
Traffic Flow Prediction Based on Dynamic Graph Spatial-Temporal Neural Network

Abstract
1. Introduction
- A multi-scale time-gated convolution is proposed to capture different temporal finesse and, based on an improved adaptive spatial self-attention mechanism, the node correlation of the real spatial relationship is calculated.
- The design is a set of adaptive graphs: a static topology graph combined with an adjacency matrix as prior information and an adaptive embedding matrix to capture real node dependencies. By capturing the similarity of changes in flow information, a set of dynamic information graphs is constructed to obtain a dynamic spatial correlation.
- Results tested on two real-world datasets and show that the framework proposed in this paper achieves the best results when compared with various baselines.
2. Literature Review
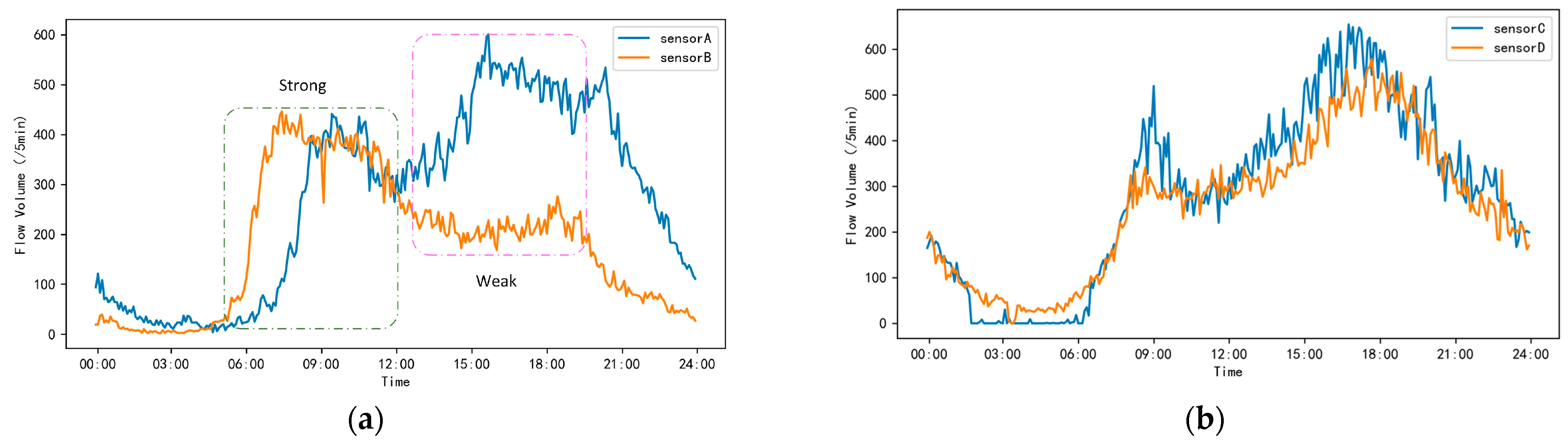
2.1. Space-Time Traffic Forecast
2.2. Graph Convolution
2.3. Attention Mechanisms
3. Materials and Methods
3.1. Problem Formulation
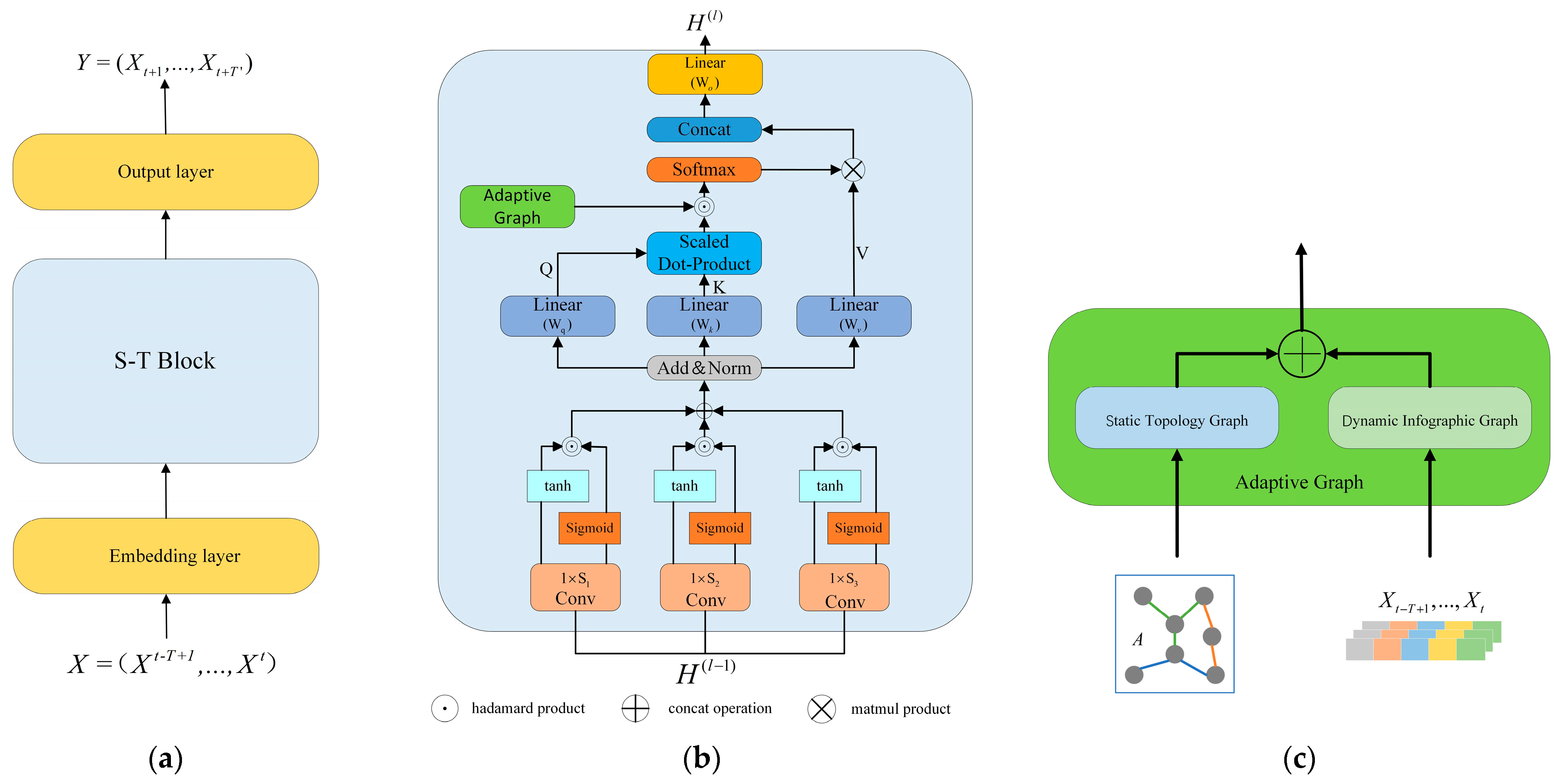
3.2. Dynamic Graph Spatial-Temporal Neural Network
3.2.1. Adaptive Graph
Static Topology Graph
Dynamic Information Graph
3.2.2. Multi-Scale Gated Time Convolution
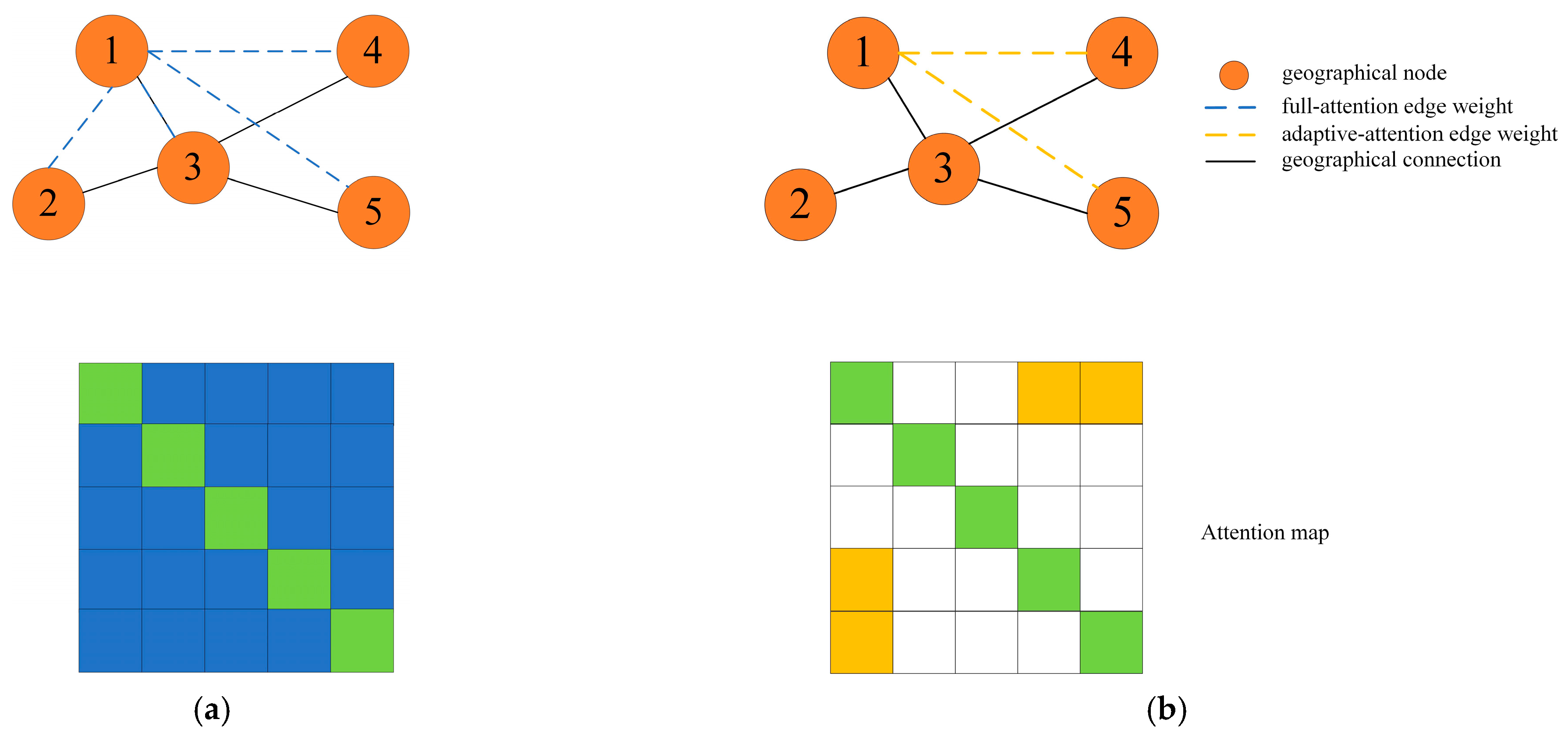
3.2.3. Spatial Attention
3.2.4. Input and Output Layer
4. Results and Discussion
4.1. Datasets
- PeMS04: Traffic data collected by Caltrans Performance Measurement System (PeMS) from 307 detectors in the San Francisco Bay Area from 1 January 2018 to 28 February 2018.
- PeMS08: Traffic information collected by the Caltrans Performance Measurement System (PeMS) from 170 detectors in the San Bernardino area from 1 July 2016 to 31 August 2016.
4.2. Baseline Method
- HA: Historical average value, which uses traffic flow data from the past period and calculates its average value to achieve prediction.
- ARIMA [8]: The Kalman filter autoregressive comprehensive moving-average model is a classic time-series prediction model.
- FNN: feedforward neural network, the neural network of multiple hidden layers.
- LSTM: Due to its memory function, LSTM can use long sequence information to construct learning models.
- DCRNN [13]: Diffusion convolutional recurrent neural network combines a recurrent neural network with diffusion convolution to model the relationship between traffic inflow and outflow.
- ASTGCN [15]: An attention-based spatiotemporal graph convolutional network for traffic flow prediction. By overlaying attention layers and convolutional layers, temporal and spatial features in the data were proposed to obtain more effective temporal and temporal features.
- STSGCN [18]: Spatiotemporal synchronous graph convolutional network. To more effectively capture complex local spatiotemporal correlations more, a spatiotemporal synchronization graph modeling mechanism is proposed.
- GWN [16]: Graph WaveNet for deep spatiotemporal graph modeling. A graph convolutional architecture, which proposes an adaptive graph to capture spatial correlations and uses diffusion convolution to capture temporal relationships, is suggested.
- AGCRN [24]: An adaptive graph convolutional recursive network for traffic volume prediction. This modifies commonly used graph convolutions through node-adaptive parameter learning and adaptive graph-generation modules, and combines graph convolution with GRU to explore spatiotemporal correlations in data.
- ASTGNN [30]: The learning dynamics and heterogeneity of spatiotemporal map data for traffic prediction. This model adopts a self-attention mechanism to capture features in both temporal and spatial dimensions.
4.3. Experiment Settings
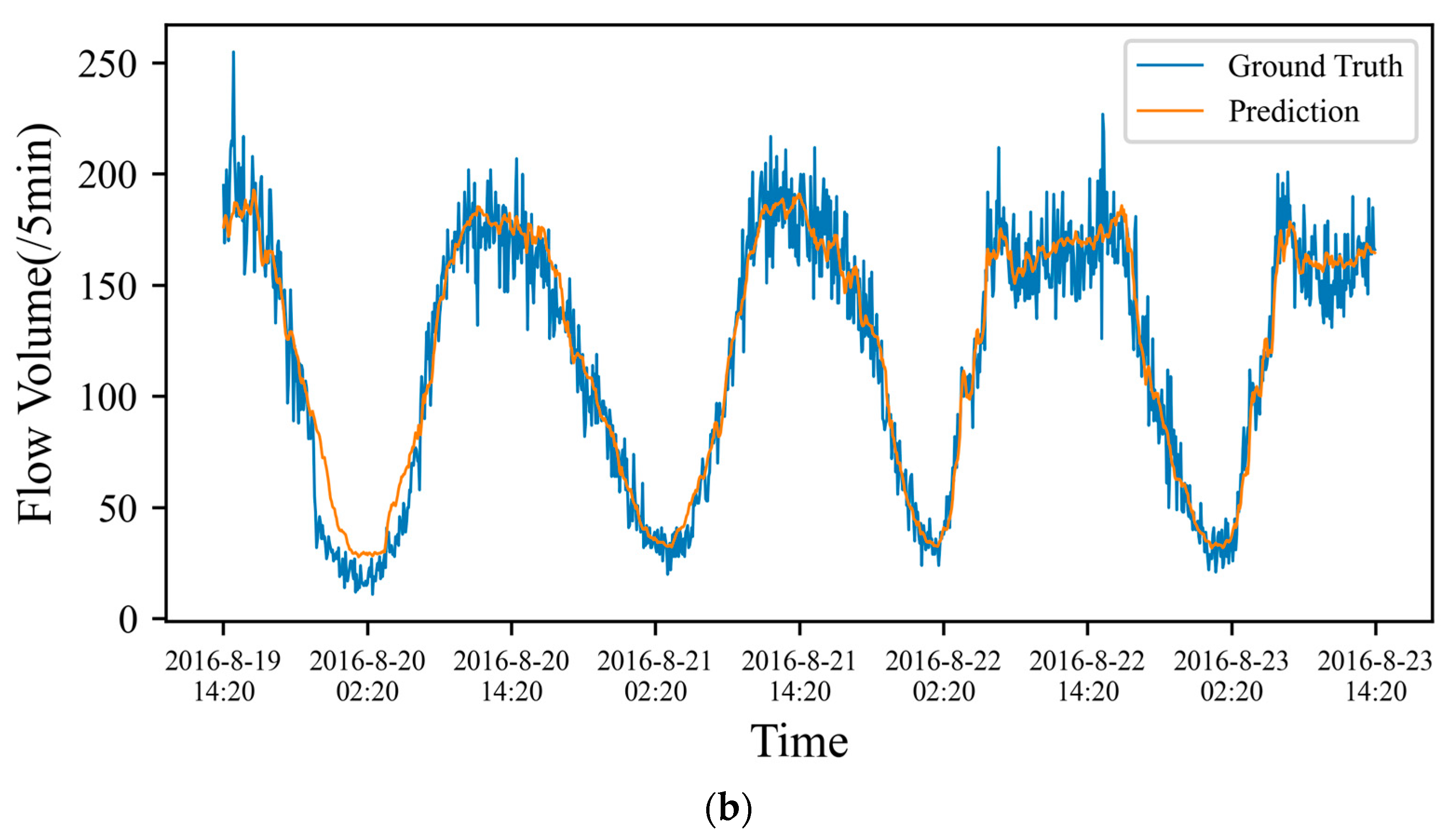
4.4. Performance Comparison
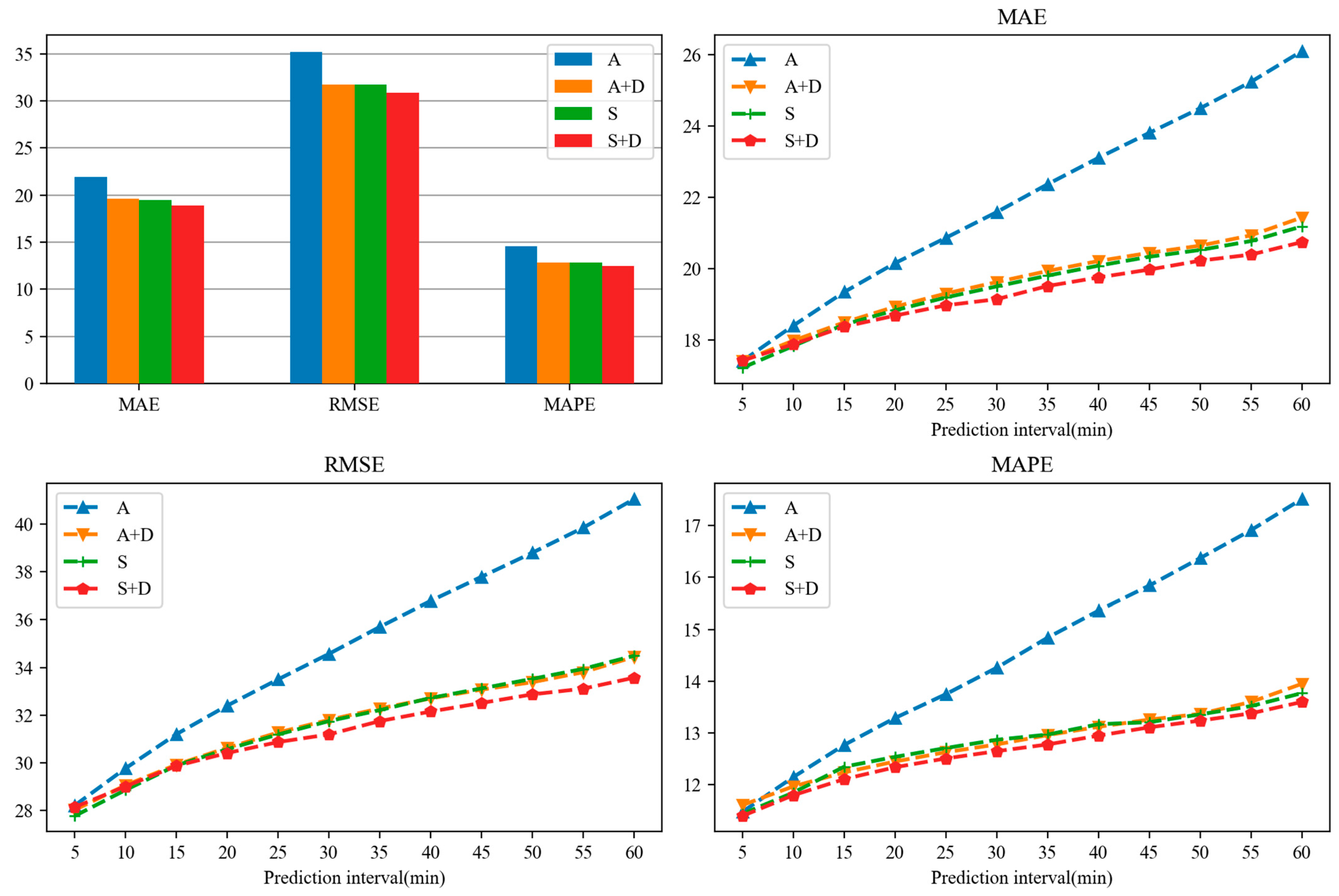
4.5. Ablation Experiment
4.6. Model Efficiency Study
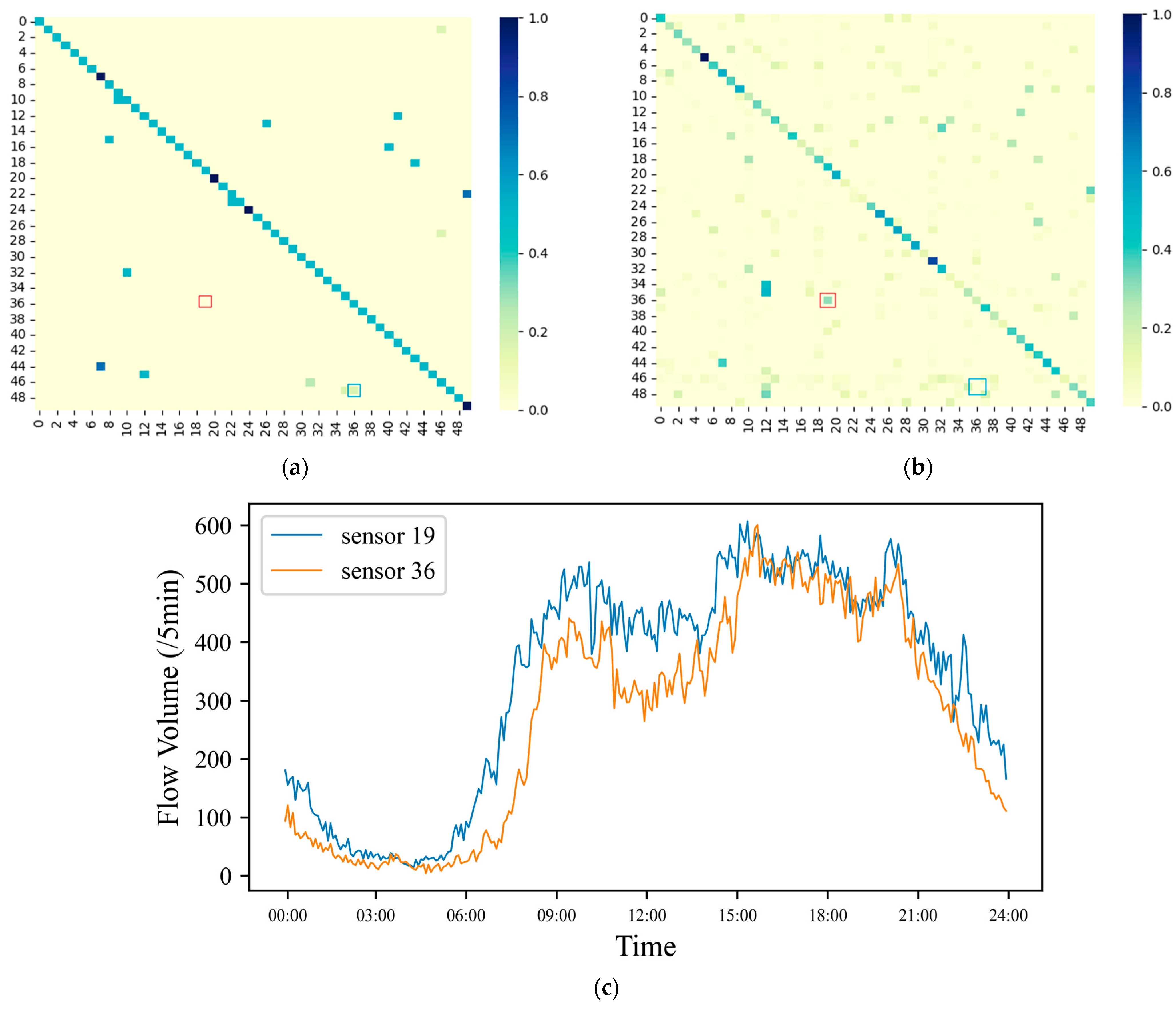
4.7. Research on the Validity of Static Topology Graph
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wan, S.; Ding, S.; Chen, C. Edge computing enabled video segmentation for real-time traffic monitoring in internet of vehicles. Pattern Recognit. 2022, 121, 108146. [Google Scholar] [CrossRef]
- Busacca, F.; Grasso, C.; Palazzo, S.; Schembra, G. A smart road side unit in a microeolic box to provide edge computing for vehicular applications. IEEE Trans. Green Commun. Netw. 2022, 7, 194–210. [Google Scholar] [CrossRef]
- Spandonidis, C.; Giannopoulos, F.; Sedikos, E.; Reppas, D.; Theodoropoulos, P. Development of a MEMS-based IoV system for augmenting road traffic survey. IEEE Trans. Instrum. Meas. 2022, 71, 1–8. [Google Scholar] [CrossRef]
- Chu, T.; Wang, J.; Codecà, L.; Li, Z. Multi-agent deep reinforcement learning for large-scale traffic signal control. IEEE Trans. Intell. Transp. Syst. 2019, 21, 1086–1095. [Google Scholar] [CrossRef]
- Feng, J.; Li, Y.; Zhang, C.; Sun, F.; Meng, F.; Guo, A.; Jin, D. Deepmove: Predicting human mobility with attentional recurrent networks. In Proceedings of the 2018 World Wide Web Conference, Lyon, France, 23–27 April 2018; pp. 1459–1468. [Google Scholar] [CrossRef]
- Gao, Q.; Zhou, F.; Trajcevski, G.; Zhang, K.; Zhong, T.; Zhang, F. Predicting human mobility via variational attention. In Proceedings of the World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 2750–2756. [Google Scholar] [CrossRef]
- Chen, C.; Petty, K.; Skabardonis, A. Freeway performance measurement system: Mining loop detector data. Transp. Res. Rec. 2001, 1748, 96–102. [Google Scholar] [CrossRef]
- Williams, B.M.; Hoel, L.A. Modeling and forecasting vehicular traffic flow as a seasonal ARIMA process: Theoretical basis and empirical results. J. Transp. Eng. 2003, 129, 664–672. [Google Scholar] [CrossRef]
- Jeong, Y.S.; Byon, Y.J.; Castro-Neto, M.M.; Easa, S.M. Supervised weighting-online learning algorithm for short-term traffic flow prediction. IEEE Trans. Intell. Transp. Syst. 2013, 14, 1700–1707. [Google Scholar] [CrossRef]
- Van Lint, J.W.C.; Van Hinsbergen, C. Short-term traffic and travel time prediction models. Artif. Intell. Appl. Crit. Transp. Issues 2012, 22, 22–41. [Google Scholar]
- Bildirici, M.; Bayazit, N.G.; Ucan, Y. Modelling oil price with lie algebras and long short-term memory networks. Mathematics 2021, 9, 1708. [Google Scholar] [CrossRef]
- Ersin, Ö.Ö.; Bildirici, M. Financial Volatility Modeling with the GARCH-MIDAS-LSTM Approach: The Effects of Economic Expectations, Geopolitical Risks and Industrial Production during COVID-19. Mathematics 2023, 11, 1785. [Google Scholar] [CrossRef]
- Li, Y.; Yu, R.; Shahabi, C. Diffusion convolutional recurrent neural network: Data-driven traffic forecasting. arXiv 2017, arXiv:1707.01926. [Google Scholar] [CrossRef]
- Seo, Y.; Defferrard, M.; Vandergheynst, P.; Bresson, X. Structured sequence modeling with graph convolutional recurrent networks. In Proceedings of the Neural Information Processing: 25th International Conference, ICONIP 2018, Siem Reap, Cambodia, 13–16 December 2018; pp. 362–373. [Google Scholar] [CrossRef]
- Yan, S.; Xiong, Y.; Lin, D. Spatial temporal graph convolutional networks for skeleton-based action recognition. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar] [CrossRef]
- Wu, Z.; Pan, S.; Long, G. Graph wavenet for deep spatial-temporal graph modeling. arXiv 2019, arXiv:1906.00121. [Google Scholar] [CrossRef]
- Guo, S.; Lin, Y.; Feng, N.; Song, C.; Wan, H. Attention based spatial-temporal graph convolutional networks for traffic flow forecasting. In Proceedings of the AAAI conference on artificial intelligence, Honolulu, HI, USA, 27–28 January 2019; pp. 922–929. [Google Scholar] [CrossRef]
- Song, C.; Lin, Y.; Guo, S.; Wan, H. Spatial-temporal synchronous graph convolutional networks: A new framework for spatial-temporal network data forecasting. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 914–921. [Google Scholar] [CrossRef]
- Oord, A.; Dieleman, S.; Zen, H. Wavenet: A generative model for raw audio. arXiv 2016, arXiv:1609.03499. [Google Scholar] [CrossRef]
- Bai, S.; Kolter, J.Z.; Koltun, V. An empirical evaluation of generic convolutional and recurrent networks for sequence modeling. arXiv 2018, arXiv:1803.01271. [Google Scholar] [CrossRef]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar] [CrossRef]
- Yu, B.; Yin, H.; Zhu, Z. Spatial-temporal graph convolutional networks: A deep learning framework for traffic forecasting. arXiv 2017, arXiv:1709.04875. [Google Scholar] [CrossRef]
- Chen, W.; Chen, L.; Xie, Y.; Cao, W.; Gao, Y.; Feng, X. Multi-range attentive bicomponent graph convolutional network for traffic forecasting. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 3529–3536. [Google Scholar] [CrossRef]
- Bai, L.; Yao, L.; Li, C.; Wang, C. Adaptive graph convolutional recurrent network for traffic forecasting. Adv. Neural Inf. Process. Syst. 2020, 33, 17804–17815. [Google Scholar] [CrossRef]
- Beltagy, I.; Peters, M.E.; Cohan, A. Longformer: The long-document transformer. arXiv 2020, arXiv:2004.05150. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar] [CrossRef]
- Arnab, A.; Dehghani, M.; Heigold, G.; Sun, C.; Lučić, M.; Schmid, C. Vivit: A video vision transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 20–25 June 2021; pp. 6836–6846. [Google Scholar]
- Bao, H.; Dong, L.; Piao, S.; Wei, F. Beit: Bert pre-training of image transformers. arXiv 2021, arXiv:2106.08254. [Google Scholar] [CrossRef]
- Zheng, C.; Fan, X.; Wang, C.; Qi, J. Gman: A graph multi-attention network for traffic prediction. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 1234–1241. [Google Scholar] [CrossRef]
- Guo, S.; Lin, Y.; Wan, H. Learning dynamics and heterogeneity of spatial-temporal graph data for traffic forecasting. IEEE Trans. Knowl. Data Eng. 2021, 34, 5415–5428. [Google Scholar] [CrossRef]
- Xu, M.; Dai, W.; Liu, C.; Gao, X.; Lin, W.; Qi, G.J.; Xiong, H. Spatial-temporal transformer networks for traffic flow forecasting. arXiv 2020, arXiv:2001.02908. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar] [CrossRef]
- Shao, Z.; Zhang, Z.; Wei, W.; Wang, F.; Xu, Y.; Cao, X.; Jensen, C.S. Decoupled dynamic spatial-temporal graph neural network for traffic forecasting. arXiv 2022, arXiv:2206.09112. [Google Scholar] [CrossRef]
- Shin, Y.; Yoon, Y. Pgcn: Progressive graph convolutional networks for spatial-temporal traffic forecasting. arXiv 2022, arXiv:2202.08982. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Nodes | Edges | Time Steps | Time Range |
|---|---|---|---|---|
| PeMS04 | 307 | 340 | 16,992 | 1 January 2018–28 February 2018 |
| PeMS08 | 170 | 295 | 17,856 | 1 July 2016–31 August 2016 |
| Model | PeMS04 | PeMS08 | ||||
|---|---|---|---|---|---|---|
| MAE | RMSE | MAPE (%) | MAE | RMSE | MAPE (%) | |
| HA | 24.50 | 39.83 | 16.58 | 21.19 | 36.64 | 13.79 |
| ARIMA | 31.55 | 47.57 | 21.40 | 25.27 | 37.77 | 15.539 |
| FNN | 26.82 | 41.56 | 19.98 | 22.40 | 34.71 | 22.47 |
| LSTM | 25.69 | 40.02 | 17.76 | 20.24 | 31.84 | 12.78 |
| DCRNN | 23.05 | 35.72 | 15.97 | 18.29 | 28.61 | 11.62 |
| ASTGCN | 21.99 | 34.97 | 14.49 | 18.53 | 28.69 | 11.21 |
| STSGCN | 21.41 | 34.28 | 14.49 | 17.79 | 27.37 | 11.70 |
| GWN | 20.82 | 32.35 | 14.70 | 15.86 | 24.97 | 10.13 |
| AGCRN | 19.68 | 32.27 | 13.04 | 16.90 | 26.77 | 10.53 |
| ASTGNN | 19.33 | 31.20 | 13.14 | 15.81 | 25.03 | 9.97 |
| DGSTN | 18.88 | 30.86 | 12.47 | 15.27 | 24.33 | 9.82 |
| Model | MAE | RMSE | MAPE (%) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 15 min | 30 min | 60 min | 15 min | 30 min | 60 min | 15 min | 30 min | 60 min | |
| HA | 22.03 | 25.98 | 34.92 | 34.42 | 40.01 | 52.03 | 16.83 | 19.27 | 25.51 |
| LSTM | 21.13 | 24.90 | 33.40 | 33.25 | 38.54 | 49.96 | 14.26 | 16.98 | 23.89 |
| DCRNN | 19.95 | 22.64 | 28.15 | 31.30 | 34.97 | 42.29 | 13.60 | 15.57 | 19.97 |
| ASTGCN | 19.84 | 21.62 | 25.99 | 31.62 | 34.27 | 40.60 | 13.20 | 14.34 | 16.87 |
| STSGCN | 19.80 | 21.24 | 24.20 | 31.93 | 34.04 | 38.18 | 13.51 | 14.24 | 16.31 |
| GWN | 19.03 | 20.68 | 23.88 | 29.87 | 32.15 | 36.53 | 13.03 | 14.82 | 17.38 |
| AGCRN | 18.87 | 19.59 | 21.07 | 30.89 | 32.13 | 34.36 | 12.55 | 13.00 | 13.89 |
| ASTGNN | 18.17 | 19.45 | 21.30 | 29.53 | 31.57 | 34.36 | 12.55 | 12.77 | 13.95 |
| DGSTN | 18.04 | 19.09 | 20.55 | 29.59 | 31.53 | 33.81 | 12.11 | 12.74 | 13.72 |
| Model | MAE | RMSE | MAPE (%) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 15 min | 30 min | 60 min | 15 min | 30 min | 60 min | 15 min | 30 min | 60 min | |
| HA | 18.28 | 21.45 | 29.81 | 28.23 | 33.26 | 44.40 | 20.33 | 21.86 | 26.46 |
| LSTM | 16.57 | 19.61 | 26.58 | 25.88 | 30.76 | 40.29 | 10.30 | 12.29 | 17.14 |
| DCRNN | 15.79 | 18.02 | 22.49 | 24.45 | 28.08 | 34.48 | 10.01 | 11.42 | 14.31 |
| ASTGCN | 16.35 | 18.40 | 22.25 | 25.25 | 28.43 | 33.77 | 10.11 | 11.06 | 13.10 |
| STSGCN | 16.40 | 17.68 | 20.15 | 25.10 | 27.35 | 30.92 | 10.91 | 11.52 | 13.01 |
| GWN | 14.49 | 15.85 | 17.91 | 22.75 | 25.10 | 28.21 | 9.18 | 10.10 | 11.31 |
| AGCRN | 15.45 | 16.68 | 19.53 | 24.25 | 26.43 | 30.78 | 9.63 | 10.34 | 12.19 |
| ASTGNN | 14.23 | 15.78 | 18.25 | 22.47 | 24.99 | 28.55 | 9.23 | 9.92 | 11.22 |
| DGSTN | 14.26 | 15.30 | 16.92 | 22.46 | 24.41 | 26.89 | 9.20 | 9.76 | 10.84 |
| Model | Computation Time | |
|---|---|---|
| Training (s/Epoch) | Inference (s) | |
| DCRNN | 93.20 s | 11.91 s |
| STSGCN | 196.98 s | 26.69 s |
| ASTGCN | 84.39 s | 9.45 s |
| ASTGNN | 101.37 s | 47.91 s |
| DGSTN | 74.01 s | 9.99 s |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, M.; Liu, Z. Traffic Flow Prediction Based on Dynamic Graph Spatial-Temporal Neural Network. Mathematics 2023, 11, 2528. https://doi.org/10.3390/math11112528
Jiang M, Liu Z. Traffic Flow Prediction Based on Dynamic Graph Spatial-Temporal Neural Network. Mathematics. 2023; 11(11):2528. https://doi.org/10.3390/math11112528
Chicago/Turabian StyleJiang, Ming, and Zhiwei Liu. 2023. "Traffic Flow Prediction Based on Dynamic Graph Spatial-Temporal Neural Network" Mathematics 11, no. 11: 2528. https://doi.org/10.3390/math11112528
APA StyleJiang, M., & Liu, Z. (2023). Traffic Flow Prediction Based on Dynamic Graph Spatial-Temporal Neural Network. Mathematics, 11(11), 2528. https://doi.org/10.3390/math11112528