1. Introduction and Preliminaries
Consider a collection of n assets and let us denote by the collection of random rates of return of the collection, and by the vector of expected return of these assets, that is . A portfolio with no short positions consists of a vector such that and the expected return of the portfolio is given by . Here . The class of admissible portfolios is defined by
An investor interested in obtaining the maximum possible return on her investment needs to solve the following problem:
Certainly, this problem has a solution and it is a corner of
. However, this solution is not satisfactory because it ignores some essential issues. Most notably, neither the risk nor the diversification of the portfolio is taken into consideration. There are many ways of setting up a satisfactory (risk, return) balance, and each one of them leads to a solution to the problem. The classical, and most widely used, mean-variance solution by [
1] has been known for long to be highly sensitive to parameter estimation errors (e.g., of covariance matrix and especially mean vector of assets returns, see [
2]). Several solutions have been proposed for a robust portfolio optimization within this paradigm based on a trade-off of risk and return [
3].
The other relevant issue related to the classical Markowitz proposal is the diversification issue. Diversification appears to be an intuitive concept but as with the notion of risk, there does not seem to exist an agreement on how to specify and measure it. From a practitioner perspective, it is widely accepted that a well-diversified portfolio is one where shocks to individual components do not heavily affect the overall performance of the portfolio. This qualitative definition translates in the mean-variance model to an increase in the number of uncorrelated constituents in the portfolio, as it is clear that the larger the number of (uncorrelated) assets the lower the overall variance of the portfolio, and this can be driven to almost zero in an equally weighted portfolio. However authors such as [
4] show that in the case of equity mutual funds in spite of the huge number of stocks they hold (more than 100 in many cases) their portfolios are not perfectly diversified, in terms of risk reduction; reference [
5] show that in non-Gaussian return distributions, increasing portfolio sizes could not reduce monotonically large risks, and instead a lower number of assets could improve diversification in a bear market. In any case, for the practitioner diversification of a portfolio is still tied to a play with size (number of assets) and approximate weights to uniform distribution. A recent extensive review of the research literature dealing with the relation of number of assets and portfolio diversification is given in [
6], and a more general review of diversification in portfolio theory, with focus on its defining principles, usefulness and measurement is given in [
7].
Supervised methods to achieve diversification based on risk reduction, such as the MV optimization approach for minimizing the variance, in practice tend to concentrate on very small subsets of the portfolios of interest (more often than not, on a single asset), and this goes against the former accepted notion of diversification, which asks for a reasonable number of assets with similar weights in the portfolio. A prior proposal in which diversification is taken into account along with risk and return tradeoff is that of [
8]. They minimize an entropy divergence between the unknown portfolio and that of the naive portfolio subject to return-risk constraint. In this way they achieve a shrinkage towards the maximum diversification as high as possible while maintaining the risk-return constraint. The use of entropy as a measure of diversification in portfolio selection has been validated previously in [
9].
Our proposal goes in a related, but quite different direction. We start from a portfolio that satisfies some benchmarking criterion in terms of diversification and risk tolerance, define an acceptable region in portfolio space about the benchmark, and then solve a constrained return maximization problem within that acceptance class of well diversified portfolios. This constrained linear programming problem is an alternative way to achieve shrinkage towards the benchmark.
To be explicit, let us denote by
the well diversified benchmark and define the set of admissible portfolios by
It is the specification of the , that determines the risk for the portfolios in . Consequently the focus of our attention is on the following problem
Problem 1. Determine a portfolio at which reaches its maximum possible value. That is, find For the solution of this problem we will use the method of maximum entropy in the mean (MEM). For this consider [
10]. MEM uses the standard entropy maximization method as a stepping stone to solve ill-posed, constrained, linear inverse problems. It is here where our approach differs from that of [
8]. They use a cross-entropy minimization procedure under mean variance constraints to obtain a portfolio with good diversification properties. We use the MEM to solve a sequence of constrained linear equations as a way to solve a constrained linear programming problem by a variant of the interior point approach. The mathematics of this approach was initially worked out in [
11]. As mentioned above, for us the constraints come from a preassigned band about the benchmark well diversified portfolio, and at the end we shall end with the portfolio that has a maximal return in the region of well diversified portfolios. We remark that we do not strive for efficiency in the Markowitz (risk, return) sense. Instead we start from a well diversified portfolio and improve its return while maintaining a high degree of diversification. Thus, our portfolios are efficient in the sense that it provides the highest possible returns at a given level of diversification.
The process is as follows: Starting with we increase the return in small steps and solve
This is the problem to be solved with MEM. We increase
r in small steps until no solution to this problem exists. The last
r for which the interior point method has a solution is an approximate solution to the linear programming problem. We explain how this is done in
Section 2. In
Section 4 we report our numerical examples, and for that we first explain in
Section 3 how the admissible portfolios are specified.
Section 5 concludes.
2. The Maxentropic Solution to Problem 2
Instead of solving an algebraic problem, we consider a linear, inverse ill-posed problem consisting of determining a probability measure
P on
such that
satisfies Problem 2. Here
is the identity mapping. On a
-algebra of Borel sets on
we consider the reference measure
which puts unit mass at the vertices of
The reasons behind this choice are twofold: On the one hand, the computations are simple, and on the other, is the fact that any point in any of the intervals is a convex combination of its extreme points. Before continuing, note that any
can be written as
. In particular, the entropy
of the probability
P with respect to the reference measure
Q is given by
It is to find the appropriate that we use the method of maximum entropy. Our problem consists of
Note that the last constraint in Problem 2 is automatically taken care of by this problem set up. It is a routine calculation to verify that the solution to Problem 3 is given by
The Lagrange multipliers are to be found minimizing the (dual entropy) function
This is a strictly convex function on
. Once the minimizing values
have been determined they are substituted in (
4), and then the desired portfolio is given by
The existence of the minimizer is equivalent to the existence of
in the interior of
achieving that return. When the optimization problem has no solution, the minimizer tends to infinity (in the
Appendix A we explain why that happens).
To find the portfolio in that maximizes the return fix some step size and consider and . If for some there is a portfolio of return but no portfolio of return we stop and the maximum possible return is between and that is our estimation error is smaller than Here the problem solver must choose between increasing r fast and lowering the approximation error.
4. Numerical Examples
This section is divided into three parts. In the first part we apply the two criteria for choosing a well diversified benchmark from
Section 3.1 and show explicitly how the method of maximum entropy for benchmark tracking works. That is, we explain how we choose a benchmark and examine the effect of applying the maxentropic procedure to obtain a portfolio of maximum expected return within the admissible class. We perform some simple tests. This could be considered an examination of the performance of an interior point method to solve a linear programming problem.
As the input data for the method depends on market data, that is on the average returns of the collection of assets of the portfolio, in the second section we study the robustness of the procedure by averaging over portfolios held for a rebalancing period of 5 and 20 days. In each case we start from a well diversified portfolio
with expected return
at the beginning of the period and end up with a portfolio
of return
at the end of the rebalancing period. Then we average the initial and final returns for these simulations and perform a variety of performance tests. The reason why some smoothing is expected is the following. If we denote by
the vector of initial expected returns of the well diversified portfolio for the
k-th simulation and, similarly, denote by
the vector of maximized returns at the end of the investment period in the
k-th simulation, where by
we denote the improvement in the expected return after the MEM procedure is applied to the well diversified portfolio, then if
K denotes the number of simulated rebalancing of portfolios, the expected return of the portfolio which is held constant over the simulations is given by:
This identity explains why, even though for each specific initial return the return of the optimized portfolio improves considerably, when we average over all input/output pairs, the performance looks less impressive than the results of the previous section.
In the third subsection we perform a similar analysis for a non-necessarily well diversified portfolio. The two examples we consider are a Markowitz portfolio [
1] and a quintile portfolio [
16].
4.1. How the MEM Procedure Works
To illustrate the workings of the maxentropic benchmark tracking, we considered a collection of stocks of companies belonging to the DAX index and obtained their daily close prices for a period of 500 market days from which we computed their expected daily rates of return.
For this collection of assets we consider the following two diversified portfolios: First the naive portfolio, with weights and then a portfolio that reflects the market capitalization computed as divided by the market capitalization of the collection, that is We refer to this portfolio as the relative capitalization portfolio.
For the numerical examples we considered a uniform band defined by and written in such a way that could be changed. We considered to begin with. The step size is taken initially as 10% of the portfolio (by the rationale that an investor would expect to increase its original investment by that much). However, we incremented the portfolio target return from step to step using the corrected recursion , so that the increments are smaller as the step number s increases.
4.1.1. The Naive Portfolio Is the Benchmark
For each of the 15 stocks, we show in
Table 1 its weight in the naive portfolio (the quantity to the left of the |, which is
), and its weight in the portfolio that maximizes return in the admissible band about the naive portfolio (the quantity to the right of the |).
The daily rate of return of the naive portfolio is 0.013% which is annualized to 3.3%. After applying the maxentropic procedure the new portfolio has a daily rate of return of 0.024%, which is annualized to 6.15%, that is almost twice as much as that of the naive portfolio.
We mention that the norm of the gradient of the dual entropy was less than , which means that the constraints are satisfied up to six decimal figures.
The Herfindahl index of the naive portfolio is whereas that of maximum return is . Both portfolios appear to be quite well diversified. That not much diversification is lost seems intuitive on the basis of basic analysis: is a continuous function and the neighborhood about is small, so not much diversification appears to be lost.
4.1.2. The Relative Capitalization Portfolio Is the Benchmark
We already explained how to produce a well diversified portfolio for this example. This benchmark is a substitute of the market portfolio in terms of risk-return performance and we assume that it incorporates some market driven notion of diversification. In
Table 2 we show the weights of the initial relative capitalization portfolio (left of |) and the weights of the portfolio that maximizes return in the admissible band about the relative capitalization portfolio (right of |).
The average daily rate of return of the initial relative capitalization portfolio is 0.014% which annualizes to 3.7%, which is a bit higher than that of the naive portfolio. The expected daily rate of return of the portfolio that maximizes return in the admissible band is 0.027% which annualizes into 6.9%, again almost twice as much, and the portfolio stays in the preassigned band about the well diversified portfolio. The Herfindahl index of the relative capitalization portfolio is whereas that of maximum return is , a close value to the former hence keeping a similar level of diversification.
4.1.3. The Maximum Return Portfolios in Relation to the Benchmarks
Above we saw that given that the region of the well diversified portfolio in which we maximize returns is small so as not to lose diversification, we need some way to quantify how different the portfolios are. For this we use the dissimilarity measures defined previously. The Jeffrey’s distance between two portfolios
and
is computed as indicated in (
7) and the Kullback–Leibler divergence is computed as indicated in (
8).
As one can observe in the two cases the small values in both metrics indicate the closeness of both portfolios.
4.2. The Average Performance of the Procedure in Real Life
In order to illustrate the practical usefulness of the MEM diversified portfolio selection method we performed a large number of randomized backtests on a list of portfolios over multiple historical market datasets obtained on a rolling-window basis. The raw historical market data on a daily period is obtained for two international equity indices: The German DAX from 2009-01-01 to 2019-12-31 (for small size portfolios), and the US SP500 from 2008-12-01 to 2018-12-01 (for big size portfolios). Each historical market data is resample into multiple datasets; each resample is obtained by randomly choosing a subset of the stock names (15 for the DAX index, 50 for the SP500) and randomly choosing a time period of 2 years (or 504 days) over the available long period. We apply a rolling window of length 1 year (252 days) for a walk-forward backtesting where the in-sample and out-of-sample windows are constantly shifted. In the in-sample window we estimate parameter values of each portfolio strategy (e.g., covariance, mean, and others). Using the estimated parameters, the optimal portfolio for each considered model is calculated, and tests its performance in the out-sample window by holding the portfolio with the optimal weights through a specific period. We tested for out-sample holding periods of 5 days (a week) and 20 days (one month). Walk-forward backtesting provides a historical simulation of how each portfolio strategy would have performed in the past. This has a clear historical interpretation and its performance can be reconciled with paper trading (for further details see [
17]).
Note that our goal is to determine how the MEM diversified portfolio selection impacts on the performance of the associated diversified benchmark portfolio. Thus, if X is some portfolio selection strategy we denote by MEM_X the MEM diversified portfolio selection on top of X. For our experiments we will consider X to be: naive (i.e., equally weighted portfolio) and capital (the market capitalization based portfolio, each weight computed as divided by the market capitalization of the collection, that is ). The respective MEM diversified portfolios will be denoted MEM_Naive and MEM_Cap.
To evaluate the performance of each model, we use the following measures: Sharpe ratio (the ratio between the (geometric) annualized return and the annualized standard deviation), Maximum Drawdown (the maximum loss from a peak to a trough of a portfolio), annual return, annual volatility (as annualized standard deviation of returns), and Sterling ratio (the annualized return over maximum drawdown). We also compute the Herfindahl concentration index for each portfolio as an indicator of diversification relative to the naive portfolio (i.e., a well-diversified portfolio of
n assets should have its H-index close to
). All portfolio backtesting experiments were performed with the R package portfolioBacktest [
18].
Results for the German market, where we build portfolios of 15 stocks randomly selected from the DAX and for up to 30 price scenarios are shown in
Table 3 (for portfolio rebalancing every 5 days) and
Table 4 (for portfolio rebalancing every 20 days). Results for the US market, where we build portfolios of 50 stocks randomly selected from the SP500, and for up to 30 price scenarios, are shown in
Table 5 (for portfolio rebalancing every 5 days) and
Table 6 (for portfolio rebalancing every 20 days). The bandwidth factor
is fixed at 0.6 (after trying several values ranging from 0.5 to 0.9 and found little variation in the results). Bear in mind that all performance results are average values over all the considered trading scenarios.
We saw in the first section that the expected return relative to that of the benchmark can be increased by appropriately modifying the portfolio. As we saw in the simulations, realized returns might be smaller than expected returns. Our scenario simulation nevertheless shows that the annual returns of the modified portfolio are larger than those of the benchmark without affecting the diversification. We mention that the other performance measures (Sharpe ratio, maximum drawdown and the Sterling ratio described a few lines above) listed in the tables are satisfactory. It appears that the procedure also decreases the volatility of the maximum return portfolio even though this was not an objective of the maxentropic benchmark tracking procedure.
4.3. The MEM Procedure Applied to a Non Well Diversified Portfolio
As it should be clear, the MEM procedure could be applied to any portfolio, regardless of its being well diversified or not. For this we considered a Markowitz type portfolio and a quintile portfolio. Recall that the quintile portfolio consists of sorting assets from high to low by expected return and selecting the top 20% for long-only positions. The mathematical soundness of this strategy as a solution to robust portfolio optimization is analyzed in [
16].
We defined a band about the two chosen portfolios for the purpose of maxentropic approach to return augmentation within the acceptable band about the benchmark. Keep in mind that now the acceptable portfolios near the benchmark are not required to be well diversified. To examine the performance of the method we performed the same tests as those that we applied to the well diversified portfolio. The results are shown in the
Appendix B, in
Table A1 and
Table A2 for DAX market and
Table A3 and
Table A4 for the US market. The nomenclature for the portfolios in these tables is Markowitz5, for the MV or mean-variance portfolio with target return 0.05 (in other words, the minimum variance portfolio to achieve return of 0.05), and quintile, and the respective portfolios after applying MEM for return maximization are termed are MEM_MV and MEM_Quin.
What is somewhat surprising from these tables, is that all performance measures improve after the maxentropic procedure is applied except the Herfindahl diversification index that becomes worse. The lesson seems to be that the maxentropic procedure for benchmark tracking does improve a portfolio optimization strategy keeping in line with the diversification or lack thereof. As an illustration of these facts we include in
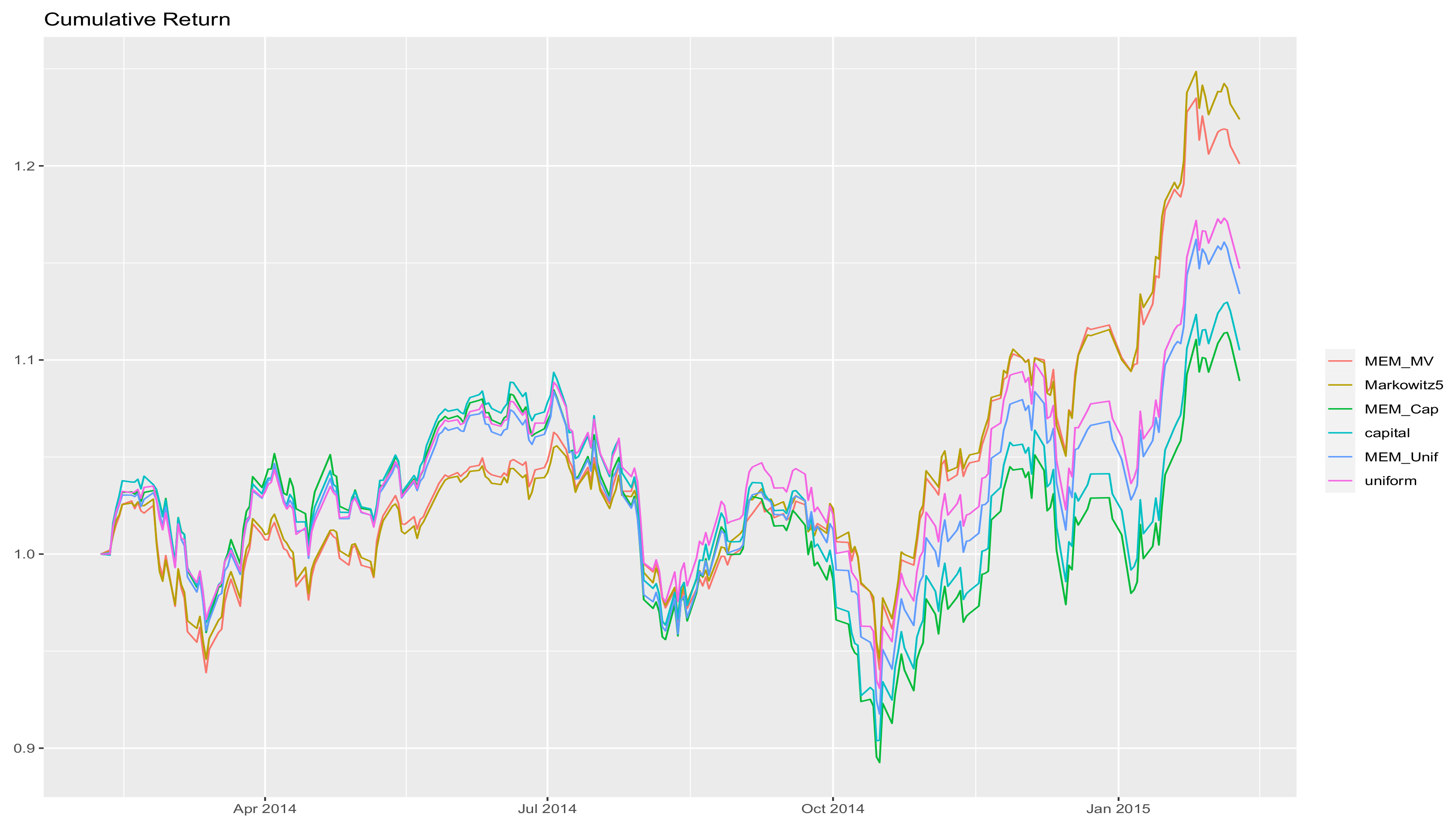
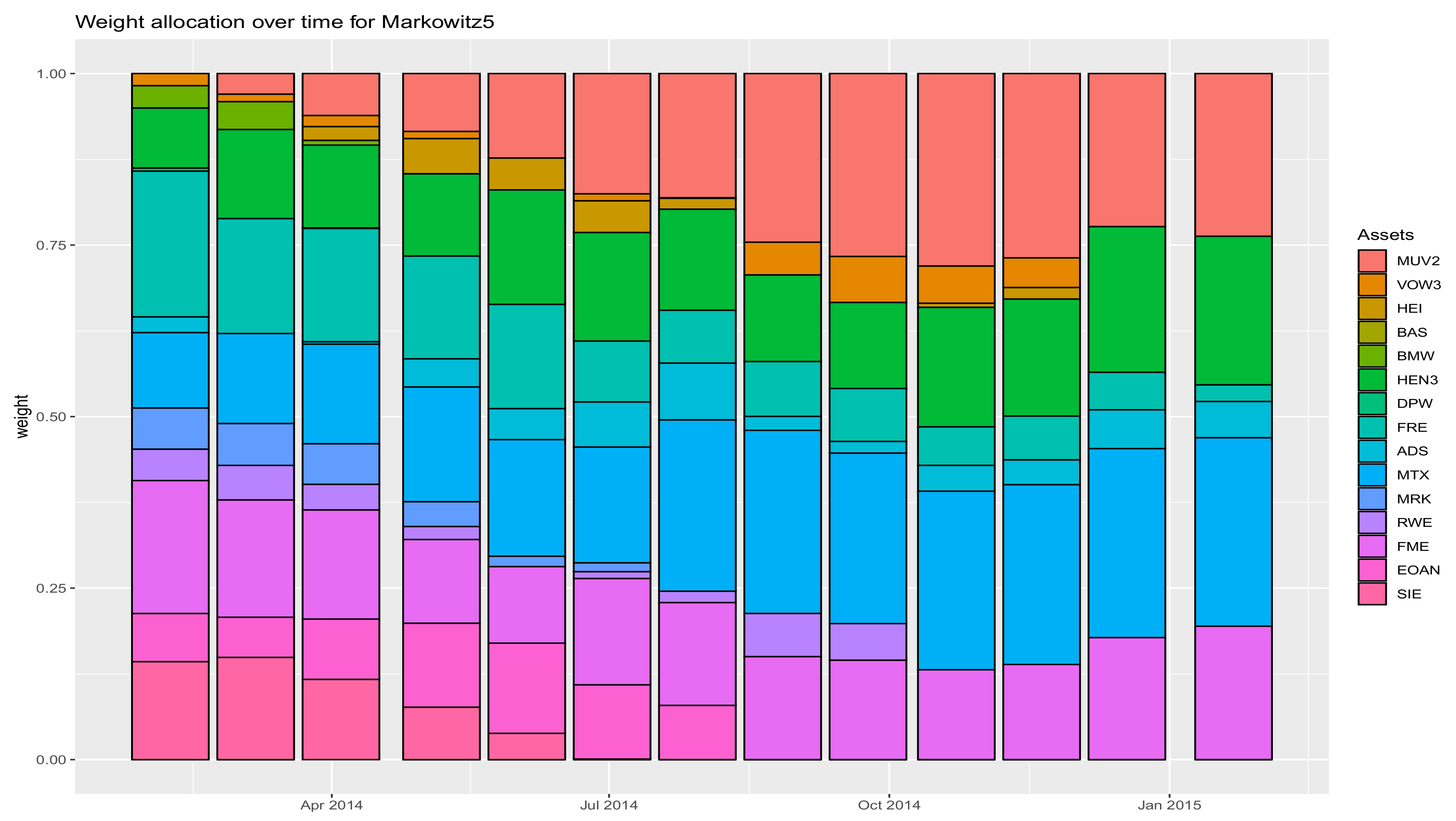
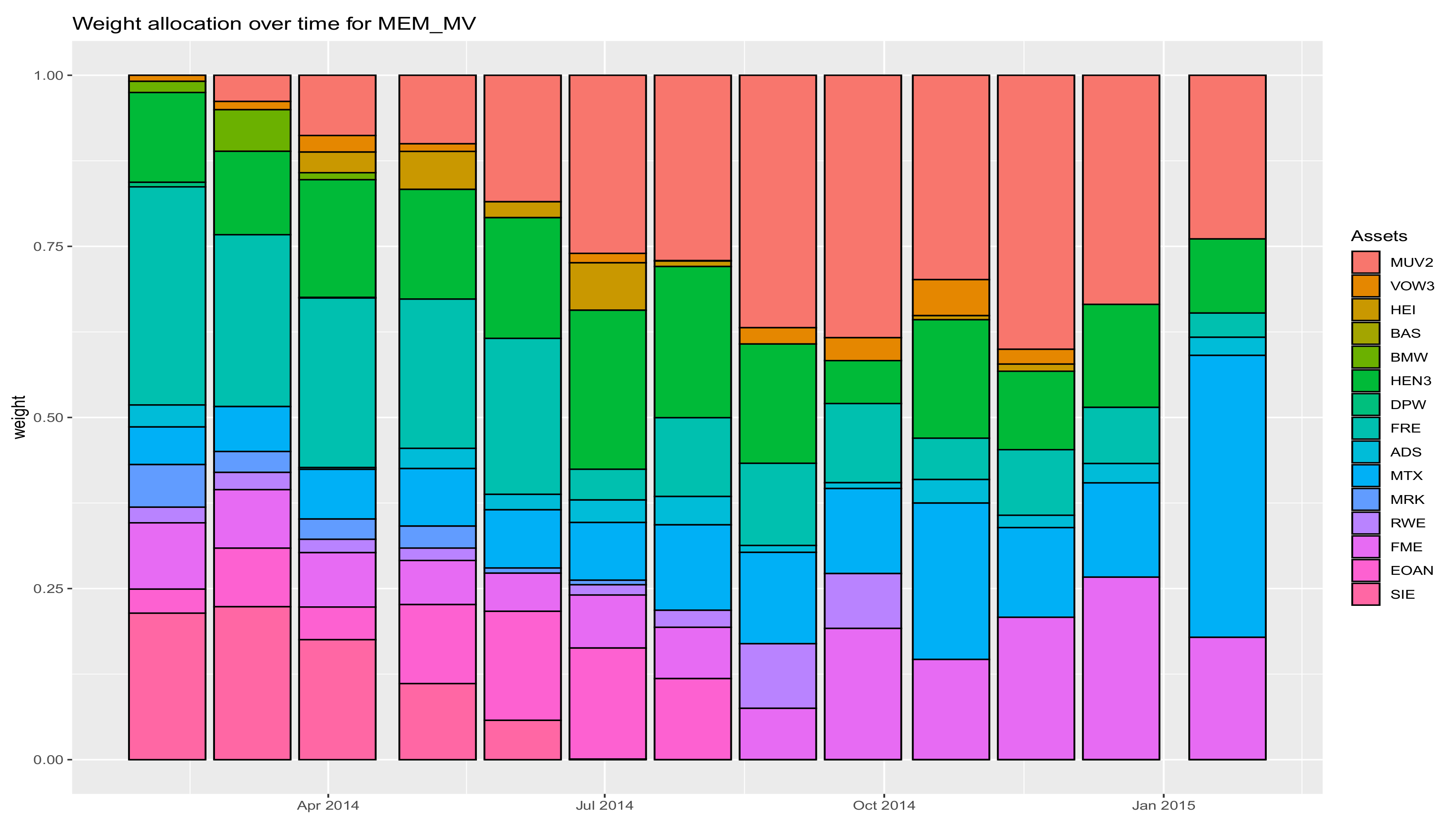
Appendix B a plot of the cumulative returns of the portfolios obtained in one of the 30 simulations considered for the DAX (
Figure A1), as well as pictures of the asset allocation by the MV method (
Figure A2) and the asset allocation of the same portfolio optimized by the maxentropic procedure (
Figure A3).
5. Concluding Remarks
The first and more obvious comment is that the maxentropic procedure to obtain a portfolio that maximizes the expected return within a band about the benchmark works quite well, regardless of whether the benchmark is well diversified or not. If the benchmark is well diversified, the new portfolio is well diversified as well. This is a reflection of the fact that the diversification index is a continuous function of the portfolio. Moreover, if the market is considered efficient and the relative capitalization reflects the efficiency of the market, then choosing the relative capitalization as a measure of diversification for our benchmark (which is good according to the Herfindahl index), then we maintain the market efficiency and improve upon the return of a well diversified and efficient portfolio.
The general outcome result from our maxentropic optimization is that not only is the expected return increased, also the realized return increases and some standard performance measures, like the Sharpe ratio, the max drawdown and the Sterling ratio, improve as well. This seems to happen not only when the benchmark is well diversified, but at least for the Markowitz and the quintile portfolios, the performance measures report a satisfactory outcome, except concerning the diversification that seems to deteriorate.
To conclude, the procedure seems to open the door to a well behaved benchmark tracking methodology.





{kind=link}
{kind=link}
{kind=link}