
Experimental Study of Excessive Local Refinement Reduction Techniques for Global Optimization DIRECT-Type Algorithms


Abstract
1. Introduction
Contributions and Structure
- It reviews the proposed techniques for excessive local refinement reduction for DIRECT-type algorithms.
- It experimentally validates them on one of the fastest two-step Pareto selection based 1-DTC-GL algorithm.
- It accurately assesses the impact of each of them and, based on these results, makes recommendations for DIRECT-type algorithms in general.
- All six of the newly developed DIRECT-type algorithmic variations are freely available to anyone, ensuring complete reproducibility and re-usability of all results.
2. Materials and Methods
2.1. Overview of the DIRECT Algorithm
| Algorithm 1: Main steps of the DIRECT algorithm |
 |
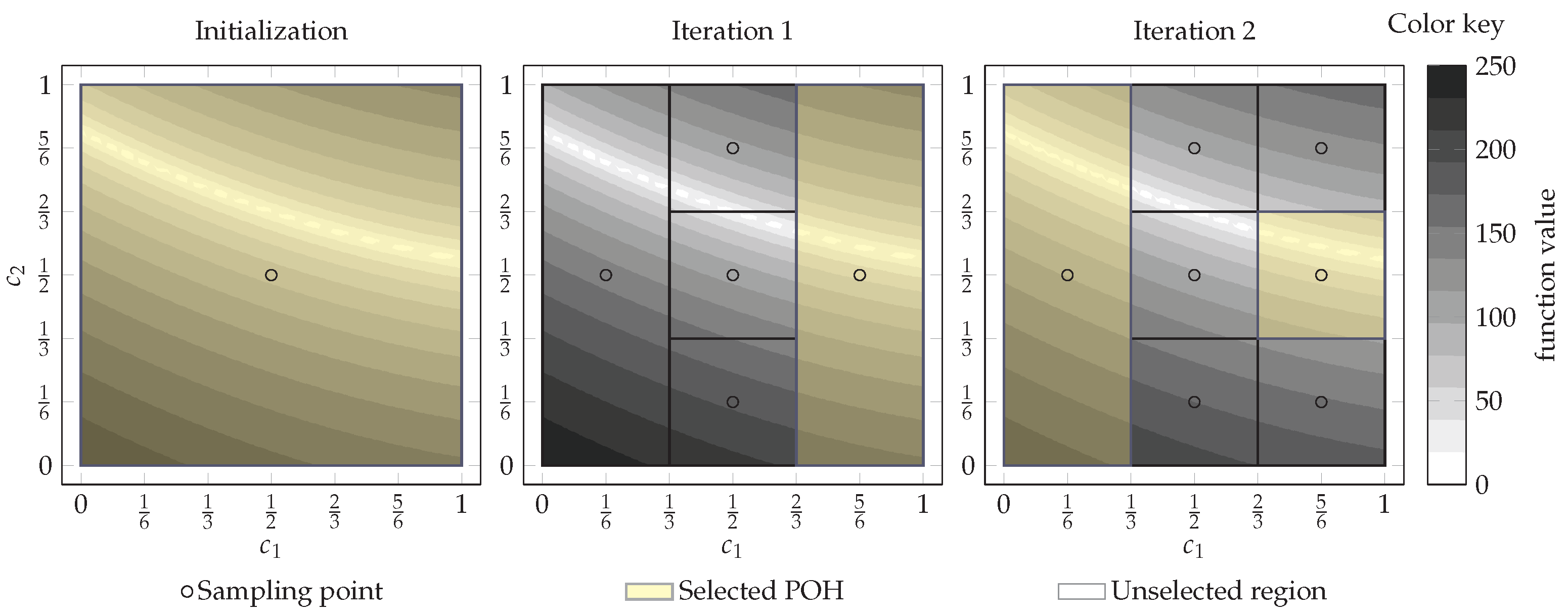
2.2. Two-Step Pareto Selection Based 1-DTC-GL Algorithm
| Algorithm 2: Pareto selection enhancing the global search |
 |
| Algorithm 3: Pareto selection enhancing the local search |
| input: Current partition and related information; output: Set of selected POHs ; |
|
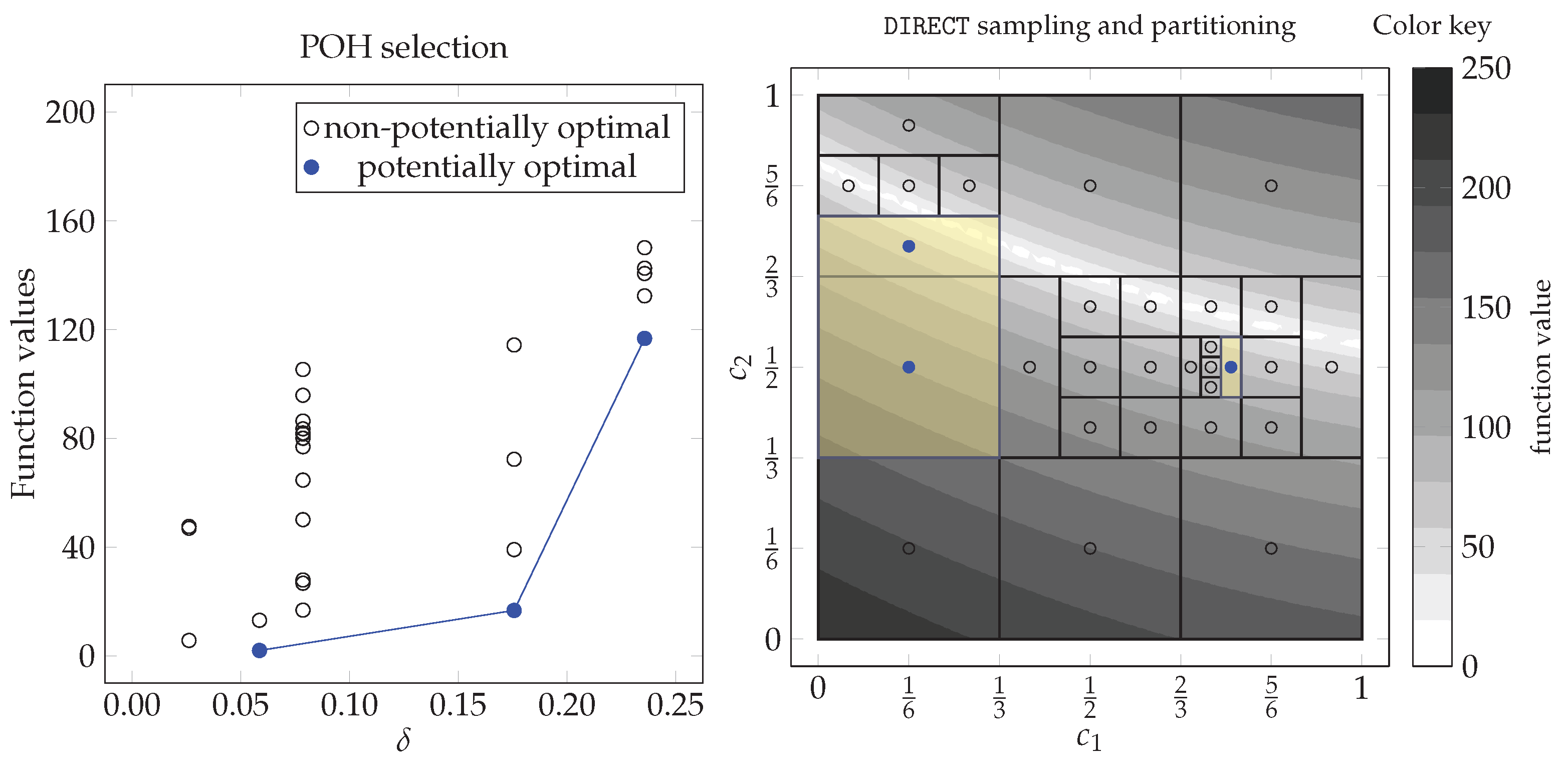
2.3. Review of Excessive Local Refinement Reduction Techniques
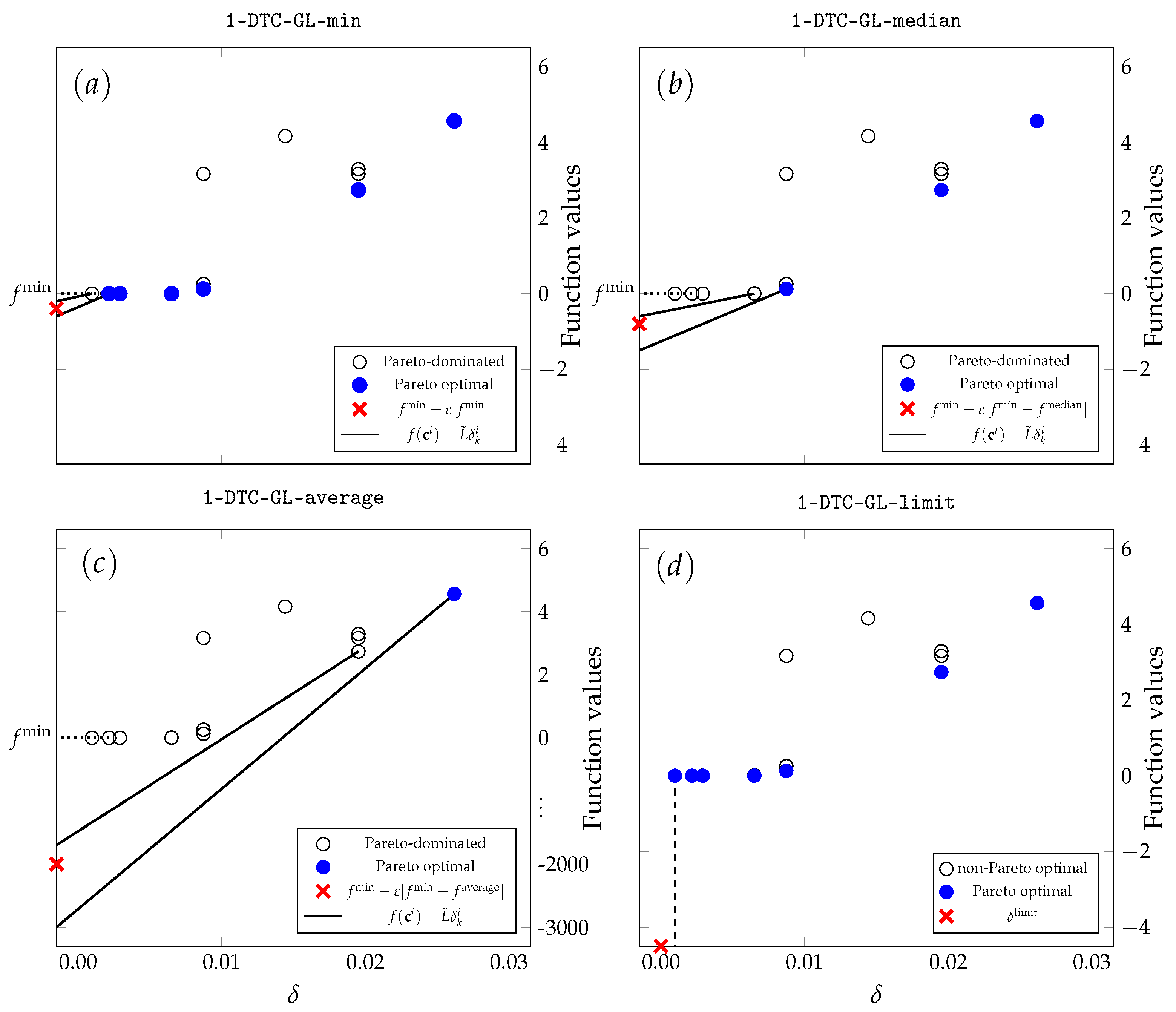
2.3.1. Replacing the Minimum Value with an Average and Median Values
2.3.2. Limiting the Measure of Hyper-Rectangles
2.3.3. Balancing the Local and Global Searches
2.4. New Two-Step Pareto Selection Based Algorithmic Variations for Excessive Local Refinement Reduction
2.4.1. 1-DTC-GL-min Algorithm
2.4.2. 1-DTC-GL-median Algorithm
2.4.3. 1-DTC-GL-average Algorithm
2.4.4. 1-DTC-GL-limit Algorithm
2.4.5. 1-DTC-GL-gb Algorithm
2.4.6. 1-DTC-GL-rev Algorithm
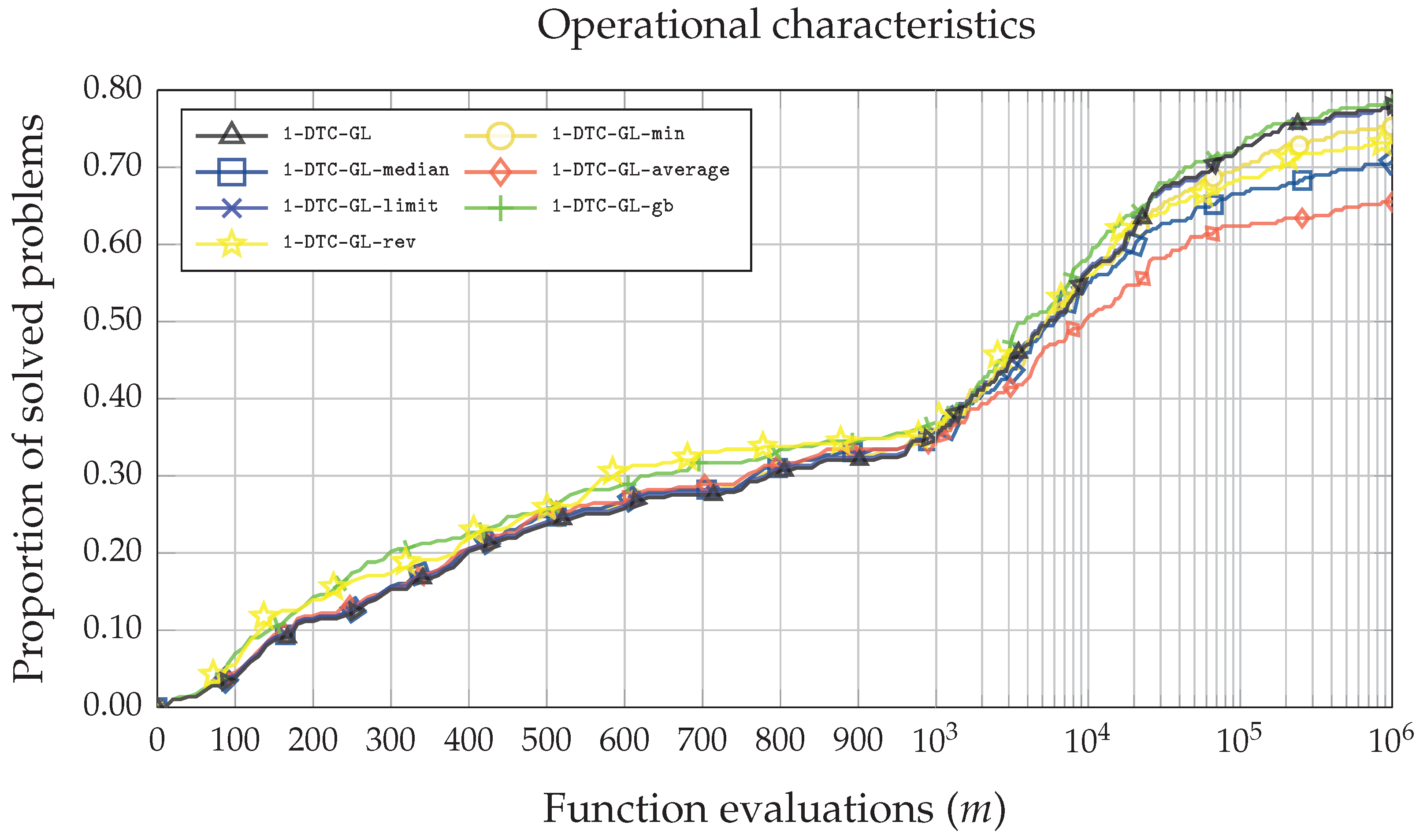
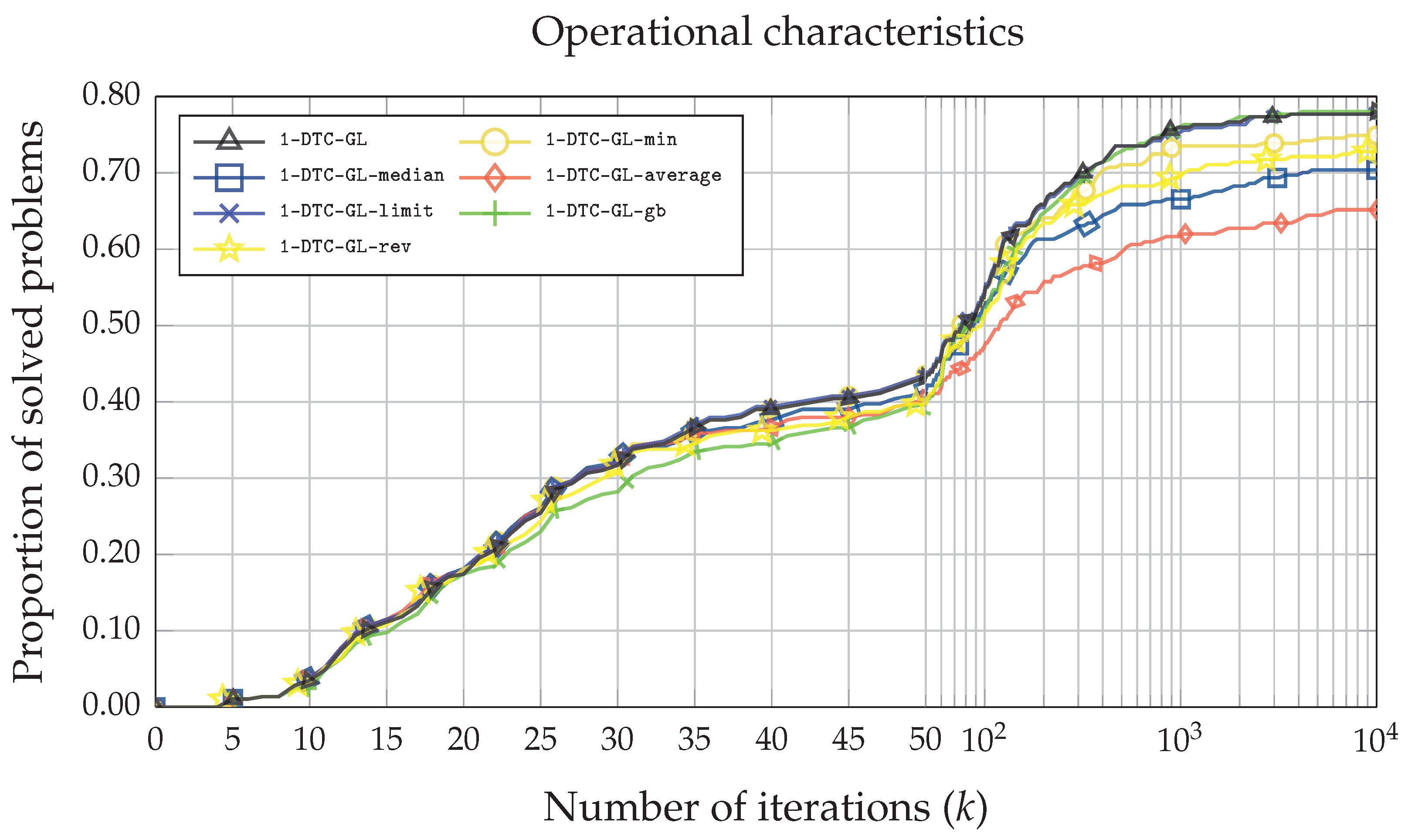
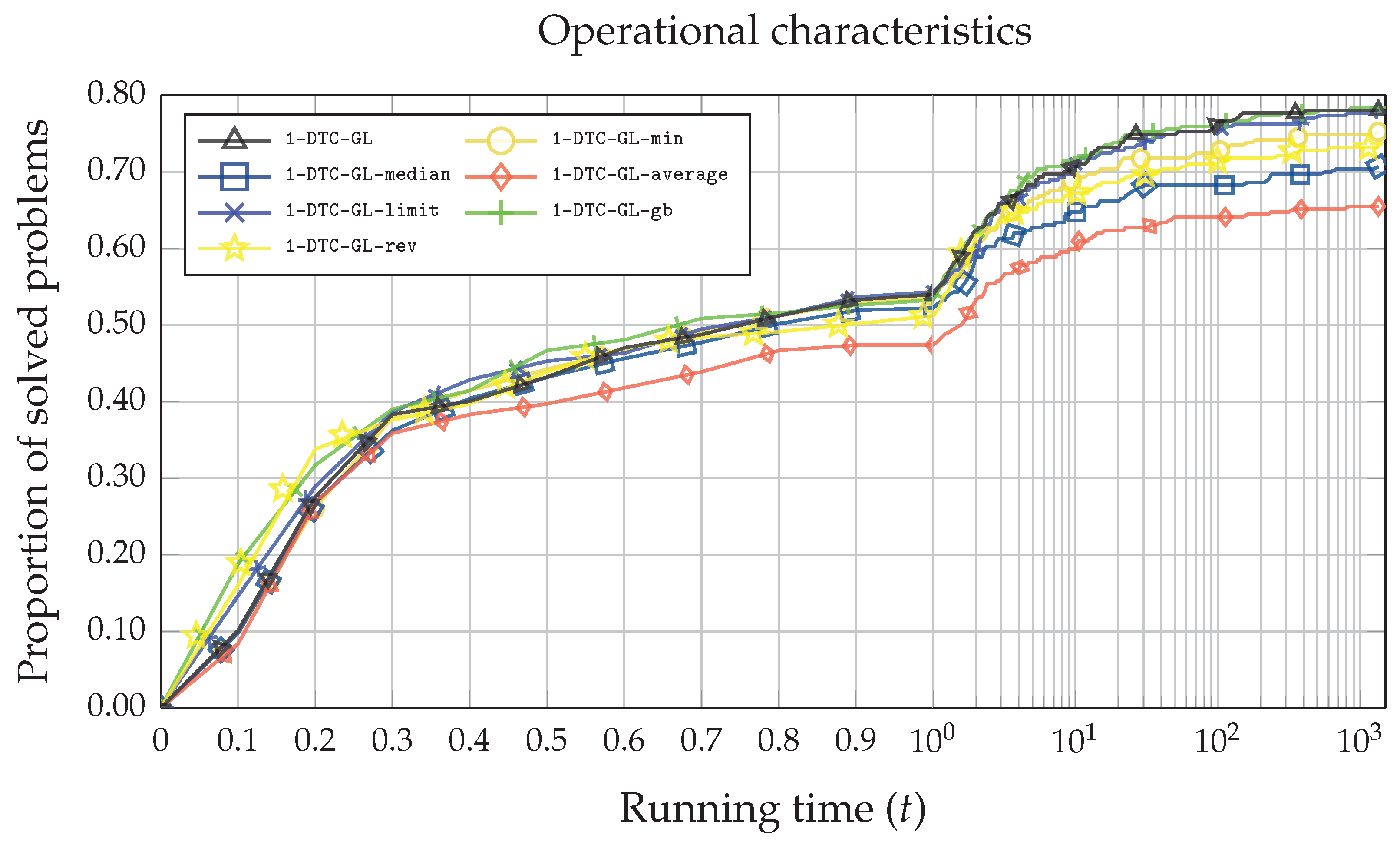
3. Results and Discussions
4. Conclusions and Potential Future Directions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. DIRECTGOLib v1.2 Library

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| # | Name | Source | n | D | Type | No. of Minima | ||
|---|---|---|---|---|---|---|---|---|
| 1 | AckleyN2 | [40] | 2 | uni-modal | convex | |||
| 2 | AckleyN3 | [40] | 2 | uni-modal | convex | |||
| 3 | AckleyN4 | [40] | 2 | non-convex | multi-modal | |||
| 4 | Adjiman | [40] | 2 | - | non-convex | multi-modal | ||
| 5 | BartelsConn | [40] | 2 | non-convex | multi-modal | |||
| 6 | Beale | [41,42] | 2 | - | non-convex | multi-modal | ||
| 7 | BiggsEXP2 | [40] | 2 | - | non-convex | multi-modal | ||
| 8 | BiggsEXP3 | [40] | 3 | - | non-convex | multi-modal | ||
| 9 | BiggsEXP4 | [40] | 4 | - | non-convex | multi-modal | ||
| 10 | BiggsEXP5 | [40] | 5 | - | non-convex | multi-modal | ||
| 11 | BiggsEXP6 | [40] | 6 | - | non-convex | multi-modal | ||
| 12 | Bird | [40] | 2 | - | non-convex | multi-modal | ||
| 13 | Bohachevsky1 | [41,42] | 2 | convex | uni-modal | |||
| 14 | Bohachevsky2 | [41,42] | 2 | non-convex | multi-modal | |||
| 15 | Bohachevsky3 | [41,42] | 2 | non-convex | multi-modal | |||
| 16 | Booth | [41,42] | 2 | - | convex | uni-modal | ||
| 17 | Brad | [40] | 3 | - | non-convex | multi-modal | ||
| 18 | Branin | [41,43] | 2 | - | non-convex | multi-modal | ||
| 19 | Bukin4 | [40] | 2 | - | convex | multi-modal | ||
| 20 | Bukin6 | [42] | 2 | - | convex | multi-modal | ||
| 21 | CarromTable | [44] | 2 | - | non-convex | multi-modal | ||
| 22 | ChenBird | [40] | 2 | - | non-convex | multi-modal | ||
| 23 | ChenV | [40] | 2 | - | non-convex | multi-modal | ||
| 24 | Chichinadze | [40] | 2 | - | non-convex | multi-modal | ||
| 25 | Cola | [40] | 17 | - | non-convex | multi-modal | ||
| 26 | Colville | [41,42] | 4 | - | non-convex | multi-modal | ||
| 27 | Cross_function | [44] | 2 | - | non-convex | multi-modal | ||
| 28 | Cross_in_Tray | [42] | 2 | - | non-convex | multi-modal | ||
| 29 | CrownedCross | [44] | 2 | - | non-convex | multi-modal | ||
| 30 | Crosslegtable | [44] | 2 | - | non-convex | multi-modal | ||
| 31 | Cube | [44] | 2 | - | convex | multi-modal | ||
| 32 | Damavandi | [44] | 2 | - | non-convex | multi-modal | ||
| 33 | Dejong5 | [42] | 2 | - | non-convex | multi-modal | ||
| 34 | Dolan | [40] | 5 | - | non-convex | multi-modal | ||
| 35 | Drop_wave | [42] | 2 | non-convex | multi-modal | |||
| 36 | Easom | [41,42] | 2 | non-convex | multi-modal | |||
| 37 | Eggholder | [42] | 2 | - | non-convex | multi-modal | ||
| 38 | Giunta | [44] | 2 | - | non-convex | multi-modal | ||
| 39 | Goldstein_and _Price | [41,43] | 2 | non-convex | multi-modal | |||
| 40 | Hartman3 | [41,42] | 3 | - | non-convex | multi-modal | ||
| 41 | Hartman4 | [41,42] | 4 | - | non-convex | multi-modal | ||
| 42 | Hartman6 | [41,42] | 6 | - | non-convex | multi-modal | ||
| 43 | HelicalValley | [44] | 3 | - | convex | multi-modal | ||
| 44 | HimmelBlau | [44] | 2 | - | convex | multi-modal | ||
| 45 | Holder_Table | [42] | 2 | - | non-convex | multi-modal | ||
| 46 | Hump | [41,42] | 2 | - | non-convex | multi-modal | ||
| 47 | Langermann | [42] | 2 | - | non-convex | multi-modal | ||
| 48 | Leon | [44] | 2 | - | convex | multi-modal | ||
| 49 | Levi13 | [44] | 2 | - | non-convex | multi-modal | ||
| 50 | Matyas | [41,42] | 2 | convex | uni-modal | |||
| 51 | McCormick | [42] | 2 | - | convex | multi-modal | ||
| 52 | ModSchaffer1 | [45] | 2 | non-convex | multi-modal | |||
| 53 | ModSchaffer2 | [45] | 2 | non-convex | multi-modal | |||
| 54 | ModSchaffer3 | [45] | 2 | non-convex | multi-modal | |||
| 55 | ModSchaffer4 | [45] | 2 | non-convex | multi-modal | |||
| 56 | PenHolder | [41,42] | 2 | - | non-convex | multi-modal | ||
| 57 | Permdb4 | [41,42] | 4 | - | non-convex | multi-modal | ||
| 58 | Powell | [41,42] | 4 | - | convex | multi-modal | ||
| 59 | Power_Sum | [41,42] | 4 | convex | multi-modal | |||
| 60 | Shekel5 | [41,42] | 4 | - | non-convex | multi-modal | ||
| 61 | Shekel7 | [41,42] | 4 | - | non-convex | multi-modal | ||
| 62 | Shekel10 | [41,42] | 4 | - | non-convex | multi-modal | ||
| 63 | Shubert | [41,42] | 2 | - | non-convex | multi-modal | ||
| 64 | TestTubeHolder | [44] | 2 | - | non-convex | multi-modal | ||
| 65 | Trefethen | [44] | 2 | - | non-convex | multi-modal | ||
| 66 | Wood | [45] | 4 | non-convex | multi-modal | |||
| 67 | Zettl | [44] | 2 | - | convex | multi-modal |
| # | Name | Source | D | Type | No. of Minima | ||
|---|---|---|---|---|---|---|---|
| 1 | Ackley | [41,42] | non-convex | multi-modal | |||
| 2 | AlpineN1 | [44] | non-convex | multi-modal | |||
| 3 | Alpine | [44] | non-convex | multi-modal | |||
| 4 | Brown | [40] | - | convex | uni-modal | ||
| 5 | ChungR | [40] | - | convex | uni-modal | ||
| 6 | Csendes | [44] | convex | multi-modal | |||
| 7 | Cubic | [42] | - | convex | uni-modal | ||
| 8 | Deb01 | [44] | non-convex | multi-modal | |||
| 9 | Deb02 | [44] | non-convex | multi-modal | |||
| 10 | Dixon_and_Price | [41,42] | - | convex | multi-modal | ||
| 11 | Dejong | [42] | - | convex | uni-modal | ||
| 12 | Exponential | [40] | - | non-convex | multi-modal | ||
| 13 | Exponential2 | [42] | - | non-convex | multi-modal | ||
| 14 | Exponential3 | [42] | - | non-convex | multi-modal | ||
| 15 | Griewank | [41,42] | non-convex | multi-modal | |||
| 16 | Layeb01 | [46] | convex | uni-modal | |||
| 17 | Layeb02 | [46] | - | convex | uni-modal | ||
| 18 | Layeb03 | [46] | non-convex | multi-modal | |||
| 19 | Layeb04 | [46] | - | non-convex | multi-modal | ||
| 20 | Layeb05 | [46] | - | non-convex | multi-modal | ||
| 21 | Layeb06 | [46] | - | non-convex | multi-modal | ||
| 22 | Layeb07 | [46] | non-convex | multi-modal | |||
| 23 | Layeb08 | [46] | - | non-convex | multi-modal | ||
| 24 | Layeb09 | [46] | - | non-convex | multi-modal | ||
| 25 | Layeb10 | [46] | - | non-convex | multi-modal | ||
| 26 | Layeb11 | [46] | - | non-convex | multi-modal | ||
| 27 | Layeb12 | [46] | - | non-convex | multi-modal | ||
| 28 | Layeb13 | [46] | - | non-convex | multi-modal | ||
| 29 | Layeb14 | [46] | - | non-convex | multi-modal | ||
| 30 | Layeb15 | [46] | - | non-convex | multi-modal | ||
| 31 | Layeb16 | [46] | - | non-convex | multi-modal | ||
| 32 | Layeb17 | [46] | - | non-convex | multi-modal | ||
| 33 | Layeb18 | [46] | - | non-convex | multi-modal | ||
| 34 | Levy | [41,42] | non-convex | multi-modal | |||
| 35 | Michalewicz | [41,42] | - | non-convex | multi-modal | ||
| 36 | Pinter | [44] | non-convex | multi-modal | |||
| 37 | Qing | [44] | - | non-convex | multi-modal | ||
| 38 | Quadratic | [42] | - | convex | uni-modal | ||
| 39 | Rastrigin | [41,42] | non-convex | multi-modal | |||
| 40 | Rosenbrock | [41,43] | non-convex | uni-modal | |||
| 41 | Rotated_H_Ellip | [42] | convex | uni-modal | |||
| 42 | Schwefel | [41,42] | non-convex | multi-modal | |||
| 43 | SineEnvelope | [44] | - | non-convex | multi-modal | ||
| 44 | Sinenvsin | [45] | non-convex | multi-modal | |||
| 45 | Sphere | [41,42] | convex | uni-modal | |||
| 46 | Styblinski_Tang | [47] | non-convex | multi-modal | |||
| 47 | Sum_Squares | [47] | convex | uni-modal | |||
| 48 | Sum_Of_Powers | [42] | convex | uni-modal | |||
| 49 | Trid | [41,42] | - | convex | multi-modal | ||
| 50 | Trigonometric | [41,42] | non-convex | multi-modal | |||
| 51 | Vincent | [47] | - | non-convex | multi-modal | ||
| 52 | WWavy | [40] | non-convex | multi-modal | |||
| 53 | XinSheYajngN1 | [40] | non-convex | multi-modal | |||
| 54 | XinSheYajngN2 | [40] | non-convex | multi-modal | |||
| 55 | Zakharov | [41,42] | convex | multi-modal |
References
- Sergeyev, Y.D.; Kvasov, D.E.; Mukhametzhanov, M.S. On the efficiency of nature-inspired metaheuristics in expensive global optimization with limited budget. Sci. Rep. 2018, 8, 453. [Google Scholar] [CrossRef] [PubMed]
- Lee, C.Y.; Zhuo, G.L. A Hybrid Whale Optimization Algorithm for Global Optimization. Mathematics 2021, 9, 1477. [Google Scholar] [CrossRef]
- Al-Shaikh, A.; Mahafzah, B.A.; Alshraideh, M. Hybrid harmony search algorithm for social network contact tracing of COVID-19. Soft Comput. 2021, 1–23. [Google Scholar] [CrossRef] [PubMed]
- Zhigljavsky, A.; Žilinskas, A. Stochastic Global Optimization; Springer: New York, NY, USA, 2008. [Google Scholar]
- Horst, R.; Pardalos, P.M.; Thoai, N.V. Introduction to Global Optimization; Nonconvex Optimization and Its Application; Kluwer Academic Publishers: Berlin, Germany, 1995. [Google Scholar]
- Sergeyev, Y.D.; Kvasov, D.E. Deterministic Global Optimization: An Introduction to the Diagonal Approach; SpringerBriefs in Optimization; Springer: Berlin, Germany, 2017. [Google Scholar] [CrossRef]
- Jones, D.R.; Perttunen, C.D.; Stuckman, B.E. Lipschitzian Optimization Without the Lipschitz Constant. J. Optim. Theory Appl. 1993, 79, 157–181. [Google Scholar] [CrossRef]
- Carter, R.G.; Gablonsky, J.M.; Patrick, A.; Kelley, C.T.; Eslinger, O.J. Algorithms for noisy problems in gas transmission pipeline optimization. Optim. Eng. 2001, 2, 139–157. [Google Scholar] [CrossRef]
- Cox, S.E.; Haftka, R.T.; Baker, C.A.; Grossman, B.; Mason, W.H.; Watson, L.T. A Comparison of Global Optimization Methods for the Design of a High-speed Civil Transport. J. Glob. Optim. 2001, 21, 415–432. [Google Scholar] [CrossRef]
- Paulavičius, R.; Sergeyev, Y.D.; Kvasov, D.E.; Žilinskas, J. Globally-biased BIRECT algorithm with local accelerators for expensive global optimization. Expert Syst. Appl. 2020, 144, 11305. [Google Scholar] [CrossRef]
- Paulavičius, R.; Žilinskas, J. Simplicial Global Optimization; SpringerBriefs in Optimization; Springer: New York, NY, USA, 2014. [Google Scholar] [CrossRef]
- Stripinis, L.; Paulavičius, R.; Žilinskas, J. Penalty functions and two-step selection procedure based DIRECT-type algorithm for constrained global optimization. Struct. Multidiscip. Optim. 2019, 59, 2155–2175. [Google Scholar] [CrossRef]
- Paulavičius, R.; Žilinskas, J. Analysis of different norms and corresponding Lipschitz constants for global optimization. Technol. Econ. Dev. Econ. 2006, 36, 383–387. [Google Scholar] [CrossRef]
- Piyavskii, S.A. An algorithm for finding the absolute minimum of a function. Theory Optim. Solut. 1967, 2, 13–24. (In Russian) [Google Scholar] [CrossRef]
- Sergeyev, Y.D.; Kvasov, D.E. Lipschitz global optimization. In Wiley Encyclopedia of Operations Research and Management Science (in 8 volumes); Cochran, J.J., Cox, L.A., Keskinocak, P., Kharoufeh, J.P., Smith, J.C., Eds.; John Wiley & Sons: New York, NY, USA, 2011; Volume 4, pp. 2812–2828. [Google Scholar]
- Rios, L.M.; Sahinidis, N.V. Derivative-free optimization: A review of algorithms and comparison of software implementations. J. Glob. Optim. 2007, 56, 1247–1293. [Google Scholar] [CrossRef]
- Stripinis, L.; Paulavičius, R. DIRECTGO: A New DIRECT-Type MATLAB Toolbox for Derivative-Free Global Optimization. ACM Trans. Math. Softw. 2022, 1–45. [Google Scholar] [CrossRef]
- Jones, D.R. The Direct Global Optimization Algorithm. In The Encyclopedia of Optimization; Floudas, C.A., Pardalos, P.M., Eds.; Kluwer Academic Publishers: Dordrect, The Netherlands, 2001; pp. 431–440. [Google Scholar]
- Holmstrom, K.; Goran, A.O.; Edvall, M.M. User’s Guide for TOMLAB 7. 2010. Available online: https://tomopt.com/docs/TOMLAB.pdf (accessed on 15 November 2021).
- Stripinis, L.; Paulavičius, R. An extensive numerical benchmark study of deterministic vs. stochastic derivative-free global optimization algorithms. arXiv 2022, arXiv:2209.05759. [Google Scholar] [CrossRef]
- Stripinis, L.; Paulavičius, R. An empirical study of various candidate selection and partitioning techniques in the DIRECT framework. J. Glob. Optim. 2022, 1–31. [Google Scholar] [CrossRef]
- Jones, D.R.; Martins, J.R.R.A. The DIRECT algorithm: 25 years later. J. Glob. Optim. 2021, 79, 521–566. [Google Scholar] [CrossRef]
- Finkel, D.E.; Kelley, C.T. Additive scaling and the DIRECT algorithm. J. Glob. Optim. 2006, 36, 597–608. [Google Scholar] [CrossRef]
- Finkel, D.; Kelley, C. An Adaptive Restart Implementation of DIRECT; Technical Report CRSC-TR04-30; Center for Research in Scientific Computation, North Carolina State University: Raleigh, NC, USA, 2004; pp. 1–16. [Google Scholar]
- Liu, Q. Linear scaling and the DIRECT algorithm. J. Glob. Optim. 2013, 56, 1233–1245. [Google Scholar] [CrossRef]
- Liu, Q.; Zeng, J.; Yang, G. MrDIRECT: A multilevel robust DIRECT algorithm for global optimization problems. J. Glob. Optim. 2015, 62, 205–227. [Google Scholar] [CrossRef]
- Sergeyev, Y.D.; Kvasov, D.E. Global search based on diagonal partitions and a set of Lipschitz constants. SIAM J. Optim. 2006, 16, 910–937. [Google Scholar] [CrossRef]
- Paulavičius, R.; Sergeyev, Y.D.; Kvasov, D.E.; Žilinskas, J. Globally-biased DISIMPL algorithm for expensive global optimization. J. Glob. Optim. 2014, 59, 545–567. [Google Scholar] [CrossRef]
- Stripinis, L.; Paulavičius, R.; Žilinskas, J. Improved scheme for selection of potentially optimal hyper-rectangles in DIRECT. Optim. Lett. 2018, 12, 1699–1712. [Google Scholar] [CrossRef]
- De Corte, W.; Sackett, P.R.; Lievens, F. Designing pareto-optimal selection systems: Formalizing the decisions required for selection system development. J. Appl. Psychol. 2011, 96, 907–926. [Google Scholar] [CrossRef]
- Liu, Q.; Cheng, W. A modified DIRECT algorithm with bilevel partition. J. Glob. Optim. 2014, 60, 483–499. [Google Scholar] [CrossRef]
- Liu, H.; Xu, S.; Wang, X.; Wu, X.; Song, Y. A global optimization algorithm for simulation-based problems via the extended DIRECT scheme. Eng. Optim. 2015, 47, 1441–1458. [Google Scholar] [CrossRef]
- Baker, C.A.; Watson, L.T.; Grossman, B.; Mason, W.H.; Haftka, R.T. Parallel Global Aircraft Configuration Design Space Exploration. In Practical Parallel Computing; Nova Science Publishers, Inc.: Hauppauge, NY, USA, 2001; pp. 79–96. [Google Scholar]
- He, J.; Verstak, A.; Watson, L.T.; Sosonkina, M. Design and implementation of a massively parallel version of DIRECT. Comput. Optim. Appl. 2008, 40, 217–245. [Google Scholar] [CrossRef]
- Stripinis, L.; Paulavičius, R. DIRECTGOLib—DIRECT Global Optimization Test Problems Library, Version v1.2, GitHub. 2022. Available online: https://github.com/blockchain-group/DIRECTGOLib/tree/v1.2 (accessed on 10 July 2022).
- Grishagin, V.A. Operating characteristics of some global search algorithms. In Problems of Stochastic Search; Zinatne: Riga, Latvia, 1978; Volume 7, pp. 198–206. (In Russian) [Google Scholar]
- Strongin, R.G.; Sergeyev, Y.D. Global Optimization with Non-Convex Constraints: Sequential and Parallel Algorithms; Kluwer Academic Publishers: Dordrecht, The Netherlands, 2000. [Google Scholar]
- Jusevičius, V.; Oberdieck, R.; Paulavičius, R. Experimental Analysis of Algebraic Modelling Languages for Mathematical Optimization. Informatica 2021, 32, 283–304. [Google Scholar] [CrossRef]
- Jusevičius, V.; Paulavičius, R. Web-Based Tool for Algebraic Modeling and Mathematical Optimization. Mathematics 2021, 9, 2751. [Google Scholar] [CrossRef]
- Jamil, M.; Yang, X.S. A literature survey of benchmark functions for global optimisation problems. Int. J. Math. Model. Numer. Optim. 2013, 4, 150–194. [Google Scholar] [CrossRef]
- Hedar, A. Test Functions for Unconstrained Global Optimization. 2005. Available online: http://www-optima.amp.i.kyoto-u.ac.jp/member/student/hedar/Hedar_files/TestGO.htm (accessed on 22 March 2017).
- Surjanovic, S.; Bingham, D. Virtual Library of Simulation Experiments: Test Functions and Datasets. 2013. Available online: http://www.sfu.ca/~ssurjano/index.html (accessed on 22 March 2017).
- Dixon, L.; Szegö, C. The Global Optimisation Problem: An Introduction. In Towards Global Optimization; Dixon, L., Szegö, G., Eds.; North-Holland Publishing Company: Amsterdam, The Netherlands, 1978; Volume 2, pp. 1–15. [Google Scholar]
- Gavana, A. Global Optimization Benchmarks and AMPGO. Available online: http://infinity77.net/global_optimization/index.html (accessed on 22 July 2021).
- Mishra, S.K. Some New Test Functions for Global Optimization and Performance of Repulsive Particle Swarm Method. 2006. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=926132 (accessed on 23 August 2006). [CrossRef]
- Abdesslem, L. New hard benchmark functions for global optimization. arXiv 2022, arXiv:2202.04606. [Google Scholar]
- Clerc, M. The swarm and the queen: Towards a deterministic and adaptive particle swarm optimization. In Proceedings of the 1999 Congress on Evolutionary Computation-CEC99 (Cat. No. 99TH8406), Washington, DC, USA, 6–9 July 1999; Volume 3, pp. 1951–1957. [Google Scholar] [CrossRef]






| Problems | Overall | Convex | Non-Convex | Uni-Modal | Multi-Modal | ||||
|---|---|---|---|---|---|---|---|---|---|
| # of cases | 287 | 174 | 113 | 69 | 218 | 53 | 234 | 181 | 106 |
| Algorithm | Criteria | Average | Median | Success Rate | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Overall | Convex | Non-Convex | Uni-Modal | Multi-Modal | ||||||||
| 1-DTC-GL | 244135 | 77155 | 501255 | 81666 | 295559 | 74085 | 282651 | 252345 | 230325 | 5515 | ||
| 901 | 297 | 1831 | 233 | 1113 | 198 | 1060 | 512 | 1555 | 76 | |||
| 1-DTC-GL-min | 267833 | 123235 | 490489 | 82747 | 326416 | 74774 | 311560 | 266234 | 270524 | 5411 | ||
| 2119 | 1372 | 3268 | 362 | 2675 | 293 | 2532 | 1335 | 3438 | 75 | |||
| 1-DTC-GL-median | 313159 | 138673 | 581836 | 124182 | 372973 | 126666 | 355399 | 337280 | 272582 | 6003 | ||
| 2594 | 1659 | 4035 | 561 | 3238 | 572 | 3052 | 2062 | 3490 | 88 | |||
| 1-DTC-GL-average | 361511 | 180635 | 640029 | 169850 | 422175 | 180637 | 402479 | 404591 | 289041 | 9483 | ||
| 3804 | 3179 | 4765 | 561 | 1456 | 1653 | 4291 | 3462 | 4379 | 120 | |||
| 1-DTC-GL-limit | 262205 | 106080 | 502608 | 92052 | 316060 | 74085 | 304813 | 271809 | 246047 | 5411 | ||
| 1123 | 633 | 1877 | 357 | 1365 | 228 | 1325 | 742 | 1764 | 75 | |||
| 1-DTC-GL-gb | 237783 | 69758 | 496513 | 84037 | 286446 | 71725 | 275395 | 253218 | 211818 | 3871 | ||
| 998 | 323 | 2037 | 288 | 1223 | 215 | 1175 | 609 | 1651 | 80 | |||
| 1-DTC-GL-rev | 286942 | 136047 | 519293 | 85872 | 350583 | 70626 | 335936 | 286353 | 287931 | 5329 | ||
| 1694 | 936 | 2861 | 323 | 2128 | 250 | 2021 | 1019 | 2828 | 95 | |||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Stripinis, L.; Paulavičius, R. Experimental Study of Excessive Local Refinement Reduction Techniques for Global Optimization DIRECT-Type Algorithms. Mathematics 2022, 10, 3760. https://doi.org/10.3390/math10203760
Stripinis L, Paulavičius R. Experimental Study of Excessive Local Refinement Reduction Techniques for Global Optimization DIRECT-Type Algorithms. Mathematics. 2022; 10(20):3760. https://doi.org/10.3390/math10203760
Chicago/Turabian StyleStripinis, Linas, and Remigijus Paulavičius. 2022. "Experimental Study of Excessive Local Refinement Reduction Techniques for Global Optimization DIRECT-Type Algorithms" Mathematics 10, no. 20: 3760. https://doi.org/10.3390/math10203760
APA StyleStripinis, L., & Paulavičius, R. (2022). Experimental Study of Excessive Local Refinement Reduction Techniques for Global Optimization DIRECT-Type Algorithms. Mathematics, 10(20), 3760. https://doi.org/10.3390/math10203760