
A Multi-Scaling Reinforcement Learning Trading System Based on Multi-Scaling Convolutional Neural Networks


Abstract
:1. Introduction
- Our research presents a new network structure, MS-CNN, for extracting multi-scaling features for studying financial markets. This network can automatically explore multi-scaling features of daily and weekly trading data through multi-scaling CNN, similar to the attention humans pay to information at different temporal and spatial scaling during stock trading. Additionally, we employ a backbone CNN to extract stock features and introduce an average pooling layer to prevent overfitting and enhance the network’s robustness. Our findings demonstrate that a multi-scaling CNN can detect more reliable information in this task.
- By taking advantage of the multi-scaling CNN, we propose the MS-CNN-SARSA model using an on-policy reinforcement learning algorithm, namely SARSA, which tends to avoid dangerous strategies in the presence of a large number of negative rewards when close to the optimal path. In this way, the agent is able to generate dynamic trading strategies by learning multi-scaling information on different time scaling on the stock market.
- Our experimental results on four real datasets demonstrate the significant performance of the proposed model. By extracting multi-scaling features, the agent can act over longer time scaling. To be more specific, the agent identifies a weekly low for a stock and buys at that point without being swayed by the daily fluctuations of the stock during successive declines. In addition, we performed several experiments of comparison and ablation to validate the excellent network structure. This includes comparing the performance of MS-CNN-SARSA using modules of different sizes and network structures with different activation functions.
2. Literature Review
2.1. Reinforcement Learning in a Trading System
2.2. Time Series-Based Multi-Scaling Learning
3. The Formulation of Problem
4. Methodology
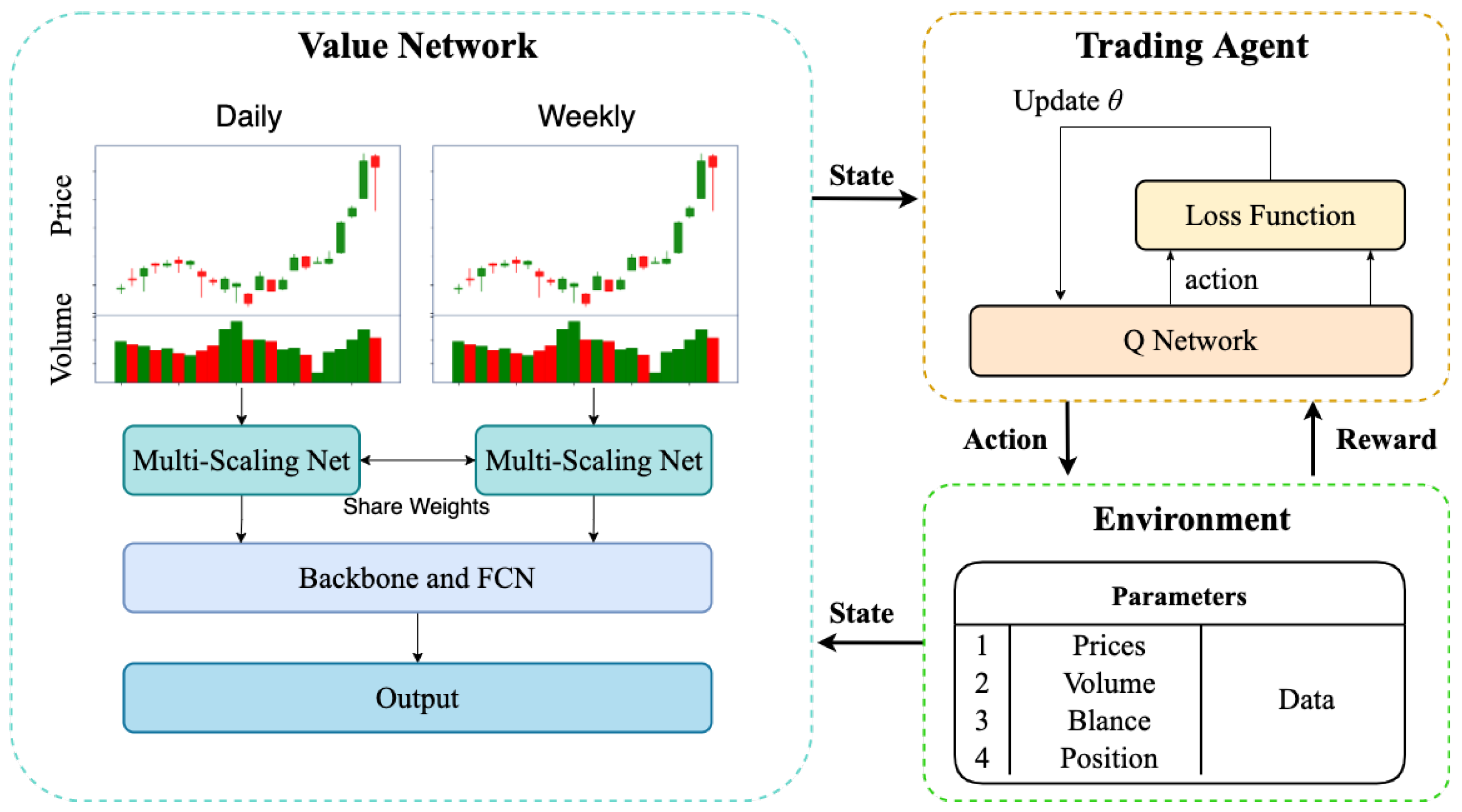
4.1. System Overview
4.2. The Structure of Q-Network Based on Multi-Scaling CNN
4.3. MS-CNN-SARSA Algorithm
| Algorithm 1 MS-CNN-SARSA Algorithm |
Input: opening, high, low, closing prices, and transaction volume;
|
5. Experiments and Results
5.1. Dataset
5.2. Evaluation Indicators
- Profit: The profit of trading activities is a measure of the capital that has been gained or lost. To determine the profit at each time step t, we utilized Equation (7), which involved calculating the profit using the present amount and the initial amount .
- Sharpe ratio (SR): This ratio shows the average return earned per unit of total risk over the risk-free rate, which is computed in Equation (8), where refers to the risk-free asset return and refers to the expected value of the portfolio value. We assumed in this study.
- Annualized return (AR): AR represents an investment’s average percentage of profits and losses generated through trading activity over a one-year period.where CR is calculated by .
5.3. Baseline Methods
- Buy and hold: This involves the investor choosing an investment asset with a long position in the initial investment phase. Once the asset is purchased, it is held until the end of the period, regardless of any changes in its price.
- Sell and hold: This involves the investor choosing an investment asset with a short position in the initial investment phase. Once the asset is purchased, it is held until the end of the period, regardless of any changes in its price.
- DQN-Pattern: This learns suitable trading patterns according to candlestick patterns for a specific stock. More details can be seen in [24].
- DQN-Vanilla: This involves using raw candlestick data to train a fitted learning algorithm to create trading rules. More details can be seen in [24].
5.4. Experimental Setup
5.5. Experimental Results
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Poterba, J.M.; Summers, L.H. Mean Reversion in Stock Prices: Evidence and Implications; Social Science Electronic Publishing: London, UK, 1988. [Google Scholar]
- Moody, J.E.; Saffell, M.J. Reinforcement learning for trading. In Proceedings of the NIPS’98: 11th International Conference on Neural Information Processing Systems, Denver, CO, USA, 30 November–5 December 1998; Volume 17, pp. 917–923. [Google Scholar]
- Neuneier, R. Enhancing Q-learning for optimal asset allocation. In Proceedings of the NIPS’98: 11th International Conference on Neural Information Processing Systems, Denver, CO, USA, 30 November–5 December 1998; pp. 936–942. [Google Scholar]
- Corazza, M.; Sangalli, A. Q-Learning and SARSA: A Comparison between Two Intelligent Stochastic Control Approaches for Financial Trading. SSRN Electron. J. 2015. [Google Scholar] [CrossRef]
- Yan, C.; Mabu, S.; Hirasawa, K. Genetic network programming with sarsa learning and its application to creating stock trading rules. In Proceedings of the 2007 IEEE Congress on Evolutionary Computation, Singapore, 25–28 September 2007; pp. 220–227. [Google Scholar]
- Moody, J.; Saffell, M. Learning to trade via direct reinforcement. IEEE Trans. Neural Netw. 2001, 12, 875–889. [Google Scholar] [CrossRef] [PubMed]
- Gold, C. FX trading via recurrent reinforcement learning. In Proceedings of the 2003 IEEE International Conference on Computational Intelligence for Financial Engineering, Hong Kong, China, 20–23 March 2003; pp. 363–370. [Google Scholar]
- Zhang, J.; Maringer, D. Indicator selection for daily equity trading with recurrent reinforcement learning. In Proceedings of the 15th Annual Conference Companion on Genetic and Evolutionary Computation, Amsterdam, The Netherlands, 6–10 July 2013; pp. 1757–1758. [Google Scholar]
- Zhang, J.; Maringer, D. Using a genetic algorithm to improve recurrent reinforcement learning for equity trading. Comput. Econ. 2016, 47, 551–567. [Google Scholar] [CrossRef]
- Yue, D.; Feng, B.; Kong, Y.; Ren, Z.; Dai, Q. Deep Direct Reinforcement Learning for Financial Signal Representation and Trading. IEEE Trans. Neural Netw. Learn. Syst. 2016, 28, 653–664. [Google Scholar]
- Liu, F.; Li, Y.; Li, B.; Li, J.; Xie, H. Bitcoin transaction strategy construction based on deep reinforcement learning. Appl. Soft Comput. 2021, 113, 107952. [Google Scholar] [CrossRef]
- Mahayana, D.; Shan, E.; Fadhl’Abbas, M. Deep Reinforcement Learning to Automate Cryptocurrency Trading. In Proceedings of the 2022 12th International Conference on System Engineering and Technology (ICSET), Bandung, Indonesia, 3–4 October 2022; pp. 36–41. [Google Scholar]
- Tsai, Y.-C.; Szu, F.-M.; Chen, J.-H.; Chen, S.Y.-C. Financial Vision-Based Reinforcement Learning Trading Strategy. Analytics 2022, 1, 35–53. [Google Scholar] [CrossRef]
- Xiao, X. Quantitative Investment Decision Model Based on PPO Algorithm. Highlights Sci. Eng. Technol. 2023, 34, 16–24. [Google Scholar] [CrossRef]
- Si, W.; Li, J.; Ding, P.; Rao, R. A multi-objective deep reinforcement learning approach for stock index future’s intraday trading. In Proceedings of the 2017 10th International Symposium on Computational Intelligence and Design (ISCID), Hangzhou, China, 9–10 December 2017; Volume 2, pp. 431–436. [Google Scholar]
- Huang, C.Y. Financial trading as a game: A deep reinforcement learning approach. arXiv 2018, arXiv:1807.02787. [Google Scholar]
- Chen, L.; Gao, Q. Application of Deep Reinforcement Learning on Automated Stock Trading. In Proceedings of the 2019 IEEE 10th International Conference on Software Engineering and Service Science (ICSESS), Beijing, China, 18–20 October 2019; pp. 29–33. [Google Scholar]
- Chakraborty, S. Capturing financial markets to apply deep reinforcement learning. arXiv 2019, arXiv:1907.04373. [Google Scholar]
- Corazza, M.; Fasano, G.; Gusso, R.; Pesenti, R. A Comparison among Reinforcement Learning Algorithms in Financial Trading Systems; Research Paper Series No. 33; University Ca’Foscari of Venice, Department of Economics: Venice, Italy, 2019. [Google Scholar]
- Li, Y.; Ni, P.; Chang, V. Application of deep reinforcement learning in stock trading strategies and stock forecasting. Computing 2020, 102, 1305–1322. [Google Scholar] [CrossRef]
- Wu, X.; Chen, H.; Wang, J.; Troiano, L.; Fujita, H. Adaptive Stock Trading Strategies with Deep Reinforcement Learning Methods. Inf. Sci. 2020, 538, 142–158. [Google Scholar] [CrossRef]
- Shi, Y.; Li, W.; Zhu, L.; Guo, K.; Cambria, E. Stock trading rule discovery with double deep Q-network. Appl. Soft Comput. 2021, 107, 107320. [Google Scholar] [CrossRef]
- Cheng, L.C.; Huang, Y.H.; Hsieh, M.H.; Wu, M.E. A novel trading strategy framework based on reinforcement deep learning for financial market predictions. Mathematics 2021, 9, 3094. [Google Scholar] [CrossRef]
- Taghian, M.; Asadi, A.; Safabakhsh, R. Learning financial asset-specific trading rules via deep reinforcement learning. Expert Syst. Appl. 2022, 195, 116523. [Google Scholar] [CrossRef]
- Zhang, Z.; Zohren, S.; Roberts, S. Deep reinforcement learning for trading. J. Financ. Data Sci. 2020, 2, 25–40. [Google Scholar] [CrossRef]
- Jiang, C.; Wang, J. A Portfolio Model with Risk Control Policy Based on Deep Reinforcement Learning. Mathematics 2022, 11, 19. [Google Scholar] [CrossRef]
- Li, Y.; Liu, P.; Wang, Z. Stock Trading Strategies Based on Deep Reinforcement Learning. Sci. Program. 2022, 2022, 4698656. [Google Scholar] [CrossRef]
- Wang, J.; Jing, F.; He, M. Stock Trading Strategy of Reinforcement Learning Driven by Turning Point Classification. Neural Process. Lett. 2022, 1–20. [Google Scholar] [CrossRef]
- Carta, S. A multi-layer and multi-ensemble stock trader using deep learning and deep reinforcement learning. Appl. Intell. Int. J. Artif. Intell. Neural Netw. Complex Probl. Solving Technol. 2021, 51, 889–905. [Google Scholar] [CrossRef]
- Shavandi, A.; Khedmati, M. A multi-agent deep reinforcement learning framework for algorithmic trading in financial markets. Expert Syst. Appl. 2022, 208, 118124. [Google Scholar] [CrossRef]
- Wang, Y.; Wun Cheung, S.; Chung, E.T.; Efendiev, Y.; Wang, M. Deep Multiscale Model Learning. J. Comput. Phys. 2018, 406, 109071. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the Annual Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–8 December 2012. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.B.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Proceedings of the Annual Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; Volume 28. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Redmon, J.; Divvala, S.K.; Girshick, R.B.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, S.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Redmon, S.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.; Liao, H.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Kirisci, M.; Yolcu, O.C. A New CNN-Based Model for Financial Time Series: TAIEX and FTSE Stocks Forecasting. Neural Process. Lett. 2022, 54, 3357–3374. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; pp. 4278–4284. [Google Scholar]
- Yang, Y.; Xu, C.; Dong, F.; Wang, X. A New Multi-Scale Convolutional Model Based on Multiple Attention for Image Classification. Appl. Sci. 2020, 10, 101. [Google Scholar] [CrossRef]
- Dacorogna, M.M.; Gauvreau, C.L.; Müller, U.A.; Olsen, R.B.; Pictet, O.V. Changing time scale for short-term forecasting in financial markets. J. Forecast. 1996, 15, 203–227. [Google Scholar] [CrossRef]
- Geva, A.B. ScaleNet-multiscale neural-network architecture for time series prediction. IEEE Trans. Neural Netw. 1998, 9, 1471–1482. [Google Scholar] [CrossRef]
- Cui, Z.; Chen, W.; Chen, Y. Multi-Scale Convolutional Neural Networks for Time Series Classification. arXiv 2016, arXiv:1603.06995. [Google Scholar]
- Liu, G.; Mao, Y.; Sun, Q.; Huang, H.; Gao, W.; Li, X.; Shen, J.; Li, R.; Wang, X. Multi-scale Two-way Deep Neural Network for Stock Trend Prediction. In Proceedings of the International Joint Conference on Artificial Intelligence, Yokohama, Japan, 7–15 January 2021; pp. 4555–4561. [Google Scholar]
- Teng, X.; Zhang, X.; Luo, Z. Multi-scale local cues and hierarchical attention-based LSTM for stock price trend prediction. Neurocomputing 2022, 505, 92–100. [Google Scholar] [CrossRef]
- Taghian, M.; Asadi, A.; Safabakhsh, R. A Reinforcement Learning Based Encoder-Decoder Framework for Learning Stock Trading Rules. arXiv 2021, arXiv:2101.03867. [Google Scholar]
- Sharpe, W.F. The Sharpe Ratio. J. Portf. Manag. 1994, 21, 49–58. [Google Scholar] [CrossRef]
- Sutton, R.; Barto, A. Reinforcement Learning:An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Indicators | Buy and Hold | Sell and Hold | DQN-Pattern | DQN-Vanilla | SARSA |
|---|---|---|---|---|---|---|
| DJIA | Profit | 53,608 | −53,608 | 59,233 | 83,737 | 299,740 |
| SR | 0.304 | −0.079 | 0.325 | 0.414 | 0.996 | |
| AR | 11.34 | −2.88 | 12.16 | 13.97 | 32.66 | |
| NASDAQ | Profit | 239,668 | −239,668 | 234,454 | 283,431 | 394,018 |
| SR | 0.803 | −0.744 | 0.787 | 1.000 | 1.245 | |
| AR | 28.92 | −39.82 | 28.49 | 31.03 | 38.60 | |
| AAPL | Profit | 679,847 | −679,847 | 640,594 | 766,268 | 1,341,994 |
| SR | 1.271 | −0.234 | 1.230 | 1.563 | 2.061 | |
| AR | 57.80 | −100.00 | 55.95 | 59.22 | 78.41 | |
| GE | Profit | −273,017 | 273,017 | 31,425 | 794,302 | 950,557 |
| SR | −0.425 | 0.918 | 0.673 | 1.831 | 1.301 | |
| AR | −35.55 | 30.71 | 4.09 | 58.84 | 72.26 |
| Dataset | Indicators | Single-Scaling | Multi-Scaling |
|---|---|---|---|
| DJIA | Profit | 140,750 | 299,740 |
| SR | 0.570 | 0.996 | |
| AR | 20.22 | 32.66 | |
| NASDAQ | Profit | 337,034 | 394,018 |
| SR | 1.073 | 1.245 | |
| AR | 35.3 | 38.60 | |
| AAPL | Profit | 763,222 | 1,341,994 |
| SR | 1.439 | 2.061 | |
| AR | 60.3 | 78.41 | |
| GE | Profit | 518,108 | 950,557 |
| SR | 0.931 | 1.301 | |
| AR | 54.85 | 72.26 |
| Dataset | Indicators | Tanh | ELU | ReLU | SiLU |
|---|---|---|---|---|---|
| DJIA | Profit | 299,740 | 82,890 | 293,075 | 124,262 |
| SR | 0.996 | 0.395 | 0.996 | 0.533 | |
| AR | 32.66 | 14.33 | 31.82 | 17.96 | |
| NASDAQ | Profit | 394,018 | 371,022 | 330,909 | 952,494 |
| SR | 1.245 | 1.121 | 1.075 | 2.246 | |
| AR | 38.60 | 37.68 | 34.75 | 64.12 | |
| AAPL | Profit | 1,341,994 | 1,356,284 | 999,571 | 1,239,528 |
| SR | 2.061 | 2.064 | 1.699 | 1.893 | |
| AR | 78.41 | 78.83 | 68.74 | 76.17 | |
| GE | Profit | 950,557 | 240,908 | 156,689 | 15,065 |
| SR | 1.301 | 0.626 | 0.498 | 0.262 | |
| AR | 72.26 | 36.41 | 33.63 | 16.93 | |
| Mean | Profit | 746,577.25 | 512,776.00 | 445,061.00 | 582,837.25 |
| SR | 1.401 | 1.052 | 1.067 | 1.234 | |
| AR | 55.48 | 41.81 | 42.24 | 43.08 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, Y.; Cui, K.; Song, Y.; Chen, Z. A Multi-Scaling Reinforcement Learning Trading System Based on Multi-Scaling Convolutional Neural Networks. Mathematics 2023, 11, 2467. https://doi.org/10.3390/math11112467
Huang Y, Cui K, Song Y, Chen Z. A Multi-Scaling Reinforcement Learning Trading System Based on Multi-Scaling Convolutional Neural Networks. Mathematics. 2023; 11(11):2467. https://doi.org/10.3390/math11112467
Chicago/Turabian StyleHuang, Yuling, Kai Cui, Yunlin Song, and Zongren Chen. 2023. "A Multi-Scaling Reinforcement Learning Trading System Based on Multi-Scaling Convolutional Neural Networks" Mathematics 11, no. 11: 2467. https://doi.org/10.3390/math11112467
APA StyleHuang, Y., Cui, K., Song, Y., & Chen, Z. (2023). A Multi-Scaling Reinforcement Learning Trading System Based on Multi-Scaling Convolutional Neural Networks. Mathematics, 11(11), 2467. https://doi.org/10.3390/math11112467