
Hybrid Character Generation via Shape Control Using Explicit Facial Features
Abstract
:1. Introduction
- We define a set of explicit facial features that effectively represents facial characteristics. This feature has the advantage of being measured regardless of the pose and size of facial images. The explicit facial features can be utilized not only in our research but also in various anthropometry fields, such as facial aesthetics, forensic science, facial recognition, and facial measurement.
- We propose a novel method to generate the shape of a character’s face by appropriately controlling the shapes of input and styled faces using explicit facial features. This method is designed based on an energy minimization technique that utilizes the input and styled faces to generate a smooth version of the character’s face. This method produces the shape of the face, which can serve as an effective guideline for various generative models, including warping-field-based models and diffusion models.
- We propose a deep-learning-based method that effectively applies texture-based style to a character’s face by employing the shape of the face as a guideline. This method is applied step by step to the components of the face, providing the advantage of effective style transfer with artifact control.
2. Related Work
2.1. General Schemes for Face Style Transfer
2.2. Face Style Transfer Using Feature Map Modulation
2.3. Face Style Transfer Using Spatial Interpolation
2.3.1. Warping-Field-Based Schemes
2.3.2. Control-Point-Based Schemes
2.3.3. Landmark-Based Schemes
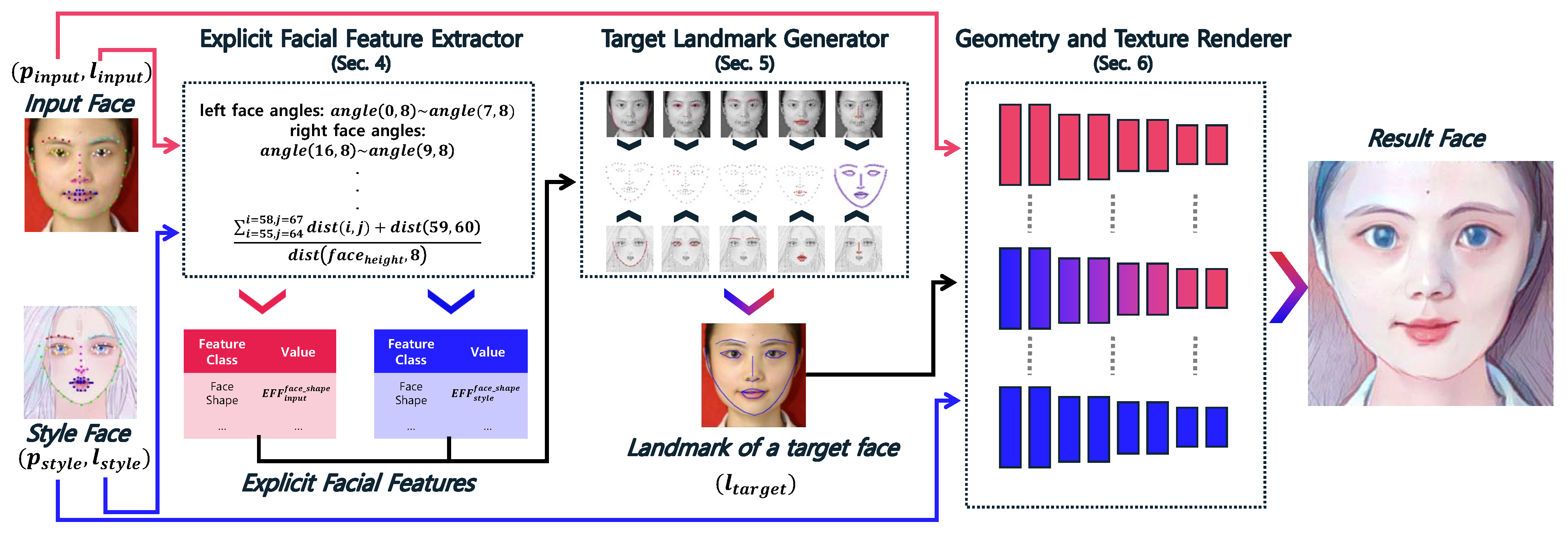
3. Overview
4. Explicit Facial Feature Extractor
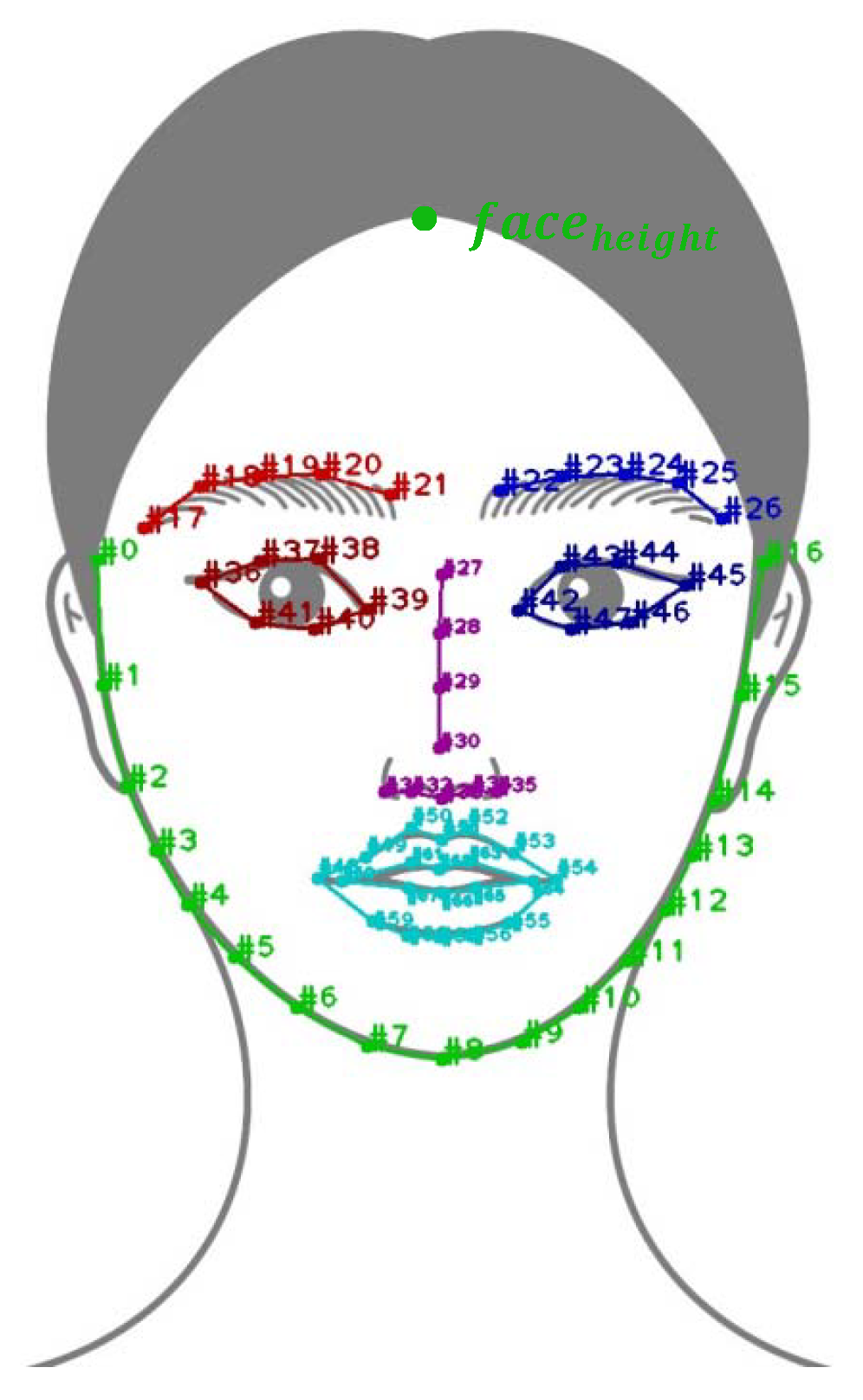
4.1. Anthropometry-Based Explicit Facial Features
4.2. Defining Explicit Facial Features
4.2.1. Preparation
4.2.2. Definition of Face Shape Features
4.2.3. Definition of Eyebrow Features
4.2.4. Definition of Eye Features
4.2.5. Definition of Nose Features
4.2.6. Definition of Lip Features
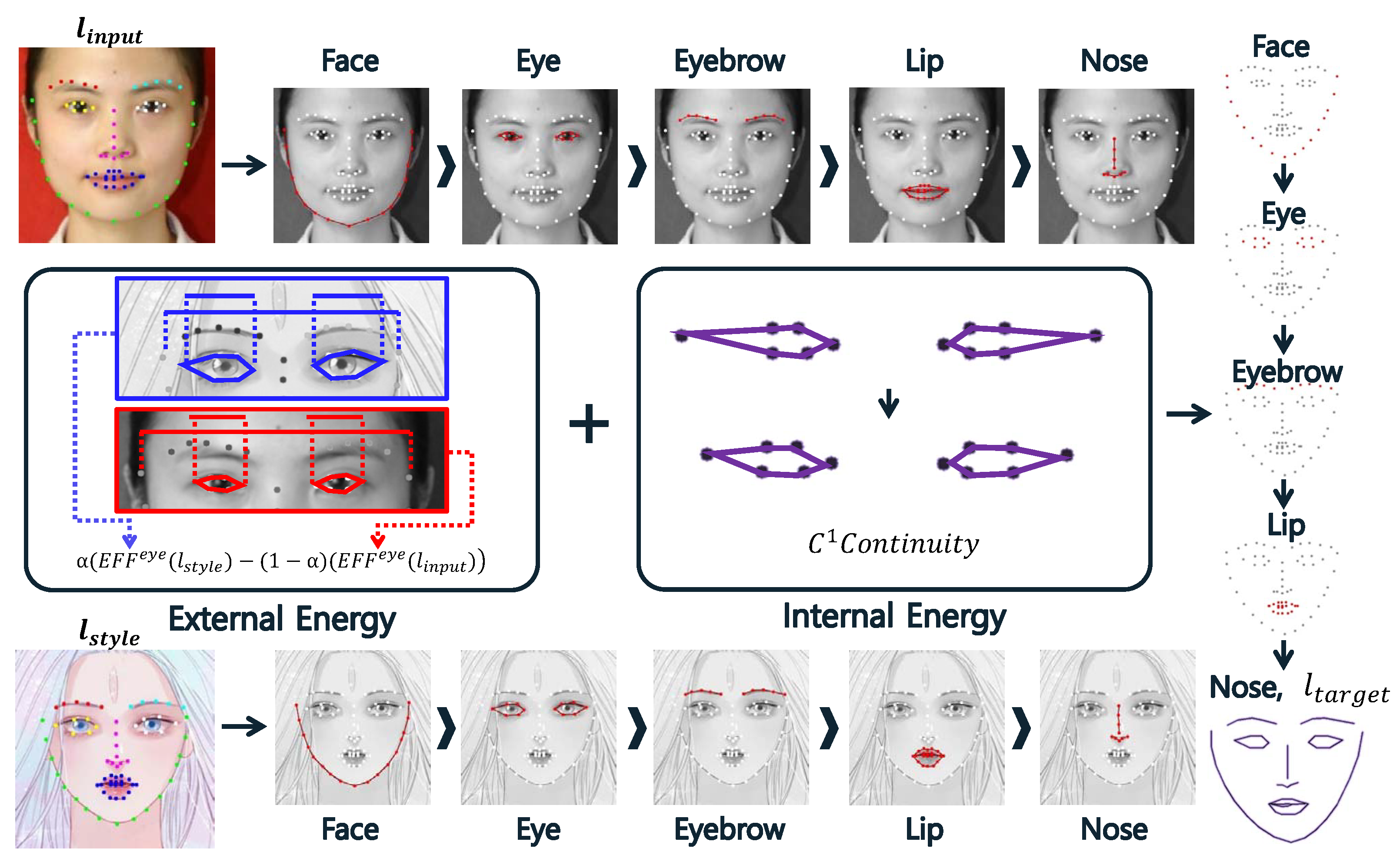
5. Target Landmark Generator
6. Stylizer with Landmarks
7. Implementation and Results
7.1. Implementation Environment
7.2. Training Data
7.3. Results
8. Comparison and Analysis
8.1. Evaluation
8.1.1. Evaluation Using FID
8.1.2. Evaluation Using KID
8.1.3. Discussion
8.2. User Study
- Q1. Please select the image that reflects the shape of both the input and styled faces.
- Q2. Please select the image that is most similar to the styled face in terms of textural aspects.
- Q3. Please select the image that reflects both the shape of the input and styled faces and is most similar to the styled face in terms of textural aspects.
8.3. Ablation Study
8.4. Applications
8.5. Limitations
9. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Gatys, L.A.; Ecker, A.S.; Bethge, M. Image style transfer using convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2414–2423. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Kim, J.; Kim, M.; Kang, H.; Lee, K. U-gat-it: Unsupervised generative attentional networks with adaptive layer-instance normalization for image-to-image translation. In Proceedings of the 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, 26–30 April 2020; pp. 26–30. [Google Scholar]
- Karras, T.; Laine, S.; Aila, T. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–17 June 2019; pp. 4401–4410. [Google Scholar]
- Pinkney, J.N.; Adler, D. Resolution dependent GAN interpolation for controllable image synthesis between domains. arXiv 2020, arXiv:2010.05334. [Google Scholar]
- Song, G.; Luo, L.; Liu, J.; Ma, W.C.; Lai, C.; Zheng, C.; Cham, T.J. AgileGAN: Stylizing portraits by inversion-consistent transfer learning. ACM Trans. Graph. 2021, 40, 117. [Google Scholar] [CrossRef]
- Liu, M.; Li, Q.; Qin, Z.; Zhang, G.; Wan, P.; Zheng, W. BlendGAN: Implicitly GAN blending for arbitrary stylized face generation. In Proceedings of the NeurIPS 2021, on-line conference, 6–14 December 2021; pp. 29710–29722. [Google Scholar]
- Yang, S.; Jiang, L.; Liu, Z.; Loy, C.C. Pastiche Master: Exemplar-based high-resolution portrait style transfer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 7693–7702. [Google Scholar]
- Zhu, P.; Abdal, R.; Femiani, J.; Wonka, P. Mind the gap: Domain gap control for single shot domain adaptation for generative adversarial networks. arXiv 2021, arXiv:2110.08398. [Google Scholar]
- Gong, J.; Hold-Geoffroy, Y.; Lu, J. Autotoon: Automatic geometric warping for face cartoon generation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Snowmass Village, CO, USA, 1–5 March 2020; pp. 360–369. [Google Scholar]
- Gu, Z.; Dong, C.; Huo, J.; Li, W.; Gao, Y. CariMe: Unpaired caricature generation with multiple exaggerations. IEEE Trans. Multimed. 2021, 24, 2673–2686. [Google Scholar] [CrossRef]
- Shi, Y.; Deb, D.; Jain, A.K. WarpGAN: Automatic caricature generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 10762–10771. [Google Scholar]
- Liu, X.C.; Yang, Y.L.; Hall, P. Learning to warp for style transfer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 3702–3711. [Google Scholar]
- Kim, S.S.; Kolkin, N.; Salavon, J.; Shakhnarovich, G. Deformable style transfer. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 246–261. [Google Scholar]
- Cao, K.; Liao, J.; Yuan, L. CariGANs: Unpaired photo-to-caricature translation. ACM Trans. Graph. 2018, 37, 244. [Google Scholar] [CrossRef]
- Yaniv, J.; Newman, Y.; Shamir, A. The face of art: Landmark detection and geometric style in portraits. ACM Trans. Graph. 2019, 38, 60. [Google Scholar] [CrossRef]
- Huang, X.; Belongie, S. Arbitrary style transfer in real-time with adaptive instance normalization. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 1501–1510. [Google Scholar]
- Jang, W.; Ju, G.; Jung, Y.; Yang, J.; Tong, X.; Lee, S. StyleCariGAN: Caricature generation via StyleGAN feature map modulation. ACM Trans. Graph 2021, 40, 116. [Google Scholar] [CrossRef]
- Zhu, J.; Shen, Y.; Zhao, D.; Zhou, B. In-domain GAN inversion for real image editing. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 592–608. [Google Scholar]
- Rungruanganukul, M.; Siriborvornratanakul, T. Deep learning based gesture classification for hand physical therapy interactive program. In Proceedings of the International Conference on Human-Computer Interaction, Copenhagen, Denmark, 19–24 July 2020; pp. 349–358. [Google Scholar]
- Miah, A.S.M.; Hasan, M.A.M.; Shin, J. Dynamic Hand Gesture Recognition using Multi-Branch Attention Based Graph and General Deep Learning Model. IEEE Access 2013, 11, 4703–4716. [Google Scholar] [CrossRef]
- Xie, D.; Liang, L.; Jin, L.; Xu, J.; Li, M. Scut-fbp: A benchmark dataset for facial beauty perception. In Proceedings of the IEEE International Conference on Systems, Man, and Cybernetics, Hong Kong, China, 9–12 October 2015; pp. 1821–1826. [Google Scholar]
- Wei, W.; Ho, E.S.L.; McCay, K.D.; Damaševičius, R.; Maskeliūnas, R.; Esposito, A. Assessing facial symmetry and attractiveness using augmented reality. Pattern Anal. Appl. 2022, 25, 635–651. [Google Scholar] [CrossRef]
- Moreton, R. Forensic Face Matching. In Forensic Face Matching: Research and Practice; Oxford Academic: Oxford, UK, 2021; p. 144. [Google Scholar]
- Sezgin, N.; Karadayi, B. Sex estimation from biometric face photos for forensic purposes. Med. Sci. Law 2022, 63, 105–113. [Google Scholar] [CrossRef] [PubMed]
- Porter, J.P.; Olson, K.L. Anthropometric facial analysis of the African American woman. Arch. Facial Plast. Surg. 2001, 3, 191–197. [Google Scholar] [CrossRef] [PubMed]
- Maalman, R.S.-E.; Abaidoo, C.S.; Tetteh, J.; Darko, N.D.; Atuahene, O.O.-D.; Appiah, A.K.; Diby, T. Anthropometric study of facial morphology in two tribes of the upper west region of Ghana. Int. J. Anat. Res. 2017, 5, 4129–4135. [Google Scholar] [CrossRef]
- Farkas, L. Anthropometry of the Head and Face; Raven Press: New York, NY, USA, 1994. [Google Scholar]
- Merler, M.; Ratha, N.; Feris, R.S.; Smith, J.R. Diversity in faces. arXiv 2019, arXiv:1901.10436. [Google Scholar]
- Zhou, H.; Liu, J.; Liu, Z.; Liu, Y.; Wang, X. Rotate-and-render: Unsupervised photorealistic face rotation from single-view images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 5911–5920. [Google Scholar]
- King, D.E. Dlib-ml: A machine learning toolkit. J. Mach. Learn. Res. 2009, 10, 1755–1758. [Google Scholar]
- Kass, M.; Witkin, A.; Terzopoulos, D. Snakes: Active contour models. Int. J. Comput. Vis. 1988, 1, 321–331. [Google Scholar] [CrossRef]
- Kolkin, N.; Salavon, J.; Shakhnarovich, G. Style transfer by relaxed optimal transport and self-similarity. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 10051–10060. [Google Scholar]
- Liang, L.; Lin, L.; Jin, L.; Xie, D.; Li, M. SCUT-FBP5500: A diverse benchmark dataset for multi-paradigm facial beauty prediction. In Proceedings of the IEEE 24th International conference on pattern recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 1598–1603. [Google Scholar]
- Niu, Z.; Zhou, M.; Wang, L.; Gao, X.; Hua, G. Ordinal regression with multiple output cnn for age estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 4920–4928. [Google Scholar]
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 10684–10695. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | InputFID | StyleFID | MeanFID |
|---|---|---|---|
| ours | 176.41 | 221.94 | 194.79 |
| Kim et al.’s [14] | 184.2 | 223.84 | 198.93 |
| Yaniv et al.’s [16] | 234.71 | 189.50 | 212.11 |
| Kolkin et al.’s [33] | 83.96 | 261.27 | 172.61 |
| Gatys et al.’s [1] | 249.36 | 250.63 | 249.99 |
| Method | InputKID | StyleKID | MeanKID |
|---|---|---|---|
| Ours | 0.42 | 0.44 | 0.43 |
| Kim et al.’s [14] | 0.43 | 0.45 | 0.44 |
| Yaniv et al.’s [16] | 0.52 | 0.41 | 0.46 |
| Kolkin et al.’s [33] | 0.25 | 0.59 | 0.42 |
| Gatys et al.’s [1] | 0.55 | 0.46 | 0.50 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, J.; Yeom, J.; Yang, H.; Min, K. Hybrid Character Generation via Shape Control Using Explicit Facial Features. Mathematics 2023, 11, 2463. https://doi.org/10.3390/math11112463
Lee J, Yeom J, Yang H, Min K. Hybrid Character Generation via Shape Control Using Explicit Facial Features. Mathematics. 2023; 11(11):2463. https://doi.org/10.3390/math11112463
Chicago/Turabian StyleLee, Jeongin, Jihyeon Yeom, Heekyung Yang, and Kyungha Min. 2023. "Hybrid Character Generation via Shape Control Using Explicit Facial Features" Mathematics 11, no. 11: 2463. https://doi.org/10.3390/math11112463
APA StyleLee, J., Yeom, J., Yang, H., & Min, K. (2023). Hybrid Character Generation via Shape Control Using Explicit Facial Features. Mathematics, 11(11), 2463. https://doi.org/10.3390/math11112463