
Data-Driven Event-Triggered Platoon Control under Denial-of-Service Attacks


Abstract
:1. Introduction
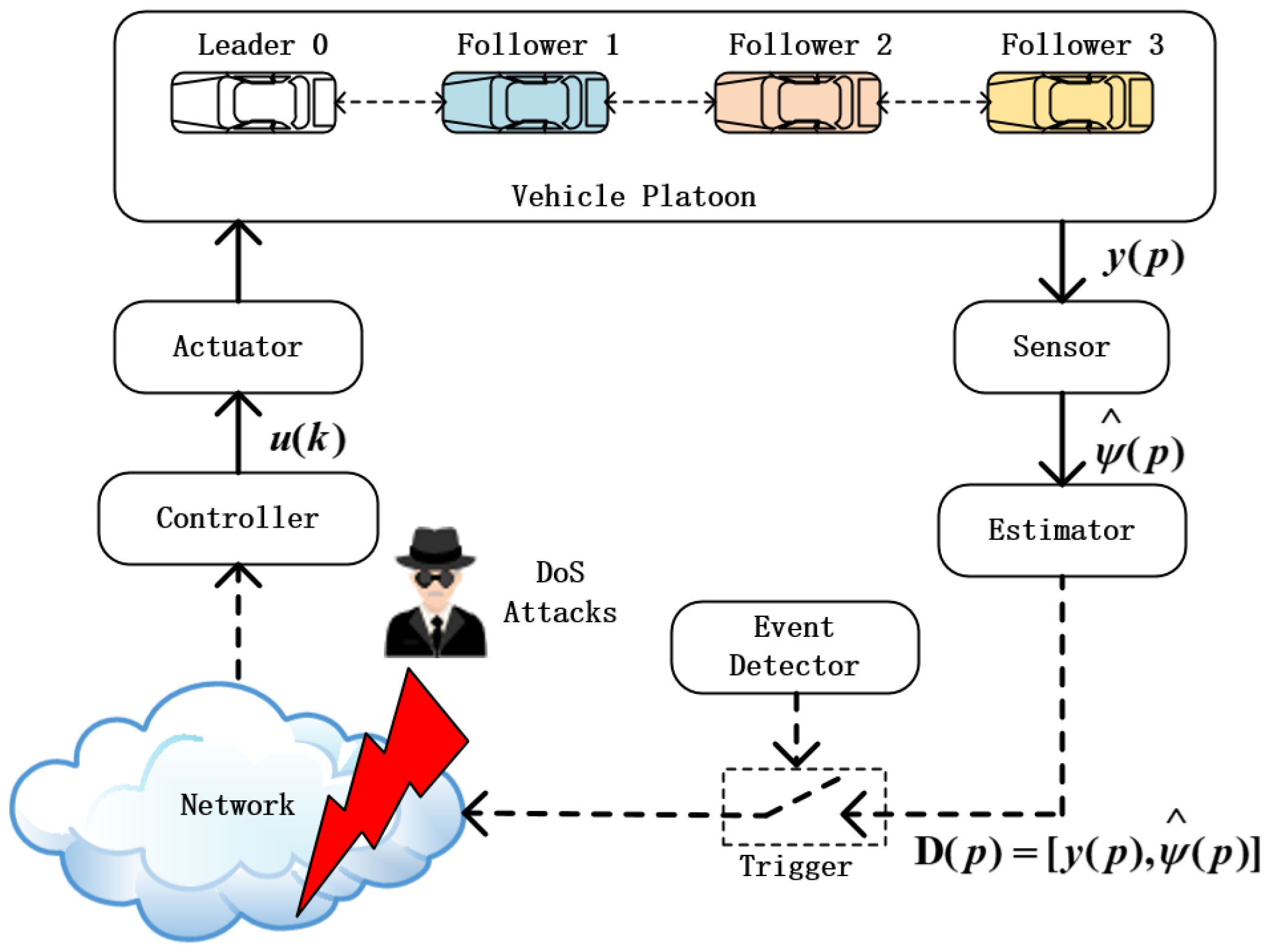
2. MFAPC Framework and Problem Formulation
2.1. Vehicle System Modeling
2.2. MFAPC Algorithm Design
2.3. Event-Triggered Mechanism Design
2.4. MFAPC Modeling under DoS Attacks
3. Security Analysis
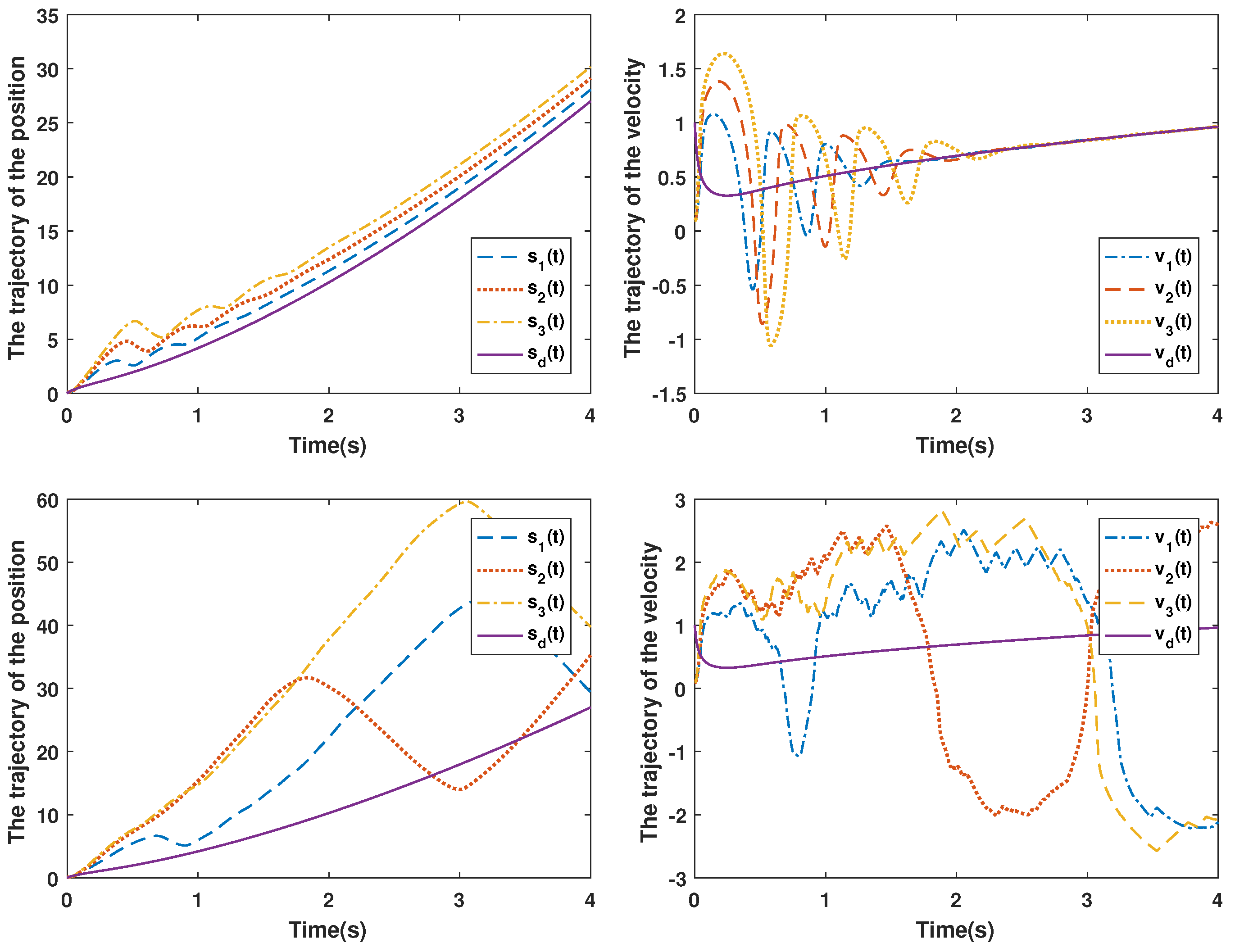
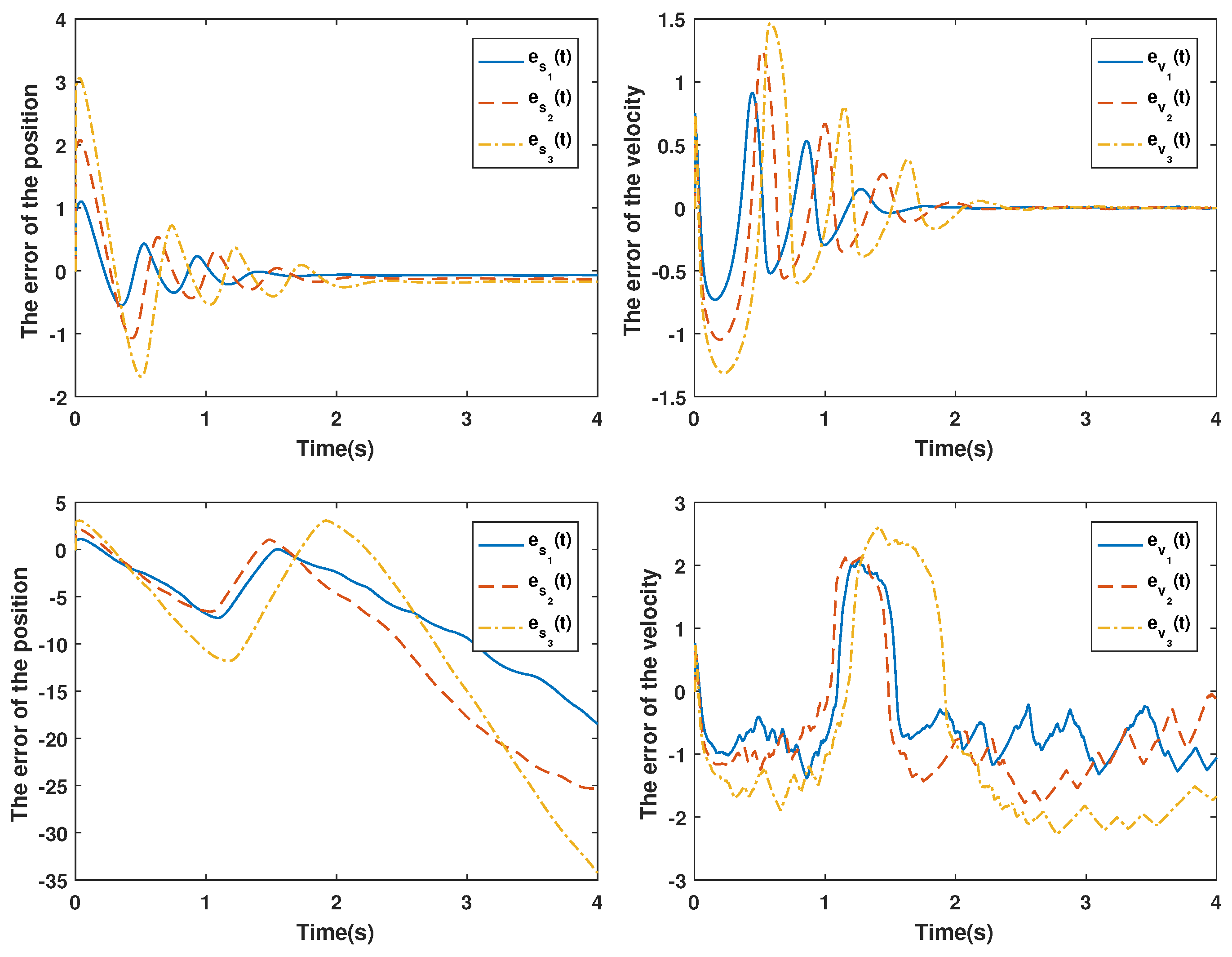
4. Simulation and Experimental Results
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Wang, S.; Hui, Y.; Sun, X.; Shi, D. Neural network sliding mode control of intelligent vehicle longitudinal dynamics. IEEE Access 2019, 7, 162333–162342. [Google Scholar] [CrossRef]
- Saraiva, T.D.V.; Campos, C.A.V.; Fontes, R.D.R.; Rothenberg, C.E.; Sorour, S.; Valaee, S. An application-driven framework for intelligent transportation systems using 5G network slicing. IEEE Trans. Intell. Transp. Syst. 2021, 22, 5247–5260. [Google Scholar] [CrossRef]
- Mu, S.; Xiong, Z.; Tian, Y. Intelligent traffic control system based on cloud computing and big data mining. IEEE Trans. Ind. Inform. 2019, 15, 6583–6592. [Google Scholar]
- Xu, L.; Zhuang, W.; Yin, G.; Bian, C.; Wu, H. Modeling and robust control of heterogeneous vehicle platoons on curved roads subject to disturbances and delays. IEEE Trans. Veh. Technol. 2019, 68, 11551–11564. [Google Scholar] [CrossRef]
- Chen, J.; Liang, H.; Li, J.; Lv, Z. Connected automated vehicle platoon control with input saturation and variable time headway strategy. IEEE Trans. Intell. Transp. Syst. 2020, 22, 4929–4940. [Google Scholar] [CrossRef]
- Zhang, H.; Liu, J.; Wang, Z.; Yan, H.; Zhang, C. Distributed adaptive event-triggered control and stability analysis for vehicular platoon. IEEE Trans. Intell. Transp. Syst. 2021, 22, 1627–1638. [Google Scholar] [CrossRef]
- Li, Y.; Zhong, Z.; Song, Y.; Sun, Q.; Sun, H.; Hu, S.; Wang, Y. Longitudinal platoon control of connected vehicles: Analysis and verification. IEEE Trans. Intell. Transp. Syst. 2020, 23, 4225–4235. [Google Scholar] [CrossRef]
- di Bernardo, M.; Salvi, A.; Santini, S. Distributed consensus strategy for platooning of vehicles in the presence of time-varying heterogeneous communication delays. IEEE Trans. Intell. Transp. Syst. 2015, 16, 102–112. [Google Scholar] [CrossRef]
- Li, M.; Cao, Z.; Li, Z. A reinforcement learning-based vehicle platoon control strategy for reducing energy consumption in traffic oscillations. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 5309–5322. [Google Scholar] [CrossRef]
- Song, X.; Feng, D.; Feng, X. Data-driven optimal cooperative adaptive cruise control of heterogeneous vehicle platoons with unknown dynamics. Sci. China-Inf. Sci. 2020, 63, 9. [Google Scholar] [CrossRef]
- Li, G.; Görges, D. Ecological adaptive cruise control for vehicles with step-gear transmission based on reinforcement learning. IEEE Trans. Intell. Transp. Syst. 2020, 21, 4895–4905. [Google Scholar] [CrossRef]
- Hou, Z.; Jin, S. Model Free Adaptive Control: Theory and Applications; CRC Press: Boca Raton, FL, USA, 2013. [Google Scholar]
- Hou, Z.; Jin, S. A novel data-driven control approach for a class of discrete-time nonlinear systems. IEEE Trans. Control Syst. Technol. 2011, 19, 1549–1558. [Google Scholar] [CrossRef]
- Hou, Z.; Chi, R.; Gao, H. An overview of dynamic-linearization-based data-driven control and applications. IEEE Trans. Ind. Electron. 2017, 64, 4076–4090. [Google Scholar] [CrossRef]
- Hou, Z.; Jin, S. Data-driven model-free adaptive control for a class of MIMO nonlinear discrete-time systems. IEEE Trans. Neural Netw. 2011, 22, 2173–2188. [Google Scholar] [PubMed]
- Chi, R.; Zhang, H.; Huang, B.; Hou, Z. Quantitative Data-Driven Adaptive Iterative Learning Control: From Trajectory Tracking to Point-to-Point Tracking. IEEE Trans. Cybern. 2020, 52, 4859–4873. [Google Scholar] [CrossRef] [PubMed]
- Hou, Z.; Xiong, S. On model-free adaptive control and its stability analysis. IEEE Trans. Autom. Control 2019, 64, 4555–4569. [Google Scholar] [CrossRef]
- Xiong, S.; Hou, Z. Model-free adaptive control for unknown MIMO nonaffine nonlinear discrete-time systems with experimental validation. IEEE Trans. Neural Netw. Learn. Syst. 2020, 33, 1727–1739. [Google Scholar] [CrossRef]
- Bu, X.; Yu, W.; Yu, Q.; Hou, Z.; Yang, J. Event-Triggered Model-Free Adaptive Iterative Learning Control for a Class of Nonlinear Systems Over Fading Channels. IEEE Trans. Cybern. 2021, 52, 9597–9608. [Google Scholar] [CrossRef]
- Liu, D.; Yang, G. Prescribed performance model-free adaptive integral sliding mode control for discrete-time nonlinear systems. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 2222–2230. [Google Scholar] [CrossRef]
- Xu, D.; Shi, Y.; Ji, Z. Model-free adaptive discrete-time integral sliding-mode-constrained-control for autonomous 4WMV parking systems. IEEE Trans. Ind. Electron. 2018, 65, 834–843. [Google Scholar] [CrossRef]
- Liu, S.; Hou, Z.; Tian, T.; Deng, Z.; Li, Z. A novel dual successive projection-based model-free adaptive control method and application to an autonomous car. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3444–3457. [Google Scholar] [PubMed]
- Jiang, Q.; Liao, Y.; Li, Y.; Fan, J.; Miao, Y. Heading control of unmanned surface vehicle with variable output constraint model-free adaptive control algorithm. IEEE Access 2019, 7, 131008–131018. [Google Scholar] [CrossRef]
- Liao, Y.; Jiang, Q.; Du, T.; Jiang, W. Redefined output model-free adaptive control method and unmanned surface vehicle heading control. IEEE J. Ocean. Eng. 2020, 45, 714–723. [Google Scholar] [CrossRef]
- Liu, D.; Yang, G. Neural network-based event-triggered MFAC for nonlinear discrete-time processes. Neurocomputing 2018, 272, 356–364. [Google Scholar] [CrossRef]
- Lin, N.; Chi, R.; Huang, B. Event-triggered model-free adaptive control. IEEE Trans. Syst. Man, Cybern. Syst. 2019, 51, 3358–3369. [Google Scholar] [CrossRef]
- Li, H.; Wang, Y.; Zhang, H. Data-driven-based event-triggered tracking control for non-linear systems with unknown disturbance. IET Control Theory Appl. 2019, 13, 2197–2206. [Google Scholar] [CrossRef]
- Lin, N.; Chi, R.; Huang, B.; Hou, Z. Event-triggered nonlinear iterative learning control. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 5118–5128. [Google Scholar] [CrossRef]
- Mao, J.; Sun, Y.; Yi, X.; Liu, H.; Ding, D. Recursive filtering of networked nonlinear systems: A survey. Int. J. Syst. Sci. 2021, 52, 1110–1128. [Google Scholar] [CrossRef]
- Ding, D.; Han, Q.L.; Ge, X.; Wang, J. Secure state estimation and control of cyber-physical systems: A survey. IEEE Trans. Syst. Man, Cybern. Syst. 2020, 51, 176–190. [Google Scholar] [CrossRef]
- Deng, C.; Zhang, D.; Gang, F. Resilient practical cooperative output regulation for MASs with unknown switching exosystem dynamics under DoS attacks. Automatica 2022, 139, 110172. [Google Scholar] [CrossRef]
- Li, Z.; Che, W. Event-triggered asynchronous periodic distributed secondary control of microgrids under DoS attacks. J. Frankl. Inst. 2022. [Google Scholar] [CrossRef]
- Yue, B.; Che, W. Data-Driven dynamic event-triggered fault-tolerant platooning control. IEEE Trans. Ind. Inform. 2022. [Google Scholar] [CrossRef]
- Ma, Y.; Che, W.; Deng, C.; Wu, Z. Observer-based event-triggered containment control for MASs under DoS attacks. IEEE Trans. Cybern. 2021. [Google Scholar] [CrossRef] [PubMed]
- Ma, Y.; Che, W.; Deng, C.; Wu, Z. Distributed model-free adaptive control for learning nonlinear MASs under DoS attacks. IEEE Trans. Neural Netw. Learn. Syst. 2021. [Google Scholar] [CrossRef] [PubMed]
- Wan, Y.; Wen, G.; Yu, X.; Huang, T. Distributed Consensus Tracking of Networked Agent Systems under Denial-of-Service Attacks. IEEE Trans. Syst. Man, Cybern. Syst. 2021, 51, 61836196. [Google Scholar] [CrossRef]
- Pang, Z.; Liu, G.; Zhou, D.; Sun, D. Data-based predictive control for networked nonlinear systems with network-induced delay and packet dropout. IEEE Trans. Ind. Electron. 2016, 63, 1249–1257. [Google Scholar] [CrossRef]
- Pang, Z.; Liu, G.; Zhou, D.; Sun, D. Data-based predictive control for networked non-linear systems with two-channel packet dropouts. IET Control. Theory Applocations 2015, 9, 1154–1161. [Google Scholar] [CrossRef]
- Yu, W.; Wang, R.; Bu, X.; Hou, Z. Model free adaptive control for a class of nonlinear systems with fading measurements. J. Frankl. Inst.-Eng. Appl. Math. 2020, 357, 7743–7760. [Google Scholar] [CrossRef]
- Yu, W.; Wang, R.; Bu, X.; Hou, Z.; Wu, Z. Resilient Model-Free Adaptive Iterative Learning Control for Nonlinear Systems under Periodic DoS Attacks via a Fading Channel. IEEE Trans. Syst. Man, Cybern. Syst. 2021, 52, 4117–4128. [Google Scholar] [CrossRef]
- Qiu, X.; Wang, Y.; Xie, X. Resilient model-free adaptive control for cyber-physical systems against jamming attack. Neurocomputing 2020, 413, 422–430. [Google Scholar] [CrossRef]
- Wang, Y.; Qiu, X.; Zhang, H.; Xie, X. Data-driven-based event-triggered control for nonlinear CPSs against jamming attacks. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 3171–3177. [Google Scholar] [CrossRef] [PubMed]
- Sun, H.; Hou, Z.; Li, D. Coordinated iterative learning control schemes for train trajectory tracking with overspeed protection. IEEE Trans. Autom. Sci. Eng. 2013, 10, 323–333. [Google Scholar] [CrossRef]
- Yue, B.; Che, W. Data-driven resilient platooning control for vehicular platooning systems with denial-of-service attacks. Int. J. Robust Nonlinear Control 2022, 32, 7099–7112. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| This Paper | [13] | |
|---|---|---|
| 26.18 | 1.33 | |
| 58.83 | 1.48 | |
| 98.72 | 2 | |
| 25.77 | 75.96 | |
| 46.04 | 119.80 | |
| 67.34 | 176.21 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Z.; Zhu, L.; Wang, Z.; Che, W. Data-Driven Event-Triggered Platoon Control under Denial-of-Service Attacks. Mathematics 2022, 10, 3985. https://doi.org/10.3390/math10213985
Li Z, Zhu L, Wang Z, Che W. Data-Driven Event-Triggered Platoon Control under Denial-of-Service Attacks. Mathematics. 2022; 10(21):3985. https://doi.org/10.3390/math10213985
Chicago/Turabian StyleLi, Zengwei, Lin Zhu, Zhenling Wang, and Weiwei Che. 2022. "Data-Driven Event-Triggered Platoon Control under Denial-of-Service Attacks" Mathematics 10, no. 21: 3985. https://doi.org/10.3390/math10213985
APA StyleLi, Z., Zhu, L., Wang, Z., & Che, W. (2022). Data-Driven Event-Triggered Platoon Control under Denial-of-Service Attacks. Mathematics, 10(21), 3985. https://doi.org/10.3390/math10213985