
Meta-Heuristic Optimization of LSTM-Based Deep Network for Boosting the Prediction of Monkeypox Cases
 ,
,  ,
,  ,
,  ,
,  ,
,  ,
,  ,
,  , and
, and 
Abstract
1. Introduction
- A new approach is proposed based on optimized LSTM prediction to improve the accuracy of Monkeypox infection prediction.
- The proposed approach is compared with other ML models and optimization algorithms, and the results are recorded.
- The recorded results are analyzed using statistical methods such as Wilcoxon’s rank-sum test and one-way analysis of variance to evaluate the statistical difference and significance of the proposed approach.
- The proposed approach can be generalized and tested for other datasets.
2. Related Works
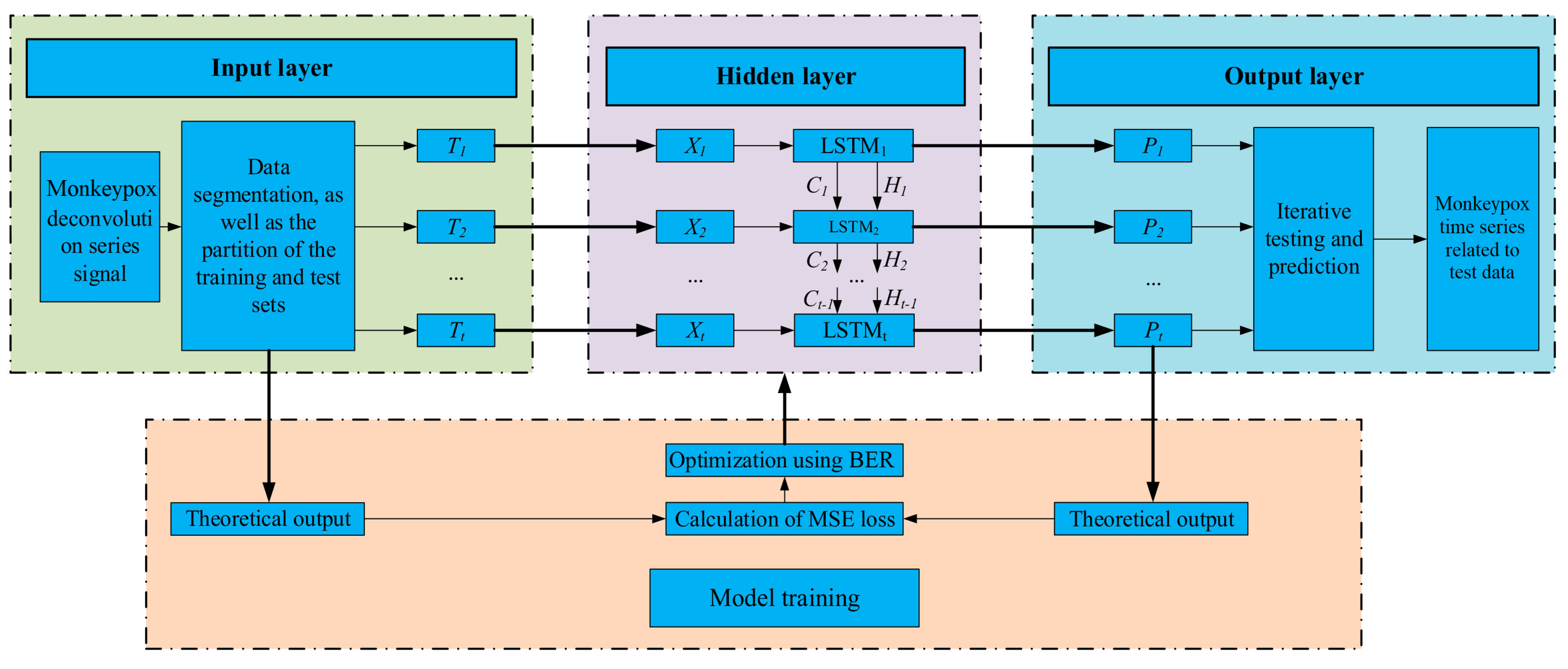
3. The Proposed Methodology
| Algorithm 1: The proposed prediction algorithm of Monkeypox confirmed cases. |
|
3.1. LSTM
3.2. Al-Biruni Earth Radius Optimization Algorithm
| Algorithm 2: BER optimization algorithm. |
|
3.2.1. Exploration Operation
- Moving towards the best solution : Using this strategy, the lone explorer in the group will look for promising new areas to explore in the immediate vicinity of where it now is. This is achieved by iteratively looking for a better choice (in terms of fitness) among the many possible alternatives in the immediate area. To do so, the BER study makes use of the following equations:where , h is a number that is randomly selected from the range , and are coefficient vectors whose values are measured by Equation (2), is the solution vector at iteration t, and is the diameter of the circle in which the search agent will look for promising areas.
3.2.2. Exploitation Operation
- Moving towards the best solution: To move in the direction of the best solution, the following equation is employed.where is a random vector calculated using Equation (2) that controls the movement steps towards the best solution, is the solution vector at iteration t, (t) is the best solution vector, and refers to the distance vector.
- Searching the area around the best solution: The area around the best answer is the most promising option (leader). This leads some people to look for improvements by exploring areas close to the optimal answer. The BER uses the following equation to carry out the aforementioned procedure.where refers to the best solution. After comparing and , the best solution can be selected. If the best fitness is not changed for the last two iterations, the solution is mutated by the following equation:where z is a random number in the range and t is the iteration number.
3.2.3. Selection of the Best Solution
4. Experimental Results
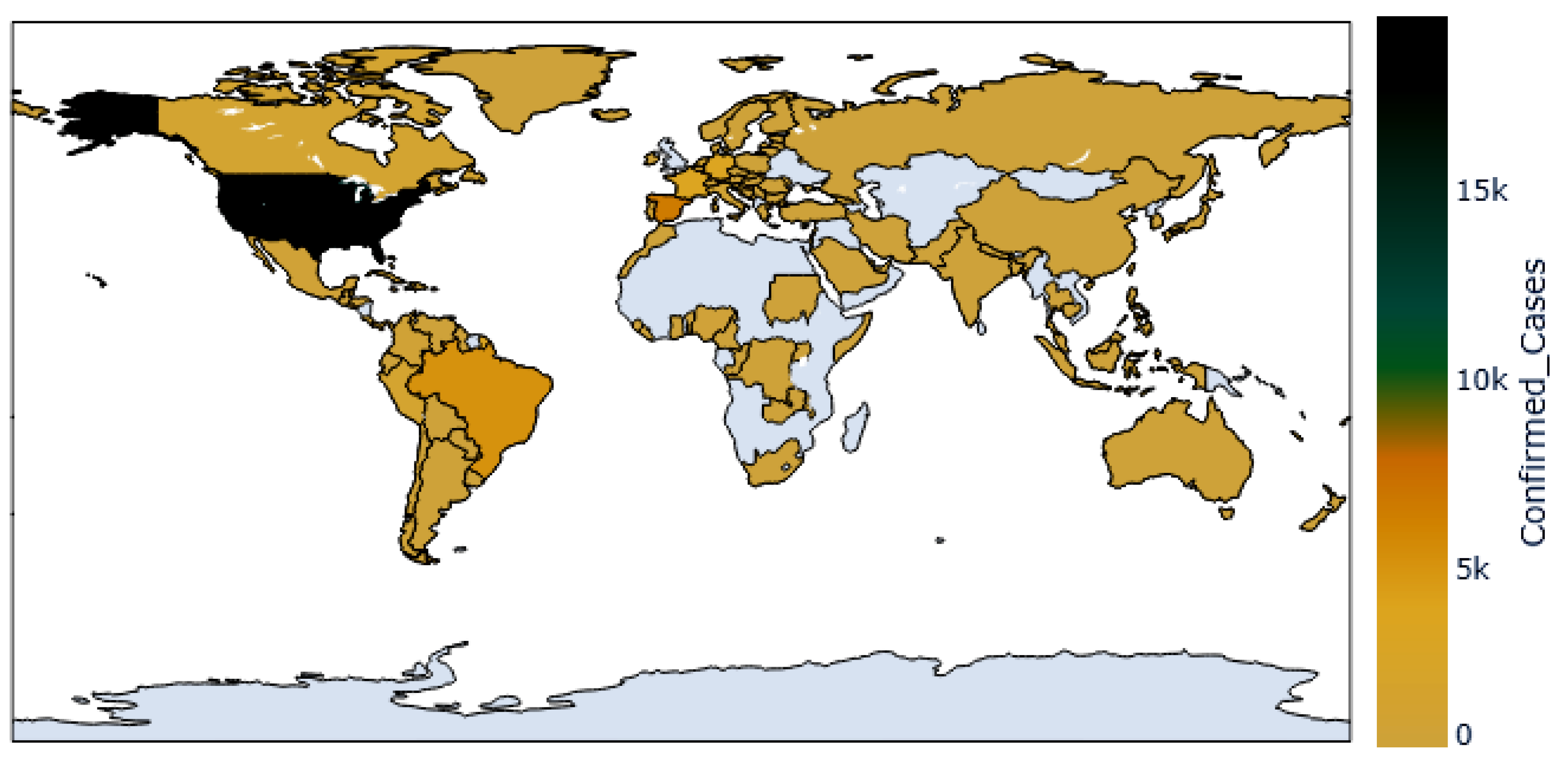
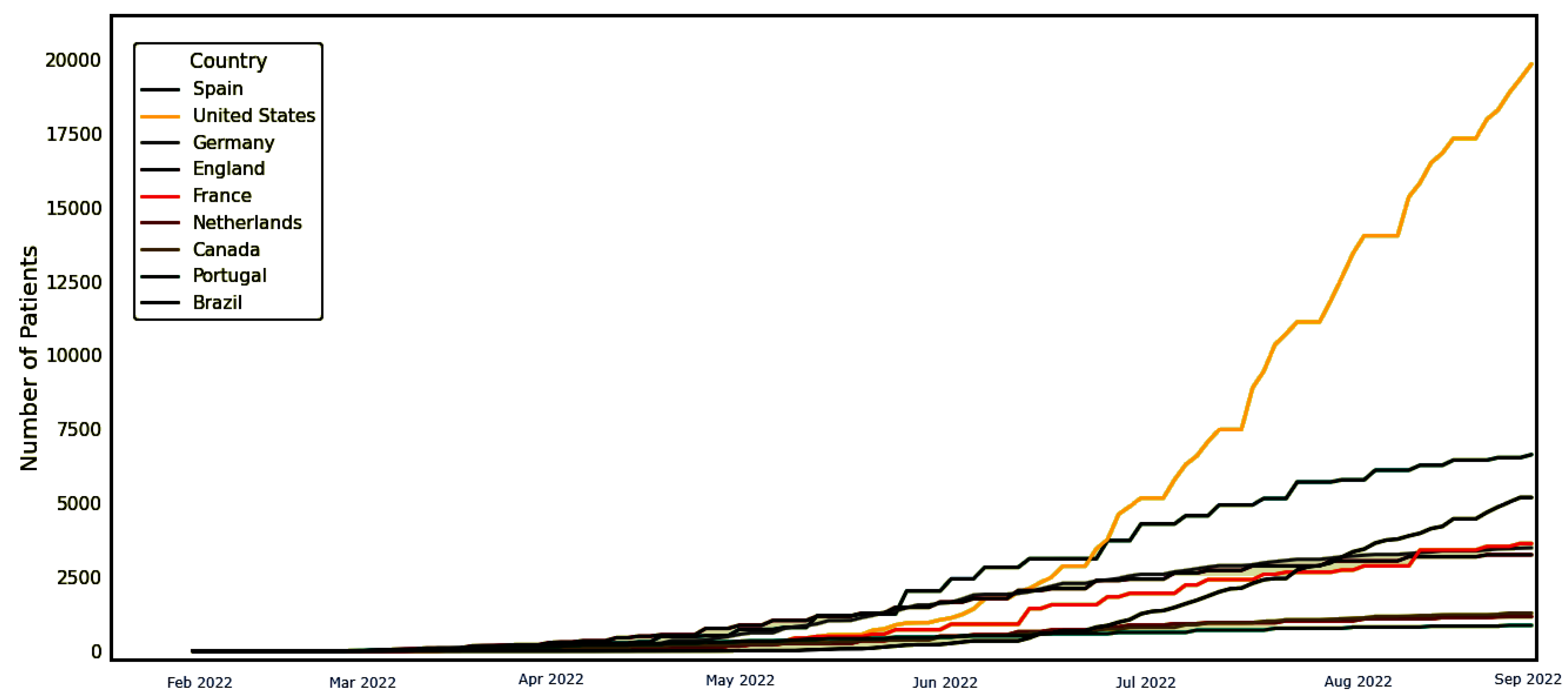
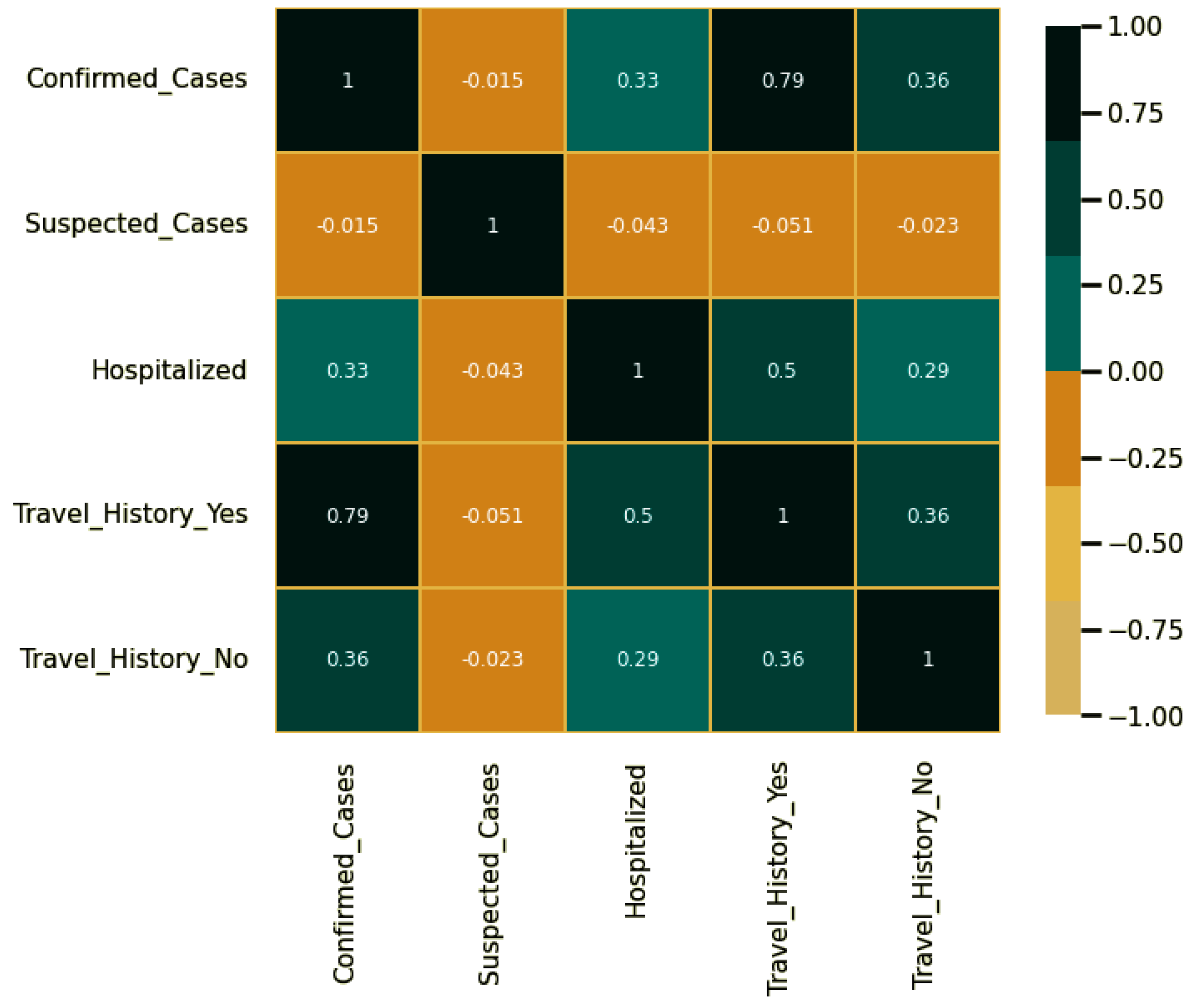
4.1. Dataset
4.2. Configuration Parameters
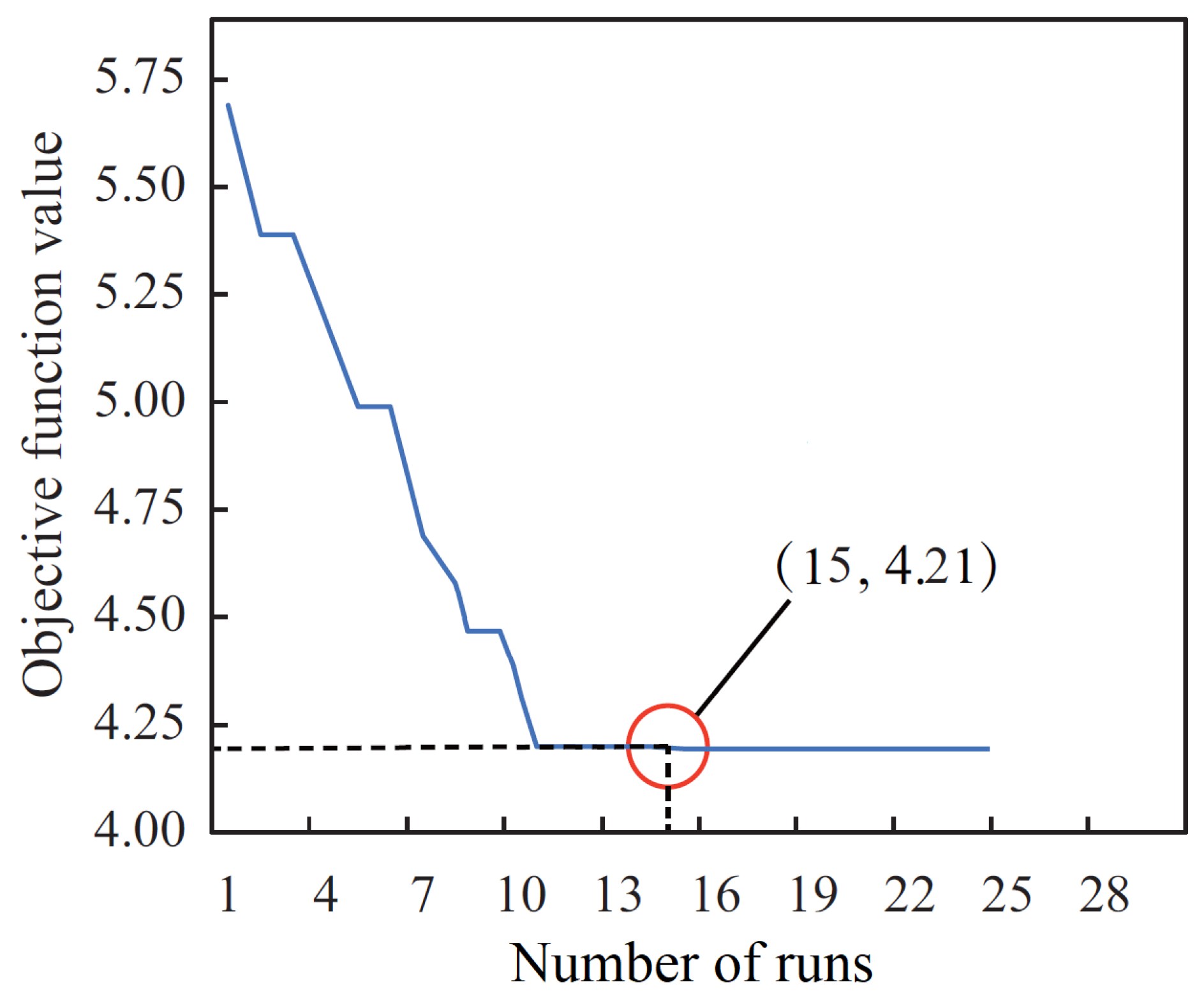
4.3. Optimization of Parameters in LSTM
4.4. Evaluation Criteria
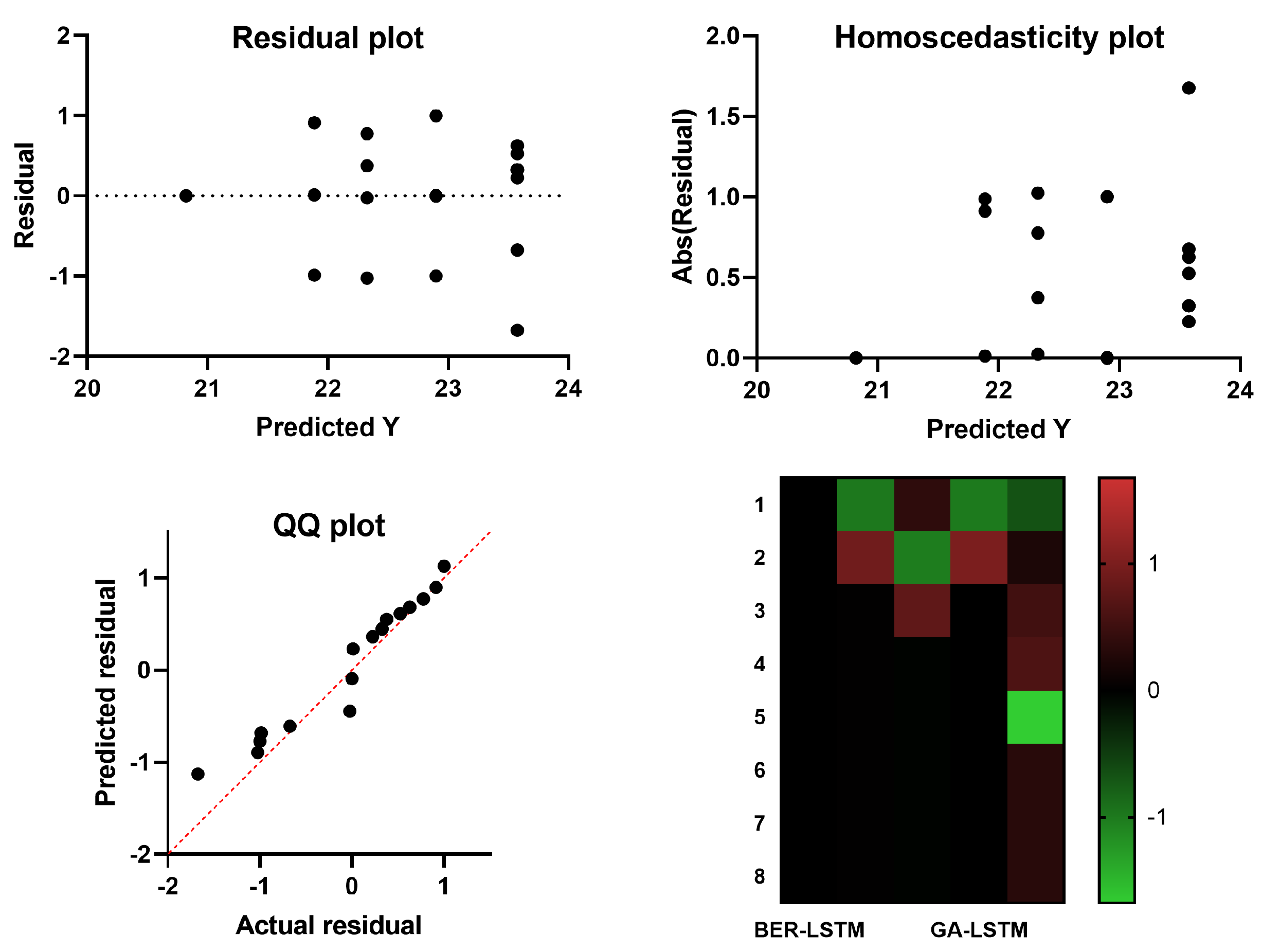
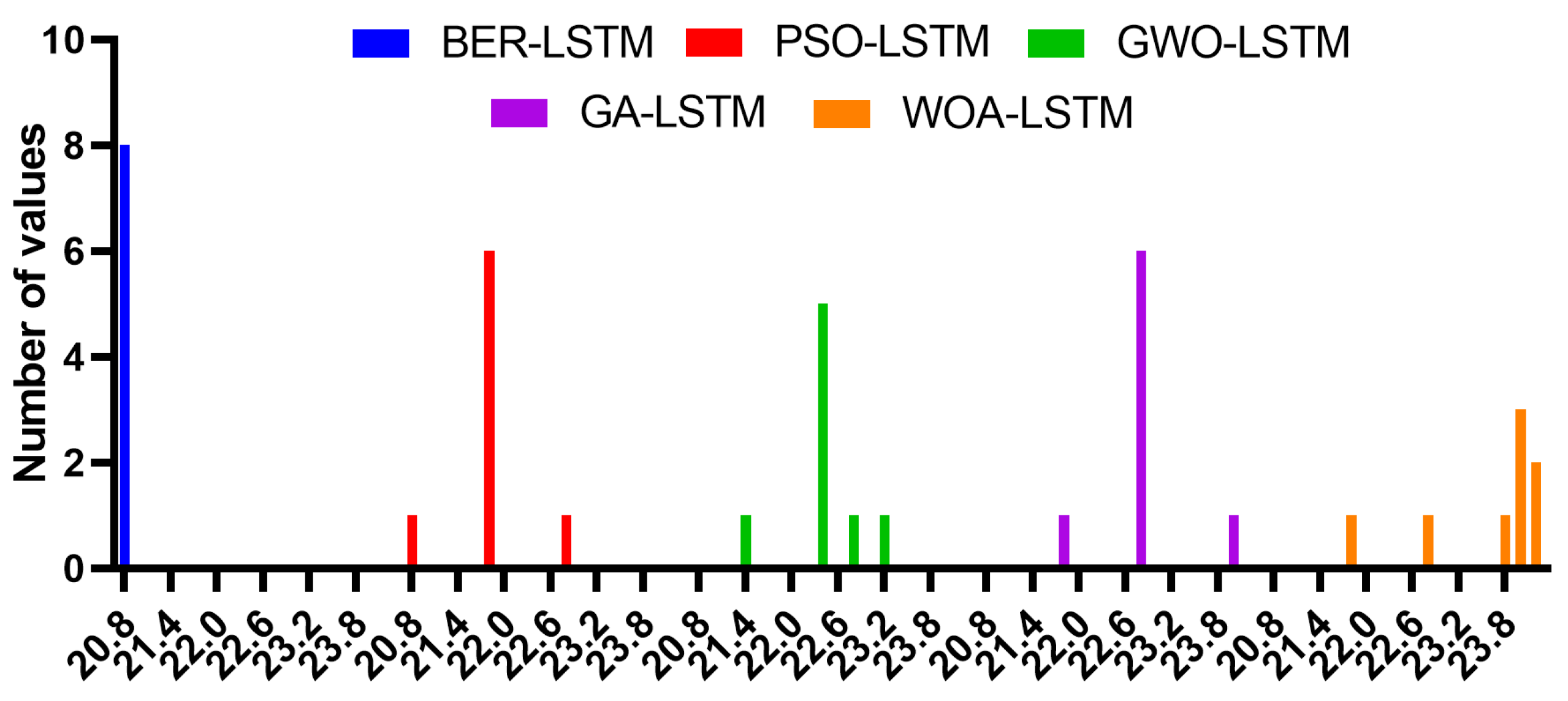
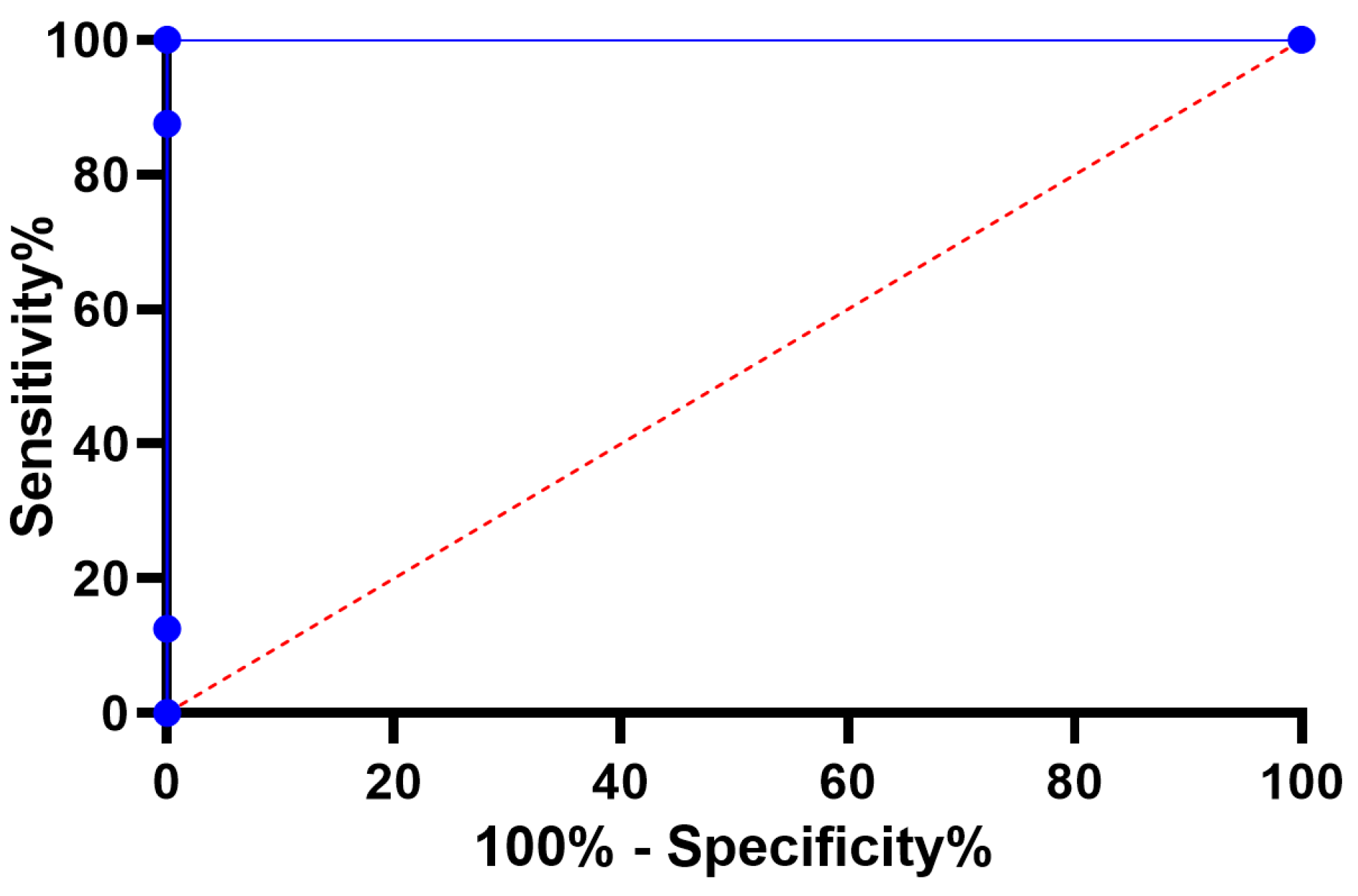
4.5. The Achieved Results
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Banerjee, I.; Robinson, J.; Sathian, B. Global re-emergence of human monkeypox: Population on high alert. Nepal J. Epidemiol. 2022, 12, 1179–1181. [Google Scholar] [CrossRef] [PubMed]
- Rogers, J.V.; Parkinson, C.V.; Choi, Y.W.; Speshock, J.L.; Hussain, S.M. A Preliminary Assessment of Silver Nanoparticle Inhibition of Monkeypox Virus Plaque Formation. Nanoscale Res. Lett. 2008, 3, 129–133. [Google Scholar] [CrossRef]
- Alakunle, E.; Moens, U.; Nchinda, G.; Okeke, M.I. Monkeypox Virus in Nigeria: Infection Biology, Epidemiology, and Evolution. Viruses 2020, 12, 1257. [Google Scholar] [CrossRef]
- Breman, J.G.; Kalisa-Ruti, N.; Steniowski, M.V.; Zanotto, E.; Gromyko, A.I.; Arita, I. Human monkeypox, 1970–79. Bull. World Health Organ. 1980, 58, 165–182. [Google Scholar] [PubMed]
- Nguyen, P.Y.; Ajisegiri, W.S.; Costantino, V.; Chughtai, A.A.; MacIntyre, C.R. Reemergence of Human Monkeypox and Declining Population Immunity in the Context of Urbanization, Nigeria, 2017–2020. Emerg. Infect. Dis. 2021, 27, 1007. [Google Scholar] [CrossRef] [PubMed]
- Perkins, K.M.; Reddy, S.C.; Fagan, R.; Arduino, M.J.; Perz, J.F. Investigation of healthcare infection risks from water-related organisms: Summary of CDC consultations, 2014–2017. Infect. Control Hosp. Epidemiol. 2019, 40, 621–626. [Google Scholar] [CrossRef] [PubMed]
- Hill, B. The 2022 multinational monkeypox outbreak in non-endemic countries. Br. J. Nurs. 2022, 31, 664–665. [Google Scholar] [CrossRef]
- Miethke-Morais, A.; Cassenote, A.; Piva, H.; Tokunaga, E.; Cobello, V.; Rodrigues Gonçalves, F.A.; dos Santos Lobo, R.; Trindade, E.; Carneiro D’Albuquerque, L.A.; Haddad, L. COVID-19-related hospital cost-outcome analysis: The impact of clinical and demographic factors. Braz. J. Infect. Dis. 2021, 25, 101609. [Google Scholar] [CrossRef]
- Xu, L.; Magar, R.; Barati Farimani, A. Forecasting COVID-19 new cases using deep learning methods. Comput. Biol. Med. 2022, 144, 105342. [Google Scholar] [CrossRef]
- Annas, S.; Isbar Pratama, M.; Rifandi, M.; Sanusi, W.; Side, S. Stability analysis and numerical simulation of SEIR model for pandemic COVID-19 spread in Indonesia. Chaos Solitons Fractals 2020, 139, 110072. [Google Scholar] [CrossRef]
- El-Kenawy, E.S.M.; Ibrahim, A.; Mirjalili, S.; Eid, M.M.; Hussein, S.E. Novel Feature Selection and Voting Classifier Algorithms for COVID-19 Classification in CT Images. IEEE Access 2020, 8, 179317–179335. [Google Scholar] [CrossRef] [PubMed]
- For Alzheimer’s Disease Neuroimaging Initiative; Lee, G.; Nho, K.; Kang, B.; Sohn, K.A.; Kim, D. Predicting Alzheimer’s disease progression using multi-modal deep learning approach. Sci. Rep. 2019, 9, 1952. [Google Scholar] [CrossRef] [PubMed]
- Sharma, K.; Kaur, A.; Gujral, S. Brain Tumor Detection based on Machine Learning Algorithms. Int. J. Comput. Appl. 2014, 103, 7–11. [Google Scholar] [CrossRef]
- Agrawal, M.; Jain, V. Prediction of Breast Cancer based on Various Medical Symptoms Using Machine Learning Algorithms. In Proceedings of the 2022 6th International Conference on Trends in Electronics and Informatics (ICOEI), Tirunelveli, India, 28–30 April 2022; pp. 1242–1245. [Google Scholar] [CrossRef]
- Rabbi, M.F.; Mahedy Hasan, S.M.; Champa, A.I.; AsifZaman, M.; Hasan, M.K. Prediction of Liver Disorders using Machine Learning Algorithms: A Comparative Study. In Proceedings of the 2020 2nd International Conference on Advanced Information and Communication Technology (ICAICT), Dhaka, Bangladesh, 28–29 November 2020; pp. 111–116. [Google Scholar] [CrossRef]
- Swain, D.; Pani, S.K.; Swain, D. A Metaphoric Investigation on Prediction of Heart Disease using Machine Learning. In Proceedings of the 2018 International Conference on Advanced Computation and Telecommunication (ICACAT), Bhopal, India, 28–29 December 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Zhu, W.; Sun, L.; Huang, J.; Han, L.; Zhang, D. Dual Attention Multi-Instance Deep Learning for Alzheimer’s Disease Diagnosis With Structural MRI. IEEE Trans. Med. Imaging 2021, 40, 2354–2366. [Google Scholar] [CrossRef]
- Chandra, M.M.G. Effective Heart Disease Prediction Using Hybrid Machine Learning Techniques. Int. J. Sci. Res. Eng. Manag. 2022, 6. [Google Scholar] [CrossRef]
- Wang, Z.; Zhu, X.; Adeli, E.; Zhu, Y.; Nie, F.; Munsell, B.; Wu, G. Multi-modal classification of neurodegenerative disease by progressive graph-based transductive learning. Med. Image Anal. 2017, 39, 218–230. [Google Scholar] [CrossRef]
- Wu, C.C.; Yeh, W.C.; Hsu, W.D.; Islam, M.M.; Nguyen, P.A.A.; Poly, T.N.; Wang, Y.C.; Yang, H.C.; Li, Y.C. Prediction of fatty liver disease using machine learning algorithms. Comput. Methods Programs Biomed. 2019, 170, 23–29. [Google Scholar] [CrossRef]
- Qin, J.; Chen, L.; Liu, Y.; Liu, C.; Feng, C.; Chen, B. A Machine Learning Methodology for Diagnosing Chronic Kidney Disease. IEEE Access 2020, 8, 20991–21002. [Google Scholar] [CrossRef]
- Khan, M.M.R.; Arif, R.B.; Siddique, M.A.B.; Oishe, M.R. Study and Observation of the Variation of Accuracies of KNN, SVM, LMNN, ENN Algorithms on Eleven Different Datasets from UCI Machine Learning Repository. In Proceedings of the 2018 4th International Conference on Electrical Engineering and Information & Communication Technology (iCEEiCT), Dhaka, Bangladesh, 13–15 September 2018; pp. 124–129. [Google Scholar] [CrossRef]
- Abdar, M.; Książek, W.; Acharya, U.R.; Tan, R.S.; Makarenkov, V.; Pławiak, P. A new machine learning technique for an accurate diagnosis of coronary artery disease. Comput. Methods Programs Biomed. 2019, 179, 104992. [Google Scholar] [CrossRef]
- Islam, T.; Hussain, M.A.; Chowdhury, F.U.H.; Islam, B.M.R. A Web-scraped Skin Image Database of Monkeypox, Chickenpox, Smallpox, Cowpox, and Measles. bioRxiv 2022. [Google Scholar] [CrossRef]
- Monkeypox Skin Images Dataset (MSID). Available online: https://www.kaggle.com/datasets/dipuiucse/monkeypoxskinimagedataset (accessed on 1 September 2022).
- Ahsan, M.M.; Uddin, M.R.; Farjana, M.; Sakib, A.N.; Momin, K.A.; Luna, S.A. Image Data collection and implementation of deep learning-based model in detecting Monkeypox disease using modified VGG16. arXiv 2022, arXiv:2206.01862. [Google Scholar] [CrossRef]
- Abdelhamid, A.A.; El-Kenawy, E.S.M.; Alotaibi, B.; Amer, G.M.; Abdelkader, M.Y.; Ibrahim, A.; Eid, M.M. Robust Speech Emotion Recognition Using CNN+LSTM Based on Stochastic Fractal Search Optimization Algorithm. IEEE Access 2022, 10, 49265–49284. [Google Scholar] [CrossRef]
- El-kenawy, E.S.M.; Abdelhamid, A.A.; Ibrahim, A.; Mirjalili, S.; Khodadad, N.; duailij, M.A.A.; Alhussan, A.A.; Khafaga, D.S. Al-Biruni Earth Radius (BER) Metaheuristic Search Optimization Algorithm. Comput. Syst. Sci. Eng. 2023, 1–18, in press. [Google Scholar] [CrossRef]
- Abdelhamid, A.A.; El-Kenawy, E.S.M.; Khodadadi, N.; Mirjalili, S.; Khafaga, D.S.; Alharbi, A.H.; Ibrahim, A.; Eid, M.M.; Saber, M. Classification of Monkeypox Images Based on Transfer Learning and the Al-Biruni Earth Radius Optimization Algorithm. Mathematics 2022, 10, 3614. [Google Scholar] [CrossRef]
- Nasser AlEisa, H.; El-kenawy, E.S.M.; Ali Alhussan, A.; Saber, M.; Abdelhamid, A.; Sami Khafaga, D. Transfer Learning for Chest X-rays Diagnosis Using Dipper Throated Algorithm. Comput. Mater. Contin. 2022, 73, 2371–2387. [Google Scholar]
- Eid, M.M.; El-kenawy, E.S.M.; Ibrahim, A. A binary Sine Cosine-Modified Whale Optimization Algorithm for Feature Selection. In Proceedings of the 2021 National Computing Colleges Conference (NCCC), Taif, Saudi Arabia, 27–28 March 2021; pp. 1–6. [Google Scholar]
- El-Kenawy, E.S.M.; Mirjalili, S.; Ghoneim, S.S.M.; Eid, M.M.; El-Said, M.; Khan, Z.S.; Ibrahim, A. Advanced Ensemble Model for Solar Radiation Forecasting Using Sine Cosine Algorithm and Newton’s Laws. IEEE Access 2021, 9, 115750–115765. [Google Scholar] [CrossRef]
- Rajasthan, J. Monkeypox. 2019. Available online: https://www.kaggle.com/datasets/deepcontractor/monkeypox-dataset-daily-updated (accessed on 7 September 2022).
- Awange, J.L.; Paláncz, B.; Lewis, R.H.; Völgyesi, L. (Eds.) Particle Swarm Optimization. In Mathematical Geosciences: Hybrid Symbolic-Numeric Methods; Springer International Publishing: Cham, Switzerland, 2018; pp. 167–184. [Google Scholar] [CrossRef]
- Mirjalili, S.; Mirjalili, S.M.; Lewis, A. Grey Wolf Optimizer. Adv. Eng. Softw. 2014, 69, 46–61. [Google Scholar] [CrossRef]
- Immanuel, S.D.; Chakraborty, U.K. Genetic Algorithm: An Approach on Optimization. In Proceedings of the 2019 International Conference on Communication and Electronics Systems (ICCES), Tamil Nadu, India, 17–17 July 2019; pp. 701–708. [Google Scholar] [CrossRef]
- Mirjalili, S.; Lewis, A. The Whale Optimization Algorithm. Adv. Eng. Softw. 2016, 95, 51–67. [Google Scholar] [CrossRef]
- El-Kenawy, E.S.M.; Mirjalili, S.; Alassery, F.; Zhang, Y.D.; Eid, M.M.; El-Mashad, S.Y.; Aloyaydi, B.A.; Ibrahim, A.; Abdelhamid, A.A. Novel Meta-Heuristic Algorithm for Feature Selection, Unconstrained Functions and Engineering Problems. IEEE Access 2022, 10, 40536–40555. [Google Scholar] [CrossRef]
- Abdel Samee, N.; El-Kenawy, E.S.M.; Atteia, G.; Jamjoom, M.M.; Ibrahim, A.; Abdelhamid, A.A.; El-Attar, N.E.; Gaber, T.; Slowik, A.; Shams, M.Y. Metaheuristic Optimization Through Deep Learning Classification of COVID-19 in Chest X-ray Images. Comput. Mater. Contin. 2022, 73, 4193–4210. [Google Scholar]
- Khafaga, D.S.; Alhussan, A.A.; El-Kenawy, E.S.M.; Ibrahim, A.; Eid, M.M.; Abdelhamid, A.A. Solving Optimization Problems of Metamaterial and Double T-Shape Antennas Using Advanced Meta-Heuristics Algorithms. IEEE Access 2022, 10, 74449–74471. [Google Scholar] [CrossRef]
- Hamayel, M.J.; Owda, A.Y. A Novel Cryptocurrency Price Prediction Model Using GRU, LSTM and bi-LSTM Machine Learning Algorithms. AI 2021, 2, 477–496. [Google Scholar] [CrossRef]
- Zhao, H.; Hou, C.; Alrobassy, H.; Zeng, X. Recognition of Transportation State by Smartphone Sensors Using Deep Bi-LSTM Neural Network. J. Comput. Netw. Commun. 2019, 2019, e4967261. [Google Scholar] [CrossRef]
- Yamak, P.T.; Yujian, L.; Gadosey, P.K. A Comparison between ARIMA, LSTM, and GRU for Time Series Forecasting. In Proceedings of the 2019 2nd International Conference on Algorithms, Computing and Artificial Intelligence (ACAI 2019), Sanya, China, 20–22 December 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 49–55. [Google Scholar] [CrossRef]
- Alex, S.A.; Jhanjhi, N.; Humayun, M.; Ibrahim, A.O.; Abulfaraj, A.W. Deep LSTM Model for Diabetes Prediction with Class Balancing by SMOTE. Electronics 2022, 11, 2737. [Google Scholar] [CrossRef]
- Chang, V.; Bailey, J.; Xu, Q.A.; Sun, Z. Pima Indians diabetes mellitus classification based on machine learning (ML) algorithms. Neural Comput. Appl. 2022, 1–17. [Google Scholar] [CrossRef] [PubMed]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Parameter | Value |
|---|---|---|
| Al-Biruni Earth Radius (BER) | Iterations | 500 |
| Number of runs | 30 | |
| Mutation probability | 0.5 | |
| Exploration percentage | 70 | |
| K (decreases from 2 to 0) | 1 | |
| Particle Swarm Optimization (PSO) [34] | Acceleration constants | [2, 12] |
| Inertia , | [0.6, 0.9] | |
| Particles | 10 | |
| Iterations | 80 | |
| Grey Wolf Optimizer (GWO) [35] | a | 2 to 0 |
| Iterations | 80 | |
| Wolves | 10 | |
| Genetic Algorithm (GA) [36] | Cross over | 0.9 |
| Mutation ratio | 0.1 | |
| Selection mechanism | Roulette wheel | |
| Iterations | 80 | |
| Agents | 10 | |
| Whale Optimization Algorithm (WOA) [37] | r | [0, 1] |
| Iterations | 80 | |
| Whales | 10 | |
| a | 2 to 0 |
| Learning Rate | Hidden Nodes | Hidden Layers | |
|---|---|---|---|
| Lower bound | 1 | 1 | |
| Upper bound | 20 | 10 | |
| Optimized values | 7 | 2 |
| Metric | Value |
|---|---|
| RMSE | |
| RRMSE | |
| MAE | |
| NSE | |
| MBE | |
| R2 | |
| WI | |
| r |
| Model | MSE | RMSE | MAE | R2 | RRMSE | r | MBE | NSE |
|---|---|---|---|---|---|---|---|---|
| BER-LSTM (Proposed) | 646.41 | 25.14 | 16.39 | 0.7 | 1.33 | 0.84 | −3.75 | 0.65 |
| LSTM | 655.33 | 27.31 | 18.6 | 0.59 | 1.66 | 0.833 | 3.79 | 0.59 |
| BILSTM | 704.64 | 28.28 | 20.68 | 0.55 | 1.38 | 0.82 | 7.03 | 0.55 |
| GRU | 643.15 | 27.08 | 17.62 | 0.61 | 1.33 | 0.83 | 1.79 | 0.61 |
| LSTMs | 618.22 | 26.57 | 17.51 | 0.63 | 1.3 | 0.85 | 0.5 | 0.63 |
| BILSTMs | 637.8 | 26.97 | 16.9 | 0.61 | 1.32 | 0.83 | −0.65 | 0.61 |
| CONVLSTMs | 728.28 | 28.73 | 17.41 | 0.53 | 1.41 | 0.8 | 0.72 | 0.53 |
| Model | MSE | RMSE | MAE | R2 | RRMSE | r | MBE | NSE |
|---|---|---|---|---|---|---|---|---|
| BER-LSTM (Proposed) | 480.53 | 20.82 | 15.25 | 0.73 | 1.36 | 0.83 | 0.06 | 0.61 |
| LSTM | 586.06 | 26.09 | 19.24 | 0.45 | 1.486 | 0.78 | 7.67 | 0.45 |
| BILSTM | 670.69 | 27.83 | 22 | 0.35 | 1.58 | 0.79 | 12.36 | 0.35 |
| GRU | 519.42 | 24.7 | 17.51 | 0.53 | 1.41 | 0.81 | 6.16 | 0.53 |
| LSTMs | 568.07 | 25.75 | 18.23 | 0.47 | 1.47 | 0.74 | 4.49 | 0.47 |
| BILSTMs | 503.24 | 24.34 | 16.72 | 0.55 | 1.39 | 0.81 | 4.12 | 0.55 |
| CONVLSTMs | 571.09 | 25.81 | 18.15 | 0.46 | 1.52 | 0.72 | 2.98 | 0.46 |
| BER-LSTM | PSO-LSTM | GWO-LSTM | GA-LSTM | WOA-LSTM | |
|---|---|---|---|---|---|
| Num. values | 8 | 8 | 8 | 8 | 8 |
| Range | 0 | 1.9 | 1.8 | 2 | 2.3 |
| Maximum | 20.82 | 22.8 | 23.1 | 23.9 | 24.2 |
| Minimum | 20.82 | 20.9 | 21.3 | 21.9 | 21.9 |
| Mean | 20.82 | 21.89 | 22.33 | 22.9 | 23.58 |
| Median | 20.82 | 21.9 | 22.3 | 22.9 | 23.9 |
| Mean std. error | 0 | 0.1797 | 0.179 | 0.189 | 0.2769 |
| Std. dev. | 0 | 0.5083 | 0.5064 | 0.5345 | 0.7833 |
| 25% Percentile | 20.82 | 21.9 | 22.3 | 22.9 | 23.13 |
| 75% Percentile | 20.82 | 21.9 | 22.6 | 22.9 | 24.05 |
| Sum | 166.6 | 175.1 | 178.6 | 183.2 | 188.6 |
| ANOVA Table | SS | DF | MS | F (DFn, DFd) | p Value |
|---|---|---|---|---|---|
| Treatment (between columns) | 34.77 | 4 | 8.694 | F (4, 35) = 30.74 | p < 0.0001 |
| Residual (within columns) | 9.899 | 35 | 0.2828 | - | - |
| Total | 44.67 | 39 | - | - | - |
| p value (two tailed) | 0.0078 | 0.0078 | 0.0078 | 0.0078 |
| Exact or estimate? | Exact | Exact | Exact | Exact |
| Significant (alpha = 0.05)? | Yes | Yes | Yes | Yes |
| PSO-LSTM | GWO-LSTM | GA-LSTM | WOA-LSTM | |
|---|---|---|---|---|
| Gaussian | Ambiguous | Ambiguous | Ambiguous | Ambiguous |
| Best-fit values | ||||
| Amplitude | 21.89 | 22.33 | 22.9 | 23.58 |
| Mean | 20.82 | 20.82 | 20.82 | 20.82 |
| SD | 2.465 | 2.465 | 2.465 | 2.465 |
| 95% CI (profile likelihood) | ||||
| Std | (Very wide) | (Very wide) | (Very wide) | (Very wide) |
| Mean | (Very wide) | (Very wide) | (Very wide) | (Very wide) |
| Goodness of Fit | ||||
| Degrees of Freedom | 5 | 5 | 5 | 5 |
| R squared | 0 | 0 | 0 | 0 |
| Sum of Squares | 1.809 | 1.795 | 2 | 4.295 |
| Sy.x | 0.6015 | 0.5992 | 0.6325 | 0.9268 |
| Constraints | ||||
| SD | SD > 0 | SD > 0 | SD > 0 | SD > 0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Eid, M.M.; El-Kenawy, E.-S.M.; Khodadadi, N.; Mirjalili, S.; Khodadadi, E.; Abotaleb, M.; Alharbi, A.H.; Abdelhamid, A.A.; Ibrahim, A.; Amer, G.M.; et al. Meta-Heuristic Optimization of LSTM-Based Deep Network for Boosting the Prediction of Monkeypox Cases. Mathematics 2022, 10, 3845. https://doi.org/10.3390/math10203845
Eid MM, El-Kenawy E-SM, Khodadadi N, Mirjalili S, Khodadadi E, Abotaleb M, Alharbi AH, Abdelhamid AA, Ibrahim A, Amer GM, et al. Meta-Heuristic Optimization of LSTM-Based Deep Network for Boosting the Prediction of Monkeypox Cases. Mathematics. 2022; 10(20):3845. https://doi.org/10.3390/math10203845
Chicago/Turabian StyleEid, Marwa M., El-Sayed M. El-Kenawy, Nima Khodadadi, Seyedali Mirjalili, Ehsaneh Khodadadi, Mostafa Abotaleb, Amal H. Alharbi, Abdelaziz A. Abdelhamid, Abdelhameed Ibrahim, Ghada M. Amer, and et al. 2022. "Meta-Heuristic Optimization of LSTM-Based Deep Network for Boosting the Prediction of Monkeypox Cases" Mathematics 10, no. 20: 3845. https://doi.org/10.3390/math10203845
APA StyleEid, M. M., El-Kenawy, E.-S. M., Khodadadi, N., Mirjalili, S., Khodadadi, E., Abotaleb, M., Alharbi, A. H., Abdelhamid, A. A., Ibrahim, A., Amer, G. M., Kadi, A., & Khafaga, D. S. (2022). Meta-Heuristic Optimization of LSTM-Based Deep Network for Boosting the Prediction of Monkeypox Cases. Mathematics, 10(20), 3845. https://doi.org/10.3390/math10203845