

Multi-Source Data Repairing: A Comprehensive Survey

 ,
,  and
and
Abstract
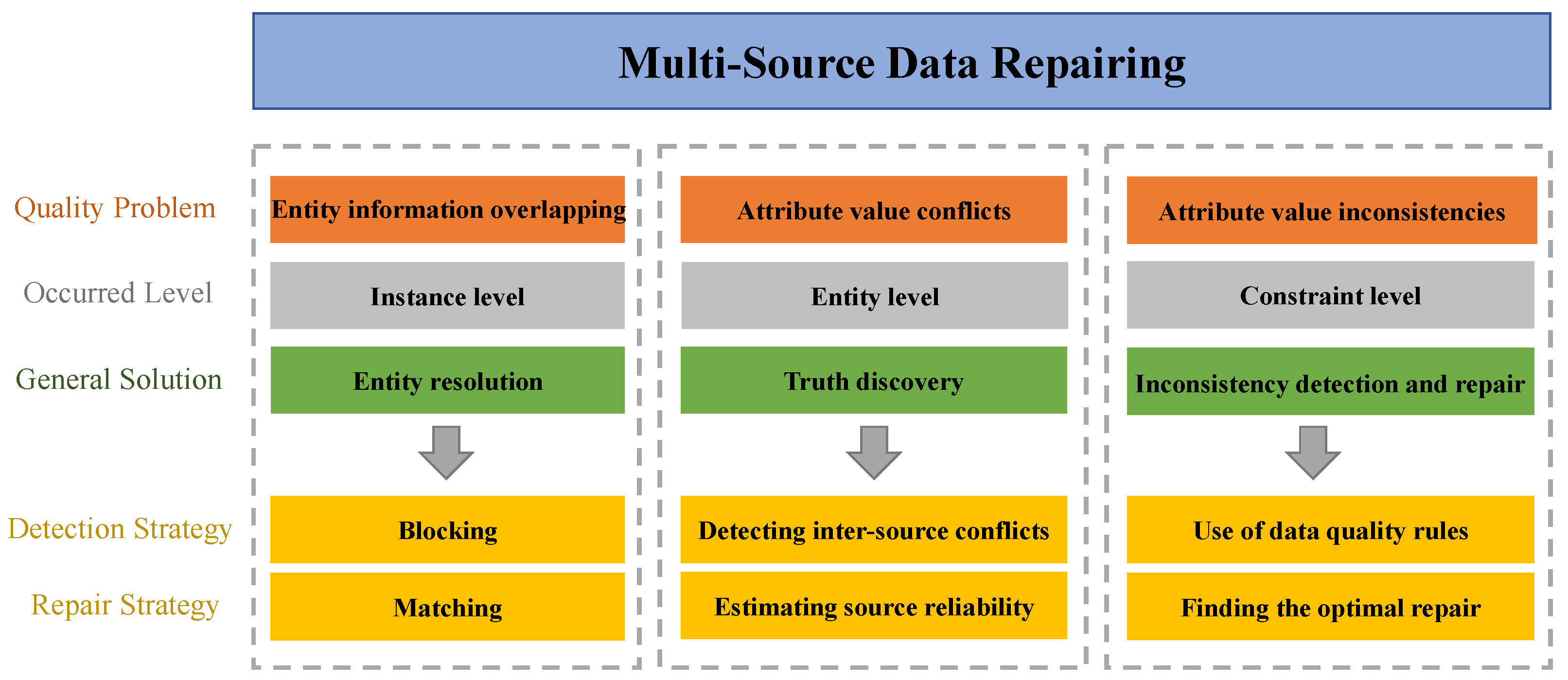
1. Introduction
2. Entity Resolution
2.1. Non-Learning-Based Methods
- Schema-type: distinguishes between schema-aware or schema-agnostic methods. The former indicates that the method selects some specific attribute values for blocking and matching, and these selected attributes are discriminative or contain less noisy data. The latter does not consider pattern information and extracts information from all attribute values.
- Step: divides the methods into three categories based on the steps included. Blocking means that the method contains only blocking steps, matching means that the process consists of only matching, blocking–matching implies that the method proposes a complete framework for ER, including both blocking and matching.
- Knowledge-based: classifies the methods into yes, which means that external knowledge, such as knowledge bases, rules, constraints, etc., are introduced into the techniques, and no, which means that they are not.
2.2. Learning-Based Methods
- Learning type: distinguishes these methods into supervised, unsupervised, semi-supervised, and deep learning, where we uniform all the learning-based methods belonging to the field of deep learning (DL) to deep learning.
- Pre-trained LM: Identifying and distinguishing entities requires capturing their semantic similarities, which requires significant language understanding and domain knowledge. Pre-trained transformer-based language models (LMs) perform well on the ER task due to their ability to understand language and their ability to learn where to pay attention. This dimension divides methods into yes and no. The former indicates introducing a pre-trained LM, while the latter does not.
3. Truth Discovery
3.1. Labeled Truths
3.2. Entity Dependency
3.3. Source Dependency
3.4. Non-Single Truth
3.5. Truth Discovery in Crowdsourcing
4. Inconsistency Detection and Repair
4.1. Table Data
4.2. Graph Data
5. Detection and Repair of Compound-Type Errors
6. Future Research Directions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Fan, W. Data Quality: From Theory to Practice. SIGMOD Rec. 2015, 44, 7–18. [Google Scholar] [CrossRef]
- Arenas, M.; Bertossi, L.E.; Chomicki, J. Consistent Query Answers in Inconsistent Databases. In Proceedings of the Eighteenth ACM SIGACT-SIGMOD-SIGART Symposium on Principles of Database Systems, Philadelphia, PA, USA, 31 May–2 June 1999; pp. 68–79. [Google Scholar]
- Cao, Y.; Deng, T.; Fan, W.; Geerts, F. On the data complexity of relative information completeness. Inf. Syst. 2014, 45, 18–34. [Google Scholar] [CrossRef]
- Fan, W.; Geerts, F. Relative Information Completeness. ACM Trans. Database Syst. 2010, 35, 97–106. [Google Scholar] [CrossRef]
- Fellegi, I.P.; Sunter, A.B. A theory for record linkage. J. Am. Stat. Assoc. 1969, 64, 1183–1210. [Google Scholar] [CrossRef]
- Elmagarmid, A.K.; Ipeirotis, P.G.; Verykios, V.S. Duplicate Record Detection: A Survey. IEEE Trans. Knowl. Data Eng. 2007, 19, 1–16. [Google Scholar] [CrossRef]
- Zhang, H.; Diao, Y.; Immerman, N. Recognizing Patterns in Streams with Imprecise Timestamps. Inf. Syst. 2013, 38, 1187–1211. [Google Scholar] [CrossRef]
- Clifford, J.; Dyreson, C.; Isakowitz, T.; Jensen, C.S.; Snodgrass, R.T. On the Semantics of “Now” in Databases. ACM Trans. Database Syst. 1997, 22, 171–214. [Google Scholar] [CrossRef]
- Widom, J. Trio: A System for Integrated Management of Data, Accuracy, and Lineage. In Proceedings of the Second Biennial Conference on Innovative Data Systems Research, Asilomar, CA, USA, 4–7 January 2005; Volume 5, pp. 262–276. [Google Scholar]
- Rahm, E.; Do, H.H. Data Cleaning: Problems and Current Approaches. IEEE Data Eng. Bull. 2000, 23, 3–13. [Google Scholar]
- Papadakis, G.; Ioannou, E.; Palpanas, T. Entity Resolution: Past, Present and Yet-to-Come. In Proceedings of the 23rd International Conference on Extending Database Technology, Copenhagen, Denmark, 30 March–2 April 2020; pp. 647–650. [Google Scholar]
- Konda, P.; Das, S.; Doan, A.; Ardalan, A.; Ballard, J.R.; Li, H.; Panahi, F.; Zhang, H.; Naughton, J.; Prasad, S.; et al. Magellan: Toward Building Entity Matching Management Systems. Proc. VLDB Endow. 2016, 9, 1197–1208. [Google Scholar] [CrossRef]
- Draisbach, U.; Naumann, F. A generalization of blocking and windowing algorithms for duplicate detection. In Proceedings of the 2011 International Conference on Data and Knowledge Engineering, Milano, Italy, 6 September 2011; pp. 18–24. [Google Scholar]
- Wang, J.; Kraska, T.; Franklin, M.J.; Feng, J. CrowdER: Crowdsourcing Entity Resolution. Proc. VLDB Endow. 2012, 5, 1483–1494. [Google Scholar] [CrossRef]
- Benjelloun, O.; Garcia-Molina, H.; Menestrina, D.; Su, Q.; Whang, S.E.; Widom, J. Swoosh: A generic approach to entity resolution. VLDB J. 2009, 18, 255–276. [Google Scholar] [CrossRef]
- Singh, R.; Meduri, V.V.; Elmagarmid, A.; Madden, S.; Papotti, P.; Quiané-Ruiz, J.A.; Solar-Lezama, A.; Tang, N. Synthesizing Entity Matching Rules by Examples. Proc. VLDB Endow. 2017, 11, 189–202. [Google Scholar] [CrossRef]
- Wang, H.; Ding, X.; Li, J.; Gao, H. Rule-Based Entity Resolution on Database with Hidden Temporal Information. IEEE Trans. Knowl. Data Eng. 2018, 30, 2199–2212. [Google Scholar] [CrossRef]
- Hao, S.; Tang, N.; Li, G.; Feng, J. Discovering Mis-Categorized Entities. In Proceedings of the 34th IEEE International Conference on Data Engineering, Paris, France, 16–19 April 2018; pp. 413–424. [Google Scholar]
- Papadakis, G.; Ioannou, E.; Niederée, C.; Fankhauser, P. Efficient entity resolution for large heterogeneous information spaces. In Proceedings of the Forth International Conference on Web Search and Web Data Mining, Hong Kong, China, 9–12 February 2011; pp. 535–544. [Google Scholar]
- Papadakis, G.; Ioannou, E.; Palpanas, T.; Niederée, C.; Nejdl, W. A blocking framework for entity resolution in highly heterogeneous information spaces. IEEE Trans. Knowl. Data Eng. 2012, 25, 2665–2682. [Google Scholar] [CrossRef]
- Lacoste-Julien, S.; Palla, K.; Davies, A.; Kasneci, G.; Graepel, T.; Ghahramani, Z. Sigma: Simple greedy matching for aligning large knowledge bases. In Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Chicago, IL, USA, 11–14 August 2013; pp. 572–580. [Google Scholar]
- Efthymiou, V.; Papadakis, G.; Stefanidis, K.; Christophides, V. MinoanER: Schema-Agnostic, Non-Iterative, Massively Parallel Resolution of Web Entities. In Proceedings of the Advances in Database Technology—22nd International Conference on Extending Database Technology, Lisbon, Portugal, 26–29 March 2019; pp. 373–384. [Google Scholar]
- Bilenko, M.; Kamath, B.; Mooney, R.J. Adaptive Blocking: Learning to Scale Up Record Linkage. In Proceedings of the 6th IEEE International Conference on Data Mining, Hong Kong, China, 18–22 December 2006; pp. 87–96. [Google Scholar]
- Michelson, M.; Knoblock, C.A. Learning Blocking Schemes for Record Linkage. In Proceedings of the AAAI’06: Proceedings of the 21st National Conference on Artificial Intelligence, Boston, MA, USA, 16–20 July 2006; pp. 440–445. [Google Scholar]
- Evangelista, L.O.; Cortez, E.; da Silva, A.S.; Meira, W., Jr. Adaptive and Flexible Blocking for Record Linkage Tasks. J. Inf. Data Manag. 2010, 1, 167. [Google Scholar]
- Das Sarma, A.; Jain, A.; Machanavajjhala, A.; Bohannon, P. An Automatic Blocking Mechanism for Large-Scale de-Duplication Tasks. In Proceedings of the 21st ACM International Conference on Information and Knowledge Management, Maui, HI, USA, 29 October–2 November 2012; pp. 1055–1064. [Google Scholar]
- Lin, X.; Li, H.; Xin, H.; Li, Z.; Chen, L. KBPearl: A Knowledge Base Population System Supported by Joint Entity and Relation Linking. Proc. VLDB Endow. 2020, 13, 1035–1049. [Google Scholar] [CrossRef]
- Zeng, W.; Zhao, X.; Tang, J.; Lin, X. Collective Entity Alignment via Adaptive Features. In Proceedings of the 36th IEEE International Conference on Data Engineering, Dallas, TX, USA, 20–24 April 2020; pp. 1870–1873. [Google Scholar]
- Meduri, V.V.; Popa, L.; Sen, P.; Sarwat, M. A Comprehensive Benchmark Framework for Active Learning Methods in Entity Matching. In Proceedings of the 2020 International Conference on Management of Data, Portland, OR, USA, 14–19 June 2020; pp. 1133–1147. [Google Scholar]
- Kushagra, S.; Saxena, H.; Ilyas, I.F.; Ben-David, S. A Semi-Supervised Framework of Clustering Selection for De-Duplication. In Proceedings of the 35th IEEE International Conference on Data Engineering, Macao, China, 8–11 April 2019; pp. 208–219. [Google Scholar]
- Ran, H.; Wang, H.; Rong, Z.; Li, J.; Hong, G. Map-Reduce Based Entity Identification in Big Data. J. Comput. Res. Dev. 2013, 50, 170–179. [Google Scholar]
- Deng, D.; Tao, W.; Abedjan, Z.; Elmagarmid, A.K.; Ilyas, I.F.; Li, G.; Madden, S.; Ouzzani, M.; Stonebraker, M.; Tang, N. Unsupervised String Transformation Learning for Entity Consolidation. In Proceedings of the 35th IEEE International Conference on Data Engineering, Macao, China, 8–11 April 2019; pp. 196–207. [Google Scholar]
- Wu, R.; Chaba, S.; Sawlani, S.; Chu, X.; Thirumuruganathan, S. ZeroER: Entity Resolution using Zero Labeled Examples. In Proceedings of the 2020 International Conference on Management of Data, Portland, OR, USA, 14–19 June 2020; pp. 1149–1164. [Google Scholar]
- Galhotra, S.; Firmani, D.; Saha, B.; Srivastava, D. Robust entity resolution using random graphs. In Proceedings of the 2018 International Conference on Management of Data, Houston, TX, USA, 10–15 June 2018; pp. 3–18. [Google Scholar]
- Ke, X.; Teo, M.; Khan, A.; Yalavarthi, V.K. A Demonstration of PERC: Probabilistic Entity Resolution with Crowd Errors. Proc. VLDB Endow. 2018, 11, 1922–1925. [Google Scholar] [CrossRef]
- Ebraheem, M.; Thirumuruganathan, S.; Joty, S.R.; Ouzzani, M.; Tang, N. Distributed Representations of Tuples for Entity Resolution. Proc. VLDB Endow. 2018, 11, 1454–1467. [Google Scholar] [CrossRef]
- Mudgal, S.; Li, H.; Rekatsinas, T.; Doan, A.; Park, Y.; Krishnan, G.; Deep, R.; Arcaute, E.; Raghavendra, V. Deep learning for entity matching: A design space exploration. In Proceedings of the 2018 International Conference on Management of Data, Houston, TX, USA, 10–15 June 2018; pp. 19–34. [Google Scholar]
- Thirumuruganathan, S.; Li, H.; Tang, N.; Ouzzani, M.; Govind, Y.; Paulsen, D.; Fung, G.; Doan, A. Deep Learning for Blocking in Entity Matching: A Design Space Exploration. Proc. VLDB Endow. 2021, 14, 2459–2472. [Google Scholar] [CrossRef]
- Li, Y.; Li, J.; Suhara, Y.; Doan, A.; Tan, W.C. Deep Entity Matching with Pre-Trained Language Models. Proc. VLDB Endow. 2020, 14, 50–60. [Google Scholar] [CrossRef]
- Wang, J.; Li, Y.; Hirota, W.; Kandogan, E. Machop: An end-to-end generalized entity matching framework. In Proceedings of the Fifth International Workshop on Exploiting Artificial Intelligence Techniques for Data Management, Philadelphia, PA, USA, 17 June 2022; pp. 2:1–2:10. [Google Scholar]
- Ye, C.; Jiang, S.; Zhang, H.; Wu, Y.; Shi, J.; Wang, H.; Dai, G. JointMatcher: Numerically-aware entity matching using pre-trained language models with attention concentration. Knowl. Based Syst. 2022, 251, 109033. [Google Scholar] [CrossRef]
- Kushagra, S.; Ben-David, S.; Ilyas, I.F. Semi-supervised clustering for de-duplication. In Proceedings of the 22nd International Conference on Artificial Intelligence and Statistics, Naha, Japan, 16–18 April 2019; Volume 89, pp. 1659–1667. [Google Scholar]
- Mueller, J.; Thyagarajan, A. Siamese Recurrent Architectures for Learning Sentence Similarity. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; pp. 2786–2792. [Google Scholar]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Li, Y.; Gao, J.; Meng, C.; Li, Q.; Su, L.; Zhao, B.; Fan, W.; Han, J. A survey on truth discovery. SIGKDD Explor. 2016, 17, 1–16. [Google Scholar] [CrossRef]
- Yin, X.; Han, J.; Yu, P.S. Truth discovery with multiple conflicting information providers on the web. In Proceedings of the 13th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Jose, CA, USA, 12–15 August 2007; pp. 1048–1052. [Google Scholar]
- Xiao, H.; Gao, J.; Li, Q.; Ma, F.; Su, L.; Feng, Y.; Zhang, A. Towards confidence interval estimation in truth discovery. IEEE Trans. Knowl. Data Eng. 2018, 31, 575–588. [Google Scholar] [CrossRef]
- Li, Q.; Li, Y.; Gao, J.; Su, L.; Zhao, B.; Demirbas, M.; Fan, W.; Han, J. A confidence-aware approach for truth discovery on long-tail data. Proc. VLDB Endow. 2014, 8, 425–436. [Google Scholar] [CrossRef]
- Li, Q.; Li, Y.; Gao, J.; Zhao, B.; Fan, W.; Han, J. Resolving conflicts in heterogeneous data by truth discovery and source reliability estimation. In Proceedings of the International Conference on Management of Data, Snowbird, UT, USA, 22–27 June 2014; pp. 1187–1198. [Google Scholar]
- Yin, X.; Tan, W. Semi-supervised truth discovery. In Proceedings of the 20th International Conference on World Wide Web, Hyderabad, India, 28 March–1 April 2011; pp. 217–226. [Google Scholar]
- Rekatsinas, T.; Joglekar, M.; Garcia-Molina, H.; Parameswaran, A.G.; Ré, C. SLiMFast: Guaranteed Results for Data Fusion and Source Reliability. In Proceedings of the 2017 ACM International Conference on Management of Data, Chicago, IL, USA, 14–19 May 2017; pp. 1399–1414. [Google Scholar]
- Yang, Y.; Bai, Q.; Liu, Q. On the Discovery of Continuous Truth: A Semi-supervised Approach with Partial Ground Truths. In Proceedings of the Web Information Systems Engineering—WISE 2018—19th International Conference, Dubai, United Arab Emirates, 12–15 November 2018; Volume 11233, pp. 424–438. [Google Scholar]
- Pasternack, J.; Roth, D. Knowing What to Believe (when you already know something). In Proceedings of the 23rd International Conference on Computational Linguistics, Beijing, China, 23–27 August 2010; pp. 877–885. [Google Scholar]
- Pasternack, J.; Roth, D. Making Better Informed Trust Decisions with Generalized Fact-Finding. In Proceedings of the 22nd International Joint Conference on Artificial Intelligence, Barcelona, Spain, 16–22 July 2011; pp. 2324–2329. [Google Scholar]
- Yu, D.; Huang, H.; Cassidy, T.; Ji, H.; Wang, C.; Zhi, S.; Han, J.; Voss, C.R.; Magdon-Ismail, M. The Wisdom of Minority: Unsupervised Slot Filling Validation based on Multi-dimensional Truth-Finding. In Proceedings of the 25th International Conference on Computational Linguistics, Technical Papers, Dublin, Ireland, 23–29 August 2014; pp. 1567–1578. [Google Scholar]
- Li, Y.; Li, Q.; Gao, J.; Su, L.; Zhao, B.; Fan, W.; Han, J. On the Discovery of Evolving Truth. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, NSW, Australia, 10–13 August 2015; pp. 675–684. [Google Scholar]
- Meng, C.; Jiang, W.; Li, Y.; Gao, J.; Su, L.; Ding, H.; Cheng, Y. Truth Discovery on Crowd Sensing of Correlated Entities. In Proceedings of the 13th ACM Conference on Embedded Networked Sensor Systems, Seoul, Republick of Korea, 1–4 November 2015; pp. 169–182. [Google Scholar]
- Yao, L.; Su, L.; Li, Q.; Li, Y.; Ma, F.; Gao, J.; Zhang, A. Online Truth Discovery on Time Series Data. In Proceedings of the 2018 SIAM International Conference on Data Mining, San Diego Marriott Mission Valley, San Diego, CA, USA, 3–5 May 2018; pp. 162–170. [Google Scholar]
- Nakhaei, Z.; Ahmadi, A.; Sharifi, A.; Badie, K. Conflict resolution in data integration using the relationship between entities. Int. J. Inf. Commun. Technol. Res. 2019, 11, 38–49. [Google Scholar]
- Ye, C.; Wang, H.; Zheng, K.; Kong, Y.; Zhu, R.; Gao, J.; Li, J. Constrained Truth Discovery. IEEE Trans. Knowl. Data Eng. 2022, 34, 205–218. [Google Scholar] [CrossRef]
- Dong, X.L.; Berti-Équille, L.; Srivastava, D. Integrating Conflicting Data: The Role of Source Dependence. Proc. VLDB Endow. 2009, 2, 550–561. [Google Scholar] [CrossRef]
- Qi, G.; Aggarwal, C.C.; Han, J.; Huang, T.S. Mining collective intelligence in diverse groups. In Proceedings of the 22nd International World Wide Web Conference, Rio de Janeiro, Brazil, 13–17 May 2013; pp. 1041–1052. [Google Scholar]
- Dong, X.L.; Berti-Équille, L.; Srivastava, D. Truth Discovery and Copying Detection in a Dynamic World. Proc. VLDB Endow. 2009, 2, 562–573. [Google Scholar] [CrossRef]
- Pochampally, R.; Das Sarma, A.; Dong, X.L.; Meliou, A.; Srivastava, D. Fusing data with correlations. In Proceedings of the International Conference on Management of Data, Snowbird, UT, USA, 22–27 June 2014; pp. 433–444. [Google Scholar]
- Zhao, B.; Rubinstein, B.I.P.; Gemmell, J.; Han, J. A Bayesian Approach to Discovering Truth from Conflicting Sources for Data Integration. Proc. VLDB Endow. 2012, 5, 550–561. [Google Scholar] [CrossRef]
- Lin, X.; Chen, L. Domain-aware multi-truth discovery from conflicting sources. Proc. VLDB Endow. 2018, 11, 635–647. [Google Scholar] [CrossRef]
- Zhi, S.; Zhao, B.; Tong, W.; Gao, J.; Yu, D.; Ji, H.; Han, J. Modeling truth existence in truth discovery. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, NSW, Australia, 10–13 August 2015; pp. 1543–1552. [Google Scholar]
- Li, Y.; Sun, H.; Wang, W.H. Towards fair truth discovery from biased crowdsourced answers. In Proceedings of the 26th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, California, CA, USA, 23–27 August 2020; pp. 599–607. [Google Scholar]
- Wang, Y.; Wang, K.; Miao, C. Truth discovery against strategic sybil attack in crowdsourcing. In Proceedings of the 26th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, California, CA, USA, 23–27 August 2020; pp. 95–104. [Google Scholar]
- Huang, H.; Fan, G.; Li, Y.; Mu, N. Multi-truth Discovery with Correlations of Candidates in Crowdsourcing Systems. In Proceedings of the Collaborative Computing: Networking, Applications and Worksharing—17th EAI International Conference, Virtual Event, 16–18 October 2021; pp. 18–32. [Google Scholar]
- Jiang, L.; Niu, X.; Xu, J.; Yang, D.; Xu, L. Incentive mechanism design for truth discovery in crowdsourcing with copiers. IEEE Trans. Serv. Comput. 2021, 5, 2838–2853. [Google Scholar] [CrossRef]
- Dong, X.L.; Saha, B.; Srivastava, D. Less is More: Selecting Sources Wisely for Integration. Proc. VLDB Endow. 2012, 6, 37–48. [Google Scholar] [CrossRef]
- Nakhaei, Z.; Ahmadi, A.; Sharifi, A.; Badie, K. Conflict resolution using relation classification: High-level data fusion in data integration. Comput. Sci. Inf. Syst. 2021, 18, 1101–1138. [Google Scholar] [CrossRef]
- Yu, Z.; Chu, X. Piclean: A probabilistic and interactive data cleaning system. In Proceedings of the 2019 International Conference on Management of Data, Amsterdam, The Netherlands, 30 June–5 July 2019; pp. 2021–2024. [Google Scholar]
- Wang, J.; Tang, N. Towards Dependable Data Repairing with Fixing Rules. In Proceedings of the International Conference on Management of Data, Snowbird, UT, USA, 22–27 June 2014; pp. 457–468. [Google Scholar]
- Fan, W.; Li, J.; Ma, S.; Tang, N.; Yu, W. Towards Certain Fixes with Editing Rules and Master Data. VLDB J. 2012, 21, 213–238. [Google Scholar] [CrossRef]
- Bohannon, P.; Fan, W.; Geerts, F.; Jia, X.; Kementsietsidis, A. Conditional Functional Dependencies for Data Cleaning. In Proceedings of the 23rd International Conference on Data Engineering, Istanbul, Turkey, 15–20 April 2007; pp. 746–755. [Google Scholar]
- Bohannon, P.; Flaster, M.; Fan, W.; Rastogi, R. A Cost-Based Model and Effective Heuristic for Repairing Constraints by Value Modification. In Proceedings of the ACM SIGMOD International Conference on Management of Data, Baltimore, MD, USA, 14–16 June 2005; Özcan, F., Ed.; ACM: Baltimore, MD, USA, 2005; pp. 143–154. [Google Scholar]
- Kolahi, S.; Lakshmanan, L.V.S. On approximating optimum repairs for functional dependency violations. In Proceedings of the Database Theory—ICDT 2009, 12th International Conference, St. Petersburg, Russia, 23–25 March 2009; Volume 361, pp. 53–62. [Google Scholar]
- Cong, G.; Fan, W.; Geerts, F.; Jia, X.; Ma, S. Improving Data Quality: Consistency and Accuracy. In Proceedings of the 33rd International Conference on Very Large Data Bases, Vienna, Austria, 23–27 September 2007; University of Vienna: Vienna, Austria, 2007; pp. 315–326. [Google Scholar]
- Fan, W.; Geerts, F.; Ma, S.; Müller, H. Detecting inconsistencies in distributed data. In Proceedings of the 26th International Conference on Data Engineering, Long Beach, CA, USA, 1–6 March 2010; pp. 64–75. [Google Scholar]
- Fan, W.; Li, J.; Tang, N.; Yu, W. Incremental Detection of Inconsistencies in Distributed Data. In Proceedings of the IEEE 28th International Conference on Data Engineering, Washington, DC, USA, 1–5 April 2012; pp. 318–329. [Google Scholar]
- Li, P.; Dai, C.; Wang, W. Inconsistent Data Cleaning Based on the Maximum Dependency Set and Attribute Correlation. Symmetry 2018, 10, 516. [Google Scholar] [CrossRef]
- Chu, X.; Ilyas, I.F.; Papotti, P. Holistic data cleaning: Putting violations into context. In Proceedings of the 29th IEEE International Conference on Data Engineering, Brisbane, Australia, 8–12 April 2013; pp. 458–469. [Google Scholar]
- Rekatsinas, T.; Chu, X.; Ilyas, I.F.; Ré, C. HoloClean: Holistic Data Repairs with Probabilistic Inference. Proc. VLDB Endow. 2017, 10, 1190–1201. [Google Scholar] [CrossRef]
- Fan, W.; Wu, Y.; Xu, J. Functional Dependencies for Graphs. In Proceedings of the 2016 International Conference on Management of Data, San Francisco, CA, USA, 26 June–1 July 2016; pp. 1843–1857. [Google Scholar]
- Fan, W.; Liu, X.; Lu, P.; Tian, C. Catching Numeric Inconsistencies in Graphs. In Proceedings of the 2018 International Conference on Management of Data, Houston, TX, USA, 10–15 June 2018; pp. 381–393. [Google Scholar]
- Lin, P.; Song, Q.; Wu, Y.; Pi, J. Repairing Entities using Star Constraints in Multirelational Graphs. In Proceedings of the 36th IEEE International Conference on Data Engineering, Dallas, TX, USA, 20–24 April 2020; pp. 229–240. [Google Scholar]
- Schneider, S.; Lambers, L.; Orejas, F. A Logic-Based Incremental Approach to Graph Repair. In Proceedings of the Fundamental Approaches to Software Engineering—22nd International Conference, Held as Part of the European Joint Conferences on Theory and Practice of Software, Prague, Czech Republic, 6–11 April 2019; Volume 11424, pp. 151–167. [Google Scholar]
- Bravo, L.; Bertossi, L.E. Logic Programs for Consistently Querying Data Integration Systems. In Proceedings of the Eighteenth International Joint Conference on Artificial Intelligence, Acapulco, Mexico, 9–15 August 2003; pp. 10–15. [Google Scholar]
- Calì, A.; Lembo, D.; Rosati, R. On the decidability and complexity of query answering over inconsistent and incomplete databases. In Proceedings of the Twenty-Second ACM SIGACT-SIGMOD-SIGART Symposium on Principles of Database Systems, San Diego, CA, USA, 9–12 June 2003; pp. 260–271. [Google Scholar]
- Wijsen, J. Condensed Representation of Database Repairs for Consistent Query Answering. In Proceedings of the Database Theory—ICDT 2003, 9th International Conference, Siena, Italy, 8–10 January 2003; Calvanese, D., Lenzerini, M., Motwani, R., Eds.; Springer: Siena, Italy, 2003; Volume 2572, pp. 375–390. [Google Scholar]
- Yakout, M.; Elmagarmid, A.K.; Neville, J.; Ouzzani, M.; Ilyas, I.F. Guided data repair. Proc. VLDB Endow. 2011, 4, 279–289. [Google Scholar] [CrossRef]
- Cheng, Y.; Chen, L.; Yuan, Y.; Wang, G. Rule-Based Graph Repairing: Semantic and Efficient Repairing Methods. In Proceedings of the 34th IEEE International Conference on Data Engineering, Paris, France, 16–19 April 2018; pp. 773–784. [Google Scholar]
- Fan, W.; Lu, P.; Tian, C.; Zhou, J. Deducing Certain Fixes to Graphs. Proc. VLDB Endow. 2019, 12, 752–765. [Google Scholar] [CrossRef]
- Fan, W.; Jin, R.; Liu, M.; Lu, P.; Tian, C.; Zhou, J. Capturing Associations in Graphs. Proc. VLDB Endow. 2020, 13, 1863–1876. [Google Scholar] [CrossRef]
- Liu, G.; Li, L. Knowledge Fragment Cleaning in a Genealogy Knowledge Graph. In Proceedings of the 2020 IEEE International Conference on Knowledge Graph, Online, 9–11 August 2020; pp. 521–528. [Google Scholar]
- Ye, C.; Li, Q.; Zhang, H.; Wang, H.; Gao, J.; Li, J. AutoRepair: An automatic repairing approach over multi-source data. Knowl. Inf. Syst. 2019, 61, 227–257. [Google Scholar] [CrossRef]
- Ye, C.; Wang, H.; Zheng, K.; Gao, J.; Li, J. Multi-source data repairing powered by integrity constraints and source reliability. Inf. Sci. 2020, 507, 386–403. [Google Scholar] [CrossRef]
- Fan, W.; Geerts, F.; Li, J.; Xiong, M. Discovering conditional functional dependencies. IEEE Trans. Knowl. Data Eng. 2010, 23, 683–698. [Google Scholar] [CrossRef]
- Rezig, E.K.; Ouzzani, M.; Aref, W.G.; Elmagarmid, A.K.; Mahmood, A.R.; Stonebraker, M. Horizon: Scalable dependency-driven data cleaning. Proc. VLDB Endow. 2021, 14, 2546–2554. [Google Scholar] [CrossRef]


{kind=link}
| Method | Schema Type | Step | Knowledge-Based |
|---|---|---|---|
| Standard blocking [5] | Schema-aware | Blocking | No |
| Sorted blocking [13] | Schema-aware | Blocking | No |
| CrowdER [14] | Schema-aware | Blocking-matching | No |
| Swoosh [15] | Schema-aware | Matching | No |
| SEMR [16] | Schema-aware | Matching | Yes |
| Rule-based ER [17] | Schema-aware | Blocking–matching | Yes |
| DMCE [18] | Schema-aware | Matching | Yes |
| Token blocking [19] | Schema-agnostic | Blocking | No |
| Attribute clustering blocking [20] | Schema-agnostic | Blocking | No |
| SiGMa [21] | Schema-agnostic | Matching | No |
| MinoanER [22] | Schema-agnostic | Blocking–matching | No |
| Method | Step | Knowledge-Based | Learning Type | Pre-Trained LM |
|---|---|---|---|---|
| ApproxDNF [23] | Blocking | No | Supervised | No |
| BSL [24] | Blocking | No | Supervised | No |
| BGP [25] | Blocking | No | Supervised | No |
| CBLOCK [26] | Blocking | No | Supervised | No |
| KBPearl [27] | Matching | Yes | Supervised | No |
| CEA [28] | Matching | Yes | Supervised | No |
| AL-EM [29] | Matching | No | Supervised | No |
| Semi-supervised de-dup [30] | Matching | No | Semi-supervised | No |
| Map-Reduce-Based EI [31] | Matching | No | Unsupervised | No |
| ULEC [32] | Matching | No | Unsupervised | No |
| ZeroER [33] | Matching | No | Unsupervised | No |
| RER [34] | Matching | Yes | Unsupervised | No |
| PERC [35] | Matching | Yes | Unsupervised | No |
| DeepER [36] | Blocking–matching | No | Deep learning | No |
| DeepMatcher [37] | Matching | No | Deep learning | No |
| DeepBlocking [38] | Blocking | No | Deep learning | No |
| DITTO [39] | Blocking–matching | Yes | Deep learning | Yes |
| Machop [40] | Matching | Yes | Deep learning | Yes |
| JointMatcher [41] | Matching | No | Deep learning | Yes |
| Method | Labeled Truths | Entity Dependency | Source Dependency | Non-Single Truth | Crowdsourcing |
|---|---|---|---|---|---|
| SSTF [50] | ✓ | ||||
| SLiMFast [51] | ✓ | ||||
| OpSTD [52] | ✓ | ||||
| Investment [53] | ✓ | ✓ | |||
| GFFTD [54] | ✓ | ||||
| MTM [55] | ✓ | ||||
| DynaTD [56] | ✓ | ||||
| TD-corr [57] | ✓ | ||||
| OTD [58] | ✓ | ||||
| CRDI [59] | ✓ | ||||
| CTD [60] | ✓ | ||||
| ACCU [61] | ✓ | ||||
| MSS [62] | ✓ | ✓ | |||
| TDCD [63] | ✓ | ||||
| PrecRecCorr [64] | ✓ | ✓ | |||
| LTM [65] | ✓ | ||||
| DART [66] | ✓ | ||||
| TEM(15) [67] | ✓ | ||||
| FairTD [68] | ✓ | ||||
| TDSSA [69] | ✓ | ||||
| MTD-CC [70] | ✓ | ✓ | ✓ | ||
| IMCC [71] | ✓ | ✓ |
| Tid | Country Code | Area Code | Phone | Name | Street | City | Zip |
|---|---|---|---|---|---|---|---|
| 01 | 908 | 5219527 | Mike | Tree Ave. | MH | 07974 | |
| 01 | 908 | 5219527 | Rick | Tree Ave. | MH | 07974 | |
| 01 | 212 | 2018967 | Joe | 5th Ave | NYC | 01202 | |
| 01 | 908 | 2018967 | Jim | Elm Str. | MH | 07974 | |
| 44 | 131 | 3314823 | Ben | High St. | EDI | EH4 1DI | |
| 44 | 131 | 4675378 | Ian | High St. | EDI | EH4 1DT | |
| 44 | 908 | 4675378 | Ian | Port PI | MH | W1B 1JH | |
| 01 | 131 | 2018967 | Sean | 3rd Str. | UN | 01202 |
| Data | Constraints | |||||
|---|---|---|---|---|---|---|
| Table Data | Graph Data | FDs | CFDs | DCs | Other Constraints | |
| FD-based value modification [78] | ✓ | ✓ | ✓ | |||
| FindVRepair [79] | ✓ | ✓ | ✓ | |||
| CFD-based Detection [77] | ✓ | ✓ | ||||
| CFD-based value modification [80] | ✓ | ✓ | ||||
| Distributed Detection [81] | ✓ | ✓ | ||||
| Incremental Detection [82] | ✓ | ✓ | ||||
| C-Repair [83] | ✓ | ✓ | ||||
| Holistic Repair [84] | ✓ | ✓ | ||||
| HoloClean [85] | ✓ | ✓ | ✓ | |||
| GFD-based Detection [86] | ✓ | ✓ | ||||
| IncDect [87] | ✓ | ✓ | ||||
| StarRepair [88] | ✓ | ✓ | ||||
| Logic-based Graph Repair [89] | ✓ | ✓ | ||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ye, C.; Duan, H.; Zhang, H.; Zhang, H.; Wang, H.; Dai, G. Multi-Source Data Repairing: A Comprehensive Survey. Mathematics 2023, 11, 2314. https://doi.org/10.3390/math11102314
Ye C, Duan H, Zhang H, Zhang H, Wang H, Dai G. Multi-Source Data Repairing: A Comprehensive Survey. Mathematics. 2023; 11(10):2314. https://doi.org/10.3390/math11102314
Chicago/Turabian StyleYe, Chen, Haoyang Duan, Hengtong Zhang, Hua Zhang, Hongzhi Wang, and Guojun Dai. 2023. "Multi-Source Data Repairing: A Comprehensive Survey" Mathematics 11, no. 10: 2314. https://doi.org/10.3390/math11102314
APA StyleYe, C., Duan, H., Zhang, H., Zhang, H., Wang, H., & Dai, G. (2023). Multi-Source Data Repairing: A Comprehensive Survey. Mathematics, 11(10), 2314. https://doi.org/10.3390/math11102314