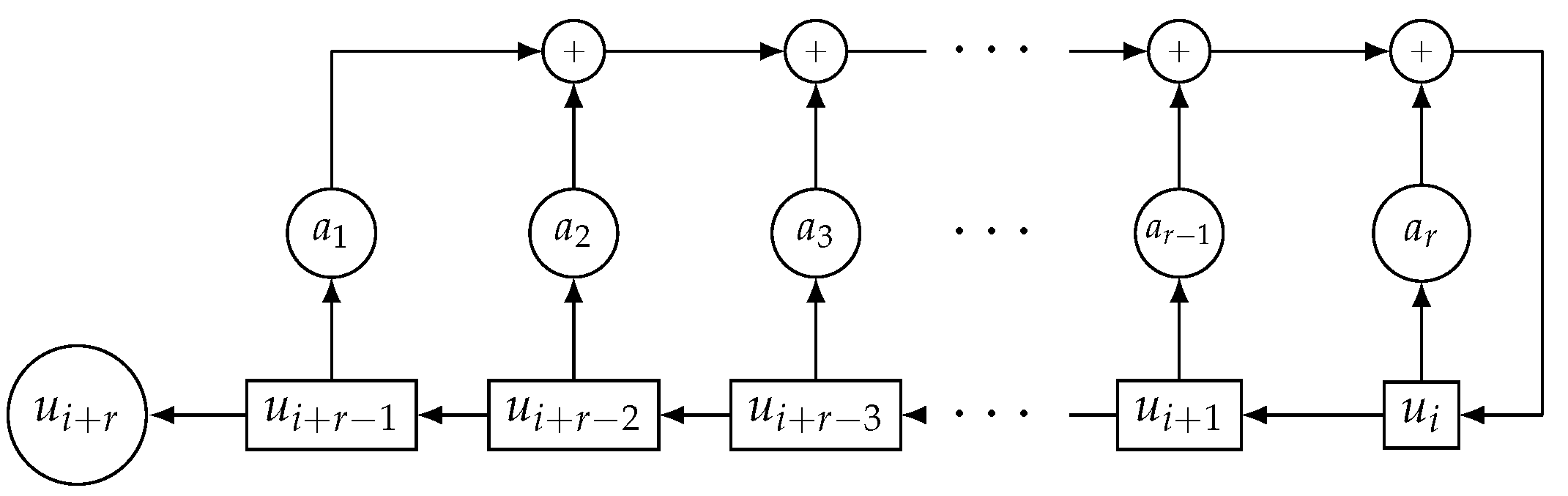
The generalized sequences seem to be the ideal candidates for the application of the previous algorithm. In fact, their period is a power of two, and as we saw in
Section 2, their linear complexity is upper bounded by
, where
L is the length of the LFSR that generates the family of generalized sequences. Therefore, we initialized Algorithm 1 with the value
.
Let us see a particular example of the application of the defined algorithm in a generalized sequence.
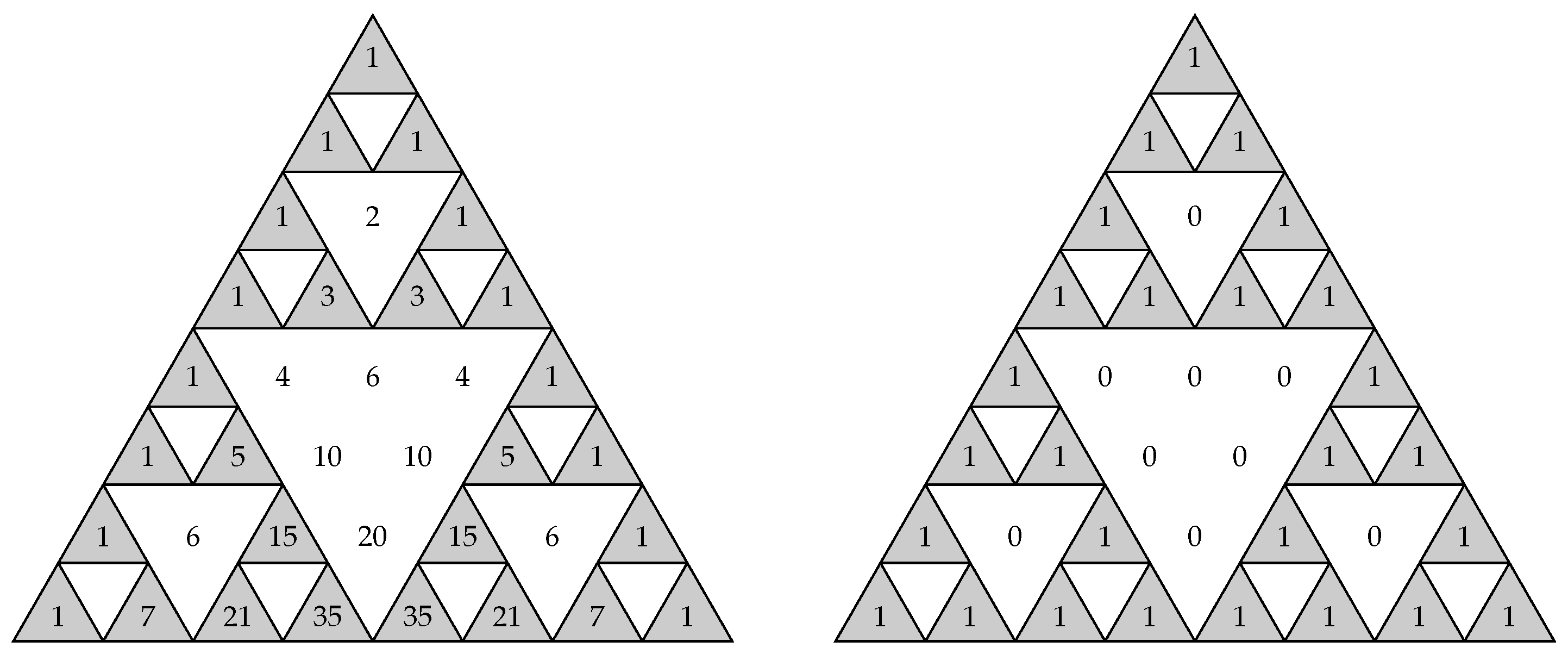
5.1. Analysis of 3 5
In a similar way to that developed in Example 3, we applied this method to generalized sequences coming from LFSRs with characteristic polynomials of degrees .
In the case
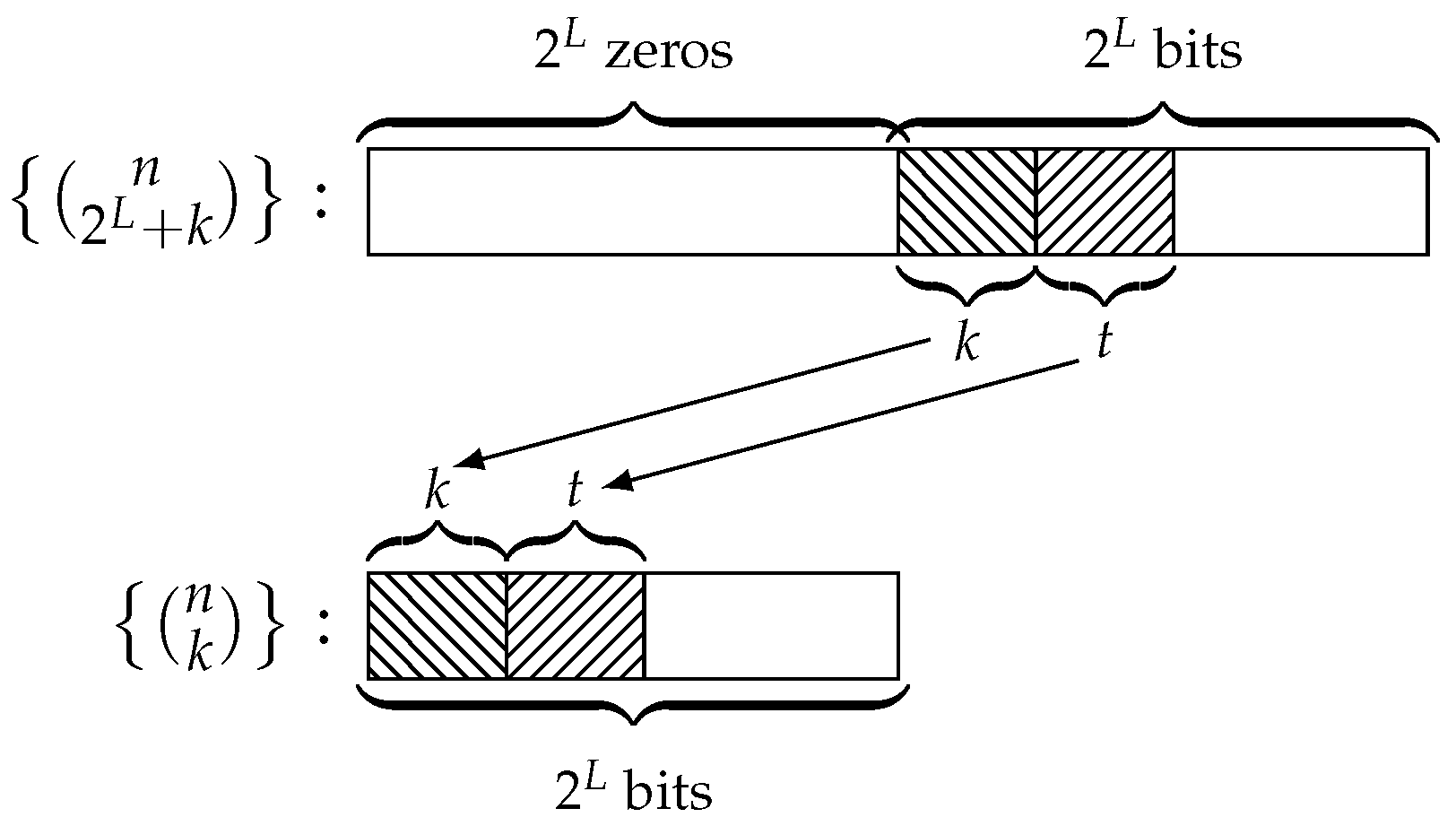
, the maximum value of the linear complexity of a generalized sequence is
. It corresponds to the column
of the matrix:
that is the second column of
(read from right to left) circled in (
11), which corresponds to the binomial sequence
. In
Table 2, we computed, for
, the values of
, the index
, the location of
, the binomial matrix
, and the binomial sequence associated with
.
We observed that for
,
, and using our algorithm, we obtained
, that is the third column of
(read from right to left) circled in
.
Due to the recursive structure of the Hadamard matrix, we can obtain the column
of
using the columns of
. We only had to concatenate twice the sequence given in the third column of
. In a similar way, for
,
, then
, that is the fourth column of
in Equation (
10) read from right to left. It can also be obtained from the concatenation twice of the fourth column of
or concatenating four times the sequence given in the fourth column of
. In conclusion, we can construct the columns
, for the cases
, using the matrix
, as we show in
Table 3. We only needed to concatenate
times the corresponding column of
in
to obtain the column in
. In the next subsection, we generalized this method of obtaining the binomial sequences associated with the column
, for different values of
L.
5.2. Analysis of 5 17
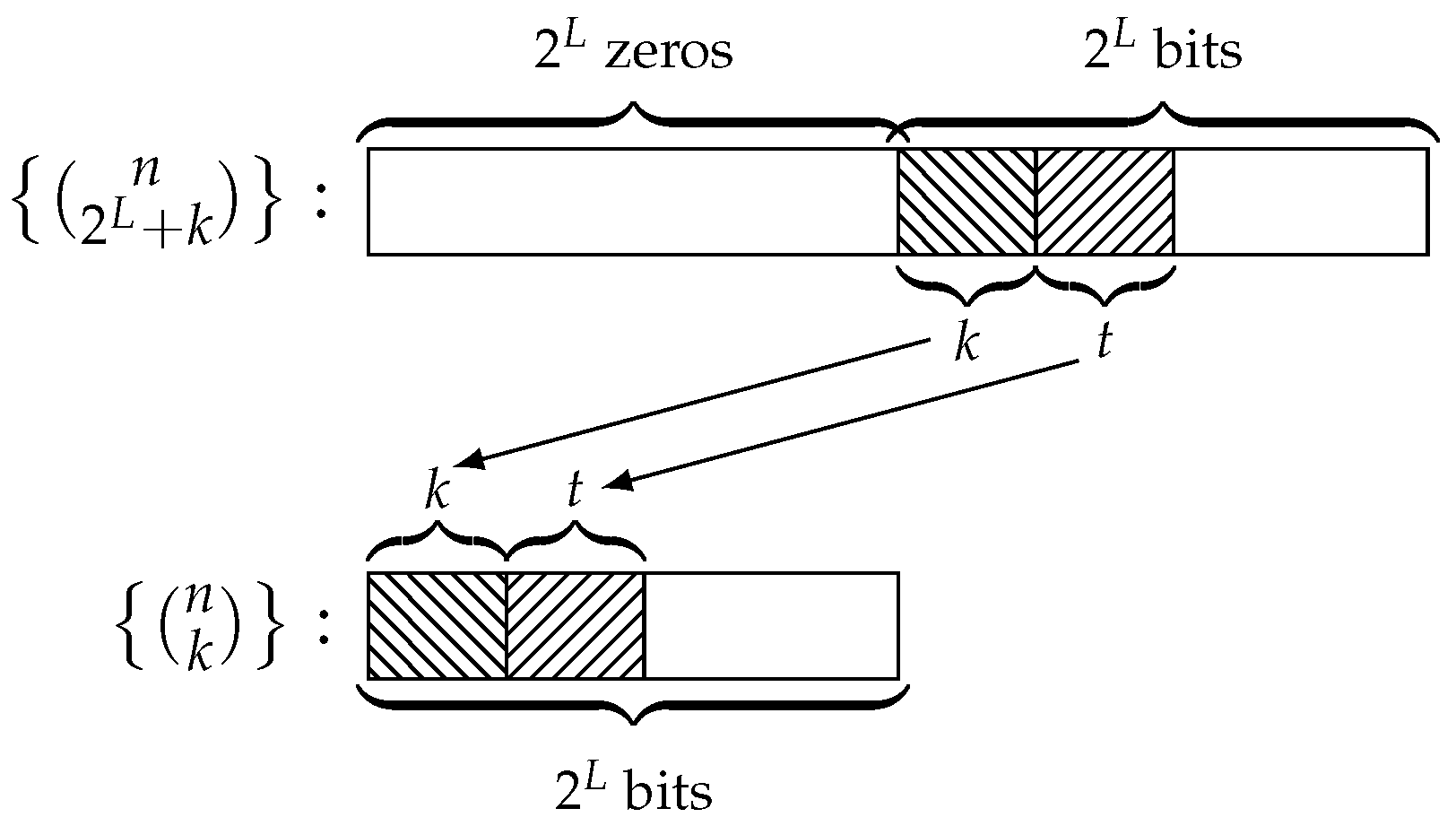
In the previous subsection, we used the matrix as the reference matrix to obtain the columns of for . From now on, we fix as our reference matrix, called the 16-box. From this matrix, we determined the column for the different cases of L, which allowed us to obtain the number of required bits to compute .
In a similar way to that developed in previous sections, we analysed the linear complexity of the generalized sequences coming from LFSRs with length L in the range .
The steps of this analysis can be enumerated as follows:
Step 1: Take the
-matrix
in Equation (
10) as the reference matrix, the 16-box, since the successive matrices
are made up of sub-matrices
or 16-boxes;
Step 2: Divide the period of the generalized sequence by 16 to determine the number of 16-boxes included in the -matrix ;
Step 3: Count the number of ones in the column of the 16-box;
Step 4: Multiply this number by the number of 16-boxes in in order to obtain the total number of ones in the column of . This number coincides with the number of bits necessary to check whether the generalized sequence has . At the same time, the column shows the distribution of the required bits all along the sequence .
This analysis was adapted to the successive n-boxes used in the following subsections. As far as L increases by one, in the frame of the box, the column is shifted one position to the left.
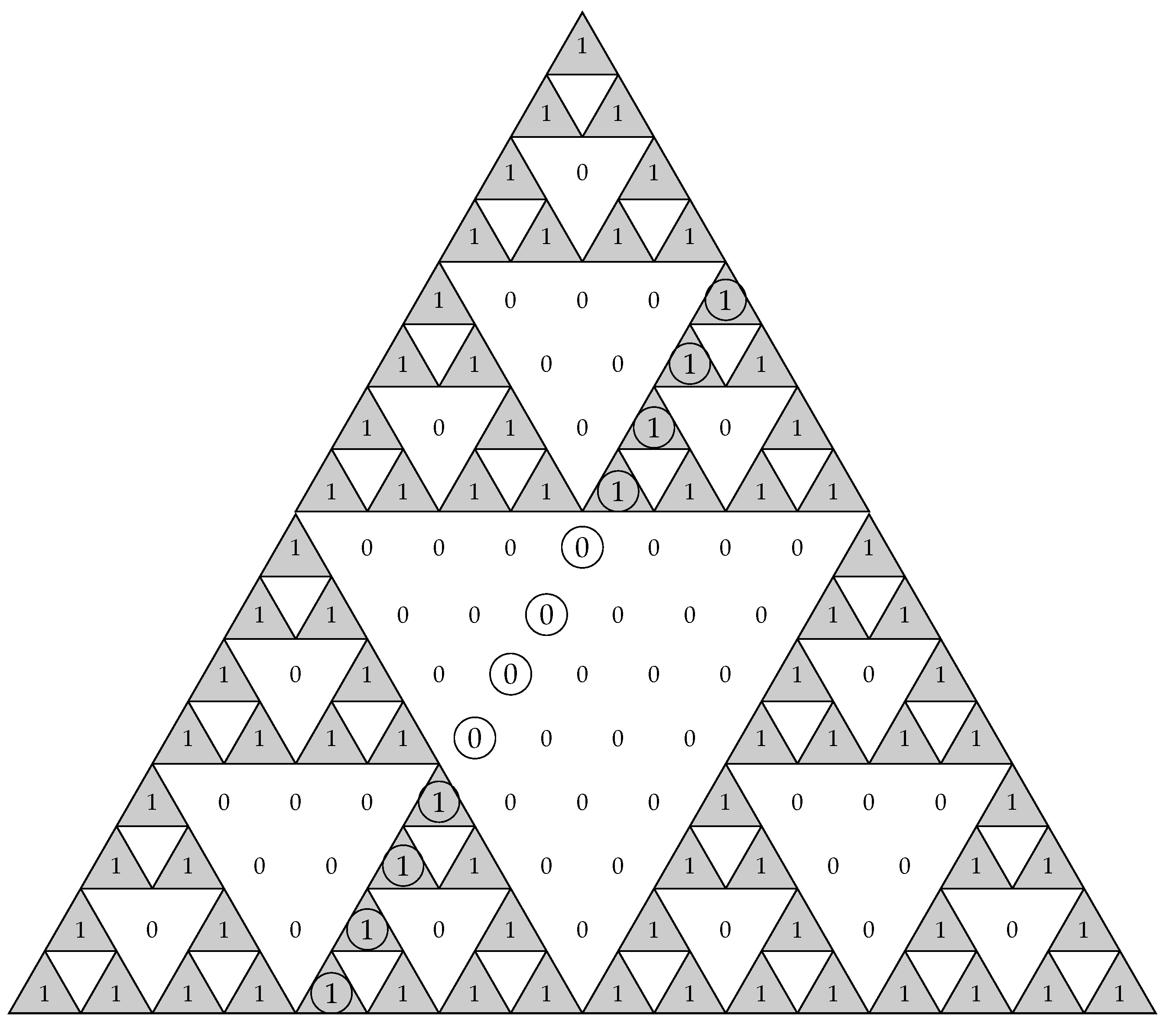
The 16-box is depicted in
Table 4. We can see the column
corresponding to each value of
L (written at the bottom of the table) in the interval
, as well as the corresponding binomial sequence
. Indeed, for
,
is the fourth column of
read from left to right. Now, for
,
is the fifth column of
or also the fifth column of
concatenated twice. Following a similar reasoning to that presented in the previous subsection, we have that the binomial sequence associated with the column
of
, for
, can be obtained from the concatenation of
times the column
of
.
The parameters that describe this analysis are shown in
Table 5 where its columns correspond to:
L = length of the LFSR generating the family of generalized sequences;
period of the generalized sequence;
No. of 16-boxes: number of 16-boxes included in the binomial matrix , i.e., ;
No. of ones/16-box: number of ones in the column of the 16-box;
No. of required bits: number of one in the column of the matrix or, equivalently, number of required bits of the sequence ; this number is expressed as a fraction of the period T.
From
Table 5, we realized that Algorithm 1 will never require the knowledge of the whole sequence
to check whether its
is maximum. At any rate, depending on the value of
L, the amount of sequence needed will be greater or shorter.
In fact, as we show in the following results, we can give an upper and lower bound of the number of operations required to compute for some particular cases.
Theorem 4. Let be a generalized sequence with period . Consider that the column of corresponds to the binomial sequence , with a positive integer. Then, the maximum number of required bits to compute from Algorithm 1 is .
Proof. This result is immediate by Corollary 2. □
Theorem 5. Let be a generalized sequence with period . Assume that the column of corresponds to the binomial sequence , with a positive integer. Then, the minimum number of required bits to compute from Algorithm 1 is .
Proof. This result is immediate by Definition 1, since the binomial sequence has a unique digit of one, while the remaining digits are zero. □
Note that these considerations can be generalized to any value of L. For , it is easy to see that and , corresponding to the binomial sequences and , respectively, are the least suitable cases since such values require the knowledge of half the sequence. Nevertheless, the value , corresponding to the binomial , requires only the knowledge of bits.
At the same time, the column of the 16-box determines the distribution of the required terms along the sequence. For instance:
For , , which means that eight out of sixteen bits of the sequence are needed to check whether . Moreover, the required bits must be consecutive;
For , , which means that one out of sixteen bits of the sequence is needed to check whether the linear complexity is maximum;
For the remaining values of
L, the number of required bits takes the values
or
, as shown in
Table 5. In fact, it depends on the number of ones along the column
of the 16-box, in particular,
for columns with two ones, e.g.,
, and
for columns with four ones, e.g.,
.
The next subsections analyse these results for greater values of L.
5.3. Analysis of 18 33
The study was similar to that of the previous subsection, but we now used a 32-box as shown in
Table 6, where
is the 16-box defined above and
is the
-null matrix. Next, we divided the period
T of the sequence by thirty-two and analysed the number of ones in the successive columns
of the 32-box when
L takes values in the interval
. It can be noticed that for these values of
L, the columns
include the corresponding ones of the 16-box plus sixteen zeros of
. See
Table 6.
Table 7 shows in detail this study for the different values of
L. According to the table, the least suitable case is
corresponding to the binomial sequence
with sixteen consecutive ones followed by sixteen consecutive zeros. On the other hand, the most suitable case is
corresponding to the binomial sequence
with a unique one followed by thirty-one zeros. See in
Table 7 the amount of sequence needed in terms of the period
T.
5.4. Analysis of 34 65
The study was similar to that of the previous subsections, but we now used a 64-box as shown in
Table 8, where
and
are defined as before and
is the
-null matrix. Now, we divided the period
T of the sequence by sixty-four and analysed the number of ones in the successive columns
of the 64-box when
L takes values in the interval
. It can be noticed that this range of values of
L can be divided into two sub-intervals:
For , in the the 64-box columns we will have the ones of two 16-boxes plus thirty-two consecutive zeros of ;
For
, in the 64-box columns, we will have the ones of the 16-box plus
consecutive zeros coming from
and
, respectively. See
Table 8.
Table 9 shows in detail this study for some values of
L in each sub-interval. According to
Table 9, the least suitable case is
, corresponding to the binomial sequence
with
consecutive ones followed by thirty-two consecutive zeros, which means that
bits are required to check the maximum complexity. On the other hand, the most suitable case is
corresponding to the binomial sequence
with a unique one followed by sixty-three zeros. Therefore, one out of sixty-four bits is needed to check
, that is only
bits of the sequence are needed.
5.5. Analysis of 66 129
The study was similar to that of the previous subsections, but we now used a 128-box as shown in
Table A1, where
,
,
are defined as before and
is the
-null matrix. Now we divided the period
T of the sequence by one-hundred twenty-eight and analysed the number of ones in the successive columns
of the 128-box, when
L takes values in the interval
. It can be noticed that this range of
L values can be divided into four sub-intervals:
For , in the the 128-box columns, we will have the ones of four 16-boxes plus sixty-four consecutive zeros of ;
For
, in the 128-box columns, we will have the ones of the 16-box, then sixteen consecutive zeros coming from
, then the ones of the 16-box, and finally, sixteen consecutive zeros coming from
. See
Table A1;
For , in the 128-box columns, we will have the ones of two consecutive 16-boxes, then consecutive zeros coming from and , respectively;
For
, in the the 128-box columns, we will have the ones of a unique 16-box, then
consecutive zeros coming from
,
, and
, respectively. See
Table A1.
Table 10 shows in detail this study for some values of
L in each sub-interval. According to
Table 10, we notice that:
In the interval , the least suitable case is , corresponding to the binomial sequence where consecutive bits of the sequence are required followed by other 64 non-necessary bits, that is bits of the sequence are needed to check the maximum complexity;
In the interval , the most suitable case is where the distribution of the needed bits over the sequence is as follows: two bits separated thirty positions from each other followed by redundant bits, which means that we need the knowledge of bits of the sequence;
In the interval , the most suitable case is , where the distribution of the needed bits over the sequence is as follows: two bits separated sixteen positions from each other followed by redundant bits, which means that we need the knowledge of bits of the sequence;
In the interval , the most suitable case is , corresponding to the binomial sequence . In that case, one out of one-hundred twenty-eight bits is required to check .
In general, we employed:
The 16-box for ;
The 32-box for ;
The 64-box for ;
The 128-box for .
For greater values of L, the process goes on in the same way as the Hadamard structure of the binomial matrices is systematically repeated.
Remark 2. With only four reference matrices, we easily obtained values of L in the range , which is the cryptographic range with practical application.




{kind=link}
{kind=link}
{kind=link}
{kind=link}