1. Introduction
Over recent decades, optimal reinsurance problems have received much attention in actuarial study. Insurers can control risks by purchasing reinsurance, and popular criteria minimize the probability of ruin, thus maximizing the expected utility and mean-variance criterion; see, for example [
1,
2,
3,
4,
5,
6,
7], etc. Recently, some researchers studied dependent classes of businesses that can describe risk claims more precisely for insurers. One dependent risk model is the so-called common shock, namely, there are different business risks as a result of one stochastic source. For this risk model, ref. [
8] found the optimal dynamic excess-of-loss reinsurance under the criterion of minimizing the ruin probability for a diffusion model; ref. [
9] investigated the optimal proportional reinsurance that maximizes the expected utility of terminal wealth for both compound Poisson and diffusion approximation risk models with the variance premium principle; ref. [
10] studied optimal mean-variance reinsurance and investment in a jump-diffusion financial market; ref. [
11] obtained the optimal proportional reinsurance for minimizing the probability of drawdown.
In order to describe the more realistic features of dependence, ref. [
12] proposed a risk model with thinning dependence, that is, one event may induce some different classes of business risks with certain probabilities. One of the typical examples is that a severe traffic accident may cause not only the loss of a damaged car, but also the medical expenses of injured drivers and passengers. For the thinning model, refs. [
13,
14] considered the optimal proportional reinsurance under the criteria of maximizing the adjustment coefficient and minimizing the probability of drawdown, respectively; ref. [
15] studied the optimal reinsurance strategies for the mean-variance criterion.
Much of the existing literature, like the studies mentioned above, studied optimal problems with some specific form of reinsurance, such as proportional reinsurance, excess-of-loss reinsurance, or a combination of the two. Recently, some scholars studied optimal reinsurance strategies with various objectives but without a constraint on the reinsurance form, which is called the per-loss reinsurance. The main method of obtaining optimal per-loss reinsurance strategies is the pointwise optimization method, which can also be understood as the specific Euler–Lagrange equation in classical calculus of variations. For example, ref. [
16] investigated the optimal investment and reinsurance strategies for insurers with a generalized mean-variance premium principle and no-short selling; ref. [
17] studied the optimal per-loss reinsurance with the criterion of minimizing the probability of ruin; ref. [
18] considered the optimal reinsurance strategy in order to minimize the drawdown probability with the mean-variance premium principle. However, very few of them considered the optimal per-loss reinsurance for dependent risk models, which are more beneficial for real insurance markets. Meanwhile, in mathematics, deriving several optimal controls that affect each other is more difficult and challenging than deriving independent controls.
In this paper, we consider the optimal per-loss reinsurance in order to maximize the expected utility of terminal wealth with a thinning-dependence structure, and the reinsurance premium is computed according to the mean-variance premium principle. By using stochastic control theory, we establish the corresponding Hamilton–Jacobi–Bellman equation for both the compound Poisson thinning model and its diffusion approximation. Via the pointwise optimization method, we obtain the closed-form expression of the optimal strategy for each business that is expressed by other given strategies, or, we can say, it is the best response to other strategies, such as in game theory. Then, we derive the necessary conditions for the optimal strategies. For the compound Poisson model, we obtain an system of equations with respect to the moment-generating functions of the optimal strategies; for the diffusion approximation model, we get a system of equations about the expectations of the optimal strategies. We prove that the solution of this equation system always exists, but may not be unique. However, for some special cases, this uniqueness is established, such as with the diffusion approximation risk model with only two classes of insurance businesses, or when there is only one group of stochastic sources and the variance safety loadings for all insurance classes are the same. For the latter case, we also find that when the number of business classes is increased, all of the original optimal retained strategies are decreased in order to balance the risk.
In addition, for the diffusion approximation risk model, we can see that the optimal strategy is actually a combination of the excess-of-loss reinsurance and the proportional reinsurance. When the mean-variance premium principle is reduced to the expected value principle, the optimal strategy becomes the excess-of-loss reinsurance. However, when it becomes the variance premium principle, the optimal strategy is not a proportional reinsurance anymore; instead, the insurer will choose to transfer all of the small-size claims and retain a portion of the excess. Moreover, we compare the optimal strategies of the dependent risk model and independent risk model with those of the jump model and the diffusion model, respectively. The results show that the optimal retained strategy for the former case is always smaller than the one for the latter.
The remainder of the paper is organized as follows. In
Section 2, we introduce the thinning model and the problem formulation. In
Section 3 and
Section 4, we derive the closed-form expressions of the optimal strategies for both the compound Poisson and diffusion approximation risk models, and we obtain the necessary conditions that the optimal strategies must satisfy. In
Section 5, we provide some numerical examples to show the properties of the optimal strategies and analyze the influences of some important parameters on the optimal strategies. Finally, we conclude this paper and raise some questions for further discussion in
Section 6.
2. Model Setup and Problem Formulation
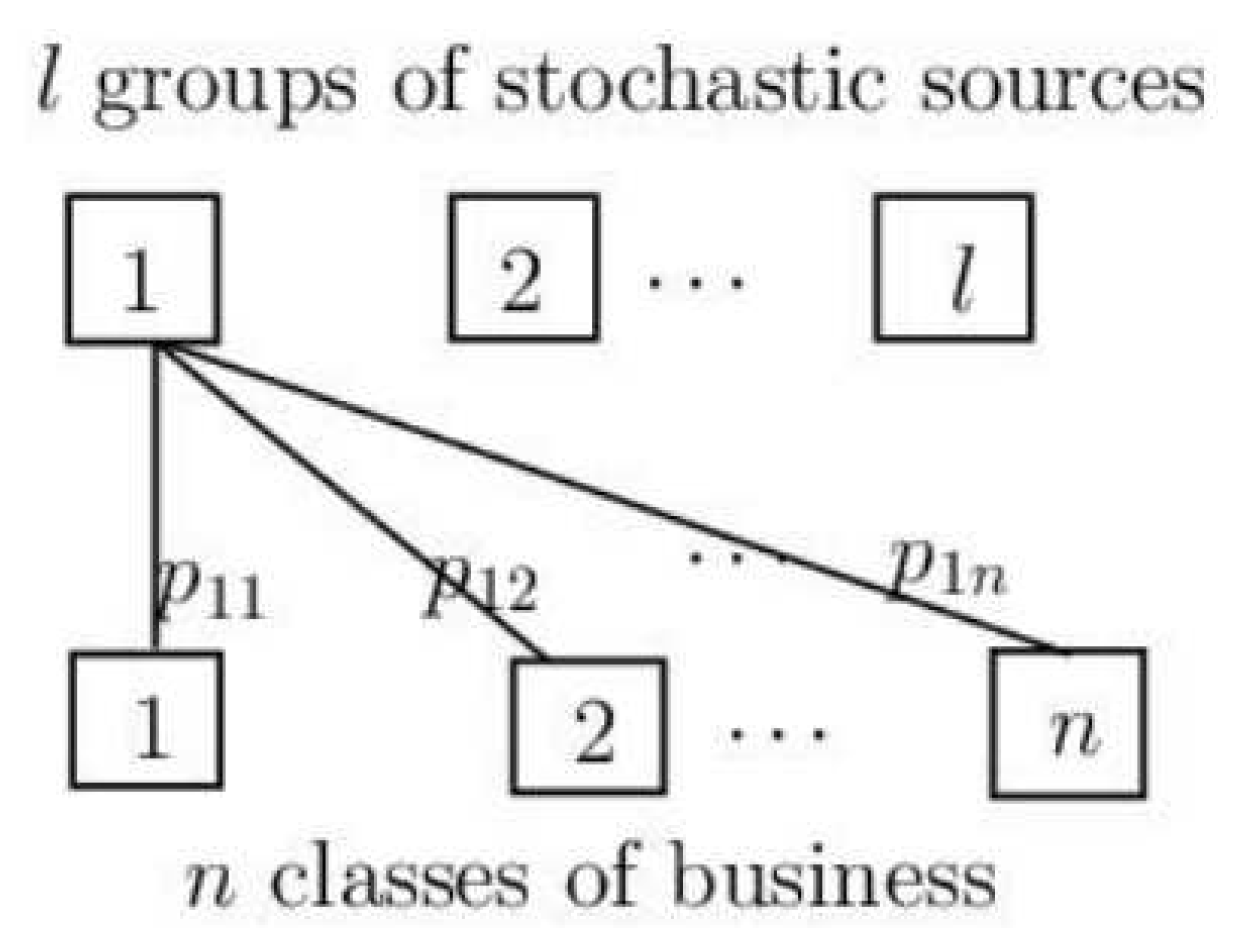
In this section, we will introduce the thinning-dependence model that was firstly proposed by [
12]. Suppose that an insurance company has
n dependent classes of businesses, such as health insurance businesses, life insurance businesses, etc., and there are
l groups of stochastic sources that may affect some of these insurance businesses with a certain probability (see
Figure 1). In this setting, we use
to denote the number of events from the
kth group that occur up to time
t, where
. Let
be the number of claims for the
jth class up to time
t generated by the
kth stochastic source. Then, the claim-number process
for the
jth business class of the insurance company can be described by
Moreover, it is assumed that are independent Poisson processes with intensities , and thus, is a time-homogeneous Poisson process with intensity . Here, represents the probability of the event that the kth risk source affects the jth business’s claim, and is the -thinning of . It is reasonable to further assume that the components of the vector of a claim-number process, , are conditionally independent given .
Here, we further explain the two independence assumptions mentioned above. The independence among means that different groups of stochastic sources do not affect each other. For example, we suppose that represents the number of traffic accidents and represents the number of epidemics; then, it is rational to assume that they are independent of each other. The independence of when given means that the events of the kth group will independently trigger different classes of insurance. For instance, we suppose that represents the number of traffic accidents, denotes the claim number generated by traffic accidents for auto insurance, and denotes the claim number generated by traffic accidents for life insurance. Then, it is reasonable to think that whether a traffic accident will trigger the auto insurance is independent of whether it will trigger the life insurance.
Let
be the claim size, which is a random variable for the
ith claim in the
jth class. Then, the total number of claims from the
jth class up to time
t can be expressed as
Therefore, the aggregate claims process of the company is given by
where
are a sequence of i.i.d positive random variables with a common distribution
. Let
, and
denote its the first- and second-order moments and the moment-generating function, respectively. As usual, we assume that the
n sequences are mutually independent and are independent of all claim-number processes.
Now, we define the surplus process of the insurance company as
where
u is the initial wealth, and
c is the premium rate. In this paper, we suppose that the insurance company can manage its risk by purchasing per-loss reinsurance via a continuously payable premium, which is computed according to the mean-variance premium principle. The insurer retains
for the
n business claims, where
is a function of
for
, and the remaining losses
are ceded to the reinsurer. Furthermore, the insurer is allowed to invest all of its wealth into a risk-free asset with an interest rate
r. Let
denote the associated surplus process under the reinsurance strategy
; then, it evolves as
where
is the mean-variance reinsurance premium, and
are safety loadings for the
jth business class.
Remark 1. If we denote , then it follows from [12] that is also a compound Poisson process. Furthermore, it is equal in law to given bywhere is a Poisson process with intensity are independent with a common distribution , and the moment-generating function iswhere . Let represent the reinsurance control process selected by the insurer; then, we define the admissible strategy as follows.
Definition 1. (Admissible control) The control is said to be admissible if and only if
- (1)
for , is increasing with respect to and ,
- (2)
is an -predictable process,
- (3)
in association with , the state Equation (2) has a unique strong solution.
The set of all admissible strategies is denoted by .
Suppose that the insurer is interested in maximizing the expected utility of its terminal wealth, say, at time
T. We assume that the insurer has a CARA preference, i.e., they choose the exponential utility function
where
is constant risk aversion. For the strategy
, we define the objective function at time
t as
and our aim is to find the value function
and the optimal strategy
such that
.
3. Optimal Results for the Compound Poisson Model
In this section, we will discuss the optimal reinsurance problem for the compound Poisson risk model with a thinning-dependence structure. As a special case, we will also analyze the results for the classical Cramer–Lundberg (C-L) model. From the standard arguments of the dynamic programming approach (see, e.g., [
19]), we see that if the optimal value function
and its partial derivatives
and
are continuous on
, then
V satisfies the following HJB equation:
with the boundary condition
Before solving this HJB equation, we first give a lemma that reveals some features of the optimal strategy and the conjecture of the value function .
Lemma 1. If the insurer chooses the exponential utility function , then the optimal strategy is independent of x. Furthermore, the value function has the form ofwith . Proof. According to Equation (
2), we know that
where
is the random Poisson measure such that
. Then, the value function
can be denoted by
Thus, from the last expression, we find that the optimal strategies only depend on the time
t. Consequently, we can derive that the value function has the form of
where
, which completes the proof. □
Next, we try to construct a solution of the HJB Equation (
3) with the boundary condition (
4). Suppose that
has the form of (
8) and satisfies (
3) and (
4). Then, we have
Putting them into back the HJB equation, we obtain
Now, we come to find the extreme point
, which causes the left-hand side of (
10) to be minimized. Firstly, we would like to find the best response
to other strategies when
are given, as shown in the following theorem.
Theorem 1. Given the other strategies , we denote . Then, the best response is given bywhere satisfies Proof. From (
10), we can see that to find the optimal
is to minimize
According tothe pointwise optimization method, this is equivalent to minimizing the following function:
Through some calculations, we find that
Therefore, for any
, the minimizer
satisfies the equation
We might as well denote
as the solution of (
11), and it is affected by the other given strategies due to the term
. If we denote
by
, then
is actually a function of
and can be written as
. Considering the constraint
, the best strategy of response
to other strategies is given by
which completes the proof. □
Before providing a further discussion on the extreme point, we first show some properties in Lemma 2, as they play key roles in this paper.
Lemma 2. is decreasing with respect to and increasing with respect to y.
Proof. Recall that
satisfies (
11). Differentiating both sides of (
11) with respect to
and
y, respectively, we get
and
Then, we can easily find that and considering that for every . □
Based on the above analysis, we now give the necessary condition that (
10) needs to achieve its minimum, as shown in the following theorem.
Theorem 2. If is the minimum point of (10), then we have the conclusion that for any , where satisfies the following system of equations: Furthermore, if is the unique solution of (13), then will be the minimum point of (10). Remark 2. From the game-theoretical perspective in [20], we can imagine that there are n decision makers in one insurance company who manage n classes of businesses, and everyone wants to maximize the expected utility of the terminal wealth for the insurance company. So, when other strategies are determined, can be understood as the best response to others. Therefore, if all strategies are optimal, then every strategy is the best response to others. From Theorem 2, we can see that if
are determined, then the extreme point will be determined, too. So, in the following, we analyze the existence and uniqueness of the solution for Equation (
13).
Theorem 3. The solution for Equation (13) always exists for any . Proof. We will use the mathematical induction method to prove this. First of all, when
, Equation (
13) reduces to
For convenience, we note that
and
; then, Equation (
14) can be rewritten as
Since
is decreasing with respect to
according to Lemma 2, it is not difficult to prove that
and
are also decreasing about
; thus, we have
. Similarly,
. Substituting
into
, we have
Then, we structure an auxiliary function
so that
and
. Therefore, there is at least one solution for Equation (
15).
Next, assuming that the conclusion is true for
, we need to prove that it is also true for
. When
, considering the first
k equations and fixing
, we know that there is at least one solution that is a function of
, which is denoted by
, according to the assumption. Putting it into the last equation, then, we can also structure an auxiliary function and prove the existence of the solution for the equation about
via the intermediate value theorem. Therefore, the existence of the solution for Equation (
13) is proved. □
It is hard to analyze the uniqueness of the solution, but we can give a sufficient condition for the case of , as Theorem 4 shows.
Theorem 4. For the case of , ifthen the solution for Equation (13) is unique. Proof. Suppose that there are two solutions
and
that satisfy Equation (
15); then, we obtain
According to the Lagrange mean-value theorem, there exist
, s.t.
and
. Then, Equation (
17) can be rewritten as
where
.
Now, we will prove that if (
16) holds, then
, and thus, the only solution of (
18) is
, which implies its uniqueness.
Firstly,
satisfies
By differentiating both sides of (
19) with respect to
, we get
On the other hand, according to Lemma 3, we derive that
By combining this with
, we get
Finally,
which completes the proof. □
Lemma 3. .
Remark 3. We can understand the system of equations (13) as a noncooperative game among the n decision makers, as we mentioned in Remark 2. Therefore, the solution of the system of equations (13) is actually a Nash equilibrium point of a static noncooperative game from the game-theoretical perspective, and the Nash equilibrium point often exists, but may not be unique sometimes. If there is only one Nash equilibrium point, then it is the optimal solution. If there are some different Nash equilibrium points, we need to make some comparisons to choose the best one. Once we get the minimum point, we can derive the solution of the HJB equation, and from the standard dynamic programming theory, we have the following verification theorem.
Theorem 5. If is the minimum point in (10), thenwhereis the solution to the HJB equation. Furthermore, we have , and the optimal reinsurance strategy is given by . Based on the results mentioned above, we will give some more specific results for some special cases in the following corollaries.
Corollary 1. For the classical C-L model, that is, when , Equation (11) reduces to We denotethe solution of Equation (20) as , and along with the claim constraint, the optimal strategy is Remark 4. The result of Corollary 1 means that the insurer retains all of the risk when the claim size is no more than . However, when the claim size is , the company will choose to retain and transfer . That is to say, for some small claims, the insurer does not want to transfer its business to the reinsurer because of the cost from the reinsurance premium, and when the claim size is beyond a certain limit, the insurer will face a relatively high risk, which may cause the bankruptcy of the company; so, for this case, they will choose to purchase reinsurance.
In addition, we can observe that as the time t goes to T, that is, goes to ν, the insurer is willing to take more risks. This is because the unknown risks are reduced when tending toward the terminal time, and the insurance company retains more in order to reduce costs.
Corollary 2. When the model is reduced to an independent risk model, that is, for and for any (we set ), the optimal retained strategy for every business is greater than that in the thinning-dependence model.
Proof. Equation (
11) can be rewritten as
where
.
For the independent risk model, (
13) is replaced by
By comparing the coefficients of (
21) and (
22), we find that
; thus, Equation (
21) has a smaller solution. Then, the proof is completed. □
Remark 5. We can understand that the independent risk model is reduced from the thinning-dependence model in the following way. For each business i, the claim only occurs from the risk source i, and the thinning probability for other businesses decreases to zero. Therefore, the insurer will choose to increase the optimal retained strategy for the ith business because the risk from other claims vanishes and they are willing to accept more risk from the ith business to maximize the expected utility of the terminal wealth.
4. Optimal Results for the Diffusion Model
Having analyzed the optimal results for the case of the compound Poisson risk model, we shall study the optimal strategy for the diffusion approximation model, as [
21] pointed out that diffusion approximation is good for a long-term picture or when facing high jump intensity. According to [
21], for
,
can be approximated by
where
are
n standard Brownian motions with correlation coefficient matrix
where
Therefore, the process
in Equation (
2) is
where
is a standard Brownian motion.
In this problem, we define the admissible strategy as follows.
Definition 2. (Admissible control) The control is said to be admissible if and only if
- (1)
for any , is increasing with respect to and ,
- (2)
is a -measurable process,
- (3)
in association with , the state Equation (23) have a unique strong solution.
The set of all admissible strategies is denoted by .
Then, to study the optimal results for the diffusion approximation model, we define the objective function at time
t with the strategy
as
and our aim is to find the value function
and the optimal strategy
such that
. Again, from the standard arguments of the dynamic programming approach, we can see that if the optimal value function
and its partial derivatives
,
, and
are continuous on
, then
satisfies
with the boundary condition
According to Lemma 1, we can also construct a solution to the HJB Equation (
24) with the boundary condition (
25) as
Now, we find the extreme point
, which is the maximizer of (
24). Firstly, we would like to find the best response
to other strategies when
are given, as shown in the following theorem.
Theorem 6. Given the other strategies , the best response is Proof. According to (
26) and the point-by-point optimization, we get the following best-response strategy:
Here, we can find that the best-response strategy is affected by the other given strategies due to the term
. So, it is actually a function of
, and we can rewrite (
27) as
which completes the proof. □
Then, as shown in
Section 3, we give the necessary condition that (
24) needs to achieve its maximum, in Theorem 7. Before that, we give some notations for convenient expression:
Theorem 7. If is the maximum point of (24), then we have the conclusion that for any , where satisfies the following system of equations: Furthermore, if is the unique solution of (28), then will be the minimum point of (24). We can see that
is determined, and we only need to derive
for every
. From the above expression, it is easy to see that
If we denote
, then
and
where
is the survival function. Obviously, there is a one-to-one relationship between
and
. Consequently, solving (
28) is equivalent to solving
for all
. If we denote
then
can be rewritten as
and then, the result about the existence and uniqueness of
is given by Theorem 8.
Theorem 8. The solution of the system of equationsalways exists for . In addition, it is unique when . Proof. Similarly to the compound Poisson model, we also use the mathematical induction method to prove the existence.
Firstly, we show that when
, there is at least one solution
that satisfies (
32). Putting
into the second equation, we obtain
Let
; we find that
which comes from the fact that
is bounded for
. Then,
has at least one solution, which implies the existence of the solution of Equation (
32) with
.
Suppose that the conclusion is true for
. Now, we prove that it is also correct for
. Let
, and fix
. According to the assumption, the solution for the first
k equations exists and is a function of
, which can be written as
. Substituting it into the last equation, we have
Let
; then, it is not difficult to find that
Thus, has at least one solution , which completes the proof of the existence.
In the following, we prove the uniqueness for the case of
. If we assume that there are two solutions
and
, by substituting them into Equation (
32), we obtain
Accordingto the Lagrange theorem, there exist
such that
Then, Equation (
33) can be expressed as
From(
29) and (
31), it is easy to see that
, so we find that the only solution of (
34) is
which completes the proof. □
Remark 6. For the case of , we can use a similar method to study the uniqueness. If the coefficient matrix of the system of linear equations with respect to is reversible, then the uniqueness of the solution is established. However, in this paper, this condition may not be satisfied when .
Once we get the maximum point, we can derive the solution of the HJB equation, and from the standard dynamic programming theory, we have the following verification theorem.
Theorem 9. If is the maximum point in (24), thenwhereis the solution to the HJB Equation (24). Furthermore, we have , and the optimal reinsurance strategy is given by . Remark 7. When the general case is reduced to the variance premium, that is, for any , then from (30), we find that are all negative. This means that the insurer will choose to transfer all of the small-size claims () to the reinsurance company and retain a proportion of the excess of the large claims. When reduced to the expected value premium, that is, for any , which implies , the optimal strategy is the excess-of-loss reinsurance strategy when . In the case of , we have , and the negative solution is equivalent to zero, i.e., if the solution of (32) is and , then is equivalent to . Taking the two-dimensional case as an example, the set of equations (32) is reduced to If the solution is and , then , and from the first equation of (35), we obtain . Therefore, , and this is equivalent to . Corollary 3. For the diffusion approximation of the classical C-L model, the optimal strategy satisfies the following equation: With the constraint , is given by Moreover, the optimal strategy for the diffusion approximation model is always greater than that for the compound Poisson model.
Proof. It is not hard to prove the result of (
37). Here, we only focus on the proof of the second part. We denote the solutions of (
21) and (
36) as
and
, respectively. From (
21), we have
and according to (
36), we can get
Since the inequality
for any
holds, we have
and thus,
, which completes the proof. □
Remark 8. As in Corollary 3, we can see that the insurer will choose to retain all of the business claims when the claim size is no more than and will transfer some when . We also find that the retained strategy increases as the time t goes to the terminal time T.
Corollary 4. For the independent risk model, that is, for and for any (we set ), the optimal retained strategy for every business is also greater than that obtained with the thinning-dependence model.
Proof. Recalling that
but for the independent risk model, we have
for any
if
. Thus, the optimal retained strategy with the independent risk model is greater than that with the thinning-dependence model. □
In the following, a special case is investigated, where the variance safety loadings are all the same and the number of stochastic sources is . In this setting, we obtain some interesting results.
Proposition 1. If for all and , then the uniqueness of the solution will be guaranteed.
Proof. In this setting, from (
31), we find that
reduces to
and
reduces to
s. Therefore, the system of equations (
32) becomes
where
and
.
If there are two solutions
and
, substituting them into (
38), we obtain
There exist
s.t.
; then, we get
We find that the determinant of the coefficient matrix is
Thus, the coefficient matrix is invertible, so the only solution of (
39) is
which completes the proof. □
Proposition 2. Let the setting for all and holds. When the number of the business classes increases from k to and the solutions are changed from to , then for any .
Proof. When
, then (
38) becomes
By making the difference between the first
k equations of (
40) and the system of equations (
38) with
, we get
Similarly, according to the Lagrange mean-value theorem, there exist
s.t.
; then, (
41) becomes
We considerthat the coefficient matrix is invertible and
for any
. Then, by solving (
42), we find
□
Remark 9. One possible explanation of this phenomenon in Proposition 2 is that when increasing the business, the insurer confronts more risks. Therefore, the insurer may choose to transfer more claims to balance the potential risk.
Remark 10. When the model degenerates to the expected value premium, that is, , we have if , and thus, . This means that the original k strategies will remain the same when . This is the natural consequence, since implies full reinsurance for the th business and no increasing risk. However, for , the results will be the same as those in Proposition 2.
5. Some Properties and Numerical Examples
In this section, we will give the examples of for both the compound Poisson (CP) model and the diffusion approximation (DA) model, and we will analyze the impacts of the safety loading and thinning probability on the optimal strategies.
Example 1. We assume that the claim sizes and are exponentially distributed with parameters 1 and 2. For other parameters, we set . Without loss of generality, we set .
The main task is to calculate
and then derive the optimal strategies. For the compound Poisson model,
satisfies Equation (
15), that is,
in which
and
where
and
satisfy
and
respectively. Through some calculations, we obtain
.
For the diffusion approximation model,
satisfies
where
and
Through some calculations, we get
, and the optimal strategies are shown in
Figure 2 and
Figure 3.
We can find from the above figures that the insurer will choose to retain all when the claim size is small and will transfer part of the claim when it is beyond some boundary. In each of the two classes, the optimal retained strategy for the diffusion approximation model is higher than that for the compound Poisson model; this is consistent with the results in Corollary 3.
Example 2. In this example, we set and we will study the influence of on the optimal strategies.
In the same way as in Example 1, we can get the results of
, as shown in
Table 1, from which we can find that when
increases,
increases and
decreases. This means the optimal retention strategy for the first class also increases with both the compound Poisson model and the diffusion approximation model. However,
decreases and
increases, which implies that the retained strategy for the second class decreases. In fact, this is intuitive because as the expected safety loading increases for the first class, the insurer does not want to pay a higher reinsurance premium, so they choose to increase
; in order to balance the risk that they face, the insurer decreases
.
Example 3. In this example, we investigate the influence of on the optimal strategy by setting , and .
Again, we can get the values of
, as shown in
Table 2. In this case, when
changes,
will also change for the diffusion model, so we focus on the segment point
. Then, we can similarly find that when
increases, the optimal retention level for the first class also increases, but for the second one, it decreases. The explanation for this is the same as that in Example 2.
Example 4. In this example, in order to study the influence of the thinning probability on the optimal strategies, we set , and . The values of , and are shown in Table 3. From
Table 3, we can observe that when
increases, the first optimal retention strategy also increases, but the second one decreases. The reason is that the increase in the probability may lead to an increase in the claim number of the first class, which may allow the insurer to charge higher premiums, so they choose to retain more to reduce the influence of the reinsurance premium on the profit. Meanwhile, they will confront more risks, which may lead them to transfer more claims for the second class to balance the risk.
6. Conclusions
In this paper, we consider the optimal reinsurance problem for both the compound Poisson risk model and the diffusion approximation risk model with a thinning-dependence structure. We assume that the insurer can purchase per-loss reinsurance to manage their risk with a mean-variance reinsurance premium. Our formulation extends the work in the literature on optimal reinsurance for correlated risks in several ways. First, we extend the common-shock-dependent model studied by [
8,
10] to a thinning-dependence model, which is a more general model for describing the structure of dependence. Second, we extend the proportional reinsurance discussed by [
14,
15] to the per-loss reinsurance, which is more challenging in terms of technique. From the perspective of game theory, we obtain the closed-form expression of the optimal strategy for each class of insurance businesses, which is the best response to other strategies. We also derive the necessary conditions for optimal strategies, and these transfer the original optimization problem into a system of equations. Furthermore, we find that the solution of this system of equations always exists, but the uniqueness of the solution will only be guaranteed under some special circumstances for the diffusion model, such as when only two risky businesses are considered or the variance safety loadings are all the same. In addition, we compare the optimal retained strategies obtained with dependent risk models to those obtained with independent risk models, and the results show that the former are always greater than the latter.
For further research, one can study some other optimization problems, such as the minimization of the probability of absolute ruin and the mean-variance criterion, and can compare how different the optimal strategies are under different criteria. One can also add model uncertainty into this problem to see the difference of those results from the original results. All of the questions mentioned above will be more interesting and challenging.







{kind=link}
{kind=link}
{kind=link}