
Enhancing the Transferability of Adversarial Examples with Feature Transformation


Abstract
:1. Introduction
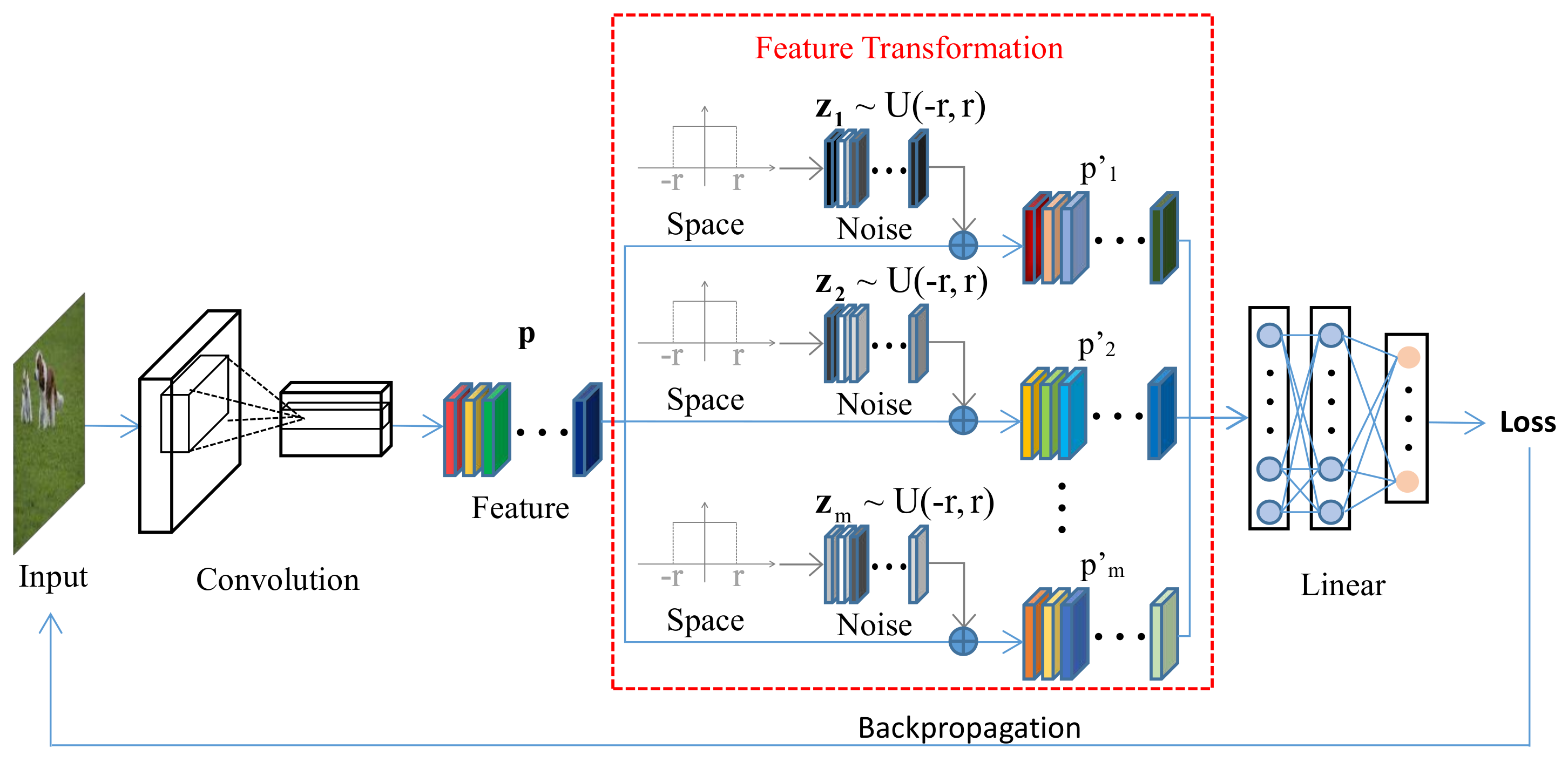
- This work proposes a novel feature transformation-based method (FTM) for enhancing the transferability of adversarial examples.
- We propose several feature transformation strategies and comprehensively analyze the hyper-parameters of them.
- The experimental results on two benchmark datasets show that FTM could effectively improve the attack success rate of the SOTA methods.
2. Related Work
2.1. Adversarial Example and Transferability
2.2. Advanced Gradient Calculation
2.3. Input Transformations
2.4. Adversarial Defense
3. Our Approach
| Algorithm 1 Algorithm of FTM. |
| Input: Original image x, true label , a classifier , loss function J, feature transformation Hyper-parameters: Perturbation size , maximum iterations T, number of iterations of feature transformation m Output: Adversarial example 1: perturbation size in each iteration: 2: while . 3: if . 4: . 5: end if 6: 7: while 8: feature: 9: transformed feature: 10: Get the gradients by 11: Update 12: end while 13: Get average gradients as 14: Update } 15: end while 16: return |
4. Experimental Results
4.1. Experiment on ImageNet
4.1.1. Experimental Setup
4.1.2. Accuracy-Preserving Transformation
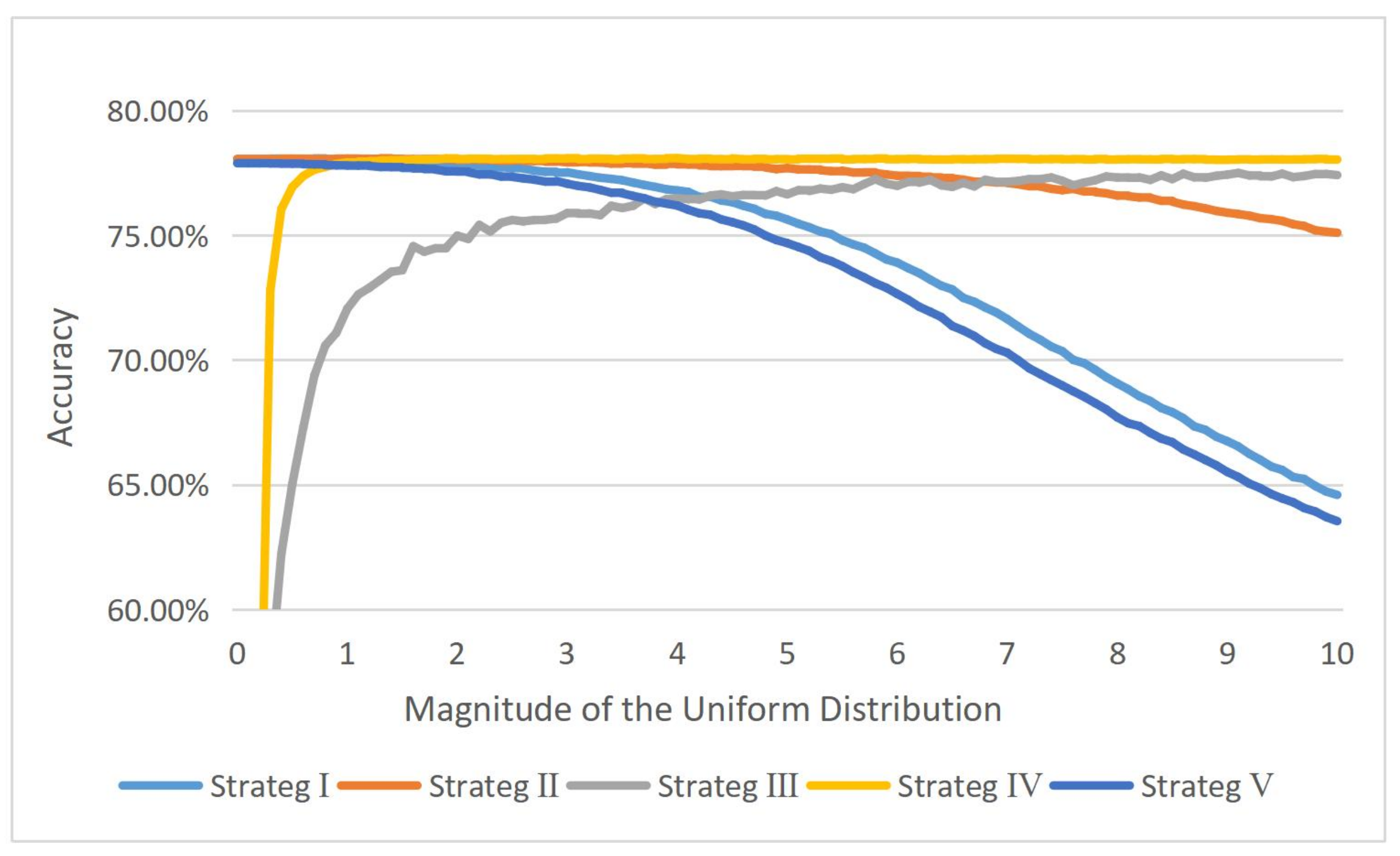
4.1.3. Feature Transformation Strategies
4.1.4. Attack with Input Transformations
4.1.5. Attack against Defense Method
4.1.6. Parameter Analysis
4.2. Experiment on Cifar10
Cifar10
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Gou, J.; Yuan, X.; Du, L.; Xia, S.; Yi, Z. Hierarchical Graph Augmented Deep Collaborative Dictionary Learning for Classification. IEEE Trans. Intell. Transp. Syst. 2022. [Google Scholar] [CrossRef]
- Gou, J.; Sun, L.; Du, L.; Ma, H.; Xiong, T.; Ou, W.; Zhan, Y. A representation coefficient-based k-nearest centroid neighbor classifier. Expert Syst. Appl. 2022, 194, 116529. [Google Scholar] [CrossRef]
- Gou, J.; He, X.; Lu, J.; Ma, H.; Ou, W.; Yuan, Y. A class-specific mean vector-based weighted competitive and collaborative representation method for classification. Neural Netw. 2022, 150, 12–27. [Google Scholar] [CrossRef] [PubMed]
- Koo, J.H.; Cho, S.W.; Baek, N.R.; Lee, Y.W.; Park, K.R. A Survey on Face and Body Based Human Recognition Robust to Image Blurring and Low Illumination. Mathematics 2022, 10, 1522. [Google Scholar] [CrossRef]
- Wang, T.; Ji, Z.; Yang, J.; Sun, Q.; Fu, P. Global Manifold Learning for Interactive Image Segmentation. IEEE Trans. Multimed. 2021, 23, 3239–3249. [Google Scholar] [CrossRef]
- Cheng, C.; Wu, X.J.; Xu, T.; Chen, G. UNIFusion: A Lightweight Unified Image Fusion Network. IEEE Trans. Instrum. Meas. 2021, 70, 1–14. [Google Scholar] [CrossRef]
- Liu, Q.; Fan, J.; Song, H.; Chen, W.; Zhang, K. Visual Tracking via Nonlocal Similarity Learning. IEEE Trans. Circuits Syst. Video Technol. 2018, 28, 2826–2835. [Google Scholar] [CrossRef]
- Zhu, X.F.; Wu, X.J.; Xu, T.; Feng, Z.H.; Kittler, J. Complementary Discriminative Correlation Filters Based on Collaborative Representation for Visual Object Tracking. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 557–568. [Google Scholar] [CrossRef]
- Ma, C.; Rao, Y.; Lu, J.; Zhou, J. Structure-Preserving Image Super-Resolution. IEEE Trans. Pattern Anal. Mach. Intell. 2021. [Google Scholar] [CrossRef]
- Gou, J.; Yu, B.; Maybank, S.J.; Tao, D. Knowledge distillation: A survey. Int. J. Comput. Vis. 2021, 129, 1789–1819. [Google Scholar] [CrossRef]
- Su, Y.; Zhang, Y.; Lu, T.; Yang, J.; Kong, H. Vanishing Point Constrained Lane Detection With a Stereo Camera. IEEE Trans. Intell. Transp. Syst. 2018, 19, 2739–2744. [Google Scholar] [CrossRef]
- Chen, Z.; Wu, X.J.; Yin, H.F.; Kittler, J. Robust Low-Rank Recovery with a Distance-Measure Structure for Face Recognition. In Proceedings of the PRICAI 2018: Trends in Artificial Intelligence, Nanjing, China, 28–31 August 2018; Geng, X., Kang, B.H., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 464–472. [Google Scholar]
- Kortli, Y.; Jridi, M.; Al Falou, A.; Atri, M. Face Recognition Systems: A Survey. Sensors 2020, 20, 342. [Google Scholar] [CrossRef]
- Adjabi, I.; Ouahabi, A.; Benzaoui, A.; Taleb-Ahmed, A. Past, Present, and Future of Face Recognition: A Review. Electronics 2020, 9, 1188. [Google Scholar] [CrossRef]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing properties of neural networks. arXiv 2013, arXiv:1312.6199. [Google Scholar]
- Li, J.; Ji, R.; Liu, H.; Hong, X.; Gao, Y.; Tian, Q. Universal Perturbation Attack Against Image Retrieval. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27–28 October 2019; pp. 4898–4907. [Google Scholar] [CrossRef]
- Liu, H.; Ji, R.; Li, J.; Zhang, B.; Gao, Y.; Wu, Y.; Huang, F. Universal Adversarial Perturbation via Prior Driven Uncertainty Approximation. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27–28 October 2019; pp. 2941–2949. [Google Scholar] [CrossRef]
- Li, H.; Zhou, S.; Yuan, W.; Li, J.; Leung, H. Adversarial-Example Attacks Toward Android Malware Detection System. IEEE Syst. J. 2020, 14, 653–656. [Google Scholar] [CrossRef]
- Kwon, H.; Kim, Y.; Yoon, H.; Choi, D. Fooling a Neural Network in Military Environments: Random Untargeted Adversarial Example. In Proceedings of the MILCOM 2018—2018 IEEE Military Communications Conference (MILCOM), Los Angeles, CA, USA, 29–31 October 2018; pp. 456–461. [Google Scholar] [CrossRef]
- Zhu, Z.A.; Lu, Y.Z.; Chiang, C.K. Generating Adversarial Examples By Makeup Attacks on Face Recognition. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 2516–2520. [Google Scholar] [CrossRef]
- Wang, K.; Li, F.; Chen, C.M.; Hassan, M.M.; Long, J.; Kumar, N. Interpreting Adversarial Examples and Robustness for Deep Learning-Based Auto-Driving Systems. IEEE Trans. Intell. Transp. Syst. 2021. [CrossRef]
- Rana, K.; Madaan, R. Evaluating Effectiveness of Adversarial Examples on State of Art License Plate Recognition Models. In Proceedings of the 2020 IEEE International Conference on Intelligence and Security Informatics (ISI), Arlington, VA, USA, 9–10 November 2020; pp. 1–3. [Google Scholar] [CrossRef]
- Hu, C.; Wu, X.J.; Li, Z.Y. Generating adversarial examples with elastic-net regularized boundary equilibrium generative adversarial network. Pattern Recognit. Lett. 2020, 140, 281–287. [Google Scholar] [CrossRef]
- Li, Z.; Feng, C.; Wu, M.; Yu, H.; Zheng, J.; Zhu, F. Adversarial robustness via attention transfer. Pattern Recognit. Lett. 2021, 146, 172–178. [Google Scholar] [CrossRef]
- Agarwal, A.; Vatsa, M.; Singh, R.; Ratha, N. Cognitive data augmentation for adversarial defense via pixel masking. Pattern Recognit. Lett. 2021, 146, 244–251. [Google Scholar] [CrossRef]
- Massoli, F.V.; Falchi, F.; Amato, G. Cross-resolution face recognition adversarial attacks. Pattern Recognit. Lett. 2020, 140, 222–229. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and Harnessing Adversarial Examples. arXiv 2014, arXiv:1412.6572. [Google Scholar]
- Kurakin, A.; Goodfellow, I.; Bengio, S. Adversarial examples in the physical world. In Proceedings of the International Conference on Learning Representations Workshop, Toulon, France, 24–26 April 2017; pp. 1–14. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, X.; Liu, C.; Song, D. Delving into transferable adversarial examples and black-box attacks. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017; pp. 1–24. [Google Scholar]
- Lin, J.; Song, C.; He, K.; Wang, L.; Hopcroft, J.E. Nesterov Accelerated Gradient and Scale Invariance for Adversarial Attacks. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020; pp. 1–12. [Google Scholar]
- Xie, C.; Zhang, Z.; Zhou, Y.; Bai, S.; Wang, J.; Ren, Z.; Yuille, A.L. Improving Transferability of Adversarial Examples With Input Diversity. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 2725–2734. [Google Scholar] [CrossRef]
- Dong, Y.; Pang, T.; Su, H.; Zhu, J. Evading Defenses to Transferable Adversarial Examples by Translation-Invariant Attacks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 4312–4321. [Google Scholar]
- Wang, X.; He, X.; Wang, J.; He, K. Admix: Enhancing the Transferability of Adversarial Attacks. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 16158–16167. [Google Scholar]
- Dong, Y.; Liao, F.; Pang, T.; Su, H.; Zhu, J.; Hu, X.; Li, J. Boosting Adversarial Attacks with Momentum. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 9185–9193. [Google Scholar] [CrossRef]
- Kurakin, A.; Goodfellow, I.; Bengio, S. Adversarial Machine Learning at Scale. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017; pp. 1–17. [Google Scholar]
- Madry, A.; Makelov, A.; Schmidt, L.; Tsipras, D.; Vladu, A. Towards Deep Learning Models Resistant to Adversarial Attacks. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018; pp. 1–28. [Google Scholar]
- Tramèr, F.; Kurakin, A.; Papernot, N.; Goodfellow, I.; Boneh, D.; Mcdaniel, P. Ensemble Adversarial Training: Attacks and Defenses. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018; pp. 1–22. [Google Scholar]
- Cohen, J.M.; Rosenfeld, E.; Kolter, J.Z. Certified Adversarial Robustness via Randomized Smoothing. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 1–36. [Google Scholar]
- Guo, C.; Rana, M.; Cisse, M.; van der Maaten, L. Countering Adversarial Images using Input Transformations. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018; pp. 1–12. [Google Scholar]
- Xie, C.; Wang, J.; Zhang, Z.; Ren, Z.; Yuille, A. Mitigating Adversarial Effects Through Randomization. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017; pp. 1–16. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Los Alamitos, CA, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar] [CrossRef]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; pp. 4278–4284. [Google Scholar]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–27 July 2017; pp. 1800–1807. [Google Scholar] [CrossRef]
- Krizhevsky, A. Learning Multiple Layers of Features from Tiny Images; University of Toronto: Toronto, ON, USA, 2009; pp. 1–60. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Strategy | Inc_v3 | Inc_v4 | IncRes_v2 | Xcep |
|---|---|---|---|---|---|
| I | - | 36.1 | 33.5 | 35.3 | |
| II | - | 37.3 | 33.7 | 35.1 | |
| FT-FGSM | III | - | 37.0 | 35.9 | 37.5 |
| IV | - | 37.5 | 32.0 | 34.7 | |
| V | - | 37.7 | 33.4 | 34.4 | |
| I | - | 55.1 | 52.5 | 59.8 | |
| II | - | 53.0 | 50.4 | 54.4 | |
| FT-MI-FGSM | III | - | 54.9 | 51.6 | 57.8 |
| IV | - | 53.4 | 50.8 | 56.5 | |
| V | - | 57.0 | 53.3 | 59.2 | |
| I | - | 43.0 | 41.3 | 42.9 | |
| II | - | 38.5 | 34.9 | 39.3 | |
| FT-SIM | III | - | 42.9 | 42.6 | 44.0 |
| IV | - | 42.2 | 42.4 | 43.5 | |
| V | - | 41.1 | 41.9 | 42.6 |
| Local Model | Attack Method | Inc_v3 | Inc_v4 | IncRes_v2 | Xcep |
|---|---|---|---|---|---|
| Inc_v3 | MI-FGSM | - | 51.3 | 49.6 | 53.0 |
| FT-MI-FGSM | - | 54.9 | 51.6 | 57.8 | |
| Inc_v4 | MI-FGSM | 56.0 | - | 48.5 | 55.0 |
| FT-MI-FGSM | 58.9 | - | 53.1 | 64.4 | |
| IncRes_v2 | MI-FGSM | 56.2 | 51.8 | - | 55.9 |
| FT-MI-FGSM | 64.1 | 57.4 | - | 63.0 | |
| Xcep | MI-FGSM | 51.4 | 50.8 | 45.3 | - |
| FT-MI-FGSM | 54.4 | 55.0 | 48.7 | - |
| Local Model | Attack Method | Inc_v3 | Inc_v4 | IncRes_v2 | Xcep |
|---|---|---|---|---|---|
| Inc_v3 | SIM | - | 37.4 | 34.7 | 37.0 |
| FT-SIM | - | 42.9 | 42.6 | 44.0 | |
| Inc_v4 | SIM | 64.0 | - | 51.9 | 59.7 |
| FT-SIM | 71.0 | - | 59.0 | 64.9 | |
| IncRes_v2 | SIM | 62.6 | 52.8 | - | 55.2 |
| FT-SIM | 75.1 | 63.4 | - | 65.2 | |
| Xcep | SIM | 57.9 | 54.3 | 50.0 | - |
| FT-SIM | 63.4 | 58.9 | 53.0 | - |
| Local Model | Attack Method | Inc_v3 | Inc_v4 | IncRes_v2 | Xcep |
|---|---|---|---|---|---|
| Inc_v3 | DIM | - | 59.5 | 55.3 | 56.3 |
| FT-DIM | - | 61.8 | 58.3 | 60.4 | |
| Inc_v4 | DIM | 59.0 | - | 52.0 | 61.7 |
| FT-DIM | 63.4 | - | 56.5 | 66.6 | |
| IncRes_v2 | DIM | 58.6 | 57.7 | - | 60.7 |
| FT-DIM | 67.2 | 66.8 | - | 66.5 | |
| Xcep | DIM | 57.3 | 64.3 | 55.6 | - |
| FT-DIM | 61.8 | 69.1 | 58.2 | - |
| Local Model | Attack Method | Inc_v3 | Inc_v4 | IncRes_v2 | Xcep |
|---|---|---|---|---|---|
| Inc_v3 | Admix | - | 52.8 | 49.1 | 56.2 |
| FT-Admix | - | 57.3 | 54.4 | 60.0 | |
| Inc_v4 | Admix | 70.8 | - | 61.1 | 67.2 |
| FT-Admix | 72.2 | - | 64.0 | 68.3 | |
| IncRes_v2 | Admix | 64.1 | 57.4 | - | 60.5 |
| FT-Admix | 66.0 | 58.7 | - | 60.4 | |
| Xcep | Admix | 70.4 | 64.3 | 60.0 | - |
| FT-Admix | 72.2 | 65.2 | 61.6 | - |
| Attack Method | RandP | JPEG | RS | Nips-r3 |
|---|---|---|---|---|
| SIM | 30.3 | 32.7 | 25.2 | 31.6 |
| FT-SIM | 38.5 | 41.0 | 37.8 | 39.5 |
| Local Model | Attack Method | Res18 | Res34 | Res50 | Res101 | Res152 |
|---|---|---|---|---|---|---|
| Res18 | MIM | - | 78.3 | 68.7 | 67.3 | 71.1 |
| FT-MIM | - | 78.8 | 69.2 | 70.5 | 73.4 | |
| Res34 | MIM | 78.7 | - | 70.0 | 69.5 | 72.3 |
| FT-MIM | 79.8 | - | 72.9 | 71.2 | 74.1 | |
| Res50 | MIM | 76.5 | 76.8 | - | 80.2 | 82.5 |
| FT-MIM | 77.8 | 78.1 | - | 82.4 | 83.8 | |
| Res101 | MIM | 71.4 | 71.7 | 76.9 | - | 80.5 |
| FT-MIM | 74.2 | 73.2 | 79.3 | - | 82.6 | |
| Res152 | MIM | 75.2 | 73.4 | 76.8 | 81.0 | - |
| FT-MIM | 76.8 | 74.9 | 78.7 | 82.0 | - |
| Local Model | Attack Method | Res18 | Res34 | Res50 | Res101 | Res152 |
|---|---|---|---|---|---|---|
| Res18 | SIM | - | 73.0 | 60.1 | 59.5 | 62.3 |
| FT-SIM | - | 73.9 | 62.2 | 62.9 | 66.0 | |
| Res34 | SIM | 74.9 | - | 60.2 | 60.9 | 63.3 |
| FT-SIM | 76.2 | - | 61.5 | 62.8 | 63.4 | |
| Res50 | SIM | 68.0 | 69.3 | - | 70.6 | 71.9 |
| FT-SIM | 72.2 | 68.2 | - | 73.9 | 76.0 | |
| Res101 | SIM | 69.2 | 67.7 | 71.0 | - | 73.9 |
| FT-SIM | 71.5 | 69.9 | 71.9 | - | 75.9 | |
| Res152 | SIM | 65.6 | 62.3 | 63.8 | 66.6 | - |
| FT-SIM | 69.5 | 67.9 | 70.4 | 73.9 | - |
| Local Model | Attack Method | Res18 | Res34 | Res50 | Res101 | Res152 |
|---|---|---|---|---|---|---|
| Res18 | Admix | - | 49.0 | 41.9 | 42.5 | 45.0 |
| FT-Admix | - | 56.4 | 47.3 | 50.4 | 51.9 | |
| Res34 | Admix | 52.5 | - | 42.7 | 46.5 | 46.0 |
| FT-Admix | 58.5 | - | 47.5 | 50.1 | 50.4 | |
| Res50 | Admix | 48.6 | 43.9 | - | 44.9 | 47.4 |
| FT-Admix | 56.1 | 50.7 | - | 53.9 | 54.4 | |
| Res101 | Admix | 48.2 | 44.6 | 44.6 | - | 49.3 |
| FT-Admix | 54.0 | 50.5 | 50.8 | - | 57.7 | |
| Res152 | Admix | 45.3 | 40.6 | 39.5 | 43.1 | - |
| FT-Admix | 55.0 | 51.6 | 50.2 | 55.1 | - |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, H.-Q.; Hu, C.; Yin, H.-F. Enhancing the Transferability of Adversarial Examples with Feature Transformation. Mathematics 2022, 10, 2976. https://doi.org/10.3390/math10162976
Xu H-Q, Hu C, Yin H-F. Enhancing the Transferability of Adversarial Examples with Feature Transformation. Mathematics. 2022; 10(16):2976. https://doi.org/10.3390/math10162976
Chicago/Turabian StyleXu, Hao-Qi, Cong Hu, and He-Feng Yin. 2022. "Enhancing the Transferability of Adversarial Examples with Feature Transformation" Mathematics 10, no. 16: 2976. https://doi.org/10.3390/math10162976
APA StyleXu, H.-Q., Hu, C., & Yin, H.-F. (2022). Enhancing the Transferability of Adversarial Examples with Feature Transformation. Mathematics, 10(16), 2976. https://doi.org/10.3390/math10162976