1. Introduction
Reversible data hiding is a technology which hides secret data in an information carrier, which can recover the original carrier without distortion and extract secret data without error. The information carrier can be sound, image, video and so on. In general, reversible data hiding is used in certain scenarios where the carrier requires lossless recovery, such as in military images, medical image diagnosis, and judicial forensics. In recent years, a large number of scholars have proposed many reversible data hiding schemes [
1,
2,
3,
4,
5,
6,
7,
8,
9,
10,
11,
12,
13,
14,
15,
16,
17,
18,
19,
20,
21,
22]. Reversible data hiding is mainly divided into the following four categories: lossless compression-based schemes [
1,
2], which generate spare room for hiding data through the lossless compression method, and recovers the original carrier and secret data after decompression to achieve the effect of lossless hiding. Difference expansion (DE)-based schemes [
3,
4,
5], which propose to take two pixels as a group, expand the difference of the pixels to embed secret data, and use the difference and the average value to obtain the new pixel with embedded data. Histogram shifting (HS)-based schemes [
6], which use the peak point and zero point of the original image histogram and the pixels between the two points are shifted to hide the secret data. Prediction error expansion (PEE)-based schemes [
7,
8], which use the correlation between pixels to predict the pixel value and obtain the pixel error, where the error value is extended to embed the secret data.
With the development of cloud services and the enhancement of people’s awareness of privacy protection, reversible data hiding has gradually become combined with encryption technology to form reversible data hiding in encrypted image (RDHEI). It can not only ensure the security of the cover image, but also embed data without knowing the original content, without destroying the structure of the original carrier, so as to achieve privacy protection. The RDHEI scheme realizes double protection for the cover image and secret information. If it focuses on protecting secret information, the application scenario of the scheme is steganography. If it focuses on protecting images with authentication, the application scenario is watermarking.
According to whether the cover image needs to be preprocessed before encryption to create spare room for secret data embedding, the RDHEI is divided into two categories: reserving room before encryption (RRBE) and vacating room after encryption (VRAE). For RRBE-based frameworks, the spatial correlation of pixels is preserved before encryption to obtain higher embedding capacity. General compression methods, such as ZIP, can be used to implement RRBE-based reversible data hiding in encrypted image scheme, but it does not take into account the characteristics of the image, so the embedding capacity is limited. Therefore, many scholars try to compress the image by mining the characteristics of the cover image to obtain more available space to increase the overall embedding rate of the scheme. Ma et al. [
9] embedded part of the least significant bit (LSB) of the pixels in the complex region into the smooth region, so as to reserve part of the LSB space of the pixels for embedding data. After that, the data extraction and image reconstruction of the scheme have no errors. Zhang et al. [
10] improved the scheme [
9] by shifting the histogram of certain pixel prediction errors to release room for data embedding before encrypting the image. The embedding rate and the peak signal-to-noise ratio (PSNR) of the decrypted image are improved. Wu et al. [
11] proposed a reversible data hiding scheme in a Paillier cryptosystem, which preprocessed the plaintext image before encryption. The embedded data can be extracted directly in the ciphertext domain using homomorphism. The scheme achieves high data hiding ability, and can safely protect user privacy and data integrity. Yin et al. [
12] adaptively predicted the multiple most significant bit (MSB) of each pixel and marked it by Huffman coding in the original image, and the image is encrypted by stream cipher. With multiple MSB replacement, the vacated space can be used to embed additional data. The method achieves high embedding capacity. Wu et al. [
13] proposed to preserve the embedding space in the plaintext image before encryption and to label the encrypted pixels into two different categories using a parametric binary tree. The secret data is embedded in one of the two categories of encrypted pixels by bit replacement, and a higher embedding rate is achieved.
In VRAE methods, content owners do not need to preprocess images before encryption. Zhang et al. [
14] proposed to embed additional data into the image by flipping 3LSBs of a small part of the encrypted data after encrypting the image with stream cipher. The receiver can obtain different available information through different permissions, but this scheme cannot achieve perfect data extraction and image recovery. Puteaux et al. [
15] replaced the most significant bit of each available pixel in the encrypted image with a small portion of the secret data after encrypting the original image. The MSB prediction can extract the embedded data without error. The clear cover image is reconstructed without loss. Qin et al. [
16] used stream cipher and block permutation to encrypt the original image block, and compressed the LSB of the block set in the smooth area of the encrypted image to create extra embedding space. According to the availability of the key, the receiver performs data extraction and image recovery, respectively.
In general, the embedding rate of VRAE-based scheme is relatively low because the encryption destroys the spatial correlation of the neighboring pixels of the image. In order to solve the above problems, many schemes use image block-based encryption methods, which can keep the correlation unchanged between pixels in each block before and after encryption. Chen et al. [
17] divided the encrypted image into non-overlapping blocks and calculated the differences between reference pixels and other pixels within the blocks. By compressing the pixel difference to vacate room for hiding secret data. Wang and He [
18] used uniform MSBs of pixels in the block to compress the block and obtained good results. However, this scheme wastes a lot of space in complex images. Fu et al. [
19] determined embeddable blocks by analyzing the distribution of MSB layers in encrypted images, and then adaptively compressed the MSB layer of embeddable blocks to vacate space according to the occurrence frequency of MSBs. Pun et al. [
20] used the traditional XOR method for block encryption to retain the redundancy in the encryption blocks. The redundant matrix existing in some encryption blocks generated available space to accommodate secret data, and the images directly decrypted by the scheme maintained high quality. Wang et al. [
21] divided image blocks into available and unavailable blocks. Pixels in the available blocks share the same most significant bits, these blocks can be reconstructed to vacate room for data embedding. The hidden data can be extracted lossless, and the original image can be perfectly recovered. Gao et al. [
22] divided the image into blocks, and used block permutation and block-level stream cipher to encrypt the image. The data hider analyzes the image blocks and adaptively determines the best block type label to encode them. The image is compressed to obtain empty rooms for embedding the encrypted secret data.
All the above methods do not make full use of the spatial correlation of pixels in the image blocks, so the payload is low. In this paper, a reversible data hiding scheme in encrypted images based on bit-plane redundancy of prediction error is proposed. On the premise of ensuring the security of the original image, the spatial correlation of the original image is extended to the prediction error image, and the correlation of the image pixels is fully utilized. The block type classification method was improved. The overall embedding capacity of the encrypted image was increased by implementing multi-level embedding on the error matrix. The receiver could extract the secret data without error and recover the original image lossless.
The rest of this paper is organized as follows. In
Section 2, we review the related work. In
Section 3, we briefly introduce the general framework and describe the details of the proposed scheme. In
Section 4, we discuss the experimental results and the performance of the scheme. We conclude our method in
Section 5.
2. Related Work
In this section, we introduce the tools used in this scheme, the Gradient-Adjusted Predictor and Huffman coding, as well as describe Gao et al.’s scheme in detail.
2.1. The Gradient-Adjusted Predictor [23]
The neighboring pixels of an image have high spatial correlation, and can be used to predict the target pixel value
x. The Gradient-Adjusted Predictor (GAP) is the adaptive predictor, which adjusts according to seven different contexts around the predicted pixel. Its simplified version, namely SGAP, provides almost similar results to GAP, but is less computationally intensive. It uses four neighboring pixels of the target pixel
x: left pixel(
), upper left pixel(
), upper pixel(
), upper right pixel(
), to predict its pixel value, as shown in
Figure 1. The pixels of the first row, first column and last row as reference pixels remain unchanged during the prediction process.
2.2. Huffman Coding
Huffman coding is a lossless binary compression coding. It is not a fixed set of encoding, but according to the frequency of each character in the given information, the dynamic generation of the optimal encoding. The more characters appear, the shorter the encoding result. The fewer occurrences, the longer the encoding result. The purpose of Huffman encoding is to further compress the file; variable length encoding is used to compress the data to the shortest length.
2.3. Gao et al.’s Method [22]
(1) Block encryption: after dividing the original image into a series of non-overlapping blocks, block scrambling and block-level stream cipher encryption are carried out on the image blocks.
(2) Block-wise compression: the pixel in the lower right corner of the encryption block is taken as the reference pixel, and the whole image block is divided into nine types (0–8) according to the bit-plane characteristics of the pixel in the block and the reference pixel. The nine image block types are compressed and their values are marked with binary codes of the same length.
(3) Data embedding: the block type label is embedded into the highest bit-plane of the pixels in the block, and the secret data is embedded into the empty bit-plane.
(4) Image recovery and data extraction: the receiver extracts the corresponding block label set from the highest bit-plane of the pixels in the block after the image is divided into blocks. The secret information is extracted from the spare space. The remaining pixels in the block are recovered according to the partial bit-plane of the reference pixel, and the encryption key is used to decrypt and scramble the block to recover the original image.
3. Proposed Method
In this paper, a new high-capacity reversible data hiding in encrypted image based on bit-plane redundancy of prediction error is proposed, which can extract the secret data correctly and recover the original image losslessly. There are three users in this scheme, which are content owner, data hider and receiver.
Figure 2 shows the framework of the proposed method.
The content owner first preprocesses the original image to obtain the prediction error image and the block type corresponding to the error matrix block. Then the prediction error image and matrix block are encrypted by stream cipher and scrambled, respectively. Finally, the block type was encoded and embedded into the block to obtain the final encrypted image and sent to the data hider.
The data hider extracts its corresponding block type value from the final encrypted image block and decodes it, calculates the spare space and embeds the encrypted secret data in it. The marked encrypted image is sent to the receiver.
The receiver divides the matrix in the marked encrypted image into blocks, extracts auxiliary information from image. According to different keys, the secret data can be extracted and the original image can be recovered, respectively.
3.1. Preprocessing
There are four stages in preprocessing: (1) using SGAP to obtain the prediction image corresponding to the original image, calculating the difference between the two images to obtain the prediction error image. (2) The error matrix in the prediction error image is divided into blocks to obtain the block types. (3) Block type merging. (4) Huffman code block type. The process is shown in
Figure 3. In order to improve the embedding rate of the scheme, multi-level embedding can be performed on the reference error pixels.
3.1.1. Calculating Prediction Error
For the original image
sized
, the three-side edge pixels of the original image are denoted as
and remain unchanged as reference pixels. The content owner uses the SGAP predictor to calculate the corresponding predicted pixel
for
x by Equation (
1).
For pixel
, the predicted pixel generated according to Equation (
1) is denoted as
. All
and reference pixels
form the predicted image
. Calculate the prediction error
corresponding to each pixel of the original image
and the predicted image
except the reference pixel
by Equation (
2).
After the edge reference pixels are removed, all calculated prediction errors are formed an error matrix of size
, denoted as
P. This is shown in the yellow area of
Figure 4.
A location map with the same size as matrix
P is generated to record the positive and negative prediction errors, denoted as
S-map. If the error value is negative, its corresponding position is 1, otherwise, its position is 0, which is used as auxiliary information
for restoration of image pixels. As shown in
Figure 5, an example of the process of generating a location map.
For the values in the error matrix P take their absolute value to obtain the matrix . The prediction error image consisting of edge pixels and matrix is denoted as .
3.1.2. Error Matrix Block Type
The content owner divides the error matrix
of size
into
n non-overlapping
sized blocks
(
i = 1, 2,
,
n.
). Each small matrix block is processed in turn, every block contains
prediction error values expressed by
, where
t = 1, 2,
,
. Use the first error pixel
in the block as the reference pixel. The prediction error values within the block are all converted into an 8-bit binary sequence using Equation (
3).
The prediction error pixels can be obtained by Equation (
4).
For each matrix block B, the content owner in turn compares each bit of reference error pixel and the remaining − 1 prediction error pixels from MSB to LSB until a certain bit is different. Let denote the length of the same bit for all error values in the block after comparison. The bit of a pixel from the most significant bit is denoted as . The former of all error pixels in each block are the same. There are nine different types of blocks at this point.
As shown in
Figure 6, for a matrix block of size
, the reference error pixel is 3, and the remaining error pixels in the block are 2,1,1, respectively. Convert it all to an 8-bit binary sequence:
. After comparing its MSB to LSB in turn, it can be obtained that the six most significant bits are the same as (000000), and only two least significant bits are different. So, this matrix block corresponds to a block type value of 6.
3.1.3. Merge Block Types to Generate -Map
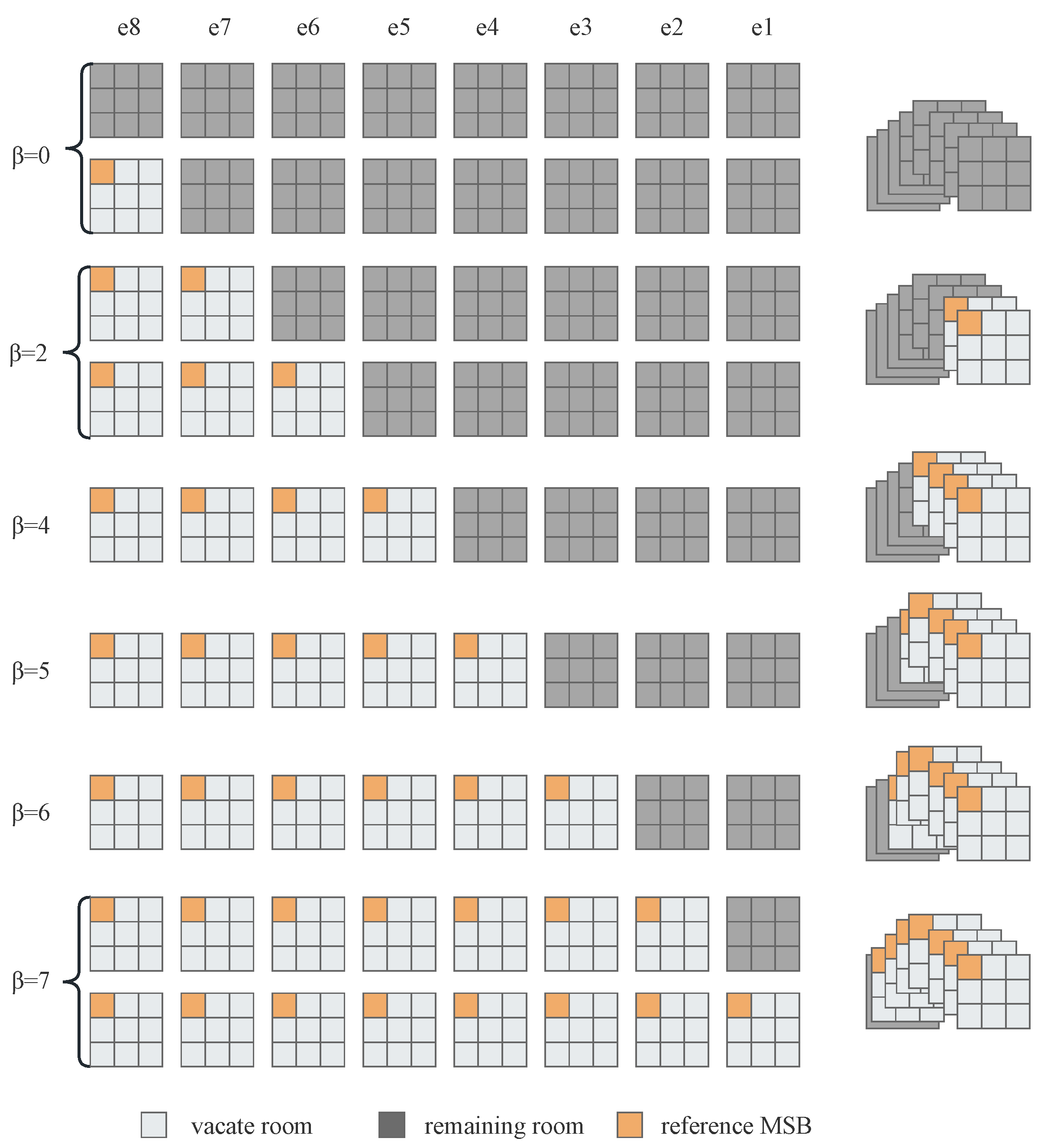
After the content owner sequentially compares the MSB to the LSB of the error pixels in all predicted error blocks B, each matrix block has its corresponding block type value, 0, 1, 2, , 8.
The number of blocks under nine different block types of smooth images Lena and Peppers, and complex images Baboon and Bridge were statistically analyzed in our experiment, as shown in
Table 1. Moreover, we experimented with more images and obtained similar results as in the table. The statistical results show that for smooth images with simple texture, the block types are mostly distributed in
= 4, 5, 6. The types of complex image blocks with rough texture were mostly distributed in
= 2, 3, 4. Therefore, we can merge the block type to reduce its unnecessary space in storage.
In this scheme, the block types are merged into six types. We use to denote the new block type value. For smooth images, if = 0, 1, then = 0. If = 2, 3, then = 2. For widely distributed block types, = 4, 5, 6, then = 4, 5, 6 remains the same. If = 7, 8, then = 7. The smoothed image yields six different block type labels, = 0, 2, 4, 5, 6, 7. For complex images, if = 0, 1, then = 0. If = 2, 3, 4, then = 2, 3, 4 remains unchanged. If = 5, 6, then = 5. If = 7, 8, then = 7. In this way, for complex images we obtain = 0, 2, 3, 4, 5, 7, six different block types. Each matrix block corresponds to a new fixed block type value, thus generating a label map -map of size .
Take a smooth image with simple texture with a block size of
as an example, the spatial distribution of the bit-planes during the merging of the block type is shown in
Figure 7. Where
–
represents eight bit-planes.
For different
values, the room that can be vacated by the corresponding block is
. As shown in
Figure 8, the original nine block types of the smoothed image are merged into six block types, where
represents the space that can be vacated by different block types.
3.1.4. Huffman Encoding Compression
Each matrix block corresponds to a fixed block type value, in this case for a smooth image = 0, 2, 4, 5, 6, 7. For complex images = 0, 2, 3, 4, 5, 7. . The n values obtained after processing the whole image prediction error matrix block. Six fixed-length Huffman codes were used to represent different six block types according to values.
The corresponding binary sequence after encoding is represented by . is the length encoded by Huffman. is the number of times different block types appear in the whole image. The coding rule is the auxiliary information .
Table 2 takes the smooth image Lena with size 512 × 512 and block size 2 × 2 as an example, Huffman coding was used to obtain the coding value corresponding to each block type
.
Equation (
5) is used to calculate the space capacity
that can be vacated by each small block, where
represents the corresponding block type value of block
.
The maximum embedding capacity of this algorithm is
, which is calculated as follows:
The block types are converted into binary sequences and concatenated with corresponding Huffman codes to generate 34 bits coding rules. Taking the smooth image Lena as an example, the coding rules are shown in
Figure 9.
3.2. Image Encryption
After preprocessing, the content owner also needs to encrypt the image using the encryption key to ensure the security of the scheme. The prediction error image composed of error matrix and unchanged image edge pixels was encrypted by stream cipher. Then, the prediction error matrix is divided into blocks and scrambled.
3.2.1. Stream Cipher Encrypts Image
For the prediction error image
, the content owner uses the encryption key
to generate an
pseudo-random matrix
R, and the matrix elements are denoted by
,
. Using Equation (
7), the pixels
corresponding to the image
are encrypted by stream cipher.
where ⊕ denotes the bitwise exclusive-or operation.
3.2.2. Block Scrambling
To further ensure the security of the encrypted image, the content owner scrambles the n error matrix blocks B using the encryption key . The key generates a sequence index of random natural numbers from 1 to n with no repetition . The matrix block B is scrambled with the index sequence to generate a new encryption block sequence .
After the above encryption process, the encrypted image is generated, the security of the image is guaranteed, and the spatial correlation of pixels in the block is not changed. If the selected s cannot completely divide the image into blocks, counts the row and column pixels that cannot be divided, and let its number be . These pixels are encrypted using only stream cipher without subsequent block scrambling.
3.3. Data Hiding
3.3.1. Embedded Block Type Value
The content owner embedded the -map into the encrypted image . Firstly, the encryption error matrix in was divided into blocks according to the same blocking method as in the preprocessing stage, the block scrambling key was used to scramble the -map to the corresponding matrix block position.
Then, all the reference error
in the encryption block,
are converted to an 8-bit binary sequence using Equation (
3), the first pixel
in the encrypted small matrix block as a reference pixel remains unchanged during the embedding process. At last, the encoded values
for the corresponding block type
are embedded into the partial MSB positions of the remaining
error pixels
in the block, where
. The residual bit-plane remains the same.
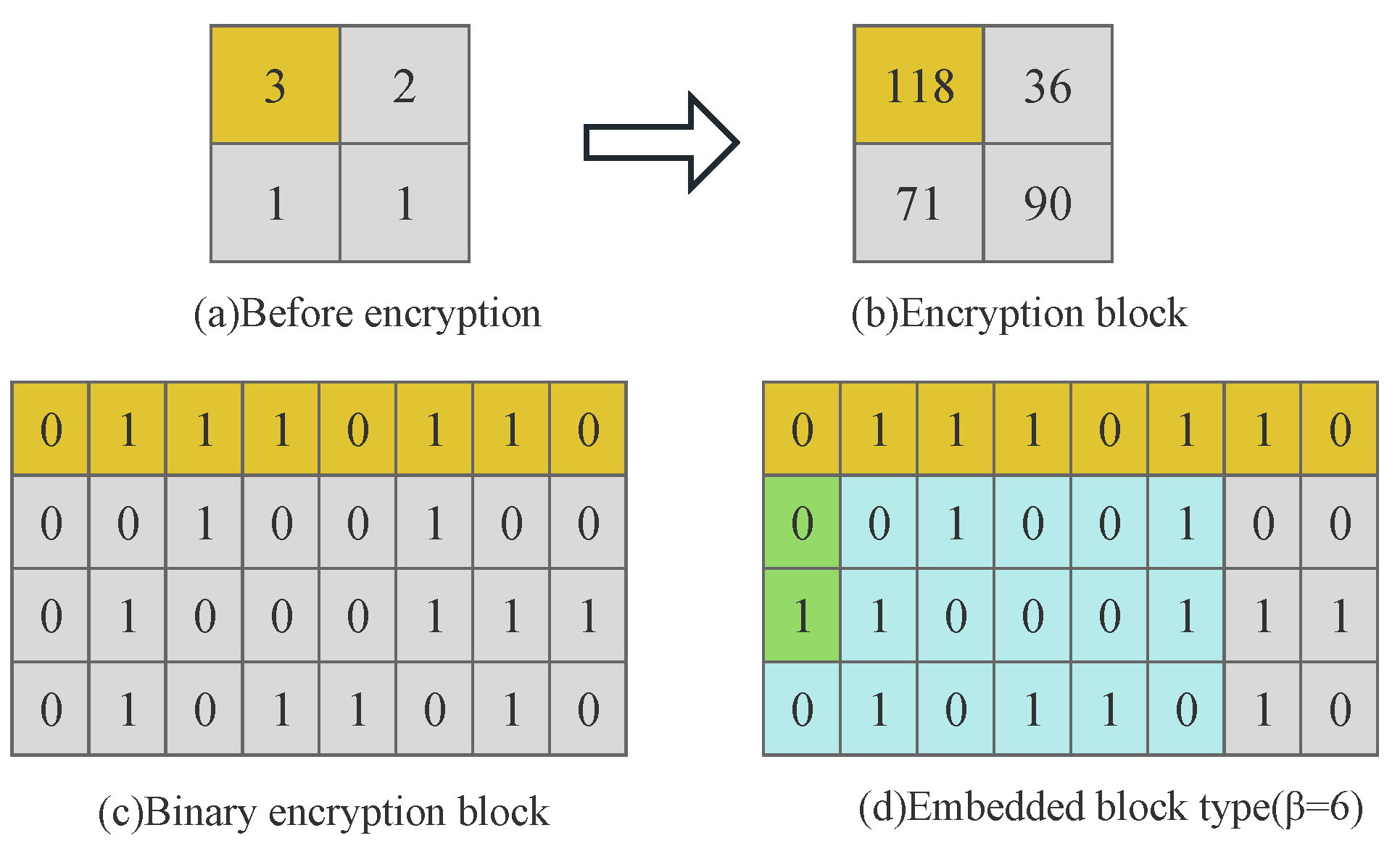
For example, the original block in
Figure 6 is encrypted by stream cipher to generate the encrypted block, the pixels in the encrypted block are converted into an 8-bit binary sequence, respectively. The encoded value
= 01 of the corresponding block type value
= 6 for the original block is embedded into the MSB bit-plane of the error pixels
and
within the encrypted block, as shown in
Figure 10.
In addition to that, the scheme needs to record the two or three bits of MSB replaced by the coded value within the matrix block with = 0 as auxiliary information to indicate that the block experiences overflow. Since the minimum of the block s = 2, the second to + 1 bits of the most significant bit-plane of all pixels within each block represent the block type. The content owner sends the final encrypted image embedded with block type values to the data hider.
3.3.2. Secret Data Embedding
After receiving the final encrypted image
sent by the content owner, the data hider first divides the error matrix
in the final encrypted image into small matrix blocks of size
and extracts the block type encoded values from the second to the fourth bit of the most significant bit-plane of all pixels in each block. The block type is recovered by decoding the encoded values using the encoding rules. Then, Equation (
5) is used to calculate the space capacity
that can be vacated for each small block. Finally, the embedded data is encrypted by stream cipher using the data hiding key
to obtain the encrypted information
, which is embedded into the remaining former
MSBs for the
pixels within the block except the reference pixel in turn.
For example, the blue area in
Figure 10d can be used to embed secret data. The (8−
) LSBs of remaining
pixels and the reference pixel remain unchanged before and after embedding the data.
3.3.3. Multi-Level Embedding
Generally, cover image pixels have high spatial correlation, which also exists for the prediction error pixels, so we can use this feature of pixels to obtain more redundant space. In the above preprocessing process, the reference error pixels in each block do not change. The content owner can extract all the reference error pixels in each matrix block to form a new error matrix, it is divided into blocks to find the corresponding block type label for each block, so as to create more extra room. The above operation can be repeated many times until the reference error matrix becomes a small matrix block that can no longer be segmented by the same method. The multi-level embedding process is shown in
Figure 11.
The size of the final matrix block is denoted by
. This step can be repeated a different number of times for each different block size
s, denoted as
.
Table 3 lists the final small matrix block sizes and the number of multi-level embeddings corresponding to different block sizes when the original image size is 512 × 512.
3.3.4. Auxiliary Information Embedding
Auxiliary information needs to be used in the data extraction and image restoration phases. Therefore, the receiver can successfully receive and extract with a specific method and embedding location. The auxiliary information of this scheme is given as follows.
- (1)
The value of the block size, s, is represented by 4 bits.
- (2)
It takes bits to record S-map.
- (3)
The Huffman coding rules for the six block types are represented by 34 bits.
- (4)
A matrix block with overflow requires bits, where = 0.
- (5)
Multi-level embedding number is represented by 3 bits.
- (6)
The last embedded coordinate is represented by bits.
The three-side edge pixels of the original image are only encrypted with the stream cipher. We connect the auxiliary information to replace the LSB of these pixels. The length of the statistical auxiliary information is denoted as , that is to replace LSBs of the reference pixel . The length value and the replaced LSBs are connected in front of the secret data, and sequentially embed the information flow into the bit-planes vacated by each encryption block. The marked encrypted image is obtained. Send to the receiver.
The formula for calculating the payload of the scheme is as follows, where
represents the maximum embedding capacity at each level of embedding.
3.4. Data Extraction and Image Recovery
In this scheme, data extraction and image recovery are separable. The content owner and the data hider send the encryption key and the data hiding key to the receiver through a specific information transmission channel. The receiver processes the marked encrypted image differently according to different permissions.
: the receiver only has the data hiding key.
: auxiliary information is extracted from the LSB of the edge pixels of the marked encrypted image , including the value of the block size s, the S-map, the coding rules, the MSB of the overflow block replaced, the multi-level embedding level and the last embedding coordinate.
: according to the block size s, the matrix in is divided into non-overlapping blocks of size .
: the encoded value is obtained by extracting the bit-plane consisting of pixels in . The value of is decoded by Huffman coding rule, and the corresponding block location map -map is recovered.
: extract the first pixel in the block forms a new matrix. The above extraction steps 2 and 3 are repeated times.
: after knowing the type value of each block, extract the bit to the bit of the bit-plane of the remaining () pixels in each block except the reference pixel. Up to the last embedding coordinate of the corresponding levels.
: the embedded information flow can be obtained by linking the extracted data together, from which the replaced LSB and the encrypted secret data are decomposed, and the data can be obtained after decrypting the with the data hiding key .
: the receiver only has the image encryption key.
: the method of Case1 is used to obtain the auxiliary information, -map and the edge pixel LSB before replacement, and the LSB is put back to restore the edge pixel.
: according to -map, the MSB in the block with = 0 which is replaced by the encoded value is put back into the block.
: divide the error matrix in the marked encrypted image into blocks of size s, and use the encryption key to reverse scramble the block to restore the encrypted block. Decrypt the image using the pseudo-random sequence of generated by the encryption key .
: the reference error pixels in each block are only encrypted before and after embedding. After decryption, the former MSBs of the reference error pixel can be used to recover MSBs of the remaining pixels in the block. The (8−) LSBs of the remaining pixels within the block has been recovered by decryption.
: the S-map extracted by the LSB of the edge pixels is used to recover the predicted error pixel of the corresponding position.
: the edge pixels use the SGAP to predict the target pixel value, and the prediction error is added to restore the original image .
: the receiver has both the data hiding key and the encryption key.
When the receiver has both the encryption key and the data hiding key, the steps in Case1 and Case2 are used to perfectly extract the secret data and recover the original image.
4. Analysis of Experimental Results
To prove the superiority of the performance of our proposed scheme, twelve grayscale images of size 512 × 512 as shown in
Figure 12, Lena, Baboon, Bridge, Boat, Cameraman, Cat, Jetplane, Goldhill, Man, Peppers, Barbara, Zelda are selected for performance testing. We also tested the performance of different methods in two datasets, BOSSbase [
24] and BOWS-2 [
25].
The embedding rate (ER) expressed in bpp. The formula is as follows:
In addition, PSNR defined in Equation (
10) and SSIM defined in Equation (
12) are used to test the reversibility of the method. The peak signal-to-noise ratio (PSNR) is used to estimate the visual quality of the recovered image
y with the original image
x.
The structural similarity (SSIM) is a measure of the similarity of two images, where
is the mean,
is the variance,
are constants. When the two images are the same, the value of SSIM is equal to 1.
4.1. Security Analysis
4.1.1. Key Spaces
In the encryption process, two different keys are used for different encryption operations. Key
uses stream cipher to generate a key matrix of size
to encrypt the prediction error image, where
, so its key space is
. Key
generates a sequence of 1 to
n nonrepeated random natural numbers to scramble
n image blocks, and its key space
. So, the total key space size
of the proposed scheme is calculated as follows:
Obviously, the key space of the scheme is quite large, so if the attacker wants to establish the same key in a short time to directly decrypt the image, it is very difficult.
4.1.2. Shannon Entropy
Image Shannon entropy is a statistical form of feature that can be used to measure the randomness of an information source. The greater the information entropy, the greater the uncertainty and randomness of the system. The maximum value of the Shannon information entropy is 8. The calculation formula is given by Equation (
14).
where
is the probability that a certain pixel gray value occurs in that image. Experiments on several standard images in
Figure 12 obtained
Table 4, it is found that the information entropy of the encrypted image is higher than that of the original image, and tends to the maximum value, indicating that the security of the algorithm can be guaranteed.
4.1.3. Single Image Test
Figure 13 takes the grayscale image Lena of size 512 × 512 and block size 2 × 2 as an example. (a) is the original image Lena. (b) is the encrypted image obtained from the prediction error image after encrypting the image stream cipher and scrambling the blocks. (c) is the restored cover image. (d) to (f) are the corresponding histograms.
For the encrypted image (b), the original image can no longer be distinguished visually. By comparing the original image (a) and the restored cover image (c) PSNR = ∞ and SSIM = 1 are obtained, that is, the scheme is reversible.
Figure 13d is the pixel histogram of the original image with continuous distribution of pixel values, and (e) is the pixel histogram of the encrypted image. The distribution of pixel values is uniform. The encrypted image has a completely different visual image and histogram distribution from the original image. Therefore, the attacker cannot determine the specific distribution of the original image pixels by histogram detection technology.
4.2. Performances under Different Parameters
In this scheme, the embedding rate is greatly affected by different block sizes.
Table 5 lists the embedding rates of the twelve images in
Figure 12 with different block sizes
s = 2,
s = 3,
s = 4,
s = 5,
s = 8 before and after multi-level embedding, respectively. The ER without multi-level embedding is denoted as BER, and the ER after the corresponding
-level embedding in
Table 3 for different block sizes is denoted as AER.
For multi-level embedding, this method can effectively improve the embedding rate of the scheme. However, when the matrix block size is large, the reference prediction error pixels of the previous unchanged are less, resulting in the decrease of embedding layer , and ER cannot be effectively improved. When the texture of the image is stronger, the spatial correlation of the pixels in the image block is lower, even fewer bits can be vacated, resulting in the decrease of the ER.
For a single test image, as the block size increases, although the available bits decrease, the block needs to store block type information also decreases, so the ER increases. However, when the block size exceeds 4, the spatial correlation of pixels in the image block is weakened, and ER will decrease.
4.3. Performance Comparison of Different Schemes
To better show the performance of the proposed scheme, the embedding rates obtained by the proposed scheme using 3 × 3 size blocks are compared with the five latest schemes, as shown in
Figure 14. The embedding rate of the proposed scheme is better than them, especially for smooth images with simple textures, which is twice that of the previous scheme [
22].
In order to test the ability of the proposed algorithm for data compression, we experimented on the BMP format of the twelve standard grayscale images in
Figure 12. Equation (
15) is used to calculate their respective compression rates
, where
and
represent the space occupied by the image before and after compression, respectively. When the
is larger, it means that the more spare rooms of the image can be used to embed the secret information, and the embedding rate is larger.
The
obtained by the proposed scheme with the optimal parameters are compared with the existing lossless compression algorithms JPEG-LS and PNG, as shown in
Table 6. From the data in the table, it can be obtained that the compression ratio of the scheme is higher than the other two in most cases, which further indicates that the performance of our scheme is better.
The scheme is processed for pixels within the original image of size
, the complexity of dividing the image into blocks is
, and the complexity of processing the pixels in the block is
. Since
, the whole complexity of the algorithm is
, which has high efficiency. The execution time of the proposed scheme for test images is counted and compared with the existing compression schemes, as shown in the right column of
Table 6. Although the time of our algorithm is slightly longer than that of the other two, it is still within the acceptable range.
In addition,
Table 7 compares the feature of the proposed algorithm with RRBE-based schemes [
12,
13], VRAE-based schemes [
18,
19,
22]. It can be seen that all schemes can achieve reversibility, the proposed scheme uses better prediction methods to reduce prediction errors to improve embedding capacity and combines their encryption methods to have a high security level.
We also selected 100 images from two image datasets, BOSSBase [
24] and BOWS-2 [
25], respectively. When the test block size is
s = 3, the embedding rate of the scheme is shown in
Figure 15, and the experimental results are shown in
Table 8. The average embedding rate is over 3.5 bpp for two datasets, with PSNR = +
∞ and SSIM = 1 for all images in the experiment. The embedding rate is improved while ensuring the reversibility of the scheme.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}