


Iterative Dual CNNs for Image Deblurring

Abstract
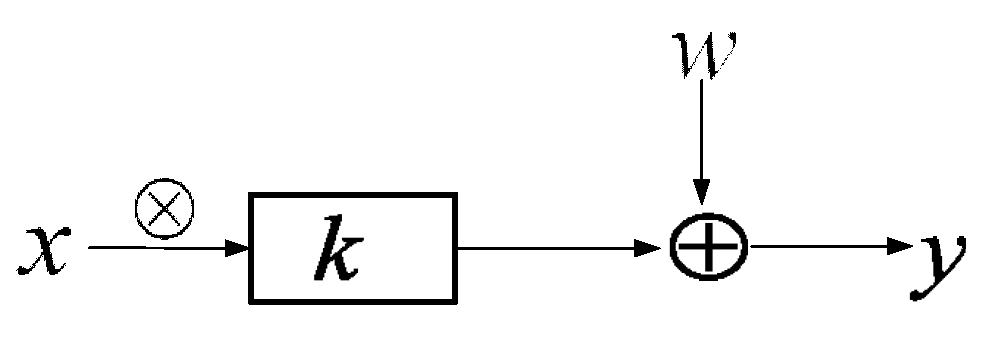
1. Introduction
- Specifically, the deblurring sub-networks based on U-Net structure are used to increase the receptive field through the multiscale inputs. That can acquire multiple-scale structural information on the blurred images and improve both the deblurring performance and the generalization ability of the networks.
- Then, the detail recovery sub-network with a shallow and wide network structure extract the texture information of the blurred images. It keeps the feature maps and the input image at the same resolution without downsampling.
- Finally, the fusion module is used to construct the clean image by fuse and enhance the output of the deblurring and texture recovery sub-networks.
- Additionally, extensive experiments illustrate that our IDC outperforms most of the state-of-the art deblurring in terms of both quantitative and qualitative analysis.
2. Related Work
2.1. Priors-Based Methods
2.2. Deep Learning Methods
2.3. End to End U-Net Structure
3. The Proposed Method
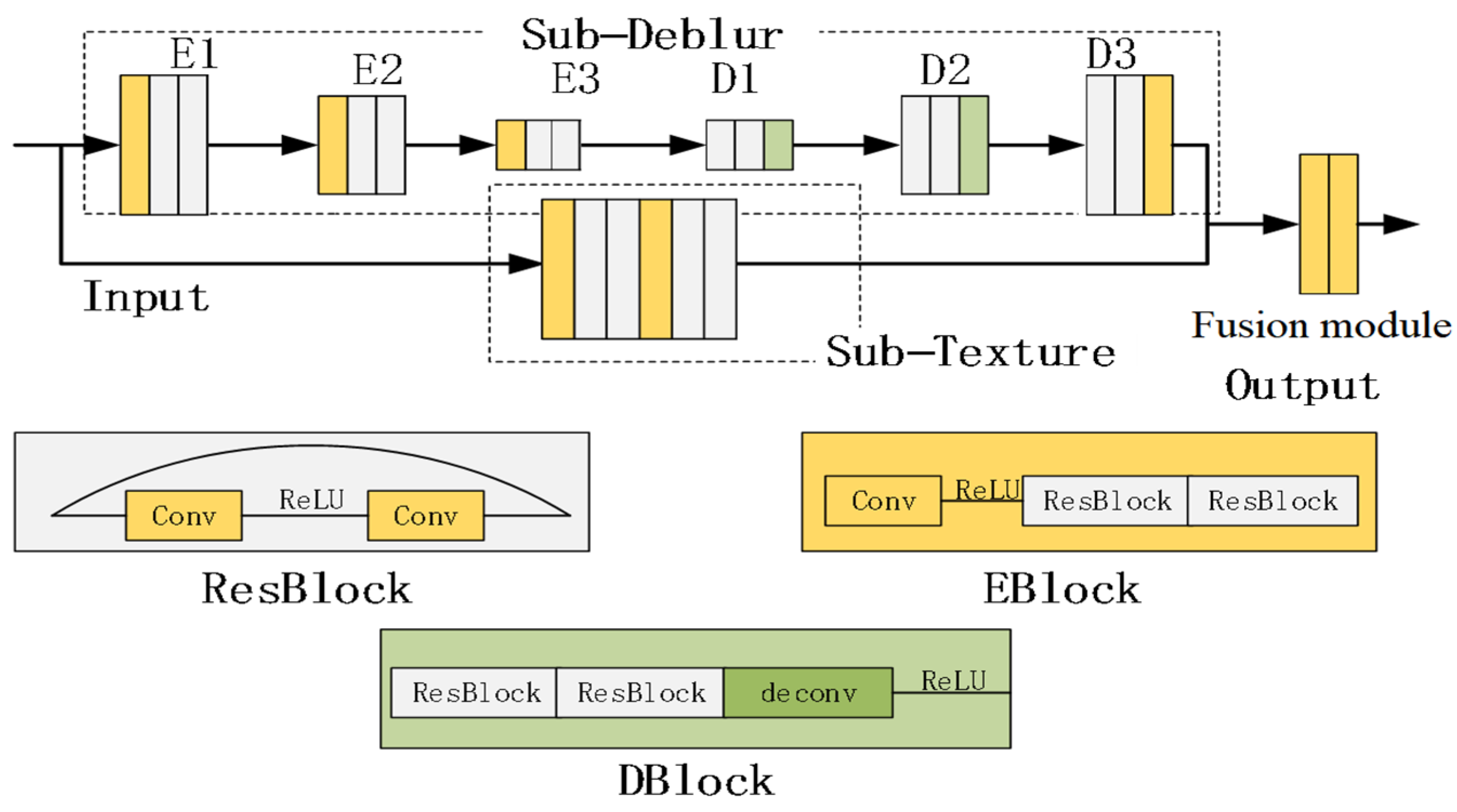
3.1. Network Structure
- ResBlock module: The residual module consists of two convolution layers and activation functions, and the convolution layers are in skip connection.
- Eblock module: The encoding module is connected with two ResBlock modules through an activation function by a convolution layer responsible for blurred image feature extraction.
- Dblock module: The decoding module serially connects two ResBlock modules and one deconvolution layer via an activation function.
- Fusion module: The information integration module combines the deblurring sub-network and the detail recovery sub-network to output the final deblurred image.
- Sub-Deblur: The deblurring sub-network consists of Eblock modules E1, E2, E3 and Dblock modules D1, D2, D3. It is based on a U-Net structure to complete the basic deblurring task.
- Sub-Texture: The detail recovery sub-network consists of two Eblock modules connected in series for image detail recovery and retention.
3.2. Multi-Scale Iterative Strategy
3.3. Mixed Loss Function
4. Experimental Results and Discussion
4.1. Objective Assessment
4.2. Subjective Assessment
4.3. Ablation Experiment
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Tian, C.; Zhang, X.; Lin, J.C.W.; Zuo, W.; Zhang, Y.; Lin, C.W. Generative Adversarial Networks for Image Super-Resolution: A Survey. arXiv 2022, preprint. arXiv:2204.13620. [Google Scholar]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 295–307. [Google Scholar] [CrossRef] [PubMed]
- Van Ouwerkerk, J.D. Image super-resolution survey. Image Vis. Comput. 2006, 24, 1039–1052. [Google Scholar] [CrossRef]
- Zhang, Y.; Tian, Y.; Kong, Y.; Zhong, B.; Fu, Y. Residual dense network for image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2472–2481. [Google Scholar]
- Yang, C.Y.; Ma, C.; Yang, M.H. Single-Image Super-Resolution: A Benchmark. In European Conference on Computer Vision; Springer: Cham, Germany, 2014; pp. 372–386. [Google Scholar]
- Tian, C.; Yuan, Y.; Zhang, S.; Lin, C.W.; Zuo, W.; Zhang, D. Image Super-resolution with An Enhanced Group Convolutional Neural Network. arxiv 2022, preprint. arXiv:2205.14548. [Google Scholar] [CrossRef] [PubMed]
- Goyal, B.; Dogra, A.; Agrawal, S.; Sohi, B.S.; Sharma, A. Image denoising review: From classical to state-of-the-art approaches. Inf. Fusion 2020, 55, 220–244. [Google Scholar] [CrossRef]
- Zhang, Q.; Xiao, J.; Tian, C.; Chun-Wei Lin, J.; Zhang, S. A robust deformed convolutional neural network (CNN) for image denoising. CAAI Trans. Intell. Technol. 2022. [Google Scholar] [CrossRef]
- Zhang, K.; Zuo, W.; Zhang, L. FFDNet: Toward a fast and flexible solution for CNN-based image denoising. IEEE Trans. Image Process. 2018, 27, 4608–4622. [Google Scholar] [CrossRef] [PubMed]
- Zheng, M.; Zhi, K.; Zeng, J.; Tian, C.; You, L. A Hybrid CNN for Image Denoising. J. Artif. Intell. Technol. 2022, 2, 93–99. [Google Scholar] [CrossRef]
- Pan, J.; Sun, D.; Pfister, H.; Yang, M.H. Blind image deblurring using dark channel prior. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1628–1636. [Google Scholar]
- Ren, W.; Cao, X.; Pan, J.; Guo, X.; Zuo, W.; Yang, M.H. Image deblurring via enhanced low-rank prior. IEEE Trans. Image Process. 2016, 25, 3426–3437. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.; Fang, F.; Wang, T.; Zhang, G. Blind image deblurring with local maximum gradient prior. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1742–1750. [Google Scholar]
- Xu, L.; Zheng, S.; Jia, J. Unnatural l0 sparse representation for natural image deblurring. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 1107–1114. [Google Scholar]
- Sun, J.; Cao, W.; Xu, Z.; Ponce, J. Learning a convolutional neural network for non-uniform motion blur removal. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 769–777. [Google Scholar]
- Jain, V.; Seung, H.S. Natural image denoising with convolutional networks. In Proceedings of the International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–11 December 2008; pp. 769–776. [Google Scholar]
- Hradis, M.; Kotera, J.; Zemčík, P.; Šroubek, F. Convolutional neural networks for direct text deblurring. In Proceedings of the British Machine Vision Conference, Swansea, UK, 7–10 September 2015. [Google Scholar]
- Su, S.; Delbracio, M.; Wang, J.; Sapiro, G.; Heidrich, W.; Wang, O. Deep video deblurring for hand-held cameras. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1279–1288. [Google Scholar]
- Nimisha, T.M.; Singh, A.K.; Rajagopalan, A.N. Blur-invariant deep learning for blind-deblurring. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 4762–4770. [Google Scholar]
- Vasu, S.; Maligireddy, V.R.; Rajagopalan, A.N. Non-blind deblurring: Handling kernel uncertainty with CNNs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3272–3281. [Google Scholar]
- Wieschollek, P.; Hirsch, M.; Schölkopf, B.; Lensch, H. Learning blind motion deblurring. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 231–240. [Google Scholar]
- Kupyn, O.; Budzan, V.; Mykhailych, M.; Mishkin, D.; Matas, J. DeblurGAN: Blind motion deblurring using conditional adversarial networks. arXiv 2017, preprint. arXiv:1711.07064. [Google Scholar]
- Li, L.; Pan, J.; Lai, W.S.; Gao, C.; Sang, N.; Yang, M.H. Learning a discriminative prior for blind image deblurring. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6616–6625. [Google Scholar]
- Zhang, J.; Pan, J.; Ren, J.; Song, Y.; Bao, L.; Lau, R.W.; Yang, M.H. Dynamic scene deblurring using spatially variant recurrent neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2521–2529. [Google Scholar]
- Nah, S.; Kim, T.H.; Lee, K.M. Deep multi-scale convolutional neural network for dynamic scene deblurring. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3883–3891. [Google Scholar]
- Gao, H.; Tao, X.; Shen, X.; Jia, J. Dynamic scene deblurring with parameter selective sharing and nested skip connections. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seoul, Korea, 27–28 October 2019; pp. 3848–3856. [Google Scholar]
- Kupyn, O.; Martyniuk, T.; Wu, J.; Wang, Z. Deblurgan-v2: Deblurring (orders-of-magnitude) faster and better. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 8878–8887. [Google Scholar]
- Suin, M.; Purohit, K.; Rajagopalan, A.N. Spatially-attentive patch-hierarchical network for adaptive motion deblurring. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 3606–3615. [Google Scholar]
- Tao, X.; Gao, H.; Shen, X.; Wang, J.; Jia, J. Scale-recurrent network for deep image deblurring. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8174–8182. [Google Scholar]
- Zhang, X.; Wang, F.; Dong, H.; Guo, Y. A Deep Encoder-Decoder Networks for Joint Deblurring and Super-Resolution. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018. [Google Scholar]
- Guo, T.; Kim, Y.; Zhang, H.; Qian, D.; Yoo, B.; Xu, J.; Zou, D.; Han, J.-J.; Choi, C. Residual Encoder Decoder Network and Adaptive Prior for Face Parsing; AAAI: Menlo Park, CA, USA, 2018. [Google Scholar]
- Mao, X.; Shen, C.; Yang, Y.B. Image restoration using very deep convolutional encoder-decoder networks with symmetric skip connections. Adv. Neural Inf. Process. Syst. 2016, 29, 2802–2810. [Google Scholar]
- Zeiler, M.D.; Krishnan, D.; Taylor, G.W.; Fergus, R. Deconvolutional networks. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, CVPR 2010, San Francisco, CA, USA, 13–18 June 2010. [Google Scholar]
- Pan, J.; Liu, R.; Su, Z.; Gu, X. Kernel estimation from salient structure for robust motion deblurring. Signal Process. Image Commun. 2012, 28, 1156–1170. [Google Scholar] [CrossRef]
- Zhang, X.; Dong, H.; Hu, Z.; Lai, W.S.; Wang, F.; Yang, M.H. Gated fusion network for joint image deblurring and super-resolution. arxiv 2018, arXiv:1807.10806. [Google Scholar]
- Hyun Kim, T.; Ahn, B.; Mu Lee, K. Dynamic scene deblurring. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; IEEE Computer Society: Washington, DC, USA, 2013; pp. 3160–3167. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Block | Kernel Number | Kernel Size | Stride | Padding |
|---|---|---|---|---|
| E2 | 32 | Conv: 5 × 5 | 1 | SAME |
| 32 | ResBlock: 5 × 5 | 1 | SAME | |
| E2 | 64 | Conv: 5 × 5 | 2 | SAME |
| 64 | ResBlock: 5 × 5 | 1 | SAME | |
| E3 | 128 | Conv: 5 × 5 | 2 | SAME |
| 128 | ResBlock: 5 × 5 | 1 | SAME | |
| D1 | 128 | deconv: 4 × 4 | 2 | SAME |
| 128 | ResBlock: 5 × 5 | 1 | SAME | |
| D2 | 64 | deconv: 4 × 4 | 2 | SAME |
| 64 | ResBlock: 5 × 5 | 1 | SAME | |
| D3 | 32 | deconv: 4 × 4 | 1 | SAME |
| 32 | ResBlock: 5 × 5 | 1 | SAME | |
| Sub-Texture | 64 | Eblock: 5 × 5 | 1 | SAME |
| Fusion module | 32 | Conv: 5 × 5 | 1 | SAME |
| 3 | Conv: 5 × 5 | 1 | SAME |
| Method | PSNR | SSIM | Runtime (per img) |
|---|---|---|---|
| Kim et al. [36] | 23.60 | 0.823 | 1 h |
| Sun et al. [15] | 24.60 | 0.842 | 20 min |
| Xu et al. [14] | 25.10 | 0.890 | 12 s |
| Nah S et al. [25] | 29.10 | 0.913 | 3 s |
| Kupyn et al. [33] | 29.55 | 0.934 | 0.7 s |
| Tao et al. [29] | 30.10 | 0.932 | 1.6 s |
| Gao et al. [26] | 30.92/31.58 | 0.942/0.948 | 1.7 s |
| Our (proposed) | 31.11 | 0.948 | 0.4 s |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.; Wang, Z.; Yang, A. Iterative Dual CNNs for Image Deblurring. Mathematics 2022, 10, 3891. https://doi.org/10.3390/math10203891
Wang J, Wang Z, Yang A. Iterative Dual CNNs for Image Deblurring. Mathematics. 2022; 10(20):3891. https://doi.org/10.3390/math10203891
Chicago/Turabian StyleWang, Jinbin, Ziqi Wang, and Aiping Yang. 2022. "Iterative Dual CNNs for Image Deblurring" Mathematics 10, no. 20: 3891. https://doi.org/10.3390/math10203891
APA StyleWang, J., Wang, Z., & Yang, A. (2022). Iterative Dual CNNs for Image Deblurring. Mathematics, 10(20), 3891. https://doi.org/10.3390/math10203891