1. Introduction
Genetic Programming (GP) [
1,
2,
3] has been used as an automatic programming approach to efficiently solve many NP problems and real-world challenges [
4,
5,
6,
7,
8,
9]. However, solutions found by GP are often unnatural due to code bloat and/or unexpected solutions [
10,
11,
12]. A code bloat is a phenomenon of variable-length solution representation (e.g., a tree-based GP) for the rapid growth tendency of a code. Often, such growth does not change the semantics of a code (it is so-called neutral code, or introns). Some common observations about code bloat are:
“
Genetic programming (GP), a widely used evolutionary computing technique, suffers from bloat—the problem of excessive growth in individuals’ sizes. As a result, its ability to efficiently explore complex search spaces reduces. The resulting solutions are less robust and generalizable. Moreover, it is difficult to understand and explain models which contain bloat” [
11].
“
Unnecessary growth in program size is known as the bloat problem in Genetic Programming. Bloat not only increases computational expenses during evolution, but also impairs the understandability and execution performance of evolved final solutions” [
12].
One of the most famous and early examples of an unexpected solution was the application of a symbolic regression for the trigonometric identity discovery of
, where an automatically found solution was [
1]
According to Koza [
1], this solution was mysterious, and required additional testing and implementation in the Mathematica software package to verify that the solution indeed closely fit the
curve. Extra effort and mathematical skills were needed to show that the mysterious solution was actually equivalent to a well-known trigonometric identity involving a phase shift:
. As such, it is a common belief that the comprehension of automatically generated solutions using GP is more often difficult, due to code bloat problems and unexpected solutions [
10,
11,
12]. This paper takes a more skeptical approach to the acceptance of those beliefs. For this purpose, we resorted to control experiments, which were also used in our previous work to tackle a similar belief that programs written in domain-specific languages (DSLs) [
13,
14] are easier to comprehend than equivalent programs written in general-purpose languages (GPLs) [
15,
16]. To test the comprehension correctness and comprehension efficiency of automatically generated GP solutions, a control experiment was designed in the area of semantic inference [
17,
18]. Semantic inference is an extension of grammatical inference [
19], also with the aim to induce, in addition to the language syntax, its semantics. As such, a complete compiler/interpreter can be automatically generated from formal specifications [
20]. To automatically generate a compiler/interpreter for small DSLs solely from programs, GP was applied in our previous research work [
18,
21,
22], where a complete compiler/interpreter was produced from automatically generated attribute grammars (AGs) [
23,
24] using the tool LISA [
25]. Because the control experiment had students as the participants, we followed the guidelines for conducting experiments in a classroom environment [
26].
The main contributions of this work are:
Providing empirical evidence about the comprehension correctness of manually written AGs vs. automatically generated AGs using GP.
Providing empirical evidence about the comprehension efficiency of manually written AGs vs. automatically generated AGs using GP.
The remainder of this paper is organized as follows.
Section 2 describes related work on program comprehension and on the code bloat problem in GP.
Section 3 highlights the main ingredients of the controlled experiment.
Section 4 gives the experimental results and data analysis.
Section 5 discusses threats to validity.
Section 6 summarizes the key findings and outlines future work.
2. Related Work
The program comprehension of GP solutions, to the best of our knowledge, has not been investigated before. On the other hand, program comprehension [
27] in other research fields has been examined extensively. For example, the comprehension of block-based programming vs. text-based programming [
28,
29], studying the impact of anti-patterns on program comprehension [
30], comprehension of DSL programs vs. GPL programs [
15,
16,
31,
32], model comprehension [
33], comparison of a textual vs. a graphical notation in domain models [
34], the influence of visual notation to requirement specification comprehension [
35], comprehension of charts for visually impaired individuals [
36], program comprehension in virtual reality [
37], software maintenance [
38], and software engineering [
39].
Code bloat in GP is an undesired property of GP, since it increases computational complexity [
1,
22], and according to common beliefs, it hampers the comprehension of GP solutions. Therefore, many researchers have tackled the code bloat problem in GP. Subsequently, a variety of approaches are described briefly. Most of these approaches can roughly be classified as tree-based, working at the individual or population level. For example, limiting the maximum tree depth for individual solutions [
1], or limiting the maximum number of tree nodes for the entire population [
40]. Furthermore, there are approaches based on controlling the distribution of program sizes [
41], techniques that punish large individuals during evaluation using the fitness function [
42], and many other approaches that do not belong to any specific category. Note that all current approaches do not eliminate the code bloat problem completely, but they are successful in significantly reducing it.
The Dynamic Limits approach was presented in [
43,
44]. It is a collective name for the Dynamic Maximum Tree Depth technique [
43] and its variations, where a dynamically limited depth or size of individuals (programs in GP) is used [
44]. Any individual who crosses the current limit is rejected unless it is currently the best rated individual. In that case, a new limit is set that corresponds to the limit used in such an individual. The same authors also proposed the resource-limited GP approach [
45], a resource-limiting technique applied to the number of tree nodes or lines of code. Compared with the previous approach, this one does not work on an individual, but on a population level. Substituting a subtree with an Approximate Terminal (SAT-GP) is yet another tree-based code bloat prevention approach which is based on the concept of approximate trees [
46]. It is applied to a portion of the largest individuals in the population by replacing a random subtree of such individuals with an approximate terminal of similar semantics. SAT-GP performance is generally better compared to the standard GP and neat-GP bloat control approach [
47]. The latter is based on the NeuroEvolution of Augmenting Topologies (NEAT) algorithm adopted for the GP and Flat Operator Equalization bloat control method (Flat-OE) [
48], which explicitly shapes the program size distributions towards a uniform or flat shape. In general, the Operator Equalization technique [
41] controls the distribution of sizes in a population by accepting individuals based on their size, directing exploration towards smaller size solutions. To address the code bloat problem in GP, the authors in [
49] used the principle of Minimum Description Length (MDL) [
50] within the fitness function, where the size of the composite operator is taken into account during the evaluation process. The hard size limit can restrict the GP search with a lesser likelihood of discovering the effective composite operators. However, according to MDL, large composite operators do not have high fitness, and will eventually be eliminated in the selection process. Therefore, the hard limit can be removed in such cases. GP programs can also be simplified online during the evolutionary process [
51]. Programs are represented as expressions stored in a tree representation [
1]. During evaluation, programs are checked recursively using the postfix order traversal mode, and algebraic simplification rules and hashing are applied to simplify programs and reduce code bloat [
52]. To tackle the code bloat problem in the standard tree-based GP it is possible to substitute standard subtree crossover with the one-point crossover (OPX) developed by Langdon and Poli in [
53], while maintaining all other GP standard aspects [
54]. Bloat and diversity can be positively affected by using multi-objective methods with the idea to search for multiple solutions, each of which satisfies different objectives to a different extent. The selection of the final solution with a certain combination of objective values is postponed until the moment when it is known which combinations of objective values exist [
55]. In addition to the above, there are many other methods to control code bloat, such as:
The code bloat problem in semantic inference [
18,
21,
22] affects performance, because more CPU time is required to evaluate a solution. Improved long-term memory assistance (ILTMA) [
22,
58], multi-threaded fitness evaluation, and a reduced number of input programs were used to address this [
22]. After evaluating each individual in the population, ILTMA generates a set of similar individuals who share the same fitness value by creating a Cartesian product [
59,
60] of the individual’s equivalent genes. The hash table then expands faster, increasing the chances that the remaining individuals are already in the hash table, instead of spending the CPU time on their evaluation. Depending on the number of available CPU cores, multi-threaded fitness evaluation can significantly improve semantic inference performance by performing parallel evaluations, while a reduced number of fitness cases can reduce the CPU time required for evaluation using a smaller number of structurally complete input programs [
22]. In addition, the limited depth of the expression tree was used to control the code bloat in semantic inference.
3. Method
The goal of the controlled experiment was to compare researchers’ comprehension of programming language specifications manually written by a language designer vs. their comprehension of programming language specifications generated automatically by GP [
1] in the field of semantic inference [
17,
18]. Particularly, we wanted to verify whether the program comprehension of automatically generated solutions using GP is indeed more difficult due to the code bloat problem and unexpected solutions. For this purpose, we prepared a controlled experiment consisting of several tasks, using AGs [
23,
24] as a specification formalism. Since it is difficult to obtain a larger group of language designers, the participants in our study were undergraduate students in the Computer Science programs at the University of Maribor and at the University of Ljubljana. Both programs are leading undergraduate Computer Science programs in Slovenia, attracting the best students, and have similar—although not identical—curricula. The experiment was conducted as part of the Compiling Programming Languages course (second year) at the University of Maribor, Faculty of Electrical Engineering and Computer Science (FERI), taught by the third author, and of the Compilers course (third year) at the University of Ljubljana, Faculty of Computer and Information Science (FRI), taught by the first author. Both courses cover similar topics. In particular, topics at the University of Maribor were: regular expressions and lexical analysis, context-free grammar (CFG), Backus–Naur form (BNF), top–down and bottom–up parsing, backtracking parser, LL(1) grammars, left recursion elimination, left factoring, recursive-descent parser, LR(0) parser, BNF for simple DSLs (e.g., [
61]), AGs (S-attributed grammars, L-attributed grammars, absolutely non-circular attribute grammars), compiler generators, denotational semantics, and operational semantics. At the University of Ljubljana, the topics included in a course cover all phases of the non-optimizing compiler: lexical and syntax analysis (regular expression based lexers, LL and LR parsers), type systems and semantic analysis, stack frames and calling conventions, translation into intermediate code, basic blocks and traces, instruction selection, liveness analysis and register allocation; through the course, a compiler is written by each student individually.
The experiment was performed simultaneously for both groups and close to the end of the course, with the aim that all the needed materials were covered before the experiment. The students performed the experimental tasks as part of the course assignments. The students’ participation was optional, and their participation was rewarded. Based on the correctness of their answers, the participants earned up to a 10% bonus on their assignment grade for the course. We chose to base the bonus on correctness to help motivate the participants to devote adequate effort to the tasks.
The experiment consisted of a background questionnaire, two tests and a feedback questionnaire after each test. The aim of the background questionnaire was to obtain participants’ perceptions/beliefs on their own knowledge of programming, compilers, AGs and their interest in programming and compilers. The first test was common to both groups of participants, with the aim to measure general knowledge about AGs. It consisted of seven tasks:
Identification of the kind of an attribute (synthesized or inherited).
Identification of a missing semantic rule for an unknown attribute.
What is the meaning of a simple AG?
Identification of AG type (S-attributed grammar, L-attributed grammar, absolutely non-circular AG, circular AG).
Is the provided specification an L-attributed AG?
Identification of a wrong AG among several correctly provided AGs.
Identification of a superficial semantic rule.
The second test was different for both groups. We made a conscious decision that the group that would perform better on the first test would be confronted with automatically generated AGs. Therefore, Group I (students from the University of Maribor, FERI) received tasks for AGs written by a language designer, whilst Group II (students from the University of Ljubljana, FRI) received tasks from automatically generated AGs. The tasks were the same, but the AGs were different (manually written vs. automatically generated). Hence, this was a between-subjects study. The second test consisted of seven tasks:
Identification of a correct AG for the language.
Identification of a correct AG for simple expressions.
Identification of a correct AG for the Robot language.
Identification of a correct AG for a simple where statement.
Correct a wrong semantic rule in AG for the language.
Correct a wrong semantic rule in AG for simple expressions.
Correct a wrong semantic rule in AG for the Robot language.
After each test, the feedback questionnaires were given to participants measuring the participants’ individual perspectives on the experiment. Namely, the participants expressed their opinion about the simplicity of the AGs in the experimental tasks.
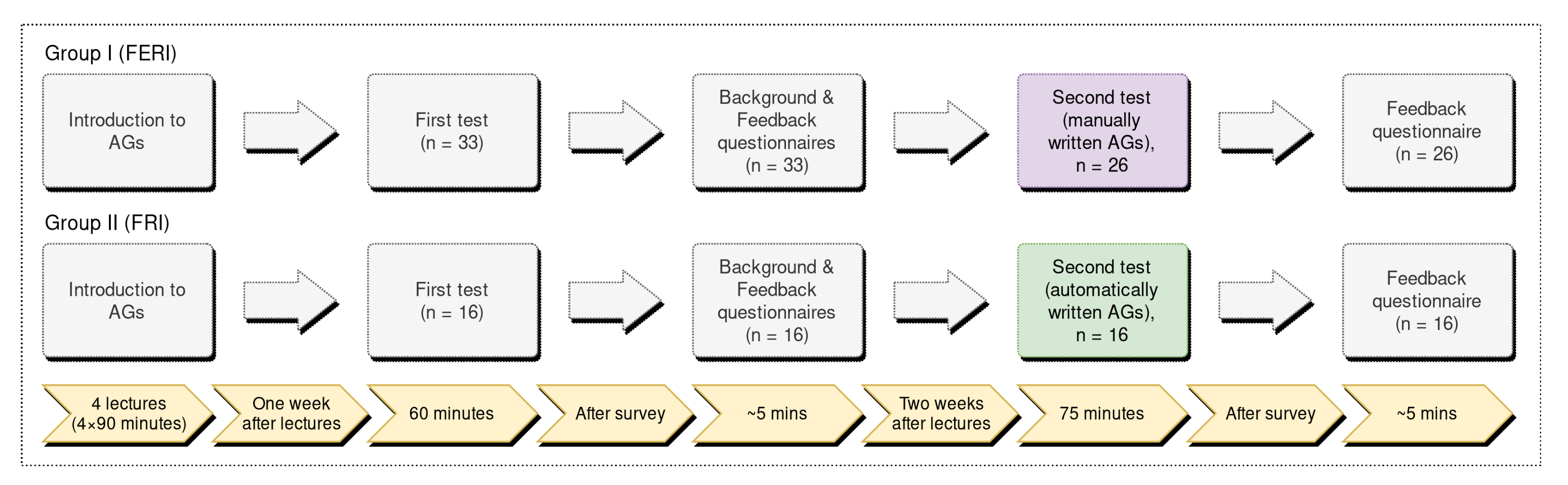
Figure 1 summarizes the overall design of the controlled experiment. After giving lectures on AGs, the participants were exposed to the first test, which lasted for 60 min, followed by 5 min of background and feedback questionnaires. In Group I (FERI), there were 33 participants, and in Group II (FRI), there were 16 participants. Seven participants from Group I (FERI) decided not to participate in the second test, which lasted for 75 min, followed by the 5 min feedback questionnaire. Note that participation in both experiments was voluntary.
We used Moodle as an online system for conducting the tests and feedback/background studies. The code inside the questions was translated into Figures with indentation and highlighted syntax. Code execution was prevented in this manner. Thus, debugging support (watch, variable list, etc.), editor functionalities (auto-complete, find and replace), and other specialized auxiliary tools (e.g.,
Figure 2 or
Figure 3) were also prevented. Only manual program comprehension was possible.
As the basis for this experiment, we formulated two hypotheses, one on correctness and one on efficiency:
There is no significant difference in the correctness of the participants’ comprehension of AGs when using manually written AGs vs. automatically generated AGs.
There is a significant difference in the correctness of the participants’ comprehension of AGs when using manually written AGs vs. automatically generated AGs.
There is no significant difference in the efficiency of the participants’ comprehension of AGs when using manually written AGs vs. automatically generated AGs.
There is a significant difference in the efficiency of the participants’ comprehension of AGs when using manually written AGs vs. automatically generated AGs.
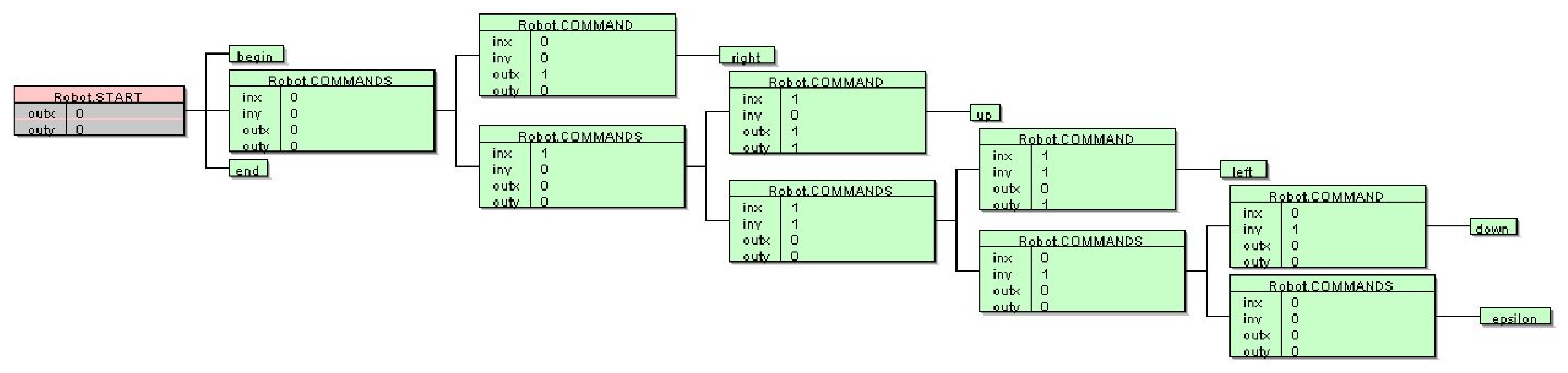
To give the reader a glimpse of a difference between a manually written vs. automatically generated AG, we provided an example for the Robot language. Listing 1 shows a manually written AG which is easy to comprehend. The initial robot position
is set in the rule
and represented with two inherited attributes,
and
. The final position is stored into two synthesized attributes:
and
, whilst the propagation of a position from one command to the next command is described in the rule
. Changing a position after one command (
,
,
,
) is described in the rule
. In
Figure 2, the semantic tree for the program
is shown. The propagation of the position can be observed nicely. The robot starts at position
, and the command
changed it to the position
and passed it to the command
, which resulted in intermediate position
. This position is then passed to the command
, which changes the robot’s position to
. Finally, this position is passed to the command
, which moves the robot back to the position
. This is the final position that is propagated to the root node (
Figure 2).
| Listing 1. Manually written AG for the Robot language. |
| language Robot { |
| lexicon { keywords begin | end |
| operation left | right | up | down |
| ignore [\0x0D\0x0A\ ] |
| } |
| attributes int *.inx; int *.iny; int *.outx; int *.outy; |
| rule start { |
| START ::= begin COMMANDS end compute { |
| START.outx = COMMANDS.outx; |
| START.outy = COMMANDS.outy; |
| COMMANDS.inx = 0; |
| COMMANDS.iny = 0; |
| }; |
| } |
| rule commands { |
| COMMANDS ::= COMMAND COMMANDS compute { |
| COMMANDS[0].outx = COMMANDS[1].outx; |
| COMMANDS[0].outy = COMMANDS[1].outy; |
| COMMAND.inx = COMMANDS[0].inx; |
| COMMAND.iny = COMMANDS[0].iny; |
| COMMANDS[1].inx = COMMAND.outx; |
| COMMANDS[1].iny = COMMAND.outy; |
| } |
| | epsilon compute { |
| COMMANDS[0].outx = COMMANDS[0].inx; |
| COMMANDS[0].outy = COMMANDS[0].iny; |
| }; |
| } |
| rule command { |
| COMMAND ::= left compute { |
| COMMAND.outx = COMMAND.inx - 1; |
| COMMAND.outy = COMMAND.iny; |
| }; |
| COMMAND ::= right compute { |
| COMMAND.outx = COMMAND.inx + 1; |
| COMMAND.outy = COMMAND.iny; |
| }; |
| COMMAND ::= up compute { |
| COMMAND.outx = COMMAND.inx; |
| COMMAND.outy = COMMAND.iny + 1; |
| }; |
| COMMAND ::= down compute { |
| COMMAND.outx = COMMAND.inx; |
| COMMAND.outy = COMMAND.iny - 1; |
| }; |
| } |
| } |
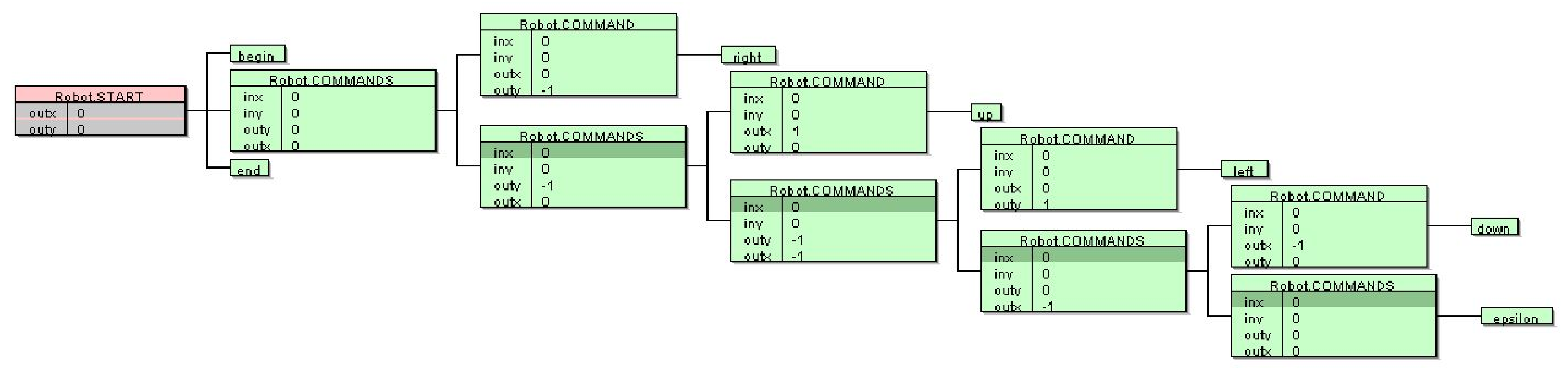
On the other hand, an automatically generated AG using Semantic Inference (Listing 2) is not intuitive anymore. The solution found by GP is an unexpected solution and contains code bloat (e.g.,
in the rule
). The robot’s position is not propagated anymore. The important information about one command (
,
,
,
) is stored in a command node. For example, the meaning of the command
is always
. After the sequence of two commands, both positions need to be summed up. The computation is further complicated due to exchanging the
and
coordinates (see
Figure 3). Just comparing the code sizes of Listings 1 and 2, it can be noticed that, in the 20 semantic equations which appear in both Listings, there are 28 operands and operators in Listing 1, whilst 42 operands and operators in Listing 2. The average number of operands and operators per semantic rule is 1.4 in Listing 1 and 2.1 in Listing 2. This is a 50% increase, which shows how the complexity of automatically generated solutions increases over manually written solutions. The increased complexity can be attributed to both code bloat and unexpected solutions.
| Listing 2. Automatically generated AG for the Robot language. |
| language Robot { |
| lexicon { |
| keywords begin | end |
| operation left | right | up | down |
| ignore [\0x0D\0x0A\ ] |
| } |
| |
| attributes int *.inx; int *.iny; |
| int *.outx; int *.outy; |
| |
| rule start { |
| START ::= begin COMMANDS end compute { |
| START.outx = COMMANDS.outy; |
| START.outy = COMMANDS.iny+COMMANDS.outx; |
| COMMANDS.inx=0; |
| COMMANDS.iny=0; |
| }; |
| } |
| |
| rule commands { |
| COMMANDS ::= COMMAND COMMANDS compute { |
| COMMANDS[0].outx = COMMANDS[1].outx+COMMAND.outx; |
| COMMANDS[0].outy = COMMANDS[1].outy-COMMAND.outy; |
| COMMAND.inx = 0; |
| COMMAND.iny = 0; |
| COMMANDS[1].inx = 0+COMMANDS[1].outy; |
| COMMANDS[1].iny = COMMAND.iny; |
| } |
| | epsilon compute { |
| COMMANDS[0].outx = COMMANDS[0].iny-COMMANDS[0].outy; |
| COMMANDS[0].outy = 0; |
| }; |
| } |
| |
| rule command { |
| COMMAND ::= left compute { |
| COMMAND.outx = COMMAND.iny-0; |
| COMMAND.outy = 1+0; |
| }; |
| COMMAND ::= right compute { |
| COMMAND.outx = COMMAND.inx-COMMAND.iny; |
| COMMAND.outy = 0-1; |
| }; |
| COMMAND ::= up compute { |
| COMMAND.outx = 1; |
| COMMAND.outy = 0+0; |
| }; |
| COMMAND ::= down compute { |
| COMMAND.outx = 0-1; |
| COMMAND.outy = COMMAND.iny; |
| }; |
| } |
| } |
4. Results
This section compares the comprehension correctness and comprehension efficiency of programming language specifications written manually by a language designer vs. their comprehension correctness and comprehension efficiency of programming language specifications automatically generated by GP in the field of semantic inference [
17,
18]. It also presents the results from the background and feedback questionnaires. All the observations were statistically tested with
as a threshold for judging significance. The Shapiro–Wilk test of normal distribution was performed for all the data. If the data were not normally distributed, we performed a non-parametric Mann–Whitney test for two independent samples. If the data were normally distributed, we performed the parametric independent Sample T-test.
Table 1 shows the results from the background questionnaire wherein the participants’ own beliefs were captured on their knowledge on programming, compilers, and AGs. Here, we used a five-point Likert scale, with 1 representing low and 5 representing high knowledge. From
Table 1, it can be observed that there was no statistically significant difference in the participants’ opinions about their knowledge on programming and AGs. However, the participants in Group II (FRI) expressed a statistically significant difference in their opinion about their knowledge about compilers. Similarly, from
Table 2, where participants’ own interest in programming and compilers are presented, it can be observed that there was no statistical significance in participants’ opinions about their interest in programming. However, there was a significant statistical difference in participants’ opinions about their interest in compilers. Both statistical significant differences in participants’ opinions about their knowledge and interest in compilers can be explained with the fact that the compilers’ course at the University of Ljubljana is an elective course. Therefore, participants from Group II (FRI) had a higher interest in compilers, and their opinion about knowledge on compilers was higher than participants’ opinions from Group I (FERI).
Table 3 shows the results of comprehension correctness for the first test measuring general knowledge about AG. Both groups, Group I (FERI) and Group II (FRI), solved the same seven tasks. It can be observed from
Table 3 that Group II (FRI) statistically performed significantly better. Its average comprehension correctness was slightly above 70%, whilst the average comprehension correctness of Group I (FERI) was only slightly above 50%. Some explanations that Group II (FRI) performed better than Group I (FERI) are:
Participants in Group II (FRI) are more experienced (third-year students) than participants in Group I (FERI) (second-year students).
The course of Group II (FRI) was elective, whilst the course of Group I (FERI) was mandatory. Therefore, the participants of Group II (FRI) had higher interest in the compiler course.
The threats to validity (
Section 5) discusses other possible reasons for which Group II (FRI) performed better on the first test than Group I (FERI).
Table 4 shows the results of comprehension correctness for the second test. Both groups had seven tasks. However, Group I (FERI) was exposed to manually written AGs, whilst Group II (FRI) was exposed to automatically generated AGs using GP in the field of semantic inference [
17,
18]. As such, those solutions suffered from the code bloat problem and many solutions were unexpected. It can be observed from
Table 4 that Group I (FERI) statistically performed significantly better than Group II (FRI) on the second test. Its average comprehension correctness was slightly below 80%, whilst the average comprehension correctness of Group II (FRI) was only slightly above 50%. AGs for simple languages such as
, simple expressions, the Robot language, and simple where statements manually written by a language designer were intuitive and easy to understand. On the other hand, Group II (FRI) performed statistically significantly worse on the second test, since the automatically generated AGs were not intuitive anymore, presumably due to the code bloat problem and unexpected solutions. Although Group II (FRI) had better results from the first test measuring general knowledge about AGs, it was statistically significantly outperformed by Group I (FERI) on the second test. Hence, we can conclude that automatically generated solutions by GP in the field of semantic inference [
17,
18] are indeed harder to comprehend than manually written solutions.
Table 5 shows the average correctness of tasks in both tests. In the first test, Group II’s (FRI) comprehension correctness was much higher than Group I (FERI) for every task except Q4, which was about the identification of the AG type (S-attributed grammar, L-attributed grammar, absolutely non-circular AG, circular AG). On task Q4, Group I (FERI) was only slightly better (57.58%) than Group II (FRI) (50.00%). The Mann–Whitney statistical test (
Table 3) shows that the comprehension correctness of Group II (FRI) was statistically significantly better than Group I (FERI) in the first test. In the second test, the opposite was true. Group I (FERI), which was exposed to manually written AGs, performed better than Group II (FRI), which was exposed to automatically generated AGs using GP on all tasks except Q4 and Q7. Task Q4 in the second test was about the identification of a correct AG for a simple where statement. It turned out that the automatically generated AG for task Q4 was the same as the manually written AG. The GP solution, in this case, did not produce code bloat or an unexpected solution. Since participants’ knowledge about AG of Group II (FRI) was higher than in Group I (FERI) (
Table 3), the correctness of Q4 in the second test was again higher within Group II (FRI) (87.50%) than within Group I (FERI) (69.23%). Task Q7 in the second test was about correcting a wrong semantic rule in an AG for the Robot language. A robot’s initial position was wrong, and finding a correct semantic rule was not so difficult, even in the automatically generated AG. Therefore, the correctness of task Q7 of Group II (FRI) was again better (87.50%) than that of Group I (FERI) (80.77%). On all other tasks (Q1–Q3, Q5–Q6), Group I (FERI) performed better than Group II (FRI). Task Q3 (identification of a correct AG for the Robot language—Listing 2), was especially difficult for participants of Group II (FRI), and nobody solved this task correctly. The Mann–Whitney statistical test (
Table 4) shows that the comprehension correctness of Group I (FERI) was statistically significantly better than Group II (FRI) in the second test.
Similarly to many other studies (e.g., [
15,
16,
33]), comprehension efficiency is measured as the ratio of the percentage of correctly answered questions to the amount of time spent answering the questions (hence, higher values are better than lower values).
Table 6 shows that Group II (FRI) was statistically significantly more efficient than Group I (FERI) on the first test, whilst the opposite was true for the second test (
Table 7). Overall, the results on comprehension efficiency (
Table 6 and
Table 7) corroborated the results on comprehension correctness (
Table 3 and
Table 4).
Table 8 shows the results from the feedback questionnaire after performing both tests. In the feedback questionnaire, we captured participants’ individual perspectives on the simplicity of AGs in each of the seven tasks. Again, we used a five-point Likert scale with 1 representing low and 5 representing high simplicity. In the statistical analysis (
Table 8), we used the average result on the simplicity of seven AGs (tasks). In the first test, the participants of Group II (FRI) found AGs simpler than the participants of Group I (FERI). The difference was statistically significant. The comprehension correctness (
Table 3) and comprehension efficiency (
Table 6) of Group II (FRI) were also statistically significantly better than Group I (FERI). The results for the second test did not surprise us. There was a statistically significant difference in participants’ opinions about the simplicity of AGs. Group I (FERI) participants’ opinions were that manually written AGs are simpler (note that five participants did not return the feedback questionnaire after the second test), whilst Group II (FRI) participants’ opinions were that automatically generated AGs are not simple anymore (note that one participant did not return the feedback questionnaire after the second test). This opinion was tested and verified in a scientific manner in our controlled experiment. The results from
Table 3,
Table 4,
Table 5,
Table 6 and
Table 7 allow us to reject both null hypotheses
and
and accept the alternative hypotheses formulated in
Section 3:
There is a significant difference in the correctness of the participants’ comprehension of AGs when using manually written AGs vs. automatically generated AGs.
There is a significant difference in the efficiency of the participants’ comprehension of AGs when using manually written AGs vs. automatically generated AGs.
5. Threats to Validity
In this section, we discuss the construct, internal and external validity threats [
62] to the results of our controlled experiment [
63].
Construct validity is about how well we can measure the properties under consideration [
64,
65]. In our experiment, we wanted to measure the comprehension or understandability of manually written and automatically generated AGs using GP in the field of semantic inference. In this respect, we designed several tasks in which the participants had to understand the provided AGs. We started with simple tasks, such as the identification of the kind of an attribute (synthesized or inherited), a missing semantic rule, the identification of AG type (S-attributed grammar, L-attributed grammar, absolutely non-circular AG, and circular AG), and the identification of a superficial semantic rule. Only a partial understanding of the whole AG is needed in these tasks. In the following tasks, the participants needed to understand complete AGs (e.g., for the Robot language) in order to solve a task correctly. With the variety of tasks, we believe that construct validity has been addressed well, since solving various tasks measures participants’ comprehension ability about AGs indirectly. In addition to comprehension, efficiency was measured as well. Efficiency was measured as the ratio of correctly answered questions to the amount of time spent answering the questions. Both correct answers and time were easy to measure. Overall, we believe that threats to construct validity were minimized successfully.
Internal validity concerns inferences between the treatment and the outcome. Are there other confounding factors that could have caused the outcome? Since the answers were given to the participants, there always exists a chance that participants guessed the correct answer. This internal validity threat was mitigated with the large number of possible answers (five options) and large number of tasks (2 × 7 = 14 tasks). Note that the order of tasks was fixed, and the same for all participants without the possibility of returning to a previous task. However, possible answers for the task were assigned between participants randomly. From the aforementioned course description at both universities (
Section 3), it can be observed that the topics were similar, but not the same. To eliminate some threats to internal validity, the same teaching material about AGs in the form of slides was prepared and explained to students in both groups (Group I—second-year students at the University of Maribor, FERI; Group II—third-year students at the University of Ljubljana, FRI). Although the material was the same, there were still two different instructors. Hence, we did not eliminate all threats to internal validity. However, we have no reason to believe that different styles of presenting AGs to participants and the slightly different topics covered in both courses (Compiling Programming Languages and Compilers) influenced the outcome of the experiment. There is no other reasonable explanation as to why Group II (FRI) performed worse on the second test rather than that the automatically generated AGs are harder to comprehend due to code bloat and unexpected solutions. Note that Group II (FRI) performed statistically significantly better on the first test. Therefore, despite better knowledge about AGs, Group II (FRI) performed statistically significantly worse on the second test. After the first test, seven students from Group I (FERI) chose not to participate in the second test. We also re-ran the statistics for the first test by eliminating those students from the first test, and the result was the same. Namely, Group II (FRI) still performed statistically significantly better than Group I (FERI). Hence, we believe that the students who dropped out in the second test did not change the sample considerably. However, another threat to internal validity can be the different tasks given to Group I (FERI) and Group II (FRI). The first test was the same for both groups, whilst in the second test, the tasks were the same. However, Group I (FERI) was exposed to manually written AGs and Group II (FRI) was exposed to automatically generated AGs. Since the tasks were the same, this internal threat was eliminated or at least minimized.
External validity refers to the extent to which results from a study can be generalized. Since only students participated in our experiment, there is an external validity threat whether results can also be generalized to professional programmers. Another external validity threat is generalization to all applications of GP (e.g., Lisp programming [
1,
3], event processing rules [
66], trading rules [
7], model-driven engineering artifacts [
9]). In our case, GP was used in semantic inference wherein AGs were automatically generated. Due to code bloat and unexpected solutions, many believe that such solutions are harder to comprehend. In this study, it is shown that there is a statistically significant difference in the comprehension correctness and comprehension efficiency of manually written AGs vs. automatically generated AGs.
6. Conclusions
There is a common belief that programs (specifications, models) [
67], which are automatically generated using the Genetic Programming (GP) approach [
1,
2,
3], are harder to comprehend than manually written programs, due to code bloat and unexpected solutions [
10,
11,
12]. In this paper, a more scientific approach is used to prove these claims for the first time to the best of our knowledge. A controlled experiment was designed, where the participants were exposed to manually written and automatically generated attribute grammar (AG) specifications [
23,
24], which were written using LISA domain-specific language (DSL). From such programs (specifications), as can be seen, for example, Listings 1 and 2, various language-based tools (e.g., compiler/interpreter, debugger, profilers) can be automatically generated [
20,
68]. The main findings from our experiment are that there is a significant difference in the comprehension correctness and comprehension efficiency of manually written AGs vs. automatically generated AGs. Hence, we can conclude that solutions automatically generated by GP in the field of semantic inference [
17,
18] are indeed harder to comprehend than manually written solutions. On the other hand, by comparing manual and automatically generated solutions, we can nicely observe how machines could be our complement in solving interesting and complex problems, despite that they are harder to understand due to human restrictions.
As with any empirical study, these results must be taken with caution. Additional replications are needed of this study. Study replications can increase the trustworthiness of the results from empirical studies if performed correctly [
69]. Hence, we urge other researchers to perform such studies using GP in other research fields (e.g., Lisp programming [
1,
3], event processing rules [
66], trading rules [
7], and model-driven engineering artifacts [
9]). Furthermore, additional controlled experiments are needed, involving not only students but also practitioners (e.g., professional programmers).
In this study, the controlled experiment was designed in a manner that lower comprehension correctness and comprehension efficiency can be attributed to both code bloat and unexpected solutions. As a future work, we would like to check how much code bloat alone affects comprehension correctness and comprehension efficiency. However, another future direction would be how the code bloat and unexpected solutions influence explainability. Users are more likely to apply artificial intelligence (AI) if they can understand the results of AI artifacts, and explainable artificial intelligence (XAI) refers to techniques to understand AI artifacts better [
70].








{kind=link}
{kind=link}
{kind=link}