
Probability and Certainty in the Performance of Evolutionary and Swarm Optimization Algorithms




Abstract
1. Introduction
That any two algorithms are equivalent when their performance is averaged across all possible problems.
In EC (EC is the abbreviation for Evolutionary Computation), it is typical to suggest that algorithm A is better than algorithm B if its average performance is better. In practical applications, however, one is often interested in the best solution found in X runs or within Y days (peak performance), and the average performance is not that relevant…
2. Quantiles or Percentiles in Measuring Algorithmic Performance
Measures of position are used to describe the position a specific data value possesses in relation to the rest of the data when in ranked order. Quartiles and percentiles are two of the most popular measures of position.
- Percentiles can be used for peak performance, average performance and bad-case performance. In the case of minimization problems for peak performance, it would be suitable to use , , , , etc. For average performance, it would be suitable to use the median instead of the arithmetic mean, and for bad-case performance Q3 = , , , etc.
- Percentiles have a nice interpretation in a way that says something about the solution quality and the probability of achieving such a solution. This is in the case that computational resources such as time or the number of generated solutions is constrained, and the solution quality is the observed value; e.g., there is at least a 50% probability of achieving a solution of quality or better. In a different case, when the required solution quality is specified, and time (or the number of function evaluations or some other computational resource) is the observed value, percentiles can provide data about time and probability that a specified solution will be obtained within such time; e.g., there is at least a 50% probability that a solution of the specified quality will be obtained in, at most, time.
- Percentiles can take into account the common and useful practice of multiple runs of an algorithm for the same problem instance. The advantage of the stochastic nature of algorithms can be exploited in this way. Table 1 contains the probabilities for a certain number of repetitions (n) and quantiles (), so when the algorithm is run only once, there is at least a 0.75 probability of obtaining a solution of quality or better than that. When the same algorithm is repeated 10 times, there is at least a 0.9437 probability of obtaining a solution of quality or better, and at least a 0.99999905 probability of achieving a solution of quality or better. The probability of 0.99999905 is calculated based on the equation in [18], and is rounded to 1.0000 in Table 1.
- Percentiles can be used even when the arithmetic mean is impossible to calculate. This applies only to the case when the required solution quality is specified and the needed time (number of generated solutions, number of iterations or some other computational resources) is the observed value.
- Evolutionary computation and swarm intelligence algorithms can have very asymmetrical distribution, and a 50th percentile (median) can be more adequate than the arithmetic mean for average performance.
3. Statistical Errors
- .
4. Experimental Research
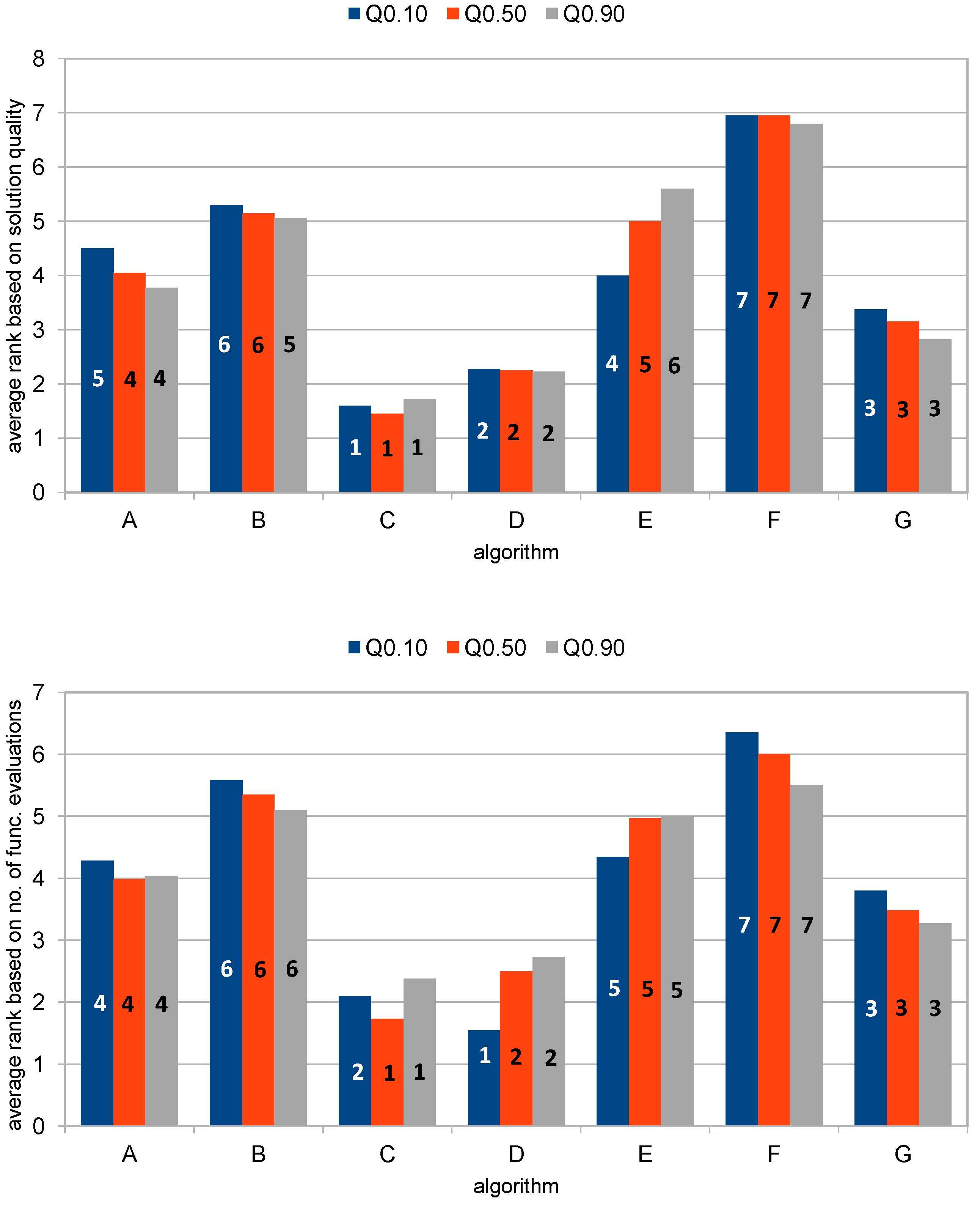
4.1. Average Observed Solution Quality
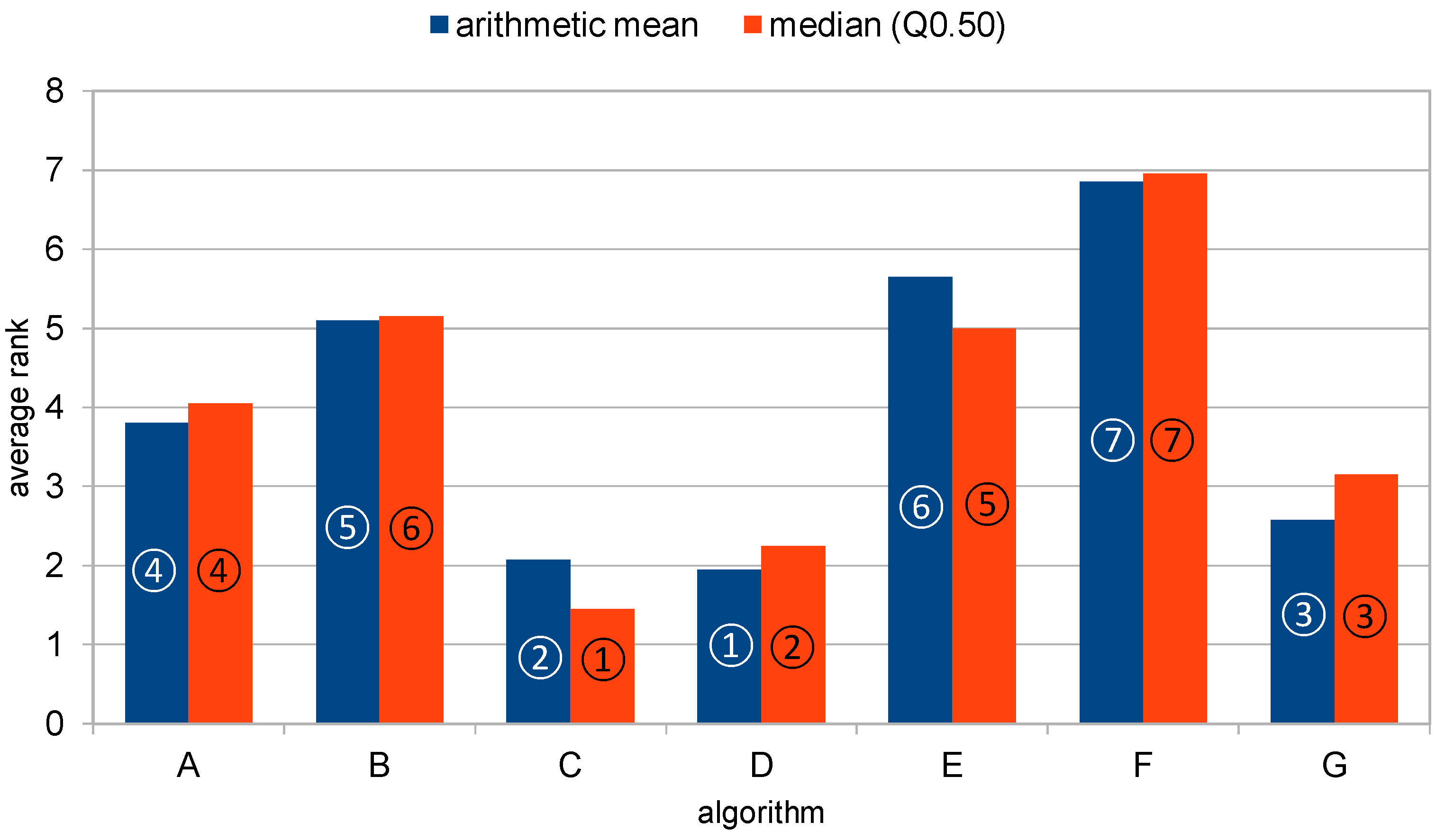
4.2. Disagreement of Mean and Median
4.3. Average Observed Number of Function Evaluations
4.4. Peak Performance and Bad-Case Performance
4.5. Confidence Interval for Calculated Statistic
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Parameters of the Algorithms Used in this Research
- ABC (A)
- -
- population size (pop_size) = 60
- -
- food number (foodNumber) = 30
- CRO (B)
- -
- width of coral reef grid (n) = 10
- -
- height of coral reef grid (m) = 10
- -
- percentage of an initially occupied reef (rho) = 0.6
- -
- percentage of broadcast spawners (fbs) = 0.9
- -
- percentage of depredated corals (rho) = 0.1
- -
- percentage of broadcast spawners (fbs) = 0.1
- -
- attempts to settle (attemptsToSettle) = 3
- JADE (C)
- -
- population size (pop_size) = 30
- -
- CR mean adaptive control parameter (muCR) = 0.5
- -
- location adaptive control parameter (muF) = 0.5
- -
- elite factor (p) = 0.05
- -
- adaptive factor (c) = 0.1
- JDE (D)
- -
- population size (pop_size) = 30
- PSO (E)
- -
- population size (pop_size) = 30
- -
- inertia weight (omega) = 0.7
- -
- cognitive coefficient (C1) = 1.4
- -
- social coefficient (C2) = 1.4
- RWSi (F)
- jDElscop (G)
- -
- starting population size (variable_pop_size) = 100
Appendix B. All Solutions Obtained by Algorithm E on Problem Instance F13
References
- Arora, S.; Barak, B. Computational Complexity: A Modern Approach, 1st ed.; Cambridge University Press: Cambridge, UK, 2009. [Google Scholar]
- Hromkovic, J. Algorithmics for Hard Problems—Introduction to Combinatorial Optimization, Randomization, Approximation, and Heuristics, 2nd ed.; Texts in Theoretical Computer Science. An EATCS Series; Springer: Berlin/Heidelberg, Germany, 2004. [Google Scholar] [CrossRef]
- Wolpert, D.; Macready, W. No free lunch theorems for optimization. IEEE Trans. Evol. Comput. 1997, 1, 67–82. [Google Scholar] [CrossRef]
- Wolpert, D.; Macready, W. Coevolutionary free lunches. IEEE Trans. Evol. Comput. 2005, 9, 721–735. [Google Scholar] [CrossRef]
- Derrac, J.; García, S.; Molina, D.; Herrera, F. A practical tutorial on the use of nonparametric statistical tests as a methodology for comparing evolutionary and swarm intelligence algorithms. Swarm Evol. Comput. 2011, 1, 3–18. [Google Scholar] [CrossRef]
- Halim, A.H.; Ismail, I.; Das, S. Performance assessment of the metaheuristic optimization algorithms: An exhaustive review. Artif. Intell. Rev. 2021, 54, 2323–2409. [Google Scholar] [CrossRef]
- Osaba, E.; Villar-Rodriguez, E.; Del Ser, J.; Nebro, A.J.; Molina, D.; LaTorre, A.; Suganthan, P.N.; Coello Coello, C.A.; Herrera, F. A Tutorial On the design, experimentation and application of metaheuristic algorithms to real-World optimization problems. Swarm Evol. Comput. 2021, 64, 100888. [Google Scholar] [CrossRef]
- Mernik, M.; Liu, S.H.; Karaboga, D.; Črepinšek, M. On clarifying misconceptions when comparing variants of the Artificial Bee Colony Algorithm by offering a new implementation. Inf. Sci. 2015, 291, 115–127. [Google Scholar] [CrossRef]
- Črepinšek, M.; Liu, S.H.; Mernik, M. Replication and comparison of computational experiments in applied evolutionary computing: Common pitfalls and guidelines to avoid them. Appl. Soft Comput. 2014, 19, 161–170. [Google Scholar] [CrossRef]
- Liu, Q.; Gehrlein, W.V.; Wang, L.; Yan, Y.; Cao, Y.; Chen, W.; Li, Y. Paradoxes in Numerical Comparison of Optimization Algorithms. IEEE Trans. Evol. Comput. 2020, 24, 777–791. [Google Scholar] [CrossRef]
- Yan, Y.; Liu, Q.; Li, Y. Paradox-free analysis for comparing the performance of optimization algorithms. IEEE Trans. Evol. Comput. 2022, 1–14. [Google Scholar] [CrossRef]
- LaTorre, A.; Molina, D.; Osaba, E.; Poyatos, J.; Del Ser, J.; Herrera, F. A prescription of methodological guidelines for comparing bio-inspired optimization algorithms. Swarm Evol. Comput. 2021, 67, 100973. [Google Scholar] [CrossRef]
- Carrasco, J.; García, S.; Rueda, M.; Das, S.; Herrera, F. Recent trends in the use of statistical tests for comparing swarm and evolutionary computing algorithms: Practical guidelines and a critical review. Swarm Evol. Comput. 2020, 54, 100665. [Google Scholar] [CrossRef]
- Omran, M.G.H.; Clerc, M.; Ghaddar, F.; Aldabagh, A.; Tawfik, O. Permutation Tests for Metaheuristic Algorithms. Mathematics 2022, 10, 2219. [Google Scholar] [CrossRef]
- Eiben, A.E.; Jelasity, M. A critical note on experimental research methodology in EC. In Proceedings of the Evolutionary Computation, 2002, CEC ’02, Washington, DC, USA, 12–17 May 2002; IEEE Press: Honolulu, HI, USA, 2002; Volume 1, pp. 582–587. [Google Scholar] [CrossRef]
- Birattari, M.; Dorigo, M. How to assess and report the performance of a stochastic algorithm on a benchmark problem: Mean or best result on a number of runs? Optim. Lett. 2007, 1, 309–311. [Google Scholar] [CrossRef]
- Eiben, A.E.; Smith, J.E. Introduction to Evolutionary Computing; Springer: Berlin/Heidelberg, Germany; New York, NY, USA, 2003. [Google Scholar]
- Ivkovic, N.; Jakobovic, D.; Golub, M. Measuring Performance of Optimization Algorithms in Evolutionary Computation. Int. J. Mach. Learn. Comp. 2016, 6, 167–171. [Google Scholar] [CrossRef]
- Johnson, R.; Kuby, P. Elementary Statistics, 11th ed.; Cengage Learning: Boston, MA, USA, 2012. [Google Scholar]
- WHO Multicentre Growth Reference Study Group. WHO Child Growth Standards: Length/Height-for-Age, Weight-for-Age, Weight-for-Length, Weight-for-Height and Body Mass Index-for-Age: Methods and Development; World Health Organization: Geneva, Switzerland, 2006.
- Port, S.; Demer, L.; Jennrich, R.; Walter, D.; Garfinkel, A. Systolic blood pressure and mortality. Lancet 2000, 355, 175–180. [Google Scholar] [CrossRef]
- Kephart, J.L.; AU Sánchez, B.N.; Moore, J.; Schinasi, L.H.; Bakhtsiyarava, M.; Ju, Y.; Gouveia, N.; Caiaffa, W.T.; Dronova, I.; Arunachalam, S.; et al. City-level impact of extreme temperatures and mortality in Latin America. Nat. Med. 2022, 28, 1700–1705. [Google Scholar] [CrossRef]
- Born, D.P.; Lomax, I.; Rüeger, E.; Romann, M. Normative data and percentile curves for long-term athlete development in swimming. J. Sci. Med. Sport 2022, 25, 266–271. [Google Scholar] [CrossRef]
- Choo, G.H.; Seo, J.; Yoon, J.; Kim, D.R.; Lee, D.W. Analysis of long-term (2005–2018) trends in tropospheric NO2 percentiles over Northeast Asia. Atmos. Pollut. Res. 2020, 11, 1429–1440. [Google Scholar] [CrossRef]
- Suzuki, T.; Hosoya, T.; Sasaki, J. Estimating wave height using the difference in percentile coastal sound level. Coast. Eng. 2015, 99, 73–81. [Google Scholar] [CrossRef]
- Iglesias, V.; Balch, J.K.; Travis, W.R. U.S. fires became larger, more frequent, and more widespread in the 2000s. Sci. Adv. 2022, 8, eabc0020. [Google Scholar] [CrossRef]
- Anjum, B.; Perros, H. Bandwidth estimation for video streaming under percentile delay, jitter, and packet loss rate constraints using traces. Comp. Commun. 2015, 57, 73–84. [Google Scholar] [CrossRef]
- Use Percentiles to Analyze Application Performance. Available online: https://www.dynatrace.com/support/help/how-to-use-dynatrace/problem-detection-and-analysis/problem-analysis/percentiles-for-analyzing-performance (accessed on 23 July 2022).
- Application Performance and Percentiles. Available online: https://www.atakama-technologies.com/application-performance-and-percentiles/ (accessed on 23 July 2022).
- Application Performance and Percentiles. 2018. Available online: https://www.adfpm.com/adf-performance-monitor-monitoring-with-percentiles/ (accessed on 23 July 2022).
- Measures Of Central Tendency For Wage Data. Available online: https://www.ssa.gov/oact/cola/central.html (accessed on 28 July 2022).
- Tang, K.; Li, X.; Suganthan, P.N.; Yang, Z.; Weise, T. Benchmark functions for the cec’2010 special session and competition on large-scale global optimization. In Nature Inspired Computation and Applications Laboratory; Technical report; University of Science and Technology of China: Anhui, China, 2009. [Google Scholar]
- Karaboga, D.; Basturk, B. A powerful and efficient algorithm for numerical function optimization: Artificial bee colony (ABC) algorithm. J. Global Optim. 2007, 39, 459–471. [Google Scholar] [CrossRef]
- Salcedo-Sanz, S.; Del Ser, J.; Landa-Torres, I.; Gil-López, S.; Portilla-Figueras, J. The coral reefs optimization algorithm: A novel metaheuristic for efficiently solving optimization problems. Sci. World J. 2014, 2014. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Sanderson, A.C. JADE: Adaptive Differential Evolution With Optional External Archive. IEEE Trans. Evol. Comp. 2009, 13, 945–958. [Google Scholar] [CrossRef]
- Brest, J.; Greiner, S.; Boskovic, B.; Mernik, M.; Zumer, V. Self-Adapting Control Parameters in Differential Evolution: A Comparative Study on Numerical Benchmark Problems. IEEE Trans. Evol. Comp. 2006, 10, 646–657. [Google Scholar] [CrossRef]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the International Conference on Neural Networks, Perth, WA, Australia, 27 November–1 December 1995; Volume 4, pp. 1942–1948. [Google Scholar]
- Brest, J.; Maučec, M.S. Self-adaptive differential evolution algorithm using population size reduction and three strategies. Soft Comp. 2010, 15, 2157–2174. [Google Scholar] [CrossRef]
- EARS—Evolutionary Algorithms Rating System (Github). 2016. Available online: https://github.com/UM-LPM/EARS (accessed on 20 October 2022).
- Fathollahi-Fard, A.M.; Hajiaghaei-Keshteli, M.; Tavakkoli-Moghaddam, R. The Social Engineering Optimizer (SEO). Eng. Appl. Artif. Intell. 2018, 72, 267–293. [Google Scholar] [CrossRef]
- Kudelić, R.; Ivković, N. Ant inspired Monte Carlo algorithm for minimum feedback arc set. Exp. Syst. Appl. 2019, 122, 108–117. [Google Scholar] [CrossRef]
- Soto-Mendoza, V.; García-Calvillo, I.; Ruiz-y Ruiz, E.; Pérez-Terrazas, J. A Hybrid Grasshopper Optimization Algorithm Applied to the Open Vehicle Routing Problem. Algorithms 2020, 13, 96. [Google Scholar] [CrossRef]
- Fathollahi-Fard, A.M.; Hajiaghaei-Keshteli, M.; Tavakkoli-Moghaddam, R. Red deer algorithm (RDA): A new nature-inspired meta-heuristic. Soft Comput. 2020, 24, 14637–14665. [Google Scholar] [CrossRef]
- Zainel, Q.M.; Darwish, S.M.; Khorsheed, M.B. Employing Quantum Fruit Fly Optimization Algorithm for Solving Three-Dimensional Chaotic Equations. Mathematics 2022, 10, 4147. [Google Scholar] [CrossRef]
- Liao, B.; Huang, Z.; Cao, X.; Li, J. Adopting Nonlinear Activated Beetle Antennae Search Algorithm for Fraud Detection of Public Trading Companies: A Computational Finance Approach. Mathematics 2022, 10, 2160. [Google Scholar] [CrossRef]
- Matsumoto, M.; Nishimura, T. Mersenne Twister: A 623-dimensionally Equidistributed Uniform Pseudo-random Number Generator. ACM Trans. Modeling Comput. Simul. 1998, 8, 3–30. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| No. of Runs | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0.0100 | 0.0500 | 0.1000 | 0.2000 | 0.2500 | 0.5000 | 0.7500 | 0.8000 | 0.9000 | 0.9500 | 0.9900 |
| 2 | 0.0199 | 0.0975 | 0.1900 | 0.3600 | 0.4375 | 0.7500 | 0.9375 | 0.9600 | 0.9900 | 0.9975 | 0.9999 |
| 3 | 0.0297 | 0.1426 | 0.2710 | 0.4880 | 0.5781 | 0.8750 | 0.9844 | 0.9920 | 0.9990 | 0.9999 | 1.0000 |
| 4 | 0.0394 | 0.1855 | 0.3439 | 0.5904 | 0.6836 | 0.9375 | 0.9961 | 0.9984 | 0.9999 | 1.0000 | 1.0000 |
| 5 | 0.0490 | 0.2262 | 0.4095 | 0.6723 | 0.7627 | 0.9688 | 0.9990 | 0.9997 | 1.0000 | 1.0000 | 1.0000 |
| 10 | 0.0956 | 0.4013 | 0.6513 | 0.8926 | 0.9437 | 0.9990 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
| 20 | 0.1821 | 0.6415 | 0.8784 | 0.9885 | 0.9968 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
| 30 | 0.2603 | 0.7854 | 0.9576 | 0.9988 | 0.9998 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
| 40 | 0.3310 | 0.8715 | 0.9852 | 0.9999 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
| 50 | 0.3950 | 0.9231 | 0.9948 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
| 100 | 0.6340 | 0.9941 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
| 200 | 0.8660 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
| 300 | 0.9510 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
| 400 | 0.9820 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
| 500 | 0.9934 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
| Algorithm A | Algorithm B | Algorithm C | Algorithm D | Algorithm E | Algorithm F | Algorithm G | |
|---|---|---|---|---|---|---|---|
| F01 | (3) | (5) | (1) | (2) | (6) | (7) | (4) |
| F02 | (4) | (5) | (1) | (2) | (6) | (7) | (3) |
| F03 | (4) | (5) | (1) | (2) | (6) | (7) | (3) |
| F04 | (7) | (5) | (3) | (2) | (4) | (6) | (1) |
| F05 | (4) | (5) | (1) | (2) | (6) | (7) | (3) |
| F06 | (4) | (5) | (3) | (1) | (6) | (7) | (2) |
| F07 | (3) | (5) | (1) | (2) | (6) | (7) | (4) |
| F08 | (4) | (5) | (2) | (3) | (6) | (7) | (1) |
| F09 | (7) | (6) | (3) | (1) | (4) | (5) | (2) |
| F10 | (4) | (5) | (1) | (2) | (6) | (7) | (3) |
| F11 | (4) | (5) | (3) | (2) | (6) | (7) | (1) |
| F12 | (1) | (5) | (4) | (2) | (6) | (7) | (3) |
| F13 | (4) | (5) | (1) | (3) | (6) | (7) | (2) |
| F14 | (5) | (4) | (1) | (2) | (6) | (7) | (3) |
| F15 | (4) | (5) | (2) | (1) | (6) | (7) | (3) |
| F16 | (5) | (6) | (2) | (1) | (4) | (7) | (3) |
| F17 | (3) | (5) | (4) | (2) | (6) | (7) | (1) |
| F18 | (4) | (6) | (2.5) | (1) | (5) | (7) | (2.5) |
| F19 | (1) | (5) | (3) | (2) | (6) | (7) | (4) |
| F20 | (1) | (5) | (2) | (4) | (6) | (7) | (3) |
| F.rank | 3.8 | 5.1 | 2.075 | 1.95 | 5.65 | 6.85 | 2.575 |
| Algorithm A | Algorithm B | Algorithm C | Algorithm D | Algorithm E | Algorithm F | Algorithm G | |
|---|---|---|---|---|---|---|---|
| F01 | (3) | (5) | (1) | (2) | (6) | (7) | (4) |
| F02 | (2) | (5) | (2) | (2) | (6) | (7) | (4) |
| F03 | (4) | (5) | (1) | (2) | (6) | (7) | (3) |
| F04 | (6) | (5) | (1) | (3) | (4) | (7) | (2) |
| F05 | (4) | (5) | (1) | (2) | (6) | (7) | (3) |
| F06 | (4) | (5) | (2) | (1) | (6) | (7) | (3) |
| F07 | (3) | (5) | (2) | (1) | (6) | (7) | (4) |
| F08 | (4) | (5) | (1) | (3) | (6) | (7) | (2) |
| F09 | (7) | (5) | (1) | (3) | (4) | (6) | (2) |
| F10 | (5) | (6) | (1) | (3) | (2) | (7) | (4) |
| F11 | (4) | (5) | (1) | (2) | (6) | (7) | (3) |
| F12 | (4) | (5) | (1.5) | (1.5) | (6) | (7) | (3) |
| F13 | (4) | (5) | (1) | (3) | (6) | (7) | (2) |
| F14 | (6) | (5) | (1) | (2) | (4) | (7) | (3) |
| F15 | (5) | (6) | (1.5) | (1.5) | (3) | (7) | (4) |
| F16 | (5) | (6) | (2) | (3) | (1) | (7) | (4) |
| F17 | (4) | (5) | (3) | (1) | (6) | (7) | (2) |
| F18 | (5) | (6) | (1) | (2) | (4) | (7) | (3) |
| F19 | (1) | (4) | (2) | (3) | (6) | (7) | (5) |
| F20 | (1) | (5) | (2) | (4) | (6) | (7) | (3) |
| F.rank | 4.05 | 5.15 | 1.45 | 2.25 | 5 | 6.95 | 3.15 |
| Algorithm A | Algorithm B | Algorithm C | Algorithm D | Algorithm E | Algorithm F | Algorithm G | |
|---|---|---|---|---|---|---|---|
| F01 | 5417 (5) | 53920 (7) | 4654 (3) | 3730 (2) | 5173 (4) | 1 (1) | 7446 (6) |
| F02 | 1264 (4) | 3433 (6) | 9855 (2) | 1027 (3) | 8842 (1) | n/a (7) | 1720 (5) |
| F03 | 4735 (4) | 12800 (6) | 2900 (3) | 2402 (2) | 2228 (1) | n/a (7) | 4996 (5) |
| F04 | n/a (5.5) | n/a (5.5) | 11450 (1) | 68470 (3) | n/a (5.5) | n/a (5.5) | 29860 (2) |
| F05 | 4537 (3) | 19820 (6) | 3323 (2) | 2604 (1) | 5471 (5) | n/a (7) | 4954 (4) |
| F06 | 52350 (4) | n/a (6) | 10640 (2) | 6566 (1) | n/a (6) | n/a (6) | 13320 (3) |
| F07 | 47830 (4) | n/a (6) | 13080 (2) | 7262 (1) | n/a (6) | n/a (6) | 18230 (3) |
| F08 | n/a (5.5) | n/a (5.5) | 8313 (1) | 15130 (2) | n/a (5.5) | n/a (5.5) | 19570 (3) |
| F09 | n/a (5.5) | n/a (5.5) | 6110 (1) | 15630 (3) | n/a (5.5) | n/a (5.5) | 12590 (2) |
| F10 | 2213 (5) | 4195 (6) | 9964 (2) | 1025 (3) | 7982 (1) | n/a (7) | 1794 (4) |
| F11 | 27390 (6) | 24840 (5) | 5549 (3) | 4821 (2) | 4128 (1) | n/a (7) | 9301 (4) |
| F12 | 27310 (5) | 39460 (6) | 7647 (2) | 4337 (1) | 17430 (4) | n/a (7) | 10460 (3) |
| F13 | 7259 (4) | 11510 (6) | 4168 (2) | 5003 (3) | 3705 (1) | n/a (7) | 7555 (5) |
| F14 | n/a (6) | n/a (6) | 3960 (1) | 4124 (2) | 48030 (4) | n/a (6) | 8014 (3) |
| F15 | 7702 (6) | 7197 (5) | 2439 (3) | 2152 (2) | 1977 (1) | 3698 (7) | 3027 (4) |
| F16 | 42300 (6) | 25410 (5) | 2016 (3) | 1298 (1) | 1669 (2) | n/a (7) | 3060 (4) |
| F17 | 26240 (5) | 26580 (6) | 6754 (3) | 3599 (2) | 3458 (1) | n/a (7) | 11040 (4) |
| F18 | 12220 (6) | 9326 (5) | 2734 (1) | 3701 (3) | 3616 (2) | n/a (7) | 4042 (4) |
| F19 | 48880 (4) | 66980 (5) | 15540 (2) | 9494 (1) | n/a (6.5) | n/a (6.5) | 27190 (3) |
| F20 | 20310 (2) | 20740 (3) | 10420 (1) | 38800 (5) | n/a (6.5) | n/a (6.5) | 31620 (4) |
| F.rank | 4.78 | 5.58 | 2 | 2.15 | 3.48 | 6.28 | 3.75 |
| Algorithm A | Algorithm B | Algorithm C | Algorithm D | Algorithm E | Algorithm F | Algorithm G | |
|---|---|---|---|---|---|---|---|
| F01 | 100% | 83% | 100% | 100% | 24% | 1% | 100% |
| F02 | 100% | 100% | 100% | 100% | 36% | 0% | 100% |
| F03 | 100% | 100% | 100% | 97% | 35% | 0% | 100% |
| F04 | 0% | 0% | 100% | 70% | 0% | 0% | 100% |
| F05 | 100% | 100% | 100% | 100% | 17% | 0% | 100% |
| F06 | 83% | 0% | 87% | 91% | 0% | 0% | 95% |
| F07 | 69% | 0% | 39% | 20% | 0% | 0% | 49% |
| F08 | 0% | 0% | 100% | 99% | 0% | 0% | 98% |
| F09 | 0% | 0% | 100% | 99% | 0% | 0% | 100% |
| F10 | 100% | 100% | 100% | 100% | 66% | 0% | 100% |
| F11 | 4% | 3% | 95% | 79% | 2% | 0% | 100% |
| F12 | 97% | 16% | 50% | 22% | 1% | 0% | 33% |
| F13 | 99% | 41% | 100% | 100% | 18% | 0% | 100% |
| F14 | 0% | 0% | 100% | 98% | 2% | 0% | 99% |
| F15 | 100% | 100% | 100% | 100% | 100% | 100% | 100% |
| F16 | 57% | 57% | 100% | 100% | 95% | 0% | 100% |
| F17 | 97% | 65% | 67% | 31% | 2% | 0% | 68% |
| F18 | 98% | 15% | 98% | 99% | 89% | 0% | 99% |
| F19 | 78% | 2% | 58% | 27% | 0% | 0% | 71% |
| F20 | 100% | 15% | 85% | 54% | 0% | 0% | 52% |
| Algorithm A | Algorithm B | Algorithm C | Algorithm D | Algorithm E | Algorithm F | Algorithm G | |
|---|---|---|---|---|---|---|---|
| F01 | 5417 | n/a | 4654 | 3730 | n/a | n/a | 7446 |
| F02 | 1264 | 3433 | 985.5 | 1027 | n/a | n/a | 1720 |
| F03 | 4735 | 12800 | 2900 | n/a | n/a | n/a | 4996 |
| F04 | n/a | n/a | 11450 | n/a | n/a | n/a | 29860 |
| F05 | 4537 | 19820 | 3323 | 2604 | n/a | n/a | 4954 |
| F06 | n/a | n/a | n/a | n/a | n/a | n/a | n/a |
| F07 | n/a | n/a | n/a | n/a | n/a | n/a | n/a |
| F08 | n/a | n/a | 8313 | n/a | n/a | n/a | n/a |
| F09 | n/a | n/a | 6110 | n/a | n/a | n/a | 12590 |
| F10 | 2213 | 4195 | 996.4 | 1025 | n/a | n/a | 1794 |
| F11 | n/a | n/a | n/a | n/a | n/a | n/a | 9301 |
| F12 | n/a | n/a | n/a | n/a | n/a | n/a | n/a |
| F13 | n/a | n/a | 4168 | 5003 | n/a | n/a | 7555 |
| F14 | n/a | n/a | 3960 | n/a | n/a | n/a | n/a |
| F15 | 770.2 | 719.7 | 243.9 | 215.2 | 197.7 | 3698 | 302.7 |
| F16 | n/a | n/a | 2016 | 1298 | n/a | n/a | 3060 |
| F17 | n/a | n/a | n/a | n/a | n/a | n/a | n/a |
| F18 | n/a | n/a | n/a | n/a | n/a | n/a | n/a |
| F19 | n/a | n/a | n/a | n/a | n/a | n/a | n/a |
| F20 | 20310 | n/a | n/a | n/a | n/a | n/a | n/a |
| F.rank | n/a | n/a | n/a | n/a | n/a | n/a | n/a |
| Algorithm A | Algorithm B | Algorithm C | Algorithm D | Algorithm E | Algorithm F | Algorithm G | |
|---|---|---|---|---|---|---|---|
| F01 | 5415 (3) | 57490 (5) | 4618 (2) | 3670 (1) | (6.5) | (6.5) | 7455 (4) |
| F02 | 1238 (3) | 3320 (5) | 979 (1) | 1002 (2) | (6.5) | (6.5) | 1727 (4) |
| F03 | 4729 (3) | 12840 (5) | 2897 (2) | 2418 (1) | (6.5) | (6.5) | 4967 (4) |
| F04 | (5.5) | (5.5) | 10800 (1) | 79390 (3) | (5.5) | (5.5) | 29770 (2) |
| F05 | 4535 (3) | 19820 (5) | 3302 (2) | 2539 (1) | (6.5) | (6.5) | 4940 (4) |
| F06 | 56480 (4) | (6) | 9671 (2) | 6069 (1) | (6) | (6) | 12190 (3) |
| F07 | 66490 (1) | (4.5) | (4.5) | (4.5) | (4.5) | (4.5) | (4.5) |
| F08 | (5.5) | (5.5) | 7876 (1) | 15240 (2) | (5.5) | (5.5) | 19360 (3) |
| F09 | (5.5) | (5.5) | 5494 (1) | 13610 (3) | (5.5) | (5.5) | 12530 (2) |
| F10 | 2044 (5) | 4039 (6) | 1001 (2) | 1026 (3) | 893 (1) | (7) | 1790 (4) |
| F11 | (5.5) | (5.5) | 5200 (2) | 4846 (1) | (5.5) | (5.5) | 9391 (3) |
| F12 | 23940 (2) | (5) | 9729 (1) | (5) | (5) | (5) | (5) |
| F13 | 5320 (3) | (6) | 4085 (1) | 4141 (2) | (6) | (6) | 7518 (4) |
| F14 | (5.5) | (5.5) | 3988 (2) | 3400 (1) | (5.5) | (5.5) | 7987 (3) |
| F15 | 655 (6) | 648 (5) | 250 (3) | 216 (2) | 193 (1) | 2903 (7) | 297 (4) |
| F16 | 80250 (6) | 45030 (5) | 1991 (3) | 1286 (1) | 1502 (2) | (7) | 3028 (4) |
| F17 | 22450 (3) | 42240 (4) | 7542 (1) | (6) | (6) | (6) | 8302 (2) |
| F18 | 7069 (5) | (6.5) | 2617 (1) | 3237 (2) | 3818 (3) | (6.5) | 3993 (4) |
| F19 | 60170 (3) | (5.5) | 17710 (1) | (5.5) | (5.5) | (5.5) | 28450 (2) |
| F20 | 14950 (2) | (6) | 10730 (1) | 61880 (3) | (6) | (6) | 93080 (4) |
| F.rank | 3.98 | 5.35 | 1.73 | 2.5 | 4.97 | 6 | 3.48 |
| Algorithm A | Algorithm B | Algorithm C | Algorithm D | Algorithm E | Algorithm F | Algorithm G | |
|---|---|---|---|---|---|---|---|
| F01 | (4) | (6) | (2) | (3) | (1) | (7) | (5) |
| F02 | (2) | (5) | (2) | (2) | (6) | (7) | (4) |
| F03 | (5) | (6) | (2) | (3) | (1) | (7) | (4) |
| F04 | (6) | (5) | (1) | (2) | (4) | (7) | (3) |
| F05 | (3) | (6) | (1) | (2) | (4) | (7) | (5) |
| F06 | (5) | (6) | (2) | (1) | (4) | (7) | (3) |
| F07 | (4) | (5) | (2) | (1) | (6) | (7) | (3) |
| F08 | (4) | (6) | (1) | (3) | (5) | (7) | (2) |
| F09 | (7) | (5) | (1) | (2) | (4) | (6) | (3) |
| F10 | (5) | (6) | (1.5) | (3) | (1.5) | (7) | (4) |
| F11 | (5) | (4) | (1) | (2) | (6) | (7) | (3) |
| F12 | (4) | (5) | (2) | (1) | (6) | (7) | (3) |
| F13 | (5) | (6) | (1) | (2) | (4) | (7) | (3) |
| F14 | (6) | (5) | (1) | (2) | (4) | (7) | (3) |
| F15 | (6) | (5) | (2.5) | (2.5) | (2.5) | (7) | (2.5) |
| F16 | (6) | (5) | (2) | (3) | (1) | (7) | (4) |
| F17 | (5) | (4) | (3) | (1) | (6) | (7) | (2) |
| F18 | (5) | (6) | (1) | (2) | (4) | (7) | (3) |
| F19 | (1) | (4) | (2) | (3) | (6) | (7) | (5) |
| F20 | (2) | (6) | (1) | (5) | (4) | (7) | (3) |
| F.rank | 4.5 | 5.3 | 1.6 | 2.275 | 4 | 6.95 | 3.375 |
| Algorithm A | Algorithm B | Algorithm C | Algorithm D | Algorithm E | Algorithm F | Algorithm G | |
|---|---|---|---|---|---|---|---|
| F01 | (3) | (5) | (1) | (2) | (6) | (7) | (4) |
| F02 | (2.5) | (5) | (1) | (2.5) | (6) | (7) | (4) |
| F03 | (4) | (5) | (1) | (2) | (6) | (7) | (3) |
| F04 | (7) | (5) | (1) | (3) | (4) | (6) | (2) |
| F05 | (4) | (5) | (1) | (2) | (6) | (7) | (3) |
| F06 | (4) | (5) | (3) | (1) | (6) | (7) | (2) |
| F07 | (3) | (5) | (2) | (1) | (6) | (7) | (4) |
| F08 | (4) | (5) | (1) | (3) | (6) | (7) | (2) |
| F09 | (7) | (6) | (1) | (3) | (4) | (5) | (2) |
| F10 | (4) | (5) | (1) | (2) | (6) | (7) | (3) |
| F11 | (4) | (5) | (3) | (1) | (6) | (7) | (2) |
| F12 | (1) | (5) | (4) | (2.5) | (6) | (7) | (2.5) |
| F13 | (4) | (5) | (1) | (3) | (6) | (7) | (2) |
| F14 | (5) | (4) | (1) | (2) | (7) | (6) | (3) |
| F15 | (4) | (5) | (1.5) | (1.5) | (6) | (7) | (3) |
| F16 | (5) | (6) | (3) | (2) | (1) | (7) | (4) |
| F17 | (4) | (5) | (2) | (2) | (6) | (7) | (2) |
| F18 | (4) | (5) | (1) | (3) | (6) | (7) | (2) |
| F19 | (1) | (5) | (3) | (2) | (6) | (7) | (4) |
| F20 | (1) | (5) | (2) | (4) | (6) | (7) | (3) |
| Algorithm A | Algorithm B | Algorithm C | Algorithm D | Algorithm E | Algorithm F | Algorithm G | |
|---|---|---|---|---|---|---|---|
| F01 | 4604 (3) | 36110 (6) | 4410 (2) | 3361 (1) | 5004 (4) | (7) | 7078 (5) |
| F02 | 1030 (4) | 2725 (6) | 874 (3) | 860 (2) | 690 (1) | (7) | 1468 (5) |
| F03 | 4051 (4) | 10410 (6) | 2637 (3) | 2182 (2) | 2119 (1) | (7) | 4608 (5) |
| F04 | (5.5) | (5.5) | 8611 (1) | 47700 (3) | (5.5) | (5.5) | 26870 (2) |
| F05 | 3827 (3) | 16150 (6) | 3090 (2) | 2256 (1) | 5700 (5) | (7) | 4581 (4) |
| F06 | 27130 (4) | (6) | 8373 (2) | 5501 (1) | (6) | (6) | 11560 (3) |
| F07 | 19750 (4) | (6) | 12630 (2) | 7223 (1) | (6) | (6) | 16870 (3) |
| F08 | (5.5) | (5.5) | 6349 (1) | 11830 (2) | (5.5) | (5.5) | 16660 (3) |
| F09 | (5.5) | (5.5) | 4184 (1) | 7850 (2) | (5.5) | (5.5) | 11000 (3) |
| F10 | 1322 (4) | 2777 (6) | 828 (3) | 796 (2) | 627 (1) | (7) | 1433 (5) |
| F11 | (5.5) | (5.5) | 4361 (2) | 3628 (1) | (5.5) | (5.5) | 8076 (3) |
| F12 | 9873 (3) | 44820 (5) | 6692 (2) | 4164 (1) | (6.5) | (6.5) | 10010 (4) |
| F13 | 3245 (3) | 9456 (6) | 2966 (2) | 2461 (1) | 4443 (4) | (7) | 6080 (5) |
| F14 | (5.5) | (5.5) | 3143 (2) | 2283 (1) | (5.5) | (5.5) | 6479 (3) |
| F15 | 367 (5) | 383.6 (7) | 132 (3) | 124 (2) | 110 (1) | 383 (6) | 172 (4) |
| F16 | 15720 (6) | 9685 (5) | 1752 (3) | 1093 (1) | 1263 (2) | (7) | 2553 (4) |
| F17 | 8557 (5) | 5600 (2) | 5705 (3) | 3163 (1) | (6.5) | (6.5) | 6178 (4) |
| F18 | 3225 (5) | 3628 (6) | 1994 (2) | 1071 (1) | 2325 (3) | (7) | 2762 (4) |
| F19 | 19950 (3) | (6) | 13480 (2) | 9166 (1) | (6) | (6) | 23790 (4) |
| F20 | 9698 (2) | 23340 (5) | 8881 (1) | 20390 (4) | (6.5) | (6.5) | 15810 (3) |
| F.rank | 4.28 | 5.58 | 2.1 | 1.55 | 4.35 | 6.35 | 3.8 |
| Algorithm A | Algorithm B | Algorithm C | Algorithm D | Algorithm E | Algorithm F | Algorithm G | |
|---|---|---|---|---|---|---|---|
| F01 | 6062 (3) | (6) | 4941 (2) | 4191 (1) | (6) | (6) | 7824 (4) |
| F02 | 1557 (3) | 4248 (5) | 1092 (1) | 1170 (2) | (6.5) | (6.5) | 1981 (4) |
| F03 | 5432 (4) | 15280 (5) | 3152 (2) | 2659 (1) | (6.5) | (6.5) | 5414 (3) |
| F04 | (5) | (5) | 15070 (1) | (5) | (5) | (5) | 33150 (2) |
| F05 | 5317 (4) | 23650 (5) | 3612 (2) | 2891 (1) | (6.5) | (6.5) | 5263 (3) |
| F06 | (5) | (5) | (5) | 13170 (1) | (5) | (5) | 13330 (2) |
| F07 | (4) | (4) | (4) | (4) | (4) | (4) | (4) |
| F08 | (5.5) | (5.5) | 11140 (1) | 18430 (2) | (5.5) | (5.5) | 21840 (3) |
| F09 | (5.5) | (5.5) | 9091 (1) | 29060 (3) | (5.5) | (5.5) | 14130 (2) |
| F10 | 3068 (4) | 5677 (5) | 1154 (1) | 1224 (2) | (6.5) | (6.5) | 2153 (3) |
| F11 | (5) | (5) | 9171 (1) | (5) | (5) | (5) | 10390 (2) |
| F12 | 54810 (1) | (4.5) | (4.5) | (4.5) | (4.5) | (4.5) | (4.5) |
| F13 | 13870 (4) | (6) | 4887 (1) | 7548 (2) | (6) | (6) | 9073 (3) |
| F14 | (5.5) | (5.5) | 4682 (1) | 7359 (2) | (5.5) | (5.5) | 9390 (3) |
| F15 | 1360 (6) | 1129 (5) | 352 (3) | 296 (2) | 270 (1) | 7919 (7) | 454 (4) |
| F16 | (6) | (6) | 2290 (3) | 1553 (1) | 2180 (2) | (6) | 3606 (4) |
| F17 | 53830 (1) | (4.5) | (4.5) | (4.5) | (4.5) | (4.5) | (4.5) |
| F18 | 30590 (4) | (6) | 3542 (1) | 6013 (3) | (6) | (6) | 5317 (2) |
| F19 | (4) | (4) | (4) | (4) | (4) | (4) | (4) |
| F20 | 37950 (1) | (4.5) | (4.5) | (4.5) | (4.5) | (4.5) | (4.5) |
| F.rank | 4.03 | 5.1 | 2.38 | 2.73 | 5 | 5.5 | 3.27 |
| Algorithm A | Algorithm B | Algorithm C | Algorithm D | Algorithm E | Algorithm F | Algorithm G | |
|---|---|---|---|---|---|---|---|
| F01 | , | , | , | , | , | , | , |
| F02 | [-, | , | , | , | , | , | , |
| F03 | , | , | , | , | , | , | , |
| F04 | , | , | , | [-, | , | , | , |
| F05 | [-, | , | , | , | [-, | , | , |
| F06 | , | , | , | , | , | , | , |
| F07 | , | , | , | , | , | , | , |
| F08 | , | , | [-, | , | , | , | , |
| F09 | , | , | [-, | , | , | , | [-, |
| F10 | , | , | [-, | , | , | , | , |
| F11 | , | , | , | [-, | , | , | [-, |
| F12 | , | , | , | , | , | , | , |
| F13 | , | , | [-, | , | , | , | , |
| F14 | , | , | [-, | [-, | , | , | [-, |
| F15 | , | , | [-, | , | , | , | , |
| F16 | , | , | , | , | , | , | , |
| F17 | , | , | [-, | [-, | , | , | , |
| F18 | , | , | [-, | [-, | , | , | [-, |
| F19 | , | , | , | , | , | , | , |
| F20 | , | , | , | , | , | , | , |
| Algorithm A | Algorithm B | Algorithm C | Algorithm D | Algorithm E | Algorithm F | Algorithm G | |
|---|---|---|---|---|---|---|---|
| F01 | [0.40, 0.60] | [0.40, 0.60] | [0.40, 0.60] | [0.40, 0.60] | [0.41, 0.61] | [0.41, 0.61] | [0.40, 0.60] |
| F02 | [0.45, 0.65] | [0.40, 0.60] | [0.61, 0.79] | [0.43, 0.63] | [0.40, 0.60] | [0.40, 0.60] | |
| F03 | [0.41, 0.61] | [0.40, 0.60] | [0.40, 0.60] | [0.40, 0.60] | [0.42, 0.62] | [0.40, 0.60] | [0.40, 0.60] |
| F04 | [0.40, 0.60] | [0.40, 0.60] | [0.40, 0.60] | [0.40, 0.60] | [0.40, 0.60] | [0.40, 0.60] | [0.40, 0.60] |
| F05 | [0.40, 0.60] | [0.40, 0.60] | [0.40, 0.60] | [0.40, 0.60] | [0.40, 0.60] | [0.40, 0.60] | [0.40, 0.60] |
| F06 | [0.40, 0.60] | [0.40, 0.60] | [0.40, 0.60] | [0.40, 0.60] | [0.40, 0.60] | [0.41, 0.61] | [0.40, 0.60] |
| F07 | [0.40, 0.60] | [0.40, 0.60] | [0.40, 0.60] | [0.40, 0.60] | [0.40, 0.60] | [0.40, 0.60] | [0.40, 0.60] |
| F08 | [0.40, 0.60] | [0.40, 0.60] | [0.40, 0.60] | [0.40, 0.60] | [0.42, 0.62] | [0.40, 0.60] | [0.40, 0.60] |
| F09 | [0.40, 0.60] | [0.40, 0.60] | [0.40, 0.60] | [0.40, 0.60] | [0.40, 0.60] | [0.40, 0.60] | [0.40, 0.60] |
| F10 | [0.40, 0.60] | [0.40, 0.60] | [0.77, 0.91] | [0.40, 0.60] | [0.43, 0.63] | [0.40, 0.60] | [0.40, 0.60] |
| F11 | [0.40, 0.60] | [0.40, 0.60] | [0.40, 0.60] | [0.40, 0.60] | [0.40, 0.60] | [0.40, 0.60] | [0.40, 0.60] |
| F12 | [0.40, 0.60] | [0.40, 0.60] | [0.40, 0.60] | [0.40, 0.60] | [0.42, 0.62] | [0.40, 0.60] | [0.40, 0.60] |
| F13 | [0.40, 0.60] | [0.40, 0.60] | [0.40, 0.60] | [0.40, 0.60] | [0.59, 0.77] | [0.40, 0.60] | [0.40, 0.60] |
| F14 | [0.40, 0.60] | [0.40, 0.60] | [0.40, 0.60] | [0.40, 0.60] | [0.40, 0.60] | [0.40, 0.60] | [0.40, 0.60] |
| F15 | [0.40, 0.60] | [0.40, 0.60] | [0.97, 1.00] | [0.47, 0.67] | [0.40, 0.60] | [0.45, 0.65] | |
| F16 | [0.40, 0.60] | [0.40, 0.60] | [0.40, 0.60] | [0.40, 0.60] | [0.40, 0.60] | [0.40, 0.60] | [0.40, 0.60] |
| F17 | [0.40, 0.60] | [0.40, 0.60] | [0.40, 0.60] | [0.40, 0.60] | [0.42, 0.62] | [0.40, 0.60] | [0.40, 0.60] |
| F18 | [0.40, 0.60] | [0.40, 0.60] | [0.40, 0.60] | [0.40, 0.60] | [0.40, 0.60] | [0.40, 0.60] | [0.40, 0.60] |
| F19 | [0.40, 0.60] | [0.40, 0.60] | [0.40, 0.60] | [0.40, 0.60] | [0.40, 0.60] | [0.40, 0.60] | [0.40, 0.60] |
| F20 | [0.40, 0.60] | [0.40, 0.60] | [0.40, 0.60] | [0.40, 0.60] | [0.53, 0.71] | [0.40, 0.60] | [0.40, 0.60] |
| Algorithm A | Algorithm B | Algorithm C | Algorithm D | Algorithm E | Algorithm F | Algorithm G | |
|---|---|---|---|---|---|---|---|
| F01 | [0.04, 0.16] | [0.04, 0.16] | [0.04, 0.16] | [0.04, 0.16] | [0.04, 0.16] | [0.04, 0.16] | [0.04, 0.16] |
| F02 | [0.45, 0.65] | [0.04, 0.16] | [0.61, 0.79] | [0.17, 0.35] | [0.04, 0.16] | [0.04, 0.16] | |
| F03 | [0.04, 0.16] | [0.04, 0.16] | [0.04, 0.16] | [0.04, 0.17] | [0.04, 0.16] | [0.04, 0.16] | [0.04, 0.16] |
| F04 | [0.04, 0.16] | [0.04, 0.16] | [0.04, 0.16] | [0.04, 0.16] | [0.04, 0.16] | [0.04, 0.16] | [0.04, 0.16] |
| F05 | [0.04, 0.16] | [0.04, 0.16] | [0.19, 0.37] | [0.06, 0.20] | [0.04, 0.16] | [0.04, 0.16] | [0.04, 0.16] |
| F06 | [0.04, 0.16] | [0.04, 0.16] | [0.04, 0.16] | [0.04, 0.16] | [0.04, 0.16] | [0.04, 0.16] | [0.04, 0.16] |
| F07 | [0.04, 0.16] | [0.04, 0.16] | [0.04, 0.16] | [0.04, 0.16] | [0.04, 0.16] | [0.04, 0.16] | [0.04, 0.16] |
| F08 | [0.04, 0.16] | [0.04, 0.16] | [0.05, 0.17] | [0.04, 0.16] | [0.04, 0.16] | [0.04, 0.16] | [0.04, 0.16] |
| F09 | [0.04, 0.16] | [0.04, 0.16] | [0.04, 0.16] | [0.04, 0.16] | [0.04, 0.16] | [0.04, 0.16] | [0.04, 0.16] |
| F10 | [0.04, 0.16] | [0.04, 0.16] | [0.77, 0.91] | [0.04, 0.16] | [0.34, 0.54] | [0.04, 0.16] | [0.04, 0.16] |
| F11 | [0.04, 0.16] | [0.04, 0.16] | [0.04, 0.16] | [0.04, 0.16] | [0.05, 0.17] | [0.04, 0.16] | [0.04, 0.16] |
| F12 | [0.04, 0.16] | [0.04, 0.16] | [0.04, 0.16] | [0.04, 0.16] | [0.06, 0.20] | [0.04, 0.16] | [0.04, 0.16] |
| F13 | [0.04, 0.16] | [0.04, 0.16] | [0.04, 0.16] | [0.04, 0.16] | [0.04, 0.16] | [0.04, 0.16] | [0.04, 0.16] |
| F14 | [0.04, 0.16] | [0.04, 0.16] | [0.04, 0.16] | [0.04, 0.16] | [0.04, 0.16] | [0.04, 0.16] | [0.04, 0.16] |
| F15 | [0.04, 0.16] | [0.04, 0.16] | [0.97, 1.00] | [0.32, 0.52] | [0.04, 0.16] | [0.22, 0.40] | |
| F16 | [0.04, 0.16] | [0.04, 0.16] | [0.04, 0.16] | [0.04, 0.16] | [0.04, 0.16] | [0.04, 0.16] | [0.04, 0.16] |
| F17 | [0.04, 0.16] | [0.04, 0.16] | [0.04, 0.16] | [0.16, 0.32] | [0.09, 0.23] | [0.04, 0.16] | [0.05, 0.17] |
| F18 | [0.04, 0.16] | [0.04, 0.16] | [0.04, 0.16] | [0.04, 0.16] | [0.04, 0.16] | [0.04, 0.16] | [0.04, 0.16] |
| F19 | [0.04, 0.16] | [0.04, 0.16] | [0.04, 0.16] | [0.04, 0.16] | [0.04, 0.16] | [0.04, 0.16] | [0.04, 0.16] |
| F20 | [0.04, 0.16] | [0.04, 0.16] | [0.04, 0.16] | [0.04, 0.16] | [0.04, 0.16] | [0.04, 0.16] | [0.04, 0.16] |
| Algorithm A | Algorithm B | Algorithm C | Algorithm D | Algorithm E | Algorithm F | Algorithm G | |
|---|---|---|---|---|---|---|---|
| F01 | [0.84, 0.96] | [0.84, 0.96] | [0.84, 0.96] | [0.84, 0.96] | [0.84, 0.96] | [0.84, 0.96] | [0.84, 0.96] |
| F02 | [0.84, 0.96] | [0.84, 0.96] | [0.85, 0.97] | [0.89, 0.99] | [0.84, 0.96] | [0.84, 0.96] | |
| F03 | [0.84, 0.96] | [0.84, 0.96] | [0.84, 0.96] | [0.84, 0.96] | [0.84, 0.96] | [0.84, 0.96] | [0.84, 0.96] |
| F04 | [0.84, 0.96] | [0.84, 0.96] | [0.84, 0.96] | [0.84, 0.96] | [0.84, 0.96] | [0.84, 0.96] | [0.84, 0.96] |
| F05 | [0.84, 0.96] | [0.84, 0.96] | [0.84, 0.96] | [0.84, 0.96] | [0.85, 0.97] | [0.84, 0.96] | [0.84, 0.96] |
| F06 | [0.84, 0.96] | [0.84, 0.96] | [0.84, 0.96] | [0.84, 0.96] | [0.84, 0.96] | [0.84, 0.96] | [0.84, 0.96] |
| F07 | [0.84, 0.96] | [0.85, 0.97] | [0.84, 0.96] | [0.84, 0.96] | [0.84, 0.96] | [0.84, 0.96] | [0.84, 0.96] |
| F08 | [0.84, 0.96] | [0.84, 0.96] | [0.84, 0.96] | [0.84, 0.96] | [0.84, 0.96] | [0.84, 0.96] | [0.84, 0.96] |
| F09 | [0.84, 0.96] | [0.84, 0.96] | [0.84, 0.96] | [0.84, 0.96] | [0.84, 0.96] | [0.84, 0.96] | [0.84, 0.96] |
| F10 | [0.84, 0.96] | [0.84, 0.96] | [0.84, 0.96] | [0.84, 0.96] | [0.87, 0.97] | [0.84, 0.96] | [0.84, 0.96] |
| F11 | [0.84, 0.96] | [0.84, 0.96] | [0.84, 0.96] | [0.84, 0.96] | [0.84, 0.96] | [0.84, 0.96] | [0.84, 0.96] |
| F12 | [0.84, 0.96] | [0.84, 0.96] | [0.84, 0.96] | [0.84, 0.96] | [0.84, 0.96] | [0.84, 0.96] | [0.84, 0.96] |
| F13 | [0.84, 0.96] | [0.84, 0.96] | [0.84, 0.96] | [0.84, 0.96] | [0.85, 0.97] | [0.84, 0.96] | [0.84, 0.96] |
| F14 | [0.84, 0.96] | [0.84, 0.96] | [0.84, 0.96] | [0.84, 0.96] | [0.84, 0.96] | [0.84, 0.96] | |
| F15 | [0.84, 0.96] | [0.84, 0.96] | [0.97, 1.00] | [0.84, 0.96] | [0.84, 0.96] | ||
| F16 | [0.84, 0.96] | [0.84, 0.96] | [0.84, 0.96] | [0.84, 0.96] | [0.84, 0.96] | [0.84, 0.96] | [0.84, 0.96] |
| F17 | [0.84, 0.96] | [0.84, 0.96] | [0.84, 0.96] | [0.88, 0.98] | [0.84, 0.96] | [0.84, 0.96] | [0.84, 0.96] |
| F18 | [0.84, 0.96] | [0.84, 0.96] | [0.84, 0.96] | [0.84, 0.96] | [0.84, 0.96] | [0.84, 0.96] | [0.84, 0.96] |
| F19 | [0.84, 0.96] | [0.84, 0.96] | [0.84, 0.96] | [0.84, 0.96] | [0.84, 0.96] | [0.84, 0.96] | [0.84, 0.96] |
| F20 | [0.84, 0.96] | [0.84, 0.96] | [0.84, 0.96] | [0.84, 0.96] | [0.87, 0.97] | [0.84, 0.96] | [0.84, 0.96] |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ivković, N.; Kudelić, R.; Črepinšek, M. Probability and Certainty in the Performance of Evolutionary and Swarm Optimization Algorithms. Mathematics 2022, 10, 4364. https://doi.org/10.3390/math10224364
Ivković N, Kudelić R, Črepinšek M. Probability and Certainty in the Performance of Evolutionary and Swarm Optimization Algorithms. Mathematics. 2022; 10(22):4364. https://doi.org/10.3390/math10224364
Chicago/Turabian StyleIvković, Nikola, Robert Kudelić, and Matej Črepinšek. 2022. "Probability and Certainty in the Performance of Evolutionary and Swarm Optimization Algorithms" Mathematics 10, no. 22: 4364. https://doi.org/10.3390/math10224364
APA StyleIvković, N., Kudelić, R., & Črepinšek, M. (2022). Probability and Certainty in the Performance of Evolutionary and Swarm Optimization Algorithms. Mathematics, 10(22), 4364. https://doi.org/10.3390/math10224364