
How to Train Novices in Bayesian Reasoning


 ,
,
Abstract
1. Introduction
“10% of women at age forty who participate in a study have a particular disease. 60% of women with the disease will have a positive reaction to a test. 20% of women without the disease will also test positive. Calculate the probability of having the particular disease if given a positive test result.”
In 10% of comparable cases regarding a specific criminal offense, the charges are actually correct. In 60% of the cases in which the charges are correct, incriminating evidence is given. In 20% of the cases in which the charges are incorrect, incriminating evidence is given nevertheless.
2. Evidence-Based and Theoretical Considerations for Developing a Training Course on Bayesian Reasoning
2.1. Categories of Bayesian Reasoning
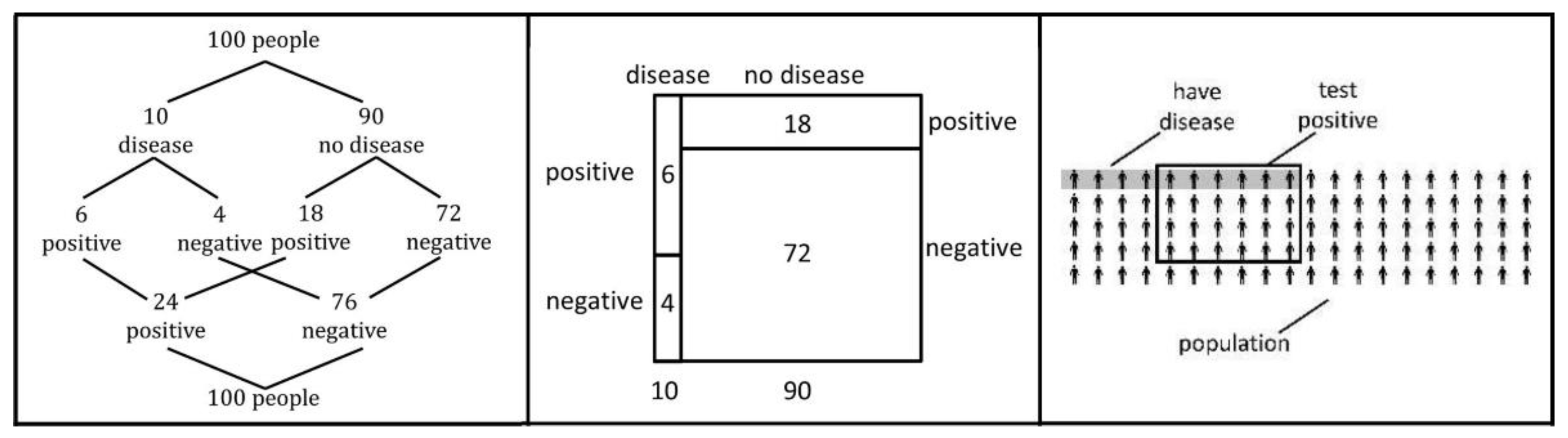
2.2. Facilitating Bayesian Reasoning through Natural Frequencies
“10 out of 100 women at age forty who participate in a study have a particular disease. 6 out of 10 women with the disease will have a positive reaction to a test. 18 out of 90 women without the disease will also test positive. Calculate the proportion of women who may have the particular disease, given a positive test result.”
2.3. Facilitating Bayesian Reasoning through Visualization
2.4. Training Bayesian Reasoning
- In some of the interventions, probabilities were used as an information format for statistical data [44]. However, research has consistently shown that using natural frequencies or translating probabilities into natural frequencies can boost people’s performance in Bayesian situations.
- In most of the interventions, a tree diagram was used to visualize the statistical information of Bayesian situations [46]. However, as mentioned above, although a tree diagram does increase people’s performance, research has also yielded evidence that other visualizations are more promising.
- Most of the participants who were recruited did not study a subject which specifically requires Bayesian Reasoning [20]. Exceptions occurred in the intervention studies that refer to medicine students who worked with medical Bayesian situations.
- None of the intervention studies refer to Bayesian Reasoning as a complex cognitive skill involving abilities beyond performance.
2.5. Four-Component Instructional Design (4C/ID) Model
2.5.1. Learning Tasks
2.5.2. Supportive Information
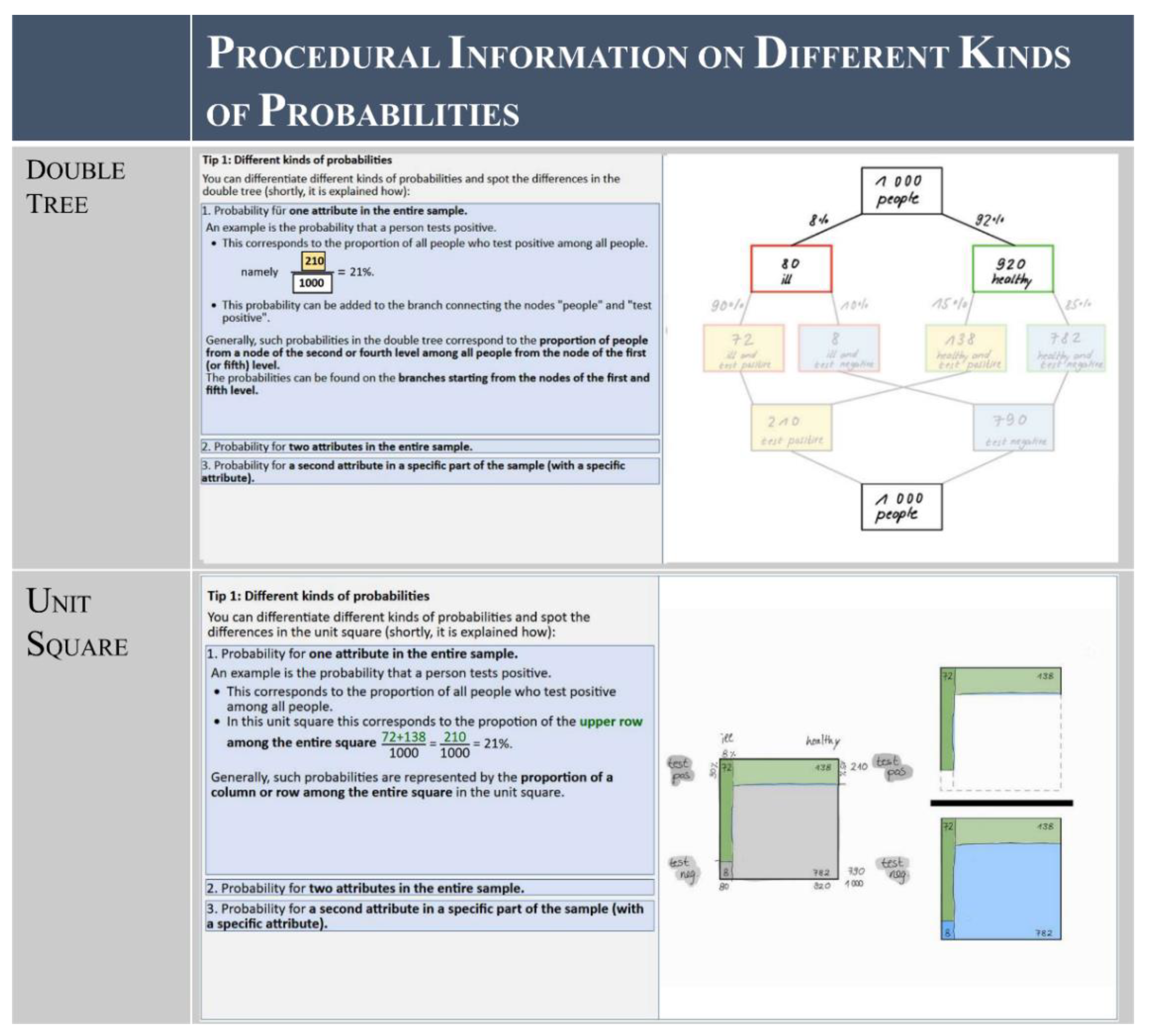
2.5.3. Procedural Information
2.5.4. Part-Task Practice
3. Description of the Training Course on Bayesian Reasoning
- The format of statistical information: using natural frequencies;
- The visualization of statistical information: using a double tree or unit square; and
- The instructional approach: using the 4C/ID model.
3.1. Learning Tasks: Performance, Covariation and Communication in Real-Life Bayesian Situations
3.2. Supportive Information on the Task Class of Performance: Mental Models and Worked Examples
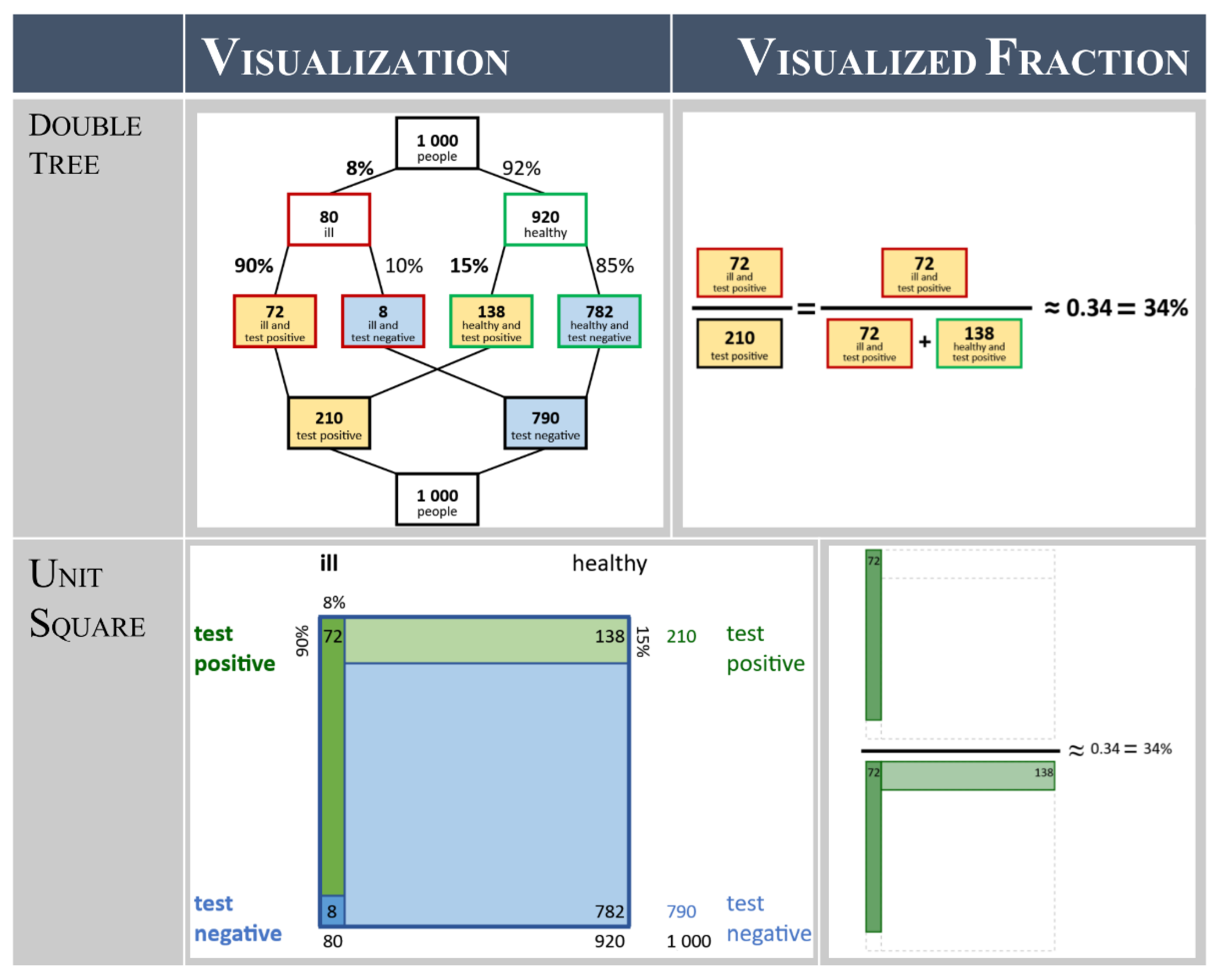
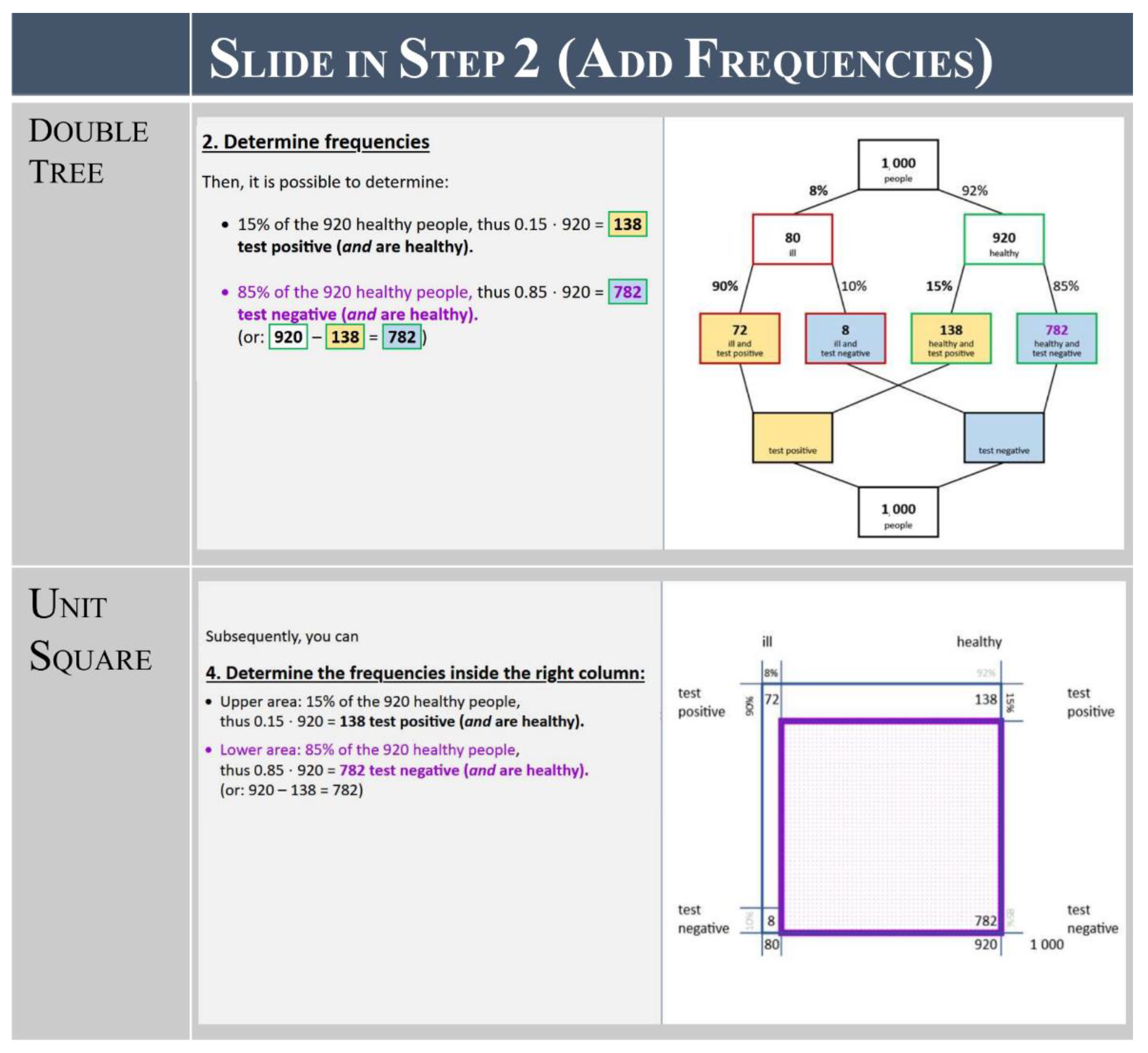
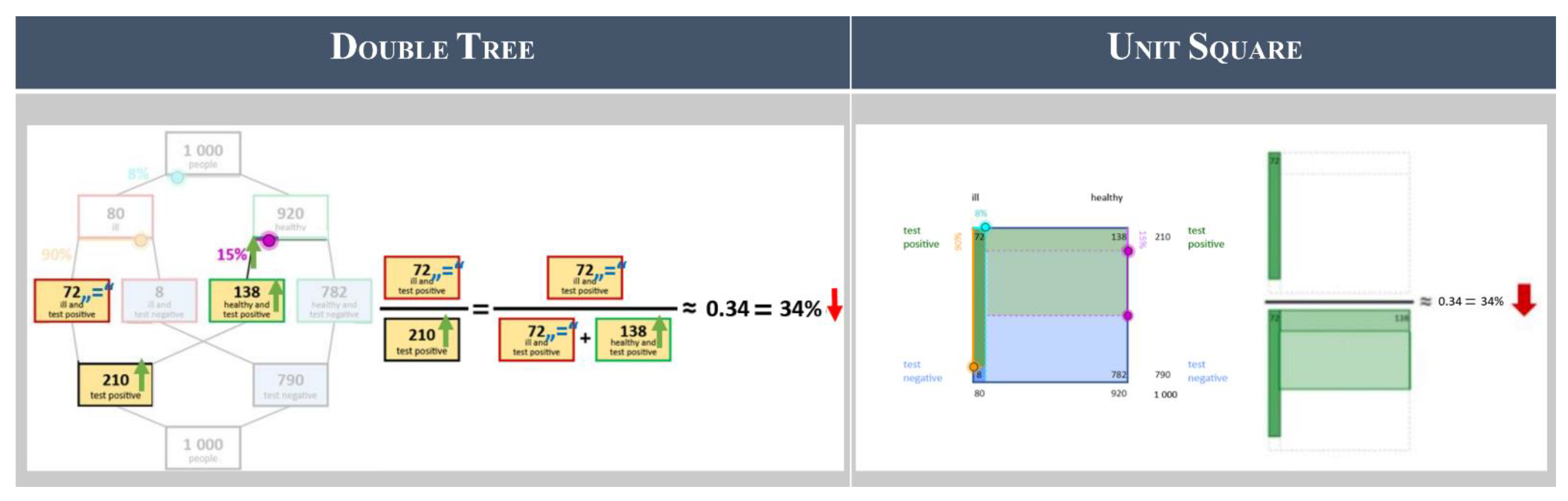
3.2.1. Mental Models: Frequency-Based Double Trees and Unit Squares
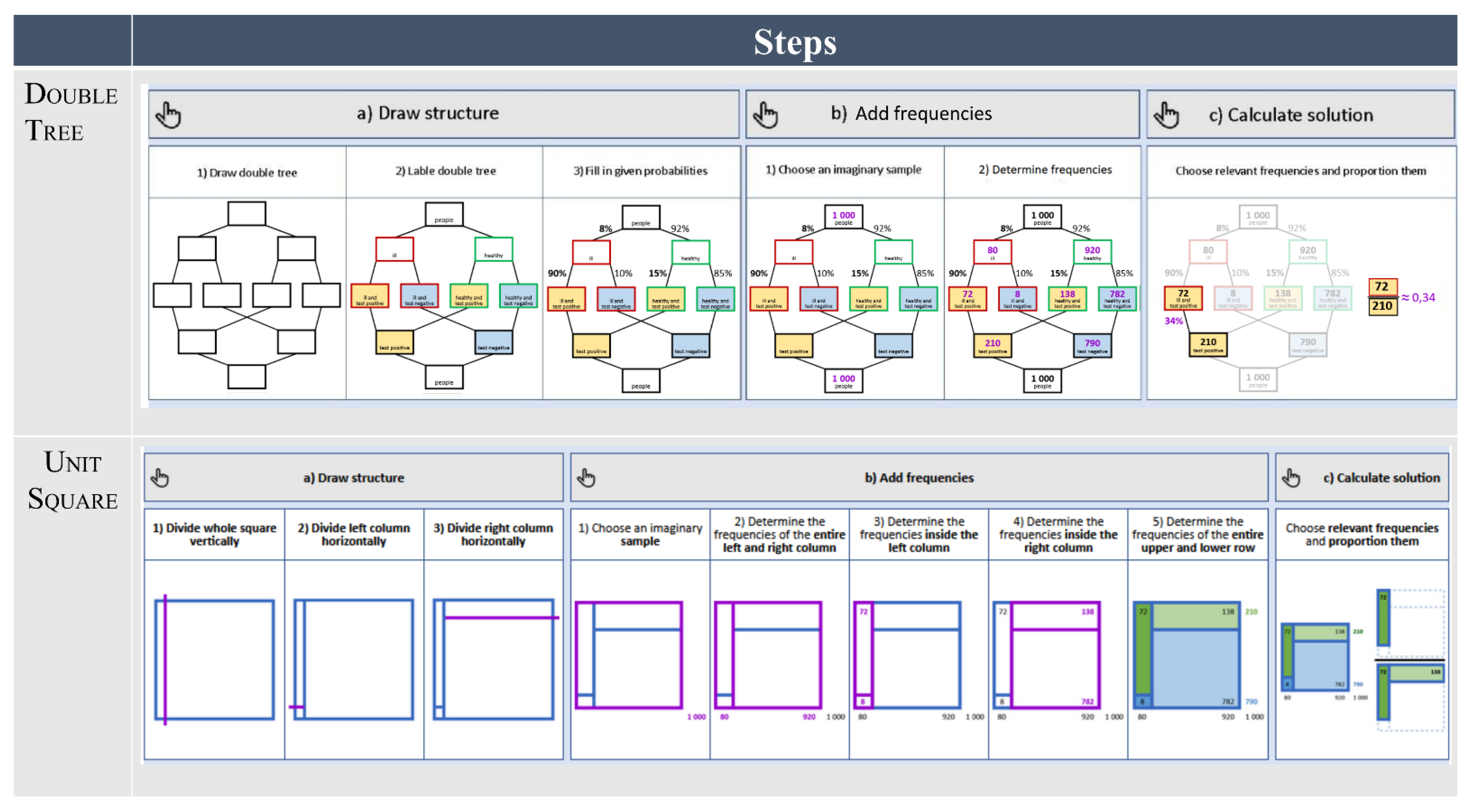
3.2.2. Cognitive Strategy: Worked Example
- Draw the structure of the visualization with the given information (draw structure);
- Translate the given probabilistic information into frequencies and add them to the visualization (add frequencies); and
- Calculate the required probability with the visualization (calculate solution).
3.3. Supportive Information for the Task Class of Covariation: Mental Models and Worked-Examples
3.3.1. Mental Model: Dynamic Frequency-Based Double Trees and Unit Squares
3.3.2. Cognitive Strategy: Worked Examples
3.4. Procedural Information: Facilitating Recurring Aspects in Bayesian Situations
3.5. Whole-Task Practice
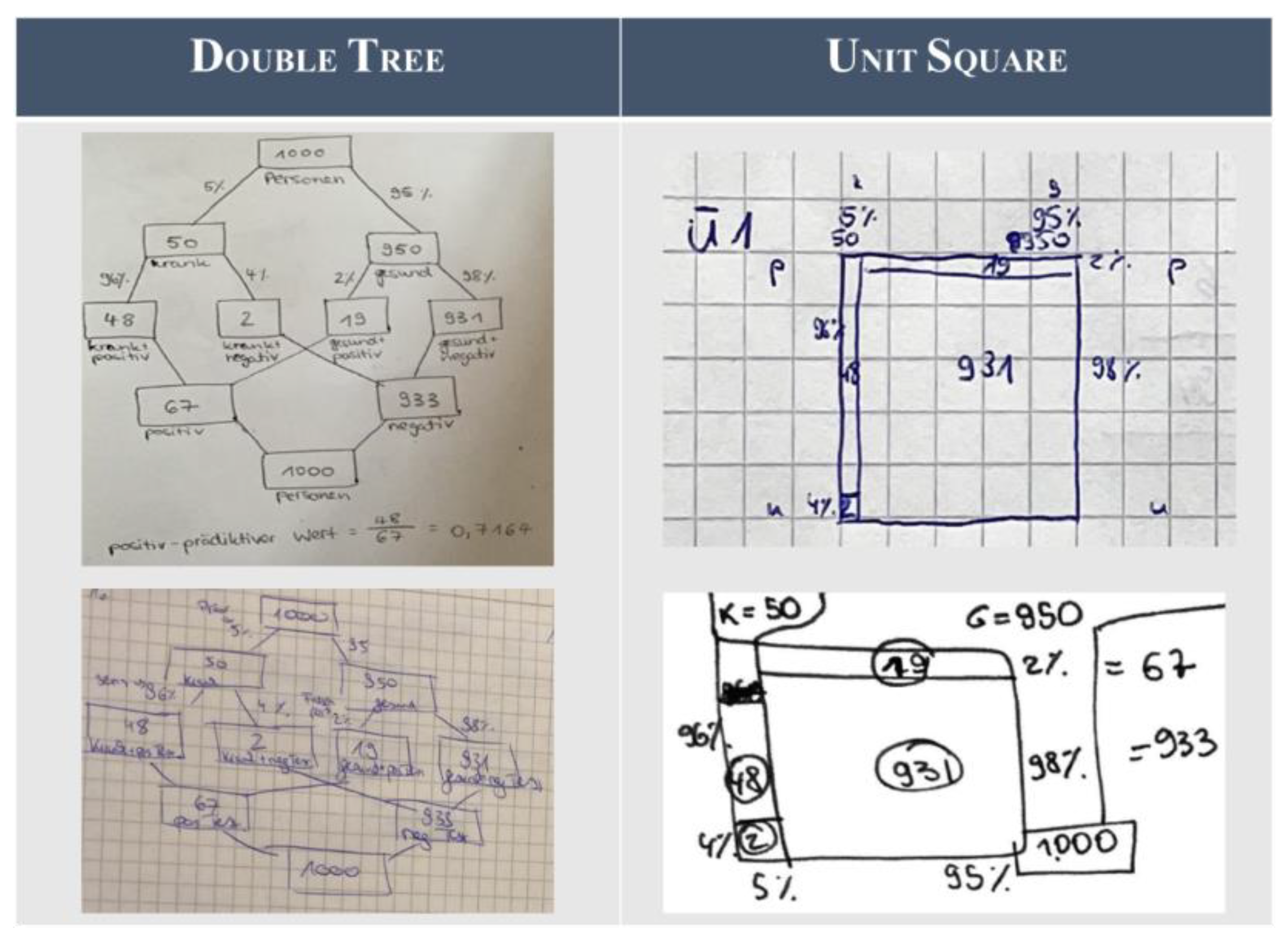
3.5.1. Practice of the Task Class of Performance
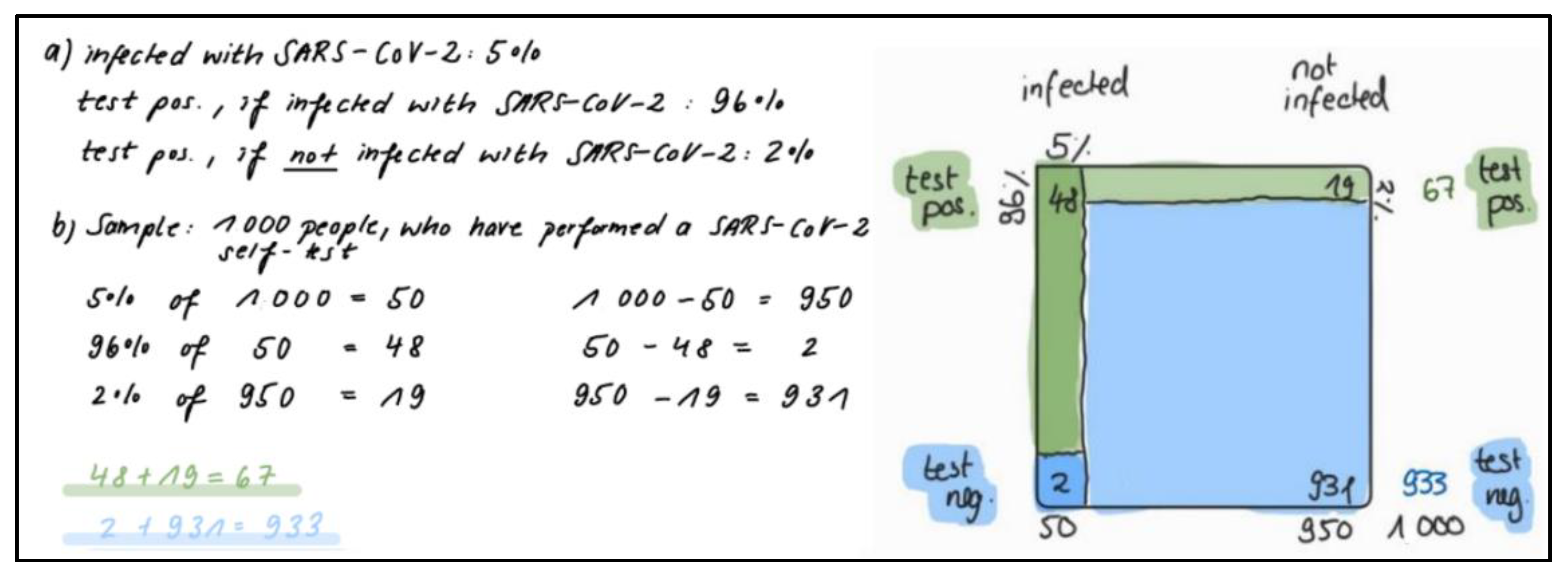
- An explanation of how the correct solution could have been calculated by using the visualization (double tree or unit square) correctly;
- A statement about which error has been made in the calculation, e.g., “You have calculated 48/50”;
- An explanation of why this is wrong, e.g., “Therefore, you did not calculate how many of those tested positive are actually infected with SARS-CoV-2, but how many of those infected correctly test positive”;
- An explanation of which probability has, thereby, been calculated, e.g., “The probability which you have calculated is: The probability that a person tests positive, if (s)he is infected with SARS-CoV-2 (=48/50 = 96%) and this is the sensitivity”.
3.5.2. Practice of the Task Class of Covariation
4. Formative Evaluation of the Training Courses
- on three of the learning tasks (Section 3.1) without any instruction in the beginning (phase 1);
- with the materials of the training courses regarding the aspect of performance with the supportive and procedural information (phase 2);
- with the materials of the training courses regarding the aspect of covariation with the supportive and procedural information (phase 3); and
- on four of the learning tasks (Section 3.1) without the material of the training courses (phase 4).
5. Discussion and Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- De Finetti, B. Theory of Probability: A Critical Introductory Treatment, 1st ed.; John Wiley & Sons: Chichester, UK; Hoboken, NJ, USA, 2017; ISBN 978-111-928-637-0. [Google Scholar]
- Gelman, A. Bayesian Data Analysis, 3rd ed.; CRC Press: Hoboken, NJ, USA, 2013; ISBN 978-143-984-095-5. [Google Scholar]
- McGrayne, S.B. The Theory That Would Not Die: How Bayes’ Rule Cracked the Enigma Code, Hunted Down Russian Submarines, & Emerged Triumphant from Two Centuries of Controversy; Yale University Press: New Haven, CT, USA, 2011; ISBN 978-030-018-822-6. [Google Scholar]
- Ashby, D. Bayesian statistics in medicine: A 25 year review. Stat. Med. 2006, 25, 3589–3631. [Google Scholar] [CrossRef]
- Satake, E.; Murray, A.V. Teaching an Application of Bayes’ Rule for Legal Decision-Making: Measuring the Strength of Evidence. J. Stat. Educ. 2014, 22. [Google Scholar] [CrossRef]
- Hoffrage, U.; Hafenbrädl, S.; Bouquet, C. Natural frequencies facilitate diagnostic inferences of managers. Front. Psychol. 2015, 6, 642. [Google Scholar] [CrossRef]
- Kahneman, D.; Slovic, P.; Tversky, A. (Eds.) Judgment under Uncertainty: Heuristics and Biases, 1st ed.; Cambridge University Press: Cambridge, UK, 1982; ISBN 978-052-128-414-1. [Google Scholar]
- Gigerenzer, G.; Hoffrage, U. How to improve Bayesian reasoning without instruction: Frequency formats. Psychol. Rev. 1995, 102, 684–704. [Google Scholar] [CrossRef]
- McDowell, M.; Jacobs, P. Meta-analysis of the effect of natural frequencies on Bayesian reasoning. Psychol. Bull. 2017, 143, 1273–1312. [Google Scholar] [CrossRef]
- Cosmides, L.; Tooby, J. Are humans good intuitive statisticians after all? Rethinking some conclusions from the literature on judgment under uncertainty. Cognition 1996, 58, 1–73. [Google Scholar] [CrossRef]
- Eddy, D.M. Probabilistic reasoning in clinical medicine: Problems and opportunities. In Judgment under Uncertainty: Heuristics and Biases; Kahneman, D., Slovic, P., Tversky, A., Eds.; Cambridge University Press: Cambridge, UK, 1982; pp. 249–267. ISBN 978-052-128-414-1. [Google Scholar]
- Gigerenzer, G. Calculated Risks: How to Know When Numbers Deceive You; Simon & Schuster: New York, NY, USA, 2002; ISBN 074-320-556-1. [Google Scholar]
- Schneps, L.; Colmez, C. Math on Trial: How Numbers Get Used and Abused in the Courtroom, 1st ed.; Basic Books: New York, NY, USA, 2013; ISBN 978-046-503-292-1. [Google Scholar]
- Stine, G.J. Acquired Immune Deficiency Syndrome: Biological, Medical, Social, and Legal Issues; Prentice Hall: Upper Saddle River, NJ, USA, 1996. [Google Scholar]
- Johnson, E.D.; Tubau, E. Comprehension and computation in Bayesian problem solving. Front. Psychol. 2015, 6, 938. [Google Scholar] [CrossRef]
- Hoffrage, U.; Krauss, S.; Martignon, L.; Gigerenzer, G. Natural frequencies improve Bayesian reasoning in simple and complex inference tasks. Front. Psychol. 2015, 6, 1473. [Google Scholar] [CrossRef]
- Binder, K.; Krauss, S.; Bruckmaier, G.; Marienhagen, J. Visualizing the Bayesian 2-test case: The effect of tree diagrams on medical decision making. PLoS ONE 2018, 13, e0195029. [Google Scholar] [CrossRef]
- Brase, G.L. Pictorial representations in statistical reasoning. Appl. Cogn. Psychol. 2009, 23, 369–381. [Google Scholar] [CrossRef]
- Binder, K.; Krauss, S.; Bruckmaier, G. Effects of visualizing statistical information—An empirical study on tree diagrams and 2 × 2 tables. Front. Psychol. 2015, 6, 1186. [Google Scholar] [CrossRef]
- Sirota, M.; Kostovičová, L.; Vallée-Tourangeau, F. How to train your Bayesian: A problem-representation transfer rather than a format-representation shift explains training effects. Q. J. Exp. Psychol. 2015, 68, 1–9. [Google Scholar] [CrossRef]
- Van Merriënboer, J.J.G.; Kirschner, P.A. Ten Steps to Complex Learning: A Systematic Approach to Four-Component Instructional Design, 2nd ed.; Routledge: New York, NY, USA, 2013; ISBN 978-020-309-686-4. [Google Scholar]
- Zhu, L.; Gigerenzer, G. Children can solve Bayesian problems: The role of representation in mental computation. Cognition 2006, 98, 287–308. [Google Scholar] [CrossRef] [PubMed]
- Borovcnik, M. Multiple Perspectives on the Concept of Conditional Probability. Av. Investig. Educ. Mat. 2012, 2, 5–27. [Google Scholar] [CrossRef]
- Böcherer-Linder, K.; Eichler, A. The Impact of Visualizing Nested Sets. An Empirical Study on Tree Diagrams and Unit Squares. Front. Psychol. 2017, 7, 2026. [Google Scholar] [CrossRef]
- Leinhardt, G.; Zaslavsky, O.; Stein, M.K. Functions, Graphs, and Graphing: Tasks, Learning, and Teaching. Rev. Educ. Res. 1990, 60, 1–64. [Google Scholar] [CrossRef]
- Ayalon, M.; Wilkie, K.J. Exploring secondary students’ conceptualization of functions in three curriculum contexts. J. Math. Behav. 2019, 56, 100718. [Google Scholar] [CrossRef]
- Thompson, P.W.; Carlson, M.P. Variation, covariation, and functions: Foundational ways of thinking mathematically. In Compendium for Research in Mathematics Education; National Council of Teachers of Mathematics: Reston, VA, USA, 2017; pp. 421–456. [Google Scholar]
- Niss, M.; Højgaard, T. Mathematical competencies revisited. Educ. Stud. Math. 2019, 102, 9–28. [Google Scholar] [CrossRef]
- Wild, C.J.; Pfannkuch, M. Statistical Thinking in Empirical Enquiry. Int. Stat. Rev. 1999, 67, 223–248. [Google Scholar] [CrossRef]
- Gal, I. Adults’ Statistical Literacy: Meanings, Components, Responsibilities. Int. Stat. Rev. 2002, 70, 1–25. [Google Scholar] [CrossRef]
- Buckman, R.A. Breaking bad news: The S-P-I-K-E-S strategy. Community Oncol. 2005, 2, 138–142. [Google Scholar] [CrossRef]
- Brinktrine, R.; Schneider, H. Juristische Schlüsselqualifikationen: Einsatzbereiche—Examensrelevanz—Examenstraining; Springer: Berlin, Germany, 2008; ISBN 978-354-048-698-5. [Google Scholar]
- Bromme, R.; Nückles, M.; Rambow, R. Adaptivity and anticipation in expert-laypeople communication. In Psychological Models of Communication in Collaborative Systems; Brennan, S.E., Ed.; AAAI Press: Menlo Park, CA, USA, 1999; pp. 17–24. ISBN 978-157-735-105-4. [Google Scholar]
- Frerejean, J.; Merriënboer, J.J.G.; Kirschner, P.A.; Roex, A.; Aertgeerts, B.; Marcellis, M. Designing instruction for complex learning: 4C/ID in higher education. Eur. J. Educ. 2019, 54, 513–524. [Google Scholar] [CrossRef]
- Krauss, S.; Weber, P.; Binder, K.; Bruckmaier, G. Natürliche Häufigkeiten als numerische Darstellungsart von Anteilen und Unsicherheit—Forschungsdesiderate und einige Antworten. J. Math. Didakt. 2020, 41, 485–521. [Google Scholar] [CrossRef]
- Kleiter, G.D. Natural Sampling: Rationality without Base Rates. In Contributions to Mathematical Psychology, Psychometrics, and Methodology; Fischer, G.H., Ed.; Springer: New York, NY, USA, 1994; pp. 375–388. ISBN 978-038-794-169-1. [Google Scholar]
- Brase, G. What facilitates Bayesian reasoning? A crucial test of ecological rationality versus nested sets hypotheses. Psychon. Bull. Rev. 2021, 28, 703–709. [Google Scholar] [CrossRef]
- Böcherer-Linder, K.; Eichler, A.; Vogel, M. The impact of visualization on flexible Bayesian reasoning. AIEM 2017, 25–46. [Google Scholar] [CrossRef]
- Böcherer-Linder, K.; Eichler, A. How to Improve Performance in Bayesian Inference Tasks: A Comparison of Five Visualizations. Front. Psychol. 2019, 10, 267. [Google Scholar] [CrossRef]
- Binder, K.; Krauss, S.; Schmidmaier, R.; Braun, L.T. Natural frequency trees improve diagnostic efficiency in Bayesian reasoning. Adv. Health Sci. Educ. 2021, 26, 847–863. [Google Scholar] [CrossRef]
- Sloman, S.A.; Over, D.; Slovak, L.; Stibel, J.M. Frequency illusions and other fallacies. Organ. Behav. Hum. Decis. Processes 2003, 91, 296–309. [Google Scholar] [CrossRef]
- Eichler, A.; Böcherer-Linder, K.; Vogel, M. Different Visualizations Cause Different Strategies When Dealing With Bayesian Situations. Front. Psychol. 2020, 11, 1897. [Google Scholar] [CrossRef]
- Khan, A.; Breslav, S.; Glueck, M.; Hornbæk, K. Benefits of visualization in the Mammography Problem. Int. J. Hum.-Comput. Stud. 2015, 83, 94–113. [Google Scholar] [CrossRef]
- Bea, W. Stochastisches Denken: Analysen aus Kognitionspsychologischer und Didaktischer Perspektive; Lang: Frankfurt am Main, Germany, 1995; ISBN 363-148-844-0. [Google Scholar]
- Chow, A.F.; van Haneghan, J.P. Transfer of solutions to conditional probability problems: Effects of example problem format, solution format, and problem context. Educ. Stud. Math. 2016, 93, 67–85. [Google Scholar] [CrossRef]
- Kurzenhäuser, S.; Hoffrage, U. Teaching Bayesian Reasoning: An evaluation of a classroom tutorial for medical students. Med. Teach. 2009, 24, 516–521. [Google Scholar] [CrossRef] [PubMed]
- Ruscio, J. Comparing Bayes’s theorem to frequency-based approaches to teaching Bayesian reasoning. Teach. Psychol. 2003, 30, 325–328. [Google Scholar]
- Sedlmeier, P.; Gigerenzer, G. Teaching Bayesian reasoning in less than two hours. J. Exp. Psychol. Gen. 2001, 130, 380–400. [Google Scholar] [CrossRef]
- Starns, J.J.; Cohen, A.L.; Bosco, C.; Hirst, J. A visualization technique for Bayesian reasoning. Appl. Cognit. Psychol. 2019, 33, 234–251. [Google Scholar] [CrossRef]
- Steckelberg, A.; Balgenorth, A.; Berger, J.; Mühlhauser, I. Explaining computation of predictive values: 2 × 2 table versus frequency tree. A randomized controlled trial ISRCTN74278823. BMC Med. Educ. 2004, 4, 13. [Google Scholar] [CrossRef]
- Talboy, A.N.; Schneider, S.L. Improving Accuracy on Bayesian Inference Problems Using a Brief Tutorial. J. Behav. Dec. Mak. 2017, 30, 373–388. [Google Scholar] [CrossRef]
- Wassner, C. Förderung Bayesianischen Denkens: Kognitionspsychologische Grundlagen und Didaktische Analysen; Franzbecker: Hildesheim, Germany, 2004. [Google Scholar]
- Maggio, L.A.; Cate, O.T.; Irby, D.M.; O’Brien, B.C. Designing evidence-based medicine training to optimize the transfer of skills from the classroom to clinical practice: Applying the four component instructional design model. Acad. Med. J. Assoc. Am. Med. Coll. 2015, 90, 1457–1461. [Google Scholar] [CrossRef]
- Wopereis, I.; Frerejean, J.; Brand-Gruwel, S. Information Problem Solving Instruction in Higher Education: A Case Study on Instructional Design. In Information Literacy: Moving Toward Sustainability, Proceedings of the Third European Conference, ECIL 2015, Tallinn, Estonia, 19–22 October 2015; Revised Selected Papers; Kurbanoğlu, S., Boustany, J., Špiranec, S., Grassian, E., Mizrachi, D., Roy, L., Eds.; Springer: Cham, Switzerland, 2015; pp. 293–302. ISBN 978-331-928-197-1. [Google Scholar]
- Sarfo, F.K.; Elen, J. Developing technical expertise in secondary technical schools: The effect of 4C/ID learning environments. Learn. Environ. Res. 2007, 10, 207–221. [Google Scholar] [CrossRef]
- Martinez-Mediano, C.; Rioperez Losada, N. Internet-Based Performance Support Systems in Engineering Education. IEEE Rev. Iberoam. Tecnol. Aprendiz. 2017, 12, 86–93. [Google Scholar] [CrossRef]
- Costa, J.M.; Miranda, G.L.; Melo, M. Four-component instructional design (4C/ID) model: A meta-analysis on use and effect. Learn. Environ. Res. 2021, 2021, 1–19. [Google Scholar] [CrossRef]
- Van Merriënboer, J.J.G.; Clark, R.E.; Croock, M.B.M. Blueprints for complex learning: The 4C/ID-model. Educ. Technol. Res. Dev. 2002, 50, 39–61. [Google Scholar] [CrossRef]
- Van Merriënboer, J.J.G.; Seel, N.M.; Kirschner, P.A. Mental Models as a New Foundation for Instructional Design. Educ. Technol. 2002, 42, 60–66. [Google Scholar]
- Clark, R.C.; Nguyen, F.; Sweller, J. Efficiency in Learning: Evidence-Based Guidelines to Manage Cognitive Load; John Wiley & Sons: Hoboken, NJ, USA, 2011; ISBN 978-111-804-674-6. [Google Scholar]
- Renkl, A. The Worked Examples Principle in Multimedia Learning. In The Cambridge Handbook of Multimedia Learning, 2nd ed.; Mayer, R.E., Ed.; Cambridge University Press: Cambridge, UK, 2014; pp. 391–412. ISBN 978-113-954-736-9. [Google Scholar]
- Van Merriënboer, J.J.G.; Kester, L. The Four-Component Instructional Design Model: Multimedia Principles in Environments for Complex Learning. In The Cambridge Handbook of Multimedia Learning, 2nd ed.; Mayer, R.E., Ed.; Cambridge University Press: Cambridge, UK, 2014; pp. 104–148. ISBN 978-113-954-736-9. [Google Scholar]
- Kirkwood, B.R.; Sterne, J.A.C. Essential Medical Statistics, 2nd ed.; Blackwell Publishing: Malden, MA, USA, 2003; ISBN 978-144-439-284-5. [Google Scholar]
- Mayer, R.E. (Ed.) The Cambridge Handbook of Multimedia Learning, 2nd ed.; Cambridge University Press: Cambridge, UK, 2014; ISBN 978-113-954-736-9. [Google Scholar]
- Mayer, R.E. Applying the Science of Learning: Evidence-Based Principles for the Design of Multimedia Instruction. Am. Psychol. 2008, 63, 760–769. [Google Scholar] [CrossRef]
- Ainsworth, S. DeFT: A conceptual framework for considering learning with multiple representations. Learn. Instr. 2006, 16, 183–198. [Google Scholar] [CrossRef]
- Eichler, A.; Vogel, M. Teaching Risk in School. Math. Enthus. 2015, 12, 168–183. [Google Scholar] [CrossRef]
- Rey, G.D.; Beege, M.; Nebel, S.; Wirzberger, M.; Schmitt, T.H.; Schneider, S. A Meta-analysis of the Segmenting Effect. Educ. Psychol. Rev. 2019, 31, 389–419. [Google Scholar] [CrossRef]
- Mayer, R.E.; Wells, A.; Parong, J.; Howarth, J.T. Learner control of the pacing of an online slideshow lesson: Does segmenting help? Appl. Cognit. Psychol. 2019, 33, 930–935. [Google Scholar] [CrossRef]
- Schneider, S.; Beege, M.; Nebel, S.; Rey, G.D. A meta-analysis of how signaling affects learning with media. Educ. Res. Rev. 2018, 23, 1–24. [Google Scholar] [CrossRef]
- Mayer, R.E.; Fiorella, L. Principles for Reducing Extraneous Processing in Multimedia Learning: Coherence, Signaling, Redundancy, Spatial Contiguity, and Temporal Contiguity Principles. In The Cambridge Handbook of Multimedia Learning, 2nd ed.; Mayer, R.E., Ed.; Cambridge University Press: Cambridge, UK, 2014; pp. 279–315. ISBN 978-113-954-736-9. [Google Scholar]
- Ayres, P.; Sweller, J. The Split-Attention Principle in Multimedia Learning. In The Cambridge Handbook of Multimedia Learning, 2nd ed.; Mayer, R.E., Ed.; Cambridge University Press: Cambridge, UK, 2014; pp. 206–226. ISBN 978-113-954-736-9. [Google Scholar]
- Sweller, J. Cognitive Load Theory. In The Psychology of Learning and Motivation, 55, Cognition in Education; Mestre, J.P., Ross, B.H., Eds.; Academic Press: San Diego, CA, USA, 2011; pp. 37–76. ISBN 978-012-387-691-1. [Google Scholar]
- Schnotz, W. Integrated Model of Text and Picture Comprehension. In The Cambridge Handbook of Multimedia Learning, 2nd ed.; Mayer, R.E., Ed.; Cambridge University Press: Cambridge, UK, 2014; pp. 72–103. ISBN 978-113-954-736-9. [Google Scholar]
- Schnotz, W.; Mengelkamp, C.; Baadte, C.; Hauck, G. Focus of attention and choice of text modality in multimedia learning. Eur. J. Psychol. Educ. 2014, 29, 483–501. [Google Scholar] [CrossRef]
- Kulgemeyer, C. A Framework of Effective Science Explanation Videos Informed by Criteria for Instructional Explanations. Res. Sci. Educ. 2020, 50, 2441–2462. [Google Scholar] [CrossRef]
- Spanjers, I.A.E.; van Gog, T.; Wouters, P.; van Merriënboer, J.J.G. Explaining the segmentation effect in learning from animations: The role of pausing and temporal cueing. Comput. Educ. 2012, 59, 274–280. [Google Scholar] [CrossRef]
- Guo, P.J.; Juho, K.; Rob, R. How video production affects student engagement: An empirical study of MOOC videos. In Proceedings of the L@S 2014: First (2014) ACM Conference on Learning @ Scale, Atlanta, GA, USA, 4–5 March 2014; pp. 41–50, ISBN 978-145-032-669-8. [Google Scholar]
- Ouwehand, K.; van Gog, T.; Paas, F. Designing effective video-based modeling examples using gaze and gesture cues. Educ. Technol. Soc. 2015, 18, 78–88. [Google Scholar]
- Van Wermeskerken, M.; Ravensbergen, S.; van Gog, T. Effects of instructor presence in video modeling examples on attention and learning. Comput. Hum. Behav. 2018, 89, 430–438. [Google Scholar] [CrossRef]
- Hertwig, R.; Benz, B.; Krauss, S. The conjunction fallacy and the many meanings of and. Cognition 2008, 108, 740–753. [Google Scholar] [CrossRef] [PubMed]
- Böcherer-Linder, K.; Eichler, A.; Vogel, M. Die Formel von Bayes: Kognitionspsychologische Grundlagen und empirische Untersuchungen zur Bestimmung von Teilmenge-Grundmenge-Beziehungen. J. Math. Didakt. 2018, 39, 127–146. [Google Scholar] [CrossRef]
- Rushdi, A.M.A.; Serag, H.A.M. Solutions of Ternary Problems of Conditional Probability with Applications to Mathematical Epidemiology and the COVID-19 Pandemic. Int. J. Math. Eng. Manag. Sci. 2020, 5, 787–811. [Google Scholar] [CrossRef]
- Batanero, C.; Borovcnik, M. Statistics and Probability in High School; SensePublishers: Rotterdam, The Netherlands, 2016; ISBN 978-946-300-624-8. [Google Scholar]
- Díaz, C.; Batanero, C. University Students’ Knowledge and Biases in Conditional Probability Reasoning. Int. Elect. J. Math. Ed. 2009, 4, 131–162. [Google Scholar] [CrossRef]
- Mathan, S.; Koedinger, K.R. Recasting the Feedback Debate: Benefits of Tutoring Error Detection and Correction Skills. In Artificial Intelligence in Education: Shaping the Future of Learning through Intelligent Technologies; Hoppe, U., Verdejo, F., Kay, J., Eds.; IOS Press: Amsterdam, The Netherlands, 2003; pp. 13–149. ISBN 978-158-603-356-9. [Google Scholar]
- Binder, K.; Krauss, S.; Wiesner, P. A New Visualization for Probabilistic Situations Containing Two Binary Events: The Frequency Net. Front. Psychol. 2020, 11, 750. [Google Scholar] [CrossRef]
- Bruckmaier, G.; Binder, K.; Krauss, S.; Kufner, H.-M. An Eye-Tracking Study of Statistical Reasoning with Tree Diagrams and 2 × 2 Tables. Front. Psychol. 2019, 10, 632. [Google Scholar] [CrossRef]
- Gigerenzer, G.; Multmeier, J.; Föhring, A.; Wegwarth, O. Do children have Bayesian intuitions? J. Exp. Psychol. Gen. 2021, 150, 1041–1070. [Google Scholar] [CrossRef] [PubMed]
- Hoffrage, U.; Gigerenzer, G. Using natural frequencies to improve diagnostic inferences. Acad. Med. 1998, 73, 538–540. [Google Scholar] [CrossRef] [PubMed]
- Barbieri, C.A.; Booth, J.L. Mistakes on Display: Incorrect Examples Refine Equation Solving and Algebraic Feature Knowledge. Appl. Cogn. Psychol. 2020, 34, 862–878. [Google Scholar] [CrossRef]
- Loibl, K.; Rummel, N. Knowing what you don’t know makes failure productive. Learn. Instr. 2014, 34, 74–85. [Google Scholar] [CrossRef]
- Dick, W. Formative Evaluation. In Instructional Design: Principles and Applications; Briggs, L.J., Ackermann, A.S., Eds.; Educational Technology Publications: Englewood Cliffs, NJ, USA, 1977; pp. 311–336. ISBN 978-087-778-098-4. [Google Scholar]
- Ashdown, H.F.; Fleming, S.; Spencer, E.A.; Thompson, M.J.; Stevens, R.J. Diagnostic accuracy study of three alcohol breathalysers marketed for sale to the public. BMJ Open 2014, 4, e005811. [Google Scholar] [CrossRef] [PubMed]
- Steib, N.; Büchter, T.; Eichler, A.; Krauss, S.; Binder, K.; Böcherer-Linder, K.; Vogel, M. How to boost performance and communication in Bayesian situations among future physicans and legal practitioners—A comparison of four training programs. submitted.
- Büchter, T.; Steib, N.; Krauss, S.; Eichler, A.; Binder, K.; Böcherer-Linder, K.; Vogel, M. A new take on Bayesian Reasoning: Teaching understanding of covariation. submitted.
- Bayesian Reasoning. Available online: http://bayesianreasoning.de/en/bayes_en.html (accessed on 14 March 2022).













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Researchers | Year of Publication | Sample | Characteristics of the Training Course |
|---|---|---|---|
| Bea [44] | 1995 | n = 289 economic students | Duration: 50 min Information format: probabilities Visualization: tree diagram, inverse tree diagram, unit square |
| Chow and Van Haneghan [45] | 2016 | n = 121 university students | Duration: 15 min Information format: probabilities and frequencies Visualization: tree diagram |
| Hoffrage et al. [16] | 2015 | n = 78 medicine students | Duration: not given Information format: probabilities and frequencies Visualization: tree diagram |
| Kurzenhäuser and Hoffrage [46] | 2002 | n = 208 medicine students | Duration: 60 min Information format: natural frequencies Visualization: tree diagram |
| Ruscio [47] | 2003 | n = 113 psychology students | Duration: 45 min Information format: probabilities and frequencies Visualization: tree diagram, frequency grid, 2 × 2 table |
| Sedlmeier and Gigerenzer [48] | 2001 | n = 86 university students | Duration: 60 min Information format: probabilities and frequencies Visualization: tree diagram, frequency grid |
| Sirota et al. [49] | 2015 | n = 114 social science students | Duration: 30 min Information format: probabilities and frequencies Visualization: tree diagram, Euler diagram |
| Starns et al. [49] | 2019 | n = 174 university students | Duration: <10 min Information format: probabilities Visualization: bar visualization technique |
| Steckelberg et al. [50] | 2004 | n = 184 university students | Duration: 120 min Information format: frequencies Visualization: tree diagram, 2 × 2 table |
| Talboy and Schneider [51] | 2017 | n = 213 psychology students | Duration: <10 min Information format: frequencies Visualization: 2 × 2 table, unit square |
| Wassner [52] | 2007 | n = 127 students in school | Duration: 120 min Information format: probabilities and frequencies Visualization: tree diagram |
| Students’ Correct Responses (Among All Answers) in the Four Phases | |||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Phase | Phase 1 | Phase 2 | Phase 3 | Phase 4 | |||||||||||||
| Aspect | Performance | Covariation | Performance | Covariation | Performance | Covariation | |||||||||||
| Learning task | L1 | L2 | L3 | L3-C1 | L3-C2 | L3-C3 | L3 | L3-C1 | L3-C2 | L3-C3 | L4 | L5 | L1 | T1 | L5-C1 | L5-C2 | L5-C3 |
| Medicine | 3 (8) | 4 (8) | 5 (8) | 5 (8) | 4 (8) | 5 (8) | 7 (8) | 6 (8) | 7 (8) | 8 (8) | 7 (7) | 6 (7) | 7 (7) | 7 (7) | 7 (7) | 7 (7) | 7 (7) |
| Law | 0 (8) | 0 (8) | 3 (8) | 6 (8) | 7 (8) | 5 (8) | 6 (8) | 6 (8) | 8 (8) | 4 (8) | 4 (7) | 6 (7) | 4 (6) | 4 (6) | 6 (7) | 7 (7) | 5 (7) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Büchter, T.; Eichler, A.; Steib, N.; Binder, K.; Böcherer-Linder, K.; Krauss, S.; Vogel, M. How to Train Novices in Bayesian Reasoning. Mathematics 2022, 10, 1558. https://doi.org/10.3390/math10091558
Büchter T, Eichler A, Steib N, Binder K, Böcherer-Linder K, Krauss S, Vogel M. How to Train Novices in Bayesian Reasoning. Mathematics. 2022; 10(9):1558. https://doi.org/10.3390/math10091558
Chicago/Turabian StyleBüchter, Theresa, Andreas Eichler, Nicole Steib, Karin Binder, Katharina Böcherer-Linder, Stefan Krauss, and Markus Vogel. 2022. "How to Train Novices in Bayesian Reasoning" Mathematics 10, no. 9: 1558. https://doi.org/10.3390/math10091558
APA StyleBüchter, T., Eichler, A., Steib, N., Binder, K., Böcherer-Linder, K., Krauss, S., & Vogel, M. (2022). How to Train Novices in Bayesian Reasoning. Mathematics, 10(9), 1558. https://doi.org/10.3390/math10091558