1. Introduction
A set of vertices D is a dominating set for a graph if every vertex in is adjacent to a vertex in D. Several problems related to the concept of dominance have been widely studied in graph theory literature. One of them is the minimum dominating set problem, which consists of obtaining a dominating set of smallest size; it is an NP-hard graph optimisation problem. Another is the problem of obtaining the domatic number , or domatic number problem, which consists of determining the maximum number of pairwise disjoint dominating sets in which a graph G can be partitioned. If the interest is not only the domatic number but also the elements of the partition, the disjoint dominating sets, then the problem is the domatic partition problem (DP).
Domatic number and domatic partition problems are classical optimisation problems which were introduced in the Ref. [
1]. Both are NP-complete, even for circular-arc graphs (see the Ref. [
2]), but both can be solved in linear time for interval and strongly chordal graphs (see the Ref. [
3,
4]). Domatic partition/number problems have different applications on the strategic location of facilities or resources in a network. Let us suppose that customers in a network would benefit from the installation of different types of facilities and that the nodes of the network cannot accommodate the installation of more than one type of facility. Let us also suppose that the resources provided by the facilities can only be accessed from neighbouring nodes or from itself. Then, the domatic number is the answer to the question of how many types of essential facilities (e.g., hospitals, universities, computer servers, antennas) can be located in this network, while the domatic partition states where to locate these facilities. Other application fields are related with strategy problems arising from business and military operations.
Currently, there are some known exact algorithms for the domatic number. The Ref. [
5] provided an algorithm based on the measure and conquer technique in
time and exponential space. At the same time, the Ref. [
6] proposed an algorithm based on the principle of inclusion–exclusion in
time and exponential space that also runs in
time if only polynomial space is used. Finally, the Ref. [
7] introduced an algorithm that combines both the measure and conquer and the inclusion–exclusion techniques for calculating the domatic number in
time and polynomial space. This algorithm is based on another algorithm for counting the dominating sets in
time formulated in the same paper. Thus, given that the domatic number can be calculated from the number of dominating sets of a graph, an improvement in the algorithm used to calculate it automatically implies improving the computational complexity of the domatic number. In this way, in the Ref. [
8], a faster algorithm to compute the number of dominating sets of a graph in
time was recently introduced. Nevertheless, although the authors comment that this new algorithm can also be used to obtain the domatic number in a faster way, as far as we know, the computational complexity for calculating it using this method has not been evaluated until now.
The majority of the latest exact exponential time algorithms for the domatic number have used both the inclusion–exclusion technique and the measure and conquer technique. The inclusion–exclusion technique was introduced in the Ref. [
9]. This technique, usually employed for calculating the size of the intersection of multiple sets or complex probabilities, is based on a simple idea that states it is possible to calculate the size of an intersection of multiple sets by adding the sizes of these sets separately, and then subtracting the sizes of all pairwise intersections from them. The measure and conquer technique was introduced in the Ref. [
10]. This is a method to upper bound the total number of subproblems generated mainly by recurrence algorithms, but also by branching algorithms; it is therefore a way of measuring the complexity of these algorithms. However, the use of both techniques in a single algorithm was proposed in the Ref. [
11].
Some families of graphs have received special attention when dealing with the domatic number computation; in particular, regular graphs, interval graphs, circular-arc graphs, chordal graphs, block graphs and block-cactus graphs. A graph is said to be regular of degree
r if every vertex has the same degree
r. It is said to be an interval graph if the nodes represent real line intervals and the edges join vertices whose intervals intersect. Circular-arc graphs are those whose nodes are arcs in a circle and whose edges join vertices whose arcs intersect. A circular-arc graph is a proper circular graph if no arc properly contains another. A chordal graph satisfies that all cycles of four or more vertices have a chord, that is, an edge that connects two vertices of the cycle not being part of the cycle. A
block graph is a connected graph such that each maximal connected subgraph without cut-vertices is a complete graph. A block-cactus graph is a graph whose maximal connected subgraphs without cut-vertices are either cycles or complete. There are specific bounds for the domatic number when the network is a regular graph [
12]. Additionally, there are linear-time algorithms for solving the domatic number problem in interval graphs [
3,
13]. While in circular-arc graphs the domatic number problem is NP-complete, it can be solved in
time for proper circular-arc graphs [
2]. However, linear time algorithms were developed for strong chordal graphs in the Ref. [
4]. Moreover, the domatic number for block-cactus graphs was discussed in the Ref. [
14]. As for block graphs, several related problems have been studied for this family of graphs as the power domination number [
15], the k-power domination number in the Ref. [
16], the k-distance domination problem in the Ref. [
17], and even the total domination number, as in the Ref. [
18]. However, as far as we know, the domatic number and partition problems have not been analysed for the particular case of graphs that are decomposable into blocks, where blocks are maximal connected subgraphs without cut-vertices. The main purpose of this paper is to propose a specific algorithm for obtaining a domatic partition, and as a consequence, the domatic number, in graphs with blocks. Given that blocks are not required to be complete, our algorithm can be applied to graphs other than block graphs. The new algorithm considerably reduces computation time.
The domatic partition problem has received less attention than the domatic number problem. The exact method for the domatic partition problem is based on linear integer programming. In the Ref. [
19], two mixed integer models were discussed for the independent domatic partition problem. Approximating algorithms for the domatic partition can be found in the Ref. [
20]. However, to the best of our knowledge, there are not any specific exact algorithms for the domatic partition problem.
This article is aimed to bridge this gap, studying the resolution of the domatic partition problem when the graph contains these special nodes whose removal produces two or more connected components. In other words, the goal of this paper is to develop an exact approach for separable graphs. We propose an exact decomposition algorithm based on the blocks. The algorithm iteratively solves an integer linear problem that we call the allied domatic partition problem. In fact, in order to obtain the solution of the domatic partition problem, we solve the allied domatic partition problem several times. The number of times we solve the allied domatic partition problem depends on the number of blocks of the graph, and also on the accuracy of the initial upper bound we have for the domatic partition problem. The decomposition of the problem considerably reduces the solution’s computational time.
The merits of this paper are threefold. The first merit is showcasing an innovative resolution algorithm for the domatic partition problem focused on decomposing graphs into their blocks. Therefore, this article illustrates the benefit of decomposing as a successful resolution technique. The second merit is introducing a new domination concept, the allied domination, which may help future researchers in the analysis of the domination problem. The third merit is coding the decomposition algorithm and obtaining challenging computational results that show the effectiveness of the algorithm in terms of time reduction.
The following section is about domination problems: the model in the literature for solving the independent domatic partition problem is adapted to model the domatic partiton problem. Moreover, the model for the decomposition algorithm of the following section is introduced. The new model deals with a new concept named
allied domination. Section 3 is the main section of this paper: it gives the new algorithm that we propose for obtaining a domatic partition when a graph is separable. In
Section 4, the advantages of the new algorithm are analysed by an extensive computational experience. Conclusions and future research are summarised in
Section 5.
3. Block Decomposition Algorithm
In this section, the block decomposition algorithm we propose is presented. In order to understand it, we shall first explain the procedure with an illustrative example, and we shall then describe the general algorithm. Several similar decomposition mechanisms have been described in the literature for other graph problems, see, for example, Refs. [
21,
22].
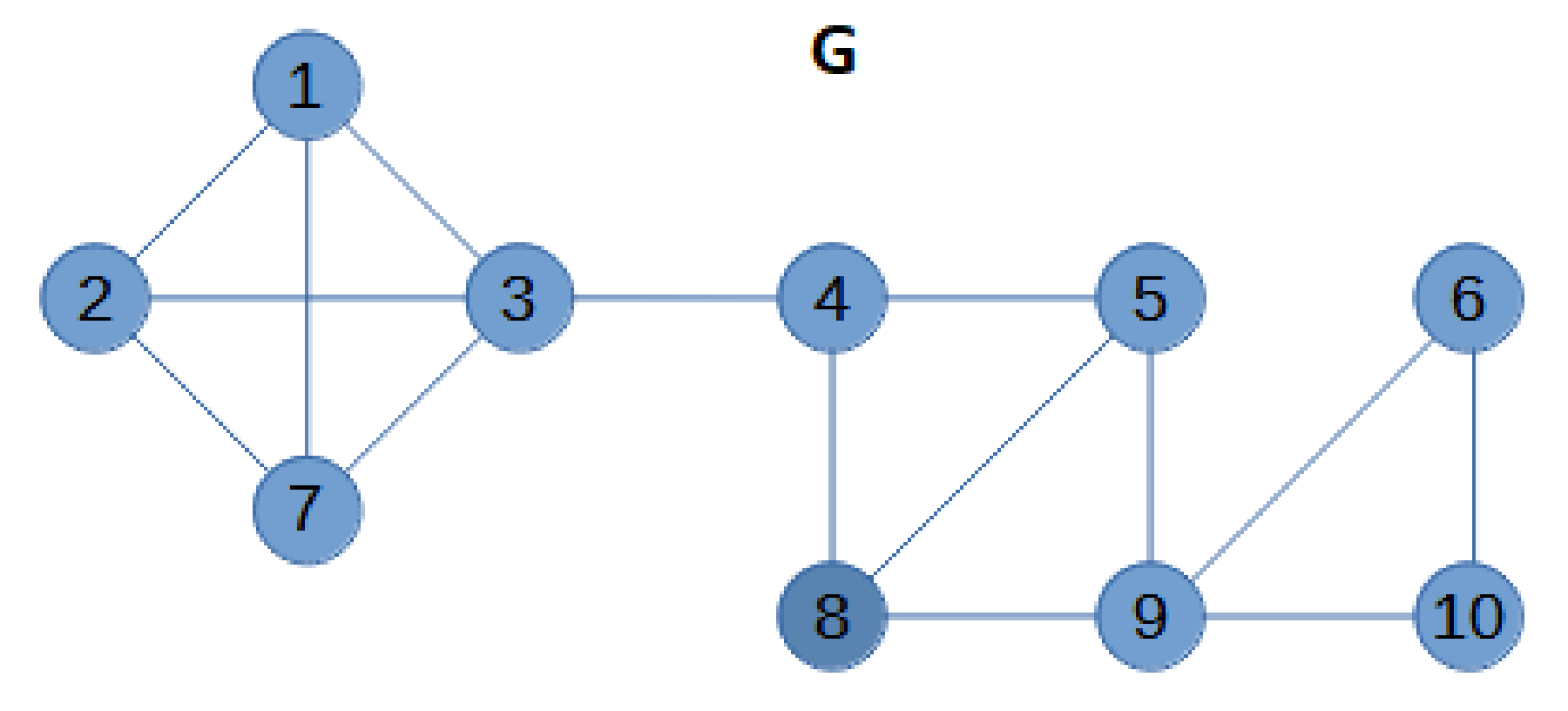
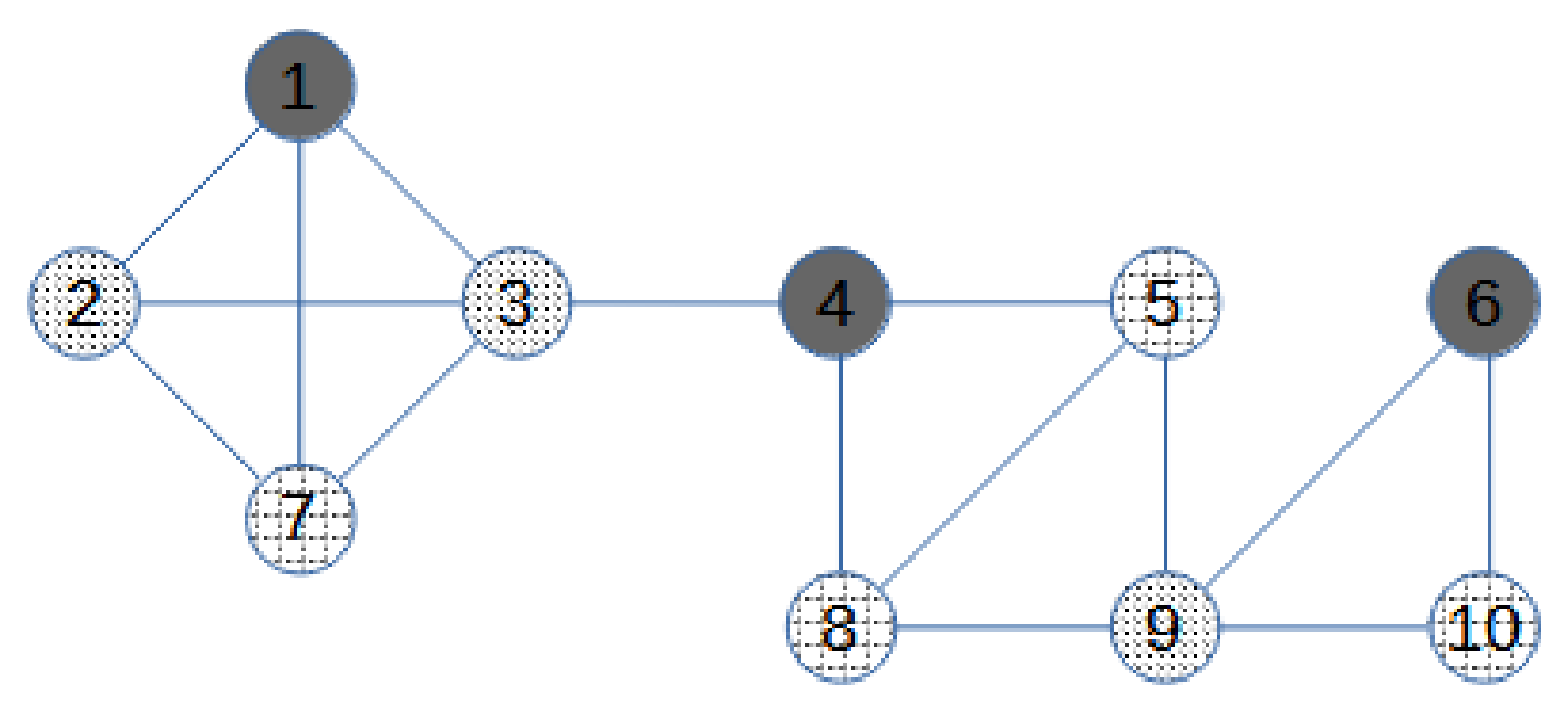
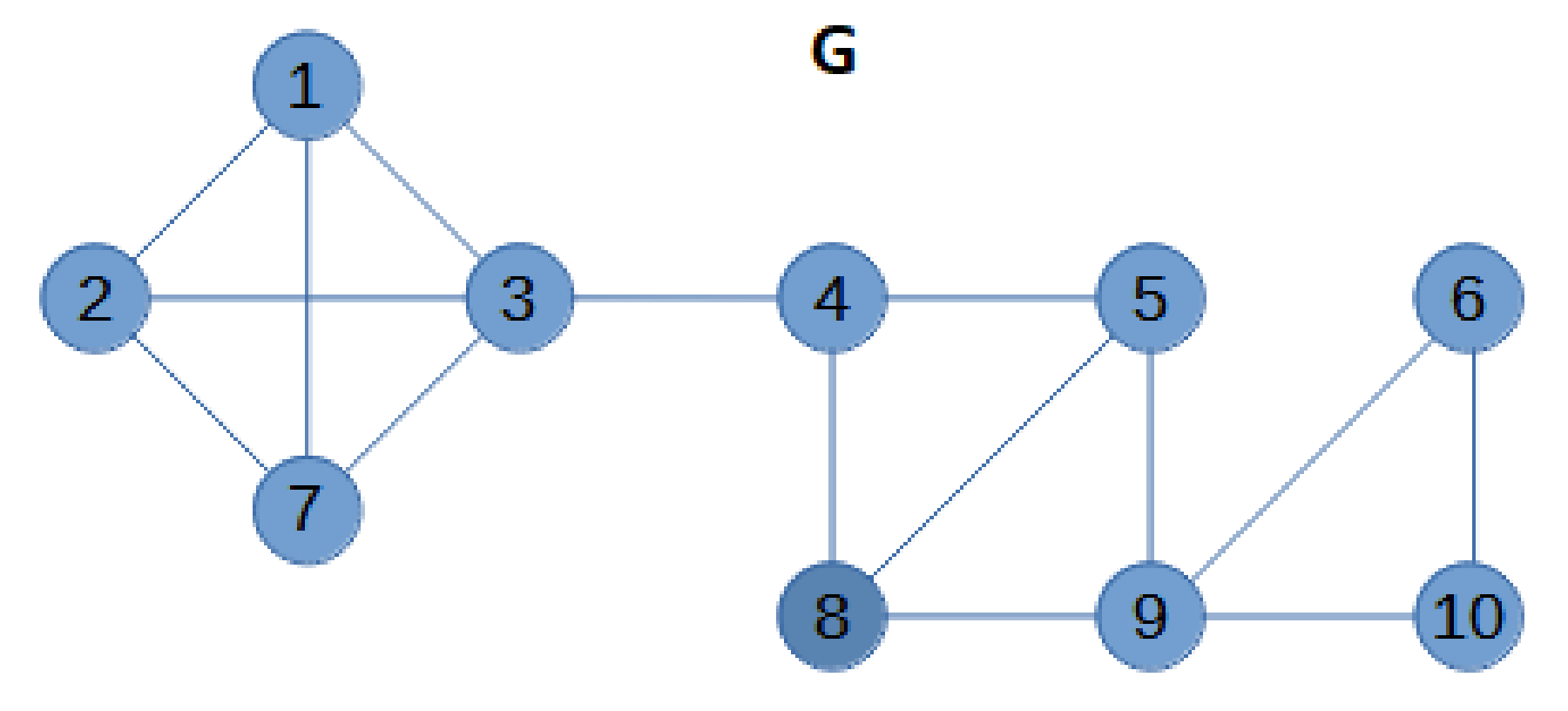
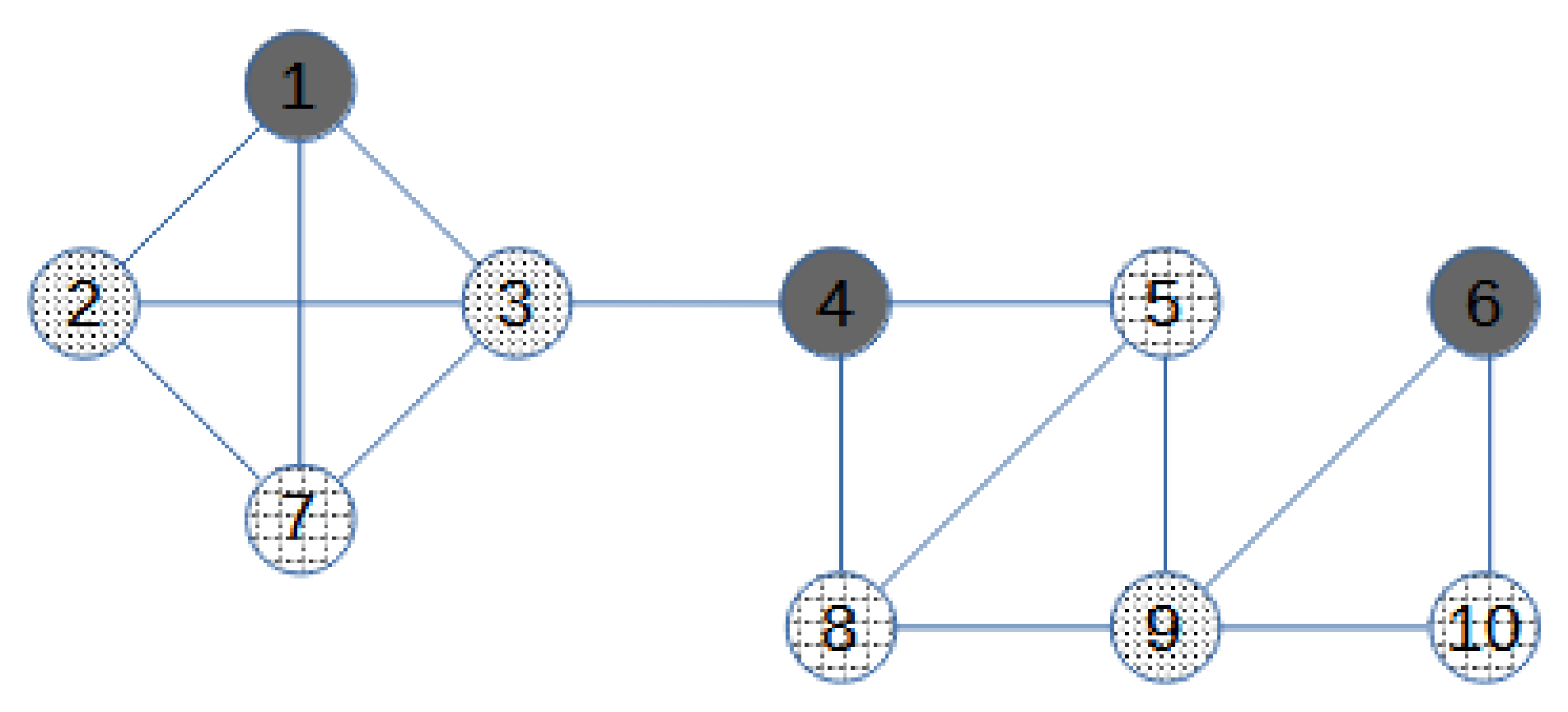
Let us consider the graph in
Figure 1. Before starting the iterative process, we update the upper bound (
) for the domatic number
to the value 3:
is the minimum degree of
G, that is, the degree of vertex 6, and
is an upper bound to
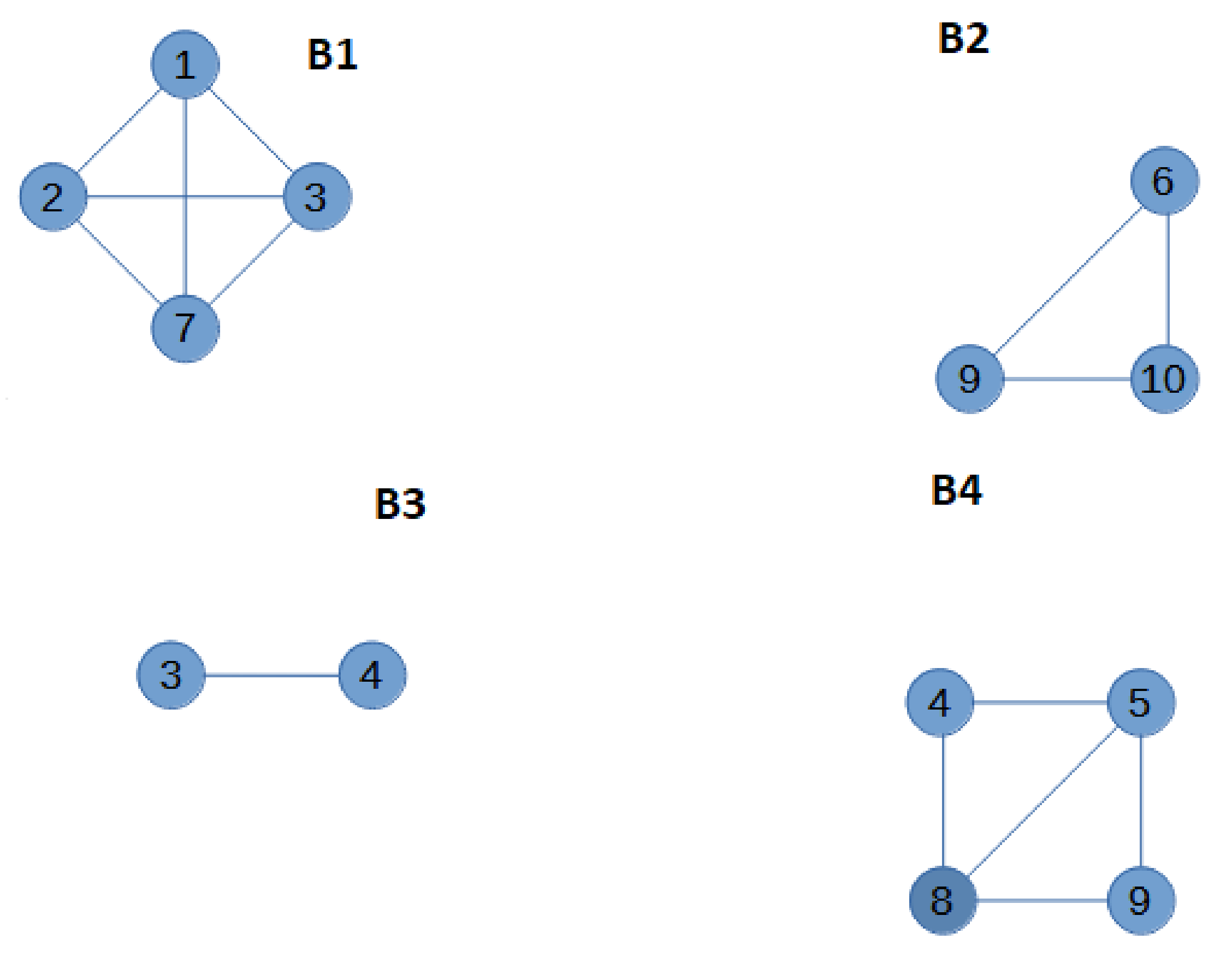
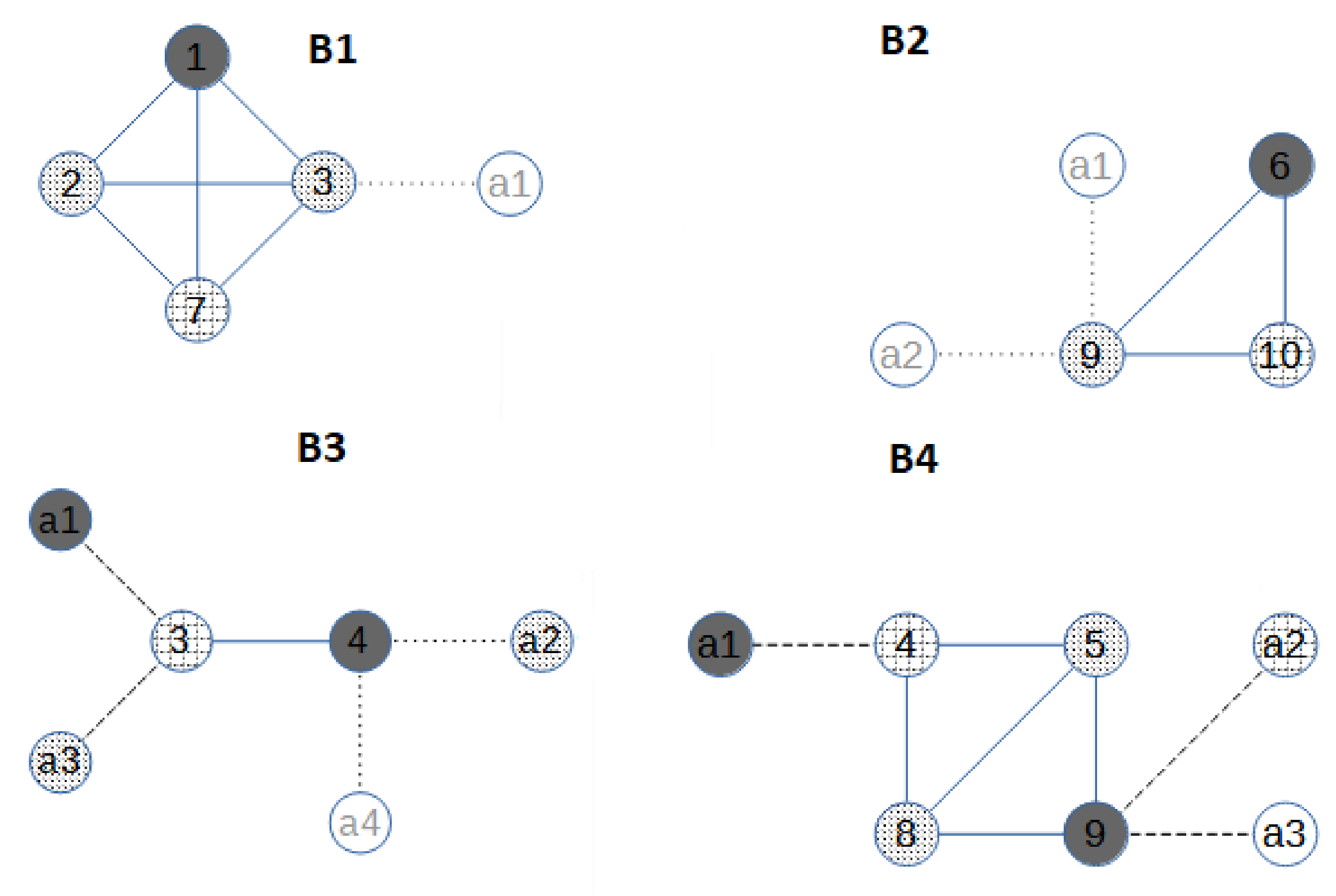
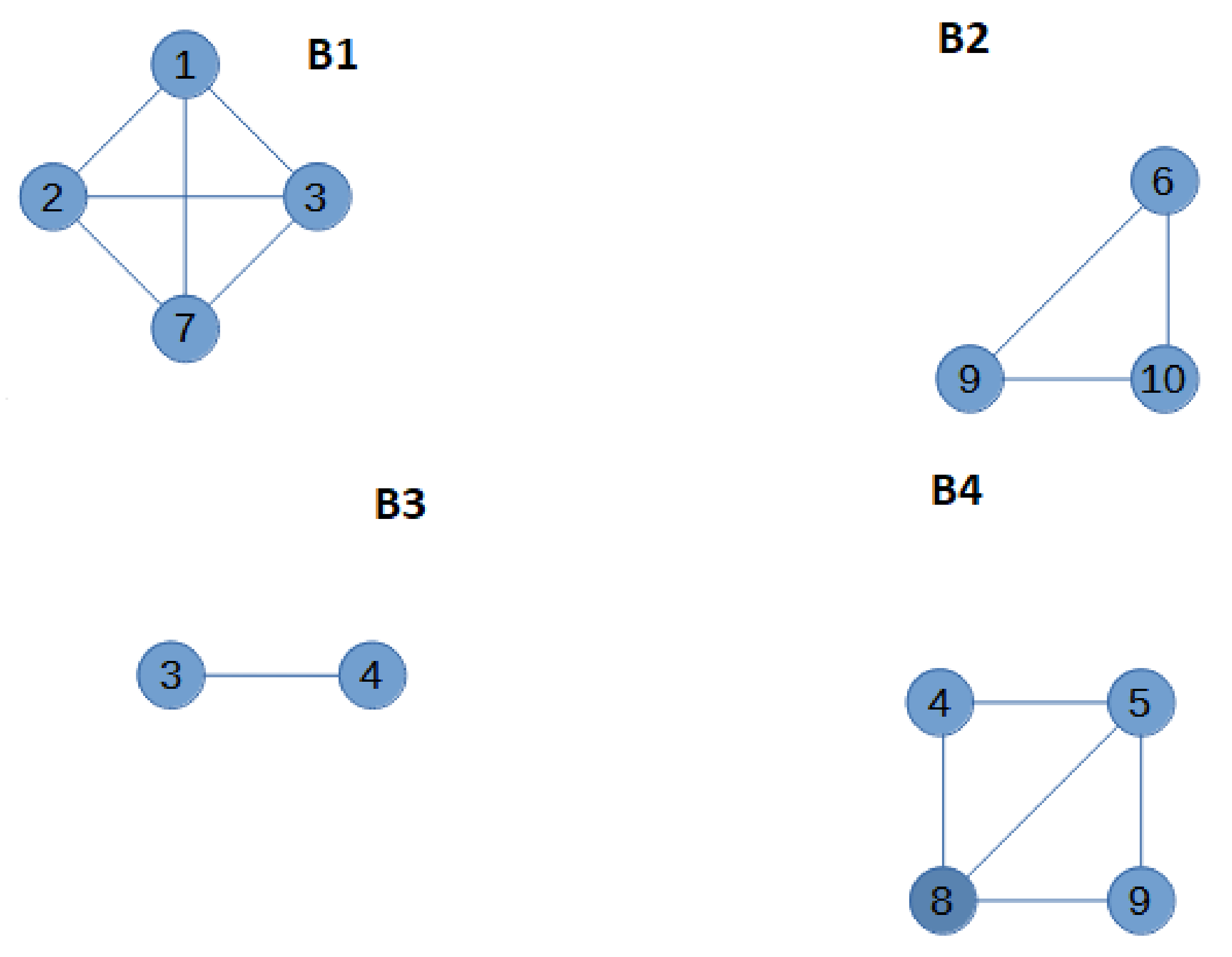
Then, the graph is split into blocks. All the blocks are the four subgraphs in
Figure 2. The blocks are sorted from the leaf blocks to the root block. In the example, blocks B1 and B2 are leaf blocks, and both are followed by blocks B3 and B4. Ties in the order can be broken arbitrarily. For the first block
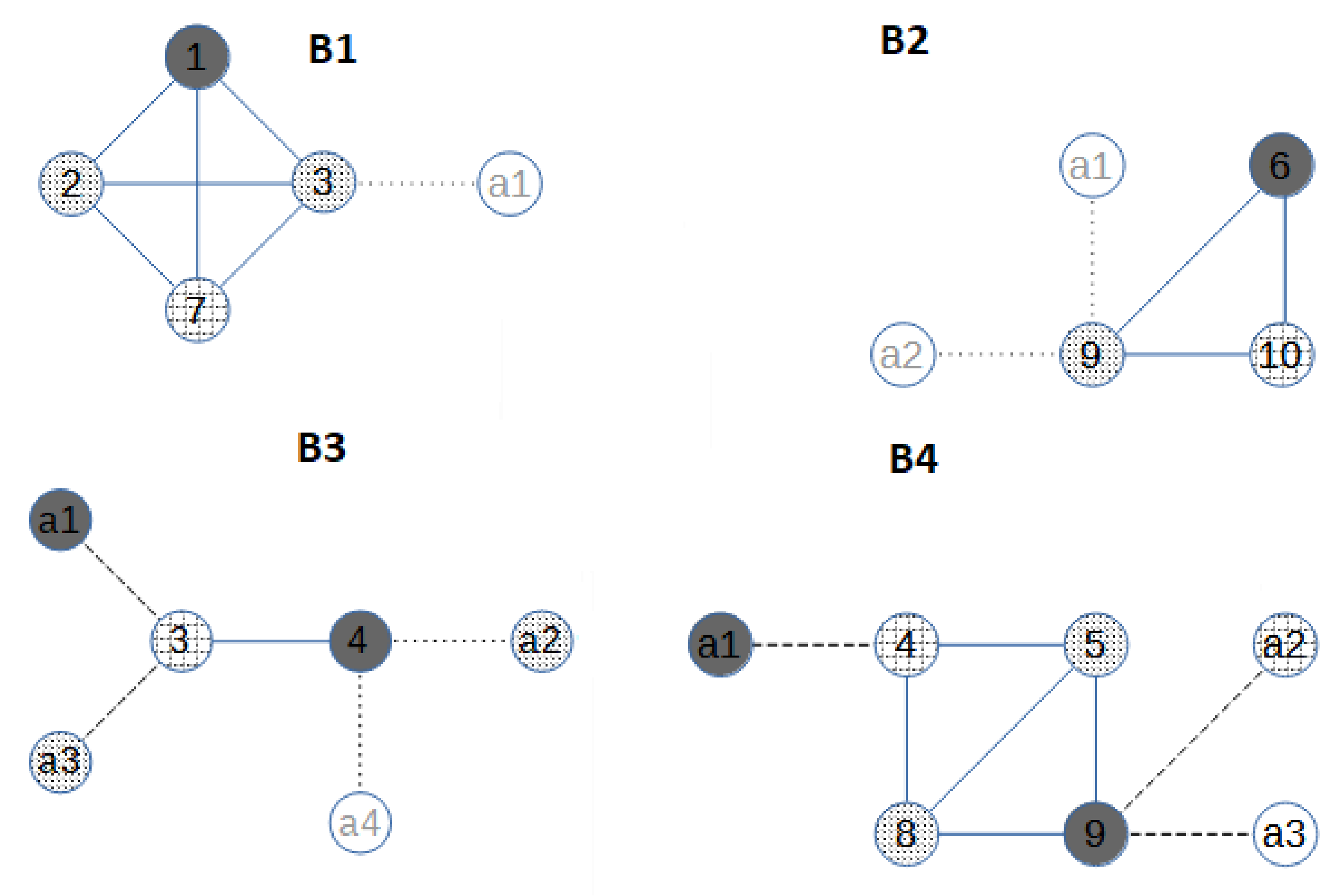
, we build an augmented block
by adding allied nodes to the cut-vertices of the block, and to each cut-vertex, an allied node for each neighbour of the cut-vertex that is not in the block is added. B1 has only one cut-vertex, node 3. The only neighbour of 3 that is not in B1 is node 4, so only one allied vertex is added to
. The augmented first block
is in
Figure 3. The weight
is assigned to the allied vertex in
. Then, we solve MC-AkDP for
with
(3 is an upper bound for
). Note that the weight
implies that if possible, the allied dominating set in
does not make use of node
, and thus the domatic partitions in adjacent blocks do not need to be coherent with their position in the partition. An optimal solution for MC-AkDP(
is the one in
Figure 2: there are three dominating sets in
, which are described by the three grey colours. Then, a similar procedure is carried on with the following block B2. B2 has one cut-vertex, node 9, and the number of neighbours of 9 that are not in B2 is two, so the augmented block
has two allied nodes with unitary weight,
The optimal value of MC-AkDP(
is zero because there are three dominating sets in
, the three grey colours in in
Figure 2. Block B3 has two cut-vertices, nodes 3 and 4. From now on, the number of allied vertices connected to a cut-vertex is not always the number of neighbours outside the block. Given a cut-vertex, if the problem MC-AkDP has been solved for other blocks connected to the same cut-vertex, the number of allied vertices connected to it must be
minus the optimal solution of the previous MC-AkDP problem. For node 3, the number of allied vertices must be
minus the optimal value of MC-AkDP(
that is 2 (3-1-0). For node 4, no other problem associated to an augmented incident block has been solved, so it has as many allied vertices as neighbours outside the block, that is, two allied vertices. Analogously, the weight is not directly one anymore; if some incident block to the cut-vertex was previously solved, then the weight is zero. Thus, in
,
and
. In
Figure 3, Weight One is indicated by light dashed grey lines, and Weight Zero by dark dashed grey lines. The optimal value of MC-AkDP(
is one because the allied node a2 is used for having three dominating sets. The last block B4 has two cut-vertices and both were the cut-vertex in previously solved MC-AkDP problems. Thus, the number of allied vertices connected to node 4 is
minus the optimal value of MC-AkDP(
and the number of allied vertices connected to node 9 is
minus the optimal value of MC-AkDP(
one allied vertex to node 4 and two allied vertices to node 9. The weight for the three allied vertices is zero and the optimal solution for the MC-AkDP(
is the one in
Figure 3. Finally, if some of the MC-AkDP problems would not have had a solution, that is, it would have been impossible to have a domatic partition of size
, we would have updated
to
and started again.
The general decomposition approach that is described in Algorithm 1 keeps the same spirit as the procedure described for the small example. It starts by sorting the blocks and initialising the number of allied vertices for any cut-vertex. The iterative pool of actions goes from line 7 to line 20. For the cut-vertex that connects the block to the tree of blocks, allied vertices are added, while for the other cut-vertices , allied vertices are added. Weights are used to minimise the number of allied nodes in the domination of r. Unweighted nodes were already used in a previous iteration, and we can make use of it freely. In line 13, is the optimal value of the MC-AkDP problem, representing the minimum number of weighted allied nodes needed for the domination, and is the partition of obtained from variables (it is where for all If any optimisation problem MC-AkDP is unfeasible, the is reduced by one unit. The last line of Algorithm 1 refers to Algorithm 2, which states how to paste all the allied dominating sets in the blocks into one dominating set of the total graph.
![Mathematics 10 00640 i001]()
In Propositions 1–8 we will prove that the output of Algorithm 1 is a domatic partition. The main goal is to prove that the MC-AkDP problem of separable graphs can be solved by solving the MC-AkDP problem of one block and the MC-AkDP problem of a related connected subgraph. As we can recursively repeat this operation until the subgraph is non-separable, that is, a block, then the MC-AkDP problem of a separable graph can be solved by solving one MC-AkDP problem for each of its blocks.
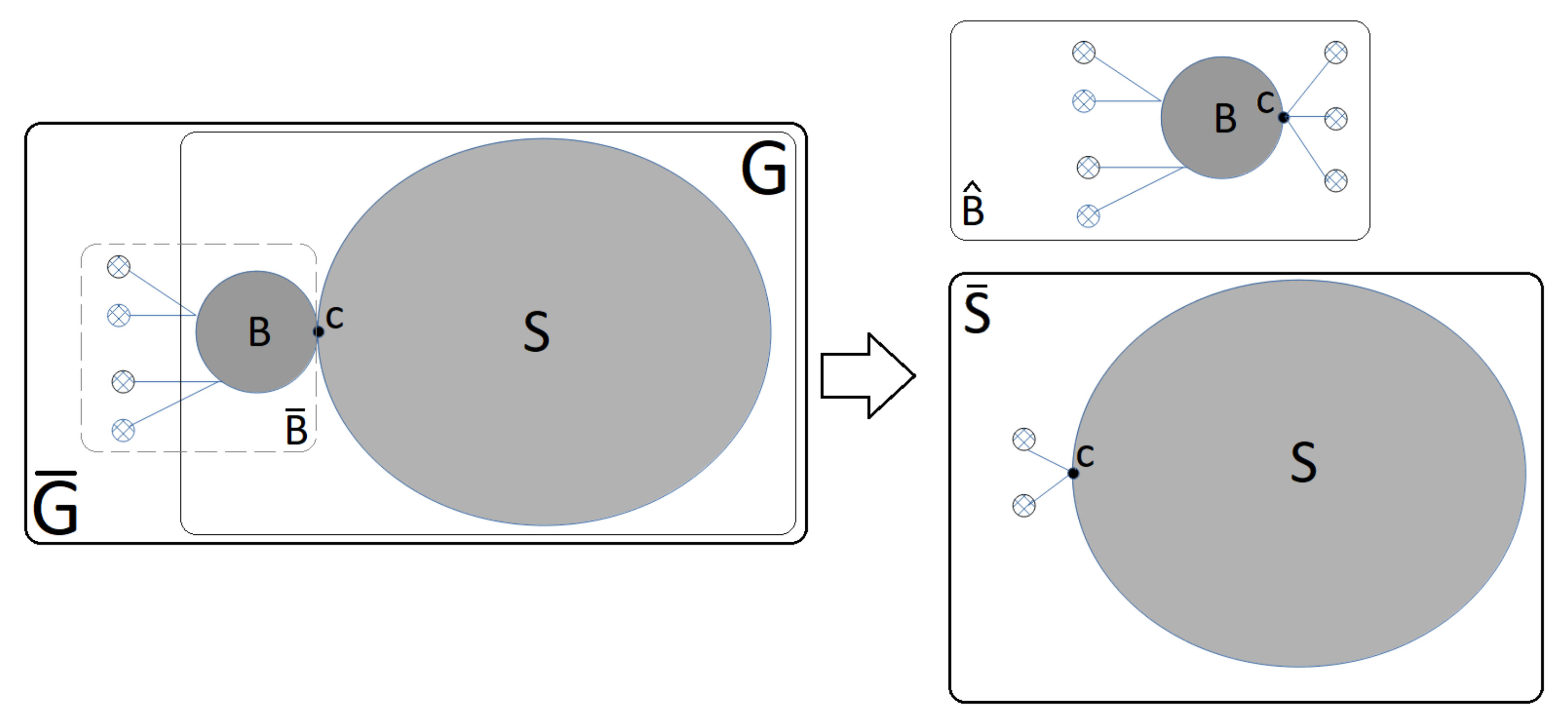
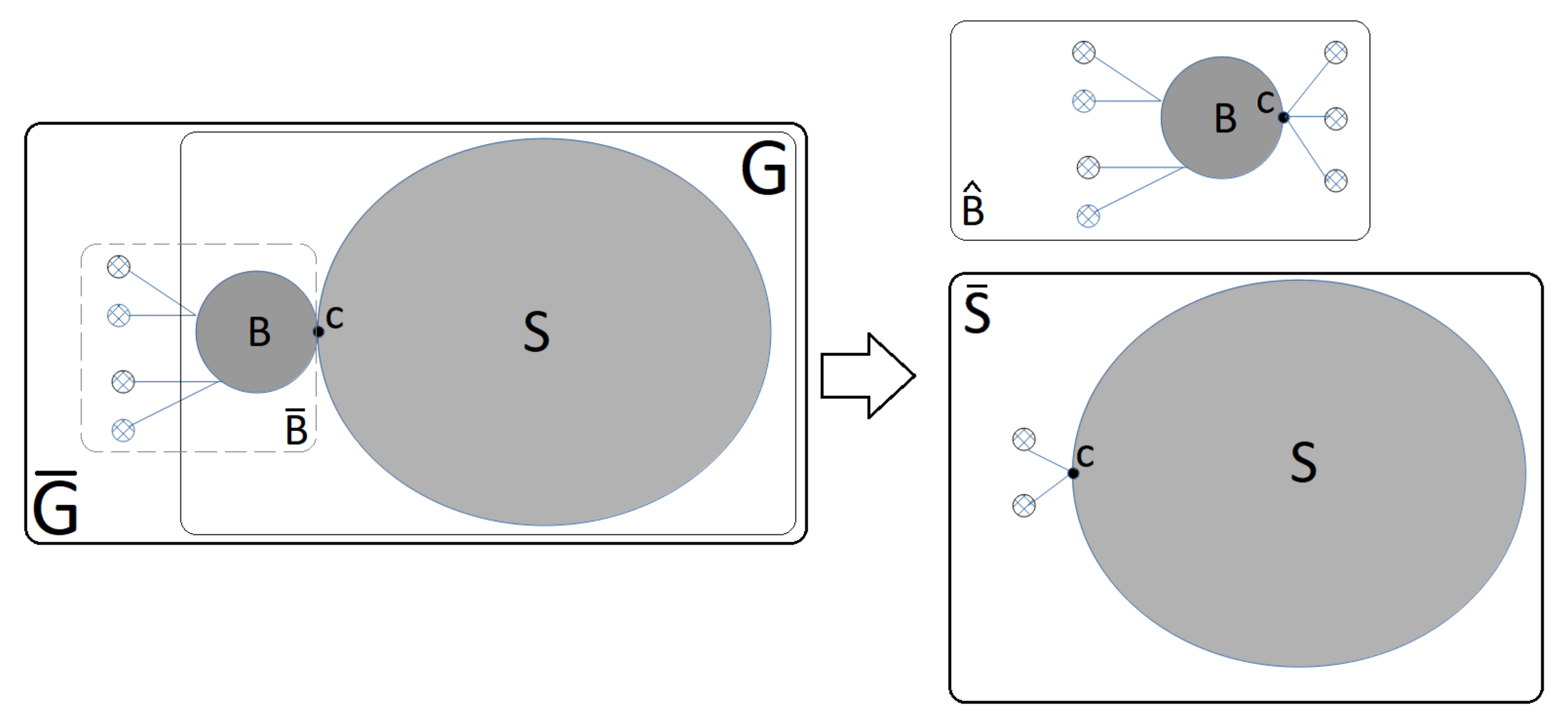
Figure 4 represents the elements that are used in the propositions. These usually are:
A separable graph ;
A leaf block ;
A cut-vertex of B named as c;
A connected subgraph such that and
An augmented block with allied nodes of weight 0 added to B named as ; and
.
The solved MC-AkDP problems are related to and the added allied nodes of Weight 0 depend on the previously solved blocks. The added allied nodes force to obtain dominating sets which are consistent with the dominating sets of the blocks already solved. We could say, in a colloquial way, that the added allied nodes are the links to the previously solved problems.
Each graph is solved in two steps. First, the graph obtained by adding allied nodes to (Proposition 1) is processed. Then, the graph is obtained by adding a number of allied nodes to S to be processed. The number of allied nodes added to S depends on the result obtained when was processed (Proposition 2).
An algorithm for matching the different obtained partitions is described (Algorithm 2) and discussed (Propositions 6 and 7). Finally, Proposition 8 proves that Algorithm 1 returns a domatic partition of G.
Proposition 1. Let
be a separable graph;
be a leaf block;
c be the cut-vertex of
be the connected subgraph such that and
be an augmented block with allied nodes of Qeight 0 added to B;
; and
be the graph obtained by adding allied nodes to .
If MC-AkDP has a solution, then MC-AkDP also has a solution.
Proof. A feasible solution consists of grouping the nodes of in the same way that these nodes are grouped in a partition for obtaining allied dominating sets in which is possible since MC-AkDP has a solution and allied nodes were added to . Note that these allied nodes do not have to be dominated, but they contribute to the domination of c. □
Corollary 1. Proposition 1 is valid independently of the weights imputed to the allied nodes added to .
Proof. That is because the weights only affect the objective function but neither the number of allied nodes to add nor to the feasible region. □
Corollary 2. In Proposition 1, if the allied nodes added to are weighted by 1 and MC-AkDP then is the maximum number of sets in that can dominate c in a MC-AkDP solution.
Proof. Since the allied nodes added to when is built are weighted by 1, then represents the minimum number of allied nodes needed to get allied dominating sets That implies is the maximum number of disjoint sets in that dominate c. □
Proposition 2. Let
be a separable graph;
be a leaf block;
c be the cut-vertex of
be the connected subgraph such that and
be an augmented block with allied nodes of weight 0 added to B;
;
be the graph obtained by adding allied nodes with weight 1 to ;
MC-AkDP;
be the graph obtained by adding allied nodes to S.
If MC-AkDP has a solution, then MC-AkDP also has a solution.
Proof. By reductio ad absurdum, if MC-AkDP does not have a solution, it would either be because not enough allied nodes were added to , or even adding infinite nodes does not guarantee that a solution can be obtained. On the one hand, if it would be possible to add more allied nodes to to achieve a solution to MC-AkDP then MC-AkDP would not have a solution: according to Corollary 1, if the maximum number of disjoint sets in that can dominate c were added, then no more allied nodes can be added. On the other hand, if even adding infinite allied nodes to would not yield a solution, it would be because MC-AkDP does not have a solution. Note that in case the solution exists, it would be enough to group the nodes of S in the same way these are grouped in a MC-AkDP and then provide as many allied nodes as needed to get allied dominating sets. □
Corollary 3. Propositions 2 are valid independently of the weights imputed to the allied nodes of .
Proof. That is because these weights only affect the objective function of MC-AkDP but not the number of allied nodes to add, nor the feasible region. □
Proposition 3. Let
be a separable graph;
be a leaf block;
c be the cut-vertex of
be a connected subgraph such that and
be an augmented block with allied nodes of Weight 0 added to B;
;
be the graph obtained by adding allied nodes with Weight 1 to S; and
be the graph obtained by adding allied nodes to S.
If MC-AkDP or MC-AkDP has no solution, then MC-AkDP has no solution.
Proof. On the one hand, if MC-AkDP has no solution, that is because MC-AkDP also has no solution, otherwise a solution of MC-AkDP would be obtained by grouping the nodes of in the same way these are grouped to obtain allied dominating sets in .
On the other hand, if MC-AkDP had no solution, it would be because either not enough allied nodes were added to or because even adding infinite allied nodes to a solution would not work. In the first case, if it would be possible to add more allied nodes to to achieve a solution to MC-AkDP then MC-AkDP would have no solution—according to Corollary 1, if the maximum number of disjoint sets in that can dominate c were added, then no more allied nodes can be added. In the second case, if by even adding infinite allied nodes to a solution could not be obtained, that would clearly happen if MC-AkDP has no solution. □
Corollary 4. Let
be a separable graph;
be a leaf block;
c be the cut-vertex of
be the connected subgraph such that and
be an augmented block with allied nodes of Weight 0 added to B;
;
be the graph obtained by adding allied nodes with weight 1 to ;
MC-AkDP; and
be the graph obtained by adding allied nodes to S.
if and only if both MC-AkDP and MC-AkDP have a solution.
Proof. Remember that is the maximum , such that MC-AkDP has a solution. On the one hand, Propositions 1 and 2 guarantee that if MC-AkDP and MC-AkDP have a solution, then MC-AkDP also has a solution. On the other hand, Proposition 3 says that if MC-AkDP or MC-AkDP have no solution, then G cannot be partitioned into allied dominating sets. Thus, can be partitioned into allied dominating sets or what is the same, , if and only if both MC-AkDP and MC-AkDP have a solution. □
Corollary 5. Let
be a separable graph;
be a leaf block;
c be the cut-vertex of
be the connected subgraph such that and
be the augmented block with allied nodes of weight 1 added to B
MC-AkDP
; and
be the graph obtained by adding allied nodes to S.
if and only if both MC-AkDP and MC-AkDP have a solution.
Proof. Trivial from Corollary 4. It is the particular case in which has 0 allied nodes. □
Let be a separable graph, a leaf block, and a connected subgraph such that . Since if and only if both MC-AkDP and MC-AkDP have a solution (Corollary 5), then one way to calculate consists of setting by enumerating, for example, by increasing it sequentially from until no solution exists or decreasing it sequentially from until both MC-AkDP and MC-AkDP have a solution. Other strategies could also be designed in order to save explorations, such as increasing/decreasing procedures with some steps larger than 1.
Proposition 4. Algorithm 1 returns the domatic number of G.
Proof. Algorithm 1 solves , sequentially decrementing from . At each iteration it starts trying MC-AkDP and MC-AkDP, given that if both problems have a solution, that would mean (Corollary 5). Each MC-AkDP is recursively solved by decomposing it into leaf blocks according to Proposition 3 until S is also a block. That is equivalent to sorting and solving the blocks from the leaf blocks to the root block as Algorithm 1 does. □
Proposition 5. For each block let be a partition of built by Algorithm 1 but excluding the allied nodes in each subset in . Then, a domatic partition of G is obtained by consistently matching the partitions .
Proof. Each block is solved by adding a number of allied nodes which represent the number of dominating sets that dominate a shared cut-vertex. Its MC-AkDP solution provides dominating sets. Thus, it is possible to find a domatic partition of G by consistently matching the partitions . Note that if the indexes j of the allied nodes were fixed to 1 in variables then the matching would not be necessary. □
The algorithm that we propose for matching the partitions is Algorithm 2. It starts with partition and finishes with a domatic partition. Partition splits the nodes in into subsets. Nodes in V that are not in are successively aggregated to so that the final partition has all the nodes in As in the description of Algorithm 1, we illustrate Algorithm 2 with the match in the example, and then we write the general matching procedure.
In our example,
is the partition in
(
is not a domatic partition of
) and it is of size
Recall that
is not a partition of
is
(first row, second column in
Table 1). The union of the rest of the partitions is
The spirit of the matching algorithm (Algorithm 2) is to complete the
sets in
with the rest of nodes, that is, with the nodes
in such a way that the three final sets are a domatic partition of
Using colours to explain the idea, if we imagine that each set of the partition
is a different colour—for instance, that node 4 is dark grey, that nodes 5 and 8 are grid grey, and that node 9 is light grey—the domatic partition nodes in
will keep their colour, and nodes in
will be inserted in these sets in such a way that any two nodes sharing a set in
will have the same colour. We iteratively incorporate nodes of
to the sets of
in order to provide every node
v in
with a neighbour in the sets to which
v does not belong. In particular, we look for a pair of nodes, one
v in
and another
in
such that there is a set in
which does not have common nodes with the neighbourhood of the former
, and the second belongs to this neighbourhood
For instance, nodes
and
satisfy both conditions:
and
Then, we add node 3 and the nodes sharing with node 3 a set in
to the set in
that had an empty intersection with the neighbourhood of 4, that is, we add nodes 2 and 3 to the set
In terms of colours, nodes 2 and 3 will be the same colour as node 9 (see
Figure 5), which makes sense since nodes 2 and 3 must be the same colour because they belong to the same set in
Then, we remove from
all the sets that contain nodes in
and we add the nodes in the removed sets to the sets in
with the common element. In the example, we remove sets
and
and we do not add anything to
because both are sets with only one node. The resulting set of sets
is the initial partition in the next iteration of the algorithm. We continue until
is empty.
Table 1 shows the evolution of
and
through the five iterations in the example. Finally, the domatic partition is
This is illustrated in
Figure 5.
The general procedure is described in Algorithm 2. It needs all the partitions obtained in Algorithms 1, and 2 adequately pastes them.
Let be the partition of obtained in Algorithm 1. Let be the union of the rest of the partitions from Algorithm 1. Let be the set of nodes of the elements and let be the set of nodes of the elements. For each v in V and each set of sets of let be a set in that contains node Algorithm 2 reads as follows.
Proposition 6. While Algorithm 2 does not finish (while ), it is possible to locate a vertex such that there exists a and , and also to locate a vertex (lines 4 and 5 of Algorithm 2).
Proof. On the one hand, if there were no , that would mean the domatic partition has already been found. On the other hand, if there were but , that would mean it is not possible to find a domatic partition of G, which cannot happen according to the Propositions 4 and 5. □
Proposition 7. Algorithm 2 gets a domatic partition of G from the partitions of the blocks provided by Algorithm 1.
Proof. First of all, note that always has a domatic number of subsets. Second, since the algorithm successively finds a node v in that is not dominated by a subset t, and given that according to Proposition 6 it is possible to incorporate into t a subset in that dominates then the Algorithm 2 obtains a domatic partition of G. □
Proposition 8. Algorithm 1 returns a domatic partition of G.
Proof. Given that Algorithm 1 calls Algorithm 2, providing it with allied domatic partitions of each block in then according to Proposition 7, a domatic partition of G is obtained. □
4. Computational Experience
We carried out a computational experience in order to analyse the performance of the decomposition method proposed to compute the domatic partition in graphs with blocks. We tested our techniques over a set of 117 randomly generated instances. Specifically, these instances contain from 100 to 400 nodes, progressively increasing the size from 25 to 25, that is, 100, 125, …, 400 nodes. In turn, it generated nine different instances for each one of these node sizes, according to the densities , , , , , , , and . That is, we have nine instances of 100 nodes, and respectively 150, 250, 500, 750, 1000, 1250, 1500, 1750, 2000 edges; nine instances of 125 nodes and respectively 188, 313, 625, 938, 1250, 1563, 1875, 2188 and 2500 edges; and so on. Apart from the randomness employed to generate these instances, they were generated in such a way that a Hamiltonian cycle can be found in every one. Finally, each one of them were joined up with itself from the initial node in such a way that the final instances have two symmetrical blocks and they cover from 199 to 799 nodes progressively, increasing the sizes from 50 to 50.
Our experiments were conducted on a PC with a 2.60 GHz Intel Xeon, 64 GB of RAM, and Ubuntu 18.04.5 LTA operating system. The instances were solved twice by linear integer programming, using both the general method and the decomposition approach. To solve the linear integer models, we used the optimisation engine IBM ILOG CPLEX Interactive Optimiser 20.1.0.0, setting a max computing time per instance of 3600 s.
Table 2 summarises the computational processing times grouped by nodes of the instances that were concluded by both methods during the processing time limit. Column #
solved shows the number of nine instances solved both by the DP model and by Algorithm 1. Column
DP time shows the average time in seconds it took to solve the model (DP), that gives the domatic number
and the domatic partition. Column
Algorithm 1 time shows the average time in seconds it took to solve Algorithm 1, that also gives
and the partition. The last row shows the global average for both methods, which is clearly advantageous for the decomposition approach, with an average time of
s versus
s of the general method. The more prominent advantage was obtained in the instances of 549 nodes which needed an average of
s to be solved by the optimisation model approach, whilst the decomposition approach only required an average of
s.
Instances with 599 to 749 nodes may seem easy instances due to the average times listed. However, the fact is that a lot of instances of these groups did not conclude, and therefore only the times of the easy instances were taken into account. In this respect,
Table 3 provides information about the instances that have not been completed for each group and method. The DP model could not solve 37 of the 117 instances within the time limit, whilst the instances not solved by the decomposition method were 28. Note how only five of the nine instances for the groups of 599 to 749 nodes were solved by the general method. Finally, the major advantage of the decomposition approach was obtained in the group of 599 instances where the decomposition method solved seven instances, whilst the general only solved five.
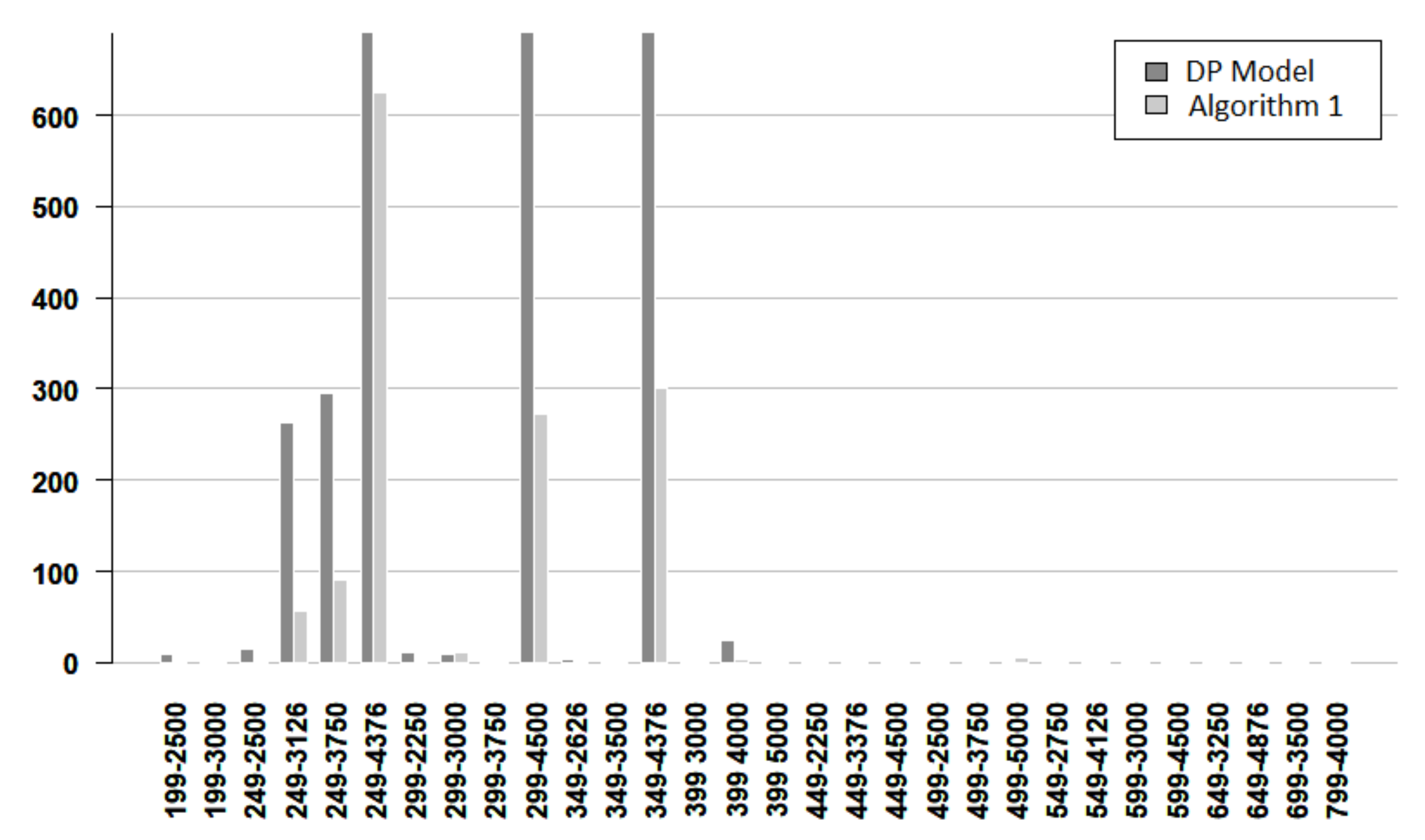
The instances that Algorithm 1 could not complete were not concluded by the DP model either. Conversely, there were nine instances concluded by the decomposition approach that could not be concluded by the DP model. The details of each one of these last instances are shown in
Table 4. Columns
# nodes and
# edges respectively indicate the number of nodes and edges of each instance,
the value of the best feasible solution found by the DP model,
the optimal value found by Algorithm 1, and finally, Column
time indicates the solution time employed by Algorithm 1. Note that the best feasible solution found by the DP model just coincides with the optimal solution in the first instance. We also highlight that the solution time for the three last instances is very small.
Given that the processing difficulty of the instances is more correlated to the number of edges than to the number of nodes, we have also obtained several tables summarising the results according to their number of edges. We classify the instances into three groups: easy, medium and hard.
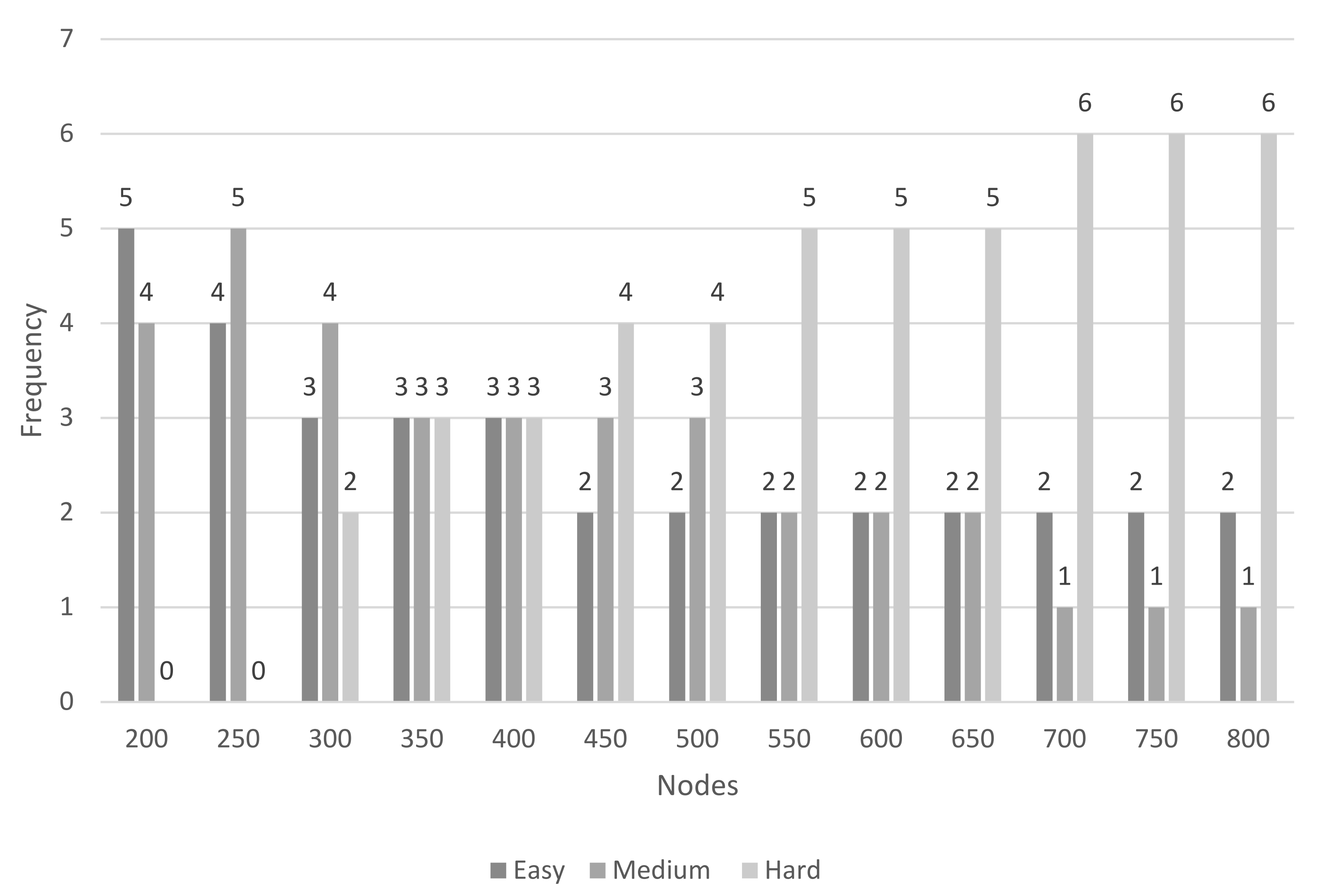
Table 5 shows the criteria followed to classify the instances according to the number of edges, as well as the number of instances belonging to each level of computational hardness.
There are easy instances with any number of nodes, but there are hard instances with only 300 nodes or more.
Figure 6 shows the frequency of each type of instance for each number of nodes.
Table 6 and
Table 7 aggregate the information in
Table 2 and
Table 3 respectively by difficulty. The former gives the average time, and the second, the number of unsolved instances. The last rows (average and total) coincide with the last rows in
Table 2 and
Table 3. Observe that the DP model did not solve 34 of the 49 hard instances, whilst Algorithm 1 did not solve 25 of them.
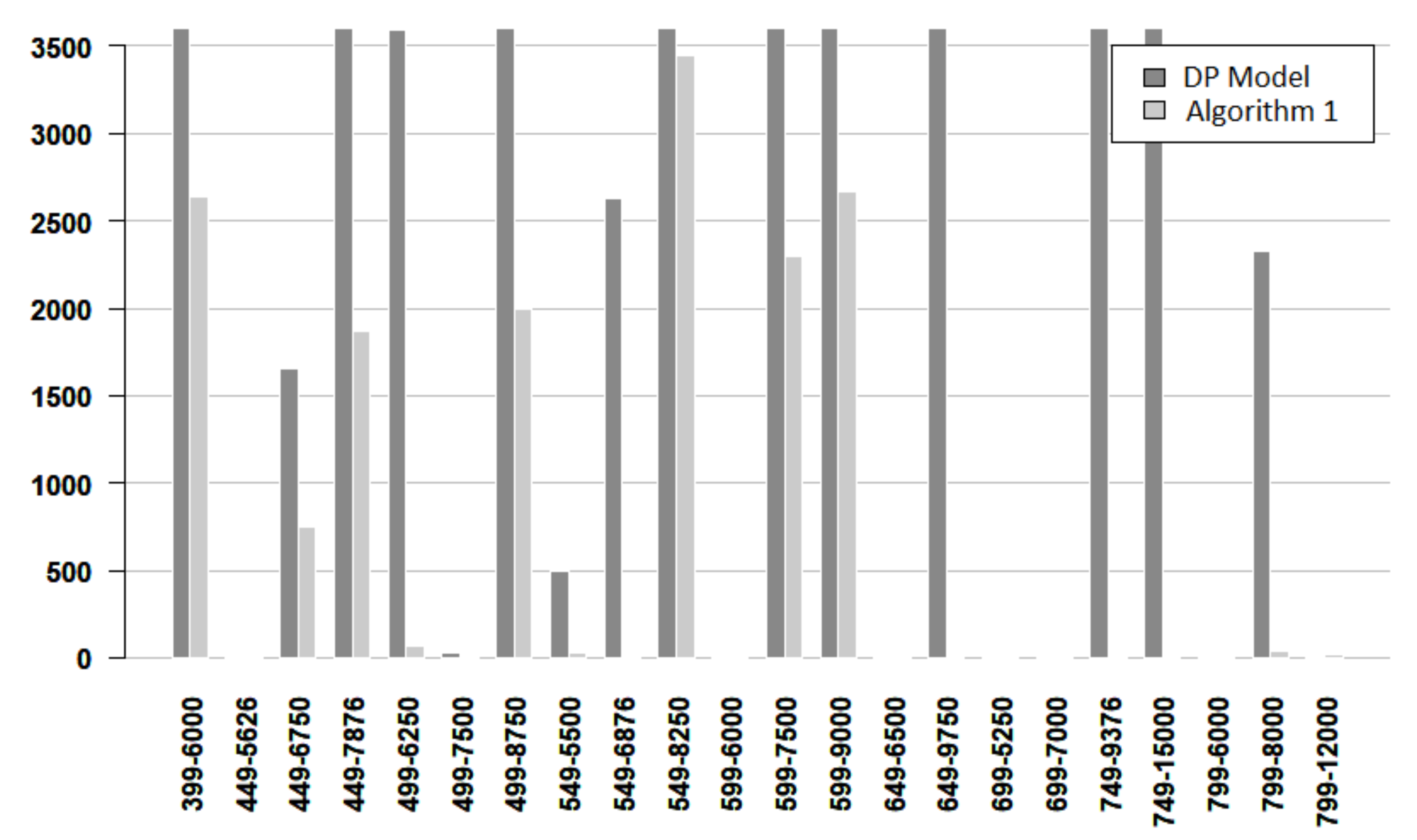
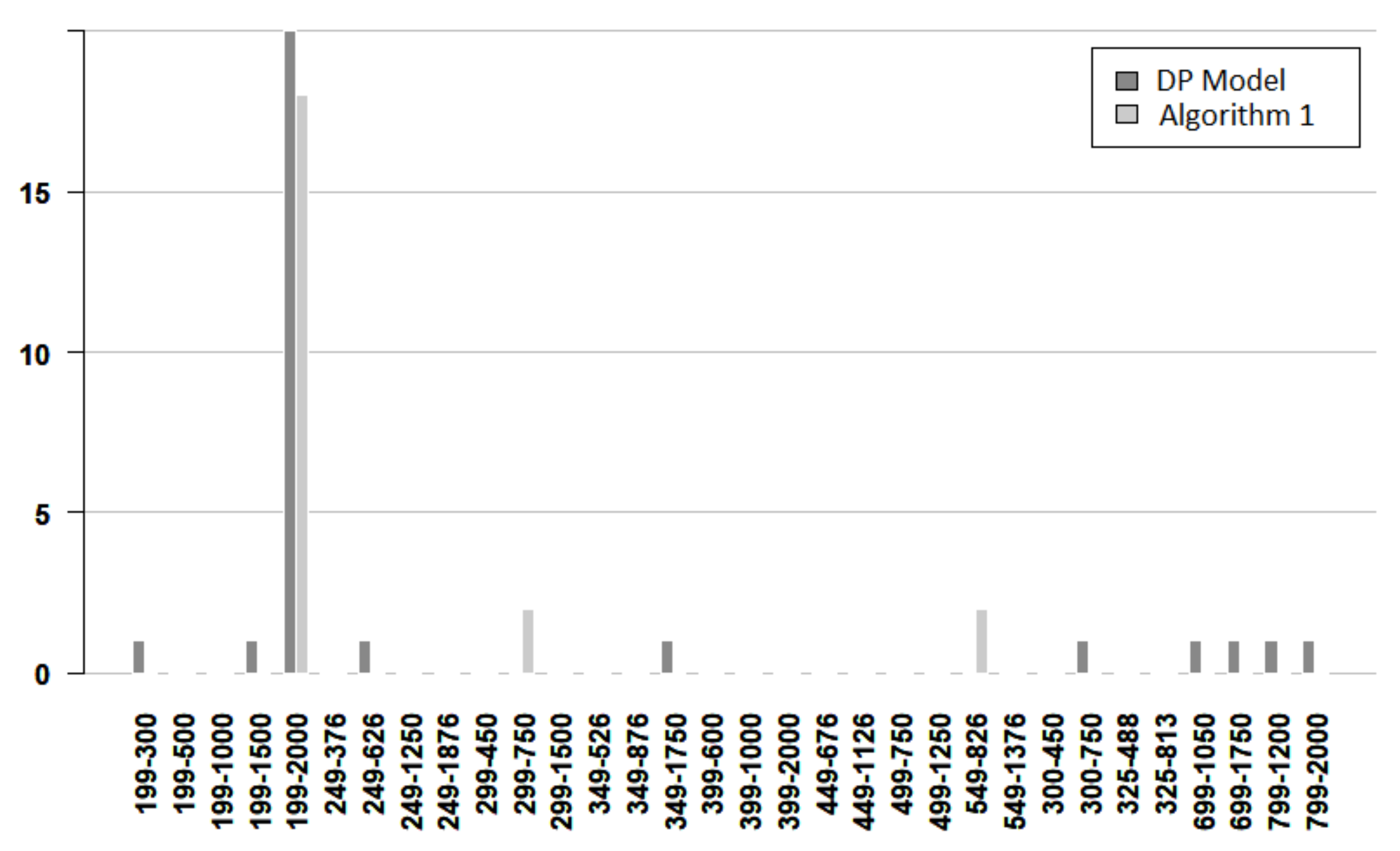
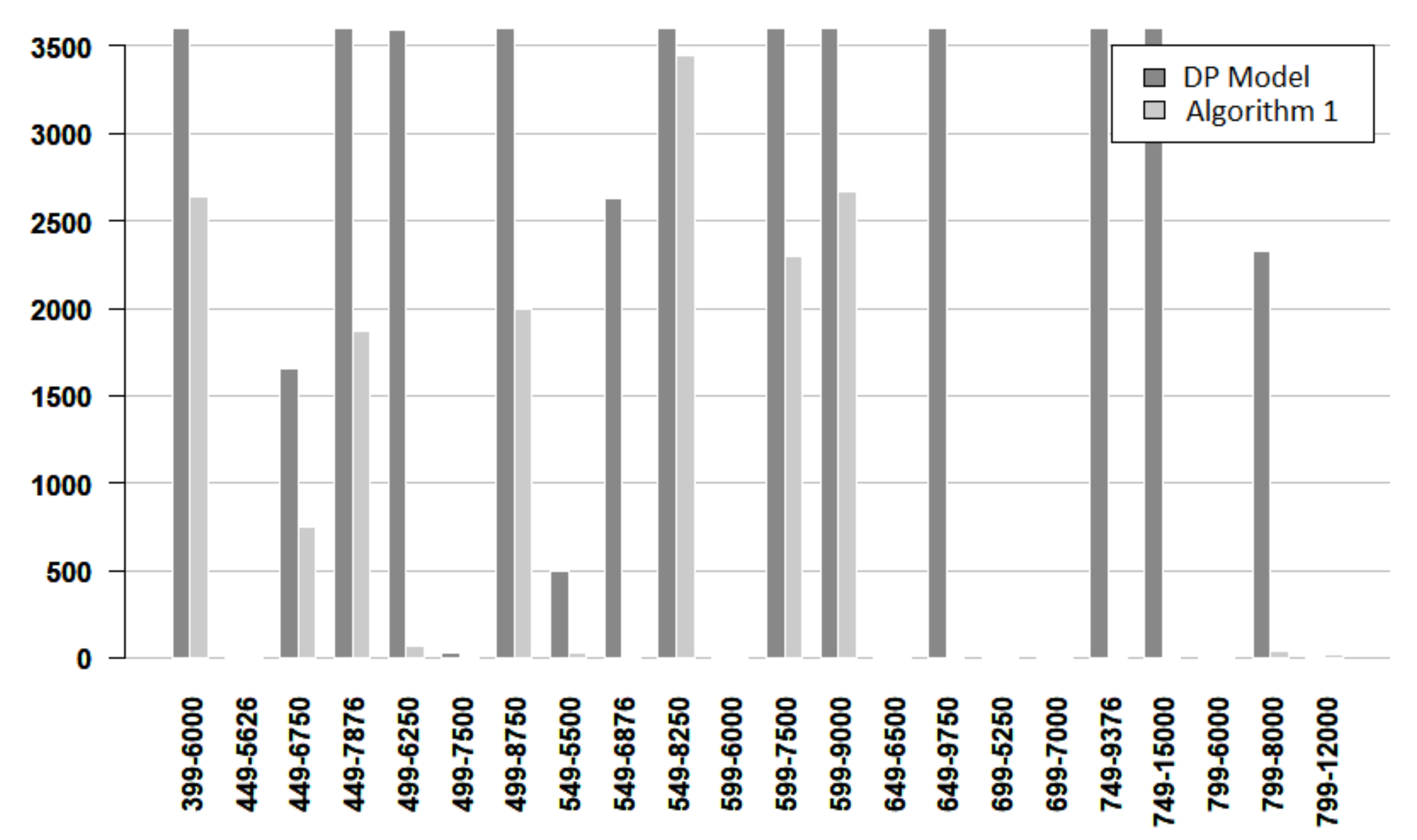
Figure 7,
Figure 8 and
Figure 9 give more details about the resolution time for solving the DP model and Algorithm 1. The vertical axis denotes the time and the horizontal axis indicates the instance. Each instance is named by its number of nodes and its number of edges. From these figures, it follows that most of the easy instances are solved in less than 5 s, and there are more DP bars than Algorithm bars. For easy instances, only one instance required more than 5 s, and the algorithm used less time for concluding. For medium instances, most of the times are very small, but when the time is larger than 10 s, the algorithm works faster. For hard instances, the bars for the DP model are always larger than the bars for the algorithm. Furthermore, in some cases, the algorithm time bar is negligible, while the DP time bar exceeds 2000 s.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}