google Scholar] [CrossRef]
- Lai, T.L. On r-quick convergence and a conjecture of Strassen. Ann. Probab. 1976, 4, 612–627. [Google Scholar] [CrossRef]
- Chow, Y.S.; Lai, T.L. Some one-sided theorems on the tail distribution of sample sums with applications to the last time and largest excess of boundary crossings. Trans. Am. Math. Soc. 1975, 208, 51–72. [Google Scholar] [CrossRef]
- Fuh, C.D.; Zhang, C.H. Poisson equation, moment inequalities and quick convergence for Markov random walks. Stoch. Process. Their Appl. 2000, 87, 53–67. [Google Scholar] [CrossRef]
- Wald, A. Sequential tests of statistical hypotheses. Ann. Math. Stat. 1945, 16, 117–186. [Google Scholar] [CrossRef]
- Wald, A. Sequential Analysis; John Wiley & Sons, Inc.: New York, NY, USA, 1947. [Google Scholar]
- Wald, A.; Wolfowitz, J. Optimum character of the sequential probability ratio test. Ann. Math. Stat. 1948, 19, 326–339. [Google Scholar] [CrossRef]
- Burkholder, D.L.; Wijsman, R.A. Optimum properties and admissibility of sequential tests. Ann. Math. Stat. 1963, 34, 1–17. [Google Scholar] [CrossRef]
- Matthes, T.K. On the optimality of sequential probability ratio tests. Ann. Math. Stat. 1963, 34, 18–21. [Google Scholar] [CrossRef]
- Ferguson, T.S. Mathematical Statistics: A Decision Theoretic Approach; Probability and Mathematical Statistics; Academic Press: Cambridge, MA, USA, 1967. [Google Scholar]
- Lehmann, E.L. Testing Statistical Hypotheses; John Wiley & Sons, Inc.: New York, NY, USA, 1968. [Google Scholar]
- Shiryaev, A.N. Optimal Stopping Rules; Series on Stochastic Modelling and Applied Probability; Springer: New York, NY, USA, 1978; Volume 8. [Google Scholar]
- Golubev, G.K.; Khas’minskii, R.Z. Sequential testing for several signals in Gaussian white noise. Theory Probab. Appl. 1984, 28, 573–584. [Google Scholar] [CrossRef]
- Tartakovsky, A.G. Asymptotically optimal sequential tests for nonhomogeneous processes. Seq. Anal. 1998, 17, 33–62. [Google Scholar] [CrossRef]
- Verdenskaya, N.V.; Tartakovskii, A.G. Asymptotically optimal sequential testing of multiple hypotheses for nonhomogeneous Gaussian processes in an asymmetric situation. Theory Probab. Appl. 1991, 36, 536–547. [Google Scholar] [CrossRef]
- Fellouris, G.; Tartakovsky, A.G. Multichannel sequential detection–Part I: Non-i.i.d. data. IEEE Trans. Inf. Theory 2017, 63, 4551–4571. [Google Scholar] [CrossRef]
- Armitage, P. Sequential analysis with more than two alternative hypotheses, and its relation to discriminant function analysis. J. R. Stat. Soc.-Ser. Methodol. 1950, 12, 137–144. [Google Scholar] [CrossRef]
- Chernoff, H. Sequential design of experiments. Ann. Math. Stat. 1959, 30, 755–770. [Google Scholar] [CrossRef]
- Kiefer, J.; Sacks, J. Asymptotically optimal sequential inference and design. Ann. Math. Stat. 1963, 34, 705–750. [Google Scholar] [CrossRef]
- Lorden, G. Integrated risk of asymptotically Bayes sequential tests. Ann. Math. Stat. 1967, 38, 1399–1422. [Google Scholar] [CrossRef]
- Lorden, G. Nearly-optimal sequential tests for finitely many parameter values. Ann. Stat. 1977, 5, 1–21. [Google Scholar] [CrossRef]
- Pavlov, I.V. Sequential procedure of testing composite hypotheses with applications to the Kiefer-Weiss problem. Theory Probab. Appl. 1990, 35, 280–292. [Google Scholar] [CrossRef]
- Baron, M.; Tartakovsky, A.G. Asymptotic optimality of change-point detection schemes in general continuous-time models. Seq. Anal. 2006, 25, 257–296. [Google Scholar] [CrossRef]
- Mosteller, F. A k-sample slippage test for an extreme population. Ann. Math. Stat. 1948, 19, 58–65. [Google Scholar] [CrossRef]
- Bakut, P.A.; Bolshakov, I.A.; Gerasimov, B.M.; Kuriksha, A.A.; Repin, V.G.; Tartakovsky, G.P.; Shirokov, V.V. Statistical Radar Theory; Tartakovsky, G.P., Ed.; Sovetskoe Radio: Moscow, Russia, 1963; Volume 1. (In Russian) [Google Scholar]
- Basseville, M.; Nikiforov, I.V. Detection of Abrupt Changes—Theory and Application; Information and System Sciences Series; Prentice-Hall, Inc.: Englewood Cliffs, NJ, USA, 1993. [Google Scholar]
- Jeske, D.R.; Steven, N.T.; Tartakovsky, A.G.; Wilson, J.D. Statistical methods for network surveillance. Appl. Stoch. Model. Bus. Ind. 2018, 34, 425–445. [Google Scholar] [CrossRef]
- Jeske, D.R.; Steven, N.T.; Wilson, J.D.; Tartakovsky, A.G. Statistical network surveillance. In Wiley StatsRef: Statistics Reference Online; Wiley: New York, NY, USA, 2018; pp. 1–12. [Google Scholar] [CrossRef]
- Tartakovsky, A.G.; Brown, J. Adaptive spatial-temporal filtering methods for clutter removal and target tracking. IEEE Trans. Aerosp. Electron. Syst. 2008, 44, 1522–1537. [Google Scholar] [CrossRef]
- Szor, P. The Art of Computer Virus Research and Defense; Addison-Wesley Professional: Upper Saddle River, NJ, USA, 2005. [Google Scholar]
- Tartakovsky, A.G. Rapid detection of attacks in computer networks by quickest changepoint detection methods. In Data Analysis for Network Cyber-Security; Adams, N., Heard, N., Eds.; Imperial College Press: London, UK, 2014; pp. 33–70. [Google Scholar]
- Tartakovsky, A.G.; Rozovskii, B.L.; Blaźek, R.B.; Kim, H. Detection of intrusions in information systems by sequential change-point methods. Stat. Methodol. 2006, 3, 252–293. [Google Scholar] [CrossRef]
- Tartakovsky, A.G.; Rozovskii, B.L.; Blaźek, R.B.; Kim, H. A novel approach to detection of intrusions in computer networks via adaptive sequential and batch-sequential change-point detection methods. IEEE Trans. Signal Process. 2006, 54, 3372–3382. [Google Scholar] [CrossRef]
- Siegmund, D. Change-points: From sequential detection to biology and back. Seq. Anal. 2013, 32, 2–14. [Google Scholar] [CrossRef]
- Moustakides, G.V. Sequential change detection revisited. Ann. Stat. 2008, 36, 787–807. [Google Scholar] [CrossRef]
- Page, E.S. Continuous inspection schemes. Biometrika 1954, 41, 100–114. [Google Scholar] [CrossRef]
- Shiryaev, A.N. On optimum methods in quickest detection problems. Theory Probab. Appl. 1963, 8, 22–46. [Google Scholar] [CrossRef]
- Moustakides, G.V.; Polunchenko, A.S.; Tartakovsky, A.G. A numerical approach to performance analysis of quickest change-point detection procedures. Stat. Sin. 2011, 21, 571–596. [Google Scholar] [CrossRef]
- Moustakides, G.V.; Polunchenko, A.S.; Tartakovsky, A.G. Numerical comparison of CUSUM and Shiryaev–Roberts procedures for detecting changes in distributions. Commun. Stat.-Theory Methods 2009, 38, 3225–3239. [Google Scholar] [CrossRef]
- Lorden, G. Procedures for reacting to a change in distribution. Ann. Math. Stat. 1971, 42, 1897–1908. [Google Scholar] [CrossRef]
- Moustakides, G.V. Optimal stopping times for detecting changes in distributions. Ann. Stat. 1986, 14, 1379–1387. [Google Scholar] [CrossRef]
- Pollak, M. Optimal detection of a change in distribution. Ann. Stat. 1985, 13, 206–227. [Google Scholar] [CrossRef]
- Tartakovsky, A.G.; Pollak, M.; Polunchenko, A.S. Third-order asymptotic optimality of the generalized Shiryaev–Roberts changepoint detection procedures. Theory Probab. Appl. 2012, 56, 457–484. [Google Scholar] [CrossRef]
- Polunchenko, A.S.; Tartakovsky, A.G. On optimality of the Shiryaev–Roberts procedure for detecting a change in distribution. Ann. Stat. 2010, 38, 3445–3457. [Google Scholar] [CrossRef]
- Shiryaev, A.N. The problem of the most rapid detection of a disturbance in a stationary process. Sov. Math.–Dokl. 1961, 2, 795–799, Translation from Doklady Akademii Nauk SSSR 1961, 138, 1039–1042. [Google Scholar]
- Tartakovsky, A.G. Discussion on “Is Average Run Length to False Alarm Always an Informative Criterion?” by Yajun Mei. Seq. Anal. 2008, 27, 396–405. [Google Scholar] [CrossRef]
- Liang, Y.; Tartakovsky, A.G.; Veeravalli, V.V. Quickest change detection with non-stationary post-change observations. IEEE Trans. Inf. Theory 2023, 69, 3400–3414. [Google Scholar] [CrossRef]
- Pergamenchtchikov, S.; Tartakovsky, A.G. Asymptotically optimal pointwise and minimax quickest change-point detection for dependent data. Stat. Inference Stoch. Process. 2018, 21, 217–259. [Google Scholar] [CrossRef]
- Fuh, C.D.; Tartakovsky, A.G. Asymptotic Bayesian theory of quickest change detection for hidden Markov models. IEEE Trans. Inf. Theory 2019, 65, 511–529. [Google Scholar] [CrossRef]
- Kolessa, A.; Tartakovsky, A.; Ivanov, A.; Radchenko, V. Nonlinear estimation and decision-making methods in short track identification and orbit determination problem. IEEE Trans. Aerosp. Electron. Syst. 2020, 56, 301–312. [Google Scholar] [CrossRef]
- Tartakovsky, A.; Berenkov, N.; Kolessa, A.; Nikiforov, I. Optimal sequential detection of signals with unknown appearance and disappearance points in time. IEEE Trans. Signal Process. 2021, 69, 2653–2662. [Google Scholar] [CrossRef]
- Pergamenchtchikov, S.M.; Tartakovsky, A.G.; Spivak, V.S. Minimax and pointwise sequential changepoint detection and identification for general stochastic models. J. Multivar. Anal. 2022, 190, 104977. [Google Scholar] [CrossRef]

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tartakovsky, A.G. Quick and Complete Convergence in the Law of Large Numbers with Applications to Statistics. Mathematics 2023, 11, 2687. https://doi.org/10.3390/math11122687
Tartakovsky AG. Quick and Complete Convergence in the Law of Large Numbers with Applications to Statistics. Mathematics. 2023; 11(12):2687. https://doi.org/10.3390/math11122687
Chicago/Turabian StyleTartakovsky, Alexander G. 2023. "Quick and Complete Convergence in the Law of Large Numbers with Applications to Statistics" Mathematics 11, no. 12: 2687. https://doi.org/10.3390/math11122687
APA StyleTartakovsky, A. G. (2023). Quick and Complete Convergence in the Law of Large Numbers with Applications to Statistics. Mathematics, 11(12), 2687. https://doi.org/10.3390/math11122687