
Expect: EXplainable Prediction Model for Energy ConsumpTion


Abstract
:1. Introduction
2. Scrutiny of the Related Work
2.1. Standalone Models
2.1.1. Statistical Techniques
2.1.2. Machine Learning Techniques
2.1.3. Deep Learning Techniques
2.2. Hybrid Approaches
2.3. Discussion
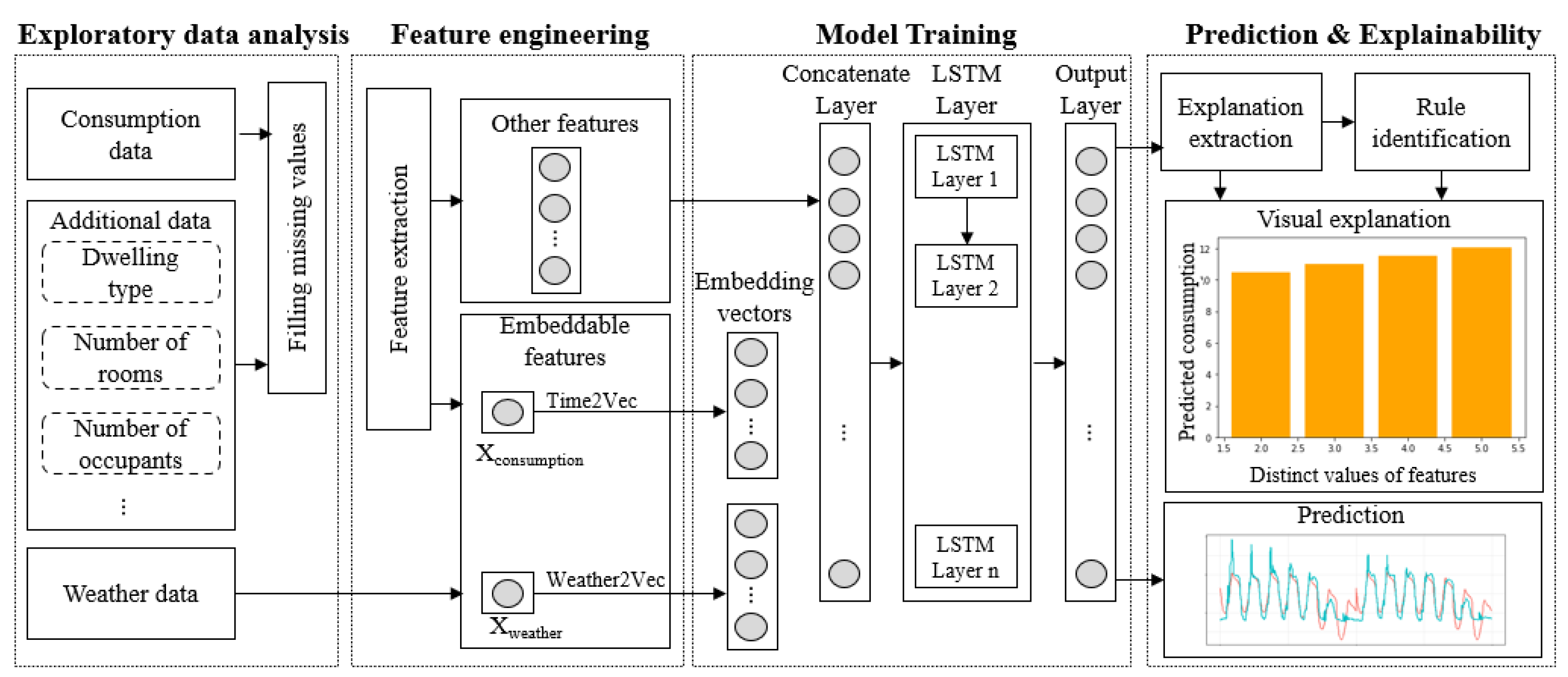
3. Expect: EXplainable Prediction Model for Energy ConsumpTion Framework
3.1. Exploratory Data Analysis
- Consumption data: Historical half-hourly energy readings for 3248 smart meters having a different range of months’ worth of consumption. The available data for a given (fully anonymized) meter_id may cover only one month or more during the year.
- Additional data: Some collected additional information was made available for a subset of the smart meters. Indeed, only 1859 out of 3248 contain some additional information, including: (a) categorical variables: dwelling type for 1702 smart meters, heating fuel for 78 smart meters, hot water fuel for 76 smart meters, boiler age for 74 smart meters, etc.; and (b) numerical variables: number of occupants for 74 smart meters, number of bedrooms for 1859 smart meters, etc.
- Weather data: Daily temperature associated with 3248 smart meters, including the average, minimum, and maximum temperature values, respectively. The location and the postcode/zip code were anonymized for privacy issues.
| Algorithm 1: Filling missing data for consumption. |
 |
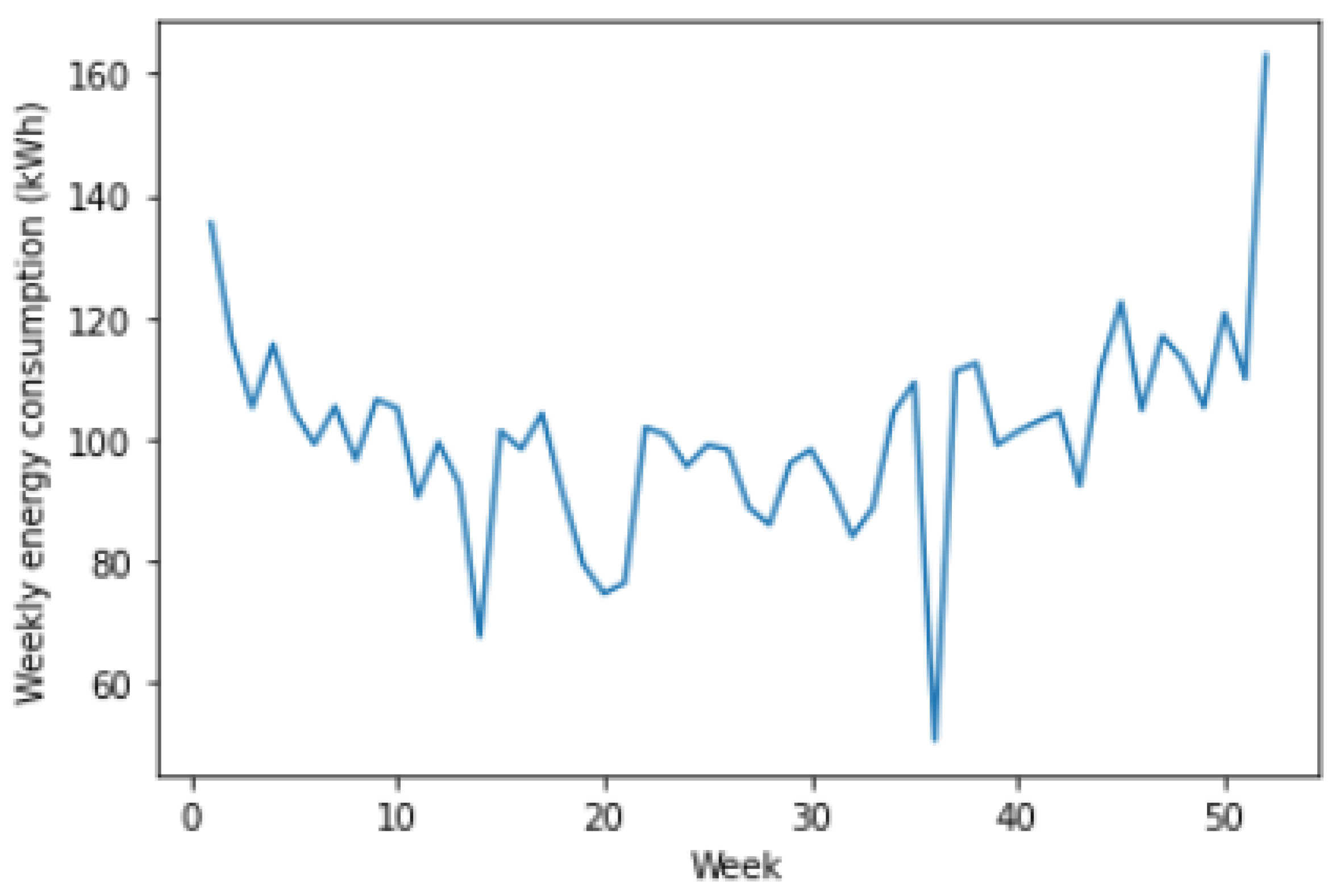
- Season 1: This is defined from January to the end of March (beginning of April). This season is flagging out gradually, decreasing energy consumption;
- Season 2: It runs from April to June (beginning of July). During this season, energy consumption tends to decrease. The shape of the plot indicates a decrease in energy consumption starting from May to June. In addition, the temperature in this season tends to increase;
- Season 3: It goes from July to September (beginning of October). We identify frequent but more minor energy variations during this season compared to season 2, growing as temperature increases;
- Season 4: It covers October to the end of December. Frequent and large energy fluctuations characterize it, with relatively large mean consumption. As a rule of thumb, the temperature is decreasing in this season.
| Algorithm 2: Seasonal_Filling (, M). |
 |
| Algorithm 3:Customized_Filling (, A, M). |
 |
| Algorithm 4: Distance for additional information. |
 |
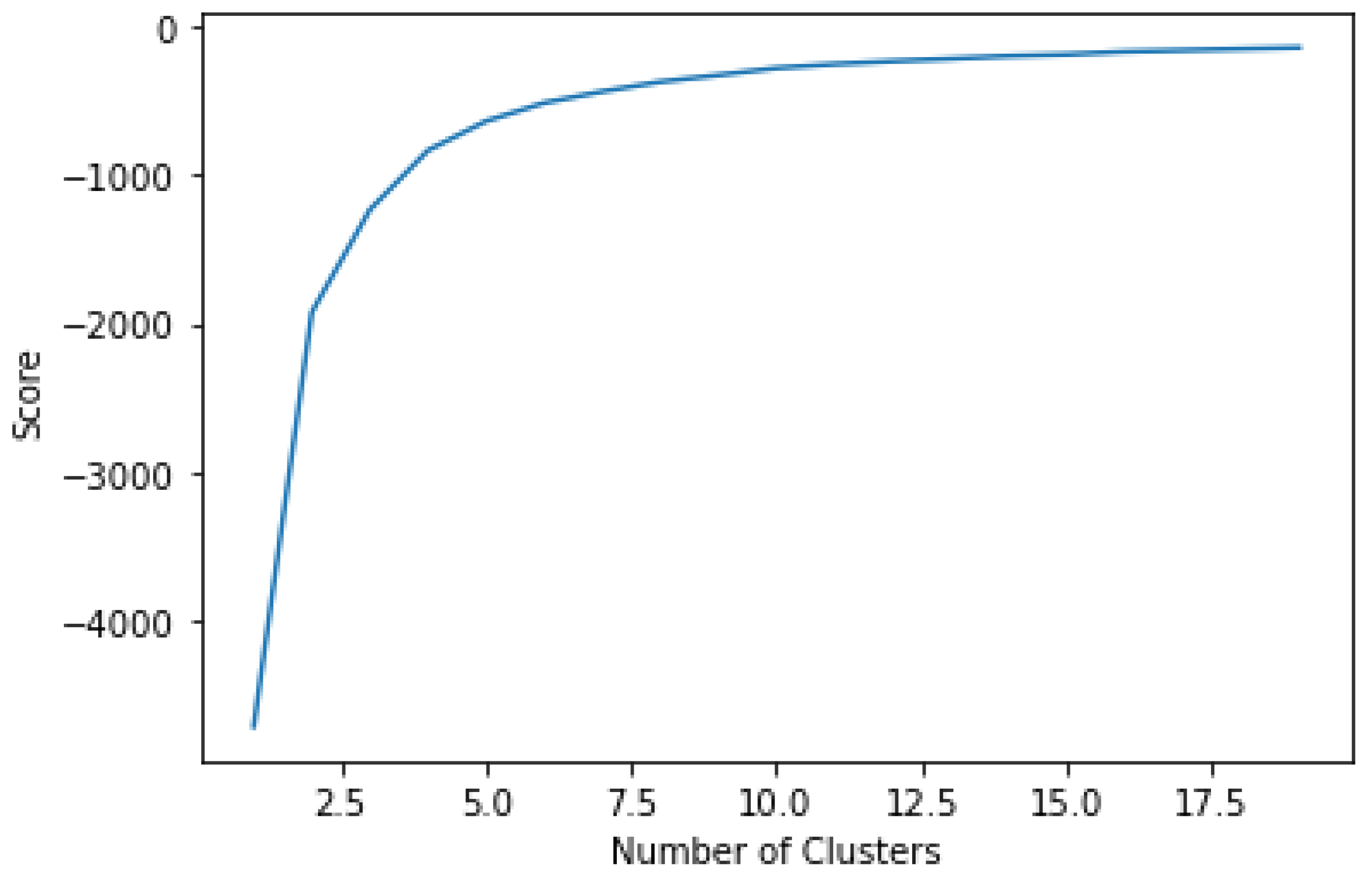
| Algorithm 5: Clustering for additional information. |
 |
3.2. Feature Engineering
3.3. Training the Model
Embedding
3.4. Prediction & Explainability
3.4.1. Prediction
3.4.2. Explainability
| Algorithm 6: Computing the PDP values. |
 |
4. Experimental Results
4.1. Evaluation Metrics
4.2. Results and Discussion
4.3. Explaining the Prediction
5. Conclusions and Future Work
- Incremental learning of the predictive model: The steady ingestion of the low data on energy consumption sent out by smart meters is heading us towards the proposal of new incremental predictions that, in lieu of departing from scratch, will seed the already existing model;
- New explainability model for heterogeneous model: The predictive model that we developed has unveiled a compelling new framework, that, unlike the existing ones, would be able to work alongside our efficient prediction model. The new explainability framework would address global and local explainabilty views. In addition, we plan to improve this part of the proposed framework; now the user can interpret the provided graphic to explain why it would have such a prediction, that is, extract automatically predictive rules that can explain the provided prediction;
- Development of a personalized “trustworthy” virtual coach for energy consumption: The latter’s aim is to engage customers with personalized, actionable advice to improve their consumption and increase their satisfaction. This virtual coach aims to provide tailored advice, alerts and recommendations by learning every household consumption behavior.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kumar, A.; Shankar, R.; Aljohani, N.R. A big data driven framework for demand-driven forecasting with effects of marketing-mix variables. Ind. Mark. Manag. 2020, 90, 493–507. [Google Scholar] [CrossRef]
- Sezer, O.B.; Gudelek, M.U.; Ozbayoglu, A.M. Financial time series forecasting with deep learning: A systematic literature review: 2005–2019. Appl. Soft Comput. 2020, 90, 106181. [Google Scholar] [CrossRef] [Green Version]
- Deb, C.; Zhang, F.; Yang, J.; Lee, S.E.; Shah, K.W. A review on time series forecasting techniques for building energy consumption. Renew. Sustain. Energy Rev. 2017, 74, 902–924. [Google Scholar] [CrossRef]
- Chujai, P.; Kerdprasop, N.; Kerdprasop, K. Time Series Analysis of Household Electric Consumption with ARIMA and ARMA Models. In Proceedings of the International MultiConference of Engineers and Computer Scientists, IMECS 2013, Hong Kong, China, 13–15 March 2013; Volume I. [Google Scholar]
- Fumo, N.; Rafe Biswas, M. Regression analysis for prediction of residential energy consumption. Renew. Sustain. Energy Rev. 2015, 47, 332–343. [Google Scholar] [CrossRef]
- Beccali, M.; Ciulla, G.; Lo Brano, V.; Galatioto, A.; Bonomolo, M. Artificial neural network decision support tool for assessment of the energy performance and the refurbishment actions for the non-residential building stock in Southern Italy. Energy 2017, 137, 1201–1218. [Google Scholar] [CrossRef]
- Kong, W.; Dong, Z.Y.; Jia, Y.; Hill, D.J.; Xu, Y.; Zhang, Y. Short-Term Residential Load Forecasting Based on LSTM Recurrent Neural Network. IEEE Trans. Smart Grid 2019, 10, 841–851. [Google Scholar] [CrossRef]
- Zhong, H.; Wang, J.; Jia, H.; Mu, Y.; Lv, S. Vector field-based support vector regression for building energy consumption prediction. Appl. Energy 2019, 242, 403–414. [Google Scholar] [CrossRef]
- Abbasi, R.A.; Javaid, N.; Ghuman, M.N.J.; Khan, Z.A.; Ur Rehman, S.; Amanullah. Short Term Load Forecasting Using XGBoost. In Web, Artificial Intelligence and Network Applications; Barolli, L., Takizawa, M., Xhafa, F., Enokido, T., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 1120–1131. [Google Scholar]
- Kim, J.Y.; Cho, S.B. Electric Energy Consumption Prediction by Deep Learning with State Explainable Autoencoder. Energies 2019, 12, 739. [Google Scholar] [CrossRef] [Green Version]
- Khandelwal, I.; Adhikari, R.; Verma, G. Time Series Forecasting Using Hybrid ARIMA and ANN Models Based on DWT Decomposition. Procedia Comput. Sci. 2015, 48, 173–179. [Google Scholar] [CrossRef] [Green Version]
- Kim, T.Y.; Cho, S.B. Predicting residential energy consumption using CNN-LSTM neural networks. Energy 2019, 182, 72–81. [Google Scholar] [CrossRef]
- Jallal, M.A.; González-Vidal, A.; Skarmeta, A.F.; Chabaa, S.; Zeroual, A. A hybrid neuro-fuzzy inference system-based algorithm for time series forecasting applied to energy consumption prediction. Appl. Energy 2020, 268, 114977. [Google Scholar] [CrossRef]
- Kao, Y.S.; Nawata, K.; Huang, C.Y. Predicting Primary Energy Consumption Using Hybrid ARIMA and GA-SVR Based on EEMD Decomposition. Mathematics 2020, 8, 1722. [Google Scholar] [CrossRef]
- Yucong, W.; Bo, W. Research on EA-Xgboost Hybrid Model for Building Energy Prediction. J. Phys. Conf. Ser. 2020, 1518, 012082. [Google Scholar] [CrossRef]
- Ilic, I.; Görgülü, B.; Cevik, M.; Baydogan, M.G. Explainable boosted linear regression for time series forecasting. Pattern Recognit. 2021, 120, 108144. [Google Scholar] [CrossRef]
- Zhang, B.; Zhao, C. Dynamic turning force prediction and feature parameters extraction of machine tool based on ARMA and HHT. Proc. Inst. Mech. Eng. Part C J. Mech. Eng. Sci. 2020, 234, 1044–1056. [Google Scholar] [CrossRef]
- Mehedintu, A.; Sterpu, M.; Soava, G. Estimation and Forecasts for the Share of Renewable Energy Consumption in Final Energy Consumption by 2020 in the European Union. Sustainability 2018, 10, 1515. [Google Scholar] [CrossRef] [Green Version]
- Aslam, S.; Herodotou, H.; Mohsin, S.M.; Javaid, N.; Ashraf, N.; Aslam, S. A survey on deep learning methods for power load and renewable energy forecasting in smart microgrids. Renew. Sustain. Energy Rev. 2021, 144, 110992. [Google Scholar] [CrossRef]
- Alanbar, M.; Alfarraj, A.; Alghieth, M. Energy Consumption Prediction Using Deep Learning Technique. Int. J. Interact. Mob. Technol. 2020, 14, 166–177. [Google Scholar] [CrossRef]
- Debnath, K.B.; Mourshed, M. Forecasting methods in energy planning models. Renew. Sustain. Energy Rev. 2018, 88, 297–325. [Google Scholar] [CrossRef] [Green Version]
- Triguero, I. FUZZ-IEEE Competition on Explainable Energy Prediction. 2020. Available online: https://ieee-dataport.org/competitions/fuzz-ieee-competition-explainable-energy-prediction (accessed on 17 November 2021).
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Kazemi, S.M.; Goel, R.; Eghbali, S.; Ramanan, J.; Sahota, J.; Thakur, S.; Wu, S.; Smyth, C.; Poupart, P.; Brubaker, M. Time2Vec: Learning a Vector Representation of Time. arXiv 2019, arXiv:1907.05321. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why Should I Trust You?”: Explaining the Predictions of Any Classifier. arXiv 2016, arXiv:1602. [Google Scholar]
- Lundberg, S.; Lee, S.I. A unified approach to interpreting model predictions. arXiv 2017, arXiv:1705.07874. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Abbreviation | Full form |
|---|---|
| AE | AutoEncoder |
| ARIMA | AutoRegressive Integrated Moving Average |
| ARMA | Autoregressive Moving Average |
| ANN | Artificial Neural Network |
| CNN | Convolutional Neural Network |
| EA | Evolutionary Algorithm |
| LR | Linear Regression |
| LSTM | Long Short-Term Memory |
| RT | Regression Tree |
| SVR | Support Vector Regression |
| XGboost | eXtreme Gradient Boosting |
| Category | Reference | XAI | Statistical Techniques | Machine Learning Techniques | Deep Learning Techniques | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| LR | ARMA | ARIMA | ANN | XGBoost | SVR | EA | RT | CNN | LSTM | AE | |||
| Standalone | [4] | No | × | × | |||||||||
| [5] | No | × | |||||||||||
| [6] | No | × | |||||||||||
| [7] | No | × | |||||||||||
| [8] | No | × | |||||||||||
| [9] | No | × | |||||||||||
| [10] | Yes | × | |||||||||||
| Hybrid | [11] | No | × | × | |||||||||
| [12] | Yes | × | × | ||||||||||
| [13] | No | × | × | ||||||||||
| [14] | No | × | × | × | |||||||||
| [15] | No | × | × | ||||||||||
| [16] | Yes | × | × | ||||||||||
| Type | Daily | Weekly | Monthly |
|---|---|---|---|
| Embedding dimension | 48 | 48 | 48 |
| Sequences size | 48 | 48 | 48 |
| LSTM layers | 1 | 1 | 2 |
| LSTM units | 100 | 200 | 200, 100 |
| Epochs | 50 | 100 | 200 |
| Optimizer/Loss | Adam/MSE | Adam/MSE | Adam/MSE |
| Method | Resolution | MSE | MAE |
|---|---|---|---|
| Linear Regression | Daily | 49.85 | 4.86 |
| Weekly | 1157.22 | 23.77 | |
| Monthly | 14,174 | 79.99 | |
| Random Forest | Daily | 48.68 | 4.78 |
| Weekly | 1130.06 | 23.31 | |
| Monthly | 13,818.84 | 78.40 | |
| Expect | Daily | 60.01 | 4.28 |
| Weekly | 566.91 | 13.82 | |
| Monthly | 29,521.40 | 121.16 |
| Method | Resolution | MSE | MAE |
|---|---|---|---|
| Linear Regression | Daily | 58.00 | 5.1738 |
| Weekly | 1992.93 | 30.46 | |
| Monthly | 14,233.43 | 81.31 | |
| Random Forest | Daily | 56.66 | 5.0797 |
| Weekly | 1945.24 | 29.89 | |
| Monthly | 13,674.78 | 78.87 | |
| Expect | Daily | 59.98 | 4.28 |
| Weekly | 565.86 | 13.80 | |
| Monthly | 29,516.15 | 121.16 |
| Method | Resolution | MSE | MAE |
|---|---|---|---|
| Linear Regression | Daily | 51.54 | 4.98 |
| Weekly | 2174.49 | 32.31 | |
| Monthly | 35,861.35 | 131.02 | |
| Random Forest | Daily | 57.52 | 5.09 |
| Weekly | 2257.00 | 31.95 | |
| Monthly | 37,614.87 | 132.55 | |
| Expect | Daily | 33.67 | 3.29 |
| Weekly | 408.61 | 11.37 | |
| Monthly | 36,266.74 | 127.98 |
| Method | Resolution | MSE | MAE |
|---|---|---|---|
| Linear Regression | Daily | 51.65 | 5.02 |
| Weekly | 2182.02 | 32.68 | |
| Monthly | 36,124.15 | 134.02 | |
| Random Forest | Daily | 51.16 | 4.94 |
| Weekly | 2158.74 | 32.14 | |
| Monthly | 35,617.61 | 132.07 | |
| Expect | Daily | 33.63 | 3.29 |
| Weekly | 408.61 | 11.36 | |
| Monthly | 36,278.63 | 128.03 |
| Data Completion | MSE | MAE | ||||
|---|---|---|---|---|---|---|
| Daily | Weekly | Monthly | Daily | Weekly | Monthly | |
| RDC and DDC | 60.01 | 566.91 | 29,521.40 | 4.28 | 13.82 | 121.16 |
| RDC and CDC | 59.98 | 565.86 | 29,516.15 | 4.28 | 13.80 | 121.16 |
| SDC and DDC | 33.67 | 408.61 | 36,266.74 | 3.29 | 11.37 | 127.98 |
| SDC and CDC | 33.63 | 408.61 | 36,278.63 | 3.29 | 11.36 | 128.03 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mouakher, A.; Inoubli, W.; Ounoughi, C.; Ko, A. Expect: EXplainable Prediction Model for Energy ConsumpTion. Mathematics 2022, 10, 248. https://doi.org/10.3390/math10020248
Mouakher A, Inoubli W, Ounoughi C, Ko A. Expect: EXplainable Prediction Model for Energy ConsumpTion. Mathematics. 2022; 10(2):248. https://doi.org/10.3390/math10020248
Chicago/Turabian StyleMouakher, Amira, Wissem Inoubli, Chahinez Ounoughi, and Andrea Ko. 2022. "Expect: EXplainable Prediction Model for Energy ConsumpTion" Mathematics 10, no. 2: 248. https://doi.org/10.3390/math10020248
APA StyleMouakher, A., Inoubli, W., Ounoughi, C., & Ko, A. (2022). Expect: EXplainable Prediction Model for Energy ConsumpTion. Mathematics, 10(2), 248. https://doi.org/10.3390/math10020248