Evaluation of Chinese Natural Language Processing System Based on Metamorphic Testing

Abstract
:1. Introduction
- We propose to apply MT to evaluate Chinese NLP systems from the perspective of users. By considering different aspects of the NLP system, we propose three categories of MRPs, and then define seven MRs under these MRPs. According to the characteristics of each task, each MR is concretized to evaluate the quality of different NLP systems;
- We conduct experiments on three common NLP systems (Baidu, Ali, Tencent) and demonstrate the feasibility and effectiveness of MT in evaluating NLP systems;
- We conduct a comparative analysis of NLP systems, revealing their capabilities and demonstrating how the results of the analysis can help users choose the appropriate NLP system according to their specific needs.
2. Metamorphic Testing
2.1. Definition of MRs
2.2. Metamorphic Relation Pattern
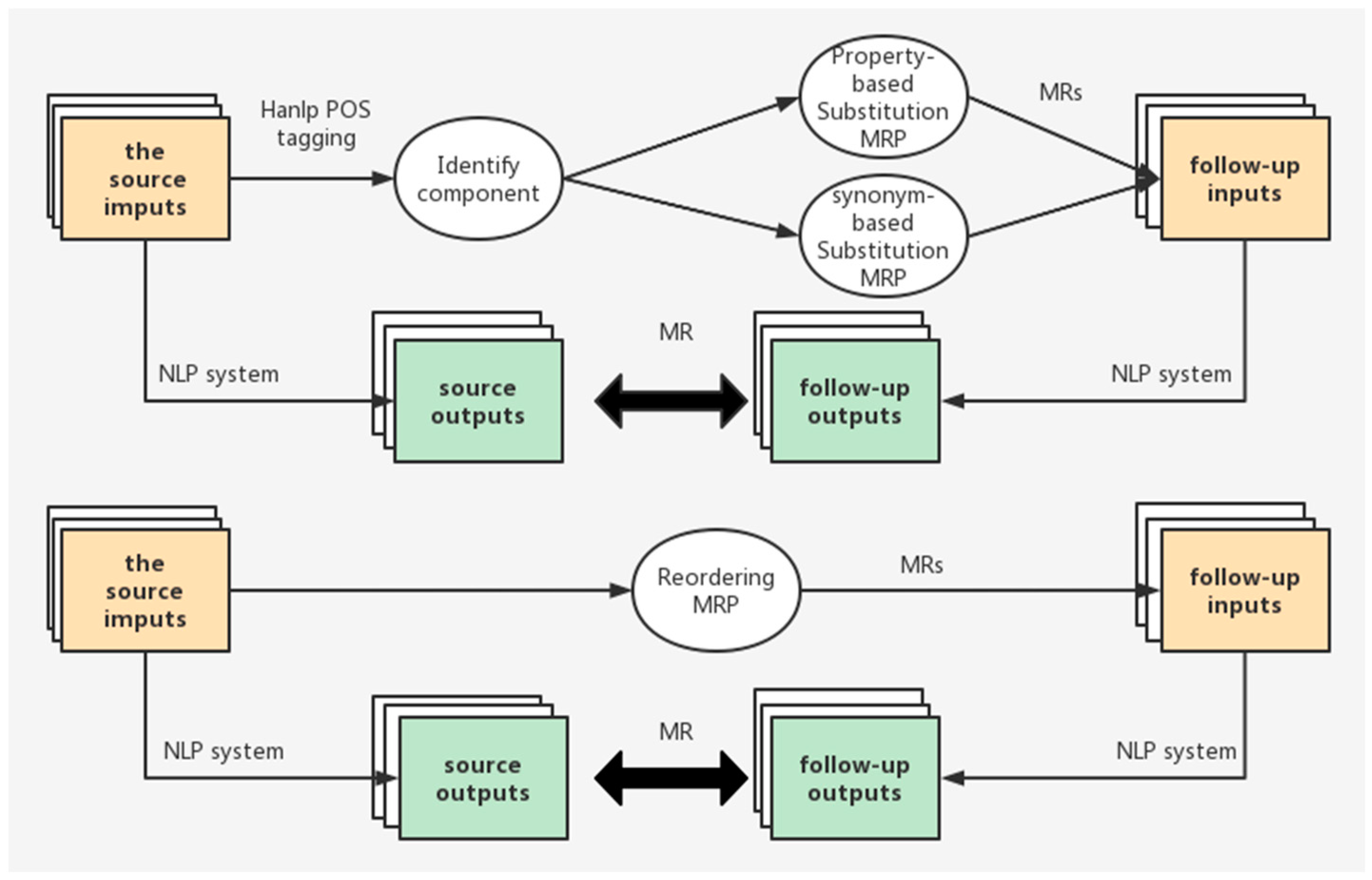
3. Our Approach
3.1. MRPs for NLP
3.1.1. Property-Based Substitution MRP (MRPpbs)
- Ts represents the given source text, X1 is the replaced word, X2 is the replaced word, and Tf is the follow-up text generated by replacing X1 with X2 in the text Ts.
- Set the source input as Is, the follow-up input as If. Different MRPs alter Is in different ways to construct If and also encode the relationship that is expected to be satisfied by Os and Of. Based on the analysis of the system and the expectations of users, we have defined four MRPpbss, which can be described in detail according to the specific tasks as follows:
- MRPpbs1:
- Replace name or pronoun of Is to generate a follow-up input In, that is, If = Replacename1→name2(Is). Then, Os and Of should be consistent.
- MRPpbs2:
- Replace country of Is to generate a follow-up input In, that is, If = Replacecountry1->country2(Is). Then, Os and Of should be consistent.
- MRPpbs3:
- Replace occupation of Is to generate a follow-up input In, that is, If = Replaceoccupation1->occupation2(Is). Then, Os and Of should be consistent.
- MRPpbs4:
- Replace punctuation of Is to generate a follow-up input In, that is, If = Replacepunctuation1->punctuation2(Is). Then, Os and Of should be consistent.
3.1.2. Synonym-Based Substitution MRP (MRPsbs)
- MRPsbs5:
- Replace nouns with synonyms of Is to generate a follow-up input In, that is, If = Replacenoun1->noun2(Is). Then, Os and Of should be consistent.
- MRPsbs6:
- Replace verbs with synonyms of Is to generate a follow-up input In, that is, If = Replaceverb1->verb2(Is). Then, Os and Of should be consistent.
3.1.3. Reordering MRP (MRPr)
- MRPr7:
- Change the order of sentences of Is to generate the follow-up input If, then Os and Of should be consistent.
4. Metamorphic Relations for Specific NLP Tasks
4.1. Text Similarity
- MR1.1–MR4.1:
- Replace the words X1 in (S1, S2) to X2 with the same property to generate follow-up inputs (Sf1, Sf2), that is, (Sf1, Sf2) = ReplaceX1->X2(S1, S2). Then, sim (S1, S2) and sim (Sf1, Sf2) should meet: sim (S1, S2) ∈ C and sim (Sf1, Sf2) ∈ C, C is an arbitrary interval.
- MR5.1–MR6.1:
- Replace the words X1 in S (S1, S2) to synonyms X2 to generate follow-up inputs (Sf1, Sf2), that is, (Sf1, Sf2) = ReplaceX1->X2(S1, S2). Then, sim (S1, S2) and sim (Sf1, Sf2) should meet: sim (S1, S2) ∈ C and sim (Sf1, Sf2) ∈ C, C is an arbitrary interval.
- MR7.1:
- Sim (S1, S2) and sim (S2, S1) should satisfy: sim (S1, S2) ∈ C and sim (S2, S1) ∈ C, C is an arbitrary interval.
4.2. Text Summarization
- MR1.2–4.2:
- Replace X1 in Ts to X2 with the same property to generate a follow-up input Tf, that is, Tf = ReplaceX1->X2(Ts). Then, sum (Ts) and sum (Tf) should satisfy: sum (Ts) = ReplaceX1->X2(sum (Tf)).
- MR5.2–6.2:
- Replace X1 in Ts to synonyms X2 to generate a follow-up input Tf, that is, Tf = ReplaceX1->X2(Ts). Then, sum (Ts) and sum (Tf) should satisfy: sum (Ts) = ReplaceX1->X2(sum (Tf)).
- MR7.2:
- Change the order of sentences to generate follow-up input Tf, and then sum (Ts) and sum (Tf) should satisfy: sum (Ts) = sum (Tf).
4.3. Text Classification
- MR1.3–4.3:
- Replace X1 in Ts to X2 with the same property word to generate follow-up input Tf, that is, Tf = ReplaceX1->X2(Ts). Then, Ls and Lf should satisfy: Ls = Lf.
- MR5.3–6.3:
- Replace X1 in Ts to synonyms X2 to generate follow-up input Tf, that is, Tf = ReplaceX1->X2(Ts). Then, Ls and Lf should satisfy: Ls = Lf.
- MR7.3:
- Change the order of sentences in the text to generate follow-up input Tf. Then, Ls and Lf should satisfy: Ls = Lf.
5. Experimental Setup
- RQ1:
- Are the MRs defined in this study are effective for evaluating the target NLP systems?
- RQ2:
- Can the MRP and its MRs that we define effectively reflect the advantages and disadvantages of the SUTs?
- RQ3:
- What are the common problems of the SUTs under different MRP and their MRs?
5.1. Realization of MRs
5.2. Target Systems
5.3. Datasets
6. Results and Analysis
6.1. RQ1: Effectiveness of MT and MRs
6.1.1. Text Similarity
6.1.2. Text Summarization
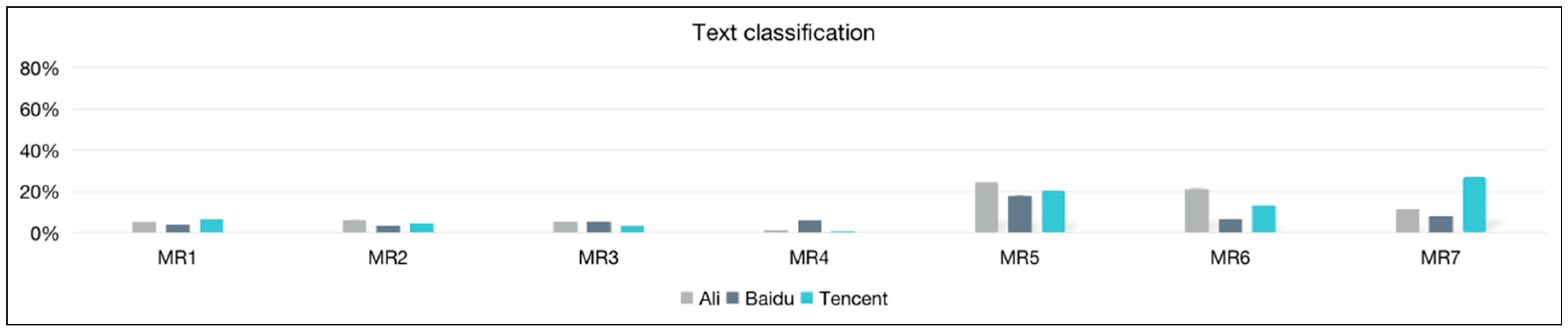
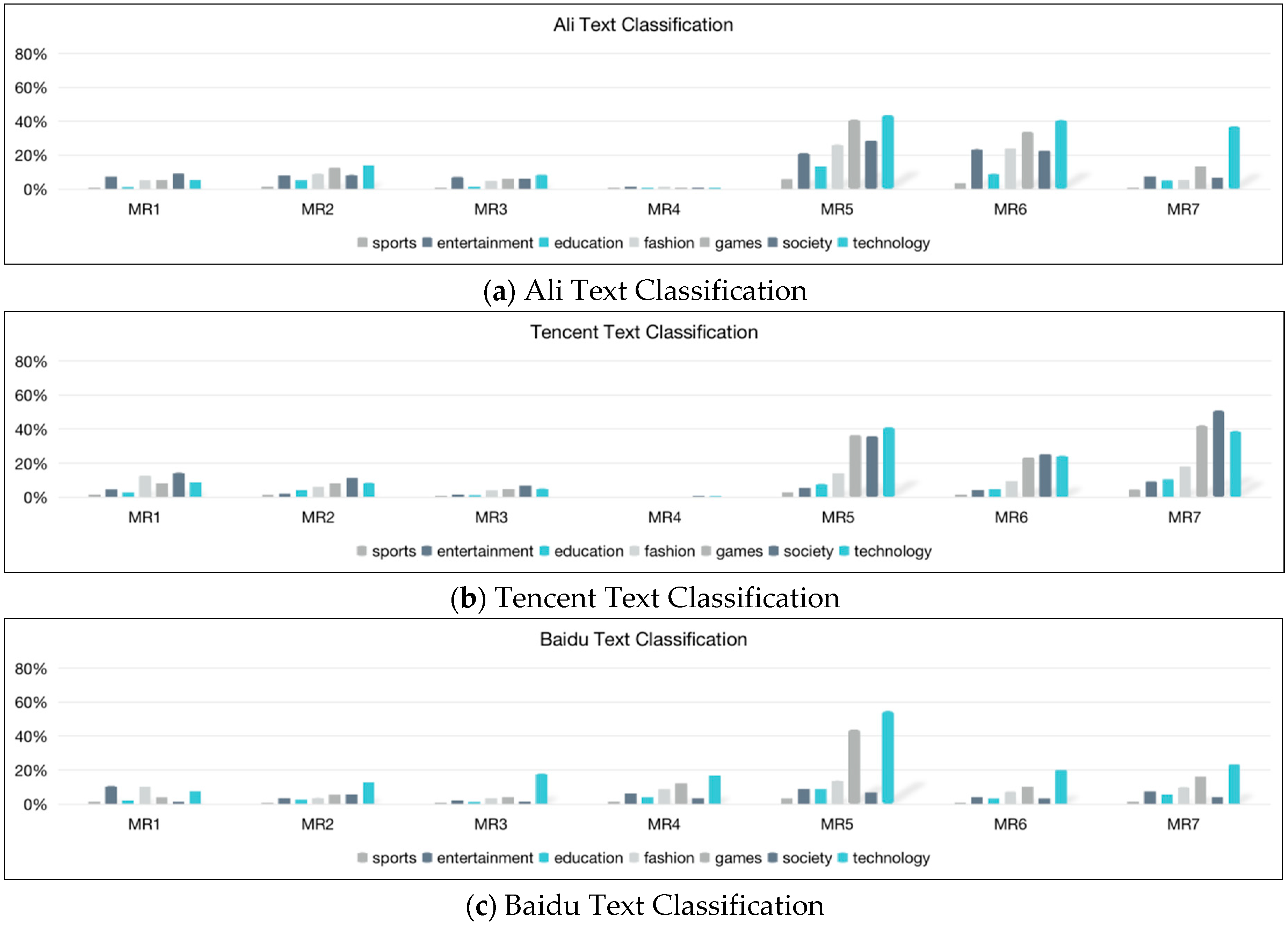
6.1.3. Text Classification
6.1.4. Conclusions
6.2. RQ2: Advantages and Disadvantages of the SUTs
6.2.1. Text Similarity
6.2.2. Text Summarization
6.2.3. Text Classification
6.2.4. Conclusions
6.3. RQ3: Common Problems of the SUTs
6.4. Comparison Results
7. Related Work
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Gomaa, W.H.; Fahmy, A.A. A Survey of Text Similarity Approaches. Int. J. Comput. Appl. 2013, 68, 13–18. [Google Scholar]
- Gambhir, M.; Gupta, V. Recent automatic text summarization techniques: A survey. Artif. Intell. Rev. 2016, 47, 1–66. [Google Scholar] [CrossRef]
- Kowsari, K.; Jafari Meimandi, K.; Heidarysafa, M.; Mendu, S.; Barnes, L.; Brown, D. Text classification algorithms: A survey. Information 2019, 10, 150. [Google Scholar] [CrossRef] [Green Version]
- Islam, A.; Inkpen, D. Semantic text similarity using corpus-based word similarity and string similarity. ACM Trans. Knowl. Discov. Data 2008, 2, 1–25. [Google Scholar] [CrossRef]
- Nitish, A.; Kartik, A.; Paul, B. DERI&UPM: Pushing Corpus Based Relatedness to Similarity: Shared Task System Description. In Proceedings of the First Joint Conference on Lexical and Computational Semantics (*SEM), Montreal, QC, Canada, 7–8 June 2012; pp. 643–647. [Google Scholar]
- Lin, C.-Y. Rouge: A package for automatic evaluation of summaries. In Proceedings of the Workshop on Text Summarization Branches Out, Post-Conference Workshop of ACL, Barcelona, Spain, 25 July 2004. [Google Scholar]
- Denkowski, M.; Lavie, A. Meteor universal: Language specific translation evaluation for any target language. In Proceedings of the Ninth Workshop on Statistical Machine Translation, Baltimore, MD, USA, 26–27 June 2014; pp. 376–380. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.-J. Bleu: A method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 7–12 July 2002; pp. 311–318. [Google Scholar]
- Han, M.; Zhang, X.; Yuan, X.; Jiang, J.; Yun, W.; Gao, C. A survey on the techniques, applications, and performance of short text semantic similarity. Concurr. Comput. Pract. Exp. 2020, 33, e5971. [Google Scholar] [CrossRef]
- Ruan, H.; Li, Y.; Wang, Q.; Liu, Y. A research on sentence similarity for question answering system based on multi-feature fusion. In Proceedings of the 2016 IEEE/WIC/ACM International Conference on Web Intelligence (WI), Omaha, NE, USA, 13–16 October 2016; pp. 507–510. [Google Scholar]
- Fan, A.; Grangier, D.; Auli, M. Controllable abstractive summarization. arXiv 2017, arXiv:1711.05217. [Google Scholar]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.R.; Le, Q.V. Xlnet: Generalized autoregressive pretraining for language understanding. Adv. Neural Inf. Process. Syst. 2019, 32, 5754–5764. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Yang, Y.; Zhang, Y.; Tar, C.; Baldridge, J. PAWS-x: A cross-lingual adversarial dataset for paraphrase identification. arXiv 2019, arXiv:1908.11828. [Google Scholar]
- Hu, B.; Chen, Q.; Zhu, F. LCSTS: A large scale chinese short text summarization dataset. arXiv 2015, arXiv:1506.05865. [Google Scholar]
- Sun, M.; Li, J.; Guo, Z.; Yu, Z.; Zheng, Y.; Si, X.; Liu, Z. Thuctc: An Efficient Chinese Text Classifier. GitHub Repos. 2016. Available online: https://github.com/diuzi/THUCTC (accessed on 1 August 2021).
- Li, J.; Du, T.; Ji, S.; Zhang, R.; Lu, Q.; Yang, M.; Wang, T. TextShield: Robust Text Classification Based on Multimodal Embedding and Neural Machine Translation. In Proceedings of the 29th USENIX Security Symposium, San Diego, CA, USA, 12–14 August 2020; pp. 1381–1398. [Google Scholar]
- Segura, S.; Fraser, G.; Sanchez, A.B.; Ruiz-Cortés, A. A survey on metamorphic testing. IEEE Trans. Softw. Eng. 2016, 42, 805–824. [Google Scholar] [CrossRef] [Green Version]
- Deng, Y.; Zheng, X.; Zhang, T.; Lou, G.; Liu, H.; Kim, M. RMT: Rule-based metamorphic testing for autonomous driving models. arXiv 2012, arXiv:2012.10672. [Google Scholar]
- Cao, Y.; Zhou, Z.Q.; Chen, T.Y. On the correlation between the effectiveness of metamorphic relations and dissimilarities of test case executions. In Proceedings of the 2013 13th International Conference on Quality Software, Najing, China, 29–30 July 2013; pp. 153–162. [Google Scholar]
- Zhou, Z.Q. Using coverage information to guide test case selection in adaptive random testing. In Proceedings of the 2010 IEEE 34th Annual Computer Software and Applications Conference Workshops, Seoul, Korea, 19–23 July 2010; pp. 208–213. [Google Scholar]
- Barus, A.C.; Chen, T.Y.; Grant, D.; Kuo, F.C.; Lau, M.F. Testing of heuristic methods: A case study of greedy algorithm. In Software Engineering Techniques; Huzar, Z., Koci, R., Meyer, B., Walter, B., Zendulka, J., Eds.; Springer: Berlin, Germany, 2011; Volume 4980, pp. 246–260. [Google Scholar]
- Chen, T.Y.; Kuo, F.C.; Liu, H.; Wang, S. Conformance testing of network simulators based on metamorphic testing technique. In Formal Techniques for Distributed Systems; Lee, D., Lopes, A., Poetzsch-Heffter, A., Eds.; Springer: Berlin, Germany, 2009; Volume 5522, pp. 243–248. [Google Scholar]
- Zhou, Z.Q.; Xiang, S.; Chen, T.Y. Metamorphic testing for software quality assessment: A study of search engines. IEEE Trans. Softw. Eng. 2016, 42, 264–284. [Google Scholar] [CrossRef]
- Zhou, Z.Q.; Sun, L.; Chen, T.Y.; Towey, D. Metamorphic Relations for Enhancing System Understanding and Use. IEEE Trans. Softw. Eng. 2020, 46, 1120–1154. [Google Scholar] [CrossRef] [Green Version]
- Available online: https://cloud.baidu.com/product/nlp_basic (accessed on 1 August 2021).
- Available online: https://cloud.tencent.com/product/nlp (accessed on 1 August 2021).
- Available online: https://ai.aliyun.com/nlp (accessed on 1 August 2021).
- Barr, E.T.; Harman, M.; McMinn, P.; Shahbaz, M.; Yoo, S. The Oracle Problem in Software Testing: A Survey. IEEE Trans. Softw. Eng. 2015, 41, 507–525. [Google Scholar] [CrossRef]
- Chen, T.Y.; Kuo, F.C.; Liu, H.; Poon, P.L.; Towey, D.; Tse, T.H.; Zhou, Z.Q. Metamorphic Testing: A Review of Challenges and Opportunities. ACM Comput. Surv. 2018, 51, 1–27. [Google Scholar] [CrossRef] [Green Version]
- Zhou, Z.Q.; Tse, T.H.; Kuo, F.C.; Chen, T.Y. Automated Functional Testing of Web Search Engines in the Absence of an Oracle; Technical Report TR-2007–06; Department of Computer Science, The University of Hong Kong: Hong Kong, China, 2007. [Google Scholar]
- Segura, S.; Parejo, J.A.; Troya, J.; Ruiz-Cortés, A. Metamorphic testing of RESTful web APIs. IEEE Trans. Softw. Eng. 2018, 44, 1083–1099. [Google Scholar] [CrossRef]
- Mihalcea, R.; Tarau, P. TextRank: Bringing Order into Texts. In Proceedings of the EMNLP, Barcelona, Spain, 1 January 2004; p. 85. [Google Scholar]
- He, H.; Choi, J.D. The Stem Cell Hypothesis: Dilemma behind Multi-Task Learning with Transformer Encoders. 2021. Available online: https://arxiv.org/abs/2109.06939 (accessed on 1 August 2021).
- Louizos, C.; Welling, M.; Kingma, D.P. Learning Sparse Neural Networks through L0 Regularization. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April 30–3 May 2018. [Google Scholar]
- Wang, H.L.; Xi, H.Y. Synonyms:Chinese Synonyms for Natural Language Processing and Understanding. Available online: https://github.com/chatopera/Synonyms (accessed on 1 August 2021).
- Bao, W.; Bao, W.; Du, J.; Yang, Y.; Zhao, X. Attentive siamese lstm network for semantic textual similarity measure. In Proceedings of the 2018 International Conference on Asian Language Processing (IALP), Bandung, Indonesia, 15–17 November 2018; pp. 312–317. [Google Scholar]
- Bouziane, A.; Bouchiha, D.; Doumi, N.; Malki, M. Question Answering Systems: Survey and Trends. Procedia Comput. Sci. 2015, 73, 366–375. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.C.; Xiong, D.Y.; Zhang, M. A survey of neural machine translation. Chin. J. Comput. 2018, 41, 100–121. [Google Scholar]
- Zhan, G.; Wang, M.; Zhan, M. Public opinion detection in an online lending forum: Sentiment analysis and data visualization. In Proceedings of the 2020 IEEE 5th International Conference on Cloud Computing and Big Data Analytics (ICCCBDA), Chengdu, China, 10–13 April 2020; pp. 211–213. [Google Scholar]
- Bagui, S.; Nandi, D.; Bagui, S.; White, R.J. Classifying phishing email using machine learning and deep learning. In Proceedings of the 2019 International Conference on Cyber Security and Protection of Digital Services (Cyber Security), Oxford, UK, 3–4 June 2019; pp. 1–2. [Google Scholar]
- Asyrofi, M.H.; Yang, Z.; Yusuf, I.N.; Kang, H.J.; Thung, F.; Lo, D. BiasFinder: Metamorphic Test Generation to Uncover Bias for Sentiment Analysis Systems. IEEE Trans. Softw. Eng. 2021. [Google Scholar] [CrossRef]
- Available online: https://www.idc.com/getdoc.jsp?containerId=prCHC47212020 (accessed on 1 August 2021).
- Peyrard, M.; Eckle-Kohler, J. Supervised learning of automatic pyramid for optimization-based multi-document summarization. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, BC, Canada, 30 July–4 August 2017; pp. 1084–1094. [Google Scholar]
- Abdi, A.; Shamsuddin, S.M.; Hasan, S.; Piran, J. Machine learning-based multi-documents sentiment-oriented summarization using linguistic treatment. Expert Syst. Appl. 2018, 109, 66–85. [Google Scholar] [CrossRef]
- Wallace, E.; Feng, S.; Kandpal, N.; Gardner, M.; Singh, S. Universal Adversarial Triggers for Attacking and Analyzing NLP. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 2153–2162. [Google Scholar]
- Shehu, H.A.; Sharif, M.H.; Sharif, M.H.; Datta, R.; Tokat, S.; Uyaver, S.; Kusetogullari, H.; Ramadan, R.A. Deep Sentiment Analysis: A Case Study on Stemmed Turkish Twitter Data. IEEE Access 2021, 9, 56836–56854. [Google Scholar] [CrossRef]
- Kim, H. Fine-Grained Named Entity Recognition Using a Multi-Stacked Feature Fusion and Dual-Stacked Output in Korean. Appl. Sci. 2021, 11, 10795. [Google Scholar] [CrossRef]
- Chen, X.; Gao, S.; Tao, C.; Song, Y.; Zhao, D.; Yan, R. Iterative document representation learning towards summarization with polishing. arXiv 2019, arXiv:1809.10324. [Google Scholar]
- Schapire, R.E.; Singer, Y. BoosTexter: A boosting-based system for text categorization. Mach. Learn. 2000, 39, 135–168. [Google Scholar] [CrossRef] [Green Version]
- Qin, P.; Tan, W.; Guo, J.; Shen, B.; Tang, Q. Achieving Semantic Consistency for Multilingual Sentence Representation Using an Explainable Machine Natural Language Parser (MParser). Appl. Sci. 2021, 11, 11699. [Google Scholar] [CrossRef]
- Zhou, Q.; Wu, X.; Zhang, S.; Kang, B.; Ge, Z.; Latecki, L.J. Contextual ensemble network for semantic segmentation. Pattern Recognit. 2022, 122, 108290. [Google Scholar] [CrossRef]
- Hao, S.; Zhou, Y.; Guo, Y. A Brief Survey on Semantic Segmentation with Deep Learning. Neurocomputing 2020, 406, 302–321. [Google Scholar] [CrossRef]
- Lateef, F.; Ruichek, Y. Survey on Semantic Segmentation using Deep Learning Techniques. Neurocomputing 2019, 338, 321–348. [Google Scholar] [CrossRef]
- Erenel, Z.; Adegboye, O.R.; Kusetogullari, H. A New Feature Selection Scheme for Emotion Recognition from Text. Appl. Sci. 2020, 10, 5351. [Google Scholar] [CrossRef]
- Wang, J.; Mao, H.; Li, H. FMFN: Fine-Grained Multimodal Fusion Networks for Fake News Detection. Appl. Sci. 2022, 12, 1093. [Google Scholar] [CrossRef]
- Jiang, K.; Lu, X. Natural Language Processing and Its Applications in Machine Translation: A Diachronic Review. In Proceedings of the 2020 IEEE 3rd International Conference of Safe Production and Informatization (IICSPI), Chongqing, China, 28–30 November 2020; pp. 210–214. [Google Scholar] [CrossRef]
- Schapire, R.E.; Singer, Y. Improved boosting algorithms using confidence-rated predictions. Mach. Learn. 1999, 37, 297–336. [Google Scholar] [CrossRef] [Green Version]
- Manning, C.D.; Raghavan, P.; Schütze, H. Introduction to Information Retrieval; Cambridge University Press: Cambridge, UK, 2008. [Google Scholar]
- Zhang, W.E.; Sheng, Q.Z.; Alhazmi, A.; Li, C. Adversarial Attacks on Deep Learning Models in Natural Language Processing: A Survey. ACM Trans. Intell. Syst. Technol. 2019, 11, 1–41. [Google Scholar] [CrossRef] [Green Version]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. Semantically Equivalent Adversarial Rules for Debugging NLP models. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Vol 1), Melbourne, Australia, 15–20 July 2018. [Google Scholar]
- Pesu, D.; Zhou, Z.Q.; Zhen, J.F. Dave Towey: A Monte Carlo method for metamorphic testing of machine translation services. In Proceedings of the 2018 IEEE/ACM 3rd International Workshop on Metamorphic Testing (MET), Gothenburg, Sweden, 27 May–3 June 2018; pp. 38–45. [Google Scholar]
- Zhou, Z.Q.; Sun, L.Q. Metamorphic testing for machine translations: MT4MT. In Proceedings of the 2018 25th Australasian Software Engineering Conference (ASWEC), Adelaide, SA, Australia, 26–30 November 2018; pp. 96–100. [Google Scholar]
- Tu, K.; Jiang, M.; Ding, Z. A metamorphic testing approach for assessing question answering systems. Mathematics 2021, 9, 726. [Google Scholar] [CrossRef]
- Zhong, W.K.; Ge, J.D.; Chen, X.; Li, C.Y.; Tang, Z.; Luo, B. Multi-Granularity Metamorphic Testing for Neural Machine Translation System. Ruan Jian Xue Bao/J. Softw. 2021, 32, 1051–1066. Available online: http://www.jos.org.cn/1000-9825/6221.htm (accessed on 1 August 2021). (In Chinese).
- Yuan, Y.; Wang, S.; Jiang, M. Tsong Yueh Chen: Perception Matters: Detecting Perception Failures of VQA Models Using Metamorphic Testing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 16908–16917. [Google Scholar]
- Segura, S.; Durán, A.; Troya, J.; Ruiz-Cortés, A. Metamorphic Relation Patterns for Query-Based Systems. In Proceedings of the 2019 IEEE/ACM 4th International Workshop on Metamorphic Testing (MET), Montreal, QC, Canada, 26 May 2019; pp. 24–31. [Google Scholar] [CrossRef]
- Wu, C.; Sun, L.; Zhou, Z.Q. The Impact of a Dot: Case Studies of a Noise Metamorphic Relation Pattern. In Proceedings of the IEEE/ACM 4th International Workshop on Metamorphic Testing ACM, Montreal, QC, Canada, 26 May 2019; pp. 17–23. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input 1: 在数学天文学领域, 他的声誉归功于天文球体的提出, 以及他对理解行星运动的早期贡献。 (In the field of mathematical astronomy, he is credited with the creation of the astronomical sphere and his early contributions to understanding the motion of planets.) |
| Input 2: 他在数学天文学方面享有盛誉是因为他引入了天文地球仪, 并对理解行星运动作出了早期贡献。 (He is credited with mathematical astronomy for his introduction of the astronomical globe and for his early contributions to the understanding of planetary motion.) |
| Output: 0.74384534 |
| MRs | Interpretation of MR Violation | Examples |
|---|---|---|
| MR1.1–MR4.1 | NLP system is sensitive to the same property words in regular rules. | S1: “小明有一个苹果。” S2: “小明有一个梨。” (S1: “Xiaoming has an apple.” S2: “Xiaoming has a pear.”) Sn1: “小红有一个苹果。” Sn2: “小红有一个梨。”(S1: “Xiaohong has an apple.” S2: “Xiaohong has a pear.”) sim (S1, S2) = 0.723585 sim (Sn1, Sn2) = 0.776188 |
| MR5.1–MR6.1 | NLP system is sensitive to similar words in regular rules. | S1: “老师今天表扬了小明。” S2: “同学们今天表扬了小明。” (S1: “The teacher praised Xiao Ming today.” S2: “The students praised Xiaoming today.”) Sn1: “老师今天夸赞了小明。” Sn2:“同学们今天夸赞了小明。” (Sn1: “The teacher speak highly of Xiaoming today.” Sn2: “The students speak highly of Xiaoming today.”) sim (S1, S2) = 0.842097 sim (Sn1, Sn2) = 0.828796 |
| MR7.1 | NLP system is sensitive to the input sequence. | S1: “小明有一个苹果。” S2: “小明有一个梨。” (S1: “Xiaoming has an apple.” S2: “Xiaoming has a pear.”) Sn1: “小明有一个梨。” Sn2: “小明有一个苹果。” (S1: “Xiaoming has a pear.” S2: “Xiaoming has an apple.”) sim (S1, S2) = 0.723585 sim (Sn1, Sn2) = 0.723585 |
| Input: 前天, 上海有网友发现, 马路上竟有几辆正在行驶的碰碰车。原来, 开碰碰车的是附近游乐场员工, 主要为免去运输烦恼。警方则表示目前正在查证, 但碰碰车绝不能上路。网友纷纷表示, 这就是跑跑卡丁车现实版! (The day before yesterday, a netizen in Shanghai found that there were several bumper cars running on the road. It turned out that the bumper car was driven by the employees of the nearby amusement park, mainly to avoid transportation troubles. The police said they were checking, but the bumper car must not be on the road. Netizens have said that this is the reality version of the go kart!) |
| Output: 上海有网友发现, 马路上竟有几辆正在行驶的碰碰车。开碰碰车的是附近游乐场员工。 (Some netizens in Shanghai found that there were several bumper cars running on the road. The bumper car is driven by the staff of the nearby amusement park.) |
| Input (ORI): “月光女神”英国歌手莎拉•布莱曼近日则表示, 9月1日她将乘坐俄“联盟”号飞船进入国际空间站, 并停留10天。她希望在空间站与地球上的小朋友进行“零时差”合唱。为了实现上太空的梦想, 55岁的她每天要进行16个小时身体训练, 还要进行心理辅导。(British singer Sarah Brightman said recently that she would enter the international space station on September 1 in a Russian Soyuz spacecraft and stay for 10 days. She hopes to sing “zero time difference” with children on earth on the space station. In order to realize her dream of going to space, the 55 year old has to carry out 16 h of physical training and psychological counseling every day.) Output (ORI): 英国歌手莎拉•布莱曼近日则表示“飞船国际空间站”她在空间站与地球上的小朋友进行合唱。(British singer Sarah Brightman said recently that she sang with children on earth on the “spaceship International Space Station”.) |
| Input (FLU): “月光女神”英国歌手莎拉•布莱曼近日则表示, 9月1日她将乘坐俄“联盟”号飞船进入国际空间站, 并停留10天。为了实现上太空的梦想, 55岁的她每天要进行16个小时身体训练, 还要进行心理辅导。她希望在空间站与地球上的小朋友进行“零时差”合唱。(British singer Sarah Brightman said recently that she would enter the international space station on September 1 in a Russian Soyuz spacecraft and stay for 10 days. In order to realize her dream of going to space, the 55 year old has to carry out 16 h of physical training and psychological counseling every day. She hopes to sing “zero time difference” with children on earth on the space station.) Output (FLU): 英国歌手莎拉•布莱曼近日则表示“飞船国际空间站”她在空间站与地球上的小朋友进行合唱。(British singer Sarah Brightman said recently that she sang with children on earth on the “spaceship International Space Station”.) |
| Input: 特派记者郑菁埃因霍温报道 2月7日晚, PSV埃因霍温俱乐部官方网站宣布, 球队已经签下中国球员周海滨, 他将于9日正式开始随队训练。 周海滨与俱乐部签署的是一份为期1年的合同……一旦周海滨出现伤病情况, 埃因霍温方面必须一直负责到他能正式恢复踢球为止。(Special correspondent Zheng Jing and PSV Eindhoven reported that on the evening of February 7, the official website of PSV Eindhoven club announced that the team had signed Chinese player Zhou Haibin, who will officially start training with the team on the 9th. Zhou Haibin signed a one-year contract with the club... In case of injury, PSV Eindhoven must be responsible until he can officially resume playing football.) |
| Output: 体育 (sports) |
| Input (ORI): 日前, 由张黎执导的电视剧《圣天门口》正在横店热拍, 在片中出演重要女性角色麦香的则是青年演员练束梅。 练束梅在由张黎执导的《人间正道是沧桑》中曾有过短暂的亮相……练束梅称, 麦香这个角色必须用真心的把自己放进去, 因为离自己太远所以要抛开生活中的自己全心投入其中。 (Recently, the TV series “holy gate” directed by Zhang Li is hot shooting in Hengdian. The young actor Lian Shumei plays the important female role Mai Xiang in the film. Lian Shumei once made a brief appearance in “the right way in the world is the vicissitudes” directed by Zhang Li... Lian Shumei said that the role of Mai Xiang must put herself in with sincerity, because she is too far away from herself, so she should abandon herself in life and devote herself to it.) Output (ORI): 娱乐(entertainment) |
| Input (FLU): 日前, 由张黎执导的电视剧《圣天门口》正在横店热拍, 在片中出演重要女性角色麦香的则是青年演员白露。 白露在由张黎执导的《人间正道是沧桑》中曾有过短暂的亮相……白露称, 麦香这个角色必须用真心的把自己放进去, 因为离自己太远所以要抛开生活中的自己全心投入其中。 (Recently, the TV series “holy gate” directed by Zhang Li is hot shooting in Hengdian. The young actor Bai Lu plays the important female role Mai Xiang in the film. Bai Lu once made a brief appearance in “the right way in the world is the vicissitudes” directed by Zhang Li... Bai Lu said that the role of Mai Xiang must put herself in with sincerity, because she is too far away from herself, so she should abandon herself in life and devote herself to it.) Output (FLU): 娱乐(entertainment) |
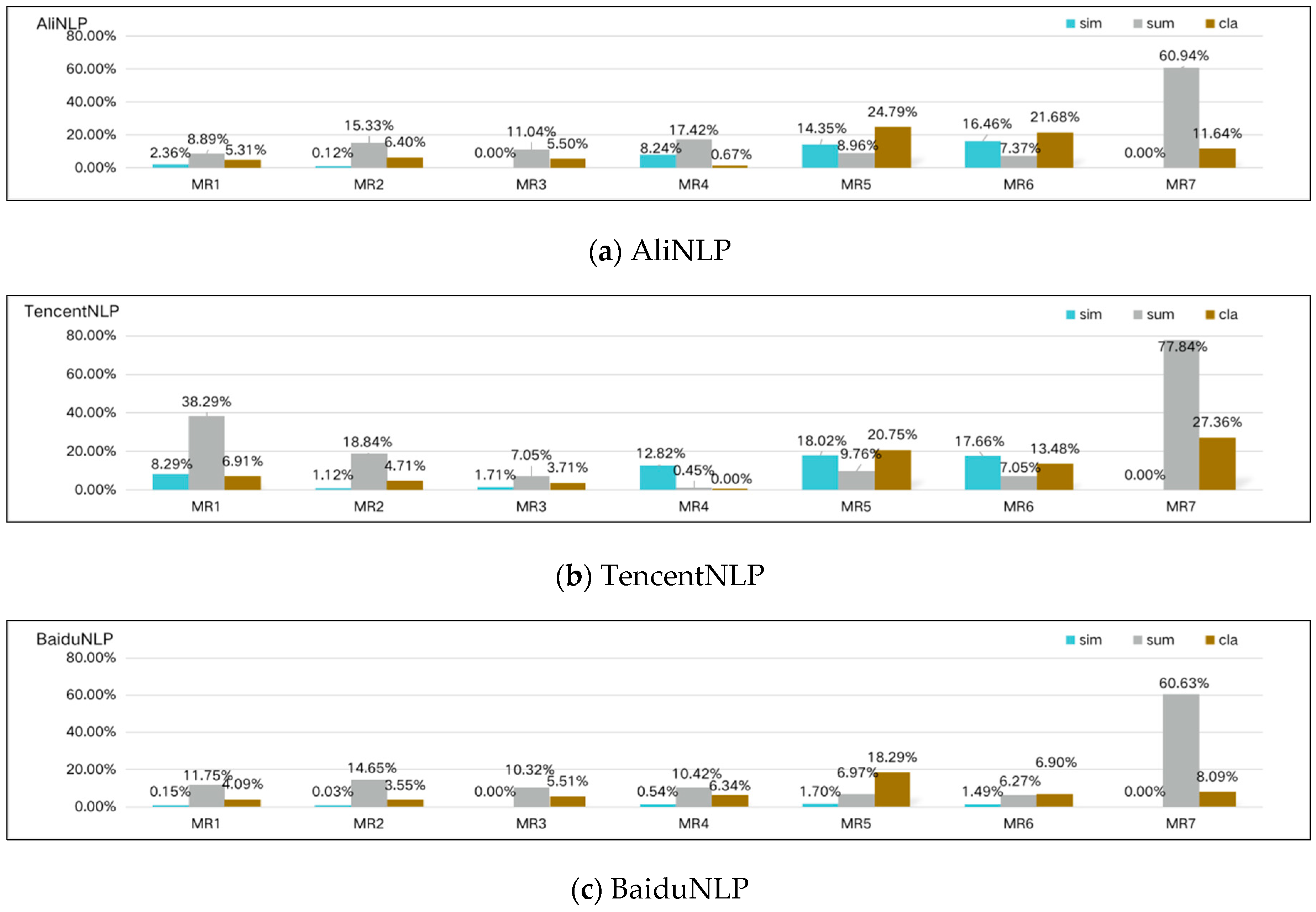
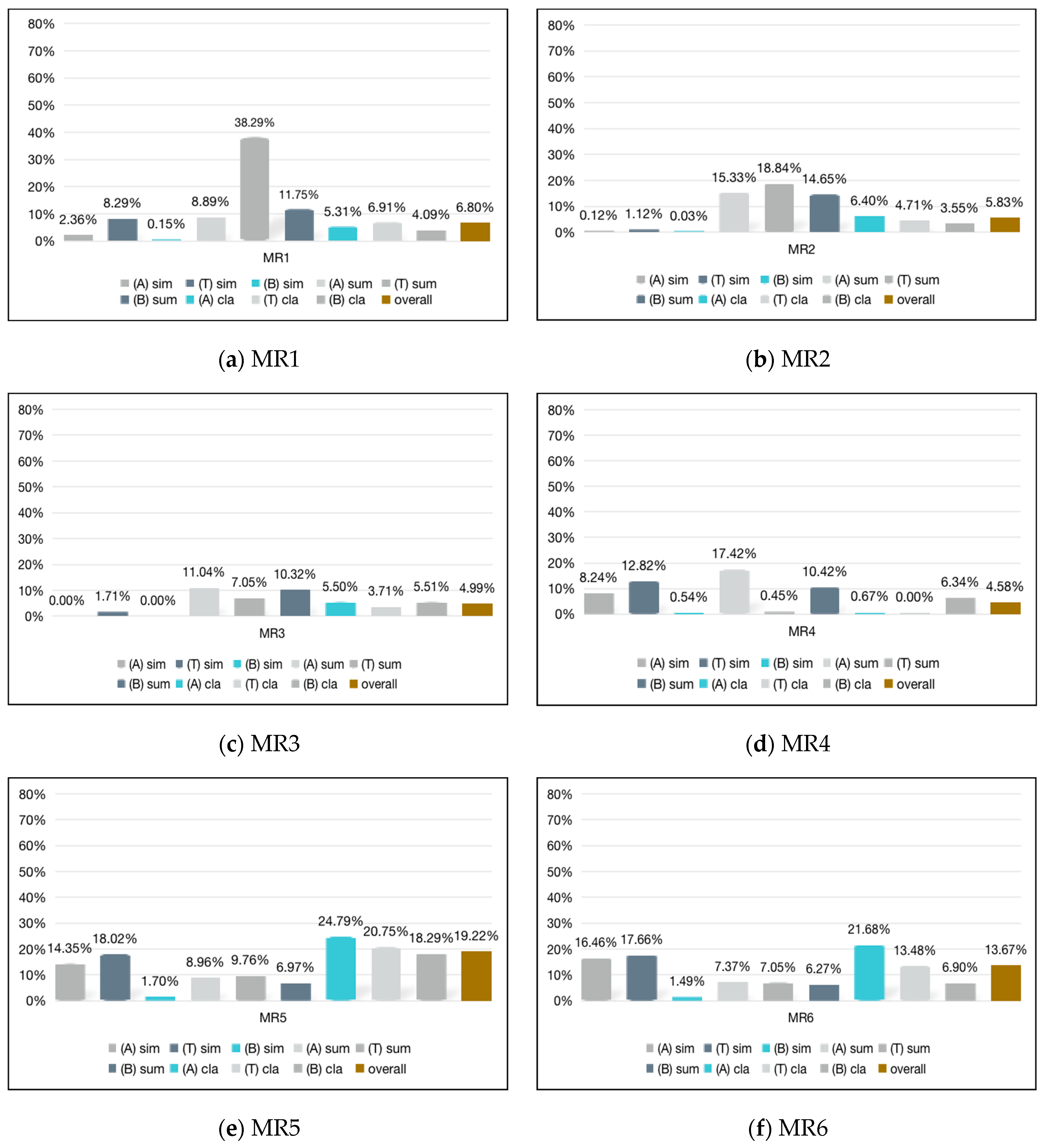
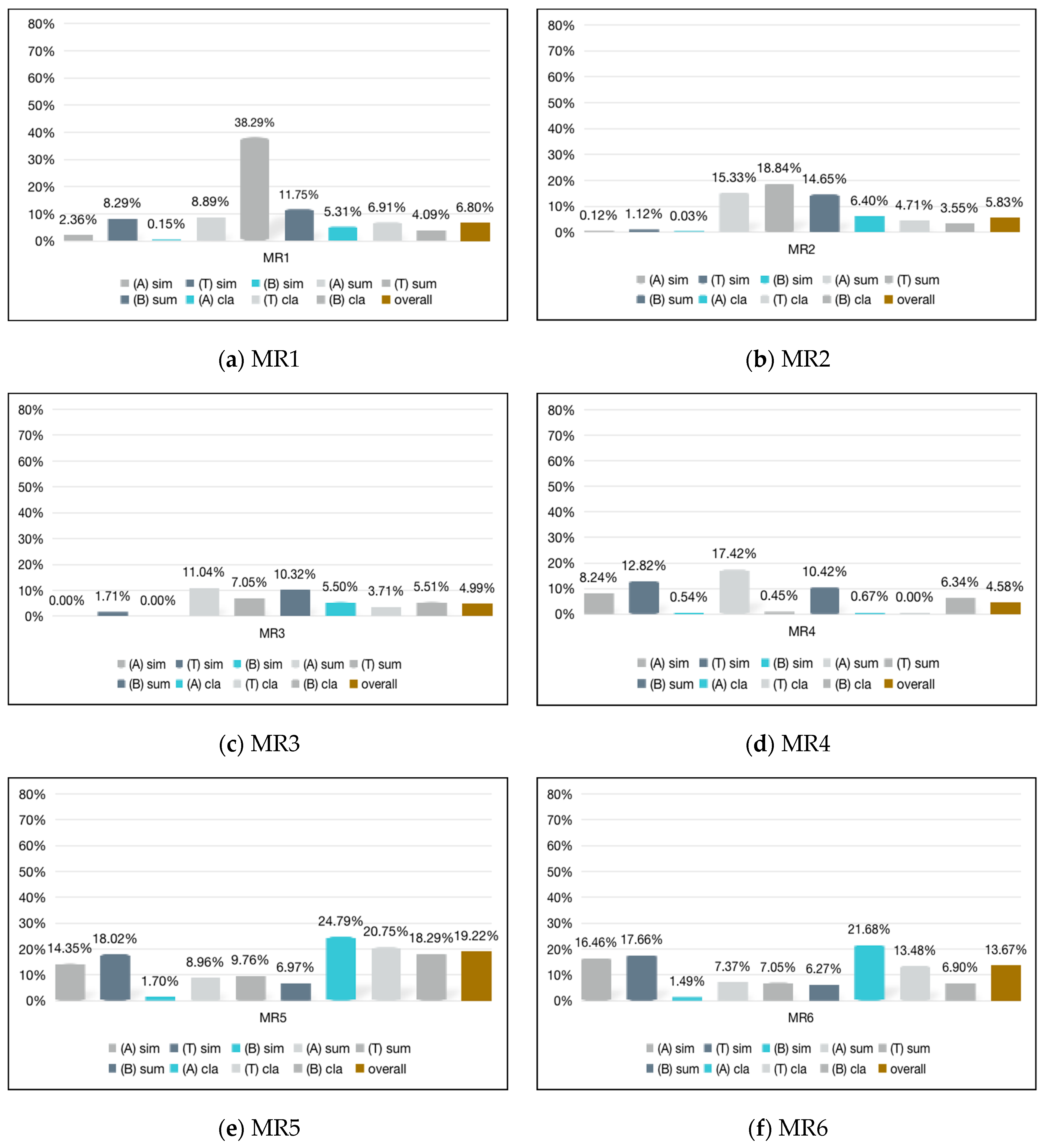
| VR (%) | MR1.1 | MR2.1 | MR3.1 | MR4.1 | MR5.1 | MR6.1 | MR7.1 |
|---|---|---|---|---|---|---|---|
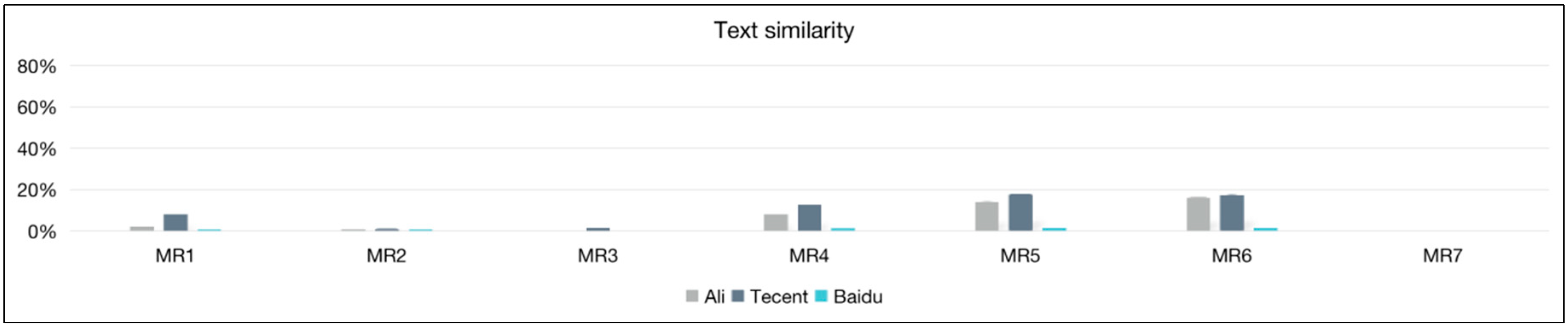
| Ali | 2.36 | 0.12 | 0.00 | 8.24 | 14.35 | 16.46 | 0.00 |
| Tencent | 8.29 | 1.12 | 1.71 | 12.82 | 18.02 | 17.66 | 0.00 |
| Baidu | 0.15 | 0.03 | 0.00 | 0.54 | 1.70 | 1.49 | 0.00 |
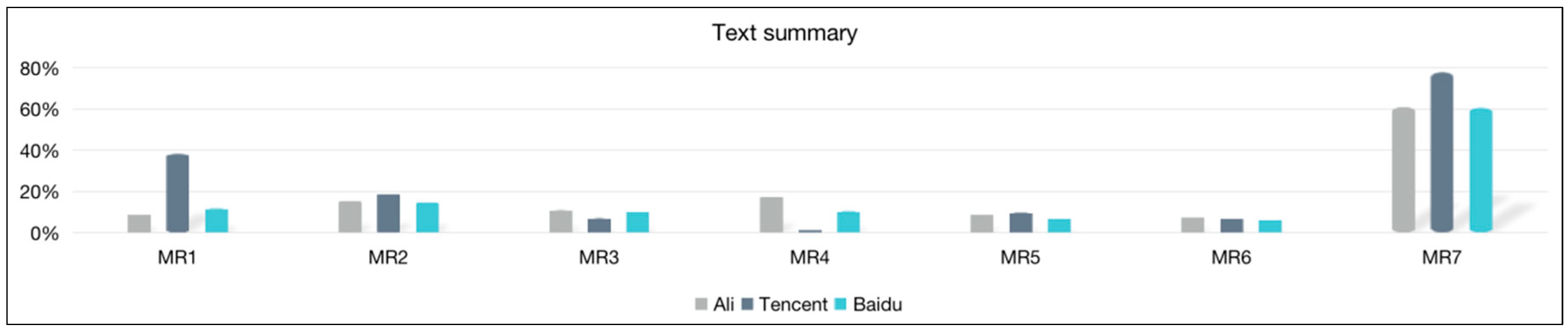
| VR (%) | MR1.2 | MR2.2 | MR3.2 | MR4.2 | MR5.2 | MR6.2 | MR7.2 |
|---|---|---|---|---|---|---|---|
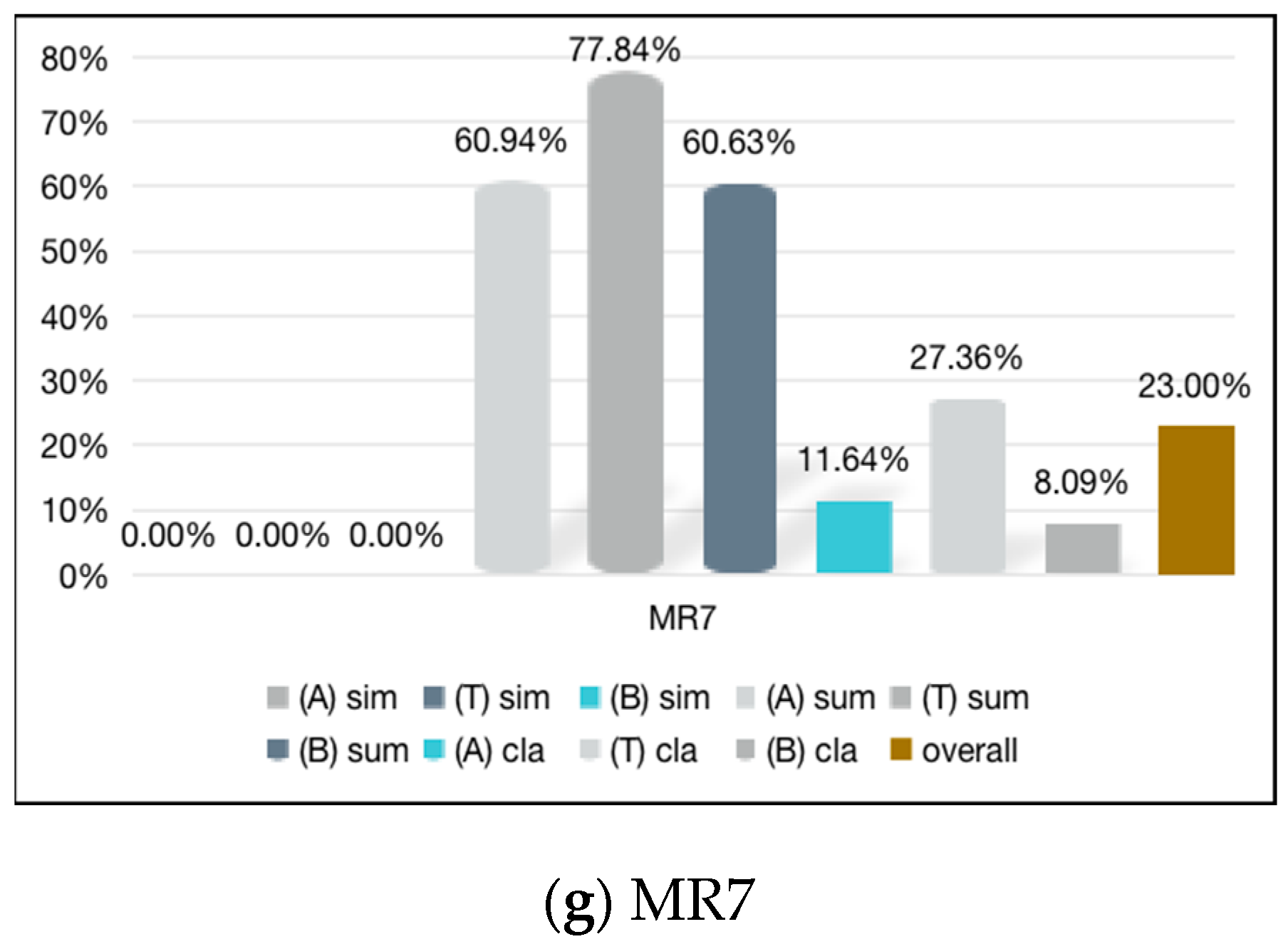
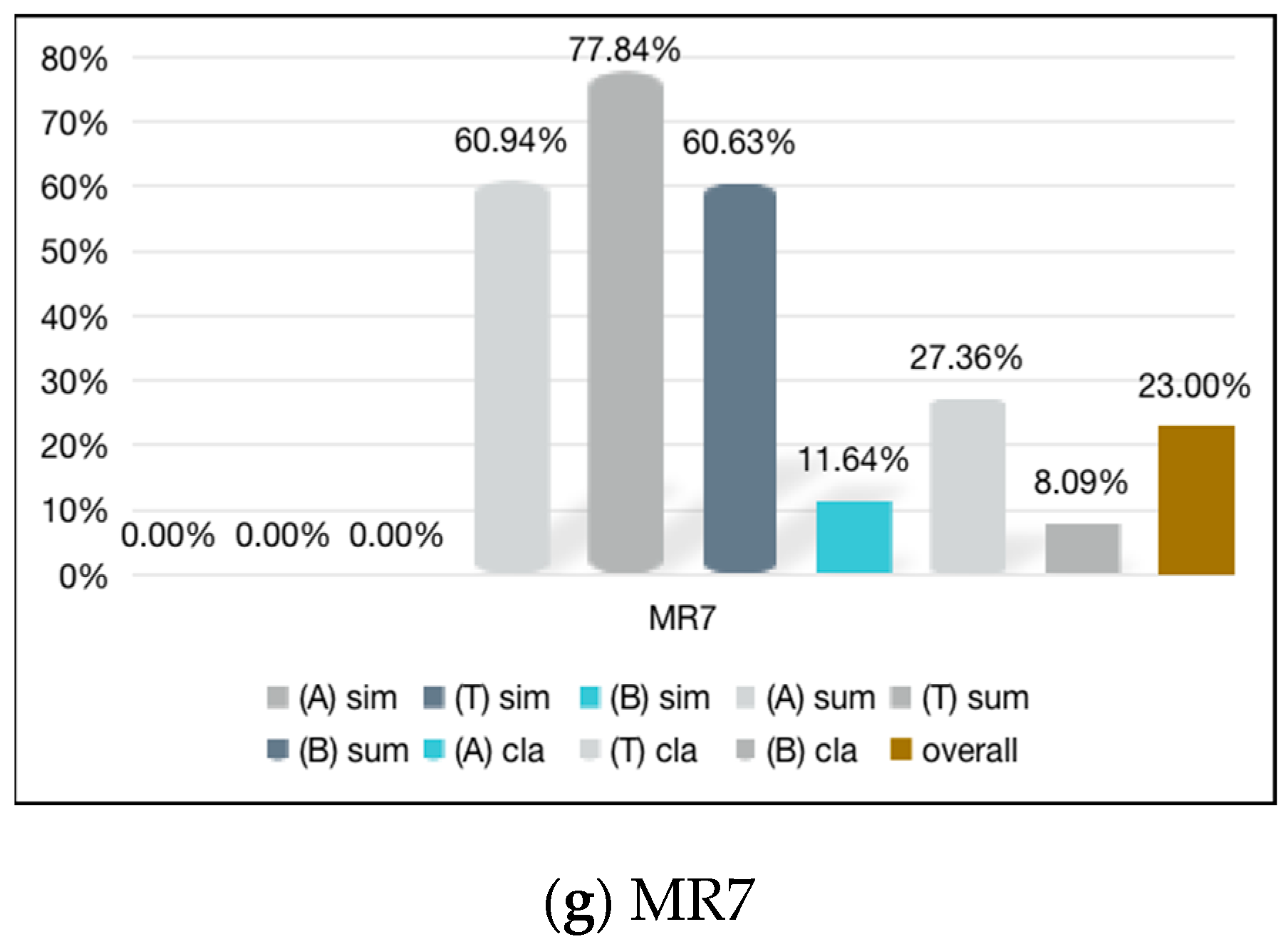
| Ali | 8.89 | 15.33 | 11.04 | 17.42 | 8.96 | 7.37 | 60.94 |
| Tencent | 38.29 | 18.84 | 7.05 | 0.45 | 9.76 | 7.05 | 77.84 |
| Baidu | 11.75 | 14.65 | 10.32 | 10.42 | 6.97 | 6.27 | 60.63 |
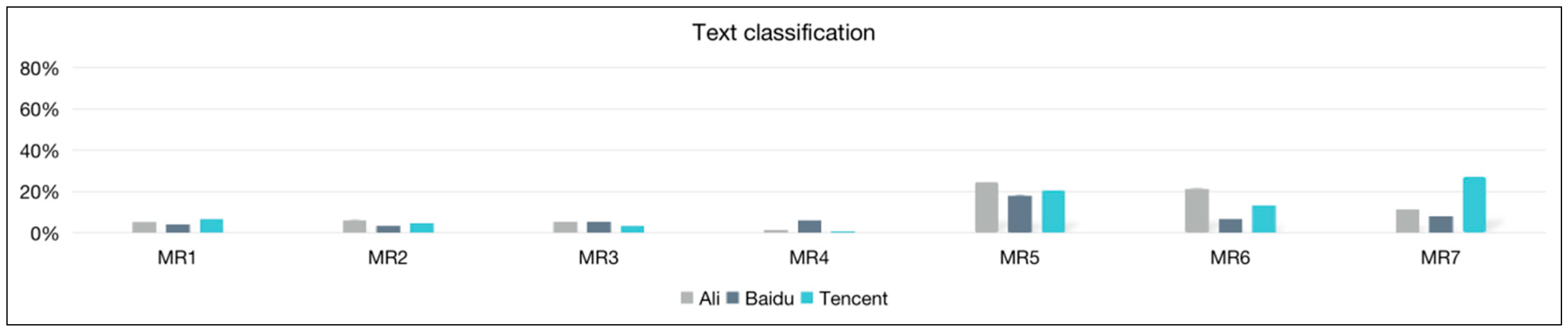
| VR (%) | MR1.3 | MR2.3 | MR3.3 | MR4.3 | MR5.3 | MR6.3 | MR7.3 |
|---|---|---|---|---|---|---|---|
| sports | 1.05 | 1.54 | 1.02 | 0.14 | 5.92 | 3.66 | 0.92 |
| entertainment | 7.35 | 8.32 | 7.21 | 0.67 | 21.22 | 23.65 | 7.70 |
| education | 1.30 | 5.36 | 1.54 | 0.19 | 13.55 | 9.14 | 5.22 |
| fashion | 5.29 | 9.16 | 4.97 | 0.63 | 26.39 | 24.24 | 5.41 |
| games | 5.37 | 12.64 | 6.08 | 1.01 | 41.10 | 33.96 | 13.49 |
| society | 9.26 | 8.46 | 6.35 | 0.96 | 28.86 | 22.80 | 6.81 |
| technology | 5.58 | 14.27 | 8.54 | 1.13 | 43.89 | 40.92 | 37.18 |
| All | 5.31 | 6.40 | 5.50 | 0.67 | 24.79 | 21.68 | 11.64 |
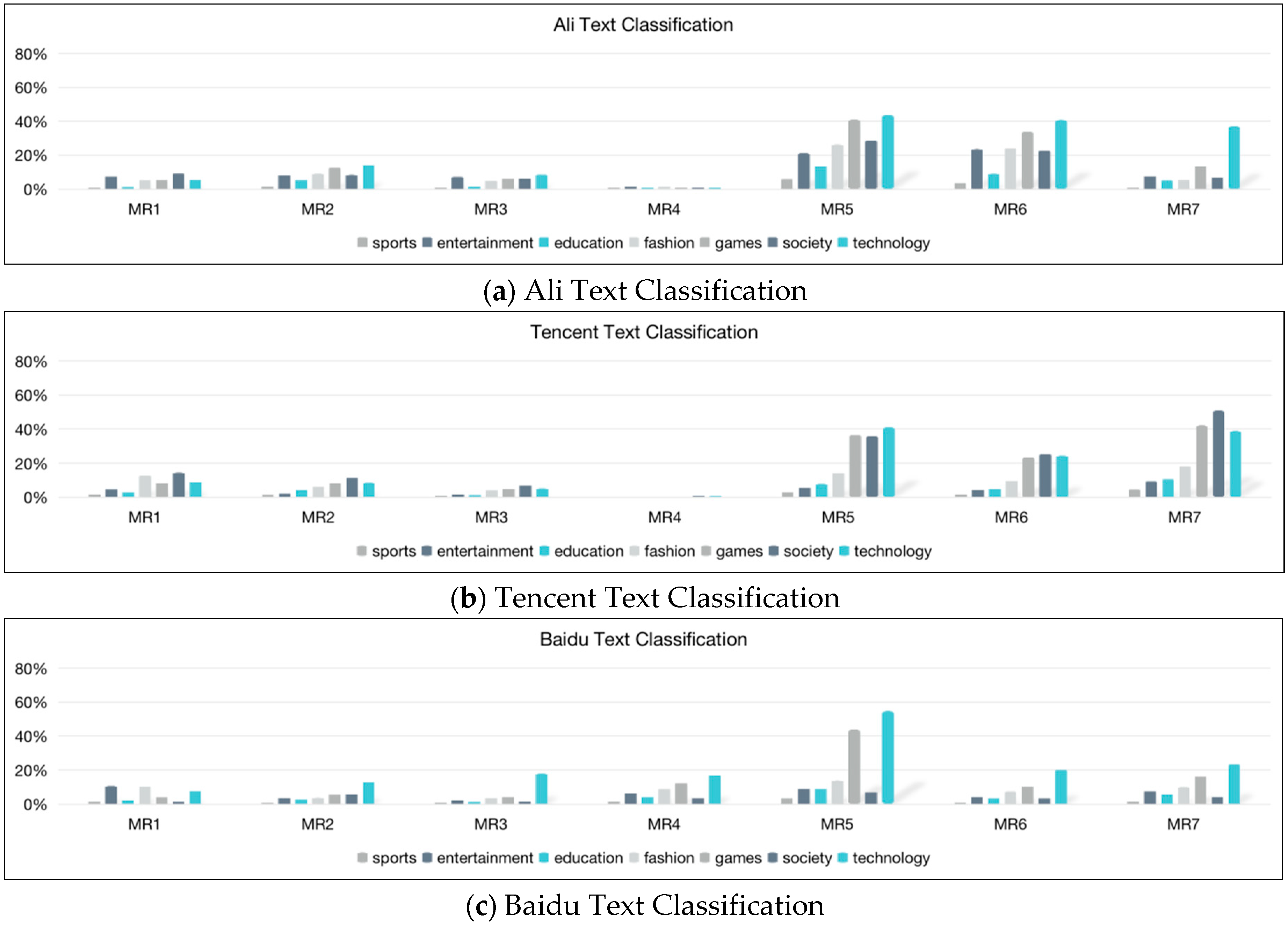
| VR (%) | MR1.3 | MR2.3 | MR3.3 | MR4.3 | MR5.3 | MR6.3 | MR7.3 |
|---|---|---|---|---|---|---|---|
| sports | 0.75 | 0.83 | 0.44 | 1.58 | 3.46 | 1.08 | 1.85 |
| entertainment | 10.56 | 3.56 | 2.36 | 6.37 | 9.12 | 4.44 | 7.39 |
| education | 2.48 | 2.79 | 1.43 | 4.43 | 8.87 | 3.47 | 5.66 |
| fashion | 10.36 | 3.88 | 3.72 | 8.74 | 13.77 | 7.27 | 9.91 |
| games | 4.13 | 5.42 | 4.46 | 12.15 | 43.90 | 10.15 | 16.39 |
| society | 1.48 | 5.53 | 1.73 | 3.51 | 6.73 | 3.43 | 4.39 |
| technology | 7.68 | 13.08 | 17.88 | 16.93 | 54.91 | 20.16 | 23.39 |
| All | 4.09 | 3.55 | 5.51 | 6.34 | 18.29 | 6.90 | 8.09 |
| VR (%) | MR1.3 | MR2.3 | MR3.3 | MR4.3 | MR5.3 | MR6.3 | MR7.3 |
|---|---|---|---|---|---|---|---|
| sports | 1.74 | 1.45 | 0.41 | 0.00 | 3.08 | 1.88 | 4.61 |
| entertainment | 4.70 | 2.13 | 1.82 | 0.00 | 5.50 | 4.46 | 9.30 |
| education | 3.06 | 4.46 | 1.30 | 0.00 | 7.89 | 4.86 | 10.66 |
| fashion | 12.73 | 6.18 | 4.07 | 0.00 | 14.30 | 9.69 | 18.13 |
| games | 8.20 | 8.33 | 4.99 | 0.00 | 36.75 | 23.45 | 42.36 |
| society | 14.50 | 11.41 | 6.84 | 0.00 | 36.07 | 25.54 | 51.16 |
| technology | 9.03 | 8.57 | 5.22 | 0.00 | 41.21 | 24.47 | 39.05 |
| all | 6.91 | 4.71 | 3.71 | 0.00 | 20.75 | 13.48 | 27.36 |
| (%) | MT | Dataset-Based Evaluation Approach | ||||
|---|---|---|---|---|---|---|
| Text Similarity | Text Summarization | Text Classification | Text Similarity | Text Summarization | Text Classification | |
| AliNLP | 85.35 | 76.05 | 87.50 | 91.32 | 84.92 | 94.41 |
| TencentNLP | 83.52 | 77.55 | 86.66 | 92.20 | 83.21 | 96.12 |
| BaiduNLP | 92.47 | 76.74 | 91.46 | 92.25 | 88.60 | 96.54 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jin, L.; Ding, Z.; Zhou, H. Evaluation of Chinese Natural Language Processing System Based on Metamorphic Testing. Mathematics 2022, 10, 1276. https://doi.org/10.3390/math10081276
Jin L, Ding Z, Zhou H. Evaluation of Chinese Natural Language Processing System Based on Metamorphic Testing. Mathematics. 2022; 10(8):1276. https://doi.org/10.3390/math10081276
Chicago/Turabian StyleJin, Lingzi, Zuohua Ding, and Huihui Zhou. 2022. "Evaluation of Chinese Natural Language Processing System Based on Metamorphic Testing" Mathematics 10, no. 8: 1276. https://doi.org/10.3390/math10081276
APA StyleJin, L., Ding, Z., & Zhou, H. (2022). Evaluation of Chinese Natural Language Processing System Based on Metamorphic Testing. Mathematics, 10(8), 1276. https://doi.org/10.3390/math10081276