
Using Domain Adaptation for Incremental SVM Classification of Drift Data



Abstract
:1. Introduction
2. Related Work
2.1. Incremental Learning Method
2.2. Concept Drift in Incremental Learning
2.3. Domain Adaptation
3. Methodology
3.1. Support Vector Machine
3.2. Incremental Support Vector Machine with Adaptation Strategy
3.3. Model Ensemble Strategy
| Algorithm 1: Model ensemble strategy. |
| Inputs: |
| • Dataset arrived before time ,, |
| • Sequence of examples at time : |
| • New arriving dataset at time : |
| • Learning algorithm SVM Initialise: |
| Do: for each |
| Training from ; if : add into model set directly; update according to and else: add into model set temporally remove one out to maximum update according to and Output: New model set |
4. Results and Discussion
4.1. Dataset
4.1.1. Real Data
- Clean Data is a dataset with high dimensions and a small scale. It consists of 476 instances, and each instance has 166 features. For all instances, there are two kinds of classes;
- Credit Data is a dataset with high dimensions and a large scale. It consists of 6000 instances, each with 65 features about credit card information. For all instances, there are two kinds of classes about whether or not to approve credit;
- Mushroom Data is a dataset with low dimensions and a large scale. It consists of 5644 instances, and each instance has 23 features of the characteristics of a mushroom. For all instances, there are two classes about whether it is poisonous;
- Spambase Data is a high-dimension and medium-scale dataset. It consists of 4601 instances, each with 57 features about keywords of a message. For all instances, there are two classes about whether it is spam;
- Waveform Data is a dataset with a middle dimension and medium scale. It consists of 3345 instances, and each instance has 40 features of the characteristics of the waveform. For all instances, there are two classes of the waveform catalogue.
4.1.2. Synthetic Data
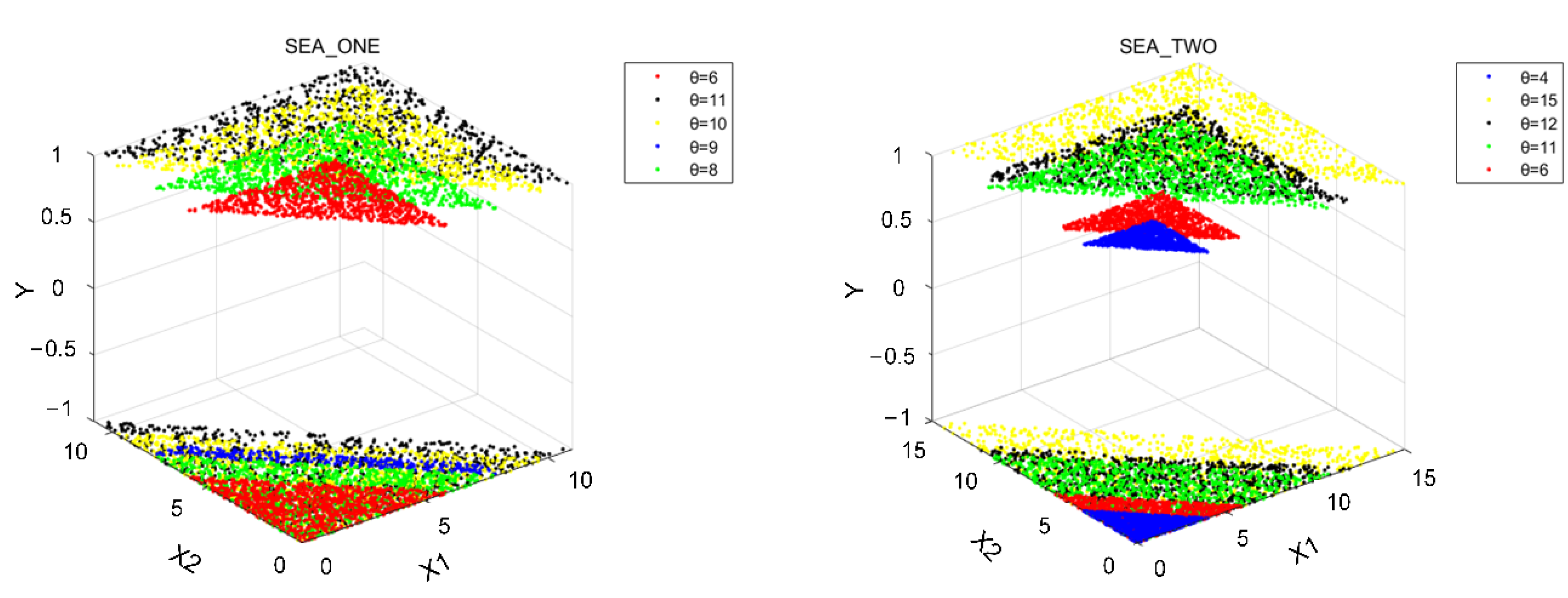
- SEA moving hyperplane concepts [21] have three features , , and . Their value is between 0 and 10. Feature and feature are relevant, while is a noisy feature with a random value. The class label of data in this concept is determined by Equation (17).
- 2.
- CIR concepts [21] apply a circle as the decision boundary in a 2-D feature space. To simulate the concept drift, we set a different radius of the circle, that is, Equation (18).
4.2. Result Analysis
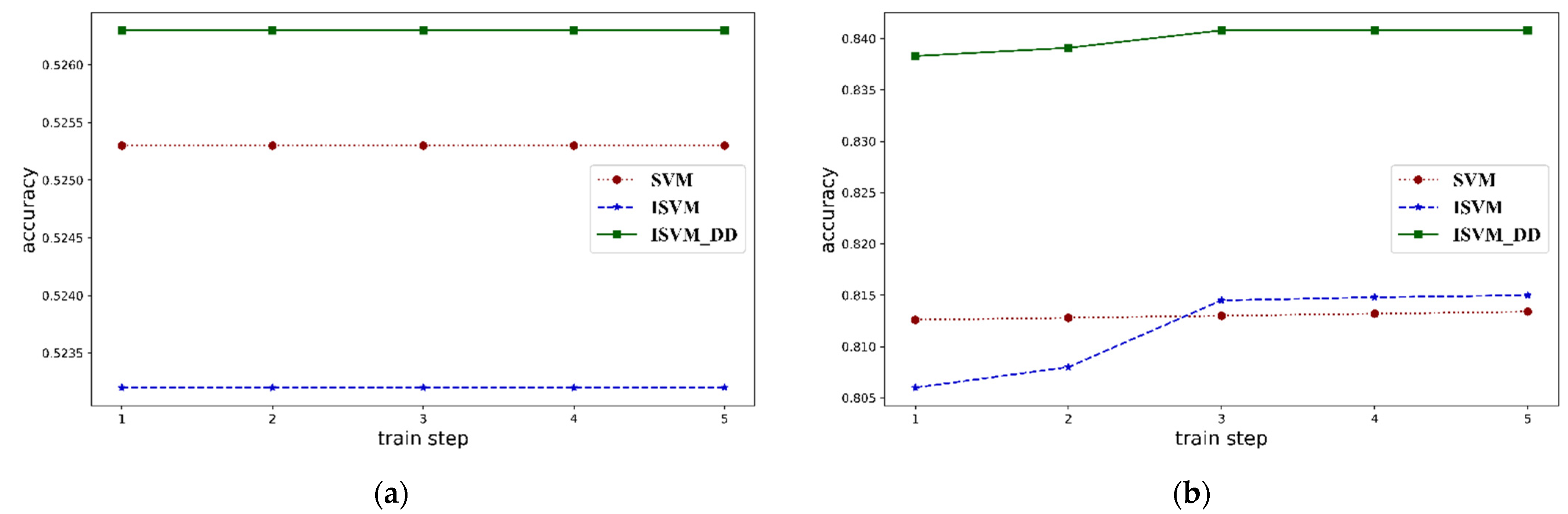
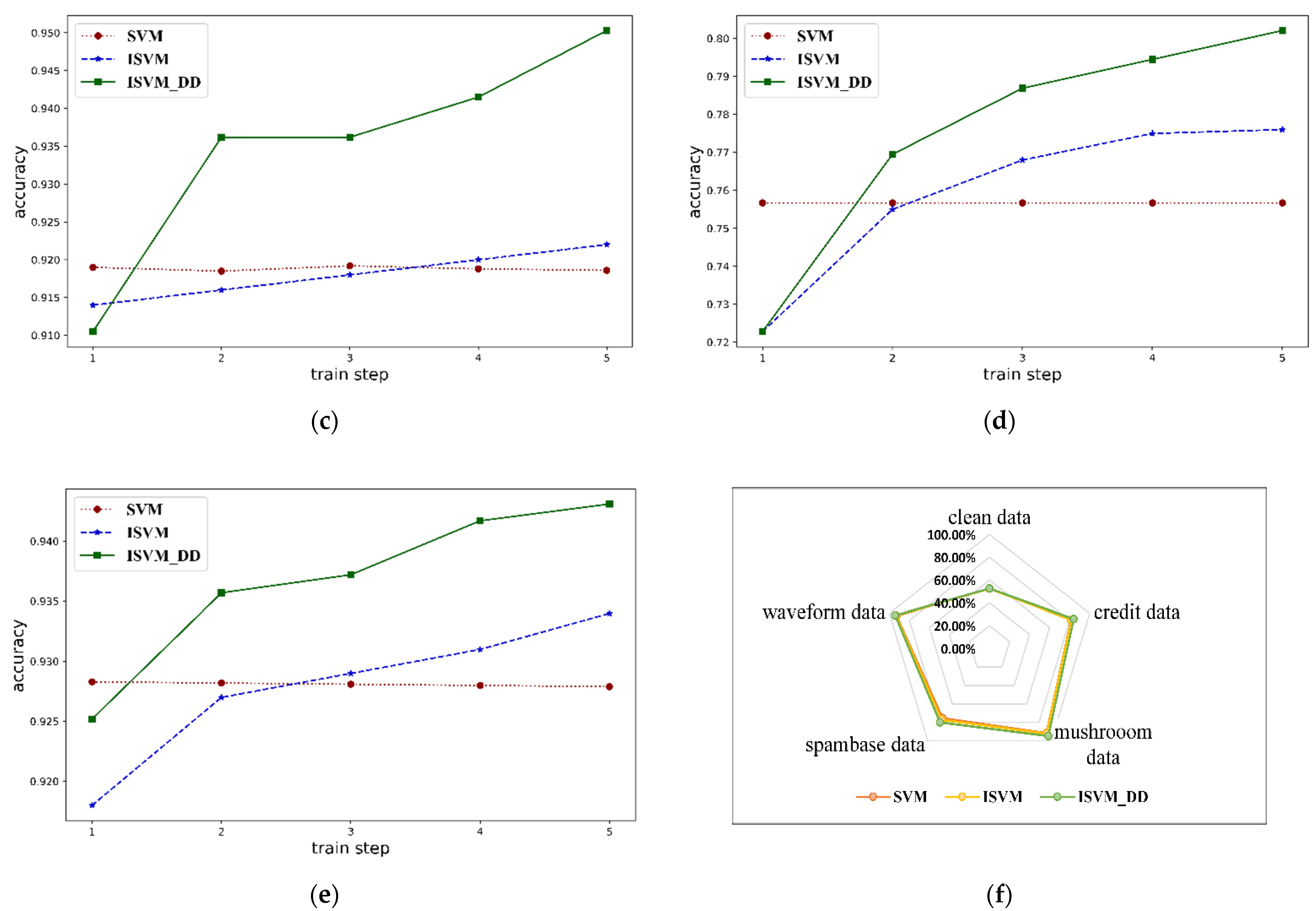
4.2.1. Results on Real Data
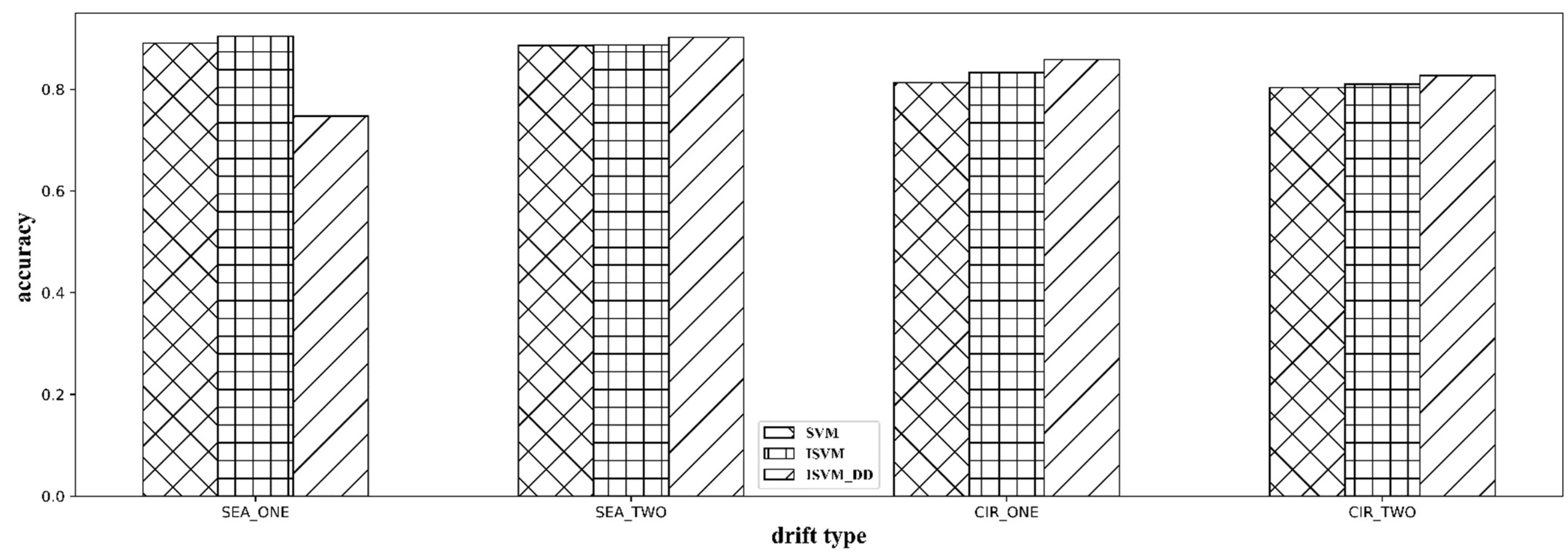
4.2.2. Results on Synthetic Data
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Polikar, R.; Upda, L.; Upda, S.S. Learn++: An incremental learning algorithm for supervised neural networks. IEEE Trans. Syst. Man Cybern. Part C 2001, 31, 497–508. [Google Scholar] [CrossRef]
- Yu, H.; Lu, J.; Zhang, G. An online robust support vector regression for data streams. IEEE Trans. Knowl. Data Eng. 2020, 34, 150–163. [Google Scholar] [CrossRef]
- Gâlmeanu, H.; Andonie, R. Weighted Incremental-Decremental Support Vector Machines for concept drift with shifting window. Neural Netw. 2022, 152, 528–541. [Google Scholar] [CrossRef] [PubMed]
- Muhlbaier, M.; Topalis, A.; Polikar, R. Incremental learning from unbalanced data. In Proceedings of the IEEE International Joint Conference on Neural Networks 2004, Budapest, Hungary, 25–29 July 2004; Volume 2, pp. 1057–1062. [Google Scholar]
- Muhlbaier, M.; Topalis, A.; Polikar, R. Learn++. MT: A New Approach to Incremental Learning. In Proceedings of the Springer International Workshop on Multiple Classifier Systems; Springer: Berlin/Heidelberg, Germany, 2004; pp. 52–61. [Google Scholar]
- Mohammed, H.S.; Leander, J.; Marbach, M. Comparison of Ensemble Techniques for Incremental Learning of New Concept Classes under Hostile Non-stationary Environments. In Proceedings of the IEEE International Conference on Systems, Man and Cybernetics, Taipei, Taiwan, 8–11 October 2006; pp. 4838–4844. [Google Scholar]
- Elwell, R.; Polikar, R. Incremental learning in non-stationary environments with controlled forgetting. In Proceedings of the IEEE International Joint Conference on Neural Networks, Atlanta, GA, USA, 14–19 June 2009; pp. 771–778. [Google Scholar]
- Uhlbaier, M.D.; Topalis, A.; Polikar, R. Learn++. NC: Combining Ensemble of Classifiers With Dynamically Weighted Consult-and-Vote for Efficient Incremental Learning of New Classes. IEEE Trans. Neural Netw. 2009, 20, 152–168. [Google Scholar] [CrossRef]
- Karnick, M.; Muhlbaier, M.D.; Polikar, R. Incremental learning in non-stationary environments with concept drift using a multiple classifier-based approach. In Proceedings of the IEEE International Conference on Pattern Recognition, Tampa, FL, USA, 8–11 December 2008; pp. 1–4. [Google Scholar]
- Elwell, R.; Polikar, R. Incremental Learning of Variable Rate Concept Drift. In Proceedings of the International Workshop on Multiple Classifier Systems; Springer: Berlin/Heidelberg, Germany, 2009; pp. 142–151. [Google Scholar]
- Ditzler, G.; Polikar, R. An ensemble based incremental learning framework for concept drift and class imbalance. In Proceedings of the IEEE International Joint Conference on Neural Networks, Barcelona, Spain, 18–23 July 2010; pp. 1–8. [Google Scholar]
- Dong, X.; Yu, Z.; Cao, W.; Shi, Y.; Ma, Q. A survey on ensemble learning. Front. Comput. Sci. 2020, 14, 241–258. [Google Scholar] [CrossRef]
- Sagi, O.; Rokach, L. Ensemble learning: A survey. Wiley Interdiscip. Rev. 68p25 Knowl. Discov. 2018, 8, e1249. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, F.; Chen, L. An Approach to Incremental SVM Learning Algorithm. In Proceedings of the IEEE International Colloquium on Computing, Communication, Control, and Management, Guangzhou, China, 3–4 August 2008; pp. 352–354. [Google Scholar]
- Liang, Z.; Li, Y.F. Incremental support vector machine learning in the primal and applications. Neurocomputing 2009, 72, 2249–2258. [Google Scholar] [CrossRef]
- Zheng, J.; Shen, F.; Fan, H.; Zhao, J. An online incremental learning support vector machine for large-scale data. Neural Comput. Appl. 2013, 22, 1023–1035. [Google Scholar] [CrossRef]
- Wang, J.; Yang, D.; Jiang, W.; Zhou, J. Semisupervised incremental support vector machine learning based on neighborhood kernel estimation. IEEE Trans. Syst. Man Cybern. Syst. 2017, 47, 2677–2687. [Google Scholar] [CrossRef]
- Gu, B.; Quan, X.; Gu, Y.; Sheng, V.S.; Zheng, G. Chunk incremental learning for cost-sensitive hinge loss support vector machine. Pattern Recognit. 2018, 83, 196–208. [Google Scholar] [CrossRef]
- Li, J.; Dai, Q.; Ye, R. A novel double incremental learning algorithm for time series prediction. Neural Comput. Appl. 2019, 31, 6055–6077. [Google Scholar] [CrossRef]
- Aldana, Y.R.; Reyes, E.J.M.; Macias, F.S.; Rodríguez, V.R.; Chacón, L.M.; Van Huffel, S.; Hunyadi, B. Nonconvulsive epileptic seizure monitoring with incremental learning. Comput. Biol. Med. 2019, 114, 103434. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Wang, Y.; Liu, Q.; Bi, C.; Jiang, X.; Sun, S. Incremental semi-supervised learning on streaming data. Pattern Recognit. 2019, 88, 383–396. [Google Scholar] [CrossRef]
- Hu, J.; Li, T.; Luo, C.; Fujita, H.; Yang, Y. Incremental fuzzy cluster ensemble learning based on rough set theory. Knowl.-Based Syst. 2017, 132, 144–155. [Google Scholar] [CrossRef]
- Pari, R.; Sandhya, M.; Sankar, S. A Multi-Tier Stacked Ensemble Algorithm to Reduce the Regret of Incremental Learning for Streaming Data. IEEE Access 2018, 6, 48726–48739. [Google Scholar] [CrossRef]
- Jiménez-Guarneros, M.; Alejo-Eleuterio, R. A Class-Incremental Learning Method Based on Preserving the Learned Feature Space for EEG-Based Emotion Recognition. Mathematics 2022, 10, 598. [Google Scholar] [CrossRef]
- Widmer, G.; Kubat, M. Learning in the presence of concept drift and hidden contexts. Mach. Learn. 1996, 23, 69–101. [Google Scholar] [CrossRef]
- Hulten, G.; Spencer, L.; Domingos, P. Mining time-changing data streams. In Proceedings of the Seventh ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, ACM, San Francisco, CA, USA, 26–29 August 2001; pp. 97–106. [Google Scholar]
- Zhu, Q.; Hu, X.; Zhang, Y.; Li, P.; Wu, X. A double-window-based classification algorithm for concept drifting data streams. In Proceedings of the IEEE International Conference on Granular Computing, San Jose, CA, USA, 14–16 August 2010; pp. 639–644. [Google Scholar]
- Bifet, A.; Gavalda, R. Learning from time-changing data with adaptive windowing. In Proceedings of the 2007 SIAM International Conference on Data Mining, Minneapolis, MN, USA, 26–28 April 2007; Society for Industrial and Applied Mathematics. pp. 443–448. [Google Scholar]
- Núñez, M.; Fidalgo, R.; Morales, R. Learning in environments with unknown dynamics: Towards more robust concept learners. J. Mach. Learn. Res. 2007, 8, 2595–2628. [Google Scholar]
- Chen, C.; Xie, W.; Huang, W.; Rong, Y.; Ding, X.; Huang, Y.; Huang, J. Progressive Feature Alignment for Unsupervised Domain Adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Chen, Y.; Yang, C.L.; Zhang, Y.; Li, Y.Z. Deep conditional adaptation networks and label correlation transfer for unsupervised domain adaptation. Pattern Recognit. 2020, 98, 107072. [Google Scholar] [CrossRef]
- He, T.; Shen, C.; Tian, Z.; Gong, D.; Sun, C.; Yan, Y. Knowledge Adaptation for Efficient Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Huang, J.; Smola, A.J.; Gretton, A.; Borgwardt, K.M.; Schölkopf, B. Correcting sample selection bias by unlabeled data. In Proceedings of the NIPS, Barcelona, Spain, 9 December 2016. [Google Scholar]
- Vapnik, V.; Izmailov, R. Knowledge transfer in SVM and neural networks. Ann. Math. Artif. Intell. 2017, 81, 3–19. [Google Scholar] [CrossRef]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2009, 22, 1345–1359. [Google Scholar] [CrossRef]
- Farahani, A.; Voghoei, S.; Rasheed, K.; Arabnia, H.R. A brief review of domain adaptation. In Proceedings of the International Conference on Data Science, Las Vegas, NV, USA, 27–30 July 2020; pp. 877–894. [Google Scholar]
- Kemker, R.; McClure, M.; Abitino, A.; Hayes, T.; Kanan, C. Measuring catastrophic forgetting in neural networks. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Nadira, A.; Abdessamad, A.; Mohamed, B.S. Regularized Jacobi Wavelets Kernel for Support Vector Machines. Statistics. Opti-Misation Inf. Comput. 2019, 7, 669–685. [Google Scholar]
- Cortes, C.; Vapnik, V. Support vector machine. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Wu, Y.; Ma, X. Alarms-related wind turbine fault detection based on kernel support vector machines. J. Eng. 2019, 18, 4980–4985. [Google Scholar] [CrossRef]
- Xu, J.; Xu, C.; Zou, B. New Incremental Learning Algorithm with Support Vector Machines. IEEE Trans. Syst. Man Cybern. Syst. 2018, 99, 1–12. [Google Scholar] [CrossRef]
- Zhang, Z.; Wang, M.; Nehorai, A. Optimal Transport in Reproducing Kernel Hilbert Spaces: Theory and Applications. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 1741–1754. [Google Scholar] [CrossRef] [PubMed]
- Arslan, G.; Madran, U.; Soyoğlu, D. An Algebraic Approach to Clustering and Classification with Support Vector Machines. Mathematics 2022, 10, 128. [Google Scholar] [CrossRef]
- Liu, X.; Zhao, B.; He, W. Simultaneous Feature Selection and Classification for Data-Adaptive Kernel-Penalized SVM. Mathematics 2020, 8, 1846. [Google Scholar] [CrossRef]
- Gonzalez-Lima, M.D.; Ludeña, C.C. Using Locality-Sensitive Hashing for SVM Classification of Large Data Sets. Mathematics 2022, 10, 1812. [Google Scholar] [CrossRef]
- Nalepa, J.; Kawulok, M. Selecting training sets for support vector machines: A review. Artif. Intell. Rev. 2019, 52, 857–900. [Google Scholar] [CrossRef]
- Moayedi, H.; Hayati, S. Modelling and optimisation of ultimate bearing capacity of strip footing near a slope by soft computing methods. Appl. Soft Comput. 2018, 66, 208–219. [Google Scholar] [CrossRef]
- Tan, B.; Zhang, Y.; Pan, S.J.; Yang, Q. Distant domain transfer learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notions | Description |
|---|---|
| a compact metric space | |
| label space, | |
| two-class classifier which labels each point, with a value | |
| probability distribution on | |
| random variable on | |
| classification error of a classifier , | |
| kernel, | |
| reproducing kernel Hilbert space | |
| regularisation parameter | |
| the space of continuous function on with the norm | |
| Dataset | Example Number | Feature Number | Label | Chunk Size |
|---|---|---|---|---|
| Clean Data | 475 | 166 | 2 | 95 |
| Credit Data | 6000 | 16 | 2 | 1200 |
| Mushroom Data | 5600 | 22 | 2 | 1120 |
| Spambase Data | 4600 | 57 | 2 | 920 |
| Waveform Data | 3300 | 40 | 2 | 660 |
| Drift Type | Fixed-Parameter | Drift Rate | Drift Parameter |
|---|---|---|---|
| SEA_ONE | A = 1, b = 1 | Low | = 10, 8, 6, 9, 11 |
| SEA_TWO | High | = 12, 6, 11, 4, 15 | |
| CIR_ONE | A = 0, b = 0 | Low | = 3, 2, 1, 4, 6 |
| CIR_TWO | High | = 1, 6, 2, 7, 3 |
| Dataset | Accuracy on Clean Data (%) | ||||
|---|---|---|---|---|---|
| Train 1 | Train 2 | Train 3 | Train 4 | Train 5 | |
| S1 | 57.89% | 57.89% | 57.89% | 57.89% | 57.89% |
| S2 | — | 60.00% | 60.00% | 60.00% | 60.00% |
| S3 | — | — | 56.84% | 56.84% | 56.84% |
| S4 | — | — | — | 62.10% | 62.10% |
| S5 | — | — | — | — | 67.36% |
| Dataset | Accuracy on Credit Data (%) | ||||
|---|---|---|---|---|---|
| Train 1 | Train 2 | Train 3 | Train 4 | Train 5 | |
| S1 | 86.08% | 85.91% | 86.08% | 85.75% | 86.08% |
| S2 | — | 83.50% | 83.16% | 82.91% | 83.16% |
| S3 | — | — | 86.16% | 85.75% | 85.75% |
| S4 | — | — | — | 83.25% | 82.41% |
| S5 | — | — | — | — | 84.33% |
| Test | 83.83% | 83.91% | 84.08% | 84.08% | 84.08% |
| Dataset | Accuracy on Mushroom Data (%) | ||||
|---|---|---|---|---|---|
| Train 1 | Train 2 | Train 3 | Train 4 | Train 5 | |
| S1 | 95.12% | 91.58% | 93.44% | 93.17% | 93.17% |
| S2 | — | 92.02% | 92.55% | 91.93% | 91.93% |
| S3 | — | — | 93.35% | 92.64% | 92.64% |
| S4 | — | — | — | 93.35% | 92.64% |
| S5 | — | — | — | — | 95.21% |
| Test | 91.05% | 93.62% | 93.62% | 94.15% | 95.03% |
| Dataset | Accuracy on Spambase Data (%) | ||||
|---|---|---|---|---|---|
| Train 1 | Train 2 | Train 3 | Train 4 | Train 5 | |
| S1 | 83.58% | 76.30% | 81.41% | 77.71% | 80.65% |
| S2 | — | 85.97% | 83.80% | 78.26% | 82.17% |
| S3 | — | — | 85.43% | 76.30% | 80.43% |
| S4 | — | — | — | 83.69% | 82.17% |
| S5 | — | — | — | — | 86.41% |
| Test | 72.28% | 76.95% | 78.69% | 79.45% | 80.21% |
| Dataset | Accuracy on Waveform Data (%) | ||||
|---|---|---|---|---|---|
| Train 1 | Train 2 | Train 3 | Train 4 | Train 5 | |
| S1 | 92.67% | 90.58% | 91.33% | 90.88% | 92.22% |
| S2 | — | 93.57% | 93.57% | 93.42% | 94.31% |
| S3 | — | — | 91.18% | 91.77% | 92.97% |
| S4 | — | — | — | 93.87% | 93.27% |
| S5 | — | — | — | — | 93.27% |
| Test | 92.52% | 93.57% | 93.72% | 94.17% | 94.31% |
| Algorithm | Test Accuracy (%) | ||||
|---|---|---|---|---|---|
| Clean Data | Credit Data | Mushroom Data | Spambase Data | Waveform Data | |
| SVM | 52.53% | 81.34% | 91.86% | 75.67% | 92.79% |
| ISVM | 52.32% | 81.52% | 92.23% | 77.38% | 93.42% |
| ISVM_DD | 52.63% | 84.08% | 95.03% | 80.21% | 94.31% |
| Algorithm | SEA_ONE | SEA_TWO | CIR_ONE | CIR_TWO |
|---|---|---|---|---|
| SVM | 89.07% | 88.65% | 81.33% | 80.32% |
| ISVM | 90.46% | 88.74% | 83.27% | 81.03% |
| ISVM_DD | 94.77% | 90.24% | 84.88% | 82.69% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tang, J.; Lin, K.-Y.; Li, L. Using Domain Adaptation for Incremental SVM Classification of Drift Data. Mathematics 2022, 10, 3579. https://doi.org/10.3390/math10193579
Tang J, Lin K-Y, Li L. Using Domain Adaptation for Incremental SVM Classification of Drift Data. Mathematics. 2022; 10(19):3579. https://doi.org/10.3390/math10193579
Chicago/Turabian StyleTang, Junya, Kuo-Yi Lin, and Li Li. 2022. "Using Domain Adaptation for Incremental SVM Classification of Drift Data" Mathematics 10, no. 19: 3579. https://doi.org/10.3390/math10193579
APA StyleTang, J., Lin, K.-Y., & Li, L. (2022). Using Domain Adaptation for Incremental SVM Classification of Drift Data. Mathematics, 10(19), 3579. https://doi.org/10.3390/math10193579