
An Intelligent Expert Combination Weighting Scheme for Group Decision Making in Railway Reconstruction


Abstract
:1. Introduction
2. The Related Work
- (1)
- In reference [36], the clustering results of IF sets are expressed in real numbers, which does not accord with the characteristics of IF sets.
- (2)
- (3)
- Reference [39] reduced the amount of calculation, but after obtaining the IF similarity matrix, only membership degree is used for clustering, ignoring non-membership degree and hesitation degree, which will inevitably cause the loss of information.
- (4)
- In literature [40], there is no analysis on the value of the clustering threshold. The value directly affects the clustering results, so the rationality of the value is particularly important.
3. Preliminaries
- (1)
- if and only ifandfor all
- (2)
- if and only ifand;
- (3)
- The complementary set of, denoted by, is
- (4)
- ;
- (5)
- calledless fuzzy than, i.e., for
- if, then,;
- if, then,.
- (1)
- if and only ifis a crisp set;
- (2)
- if and only if;
- (3)
- ;
- (4)
- If, then.
- (1)
- is an IFN;
- (2)
- if and only if;
- (3)
- =;
- (4)
- If, then, and.
- (1)
- Reflexivity:
- (2)
- Symmetry:
- (1)
- If, then.
- (2)
- If, then.
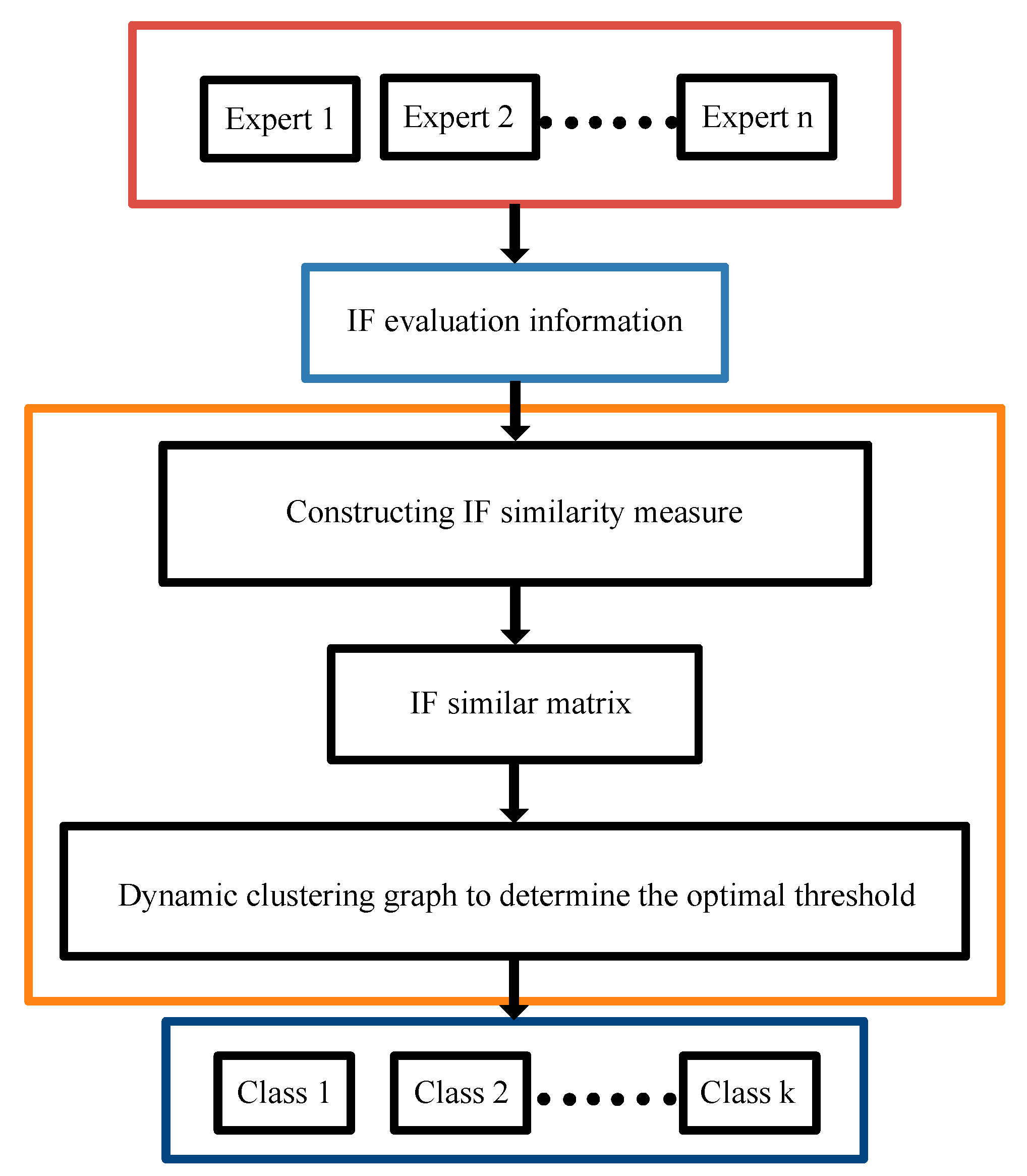
4. Our Proposed Intelligent Expert Combination Weighting Scheme
4.1. A New IF Entropy
- , ,
- , .
4.2. Clustering Method of Group Decision Experts
4.2.1. A New IF Similarity Measure
4.2.2. Threshold Change Rate Analysis Method
4.3. Analysis of Group Decision Making Expert Group Weighting
4.4. Intelligent Expert Combination Weighting Algorithm
| Algorithm 1. Intelligent expert combination weighting algorithm |
| Input the IF decision matrix given by experts where |
| 1: For implement. |
| 2: For implement. |
| 3: For implement. |
| 4: The IF similarity measure between experts is calculated according to formula (4). |
| 5: End for |
| 6: Let |
| 7: End for |
| 8: End for |
| 9: The IF decision matrix is transformed into the similarity matrix |
| 10: By selecting the risk factor β, the IF similarity matrix is transformed into the real matrix |
| 11: According to the real matrix , the dynamic clustering graph is drawn, and the optimal clustering threshold is determined by Formulae (6) and (7). According to this threshold, experts are classified into L categories. |
| 12: For implement. |
| 13: Using Formula (8), the weight of experts between categories λl is determined. |
| 14: For implement. |
| 15: Using Formula (8), the weight of experts between categories alk is determined. |
| 16: Formula (11) is used to determine the total weight of experts. ωk is calculated. |
| 17: End for. |
| 18: End for. |
| 19: For implement. |
| 20: For implement. |
| 21: The weighted operator (2) of IF sets is used to aggregate expert IF group decision-making information. |
| 22: End for. |
| 23: According to definition 8, the scores and accuracy values of each scheme xi are obtained. |
| 24: End for. |
| 25: return The results of the ranking of schemes xi. |
5. Performance Analysis
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Xie, Y.; Kou, Y.; Jiang, M.; Yu, W. Development and technical prospect of China railway. High Speed Railway Technol. 2020, 11, 11–16. [Google Scholar]
- Li, Y.B. Research on the current situation and development direction of railway freight transportation in China. Intell. City 2019, 5, 133–134. [Google Scholar]
- Fu, Z.; Zhong, M.; Li, Z. Development and innovation of Chinese railways over past century. Chin. Rail. 2021, 7, 1–7. [Google Scholar]
- Li, Z.; Xie, R.; Sun, L.; Huang, T. A survey of mobile edge computing Telecommunications Science. Chin. Rail. 2014, 2, 9–13. [Google Scholar]
- Lu, S.-T.; Yu, S.-H.; Chang, D.-S. Using fuzzy multiple criteria decision-making approach for assessing the risk of railway reconstruction project in Taiwan. Sci. Word J. 2014, 2014, 239793. [Google Scholar] [CrossRef] [Green Version]
- Wang, M.; Xie, H. Present situation analysis and discussion on development of Chinese railway construction market. J. Rail. Sci. Eng. 2008, 5, 63–67. [Google Scholar]
- Zhang, Z. Analysis on risks in construction of railway engineering projects and exploration for their prevention. Rail. Stan. Desi. 2010, 9, 51–52. [Google Scholar]
- Zadeh, L. Fuzzy sets. Inf. Control 1965, 8, 338–353. [Google Scholar] [CrossRef] [Green Version]
- Atanassov, K. Intuitionistic fuzzy sets. Fuzzy Sets Syst. 1986, 20, 87–96. [Google Scholar] [CrossRef]
- Tao, P.; Liu, Z.; Cai, R.; Kang, H. A dynamic group MCDM model with intuitionistic fuzzy set: Perspective of alternative queuing method. Inf. Sci. 2021, 555, 85–103. [Google Scholar] [CrossRef]
- Singh, M.; Rathi, R.; Antony, J.; Garza-Reyes, J. Lean six sigma project selection in a manufacturing environment using hybrid methodology based on intuitionistic fuzzy MADM approach. IEEE Trans. Eng. Manag. 2021, 99, 1–15. [Google Scholar] [CrossRef]
- Chaira, T. An intuitionistic fuzzy clustering approach for detection of abnormal regions in mammogram images. J. Digit. Imaging 2021, 34, 428–439. [Google Scholar] [CrossRef] [PubMed]
- Jiang, H.B.; Hu, B.Q. A novel three-way group investment decision model under intuitionistic fuzzy multi-attribute group decision-making environment. Inf. Sci. 2021, 569, 557–581. [Google Scholar] [CrossRef]
- Wang, W.; Zhan, J.; Mi, J. A three-way decision approach with probabilistic dominance relations under intuitionistic fuzzy information. Inf. Sci. 2022, 582, 114–145. [Google Scholar] [CrossRef]
- Wan, S.; Dong, J. A novel extension of best-worst method with intuitionistic fuzzy reference comparisons. IEEE Trans. Fuzzy Syst. 2021, 99, 1. [Google Scholar] [CrossRef]
- Kumar, D.; Agrawal, R.; Kumar, P. Bias-corrected intuitionistic fuzzy c-means with spatial neighborhood information ap proach for human brain MRI image segmentation. IEEE Trans. Fuzzy Syst. 2020. [Google Scholar] [CrossRef]
- Senapati, T.; Yager, R. Fermatean fuzzy sets. J. Ambient Intell. Humaniz. Comput. 2020, 11, 663–674. [Google Scholar] [CrossRef]
- Senapati, T.; Yager, R. Fermatean fuzzy weighted averaging/geometric operators and its application in multi-criteria decision-making methods—Science Direct. Eng. Appl. Artif. Intell. 2019, 85, 112–121. [Google Scholar] [CrossRef]
- Senapati, T.; Yager, R. Some new operations over fermatean fuzzy numbers and application of fermatean fuzzy WPM in multiple criteria decision making. Informatica 2019, 2, 391–412. [Google Scholar] [CrossRef] [Green Version]
- Ashraf, S.; Abdullah, S.; Mahmood, T.; Ghani, F. Spherical fuzzy sets and their applications in multi-attribute decision making problems. J. Intell. Fuzzy Syst. 2019, 36, 2829–2844. [Google Scholar] [CrossRef]
- Khan, M.; Kumam, P.; Liu, P.; Kumam, W.; Rehman, H. An adjustable weighted soft discernibility matrix based on generalized picture fuzzy soft set and its applications in decision making. J. Intell. Fuzzy Syst. 2020, 38, 2103–2118. [Google Scholar] [CrossRef]
- Riaz, M.; Hashmi, M. Linear Diophantine fuzzy set and its applications towards multi-attribute decision-making problems. J. Intell. Fuzzy Syst. 2019, 37, 5417–5439. [Google Scholar] [CrossRef]
- Gao, K.; Han, F.; Dong, P.; Xiong, N.; Du, R. Connected vehicle as a mobile sensor for real time queue length at signalized intersections. Sensors 2019, 19, 2059. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, Q.; Zhou, C.; Tian, Y.; Xiong, N.; Qin, Y.; Hu, B. A fuzzy probability Bayesian network approach for dynamic cybersecurity risk assessment in industrial control systems. IEEE Trans. Ind. Inform. 2017, 14, 2497–2506. [Google Scholar] [CrossRef] [Green Version]
- Luca, A.; Termini, S. A definition of a nonprobabilistie entropy in the setting of fuzzy sets theory. Inf. Control 1972, 3, 301–312. [Google Scholar] [CrossRef] [Green Version]
- Szmidt, E.; Kacprzyk, J. Entropy for intuitionistic fuzzy sets. Fuzzy Sets Syst. 2001, 118, 467–477. [Google Scholar] [CrossRef]
- Ye, J. Two effective measures of intuitionistic fuzzy entropy. Computing 2010, 87, 55–62. [Google Scholar] [CrossRef]
- Zeng, W.; Li, H. Relationship between similarity measure and entropy of interval valued fuzzy sets. Fuzzy Sets Syst. 2006, 157, 1477–1484. [Google Scholar] [CrossRef]
- Zhang, Q.; Jiang, S. A note on information entropy measures for vague sets and its applications. Inf. Sci. 2008, 178, 4184–4191. [Google Scholar] [CrossRef]
- Verma, R.; Sharma, B. Exponential entropy on intuitionistic fuzzy sets. Kybernetika 2013, 49, 114–127. [Google Scholar]
- Burillo, P.; Bustince, H. Entropy on intuitionistic fuzzy sets and on interval-valued fuzzy sets. Fuzzy Sets Syst. 1996, 78, 305–316. [Google Scholar] [CrossRef]
- Wang, J.; Wang, P. Intuitionistic linguistic fuzzy multi-criteria decision-making method based on intuitionistic fuzzy entropy. Control Decis. 2012, 27, 1694–1698. [Google Scholar]
- Wei, C.; Gao, Z.; Guo, T. An intuitionistic fuzzy entropy measure based on trigonometric function. Control Decis. 2012, 27, 571–574. [Google Scholar]
- Liu, M.; Ren, H. A new intuitionistic fuzzy entropy and application in multi-attribute decision making. Informatica 2014, 5, 587–601. [Google Scholar] [CrossRef] [Green Version]
- Ai, C.; Feng, F.; Li, J.; Liu, K. AHP method of subjective group decision-making based on interval number judgment matrix and fuzzy clustering analysis. Control Decis. 2019, 35, 41–45. [Google Scholar]
- He, Z.; Lei, Y. Research on intuitionistic fuzzy C-means clustering algorithm. Control Decis. 2011, 26, 847–850. [Google Scholar]
- Zhang, H.; Xu, Z.; Chen, Q. On clustering approach to intuitionistic fuzzy sets. Control Decis. 2007, 22, 882–888. [Google Scholar]
- He, Z.; Lei, Y.; Wang, G. Target recognition based on intuitionistic fuzzy clustering. J. Syst. Eng. Electron. 2011, 6, 1283–1286. [Google Scholar]
- Wang, Z.; Xu, Z.; Liu, S.; Tang, J. A netting clustering analysis method under intuitionistic fuzzy environment. Appl. Soft Comput. 2011, 11, 5558–5564. [Google Scholar] [CrossRef]
- Zhuo, X.; Zhang, F.; Hui, X.; Li, K. Method for determining experts’ weights based on entropy and cluster analysis. Control Decis. 2011, 26, 153–156. [Google Scholar]
- Xu, Z.; Chen, J. An overview of distance and similarity measures of intuitionistic fuzzy sets. Int. J. Uncertain. Fuzz. 2008, 16, 529–555. [Google Scholar] [CrossRef]
- Zhang, Z.; Chen, S.; Wang, C. Group decision making with incomplete intuitionistic multiplicative preference relations. Inf. Sci. 2020, 516, 560–571. [Google Scholar] [CrossRef]
- Xu, Z.S.; Yager, R.R. Some geometric aggregation operators based on intuitionistic fuzzy sets. Int. J. Gen. Syst. 2006, 35, 417–433. [Google Scholar] [CrossRef]
- Huang, S.; Liu, A.; Zhang, S.; Wang, T.; Xiong, N. BD-VTE: A novel baseline data based verifiable trust evaluation scheme for smart network systems. IEEE Trans. Netw. Sci. Eng. 2020, 8, 2087–2105. [Google Scholar] [CrossRef]
- Wu, M.; Tan, L.; Xiong, N. A structure fidelity approach for big data collection in wireless sensor networks. Sensors 2015, 15, 248–273. [Google Scholar] [CrossRef] [Green Version]
- Li, H.; Liu, J.; Wu, K.; Yang, Z.; Liu, R.; Xiong, N. Spatio-temporal vessel trajectory clustering based on data mapping and density. IEEE Access 2018, 6, 58939–58954. [Google Scholar] [CrossRef]
- Khan, M.; Kumam, P.; Alreshidi, N.; Kumam, W. Improved cosine and cotangent function-based similarity measures for q-rung orthopair fuzzy sets and TOPSIS method. Complex Intell. Syst. 2021, 7, 2679–2696. [Google Scholar] [CrossRef]
- Chen, S.; Chang, C. A novel similarity measure between Atanassov’s intuitionistic fuzzy sets based on transformation techniques with applications to pattern recognition. Inf. Sci. 2015, 291, 96–114. [Google Scholar] [CrossRef]
- Beliakov, G.; Pagola, M.; Wilkin, T. Vector valued similarity measures for Atanassov’s intuitionistic fuzzy sets. Inf. Sci. 2014, 280, 352–367. [Google Scholar] [CrossRef]
- Lohani, Q.; Solanki, R.; Muhuri, P. Novel adaptive clustering algorithms based on a probabilistic similarity measure over Atanassov intuitionistic fuzzy set. IEEE Trans. Fuzzy Syst. 2018, 6, 3715–3729. [Google Scholar] [CrossRef]
- Liu, J.; Zhou, X.; Li, H.; Huang, B.; Gu, P. An intuitionistic fuzzy three-way decision method based on intuitionistic fuzzy similarity degrees. Syst. Eng. Theory Pract. 2019, 39, 1550–1564. [Google Scholar]
- Mei, X. Dynamic intuitionistic fuzzy multi-attribute decision making method based on similarity. Stat. Decis. 2016, 15, 22–24. [Google Scholar]
- Tang, Y. Comparison and analysis of domestic and foreign railway energy consumption. Rail. Tran. Econ. 2018, 40, 97–103. [Google Scholar]
- Gao, F. A study on the current situation and development strategies of China’s railway restructuring. Railw. Freight Transport. 2020, 38, 15–19. [Google Scholar]
- Chai, J.S.; Selvachandran, G.; Smarandache, F.; Gerogiannis, V.C.; Son, L.H.; Bui, Q.-T.; Vo, B. New similarity measures for single-valued neutrosophic sets with applications in pattern recognition and medical diagnosis problems. Complex Intell. Syst. 2021, 7, 703–723. [Google Scholar] [CrossRef]
- Garg, H. Generalized intuitionistic fuzzy entropy-based approach for solving multi-attribute decision-making problems with unknown attribute weights. Proc. Natl. Acad. Sci. USA 2017, 89, 129–139. [Google Scholar] [CrossRef]
- Majumdar, P. On new measures of uncertainty for neutrosophic sets. Neutrosophic Sets Syst. 2017, 17, 50–57. [Google Scholar]
- Quek, S.G.; Selvachandran, G.; Smarandache, F.; Vimala, J.; Le, S.H.; Bui, Q.-T.; Gerogiannis, V.C. Entropy measures for Plithogenic sets and applications in multi-attribute decision making. Mathematics 2020, 8, 965. [Google Scholar] [CrossRef]
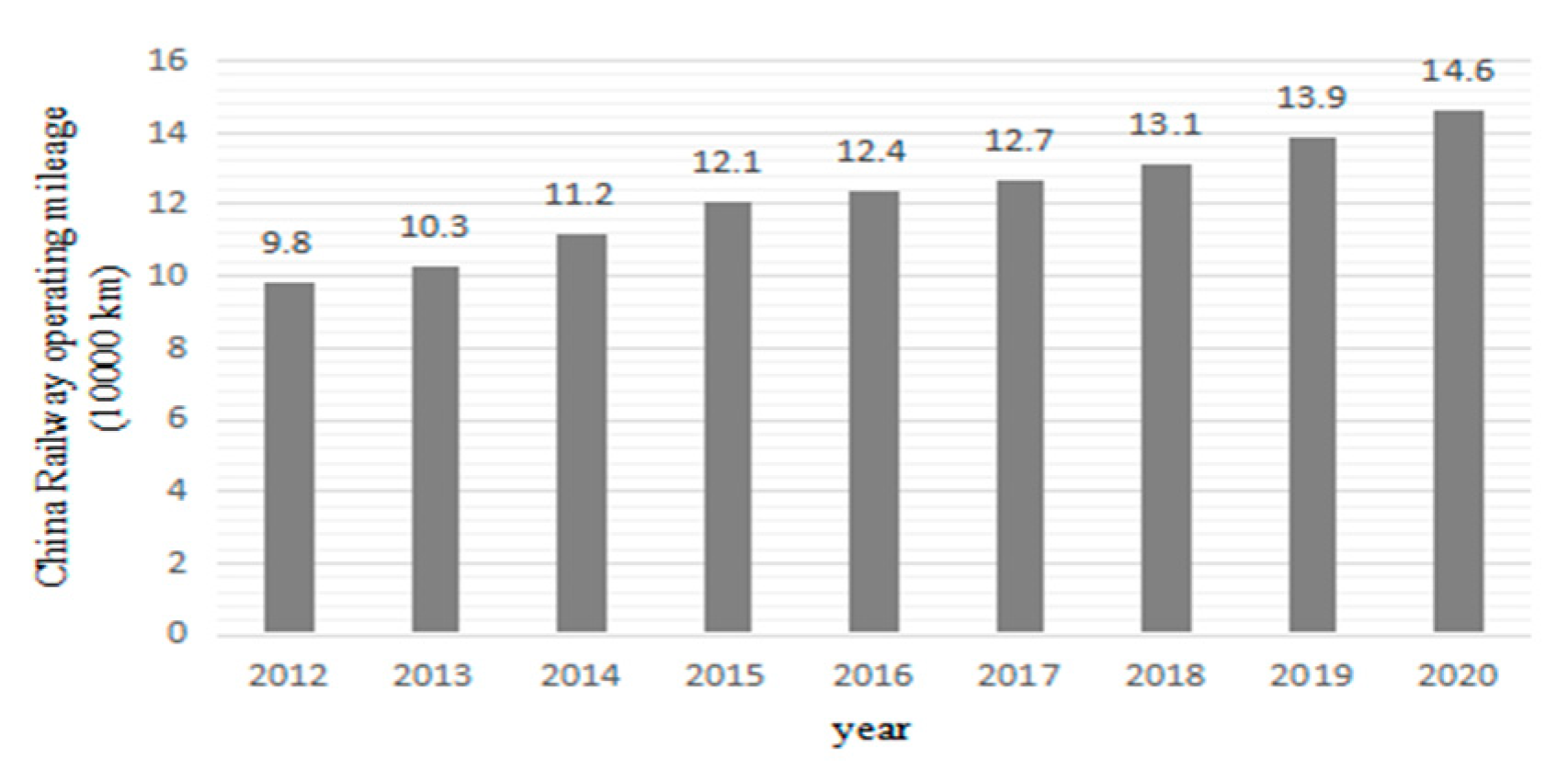
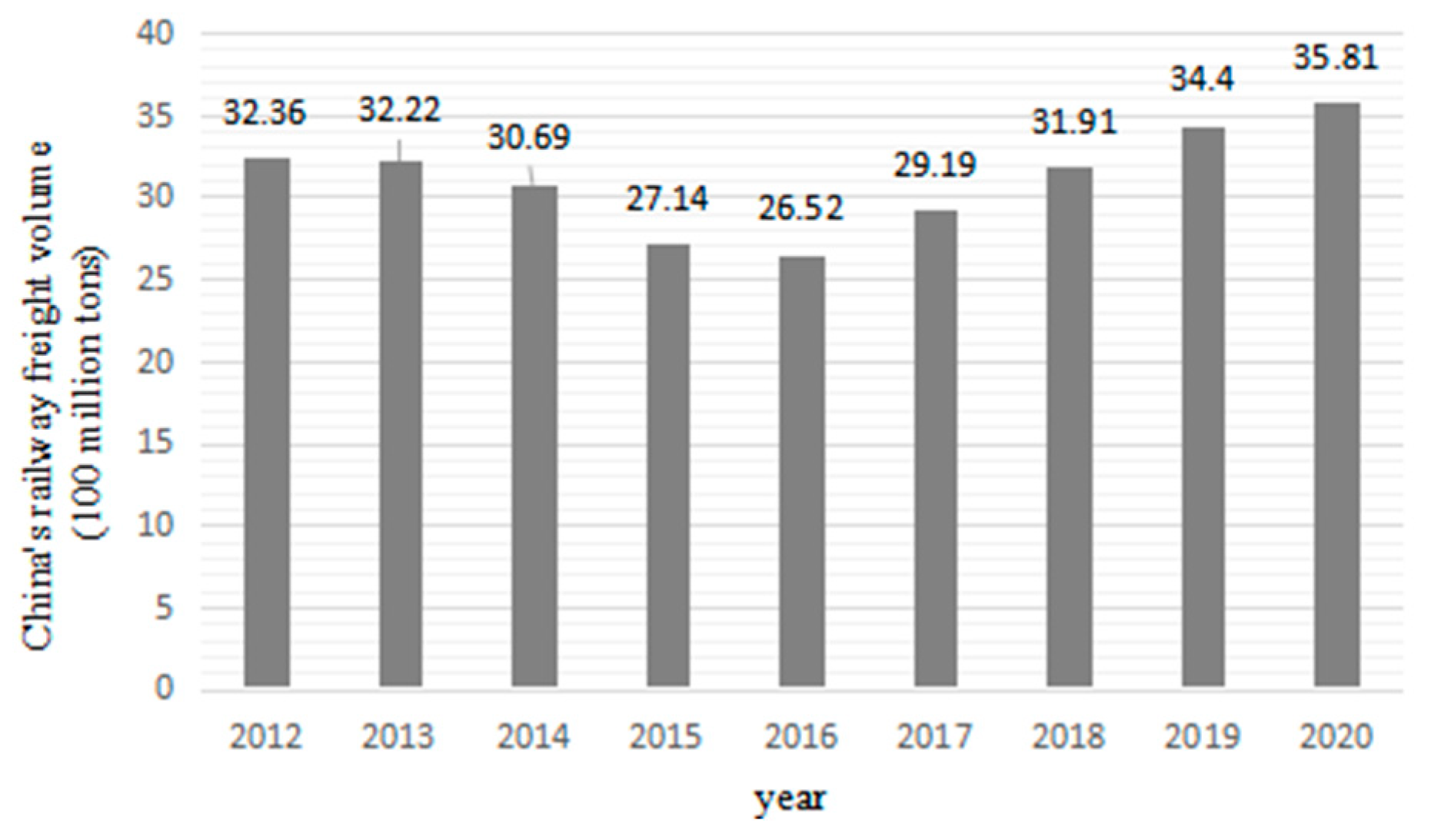
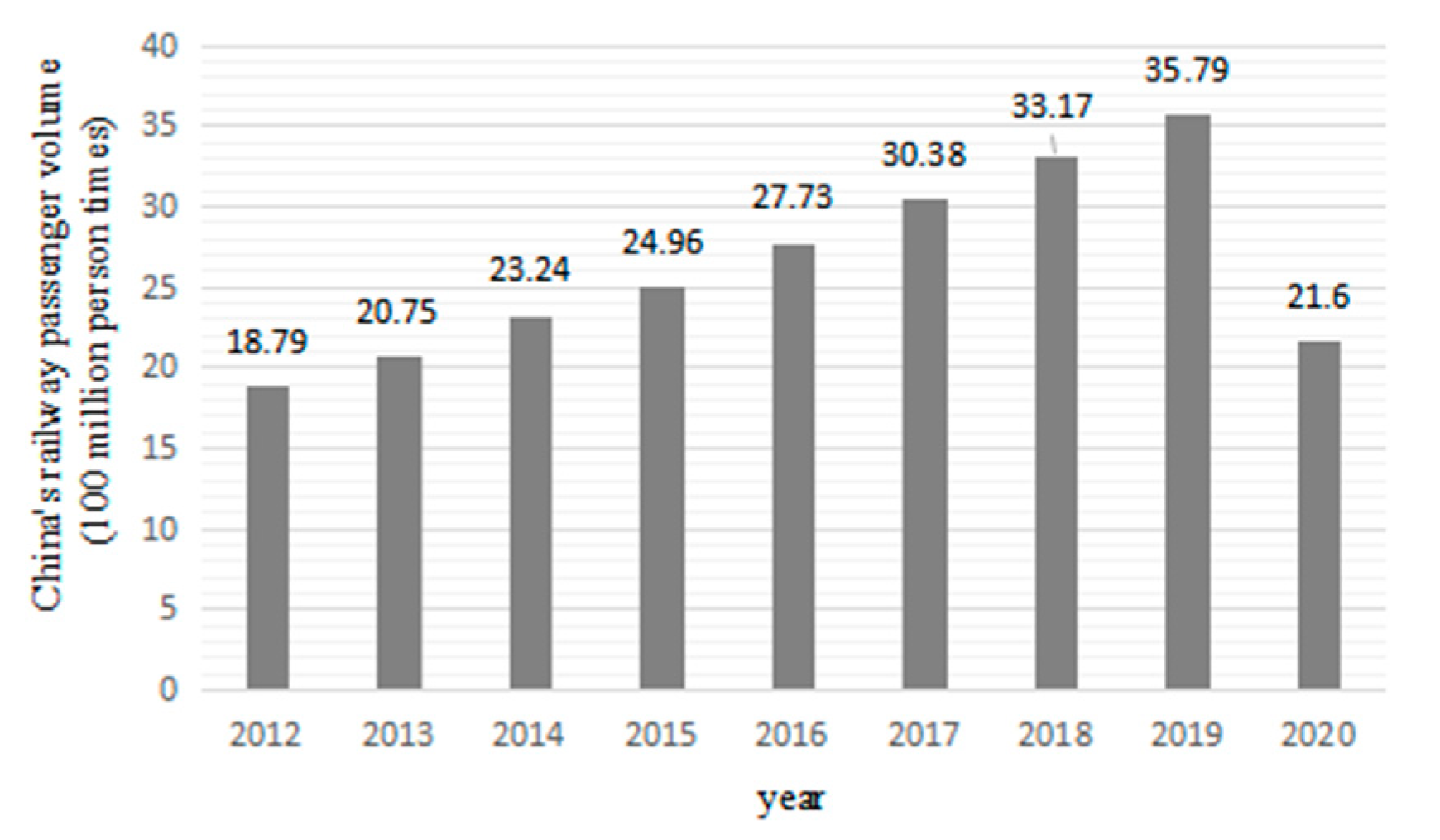




{kind=link}
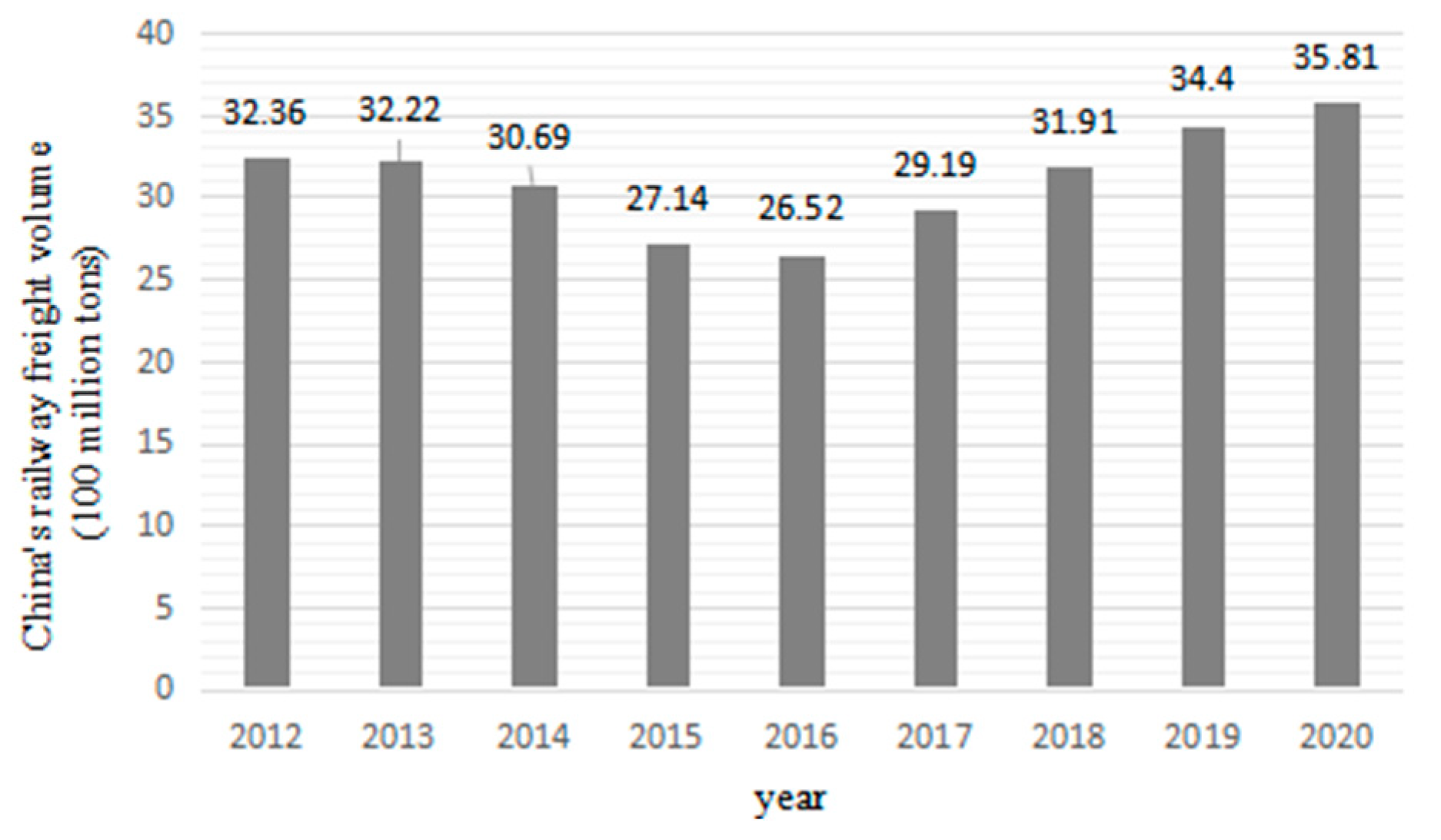{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Expert | |||||
|---|---|---|---|---|---|
| <0.43,0.45> | <0.24,0.70> | <0.57,0.40> | <0.29,0.55> | <0.25,0.60> | |
| <0.58,0.30> | <0.37,0.52> | <0.30,0.50> | <0.55,0.35> | <0.35,0.50> | |
| <0.31,0.61> | <0.74,0.22> | <0.70,0.25> | <0.50,0.40> | <0.70,0.20> | |
| <0.44,0.45> | <0.31,0.60> | <0.56,0.40> | <0.31,0.52> | <0.24,0.60> | |
| <0.31,0.60> | <0.70,0.20> | <0.75,0.20> | <0.60,0.30> | <0.68,0.20> | |
| <0.70,0.20> | <0.58,0.32> | <0.52,0.40> | <0.20,0.70> | <0.60,0.30> | |
| <0.38,0.52> | <0.72,0.21> | <0.68,0.22> | <0.61,0.30> | <0.70,0.22> | |
| <0.41,0.40> | <0.28,0.60> | <0.55,0.35> | <0.30,0.55> | <0.26,0.60> | |
| <0.56,0.34> | <0.40,0.50> | <0.30,0.40> | <0.71,0.10> | <0.38,0.45> |
| Category | The Weight of Experts within the Category |
| Category 1 | |
| Category 2 | |
| Category 3 | |
| Category 4 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zeng, L.; Ren, H.; Yang, T.; Xiong, N. An Intelligent Expert Combination Weighting Scheme for Group Decision Making in Railway Reconstruction. Mathematics 2022, 10, 549. https://doi.org/10.3390/math10040549
Zeng L, Ren H, Yang T, Xiong N. An Intelligent Expert Combination Weighting Scheme for Group Decision Making in Railway Reconstruction. Mathematics. 2022; 10(4):549. https://doi.org/10.3390/math10040549
Chicago/Turabian StyleZeng, Lihua, Haiping Ren, Tonghua Yang, and Neal Xiong. 2022. "An Intelligent Expert Combination Weighting Scheme for Group Decision Making in Railway Reconstruction" Mathematics 10, no. 4: 549. https://doi.org/10.3390/math10040549
APA StyleZeng, L., Ren, H., Yang, T., & Xiong, N. (2022). An Intelligent Expert Combination Weighting Scheme for Group Decision Making in Railway Reconstruction. Mathematics, 10(4), 549. https://doi.org/10.3390/math10040549