3.2.1. Graph Construction and Embedding Propagation
In the BiInfGCN model, the left-hand side is a graph convolution structure based on the user–item bipartite graph, which mainly contains a bipartite graph construction layer, initial embedding layer, and embedding propagation layer. First, according to Definition 2, a user–item bipartite graph is constructed based on the interaction between users and items. Then, the initial embeddings of user and item are obtained by the initial embedding layer. The GCN-like propagation architecture is constructed in the embedding propagation layer, and the graph convolution operation is performed by an iterative method so that each node eventually aggregates the features of its neighbor nodes. The user node aggregation is shown in Equation (1). Specifically, taking the user node
as an example, the node
in the
layer of the graph convolution aggregates the features of the neighboring nodes in the
layer. Similarly, the item node
in the
layer aggregates the features of the neighboring nodes in the
layer, and the aggregation is shown in Equation (2).
During the aggregation process, a symmetric normalization term is added, which is in accordance with standard GCN design and can effectively prevent the excessive increase of embedding size during graph convolution. The final user (item) embedding representation uses the right-value sum of the embeddings of each convolutional layer, as shown in Equations (3) and (4):
where
K denotes the number of convolutional layers and the weight-value parameter for each convolutional layer is adjustable. The final embeddings of users and items obtained from the “left tower” structure are denoted as
,
, respectively. The loss function
lossleft is calculated from the user and item embeddings obtained from the “left tower” structure as shown in Equation (5).
and
are defined as the inner product of user and item final representations, such as
.
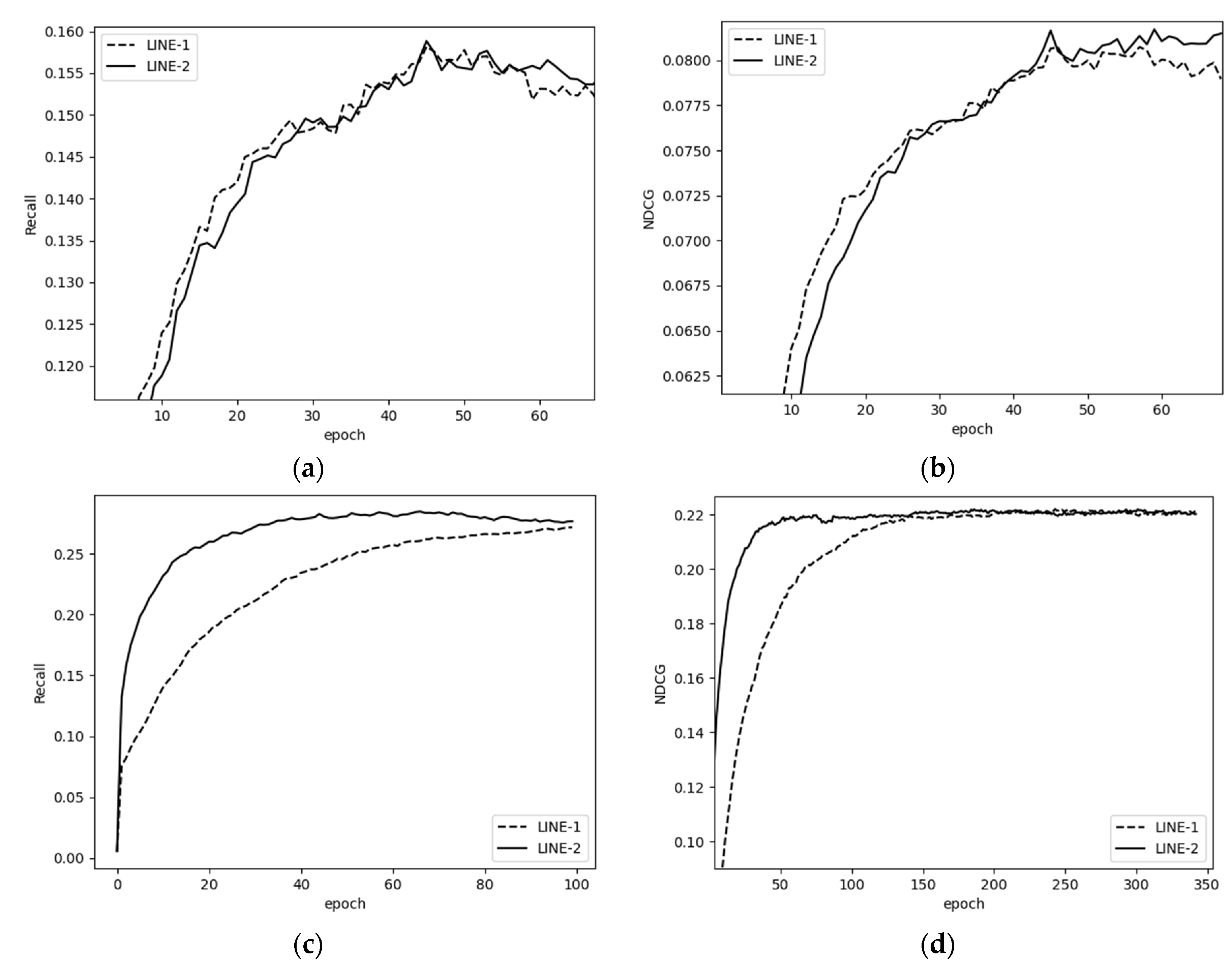
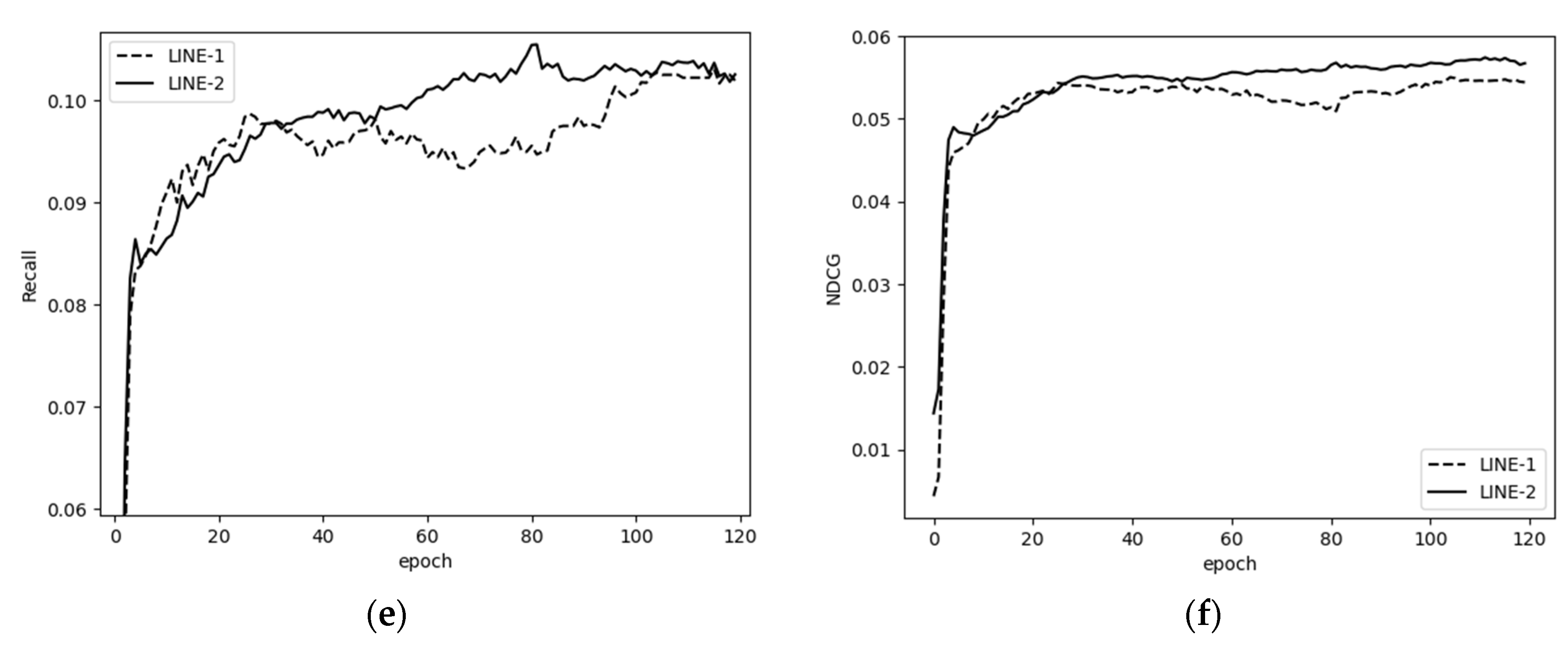
The right side shows the graph embedding structure based on an item–item homomorphic network. It mainly includes a homogeneous graph construction layer and a graph embedding representation layer. First, according to Definition 3, the item–item isomorphic graph is constructed, and then the final items’ embeddings are obtained by using the graph embedding layer. We used two approaches to learn the information network embedding, which are referred to as LINE 1 and LINE 2 in the following.
If two item nodes in the network are directly connected, then it indicates that the node pair is more closely related and should have high similarity.
First-order similarity mainly characterizes the local similarity structure in the network. Supposing there exists an edge between item nodes
and
, and the embeddings of
and
are
and
, respectively, define the co-occurrence probability between the two as shown in Equation (6), and the empirical distribution between the two exists as shown in Equation (7):
where
denotes the weight of edge
and
is the sum of the weights of all edges. The goal is to make the co-occurrence probability as close as possible to the empirical distribution, i.e., to minimize Equation (8).
denotes the distance between the two distributions. Further, by introducing KL scatter, Equation (8) can be reduced to Equation (9). Finally, model training by minimizing the objective Equation (9) can lead to a low-dimensional dense embedding representation of item nodes.
When the item–item network is constructed, the relationship between two nodes directly connected is certainly close, but it fails to fully reflect the structural information of the network. Here, the neighbors of the nodes are taken as the context information of the current node, and the relationship between two nodes is closer assuming that there are more common neighbors, i.e., two nodes have more similar context information. On this basis, the second-order similarity aggregates both the neighboring node information and the structural information of the node when calculating the node embedding representation. In second-order similarity, each node acts as a central node and also as a context node for other central nodes. Therefore, there exists a central vector representation and a context vector representation for each item node. Suppose there exists an edge e between item nodes
. The embedding of
as the central node is
and the embedding of
as the contextual node is
. Define the probability of generating context node
with
as the central node as shown in Equation (10):
where |
V| denotes the number of nodes in the network. The conditional of the distribution with node
as the central node can be expressed as
. Meanwhile, there exist empirical distribution probabilities as shown in Equation (11):
where
is the weight of edge
and
denotes the set of its contextual nodes when
is the central node, i.e., the set of neighboring nodes of node
. Therefore, the empirical distribution with node
as the central node can be expressed as
. Again, the goal is to make the conditional distribution approximate the empirical distribution and introduce
KL scatter to characterize the distance between the conditional and empirical distributions. We use the degree
of a node to denote the weight of that node in the network. We can obtain the objective function as shown in Equation (12).
Equation (13) is obtained by eliminating non-influential parameter simplification. We can arrive at a low-dimensional dense item node embedding representation by minimizing the objective function (13).
By LINE I or LINE II, we can obtain the item embedding matrix of the “right tower” structure, denoted as .
3.2.3. Model Optimization
The experiments used Bayesian personalized ranking (BPR) loss, which is widely used in recommender systems [
36]; this loss function was a personalized ranking algorithm based on Bayesian posterior optimization. The core aim was to personalize the recommendation by modeling the user’s preferences, calculating the items of potential interest to the user, and selecting the items from which the user has not interacted for ranking. The BPR loss function is calculated as shown in Equation (19):
where
denotes the set of positive and negative user–item pairs obtained from the “left tower” structure. Similarly,
denotes the set of user–item positive and negative sample pairs obtained from the “right tower” structure.
denotes the final set of user–item positive and negative sample pairs. The
loss function makes both sides of the structure (“left tower” and “right tower”) learn from each other during the back-propagation process.
denotes the Sigmoid function.
is the canonical term, where
is a tunable parameter and
is a two-parameter number to prevent overfitting by adjusting the parameter size.
is actually the initial representation vector of users and items in this loss function, i.e.,
, and
,
. Therefore, the trainable parameters in this model are the initial vector representations of users and items, and the model is optimized using stochastic gradient descent. The experiments used the control variable method to train the model by adjusting the main parameters, and after several experiments, the main parameters were set as shown in
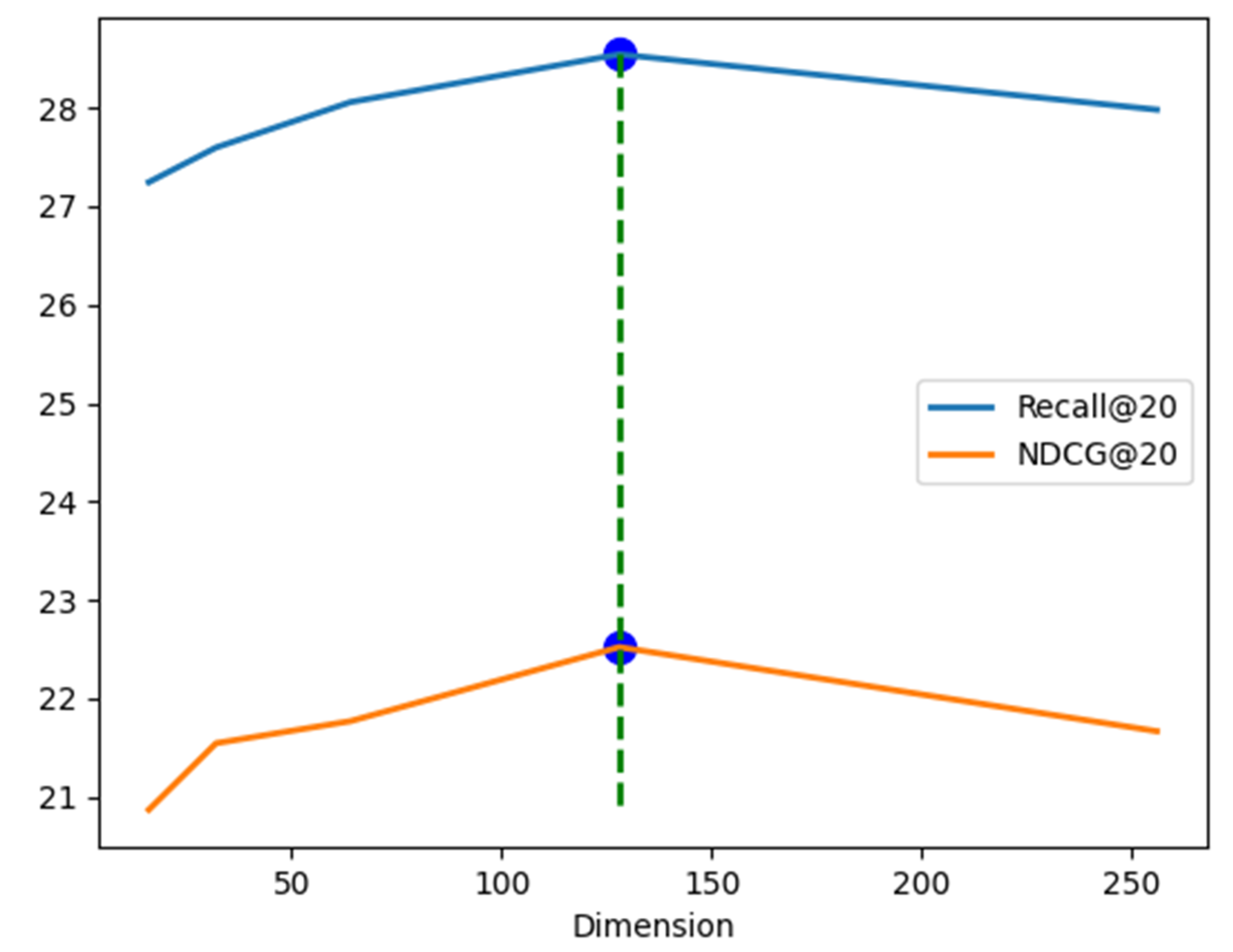
Table 2. The BiInfGCN model can achieve the best results under comprehensive conditions.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}