
Bimodal-Distributed Binarized Neural Networks


Abstract
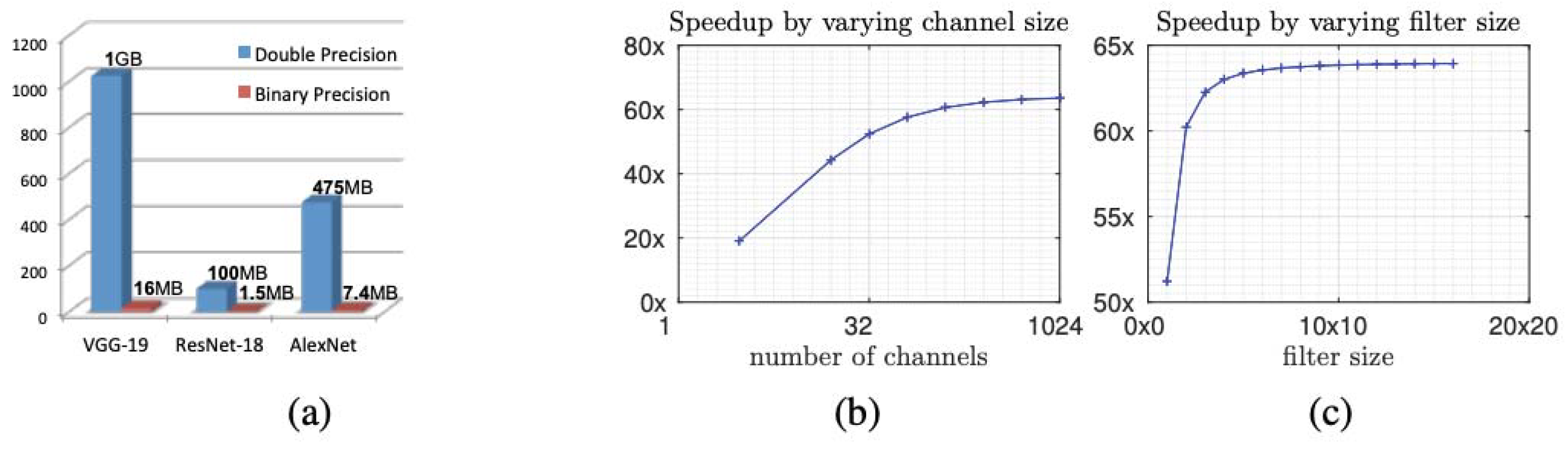
:1. Introduction
- We introduce a regularization term to manipulate the weight distribution such that it becomes a bimodal distribution that, in turn, reduces the quantization error.
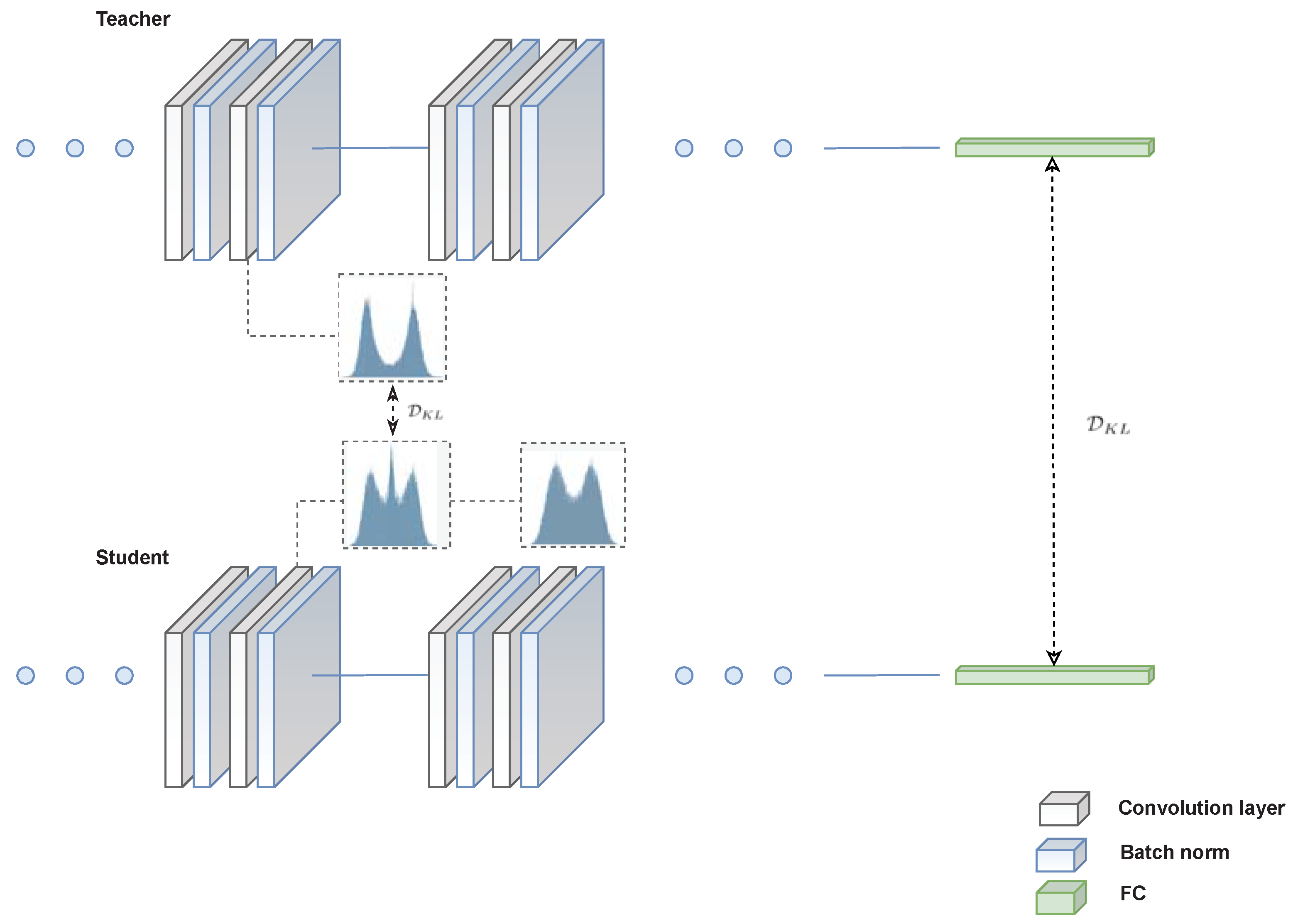
- We propose weight distribution mimicking (WDM) as a training scheme that establishes a better match between the teacher and student distribution for an FP 32 teacher and binary student.
- We are the first to analyze the distribution of the gradients of the loss term with regularization for BNNs.
- We analyze the proposed method in a variety of BNNs and achieve state-of-the-art results without increasing the number of parameters.
2. Background
3. Related Work
4. Preliminaries
4.1. BNNs
4.2. Knowledge Distillation
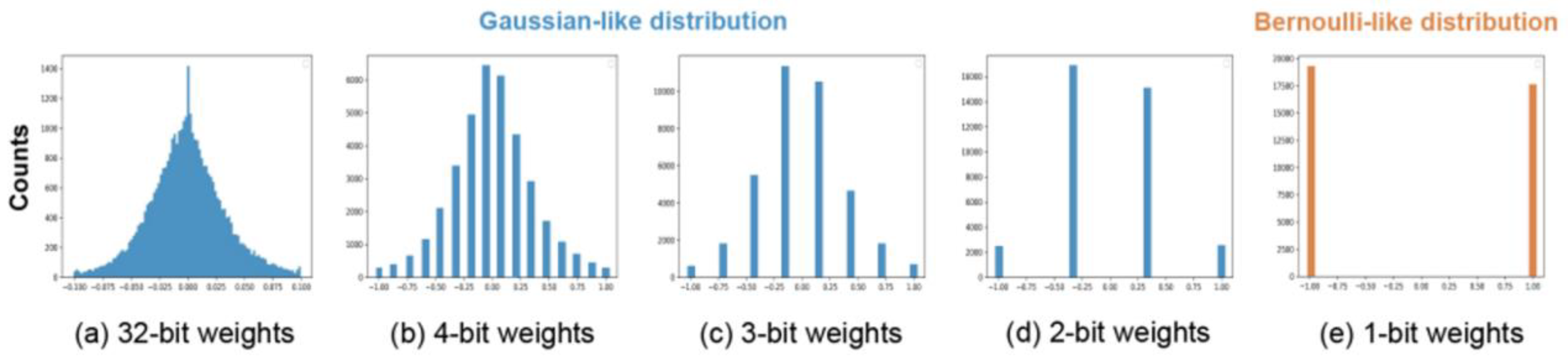
4.3. Kurtosis
5. Method
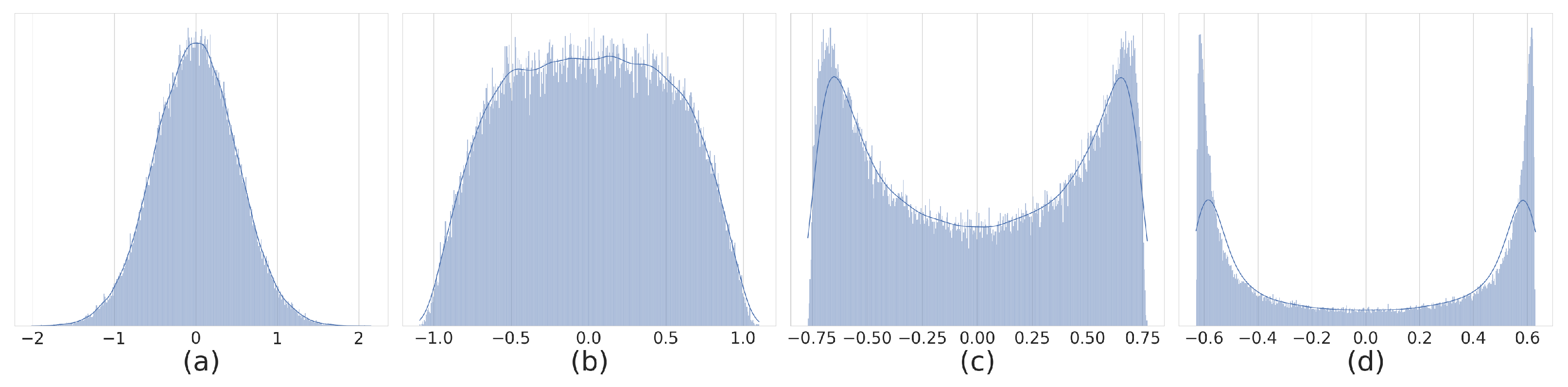
5.1. Weight Distribution Regularization
5.2. Weight Distribution Mimicking
5.3. BD-BNN
6. Results
6.1. CIFAR-10
6.2. ImageNet
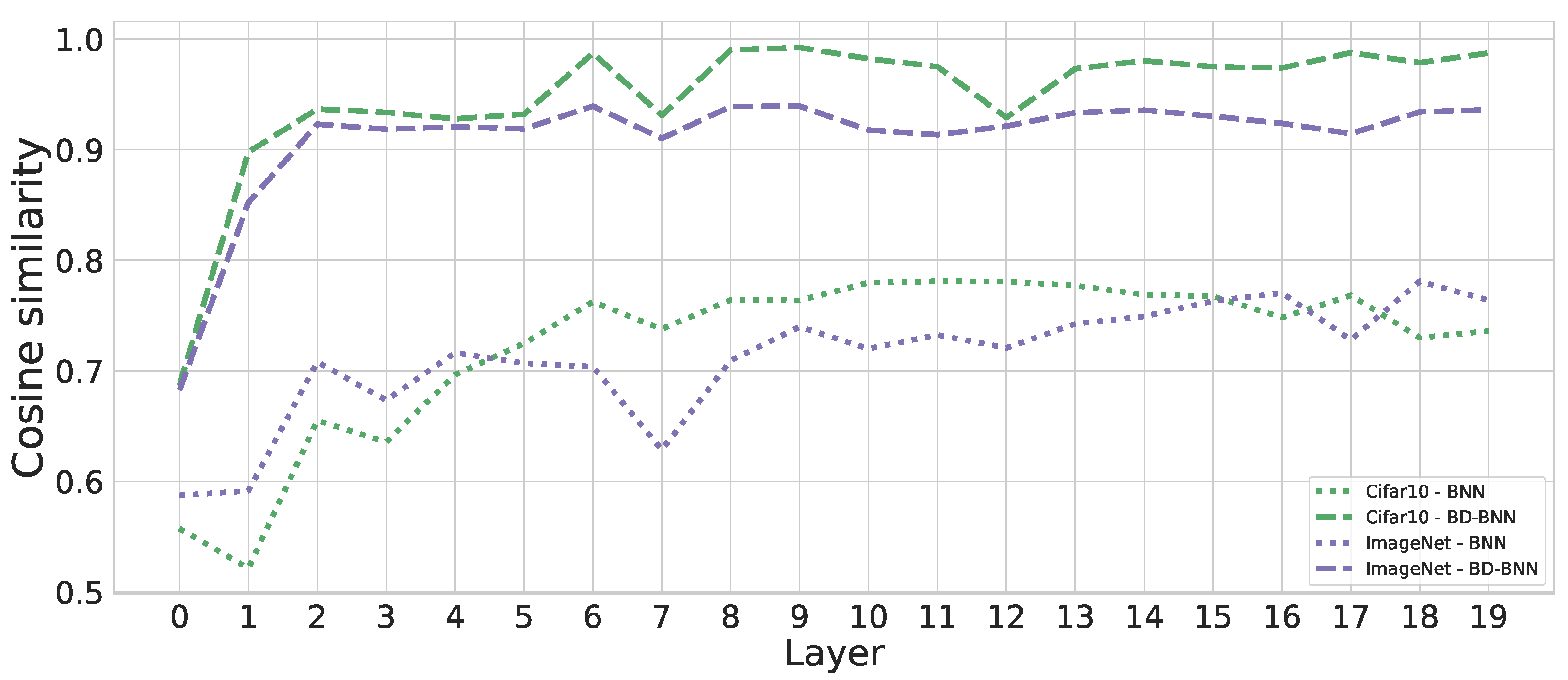
6.3. Ablation Study
7. Discussion
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Liu, Z.; Mao, H.; Wu, C.; Feichtenhofer, C.; Darrell, T.; Xie, S. A ConvNet for the 2020s. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–20 June 2022; pp. 11966–11976. [Google Scholar]
- Zou, Z.; Shi, Z.; Guo, Y.; Ye, J. Object Detection in 20 Years: A Survey. arXiv 2019, arXiv:1905.05055. [Google Scholar]
- Vaswani, A.; Shazeer, N.M.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Huang, Y.; Chen, Y. Autonomous Driving with Deep Learning: A Survey of State-of-Art Technologies. arXiv 2020, arXiv:2006.06091. [Google Scholar]
- Li, X.; Jiang, Y.; Li, M.; Yin, S. Lightweight Attention Convolutional Neural Network for Retinal Vessel Image Segmentation. IEEE Trans. Ind. Inform. 2021, 17, 1958–1967. [Google Scholar] [CrossRef]
- Li, X.; Jiang, Y.; Zhang, J.; Li, M.; Luo, H.; Yin, S. Lesion-attention pyramid network for diabetic retinopathy grading. Artif. Intell. Med. 2022, 126, 102259. [Google Scholar] [CrossRef]
- Frankle, J.; Carbin, M. The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks. arXiv 2019, arXiv:1803.03635. [Google Scholar]
- Hubara, I.; Chmiel, B.; Island, M.; Banner, R.; Naor, S.; Soudry, D. Accelerated Sparse Neural Training: A Provable and Efficient Method to Find N: M Transposable Masks. In Proceedings of the NeurIPS, Online, 6–14 December 2021. [Google Scholar]
- Chmiel, B.; Baskin, C.; Banner, R.; Zheltonozhskii, E.; Yermolin, Y.; Karbachevsky, A.; Bronstein, A.M.; Mendelson, A. Feature Map Transform Coding for Energy-Efficient CNN Inference. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–9. [Google Scholar]
- Baskin, C.; Chmiel, B.; Zheltonozhskii, E.; Banner, R.; Bronstein, A.M.; Mendelson, A. CAT: Compression-Aware Training for bandwidth reduction. J. Mach. Learn. Res. 2021, 22, 269:1–269:20. [Google Scholar]
- Banner, R.; Nahshan, Y.; Hoffer, E.; Soudry, D. Post-training 4-bit quantization of convolution networks for rapid-deployment. In Proceedings of the Conference on Neural Information Processing Systems (NeurIPS), Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Chmiel, B.; Ben-Uri, L.; Shkolnik, M.; Hoffer, E.; Banner, R.; Soudry, D. Neural gradients are lognormally distributed: Understanding sparse and quantized training. arXiv 2020, arXiv:2006.08173. [Google Scholar]
- Hinton, G.E.; Vinyals, O.; Dean, J. Distilling the Knowledge in a Neural Network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Rastegari, M.; Ordonez, V.; Redmon, J.; Farhadi, A. XNOR-Net: ImageNet Classification Using Binary Convolutional Neural Networks. In Proceedings of the ECCV, Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Chmiel, B.; Banner, R.; Shomron, G.; Nahshan, Y.; Bronstein, A.; Weiser, U. Robust quantization: One model to rule them all. Adv. Neural Inf. Process. Syst. 2020, 33, 5308–5317. [Google Scholar]
- Courbariaux, M.; Hubara, I.; Soudry, D.; El-Yaniv, R.; Bengio, Y. Binarized Neural Networks: Training Deep Neural Networks with Weights and Activations Constrained to +1 or −1. arXiv 2016, arXiv:1602.02830. [Google Scholar]
- Bengio, Y.; Léonard, N.; Courville, A.C. Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation. arXiv 2013, arXiv:1308.3432. [Google Scholar]
- Liu, Z.; Wu, B.; Luo, W.; Yang, X.; Liu, W.; Cheng, K.T. Bi-real net: Enhancing the performance of 1-bit cnns with improved representational capability and advanced training algorithm. In Proceedings of the Computer Vision—ECCV 2018—15th European Conference, Munich, Germany, 8–14 September 2018; pp. 747–763. [Google Scholar]
- Qin, H.; Gong, R.; Liu, X.; Shen, M.; Wei, Z.; Yu, F.; Song, J. Forward and Backward Information Retention for Accurate Binary Neural Networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 2247–2256. [Google Scholar]
- Martínez, B.; Yang, J.; Bulat, A.; Tzimiropoulos, G. Training Binary Neural Networks with Real-to-Binary Convolutions. arXiv 2020, arXiv:2003.11535. [Google Scholar]
- Xue, P.; Lu, Y.; Chang, J.; Wei, X.; Wei, Z. Self-distribution binary neural networks. Appl. Intell. 2022, 52, 13870–13882. [Google Scholar] [CrossRef]
- Lin, M.; Ji, R.; Xu, Z.H.; Zhang, B.; Wang, Y.; Wu, Y.; Huang, F.; Lin, C.W. Rotated Binary Neural Network. arXiv 2020, arXiv:2009.13055. [Google Scholar]
- Bulat, A.; Tzimiropoulos, G.; Kossaif, J.; Pantic, M. Improved training of binary networks for human pose estimation and image recognition. arXiv 2019, arXiv:1904.05868. [Google Scholar]
- Xu, Y.; Han, K.; Xu, C.; Tang, Y.; Xu, C.; Wang, Y. Learning Frequency Domain Approximation for Binary Neural Networks. In Proceedings of the NeurIPS, Online, 6–14 December 2021. [Google Scholar]
- Liu, Z.; Shen, Z.; Savvides, M.; Cheng, K.T. ReActNet: Towards Precise Binary Neural Network with Generalized Activation Functions. arXiv 2020, arXiv:2003.03488. [Google Scholar]
- Allen-Zhu, Z.; Li, Y. Towards Understanding Ensemble, Knowledge Distillation and Self-Distillation in Deep Learning. arXiv 2020, arXiv:2012.09816. [Google Scholar]
- Mobahi, H.; Farajtabar, M.; Bartlett, P.L. Self-Distillation Amplifies Regularization in Hilbert Space. arXiv 2020, arXiv:2002.05715. [Google Scholar]
- Zhang, L.; Song, J.; Gao, A.; Chen, J.; Bao, C.; Ma, K. Be Your Own Teacher: Improve the Performance of Convolutional Neural Networks via Self Distillation. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27–28 October 2019; pp. 3712–3721. [Google Scholar]
- Bucila, C.; Caruana, R.; Niculescu-Mizil, A. Model compression. In Proceedings of the KDD’06, Philadelphia, PA, USA, 20–23 August 2006. [Google Scholar]
- Kim, J.; Bhalgat, Y.; Lee, J.; Patel, C.; Kwak, N. QKD: Quantization-aware Knowledge Distillation. arXiv 2019, arXiv:1911.12491. [Google Scholar]
- Polino, A.; Pascanu, R.; Alistarh, D. Model compression via distillation and quantization. arXiv 2018, arXiv:1802.05668. [Google Scholar]
- Lemons, D. An Introduction to Stochastic Processes in Physics; Johns Hopkins University Press: Baltimore, MD, USA, 2003. [Google Scholar]
- Krizhevsky, A. Learning Multiple Layers of Features from Tiny Images; University of Toronto Press: Toronto, ON, Canada, 2009. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2015, arXiv:1409.1556. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Gong, R.; Liu, X.; Jiang, S.; Li, T.H.; Hu, P.; Lin, J.; Yu, F.; Yan, J. Differentiable Soft Quantization: Bridging Full-Precision and Low-Bit Neural Networks. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27–28 October 2019; pp. 4851–4860. [Google Scholar]
- Zhou, S.; Wu, Y.; Ni, Z.; Zhou, X.; Wen, H.; Zou, Y. Dorefa-Net: Training Low Bitwidth Convolutional Neural Networks with Low Bitwidth Gradients. arXiv 2018, arXiv:1606.06160. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network | Method | Bit-Width (W/A) | Acc (%) |
|---|---|---|---|
| ResNet-18 | FP32 | 32/32 | 93.00 |
| IR-Net [20] | 1/1 | 91.50 | |
| RBNN [23] | 1/1 | 92.20 | |
| BD-BNN (Ours) | 1/1 | 92.46 | |
| ResNet-20 | FP32 | 32/32 | 91.70 |
| DoReFa-Net [38] | 1/1 | 79.30 | |
| XNOR-Net [15] | 1/1 | 85.23 | |
| DSQ [37] | 1/1 | 84.11 | |
| IR-Net [20] | 1/1 | 85.40 | |
| FDA-BNN [25] | 1/1 | 86.20 | |
| RBNN [23] | 1/1 | 86.50 | |
| BD-BNN (Ours) | 1/1 | 86.50 | |
| VGG-small | FP32 | 32/32 | 93.80 |
| BNN [17] | 1/1 | 89.90 | |
| XNOR-Net [15] | 1/1 | 89.80 | |
| DSQ [37] | 1/1 | 91.72 | |
| IR-Net [20] | 1/1 | 90.40 | |
| RBNN [23] | 1/1 | 91.30 | |
| FDA-BNN [25] | 1/1 | 92.54 | |
| BD-BNN (Ours) | 1/1 | 92.7 |
| Network | Method | Bit-Width (W/A) | Top-1 (%) | Top-5 (%) |
|---|---|---|---|---|
| ResNet-18 | FP | 32/32 | 69.6 | 89.2 |
| IR-Net [20] | 1/1 | 58.1 | 80.0 | |
| RBNN [23] | 1/1 | 59.9 | 81.9 | |
| Bi-Real-Net [19] | 1/1 | 56.4 | 79.5 | |
| XNOR-Net [15] | 1/1 | 51.2 | 73.2 | |
| BNN [17] | 1/1 | 42.2 | 67.1 | |
| DeReFa-Net [38] | 1/1 | 53.4 | 67.7 | |
| FDA-BNN [25] | 1/1 | 60.2 | 82.3 | |
| BD-BNN (Ours) | 1/1 | 60.6 | 82.49 | |
| ReActNet * [26] | 1/1 | 62.1 | 83.53 | |
| BD-BNN * (Ours) | 1/1 | 63.27 | 84.42 |
| Method | W/A | Acc |
|---|---|---|
| FP | 32/32 | 91.7% |
| BNN | 1/1 | 83.9% |
| BNN + WDR | 1/1 | 85.25% |
| BNN + WDR + KD | 1/1 | 85.69% |
| BNN + WDR + WDM | 1/1 | 86.50% |
| Teacher | Student | Acc |
|---|---|---|
| FP | BNN | 58.45% |
| FP + WDR | BNN | 56.32% |
| FP | BNN + WDR | 55.25% |
| FP + WDR | BNN + WDR | 60.5% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rozen, T.; Kimhi, M.; Chmiel, B.; Mendelson, A.; Baskin, C. Bimodal-Distributed Binarized Neural Networks. Mathematics 2022, 10, 4107. https://doi.org/10.3390/math10214107
Rozen T, Kimhi M, Chmiel B, Mendelson A, Baskin C. Bimodal-Distributed Binarized Neural Networks. Mathematics. 2022; 10(21):4107. https://doi.org/10.3390/math10214107
Chicago/Turabian StyleRozen, Tal, Moshe Kimhi, Brian Chmiel, Avi Mendelson, and Chaim Baskin. 2022. "Bimodal-Distributed Binarized Neural Networks" Mathematics 10, no. 21: 4107. https://doi.org/10.3390/math10214107
APA StyleRozen, T., Kimhi, M., Chmiel, B., Mendelson, A., & Baskin, C. (2022). Bimodal-Distributed Binarized Neural Networks. Mathematics, 10(21), 4107. https://doi.org/10.3390/math10214107