
Economic Activity Forecasting Based on the Sentiment Analysis of News

 , , , ,
, , , ,
Abstract
1. Introduction
2. Economic Activity
- social media information (search keywords, comments);
- business company data (prices of real estate and goods on online portals, the volume of transactions);
- mobility data (fixed and mobile sensor data, satellite images, pollution data);
- Energy consumption data;
- Financial market data, credit card transactions;
3. Natural Language and Transformers
4. Materials and Methods
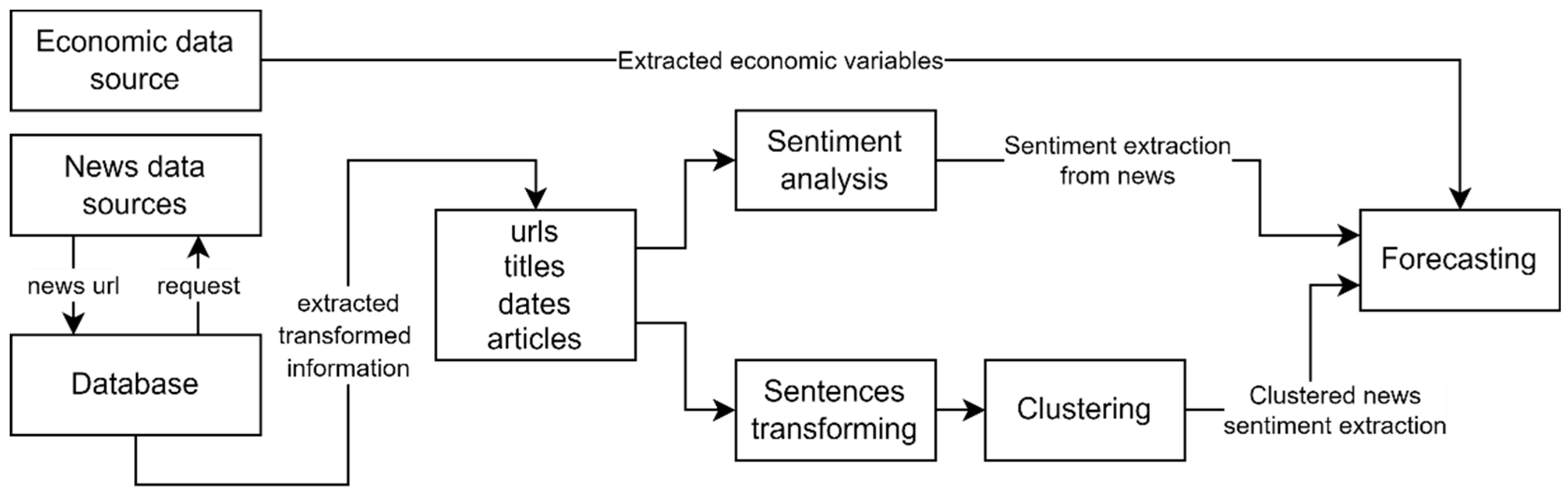
4.1. Data Gathering, Processing, and Analysis
4.2. NLP Models Used in the Research
4.3. Clustering Methods Used in the Research
- The observations are randomly divided into k clusters, and the initial centres of these clusters are selected.
- Cluster centres are recalculated.
- The distance of each observation to the clusters is calculated based on distance measures.
- The observations are assigned to the nearest cluster according to the distance to the cluster centres.
- Steps 2–4 are repeated until the cluster centres do not change or whenchange is less than the specified tolerance limit.

4.4. Clustering Evaluation Metrics
4.5. Forecasting Methods Used in the Research
4.6. Forecasting Evaluation Metrics
5. Results
5.1. News Clustering Results
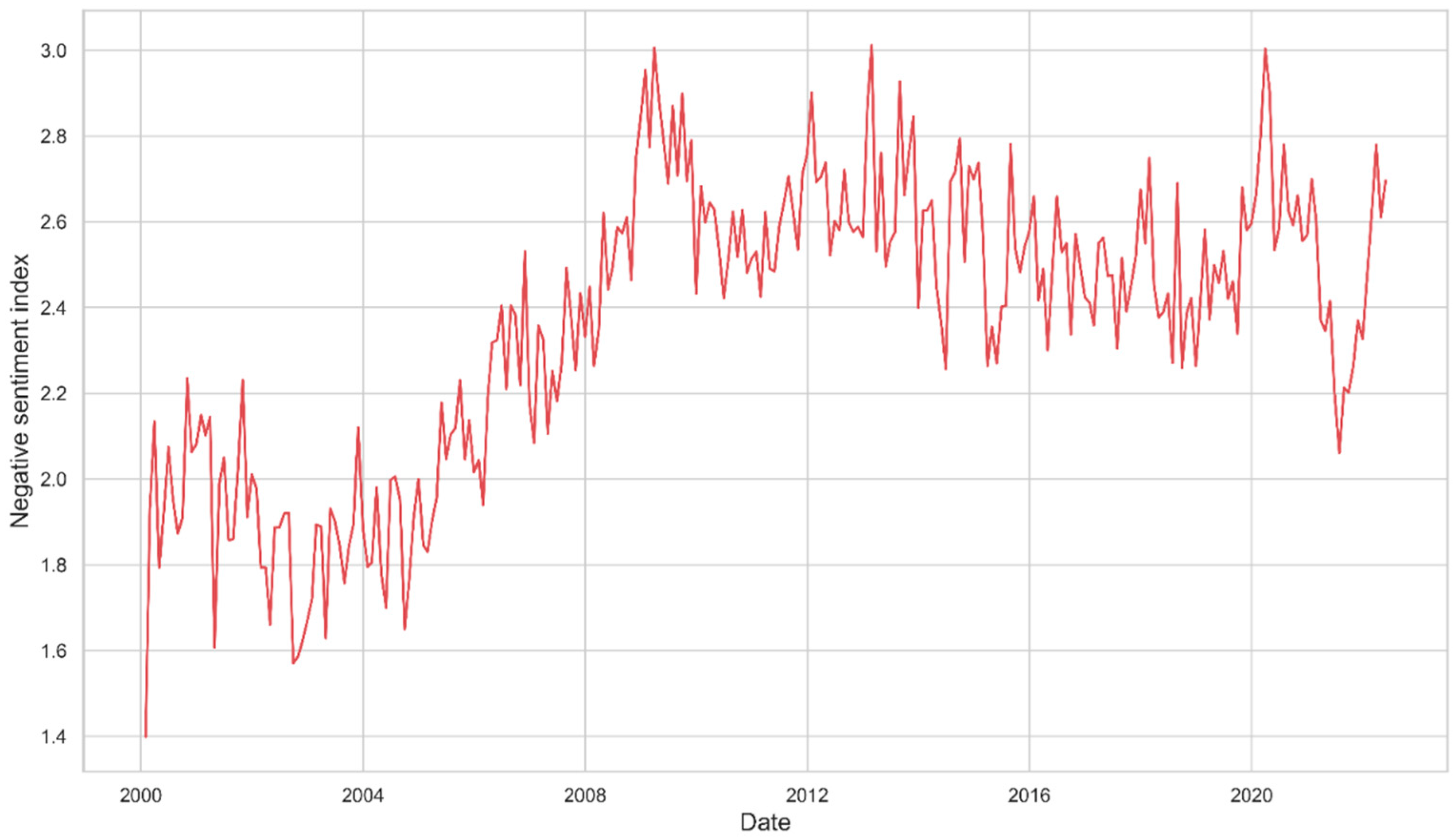
5.2. Sentiment Index of the News
5.3. Economic Activity Forecasting
- Univariate. In the univariate time series, only forecasted past values of the indicator are used.
- Best sentiment. A univariate time series of the economic activity indicator and a time series of negative sentiments for individual categories are used. Here, the sentiment time series of the categories are used separately.
- All sentiments. A univariate time series of the economic activity indicator and immediately the time series of all categories of negative sentiments are used.
- Biggest cluster. The one-dimensional time series of the economic activity indicator and the time series of the negative sentiment of the largest cluster is used.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data/Model | RMSE | MAE | MAPE | |||
|---|---|---|---|---|---|---|
| Mean | Std | Mean | Std | Mean | Std | |
| Youth unemployment rate | ||||||
| Univariate | 0.038 | 0.010 | 0.027 | 0.006 | 0.042 | 0.009 |
| Business sentiment | 0.119 | 0.017 | 0.105 | 0.018 | 0.336 | 0.052 |
| All sentiments | 0.207 | 0.041 | 0.186 | 0.040 | 0.435 | 0.061 |
| Biggest cluster | 0.221 | 0.045 | 0.196 | 0.043 | 0.458 | 0.068 |
| Overall unemployment rate | ||||||
| Univariate | 0.045 | 0.009 | 0.035 | 0.006 | 0.047 | 0.008 |
| Business sentiment | 0.121 | 0.023 | 0.110 | 0.025 | 0.338 | 0.061 |
| All sentiments | 0.264 | 0.023 | 0.256 | 0.025 | 0.533 | 0.040 |
| Biggest cluster | 0.267 | 0.035 | 0.278 | 0.037 | 0.576 | 0.045 |
| Consumer satisfaction | ||||||
| Univariate | 0.079 | 0.010 | 0.057 | 0.007 | 0.079 | 0.009 |
| Overall sentiment | 0.048 | 0.005 | 0.040 | 0.003 | 0.066 | 0.006 |
| All sentiments | 0.119 | 0.022 | 0.095 | 0.021 | 0.138 | 0.036 |
| Biggest cluster | 0.125 | 0.023 | 0.098 | 0.023 | 0.147 | 0.037 |
| Monthly inflation rate | ||||||
| Univariate | 0.187 | 0.010 | 0.143 | 0.008 | 0.340 | 0.015 |
| Overall sentiment | 0.123 | 0.003 | 0.093 | 0.002 | 0.255 | 0.008 |
| All sentiments | 0.209 | 0.010 | 0.162 | 0.006 | 0.365 | 0.032 |
| Biggest cluster | 0.208 | 0.013 | 0.158 | 0.007 | 0.356 | 0.045 |
| Annual inflation rate | ||||||
| Univariate | 0.087 | 0.018 | 0.065 | 0.013 | 0.298 | 0.030 |
| Overall sentiment | 0.062 | 0.007 | 0.053 | 0.006 | 0.283 | 0.035 |
| All sentiments | 0.106 | 0.059 | 0.081 | 0.043 | 0.285 | 0.117 |
| Biggest cluster | 0.156 | 0.068 | 0.098 | 0.056 | 0.305 | 0.158 |
| Production index | ||||||
| Univariate | 0.214 | 0.011 | 0.177 | 0.014 | 0.402 | 0.031 |
| Lithuania sentiment | 0.099 | 0.003 | 0.076 | 0.004 | 0.166 | 0.010 |
| All sentiments | 0.112 | 0.011 | 0.086 | 0.010 | 0.171 | 0.014 |
| Biggest cluster | 0.156 | 0.023 | 0.105 | 0.021 | 0.205 | 0.026 |
6. Discussion
7. Policies Implications
8. Conclusions and Future Research
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A






References
- Alexakis, G.; Panagiotakis, S.; Fragkakis, A.; Markakis, E.; Vassilakis, K. Control of smart home operations using natural language processing, voice recognition and IoT technologies in a multi-tier architecture. Designs 2019, 3, 32. [Google Scholar] [CrossRef]
- Ren, H.; Mao, X.; Ma, W.; Wang, J.; Wang, L. An English-Chinese machine translation and evaluation method for geographical names. ISPRS Int. J. Geo-Inf. 2020, 9, 139. [Google Scholar] [CrossRef]
- Neto, A.F.d.S.; Bezerra, B.L.D.; Toselli, A.H. Towards the natural language processing as spelling correction for offline handwritten text recognition systems. Appl. Sci. 2020, 10, 7711. [Google Scholar] [CrossRef]
- de Oliveira, N.R.; Pisa, P.S.; Lopez, M.A.; de Medeiros, D.S.V.; Mattos, D.M. Identifying fake news on social networks based on natural language processing: Trends and challenges. Information 2021, 12, 38. [Google Scholar] [CrossRef]
- Zhang, L.; Wang, S.; Liu, B. Deep learning for sentiment analysis: A survey. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2018, 8, e1253. [Google Scholar] [CrossRef]
- Hussein, D.M.E.-D.M. A survey on sentiment analysis challenges. J. King Saud Univ. Eng. Sci. 2018, 30, 330–338. [Google Scholar] [CrossRef]
- Taj, S.; Shaikh, B.B.; Meghji, A.F. Sentiment analysis of news articles: A lexicon based approach. In Proceedings of the 2019 2nd International Conference on Computing, Mathematics and Engineering Technologies (iCoMET), Online, 30–31 January 2019; pp. 1–5. [Google Scholar]
- Buckman, S.R.; Shapiro, A.H.; Sudhof, M.; Wilson, D.J. News sentiment in the time of COVID-19. FRBSF Econ. Lett. 2020, 8, 5. [Google Scholar]
- Baker, S.R.; Bloom, N.; Davis, S.J. Measuring economic policy uncertainty. Q. J. Econ. 2016, 131, 1593–1636. [Google Scholar] [CrossRef]
- Caldara, D.; Iacoviello, M. Measuring geopolitical risk. Am. Econ. Rev. 2022, 112, 1194–1225. [Google Scholar] [CrossRef]
- Shapiro, A.H.; Sudhof, M.; Wilson, D.J. Measuring news sentiment. J. Econom. 2020, 228, 221–243. [Google Scholar] [CrossRef]
- Sousa, M.G.; Sakiyama, K.; de Souza Rodrigues, L.; Moraes, P.H.; Fernandes, E.R.; Matsubara, E.T. BERT for stock market sentiment analysis. In Proceedings of the 2019 IEEE 31st International Conference on Tools with Artificial Intelligence (ICTAI), Portland, OR, USA, 4–6 November 2019; pp. 1597–1601. [Google Scholar]
- Jang, E.; Choi, H.; Lee, H. Stock prediction using combination of BERT sentiment Analysis and Macro economy index. J. Korea Soc. Comput. Inf. 2020, 25, 47–56. [Google Scholar]
- Gite, S.; Khatavkar, H.; Kotecha, K.; Srivastava, S.; Maheshwari, P.; Pandey, N. Explainable stock prices prediction from financial news articles using sentiment analysis. PeerJ Comput. Sci. 2021, 7, e340. [Google Scholar] [CrossRef] [PubMed]
- Galbraith, J.W.; Tkacz, G. Nowcasting GDP with Electronic Payments Data; 928991906X; ECB Statistics Paper; European Central Bank: Frankfurt am Main, Germany, 2015. [Google Scholar]
- Bok, B.; Caratelli, D.; Giannone, D.; Sbordone, A.M.; Tambalotti, A. Macroeconomic nowcasting and forecasting with big data. Annu. Rev. Econ. 2018, 10, 615–643. [Google Scholar] [CrossRef]
- Cooper, I.; Priestley, R. The world business cycle and expected returns. Rev. Financ. 2013, 17, 1029–1064. [Google Scholar] [CrossRef]
- Baumeister, C.; Hamilton, J.D. Structural interpretation of vector autoregressions with incomplete identification: Revisiting the role of oil supply and demand shocks. Am. Econ. Rev. 2019, 109, 1873–1910. [Google Scholar] [CrossRef]
- Herrera, A.M.; Rangaraju, S.K. The effect of oil supply shocks on US economic activity: What have we learned? J. Appl. Econom. 2020, 35, 141–159. [Google Scholar] [CrossRef]
- Sampi Bravo, J.R.E.; Jooste, C. Nowcasting Economic Activity in Times of COVID-19: An Approximation from the Google Community Mobility Report; World Bank Policy Research Working Paper; The World Bank: Washington, DC, USA, 2020. [Google Scholar]
- Diaz, E.M.; Perez-Quiros, G. GEA tracker: A daily indicator of global economic activity. J. Int. Money Financ. 2021, 115, 102400. [Google Scholar] [CrossRef]
- Angelov, N.; Waldenström, D. The Impact of COVID-19 on Economic Activity: Evidence from Administrative Tax Registers. 2021. Available online: https://ssrn.com/abstract=3886818 (accessed on 20 August 2022).
- Bricongne, J.-C.; Meunier, B.; Pical, T. Can Satellite Data on Air Pollution Predict Industrial Production? 2021. Available online: https://ssrn.com/abstract=3967146 (accessed on 20 August 2022).
- Baldwin, R.; Di Mauro, B.W. Economics in the time of COVID-19: A new eBook. VOX CEPR Policy Portal 2020, 2–3. Available online: https://fondazionecerm.it/wp-content/uploads/2020/03/CEPR-Economics-in-the-time-of-COVID-19_-A-new-eBook.pdf (accessed on 20 August 2022).
- Chernis, T.; Cheung, C.; Velasco, G. A three-frequency dynamic factor model for nowcasting Canadian provincial GDP growth. Int. J. Forecast. 2020, 36, 851–872. [Google Scholar] [CrossRef]
- Lourenço, N.; Rua, A. The Daily Economic Indicator: Tracking economic activity daily during the lockdown. Econ. Model. 2021, 100, 105500. [Google Scholar] [CrossRef]
- Cavallo, A.; Diewert, W.E.; Feenstra, R.C.; Inklaar, R.; Timmer, M.P. Using online prices for measuring real consumption across countries. In AEA Papers and Proceedings; American Economic Association: Nashville, TN, USA, 2018; pp. 483–487. [Google Scholar] [CrossRef]
- Mellander, C.; Lobo, J.; Stolarick, K.; Matheson, Z. Night-time light data: A good proxy measure for economic activity? PLoS ONE 2015, 10, e0139779. [Google Scholar] [CrossRef] [PubMed]
- Kapetanios, G.; Papailias, F. Big Data & Macroeconomic Nowcasting: Methodological Review; Economic Statistics Centre of Excellence, National Institute of Economic and Social Research: London, UK, 2018; Available online: http://escoe-website.s3.amazonaws.com/wp-content/uploads/2020/07/13161005/ESCoE-DP-2018-12.pdf (accessed on 20 August 2022).
- Fenz, G.; Stix, H. Monitoring the economy in real time with the weekly OeNB GDP indicator: Background, experience and outlook. Monet. Policy Econ. 2021, Q4/20–Q1/21, 17–40. [Google Scholar]
- Orihuel, E.; Sapena, J.; Navarro-Ortiz, J. An empirical algorithm for COVID-19 nowcasting and short-term forecast in Spain: A kinematic approach. Appl. Syst. Innov. 2021, 4, 2. [Google Scholar] [CrossRef]
- Xin, M.; Shalaby, A.; Feng, S.; Zhao, H. Impacts of COVID-19 on urban rail transit ridership using the Synthetic Control Method. Transp. Policy 2021, 111, 1–16. [Google Scholar] [CrossRef]
- Li, B.; Ma, L. Migration, transportation infrastructure, and the spatial transmission of COVID-19 in China. J. Urban. Econ. 2020, 15, 103351. [Google Scholar] [CrossRef]
- Eraslan, S.; Götz, T. An unconventional weekly economic activity index for Germany. Econ. Lett. 2021, 204, 109881. [Google Scholar] [CrossRef]
- Eckert, F.; Kronenberg, P.; Mikosch, H.; Neuwirth, S. Tracking Economic Activity with Alternative High-Frequency Data; KOF Working Papers; KOF Swiss Economic Institute, ETH Zurich: Zürich, Switzerland, 2020; Volume 488. [Google Scholar] [CrossRef]
- Lewis, D.J.; Mertens, K.; Stock, J.H.; Trivedi, M. Measuring real activity using a weekly economic index 1. J. Appl. Econom. 2022, 37, 667–687. [Google Scholar] [CrossRef]
- Fornaro, P.; Luomaranta, H. Aggregate fluctuations and the effect of large corporations: Evidence from Finnish monthly data. Econ. Model. 2018, 70, 245–258. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Volume 30. Available online: https://proceedings.neurips.cc/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf (accessed on 20 August 2022).
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI blog 2019, 1, 9. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Pires, T.; Schlinger, E.; Garrette, D. How multilingual is multilingual BERT? arXiv 2019, arXiv:1906.01502. [Google Scholar]
- Sanh, V.; Debut, L.; Chaumond, J.; Wolf, T. DistilBERT, a distilled version of BERT: Smaller, faster, cheaper and lighter. arXiv 2019, arXiv:1910.01108. [Google Scholar]
- Lan, Z.; Chen, M.; Goodman, S.; Gimpel, K.; Sharma, P.; Soricut, R. Albert: A lite bert for self-supervised learning of language representations. arXiv 2019, arXiv:1909.11942. [Google Scholar]
- Lewis, M.; Liu, Y.; Goyal, N.; Ghazvininejad, M.; Mohamed, A.; Levy, O.; Stoyanov, V.; Zettlemoyer, L. Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. arXiv 2019, arXiv:1910.13461. [Google Scholar]
- Adhikari, A.; Ram, A.; Tang, R.; Lin, J. Docbert: Bert for document classification. arXiv 2019, arXiv:1904.08398. [Google Scholar]
- Liu, X.; He, P.; Chen, W.; Gao, J. Multi-task deep neural networks for natural language understanding. arXiv 2019, arXiv:1901.11504. [Google Scholar]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.R.; Le, Q.V. Xlnet: Generalized autoregressive pretraining for language understanding. In Proceedings of the 33rd Conference on Neural Information Processing Systems (NIPS 2019), Vancouver, BC, Canada, 8–14 December 2019; Volume 32. Available online: https://proceedings.neurips.cc/paper/2019/hash/dc6a7e655d7e5840e66733e9ee67cc69-Abstract.html (accessed on 20 August 2022).
- Gautam, A.; Venktesh, V.; Masud, S. Fake news detection system using xlnet model with topic distributions: Constraint@ aaai2021 shared task. In International Workshop on Combating Online Hostile Posts in Regional Languages during Emergency Situation; Springer: Cham, Switzerland, 2021; pp. 189–200. [Google Scholar]
- Merchant, K.; Pande, Y. Nlp based latent semantic analysis for legal text summarization. In Proceedings of the 2018 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Bangalore, India, 19–22 September 2018; pp. 1803–1807. [Google Scholar]
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M. Huggingface’s transformers: State-of-the-art natural language processing. arXiv 2019, arXiv:1910.03771. [Google Scholar]
- Topal, M.O.; Bas, A.; van Heerden, I. Exploring transformers in natural language generation: Gpt, bert, and xlnet. arXiv 2021, arXiv:2102.08036. [Google Scholar]
- Gao, F.; Zhu, J.; Wu, L.; Xia, Y.; Qin, T.; Cheng, X.; Zhou, W.; Liu, T.-Y. Soft contextual data augmentation for neural machine translation. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 5539–5544. [Google Scholar]
- Li, X.; Fu, X.; Xu, G.; Yang, Y.; Wang, J.; Jin, L.; Liu, Q.; Xiang, T. Enhancing BERT representation with context-aware embedding for aspect-based sentiment analysis. IEEE Access 2020, 8, 46868–46876. [Google Scholar] [CrossRef]
- Dang, N.C.; Moreno-García, M.N.; De la Prieta, F. Sentiment analysis based on deep learning: A comparative study. Electronics 2020, 9, 483. [Google Scholar] [CrossRef]
- Khan, I.U.; Khan, A.; Khan, W.; Su’ud, M.M.; Alam, M.M.; Subhan, F.; Asghar, M.Z. A review of Urdu sentiment analysis with multilingual perspective: A case of Urdu and roman Urdu language. Computers 2021, 11, 3. [Google Scholar] [CrossRef]
- Iglesias, C.A.; Moreno, A. Sentiment analysis for social media. Appl. Sci. 2019, 9, 5037. [Google Scholar] [CrossRef]
- Hasan, A.; Moin, S.; Karim, A.; Shamshirband, S. Machine learning-based sentiment analysis for twitter accounts. Math. Comput. Appl. 2018, 23, 11. [Google Scholar] [CrossRef]
- Araci, D. Finbert: Financial sentiment analysis with pre-trained language models. arXiv 2019, arXiv:1908.10063. [Google Scholar]
- Malo, P.; Sinha, A.; Korhonen, P.; Wallenius, J.; Takala, P. Good debt or bad debt: Detecting semantic orientations in economic texts. J. Assoc. Inf. Sci. Technol. 2014, 65, 782–796. [Google Scholar] [CrossRef]
- Huang, A.; Wang, H.; Yang, Y. FinBERT—A Deep Learning Approach to Extracting Textual Information. 2020. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3910214 (accessed on 20 August 2022).
- Rosenthal, S.; Farra, N.; Nakov, P. SemEval-2017 task 4: Sentiment analysis in Twitter. arXiv 2019, arXiv:1912.00741. [Google Scholar]
- Lukauskas, M.; Ruzgas, T. A New Clustering Method Based on the Inversion Formula. Mathematics 2022, 10, 2559. [Google Scholar] [CrossRef]
- Ester, M.; Kriegel, H.-P.; Sander, J.; Xu, X. A density-based algorithm for discovering clusters in large spatial databases with noise. In Proceedings of the 2nd International Conference on Knowledge Discovery and Data Mining, Portland, OR, USA, 2–4 August 1996; pp. 226–231. [Google Scholar]
- Zhang, T.; Ramakrishnan, R.; Livny, M. BIRCH: An efficient data clustering method for very large databases. ACM Sigmod Rec. 1996, 25, 103–114. [Google Scholar] [CrossRef]
- Ankerst, M.; Breunig, M.M.; Kriegel, H.-P.; Sander, J. OPTICS: Ordering points to identify the clustering structure. ACM Sigmod Rec. 1999, 28, 49–60. [Google Scholar] [CrossRef]
- Caliński, T.; Harabasz, J. A dendrite method for cluster analysis. Commun. Stat. Theory Methods 1974, 3, 1–27. [Google Scholar] [CrossRef]
- Davies, D.L.; Bouldin, D.W. A cluster separation measure. IEEE Trans. Pattern Anal. Mach. Intell. 1979, 2, 224–227. [Google Scholar] [CrossRef]
- Rousseeuw, P.J. Silhouettes: A graphical aid to the interpretation and validation of cluster analysis. J. Comput. Appl. Math. 1987, 20, 53–65. [Google Scholar] [CrossRef]
- Aruoba, S.B.; Diebold, F.X.; Scotti, C. Real-time measurement of business conditions. J. Bus. Econ. Stat. 2009, 27, 417–427. [Google Scholar] [CrossRef]
- Matheson, M.T. Taxing Financial Transactions: Issues and Evidence; IMF: Washington, DC, USA, 2011. [Google Scholar]
- Brave, S.A.; Butters, R.A.; Justiniano, A. Forecasting economic activity with mixed frequency BVARs. Int. J. Forecast. 2019, 35, 1692–1707. [Google Scholar] [CrossRef]
- Bai, J.; Li, K.; Lu, L. Estimation and inference of FAVAR models. J. Bus. Econ. Stat. 2016, 34, 620–641. [Google Scholar] [CrossRef]
- Richardson, A.; van Florenstein Mulder, T.; Vehbi, T. Nowcasting GDP using machine-learning algorithms: A real-time assessment. Int. J. Forecast. 2021, 37, 941–948. [Google Scholar] [CrossRef]
- Graves, A.; Mohamed, A.-r.; Hinton, G. Speech recognition with deep recurrent neural networks. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 6645–6649. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Wang, Z.; Bovik, A.C. Mean squared error: Love it or leave it? A new look at signal fidelity measures. IEEE Signal Process. Mag. 2009, 26, 98–117. [Google Scholar] [CrossRef]
- Willmott, C.J.; Matsuura, K. Advantages of the mean absolute error (MAE) over the root mean square error (RMSE) in assessing average model performance. Clim. Res. 2005, 30, 79–82. [Google Scholar] [CrossRef]
- Glantz, S.A.; Slinker, B.K. Primer of Applied Regression & Analysis of Variance, 3rd ed.; McGraw-Hill, Inc.: New York, NY, USA, 2001; Volume 654. [Google Scholar]






| Metric Name | Formula |
|---|---|
| R2—coefficient of determination | |
| —adjusted coefficient of determination | |
| MAE—mean absolute error | |
| MSE—mean square error | |
| RMSE—rooted mean square error | |
| MPE—mean percentage error | |
| MAPE—mean absolute percentage error | |
| MASE—mean absolute scaled error |
| Calinski and Harabasz Score | Davies–Bouldin Score | |
|---|---|---|
| GMM | 11,648 | 5.841 |
| BGMM | 13,547 | 6.148 |
| K-means | 13,387 | 4.627 |
| MIDE | 12,542 | 5.314 |
| Title 1 | UNY | UNA | CS | MI | YI | PI |
|---|---|---|---|---|---|---|
| Overall sentiment | 0.021 | 0.050 | −0.200 *** | −0.009 | −0.013 | −0.012 |
| Business sentiment | 0.024 | −0.067 | −0.357 *** | 0.045 | 0.148 * | −0.128 * |
| Lithuania sentiment | −0.119 | −0.213 *** | −0.137 * | 0.148 * | 0.164 ** | −0.087 |
| Foreign sentiment | −0.212 *** | −0.259 *** | −0.650 *** | 0.052 | −0.113 | 0.068 |
| Health sentiment | −0.184 ** | −0.206 *** | 0.114 | 0.071 | 0.096 | −0.060 |
| Science sentiment | −0.139 * | −0.192 ** | 0.014 | 0.148 * | 0.327 *** | −0.012 |
| Culture sentiment | −0.301 *** | −0.272 *** | −0.300 *** | −0.039 | 0.002 | −0.075 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lukauskas, M.; Pilinkienė, V.; Bruneckienė, J.; Stundžienė, A.; Grybauskas, A.; Ruzgas, T. Economic Activity Forecasting Based on the Sentiment Analysis of News. Mathematics 2022, 10, 3461. https://doi.org/10.3390/math10193461
Lukauskas M, Pilinkienė V, Bruneckienė J, Stundžienė A, Grybauskas A, Ruzgas T. Economic Activity Forecasting Based on the Sentiment Analysis of News. Mathematics. 2022; 10(19):3461. https://doi.org/10.3390/math10193461
Chicago/Turabian StyleLukauskas, Mantas, Vaida Pilinkienė, Jurgita Bruneckienė, Alina Stundžienė, Andrius Grybauskas, and Tomas Ruzgas. 2022. "Economic Activity Forecasting Based on the Sentiment Analysis of News" Mathematics 10, no. 19: 3461. https://doi.org/10.3390/math10193461
APA StyleLukauskas, M., Pilinkienė, V., Bruneckienė, J., Stundžienė, A., Grybauskas, A., & Ruzgas, T. (2022). Economic Activity Forecasting Based on the Sentiment Analysis of News. Mathematics, 10(19), 3461. https://doi.org/10.3390/math10193461