Abstract
So far, most studies on networked evolutionary game have focused on a single update rule. This paper investigated the seeking of the Nash Equilibrium and strategy consensus of the evolutionary networked game with mixed updating rules. First, we construct the algebraic formulation for the dynamics of the evolutionary networked game by using the semi-tensor product method. Second, based on the algebraic form, the dynamic behavior of networked evolutionary games is discussed, and an algorithm to seek the Nash equilibrium is proposed. Third, we investigate the strategy consensus problem for a special networked evolutionary game. Finally, some illustrative examples are given to verify our conclusions.
MSC:
91A22; 93B25
1. Introduction
Game theory, introduced by Von et al. [1], is the study of disciplines that deal with the decision-making problems. Considering the update of strategy profiles with respect to time, biologists Smith and Price proposed the evolutionary game theory in [2]. Later, paper [2,3,4] demonstrated that players naturally evolved towards a higher-return goal or higher fitness following a series of adaptive learning processes based on specific rules, eventually reaching a steady state, which was called the Evolutionary Stable Strategy (ESS) [2]. The fundamental principle in the majority of early literature in evolutionary games was that individuals interact with all the other players. Arefin et al. [5] investigated the social dilemmas by the social efficiency deficit without the spatial structure. In the literature [6,7], the authors investigated the network adaptation dynamics of the Prisoner’s Dilemma game and the Public Goods game, respectively. Both papers demonstrated that the cooperation was actually enhanced when the network structure was taken into account. Moreover, in many practical situations, an individual only just interacts with its neighbors, such as its friends, relatives, colleagues. Due to this, Nowak and May proposed the concept of the networked evolutionary game (NEG) [8] by adding a network into the classical framework of games. In the network, nodes represent players and edges denote the relationship among players.
Recently, networked evolutionary games have been applied to many real-life decision-making problems such as the plastic ban problem in [9] and the epidemiological problems in [10]. Among the study of NEGs, a very interesting and fundamental issue is the analysis of the evolutionary trends for all players’ behaviors and the problem of the seeking strategy Nash Equilibrium. It is noted that the current works on networked evolutionary games are mainly based on mean-field techniques [11] and computer simulations [12]. However, using these methods to investigate the evolution of game dynamics from a strictly theoretical point of view is quite challenging.
Professor Cheng recently introduced a new matrix product, that is the semi-tensor product (STP) of matrices to relax the general matrix product restriction on dimensionality and could effectively handle the logic network problems. Many papers [13,14,15] applied this method to NEGs by converting logical functions into algebraic forms, which makes the problem identical to that in the control. Cheng et al. [16,17] investigated the fundamental theoretical framework for analyzing and controlling NEGs and they demonstrated that if the strategy update rule (SUR), where each player decides his action in the following step based on the knowledge about its neighbors, is one of the most critical factors of network evolutionary games. Once the SUR is determined, the evolution progress will be determined accordingly. The most popular SURs currently are the Myopic best response adjustment rule (MBRA) [18], Unconditional Imitation [8], Fermi Rule [19]. For example, some authors [20,21,22] have discussed a class of NEGs under the MBRA rule and established the corresponding algebraic formulation of the game.
It is worth noting that players may update their choices according to more than one rule. For instance, when customers purchase a product in the market, they may not be familiar with the market or may not be aware of whether the merchant’s pricing is high or typical, so they will rely on their own experiences or the recommendations of their friends. The merchant in this game may use several sales strategies to obtain a high revenue. The papers [23,24] investigated the dynamics based on a well-mixed population under mixed rules.
Based on the above-mentioned discussions, we present the model of networked evolutionary with mixed updating rules. The following list summarizes the main contributions of this study.
- This paper puts forward a new evolutionary networked game model called the Mixed Rules NEG. This model can well describe the real situation in which players adopt mixed rules to play with its neighbors in reality.
- We give two strategy updating rules and establish their strict algebraic forms by the method STP. Then, we construct the algebraic expression of the evolutionary process under mixed rules.
- We discuss the Nash Equilibrium under the game.
- A class of networked game’s strategy optimization is discussed. We obtain two results on whether and when the game will achieve an optimal strategy.
2. Preliminaries
In this section, we give some necessary preliminaries, which will be used in the sequel.
2.1. Semi-Tensor Product
Before recalling the STP of matrices, some concepts are listed as follows.
- (1)
- is the field of real numbers;
- (2)
- is the n dimensional Euclidean space;
- (3)
- is the set of real matrices;
- (4)
- is the i-th column of matrix M; is the set of columns of M;
- (5)
- is the i-th column of matrix M; is the set of columns of M;
- (6)
- denotes the row stacking form of A;
- (7)
- ;
- (8)
- is called a logical matrix if the columns of L are the form of . That is, Col (L). Denote by the set of logical matrices;
- (9)
- Assume , then , and its shorthand form is ;
- (10)
- is a probabilistic vector, if , and . The set of k dimensional probabilistic vectors is denoted by . The set of probabilistic matrices is denoted by .
- (11)
- .
The STP of matrices is the fundamental tool in our approach. We provide a brief review here and refer to [15] for details.
Definition 1.
Let and . Then, we define the STP of A and B as [15]
where is the least common multiple of n and p.
Lemma 1.
Assume and . Define two matrices, named by ‘delete rear operator’ and ‘delete front operator’ respectively, as , . Then, we have [15]
The following are some special properties of STP, which will be used in the sequel.
Definition 2.
A swap matrix is defined as follows:
If m = n, it can be expressed briefly as .
Proposition 1.
Let A be a matrix, and be two column vectors, and , . Then
Proposition 2.
Let be a finite-valued mapping. Then, there exists a unique matrix , such that
where .
Remark 1.
The STP is the ordinary matrix product when q=m, which keeps all original properties of ordinary matrix product. In this paper, the matrix product is assumed to be STP, and without confusion, one can omit the symbol ‘⋉’ and simply call it `product’.
2.2. Networked Evolutionary Game
We briefly recall the basic concepts of NEGs, proposed in [17].
Definition 3.
A fundamental network game (FNG) is consisted of three factors (N, S, C).
- 1.
- denotes the players’ set;
- 2.
- denotes the strategy set;
- 3.
- denotes the payoff matrix, element denotes the payoff of when player 1 takes strategy and player 2 takes strategy .
If A satisfy , then we say this is a symmetric game.
Definition 4.
A networked evolutionary game (NEG) consists of the following factors.
- A topology about the network, denoted by a undirected graph , where denotes the nodes, denotes the vertex. There is a adjacent matrix corresponding to the graph, if there is a edge between i and j, then , otherwise, . Denote by the neighborhood of player i where if and only if ;
- A fundamental network game G, such that if , then player i and j play FNG with strategies and , respectively;
- A strategy updating rule (SUR) , that is, player i takes the rule to determine the next step’s strategy, i.e.,
Remark 2.
We can observe from Lemma 2 that for every update rule, the existence and uniqueness of the strategy updating matrix can be guaranteed.
In addition, there are some SURs we will use in the sequel.
- (I)
- (Myopic best response adjustment rule) Each player holds the opinion that its neighbors will make the same decisions as in their last step, and the strategy choice at the present time is the best response against its neighbors’ strategies in the last step. It can be expressed asIf the set is not a singleton, then we choose the minimum, i.e., .
- (II)
- (Unconditional Imitation Rule) Each player adopts the strategy of the player with the largest gain in the neighborhood at the initial moment, i.e.,In addition, we adopt the same priority as rule (I).
- (III)
- (Repeating Rule) Each player will choose the same strategy as the last step, i.e.,
3. Main Result
3.1. Problem Formulation
In this paper, we consider a network game, and assume that it can repeat infinitely. At each time, player i only competes with its neighbors. We use to denote its aggregate payoff. Then, it can be expressed as
where denotes the payoff in the game of player i with its neighbor j when i takes strategy and j takes strategy . The NEG is evolved with the above three different SURs simultaneously, which makes the evolutionary dynamics more complicated and more consistent with the actual situation.
3.2. Mixed Rules NEG Dynamics
We assume that each player considers that its neighbors will adopt rules (I)–(III) with the probability , respectively, and these three parameters satisfy . All the players are eager to gain the maximum payoff. Then, we will establish the algebraic forms of the NEG dynamics in the following.
Using semi-tensor product method, for any , we identify Then, and .
Lemma 2.
Define a matrix , where We have
Then, let us discuss the evolutionary dynamics under three rules, respectively.
- (A)
- If player i chooses rule (I), we can transform the payoff function into algebraic form by the first rule as followswhere is the matrix A excepted the i-th column and . We can divide into blocks asThe r-th block means player i’s payoff when others’ strategy profile is at time t. We deduce the best response strategies of all the other players by lettingmeans the player i’s best response strategy when others strategy profile . Let , the algebraic forms of strategy dynamics of player i can be expressed as:
- (B)
- If player i chooses rule (II), we need an initial strategy profile, and we assume that player i’s neighbor has the maximum payoff at the initial time, then we can imply the dynamics of player i as:We can find that the dynamics of rule (II) needs the initial strategy profile.
- (C)
- If player i chooses rule (III), its strategy dynamics can be expressed as
Let us establish the algebraic forms of the payoff function of player i as:
where
Then we divide into blocks as,
The r-th blocks means player i’s payoff when the strategy profile of the last step . We deduce the best response strategies of all other players by letting
Let , the algebraic forms of strategy dynamics of player i can be expressed as:
By multiplying all the n equations together, we have the algebraic state space form of the strategy profile dynamics as:
where .
Remark 3.
It is noted that the algebraic Form (24) contains all the characteristics of the game, in other words, we can study the properties of the mixed strategy updating rules through the matrix T. The advantage of using the semi-tensor product is that the dynamical progress can be implied to the algebraic form, which helps us analyze the NEGs mathematically.
3.3. Nash Equilibrium Seeking
In this part, we will discuss the Nash equilibrium of the normal game. At first, we give the definition of the Nash equilibrium.
Definition 5.
The strategy profile is called a Nash equilibrium, if
holds for any and , where is the set of players, and are the payoff function and the set of strategies of the player i, respectively. and [25].
Remark 4.
If (25) holds when for any , then we say is a pure Nash equilibrium (PNE), and if , then it is a mixed Nash equilibrium (MNE). In this paper, we only consider the PNE.
Due to the uncertainty about the SUR used by the other players, each player makes their decision in the next step based on the expected profits of others under the mixed SURs. As a result, the study of the Nash Equilibrium is consistent with the expected profits, as in Equation (19).
Theorem 1.
Consider a given NEG . The algebraic forms of payoff functions are shown in Equation (13). There exists a NE in the game if and only if d has a non-negative column, that is, , such that
where
for , and . Moreover, the set of all NEs is
Proof. (Necessity). Assume that strategy profile is a NE of the game. Then, according to Definition 5, for any , we have
For a given strategy of player i and , it is easy to see that there must exist a , such that . When r goes from 1 to , one can obtain all possible strategies and .
Then, for each r, we have
where .
Construct the matrix for player i as
And
We can find that the j-th column of denotes the difference of player i’s payoff between and . Thus, if the strategy is , then the j-th column of is more than zero. Similarly, we can obtain , and is a NE.
Remark 5.
According to the above theorem, if the structure matrix of the game reward is known, the aforementioned theorem can solve all pure Nash equilibrium of the game directly.
Remark 6.
The aforementioned computation shows that the network between the players as well as the players’ payoff are both relevant to the Nash Equilibrium (Algorithm 1).
| Algorithm 1: Seeking of Nash Equilibrium. |
|
3.4. Strategy Consensus Analysis
In this part, we consider a special situation as [20], where the cost matrix satisfies , and . Then, we will provide two results whether and when the above game will achieve the optimal strategy profile. Moreover, one can use Theorem 1 to verify whether it is a NE.
Lemma 3.
Consider the evolutionary networked game as above. The evolutionary process of the game achieves the best strategy profile if there exists a constant α satisfying that at time t + 1 when .
Proof.
If
Then, there exists a constant satisfying that
which means that the best strategy profile can always be achieved from time t to t + 1. □
Theorem 2.
Consider the game as in Lemma 3. The evolutionary process of the game globally converges to the best strategy profile if and only if there exists a integer which satisfies . Moreover, if , then the game will converge to the optimal strategy profile at time .
Proof. (Necessity). If the game converges to the best strategy profile at time , we can deduce that
Then, the strategy profile at is
□
Obviously, the best strategy profile is achieved at time . According to the strategy dynamics (24) we can know
If is satisfied, we can know according to Lemma 3.
Proof. (Sufficiency). If there exists an integer which satisfies the condition , then it can imply . Thus we can conclude the result by (34) that
where . □
Remark 7.
Lemma 3 shows if the strategy profile of time t is known, then we can verify whether the next step’s result is the best profile. A sufficient and necessary condition is given for the existence of the optimal situation in the game under the initial condition.
4. Illustrate Example
In this section, we present an illustrate example to demonstrate how to use the results proposed in this paper to seek the Nash Equilibrium and to analyse the strategy consensus of the networked evolutionary game with mixed updating rules under different networks.
Example 1.
Consider a NEG with mixed updating rules (), which has the following factors.
- Finite networks: is a connected undirected graph, as in Figure 1a.
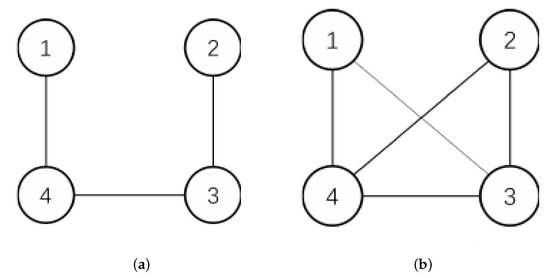 Figure 1. The networkgraph of the examples (a) Network 1, (b) Network 2.
Figure 1. The networkgraph of the examples (a) Network 1, (b) Network 2. - A fundamental networked game: every pair of players play the game G and G’s payoff bi-matrix is shown in Table 1.
- The SUR F is consisted of , which are described in (I)–(III), respectively.

Table 1.
Payoff bi-matrix of Example 1.
Table 1.
Payoff bi-matrix of Example 1.
| (1, 1) | (0, 1) | |
| (1, 0) | (2, 2) |
It’s easy to obtain that the adjacent matrices for the graph in Figure 1a is
The payoff matrix is
Assume the probability of the three SURs are and the initial strategy profile .
First, we establish the dynamics of the game. According to (13) and (19), we can establish the algebraic form of each players’ payoff functions by identifying as follows:
Divide into 16 equal blocks and underline the largest column for each block. Then, we obtain
By multiplying these equations, the state transformation matrix T can be deduced as
Thus, the algebraic form of the game dynamic is given by
Second, with the payoff Function (39), we calculate the matrix to seek the NEs. A straightforward calculation of Equation (30) gives that
By Theorem 1, it is easy to check that . Then, we obtain all the NEs of the game, which are .
Since the initial strategy is , by Lemma 3 and by calculating the transformation matrix T, we can obtain that , which means that the game dynamics will achieve the best profile in the next step by Theorem 2. We can figure out that the best strategy profile is also a NE.
Example 2.
Consider the same problem as in Example 1, but with the payoff matrix shown in Table 2 and the networks in Figure 1a,b. Assume the initial strategy profile . Similar to Example 1, we can obtain that the matrix for both graphs are
Table 2.
Payoff bi-matrix of Example 2.
Then, the Nash equilibrium of the NEG under two different networks are and , respectively.
It is clear that the corresponding Nash Equilibria of various network structures are not always the same. Calculate the state transformation matrix as follows:
We can obtain the evolution processes under two cases, that is
It is obvious that these two processes will never converge to a fixed point.
Remark 8.
From the evolution process for the Case 1, we can observe, despite the fact that strategy profile is a Nash equilibrium, the players’ strategies still change, which is due to the bounded rationality.
Remark 9.
According to those examples, we can know that if the initial strategy is set, we can establish the game evolutionary algebraic expression. In addition, we can know whether the strategy is a NE or best strategy profile by Theorem 1.
5. Conclusions
In this paper, a networked evolutionary game with a mixed strategy updating rules was investigated. By using the STP method, we obtained the algebraic forms of the payoff function and dynamics of the game. Furthermore, a necessary and sufficient condition for the existence of Nash Equilibrium was studied, and an algorithm was given for the seeking of Nash Equilibrium in the pure strategy situation. Based on the algebraic form, the dynamic behavior and the strategy consensus problem of the game have been discussed. Finally, we provide some examples, which are different in the payoff bi-matrices for the game to illustrate our method. However, because of the computational complexity, this method can only be used for small-size NEGs. More broad social dilemma games with multiple populations, such as the Prisoner’s Dilemma, will be taken into consideration for analysis and control issues in future work.
Author Contributions
Methodology, C.D.; Supervision, L.G.; Writing—original draft, Y.G. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported in part by the National Science Foundation of China under Grant 62173188.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Neumann, J.V.; Morgenstern, O. Theory of Game and Economic Behavior; Princeton University Press: Princeton, NJ, USA, 1944. [Google Scholar]
- Smith, J.M.; Price, G.R. The Logic of Animal Conflict. Nature 1973, 246, 15–18. [Google Scholar] [CrossRef]
- Sun, S.; Yang, H.; Yang, G.; Pi, J. Evolutionary Games and Dynamics in Public Goods Supply with Repetitive Actions. Mathematics 2021, 9, 1726. [Google Scholar] [CrossRef]
- Greene, R.B.; Axelrod, R. The Evolution of Cooperation. J. Policy Anal. Manag. 1984, 4, 140. [Google Scholar] [CrossRef]
- Arefin, M.R.; Kabir, K.M.A.; Jusup, M.; Ito, H.; Tanimoto, J. Social Efficiency Deficit Deciphers Social Dilemmas. Sci. Rep. 2020, 10, 16092. [Google Scholar] [CrossRef]
- Gómez-Gardeñes, J.; Romance, M.; Criado, R.; Vilone, D.; Sánchez, A. Evolutionary Games Defined at the Network Mesoscale: The Public Goods Game. Chaos 2011, 21, 016113. [Google Scholar] [CrossRef]
- Zimmermann, M.G.; Eguíluz, V.M. Cooperation, Social Networks, and the Emergence of Leadership in a Prisoner’s Dilemma with Adaptive Local Interactions. Phys. Rev. E 2005, 056118, 1515. [Google Scholar] [CrossRef]
- Nowak, M.A.; May, R.M. Evolutionary Games and Spatial Chaos. Nature 1992, 359, 826–829. [Google Scholar] [CrossRef]
- Seikh, M.R.; Karmakar, S.; Castillo, O. A Novel Defuzzification Approach of Type-2 Fuzzy Variable to Solving Matrix Games: An Application to Plastic Ban Problem. Iran. J. Fuzzy Syst. 2021, 18, 6262. [Google Scholar] [CrossRef]
- Tanimoto, J. Sociophysics Approach to Epidemics; Evolutionary Economics and Social Complexity Science; Springer: Singapore, 2021; pp. 13–60. [Google Scholar]
- Zhang, J.; Chen, X.; Zhang, C.; Wang, L.; Chu, T. Elimination Mechanism Promotes Cooperation in Coevolutionary Prisoner’s Dilemma Games. Phys. A 2010, 389, 4081–4086. [Google Scholar] [CrossRef]
- Li, R.-H.; Yu, J.X.; Lin, J. Evolution of Cooperation in Spatial Traveler’s Dilemma Game. PLoS ONE 2013, 8, e58597. [Google Scholar] [CrossRef]
- Li, Z.; Cheng, D. Algebraic Approach to Dynamics of Multivalued Networks. Int. J. Bifurc. Chaos 2010, 20, 561–582. [Google Scholar] [CrossRef]
- Cheng, D.; Qi, H. A Linear Representation of Dynamics of Boolean Networks. IEEE Trans. Autom. Contr. 2010, 55, 2251–2258. [Google Scholar] [CrossRef]
- Cheng, D.-Z.; Qi, H.-S.; Zhao, Y. Analysis and Control of Boolean Networks: A Semi-Tensor Product Approach. ACTA Autom. Sin. 2011, 37, 529–540. [Google Scholar] [CrossRef]
- Cheng, D.; Xu, T.; Qi, H. Evolutionarily Stable Strategy of Networked Evolutionary Games. IEEE Trans. Neural Netw. Learn. Syst. 2014, 25, 1335–1345. [Google Scholar] [CrossRef]
- Cheng, D.; He, F.; Qi, H.; Xu, T. Modeling, Analysis and Control of Networked Evolutionary Games. IEEE Trans. Autom. Control 2015, 60, 2402–2415. [Google Scholar] [CrossRef]
- Young, H. The Evolution of Conventions. Econometrica 1993, 61, 57–84. [Google Scholar] [CrossRef]
- Szabó, G.; Tőke, C. Evolutionary Prisoner’s Dilemma Game on a Square Lattice. Phys. Rev. E 1998, 58, 69–73. [Google Scholar] [CrossRef]
- Guo, P.; Wang, Y.; Li, H. Algebraic Formulation and Strategy Optimization for a Class of Evolutionary Networked Games via Semi-Tensor Product Method. Automatica 2013, 49, 3384–3389. [Google Scholar] [CrossRef]
- Zhu, R.; Chen, Z.; Zhang, J.; Liu, Z. Strategy Optimization of Weighted Networked Evolutionary Games with Switched Topologies and Threshold. Knowl.-Based Syst. 2022, 235, 107644. [Google Scholar] [CrossRef]
- Zhao, G.; Wang, Y. Formulation and Optimization Control of a Class of Networked Evolutionary Games with Switched Topologies. Nonlinear Anal.-Hybrid Syst. 2016, 22, 98–107. [Google Scholar] [CrossRef]
- Wang, X.-J.; Gu, C.-L.; Lv, S.-J.; Quan, J. Evolutionary Game Dynamics of Combining the Moran and Imitation Processes. Chin. Phys. B 2019, 28, 20203. [Google Scholar] [CrossRef]
- Zhang, W.; Li, Y.-S.; Xu, C. Co-Operation and Phase Behavior under the Mixed Updating Rules. Chin. Phys. Lett. 2015, 32, 118901. [Google Scholar] [CrossRef]
- Gibbons, R. A Primer in Game Theory; Harvester Wheatheaf: Munich, Germany, 1992; p. 8. ISBN 978-0-7450-1159-2. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).