


An Aggregation Rule Based on the Binomial Distribution

{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
Motivating Examples
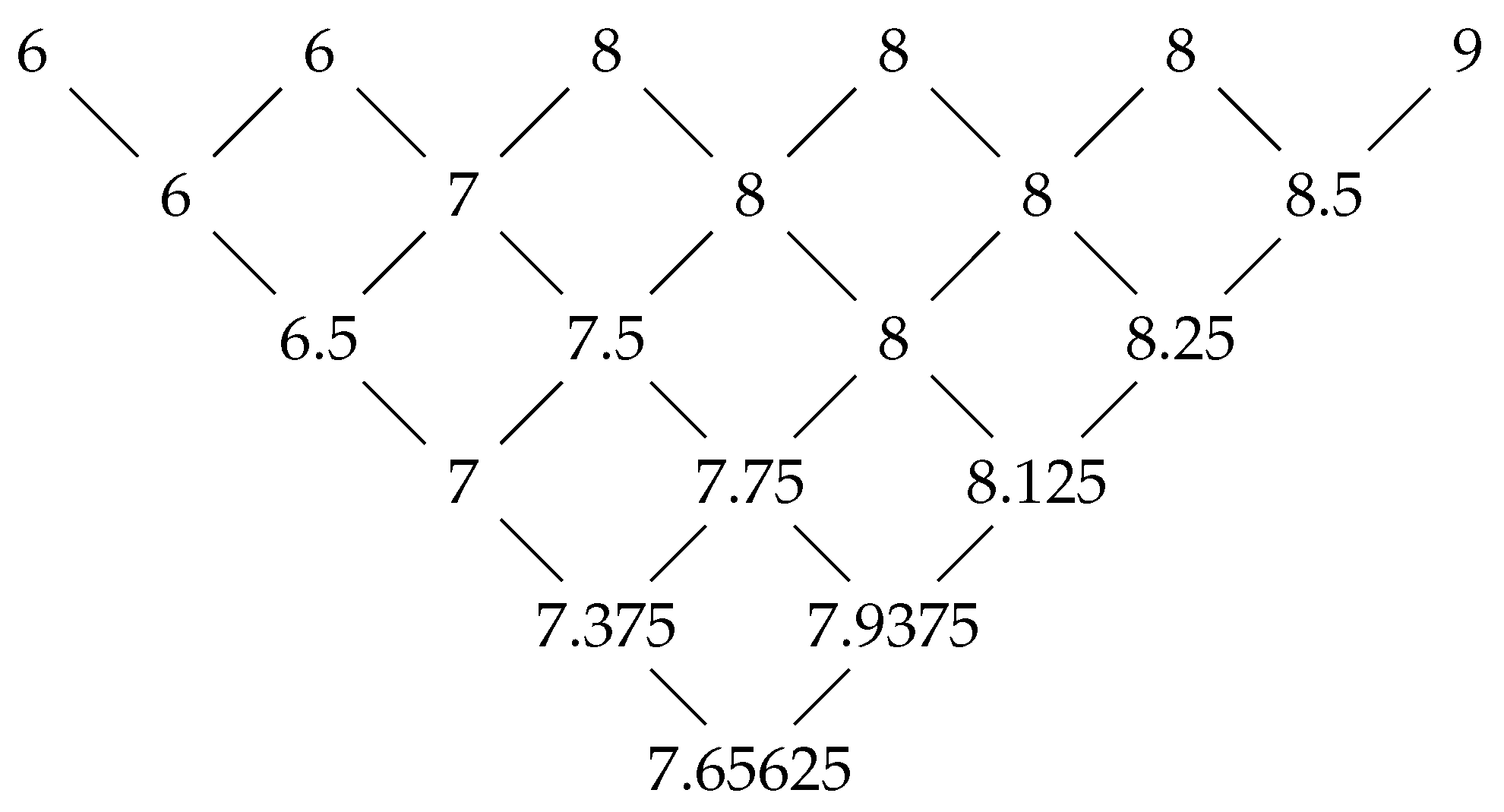
- Evaluating final degree projects and Ph.D. thesis: The evaluation of the project consists of the presentation and defense of an innovative work. The jury of the project is usually made up of three or five professors. It is usually five when it comes to doctoral theses. Each member of the committee proposes a grade. The final qualification awarded by the committee is deduced from the individual grades. Some aspects are crucial for the student: pass or not, cum laude or not.The mean of the individual grades is often used to obtain the student’s final grade. For instance, assume that the grades are on an integer scale from 0 to 10. The mean is , the median is 9 and the proposed rule in this paper yields .
- Judging professors by students in universities: Students evaluate their professors according to their satisfaction with their teaching performance. They are allowed to assign an integer number from one (very unsatisfactory) to five (very satisfactory). Thus, each professor gets a score between one and five per course, which is the mean of students’ scores. A professor usually teaches between 10 and 20 courses every five years, and therefore obtains an aggregated score of the five-year period, which is again the mean of all the courses taught.Professors can request a teaching supplement every 5 years. A very important criterion is the assessment obtained by students during these 5 years. A professor needs a minimum mark of three to obtain the five-year teaching supplement. For instance, assume the scores per course obtained by a professor in the 10 courses taught in a five-year period were:The mean is which has fatal consequences for the professor, the median is and the proposed rule is .
- Rating companies by debt agencies: Debt rating agencies (such as Standard and Poors, Fitch, Moody’s or DBR, among others) evaluate companies. They use a rating scale, which goes from the best evaluation to the worst evaluation and comprises 21 degrees. The rating scale is mainly divided into two sections or categories: investment (from 1st to 10th) and speculative (from 11th to 21st). Different agencies provide company rankings simultaneously. The way their qualifications are aggregated is fundamental for the company, investors of the company and potential future investors. Assume, that the qualifications of the four agencies for a certain company are: . If the mean, which is over 10, is used to aggregate these evaluations, the company’s category is declared speculative. Instead, the proposed rule assigns 10, which corresponds to the last level of investment category. Note that in this example, I have taken the ordinal criterion so that the lower the number, the better the rating.
- Doctoral student selection problem: Some universities offer programs for gaining the doctoral (Ph.D.) degree. The process to select students is open to students from everywhere. In most of the cases, the number of applicants is much greater than the number of available scholarships, so the candidates must be ranked. The problem of selecting young promising doctoral researchers can be seen to consist of a collection of applicants for the Ph.D. program and a set of experts who grade each applicant by using a pre-established set of allowed scores. An application of this problem at the Graduate School of Turku Center for Computer Science in Finland has been studied by using ordered weighted averages in [5].
- Artistic sports competitions: Some sports competitions require the evaluation of athletes performance by a panel of judges, such as diving, artistic skating, gymnastics, rhythmic gymnastics, dancing, riding, etc. The rules used are very diverse and range from the mean (used by several federations, for example, the International Federation for Equestrian Sports), the median (the synthesis of the scores of each subjury in rhythmic gymnastics is a median), trimmed means (used in various cases of diving) to some sophisticated methods. Other interesting techniques have been proposed by Crowley [6] or Gambarelli [7]. Both used the arithmetic mean of some scores. The first technique was based on discarding a fixed number of scores being the furthest from the median, while the second only discards scores when these were considered to be inappropriate. Regulations of some international federations collect the use of these rules, see, e.g., [8].
- Judging the judges: Federations, companies or universities are also interested in evaluating the judges that make up the evaluation panel after each evaluative activity. Judges that are too strict or not rigorous enough with the majority of the candidates are less appropriate for the constitution of new panels. Neither the mean nor the median are useful rules for detecting such extreme form of grading. The rule proposed in the article is also ideal for detecting these profiles of judges and therefore to establish rankings of judges based on their past performances as judges.
- 7.
- Ranking of research projects by scientific committees: The main distinction with the fourth example above is that in this example, the expected number of applicants is usually huge.
- 8.
- Ranking of restaurants or movies on designed websites: At a given time, the set N is large and formed from all the people who have rated these restaurants or these movies. In most of the previous examples, N is not necessarily large.
2. Ordered Weighted Averages
Properties and Examples of Ordered Weighted Averages
- 1.
- Idempotency: for all .
- 2.
- Boundness: If , then .
- 3.
- Monotonicity: If , then
- 4.
- Strict monotonicity: If and , then
- 5.
- Symmetry: for all .
- 6.
- Positivity: for all i.
- 7.
- ID-monotonicity: if and , and if and .
- 8.
- Strict ID-monotonicity: if , and and if and .
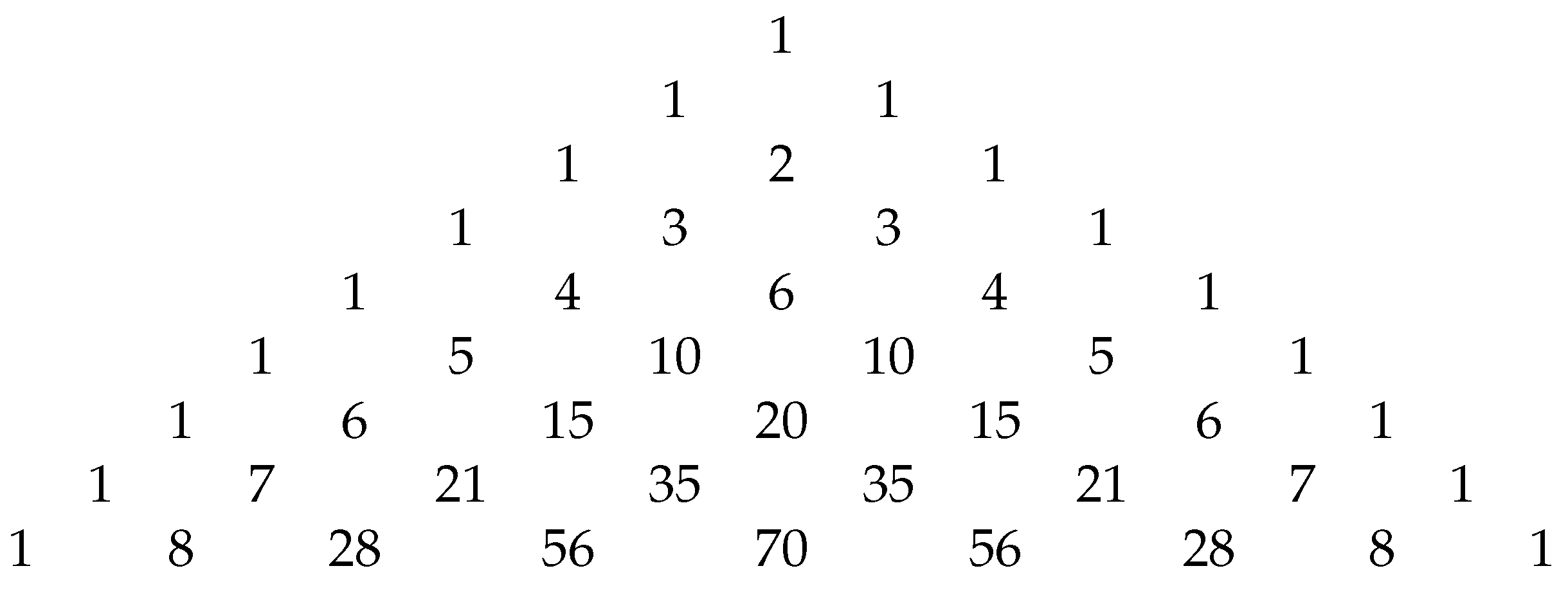
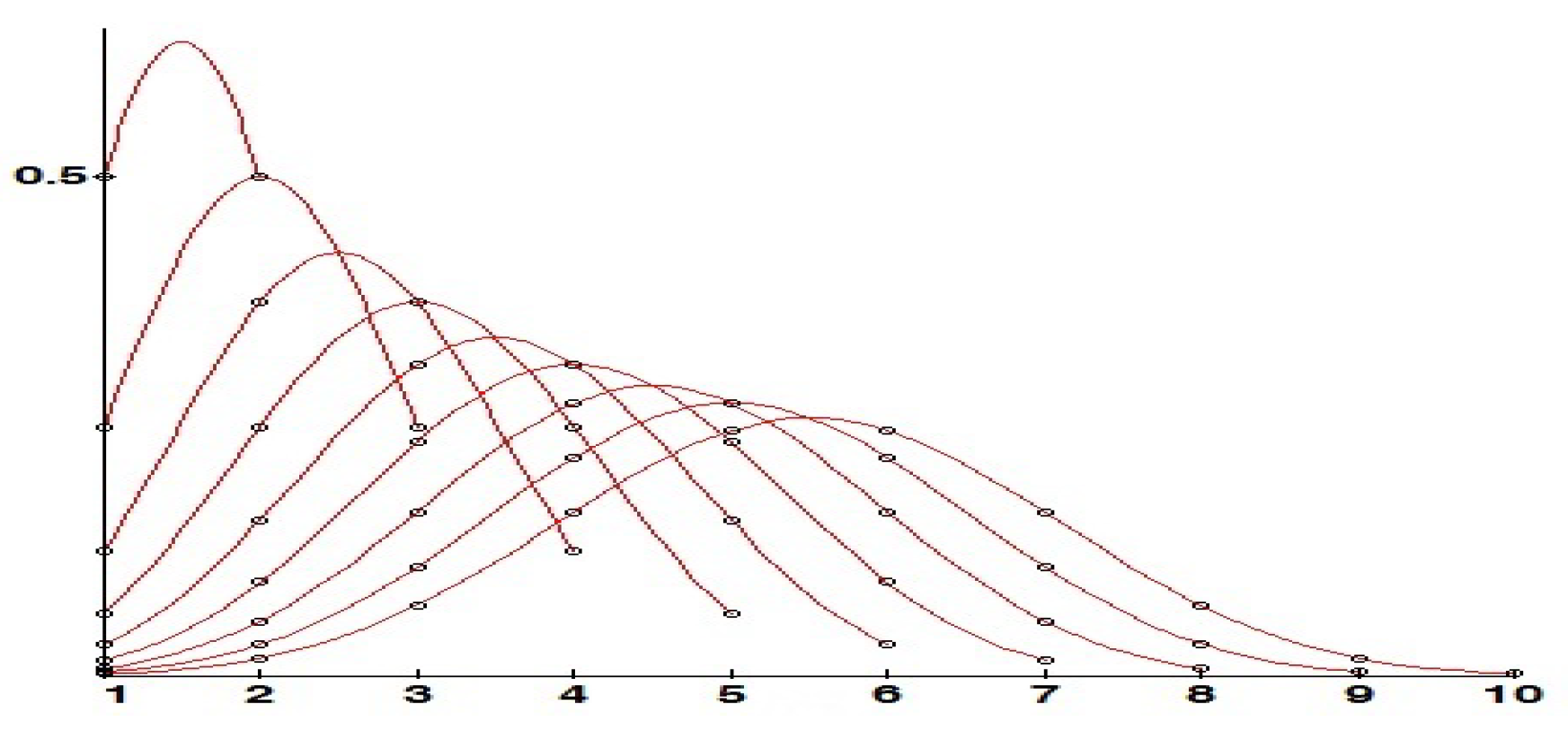
3. Binomial OWA Rules
Variants of the F-Rule
4. Some Characterizations of the F-Rule
4.1. A Characterization as a Binomial Rule
- A binomial rule is symmetric if and only if .
- A binomial rule is ID-monotonic for n large enough if and only if .
- The converse is clear sincefor all , which implies . For the direct implication, assume that the binomial rule is symmetric, then for all , which implies . Thus, and .
- The converse is clear sincewhich, respectively, imply if and if .For the direct implication, I assume that the binomial rule is not the F-rule, i.e., .Assume first that and n is odd. ConsiderAs is a fixed number and there exists some such that for all , it holds that , which ensures that ID-monotonicity fails. The proof for and n even is analogous to the former one by checking that for n large enough, which ensures that ID-monotonicity fails.The proof for is analogous to the previous one by checking, in the odd case, that for n large enough, and that for n large enough, inequalities that lead to failures of ID-monotonicity.
- The F-rule is the only binomial rule which satisfies symmetry.
- The F-rule is the only binomial rule which satisfies ID-monotonicity.
4.2. A Characterization as an OWA Rule
5. Other Significant Advantages of Using the -Rule
5.1. Discrimination
5.2. Almost Independence of Extreme Judges’ Scores
5.3. Almost Consistency with Its Variants
5.4. Computational Simplicity
6. Conclusions
- It is based on the binomial (and normal) distribution;
- It is sensitive to an increase or decrease of any judge’s score;
- It is representative of the panel of judges; all judges’ scores count;
- It discriminates very well and ties among candidates are almost avoided;
- It mostly concentrates the aggregated score in the intermediate judges’ scores, and this tendency increases when the number of members in the panel increases;
- It is consistent with its variants or , so that reversals are almost nonexistent;
- It has very little dependence on extreme judges’ scores; although potential judges’ manipulation is not fully avoided, at least it is considerably minimized when compared with other rules such as the mean;
- Close versions or can prevent having a few manipulators or radical judges, while keeping almost all the ideas that support F; the hypothetical presence of manipulators or radical judges may suggest the use of one of these two variants;
- It is also useful to evaluate the post judges’ reliability. A way to do that is by summing the coefficients assigned by the judge to all the candidates being evaluated. Judges who are poorly scored in this way can be potentially penalized;
- It is transparent, very simple to compute and therefore easy to be understood for candidates and potential audience;
- It has been shown to be applicable as a tie-breaking system in open tournaments with a limited number of rounds and many participants, e.g., as in chess, go, scrabble, bridge, etc., see [17].
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| OWA | Ordered weighted average |
| IAR | Invariant average reduction |
References
- Hillinger, C. The case for utilitarian voting. Homo Oeconomicus 2005, 23, 295–321. [Google Scholar] [CrossRef]
- Macé, A. Voting with evaluations: Characterizations of evaluative voting and range voting. J. Math. Econ. 2018, 79, 10–17. [Google Scholar] [CrossRef]
- Balinski, M.L.; Laraki, R. Majority Judgement: Measuring, Ranking, and Electing; The MIT Press: Cambridge, MA, USA, 2011. [Google Scholar]
- Aleskerov, F.; Chistyakov, V.V.; Kalyagin, V. The threshold aggregation. Econ. Lett. 2010, 107, 261–262. [Google Scholar] [CrossRef]
- Carlsson, C.; Fullér, R.; Fullér, S. OWA operators for doctoral student selection problem. In The Ordered Weighted Average Operators: Theory and Applications; Yager, R.R., Kacprzyk, J., Eds.; Kluwer Academic Publishers: London, UK, 1997; pp. 167–177. [Google Scholar]
- Crowley, L. The best average: It’s time to change how we compute scores. Int. Gymnast. 2002, 44, 34. [Google Scholar]
- Gambarelli, G. The ‘coherent majority average’ for juries’ evaluation processes. J. Sport. Sci. 2008, 26, 1091–1095. [Google Scholar] [CrossRef] [PubMed]
- Technical Regulations 2022. Fédération Internationale de Gymnastique. Available online: https://www.gymnastics.sport/site/ (accessed on 19 October 2022).
- Csiszar, O. Ordered weighted averaging operators: A short review. IEEE Syst. Man, Cybern. Mag. 2021, 7, 4–12. [Google Scholar] [CrossRef]
- Yager, R.R. On ordered weighted averaging aggregation operators in multicriteria decision making. IEEE Trans. Syst. Man Cybern. 1988, 18, 183–190. [Google Scholar] [CrossRef]
- Yager, R.R.; Kacprzyk, J. The Ordered Weighted Averaging Operators, Theory and Applications; Kluwer Academic Publishers: London, UK, 1997. [Google Scholar]
- Montero, J.; Cutello, V. Aggregation rules in committee procedures. In The Ordered Weighted Average Operators: Theory and Applications; Yager, R.R., Kacprzyk, J., Eds.; Kluwer Academic Publishers: London, UK, 1997; pp. 219–237. [Google Scholar]
- Freixas, J.; Parker, C. Manipulation in games with multiple levels of output. J. Math. Econ. 2015, 61, 144–151. [Google Scholar] [CrossRef][Green Version]
- Gibbard, A. Manipulation of voting schemes: A general result. Econometrica 1973, 41, 587–601. [Google Scholar] [CrossRef]
- Moulin, H. On strategy-proofness and single peakedness. Econometrica 1980, 35, 437–455. [Google Scholar] [CrossRef]
- Satterthwaite, M.A. Strategy-proofness and Arrow’s conditions: Existence and correspondence theorems for voting procedures and social welfare functions. J. Econ. Theory 1975, 10, 187–217. [Google Scholar] [CrossRef]
- Freixas, J. The decline of the Buchholz tiebreaker system: A preferable alternative. In Transactions on Computational Collective Intelligence, vol. XXXVII. Lecture Notes on Computer Science, 13750; Nguyen, N.T., Kowalczyk, R., Mercik, J., Motylska-Kuźma, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2022. [Google Scholar]



Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Freixas, J. An Aggregation Rule Based on the Binomial Distribution. Mathematics 2022, 10, 4418. https://doi.org/10.3390/math10234418
Freixas J. An Aggregation Rule Based on the Binomial Distribution. Mathematics. 2022; 10(23):4418. https://doi.org/10.3390/math10234418
Chicago/Turabian StyleFreixas, Josep. 2022. "An Aggregation Rule Based on the Binomial Distribution" Mathematics 10, no. 23: 4418. https://doi.org/10.3390/math10234418
APA StyleFreixas, J. (2022). An Aggregation Rule Based on the Binomial Distribution. Mathematics, 10(23), 4418. https://doi.org/10.3390/math10234418