
Fracture Recognition in Paediatric Wrist Radiographs: An Object Detection Approach




Abstract
:1. Introduction
- We hypothesise that fractures in the near vicinity of the wrist in paediatric X-ray images can be identified and localised efficiently using the YOLOv4 model proposed by Bochkovskiy et al. [15] (an object detection model). We test our hypothesis on a comprehensive expert-annotated paediatric wrist X-ray dataset. Paediatric X-ray images, compared to adult images, are more versatile in terms of injuries, possible diseases, and fracture shapes because of children’s bone growth and organ formation.
- To prove the excellence of the utilised method, we compare it against the current state-of-the-art method for fracture detection proposed by Lindsey et al. [11].
- We compare the results obtained by the trained model with the experts, getting an insight into how well the model performs compared to radiologists—on the same dataset.
- Along the same lines, we investigate radiologists’ performance while they are aided by our model, compared to their performance while they work unaided by it.
2. Materials and Methods
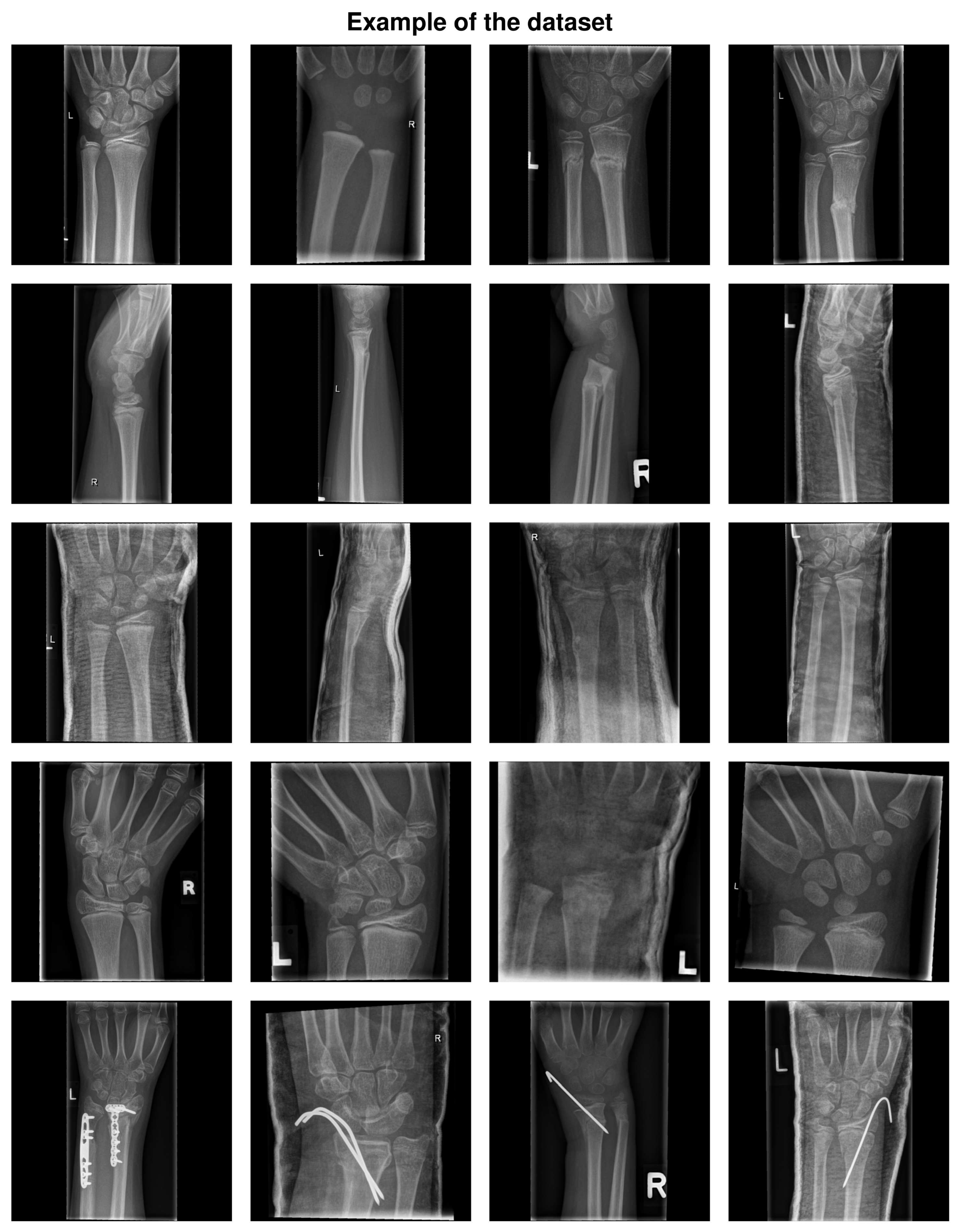
2.1. Dataset
- Training dataset consisting of images.
- Validation dataset consisting of 1950 images, used for model selection (tuning hyperparameter values, such as learning rate or batch size).
- Test dataset #1, consisting of 1950 images, used for the final inspection of models’ generalisation properties.
- Test dataset #2, consisting of 200 images, used for expert evaluation. Of the 200 images, one half did not contain any fractures while the remaining images contained at least one fracture. This kind of selection was important to properly evaluate the models against radiologists.
2.2. Utilised Methods
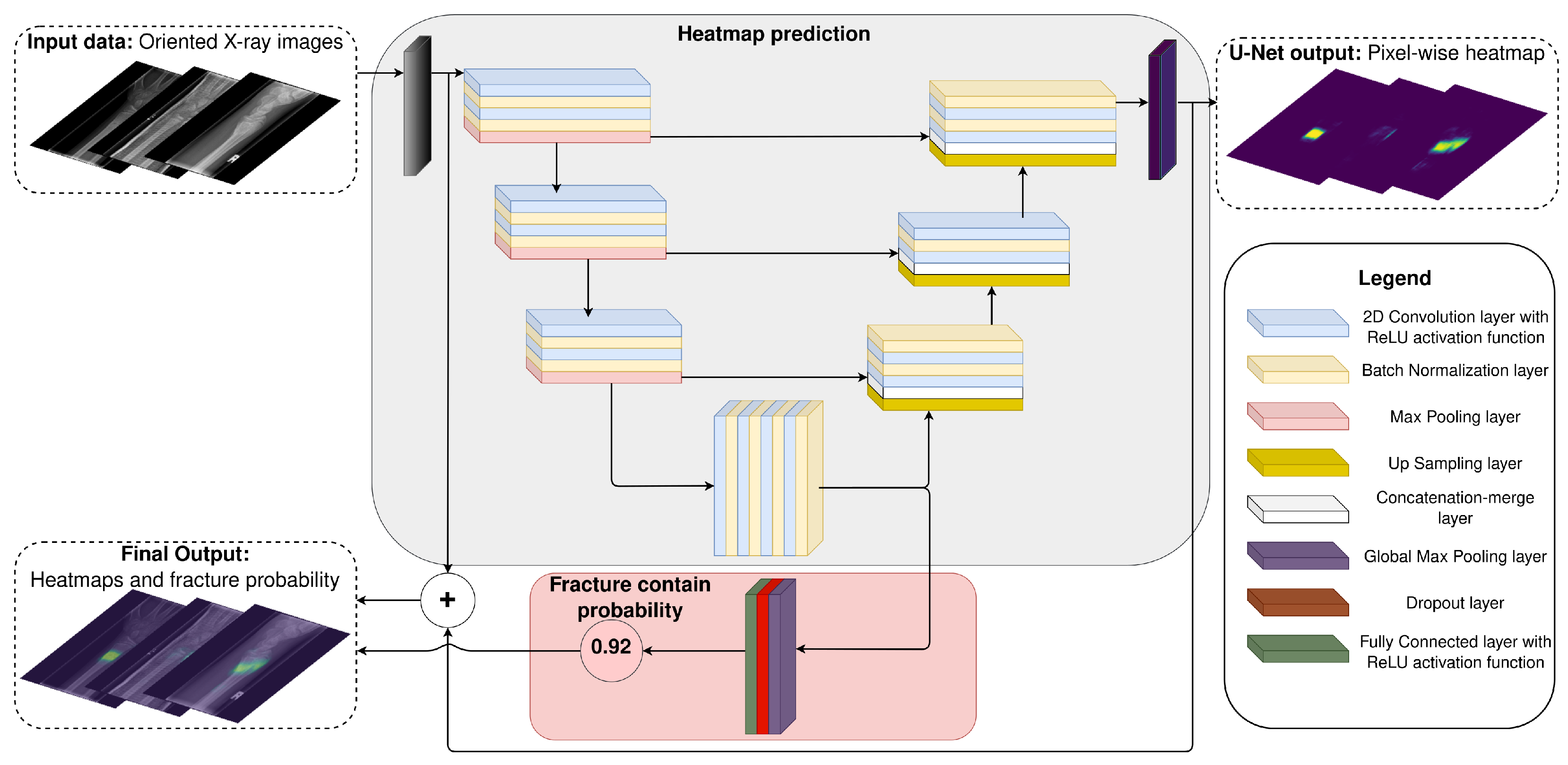
2.2.1. U-Net—A State-Of-The-Art Wrist Fracture Detection Method
- (1)
- The first part produces a pixel-wise heat map (mask) representing the probability for each pixel to belong to a fracture. This part is a U-net model with the same layer specification as described in the original paper (convolutional kernel size, padding, number of filters, etc.).
- (2)
- The second part calculates the probability that the input X-ray image contains a fracture. It consists of a global max pooling layer followed by a dropout layer with a dropout probability of (same as the original paper). Because there was no information concerning the fully connected layer, we set the number of neurons to 4096 with the ReLU activation function (inspired by the VGG19 model head [22])
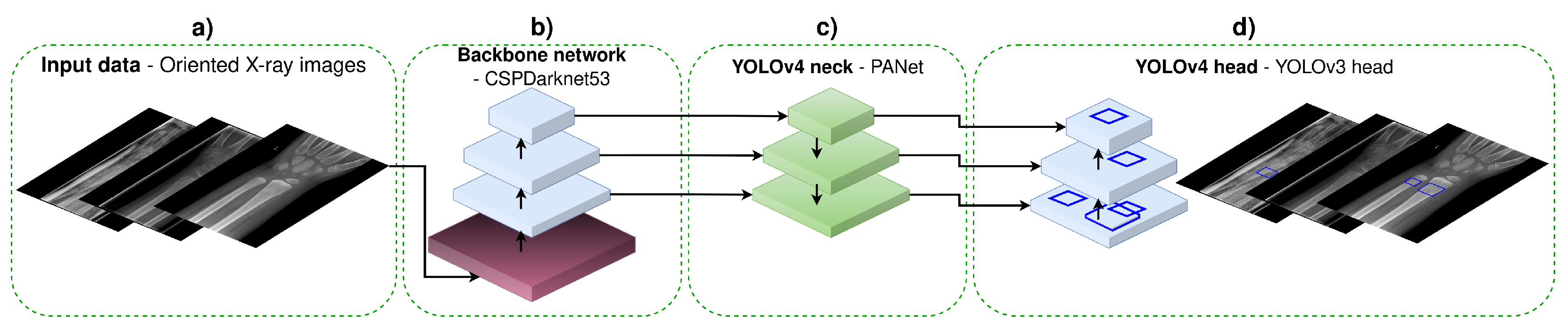
2.2.2. You-Only-Look-Once YOLOv4
- Input data—this step includes augmentation and preprocessing of the input data (XAOM with image scaling to , and pixels). In our research, we have utilised the same data augmentation methods (bag of freebies, mosaic augmentation, etc.), and image sizes that were proposed in the original YOLOv4 paper [15].
- Backbone network is a feature extractor CNN. In the original YOLOv4 paper, the authors compared several backbone CNNs, with CSPDarknet53 being the best-performing one [33]. Hence, in our work, we have utilised the same CNN model accompanied with the proposed enhancements (known as the bag of specials).
- YOLOv4 neck is used for feature aggregation. In the original paper, the authors discussed several model architectures for feature aggregation and decided to utilise PANet for aggregating features [34]. In our research, we followed the same intuition and utilised PANet as well.
- YOLOv4 head has the role of a detector, producing a vector representing objects (in our case, fractures). Each object is defined with an anchor (the coordinates of the predicted bounding box: center, height, width) and class probability. The utilised head was the same as in the original paper [35].
- YOLO 512 model having the input image size set to and original anchor sizes: , , , , , , , , .
- YOLO 512 Anchors model having the input image size set to and estimated anchor sizes: , , , , , , , , .
- YOLO 608 model having the input image size set to and original anchor sizes: , , , , , , , , .
- YOLO 608 Anchors model having the input image size set to and estimated anchor sizes: , , , , , , , , .
2.2.3. Methods Evaluation
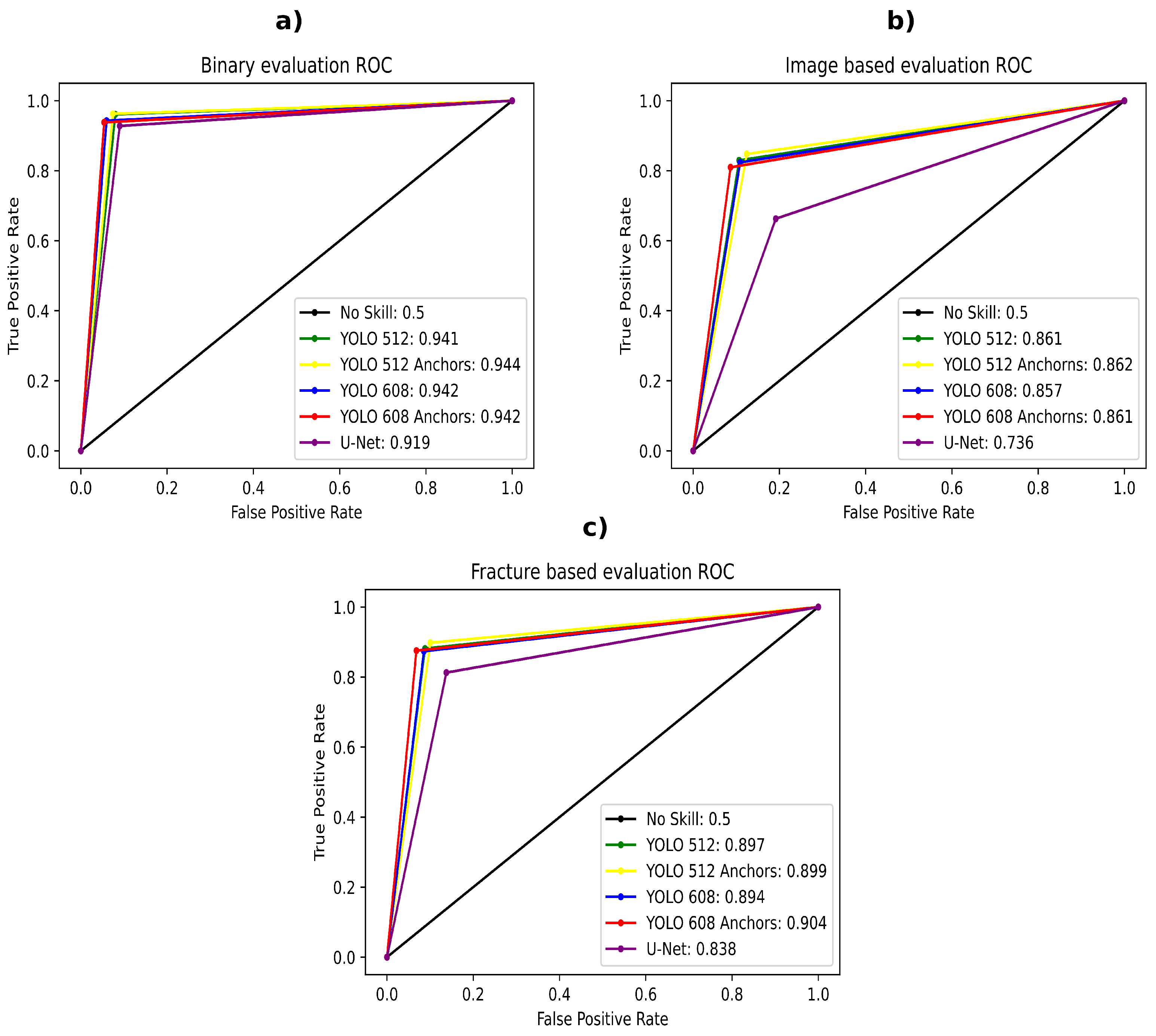
- The first evaluation benchmark involves a binary (yes/no answer) fracture presence classification task. Hence, we named it binary evaluation. This evaluation is designed according to work presented in Lindsey et al. [11]. Because the YOLOv4 method outputs a probability for each detected fracture, we would take the highest detected fracture probability in an image as the outputted value. For the U-Net model, we would simply take its second part/branch output. To obtain the models’ best performance, we used the fracture contain probability threshold —if the probability was below the set threshold value, there was no fracture presented in the image.
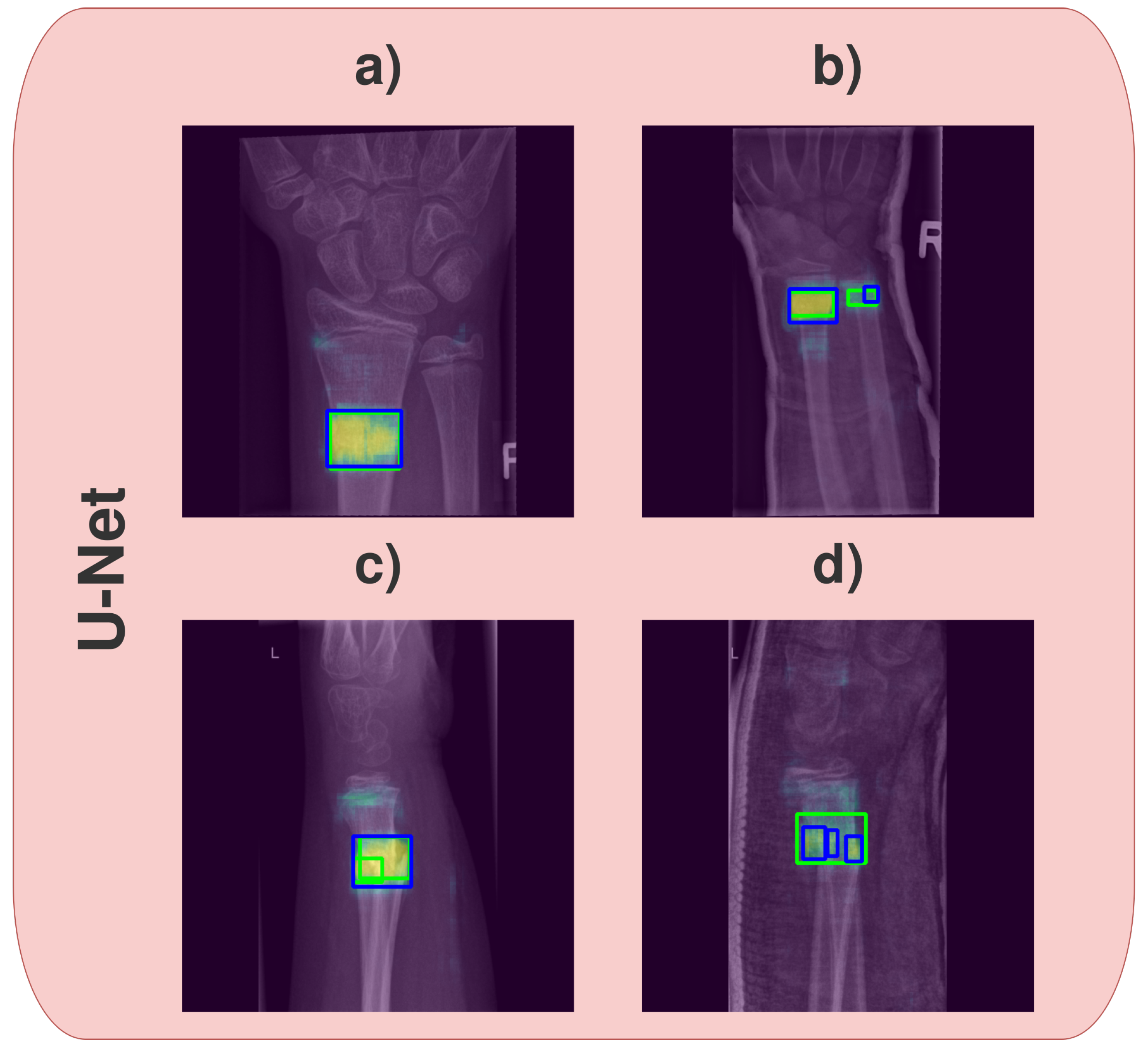
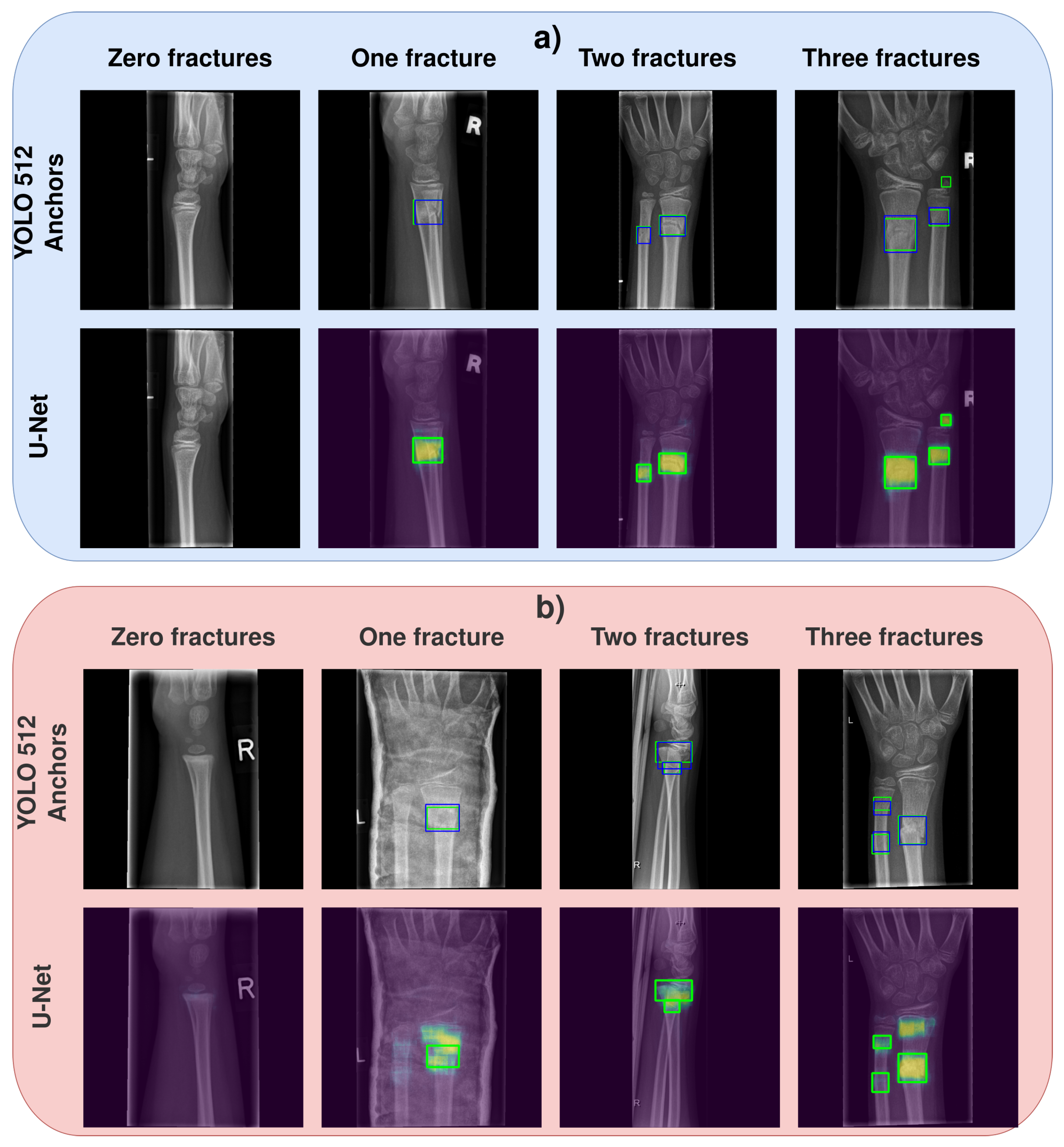
- The second evaluation benchmark we named image-based evaluation. In this test, we count the number of detected fractures in the image. To elaborate, in image-based evaluation, a true positive means that the number of detected fractures by the model is the same as the actual number of fractures in the image. If the model detects more than the actual number of fractures, it is a false positive. On the other hand, if it detects fewer fractures than the actual number of fractures, it is a false negative (if the image does not contain any fractures and models predict zero fractures, it is a true negative). For the YOLOv4 method, the image-based evaluation was simple because the method already outputs bounding boxes, including the probabilities that each bounding box contains a fracture. For the U-Net model, we had to develop an algorithm for bounding box (region) extraction. The algorithm first set heat maps to black-blank images (no fracture, 0 probability) if the second part of the U-Net model (fracture-contain probability) is lower than the experimentally defined threshold value . Second, the remaining heat map representing the fracture’s pixel-wise probability is binarised using another experimentally defined threshold value (heat map probability ). Last, we estimate the minimum bounding boxes of the fractures based on the remaining regions of white pixels, utilising the convex-hull algorithm [39]. Each bounding box represents one fracture, which allowed us to count the fractures by simply counting the bounding boxes. The image-based evaluation worked for the YOLOv4 model, but it did not evaluate the U-Net model properly due to the issues illustrated in Figure 3. Namely, after applying both threshold values ( and ), one heat map would sometimes be split into two separate bounding boxes. The opposite case is also present where, based on the heat map, only one bounding box is detected, while multiple fractures are present in close proximity to one another. Another issue is that the bounding box (after applying the threshold values) would sometimes be rather small compared to the whole heat map region, although the whole heat map perfectly fits the true bounding box of a fracture. Therefore, the image-based evaluation serves the purpose of giving us a rough estimation of models’ performance during training. For the true model performance, we propose the third evaluation.
- Third, and the most rigorous evaluation benchmark is the fracture-based evaluation. In this evaluation, we went manually through each image and evaluated every fracture separately, which means that if the image contained two fractures, we would have two evaluations for that particular image (one evaluation for each fracture). The match was positive if the IoU score of the predicted bounding box by the YOLOv4 model and the true fracture bounding box was or higher, or if the heat map generated by the U-Net model was over overlapped with the expected fracture region (the heat map was not smeared by more than with respect to the bounding box). For this evaluation, we also used the threshold ; any fracture with a probability less than the set threshold value was not considered.
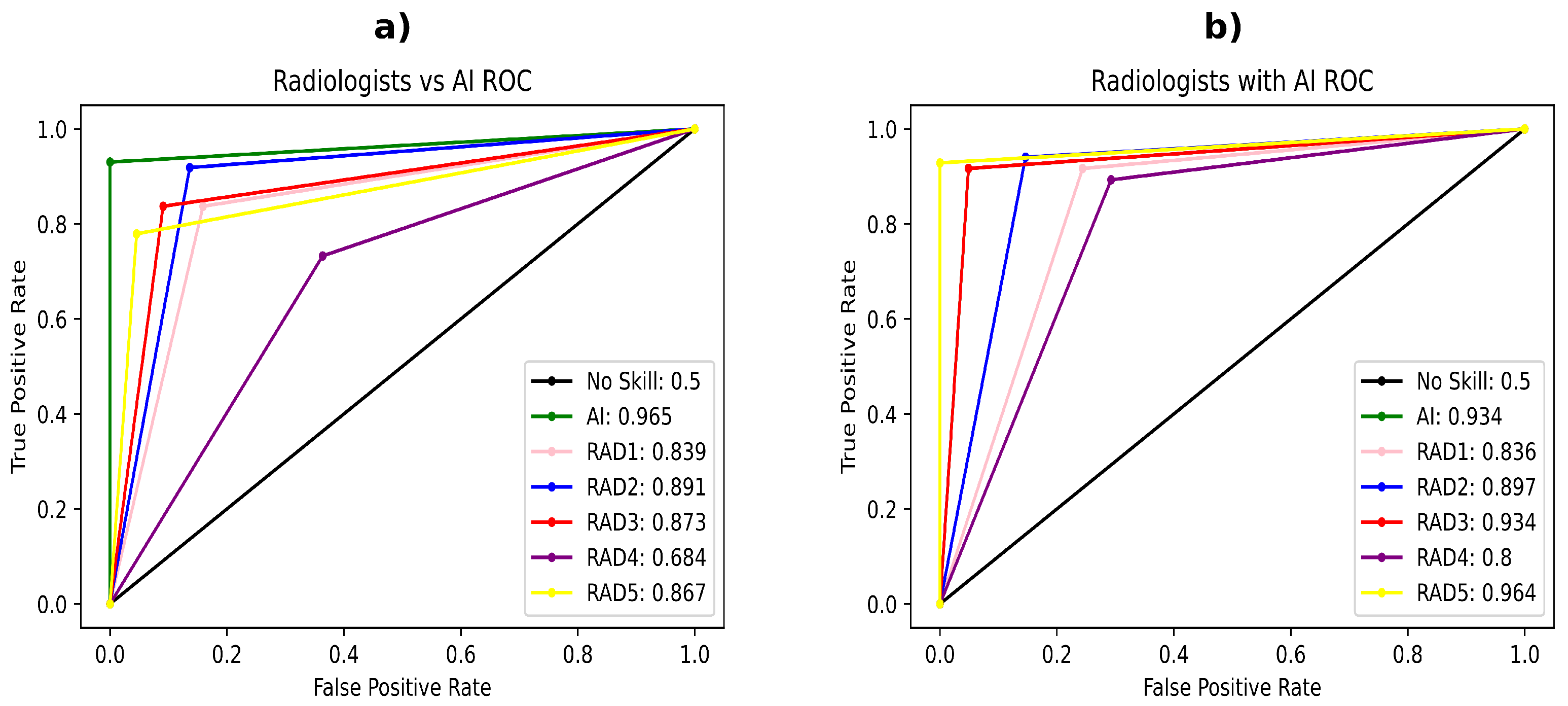
- The first evaluation is radiologist-versus-AI. This evaluation is similar to the fracture-based evaluation. The radiologists had the same task as the AI method: to draw bounding boxes around the fractures. Here, we compare the performance of five radiologists, who separately took the test against the best performing AI model, according to the prior evaluation tests.
- The second evaluation is radiologist-with-AI, where the radiologists are given the output of the AI (AI-predicted bounding boxes), and allow the radiologists to agree or disagree with the AI prediction. A radiologist can agree with the AI prediction or change it; however, once the radiologist makes the decision, it cannot be reversed. In the images not having any fractures, the assistance would simply be given such that the AI thinks there is no fracture present (just to make it clearer to the radiologists).
3. Results and Discussion
3.1. Models Evaluation Results
3.1.1. Quantitative Analysis of the Models’ Result
3.1.2. Analysis of Models’ Output Labels
3.1.3. Summary of Models Comparison
3.2. Radiologist and AI Comparison
- RAD1 F1-score increased from to ;
- RAD2 F1-score increased from to ;
- RAD3 F1-score increased from to ;
- RAD4 F1-score increased from to ;
- RAD5 F1-score increased from to .
3.3. Fracture Detection Problem and Related Work
- Dataset must be representative: it must have a sufficient number of data instances where images include demanding cases with obstacles such as cast and metal and multiple fractures on different projections. This will increase the generalisation capacity of the trained model.
- The approach with the best trade-off between explainability and accuracy is the object detection approach. Namely, the segmentation approach fails when there are many fractures nearby.
- The results, unless they are presented on a public dataset, are not that informative. Although, metrics to be used are AUC-ROC, F1-Score, and possibly MaP.
- Comparison with radiologists is a necessity because that is the proof that the proposed model can be helpful in the clinic. When comparing the developed model with radiologists, statistical analysis is a must.
- The YOLOv4-based model outperformed the U-Net model on a complex dataset, utilising an in-depth, three-stage evaluation.
- The YOLOv4-based model outperformed most radiologists, same as the U-Net model.
- The YOLOv4 method enhanced the radiologists’ performance, similar to the U-Net paper research results.
- From an interpretability point of view, the YOLOv4 method more clearly depicts the fractures than the U-Net model.
- Both methods still need radiologist monitoring and can serve only as an assisting tool, not as a standalone application [45].
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| YOLO 512 | YOLO 512 Anchors | YOLO 608 | YOLO 608 Anchors | U-Net | |
|---|---|---|---|---|---|
| YOLO 512 | 1 | 0.51184 | 0.32108 | 0.23510 | 2.99 × 10 |
| YOLO 512 Anchors | 0.51184 | 1 | 0.08168 | 0.05681 | 5.93 × 10 |
| YOLO 608 | 0.32108 | 0.08168 | 1 | 0.89568 | 0.00063 |
| YOLO 608 Anchors | 0.23510 | 0.05681 | 0.89568 | 1 | 0.00167 |
| U-Net | 2.99 × 10 | 5.93 × 10 | 0.00063 | 0.00167 | 1 |
| YOLO 512 | YOLO 512 Anchors | YOLO 608 | YOLO 608 Anchors | U-Net | |
|---|---|---|---|---|---|
| YOLO 512 | 1 | 0.48472 | 0.51516 | 0.39979 | 1.07 × 10 |
| YOLO 512 Anchors | 0.48472 | 1 | 0.16207 | 0.11554 | 1.65 × 10 |
| YOLO 608 | 0.51516 | 0.16207 | 1 | 0.93171 | 6.42 × 10 |
| YOLO 608 Anchors | 0.39979 | 0.11554 | 0.93171 | 1 | 6.40 × 10 |
| U-Net | 1.07 × 10 | 1.65 × 10 | 6.42 × 10 | 6.40 × 10 | 1 |
| YOLO 512 | YOLO 512 Anchors | YOLO 608 | YOLO 608 Anchors | U-Net | |
|---|---|---|---|---|---|
| YOLO 512 | 1 | 0.14166 | 0.42784 | 0.68905 | 1.01 × 10 |
| YOLO 512 Anchors | 0.14166 | 1 | 0.02420 | 0.37546 | 2.11 × 10 |
| YOLO 608 | 0.42784 | 0.02420 | 1 | 0.17453 | 8.83 × 10 |
| YOLO 608 Anchors | 0.68905 | 0.37546 | 0.17453 | 1 | 2.72 × 10 |
| U-Net | 1.01 × 10 | 2.11 × 10 | 8.83 × 10 | 2.72 × 10 | 1 |
| YOLO 512 Anchors | RAD1 | RAD2 | RAD3 | RAD4 | RAD5 | |
|---|---|---|---|---|---|---|
| YOLO 512 Anchors | 1 | 0.00027 | 0.06543 | 0.00418 | 1.02 × 10 | 0.00027 |
| RAD1 | 0.00027 | 1 | 0.15159 | 0.64761 | 0.00510 | 1 |
| RAD2 | 0.06543 | 0.15159 | 1 | 0.38331 | 6.16 × 10 | 0.15159 |
| RAD3 | 0.00418 | 0.64761 | 0.38331 | 1 | 0.00019 | 0.58105 |
| RAD4 | 1.02 × 10 | 0.00510 | 6.16489 × 10 | 0.00019 | 1 | 0.00143 |
| RAD5 | 0.00027 | 1 | 0.15159 | 0.58105 | 0.00143 | 1 |
| AI | RAD1 | RAD2 | RAD3 | RAD4 | RAD5 | |
|---|---|---|---|---|---|---|
| t | 0.87476 | −0.57061 | −0.32685 | −1.72765 | −2.50488 | −2.98537 |
| p | 0.38254 | 0.56877 | 0.74405 | 0.08527 | 0.01288 | 0.00311 |
References
- Randsborg, P.H.; Gulbrandsen, P.; Saltyte Benth, J.; Sivertsen, E.A.; Hammer, O.L.; Fuglesang, H.F.; Aroen, A. Fractures in children: Epidemiology and activity-specific fracture rates. J. Bone Jt. Surg. 2013, 95, e42. [Google Scholar] [CrossRef] [PubMed]
- Hedström, E.M.; Svensson, O.; Bergström, U.; Michno, P. Epidemiology of fractures in children and adolescents. Acta Orthop. 2010, 81, 148–153. [Google Scholar] [CrossRef]
- Wei, C.J.; Tsai, W.C.; Tiu, C.M.; Wu, H.T.; Chiou, H.J.; Chang, C.Y. Systematic analysis of missed extremity fractures in emergency radiology. Acta Radiol. 2006, 47, 710–717. [Google Scholar] [CrossRef]
- Olczak, J.; Fahlberg, N.; Maki, A.; Razavian, A.S.; Jilert, A.; Stark, A.; Sköldenberg, O.; Gordon, M. Artificial intelligence for analyzing orthopedic trauma radiographs: Deep learning algorithms—Are they on par with humans for diagnosing fractures? Acta Orthop. 2017, 88, 581–586. [Google Scholar] [CrossRef]
- Kim, D.; MacKinnon, T. Artificial intelligence in fracture detection: Transfer learning from deep convolutional neural networks. Clin. Radiol. 2018, 73, 439–445. [Google Scholar] [CrossRef] [PubMed]
- Raisuddin, A.M.; Vaattovaara, E.; Nevalainen, M.; Nikki, M.; Järvenpää, E.; Makkonen, K.; Pinola, P.; Palsio, T.; Niemensivu, A.; Tervonen, O.; et al. Critical evaluation of deep neural networks for wrist fracture detection. Sci. Rep. 2021, 11, 6006. [Google Scholar] [CrossRef]
- Thian, Y.L.; Li, Y.; Jagmohan, P.; Sia, D.; Chan, V.E.Y.; Tan, R.T. Convolutional neural networks for automated fracture detection and localization on wrist radiographs. Radiol. Artif. Intell. 2019, 1, e180001. [Google Scholar] [CrossRef]
- Yahalomi, E.; Chernofsky, M.; Werman, M. Detection of Distal Radius Fractures Trained by a Small Set of X-Ray Images and Faster R-CNN. In Proceedings of the Intelligent Computing; Arai, K., Bhatia, R., Kapoor, S., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 971–981. [Google Scholar]
- Gan, K.; Xu, D.; Lin, Y.; Shen, Y.; Zhang, T.; Hu, K.; Zhou, K.; Bi, M.; Pan, L.; Wu, W.; et al. Artificial intelligence detection of distal radius fractures: A comparison between the convolutional neural network and professional assessments. Acta Orthop. 2019, 90, 394–400. [Google Scholar] [CrossRef]
- Blüthgen, C.; Becker, A.S.; de Martini, I.V.; Meier, A.; Martini, K.; Frauenfelder, T. Detection and localization of distal radius fractures: Deep learning system versus radiologists. Eur. J. Radiol. 2020, 126, 108925. [Google Scholar] [CrossRef]
- Lindsey, R.; Daluiski, A.; Chopra, S.; Lachapelle, A.; Mozer, M.; Sicular, S.; Hanel, D.; Gardner, M.; Gupta, A.; Hotchkiss, R.; et al. Deep neural network improves fracture detection by clinicians. Proc. Natl. Acad. Sci. USA 2018, 115, 11591–11596. [Google Scholar] [CrossRef]
- Nichols, J.A.; Chan, H.W.H.; Baker, M.A. Machine learning: Applications of artificial intelligence to imaging and diagnosis. Biophys. Rev. 2019, 11, 111–118. [Google Scholar] [CrossRef]
- Choy, G.; Khalilzadeh, O.; Michalski, M.; Do, S.; Samir, A.E.; Pianykh, O.S.; Geis, J.; Pandharipande, P.V.; Brink, J.; Dreyer, K.J. Current Applications and Future Impact of Machine Learning in Radiology. Radiology 2018, 288, 318–328. [Google Scholar] [CrossRef]
- Zhou, Z.; Rahman Siddiquee, M.M.; Tajbakhsh, N.; Liang, J. UNet++: A Nested U-Net Architecture for Medical Image Segmentation. In Proceedings of the Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Stoyanov, D., Taylor, Z., Carneiro, G., Syeda-Mahmood, T., Martel, A., Maier-Hein, L., Tavares, J.M.R., Bradley, A., Papa, J.P., Belagiannis, V., et al., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 3–11. [Google Scholar]
- Bochkovskiy, A.; Wang, C.; Liao, H.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Hržić, F.; Tschauner, S.; Sorantin, E.; Štajduhar, I. XAOM: A method for automatic alignment and orientation of radiographs for computer-aided medical diagnosis. Comput. Biol. Med. 2021, 132, 104300. [Google Scholar] [CrossRef]
- Malik, H.; Jabbar, J.; Mehmood, H. Wrist Fracture—X-rays. Mendeley Data 2020. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar] [CrossRef]
- Frid-Adar, M.; Ben-Cohen, A.; Amer, R.; Greenspan, H. Improving the Segmentation of Anatomical Structures in Chest Radiographs Using U-Net with an ImageNet Pre-trained Encoder. In Proceedings of the Image Analysis for Moving Organ, Breast, and Thoracic Images; Stoyanov, D., Taylor, Z., Kainz, B., Maicas, G., Beichel, R.R., Martel, A., Maier-Hein, L., Bhatia, K., Vercauteren, T., Oktay, O., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 159–168. [Google Scholar]
- Bouslama, A.; Laaziz, Y.; Tali, A. Diagnosis and precise localization of cardiomegaly disease using U-NET. Inform. Med. Unlocked 2020, 19, 100306. [Google Scholar] [CrossRef]
- Rahman, M.F.; Tseng, T.L.B.; Pokojovy, M.; Qian, W.; Totada, B.; Xu, H. An automatic approach to lung region segmentation in chest X-ray images using adapted U-Net architecture. In Proceedings of the Medical Imaging 2021: Physics of Medical Imaging; Bosmans, H., Zhao, W., Yu, L., Eds.; International Society for Optics and Photonics: Bellingham, WA, USA, 2021; Volume 11595, p. 894. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2015, arXiv:cs.CV/1409.1556. [Google Scholar]
- Santurkar, S.; Tsipras, D.; Ilyas, A.; Madry, A. How Does Batch Normalization Help Optimization? In Proceedings of the Advances in Neural Information Processing Systems; Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2018; Volume 31. [Google Scholar]
- Buja, A.; Stuetzle, W.; Shen, Y. Loss functions for binary class probability estimation and classification: Structure and applications. Working Draft, 3 November 2005. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28. Available online: https://proceedings.neurips.cc/paper/2015/file/14bfa6bb14875e45bba028a21ed38046-Paper.pdf (accessed on 11 August 2022).
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Li, M.; Zhang, Z.; Lei, L.; Wang, X.; Guo, X. Agricultural Greenhouses Detection in High-Resolution Satellite Images Based on Convolutional Neural Networks: Comparison of Faster R-CNN, YOLO v3 and SSD. Sensors 2020, 20, 4938. [Google Scholar] [CrossRef]
- Wu, D.; Lv, S.; Jiang, M.; Song, H. Using channel pruning-based YOLO v4 deep learning algorithm for the real-time and accurate detection of apple flowers in natural environments. Comput. Electron. Agric. 2020, 178, 105742. [Google Scholar] [CrossRef]
- Deepa, R.; Tamilselvan, E.; Abrar, E.; Sampath, S. Comparison of Yolo, SSD, Faster RCNN for Real Time Tennis Ball Tracking for Action Decision Networks. In Proceedings of the 2019 International Conference on Advances in Computing and Communication Engineering (ICACCE), Sathyamangalam, India, 4–6 April 2019; pp. 1–4. [Google Scholar] [CrossRef]
- Tolba, M.F. YOLO V3 and YOLO V4 for masses detection in mammograms with resnet and inception for masses classification. In Advanced Machine Learning Technologies and Applications: Proceedings of AMLTA 2021; Springer: Berlin/Heidelberg, Germany, 2021; Volume 1339, p. 145. [Google Scholar] [CrossRef]
- Wang, C.Y.; Liao, H.Y.M.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 390–391. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Likas, A.; Vlassis, N.; Verbeek, J.J. The global k-means clustering algorithm. Pattern Recognit. 2003, 36, 451–461. [Google Scholar] [CrossRef]
- Nagy, E.; Janisch, M.; Hržić, F.; Sorantin, E.; Tschauner, S. A pediatric wrist trauma X-ray dataset (GRAZPEDWRI-DX) for machine learning. Sci. Data 2022, 9, 222. [Google Scholar] [CrossRef] [PubMed]
- Jocher, G.; Stoken, A.; Borovec, J.; Chaurasia, A.; Diaconu, L.; Changyu, L.; Colmagro, A.; Ye, H.; Fang, J.; Hogan, A.; et al. ultralytics/yolov5: V4.0—nn.SiLU() activations, Weights & Biases logging, PyTorch Hub integration. Available online: https://zenodo.org/record/4418161 (accessed on 11 August 2022).
- Barber, C.B.; Dobkin, D.P.; Huhdanpaa, H. The Quickhull Algorithm for Convex Hulls. ACM Trans. Math. Softw. 1996, 22, 469–483. [Google Scholar] [CrossRef]
- McNemar, Q. Note on the sampling error of the difference between correlated proportions or percentages. Psychometrika 1947, 12, 153–157. [Google Scholar] [CrossRef]
- Kim, T.K. T test as a parametric statistic. Korean J. Anesthesiol. 2015, 68, 540–546. [Google Scholar] [CrossRef] [PubMed]
- Najafabadi, M.M.; Villanustre, F.; Khoshgoftaar, T.M.; Seliya, N.; Wald, R.; Muharemagic, E. Deep learning applications and challenges in big data analytics. J. Big Data 2015, 2, 1–21. [Google Scholar] [CrossRef]
- Shorten, C.; Khoshgoftaar, T.M. A survey on image data augmentation for deep learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Irshad, H.; Veillard, A.; Roux, L.; Racoceanu, D. Methods for nuclei detection, segmentation, and classification in digital histopathology: A review—current status and future potential. IEEE Rev. Biomed. Eng. 2013, 7, 97–114. [Google Scholar] [CrossRef] [PubMed]
- Islam, M.Z.; Islam, M.M.; Asraf, A. A combined deep CNN-LSTM network for the detection of novel coronavirus (COVID-19) using X-ray images. Inform. Med. Unlocked 2020, 20, 100412. [Google Scholar] [CrossRef] [PubMed]
- Saha, P.; Sadi, M.S.; Islam, M.M. EMCNet: Automated COVID-19 diagnosis from X-ray images using convolutional neural network and ensemble of machine learning classifiers. Inform. Med. Unlocked 2021, 22, 100505. [Google Scholar] [CrossRef]








| Attribute | Attributes’ Value | ||
|---|---|---|---|
| Gender | Male: 8074 | Female: 11,626 | NA |
| Age | Male: 11.50 ± 3.61 | Female: 10.44 ± 3.56 | All: 11.07 ± 3.63 |
| Fracture | Zero: 7119 | One: 8780 | Multiple: 3801 |
| Projection | AP: 9775 | LAT: 9835 | OBL: 90 |
| Side | Left: 10,791 | Right: 8909 | NA |
| Cast | Present: 14,103 | Not present: 5597 | NA |
| Metal | Present: 686 | Not present: 19,014 | NA |
| Model Name | Fracture Contain Probability | Precision | Recall | F1-Score | Accuracy |
|---|---|---|---|---|---|
| YOLO 512 | 20.00% | 0.94658 | 0.94667 | 0.94661 | 0.94667 |
| YOLO 512 Anchors | 25.00% | 0.94969 | 0.94974 | 0.94971 | 0.94974 |
| YOLO 608 | 22.50% | 0.94311 | 0.94205 | 0.94233 | 0.94205 |
| YOLO 608 Anchors | 22.50% | 0.94264 | 0.94103 | 0.94139 | 0.94103 |
| U-Net | 72.50% | 0.92268 | 0.92154 | 0.92189 | 0.92154 |
| Model Name | Fracture Contain Probability | Heat Map Probability | Precision | Recall | F1-Score | Accuracy |
|---|---|---|---|---|---|---|
| YOLO 512 | 37.50% | / | 0.86455 | 0.85385 | 0.85556 | 0.85385 |
| YOLO 512 Anchors | 37.50% | / | 0.86470 | 0.85846 | 0.85973 | 0.85846 |
| YOLO 608 | 35.00% | / | 0.86063 | 0.84923 | 0.85103 | 0.84923 |
| YOLO 608 Anchors | 32.50% | / | 0.86570 | 0.84821 | 0.85051 | 0.84821 |
| U-Net | 2.50% | 65.00% | 0.74644 | 0.72359 | 0.72516 | 0.72359 |
| Model Name | Fracture Contain Probability | Precision | Recall | F1-Score | Accuracy |
|---|---|---|---|---|---|
| 512 | 37.50% | 0.89997 | 0.89144 | 0.89327 | 0.89144 |
| YOLO 512 Anchors | 37.50% | 0.90369 | 0.89871 | 0.89997 | 0.89871 |
| YOLO 608 | 35.00% | 0.89718 | 0.88701 | 0.88907 | 0.88701 |
| YOLO 608 Anchors | 32.50% | 0.90502 | 0.89387 | 0.89592 | 0.89387 |
| U-Net | 2.50% | 0.84805 | 0.82889 | 0.83292 | 0.82889 |
| Test Subject | Precision | Recall | F1-Score | Accuracy |
|---|---|---|---|---|
| YOLO 512 Anchors | 0.95938 | 0.95385 | 0.95449 | 0.95385 |
| RAD1 | 0.84847 | 0.83846 | 0.84099 | 0.83846 |
| RAD2 | 0.90065 | 0.9 | 0.90027 | 0.9 |
| RAD3 | 0.87743 | 0.86154 | 0.86433 | 0.86154 |
| RAD4 | 0.71338 | 0.7 | 0.70469 | 0.7 |
| RAD5 | 0.87540 | 0.83846 | 0.84268 | 0.83846 |
| Test Subject | Precision | Recall | F1-Score | Accuracy |
|---|---|---|---|---|
| YOLO 512 Anchors | 0.93307 | 0.928 | 0.92896 | 0.928 |
| RAD1 | 0.86233 | 0.864 | 0.86261 | 0.864 |
| RAD2 | 0.91156 | 0.912 | 0.91171 | 0.912 |
| RAD3 | 0.93307 | 0.928 | 0.92896 | 0.928 |
| RAD4 | 0.82962 | 0.832 | 0.83028 | 0.832 |
| RAD5 | 0.95812 | 0.952 | 0.95274 | 0.952 |
| Paper | Data | Models | Type of Fracture Recognition | Result | Comparison with Experts |
|---|---|---|---|---|---|
| Ours | Projections: AP, LAT, Oblique Training: 15,600 images Test: Test #1: 1950 images, Test #2: 2 × 100 images | YOLOv4 based models | Fracture detection | AUC-ROC: Test #1 0.899 F1-Score: Test #1 0.89997 AUC-ROC: Test #2 0.899 F1-Score: Test #2 0.95449 | Model outperformed radiologists and enhanced their performance. |
| Raisuddin et al. [6] | Projections: AP, LAT Training: 3873 images Test: Test1 414 images, Test2 210 images | ROI localisation block combined with SeresNet50 fracture classificator. Heat map with GradCAM method | Classification with heat map segmentation | AUC ROC: Test1 0.99 (0.98–0.99) F1-Score: Test1 0.95 (0.92–0.97) AUC ROC: Test2 0.84 (0.72–0.93) F1-Score: Test2 0.63 (0.44–0.80) | Model outperformed physicians (both tests) and was better than the radiologists on the Test2 |
| Blüthgen et al. [10] | Projections: AP, LAT Training: 524 images Test: 100 images (internal), 200 images (external) | Deep Learning System(DLS), Two not defined models | Classification based on the heat map overlap | AUC ROC: 0.96 (0.87–1), 0.89 (0.81–0.94) Fracture localization: 94%, 83% | Radiologist were comparable Or better than the DLS |
| Gan et al. [9] | Projections: AP Training: 2040 images Test: 300 images | Faster R-CNN for fracture extraction, Inception-v4 for ROI classification | Classification of the detected fractures | AUC ROC:0.96 (0.94–0.99) IOU: 0.87 (0.86–0.87) | Model results were comparable with orthopedics, and better than radiologists |
| Thian et al. [7] | Projections: AP, LAT Training: 6515 AP images, 6537 LAT images Test: 525 AP images, 525 LAT images | Two Faster R-CNN models: One for each projection | Fracture detection | AUC ROC: AP 0.918 (0.894–0.941), AUC ROC: LAT 0.933 (0.912, 0.954) | None |
| Yahalomi et al. [8] | Projections: AP Training: 120 images (Augmented to 4476) Test: 1312 images | Faster R-CNN: Pretrained on Image-net | Fracture detection | Accuracy: 96% MAP: 0.866 | None |
| Kim and MacKinnon [5] | Projections: LAT Training: 1389 (Augmented to 11,112) Test: 100 images | Inception-v3 | Classification | AUC ROC: 0.954 | None |
| Lindsey et al. [11] | Projections AP, LAT Training: 31,490 images Test: Test1: 3500 images, Test2: 1400 images | Modified U-Net | Classification with heat map segmentation | AUC ROC: Test1 0.967 (0.960–0.973) AUC ROC: Test2 0.975 (0.965–0.0.982) | U-net model enhanced radiologists performance. |
| Olczak et al. [4] | Projections: AP, LAT, Oblique Training: 256,458 images (wrist, hand, ankle) Test: 400 images | VGG16 | Classification | Accuracy: 83% | Model results were comparable With orthopaedics (∼82%) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hržić, F.; Tschauner, S.; Sorantin, E.; Štajduhar, I. Fracture Recognition in Paediatric Wrist Radiographs: An Object Detection Approach. Mathematics 2022, 10, 2939. https://doi.org/10.3390/math10162939
Hržić F, Tschauner S, Sorantin E, Štajduhar I. Fracture Recognition in Paediatric Wrist Radiographs: An Object Detection Approach. Mathematics. 2022; 10(16):2939. https://doi.org/10.3390/math10162939
Chicago/Turabian StyleHržić, Franko, Sebastian Tschauner, Erich Sorantin, and Ivan Štajduhar. 2022. "Fracture Recognition in Paediatric Wrist Radiographs: An Object Detection Approach" Mathematics 10, no. 16: 2939. https://doi.org/10.3390/math10162939
APA StyleHržić, F., Tschauner, S., Sorantin, E., & Štajduhar, I. (2022). Fracture Recognition in Paediatric Wrist Radiographs: An Object Detection Approach. Mathematics, 10(16), 2939. https://doi.org/10.3390/math10162939