4.2.3. Comparison
In order to verify the effectiveness of the feature fusion method proposed in this work, we performed relevant comparative experiments.
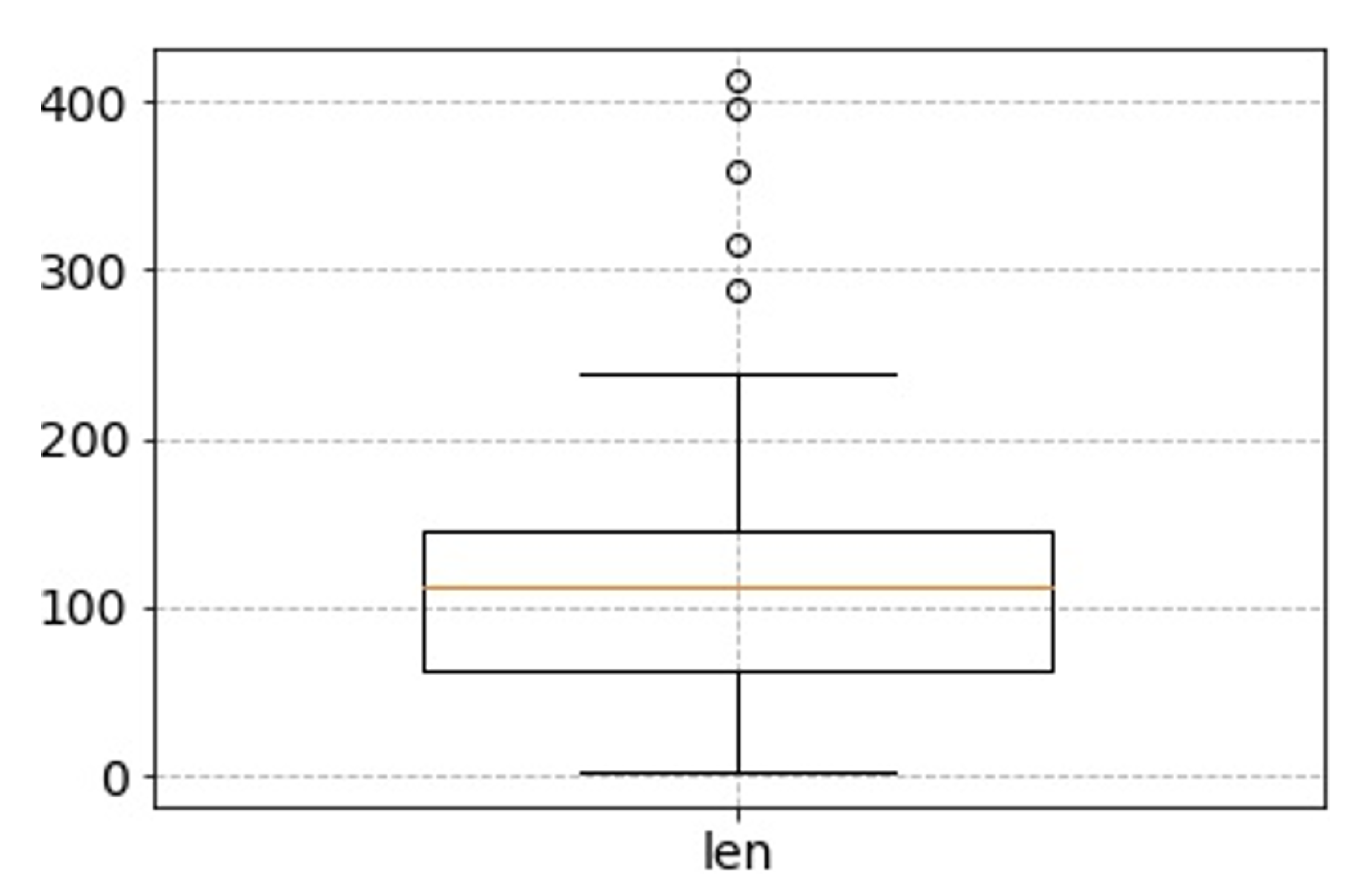
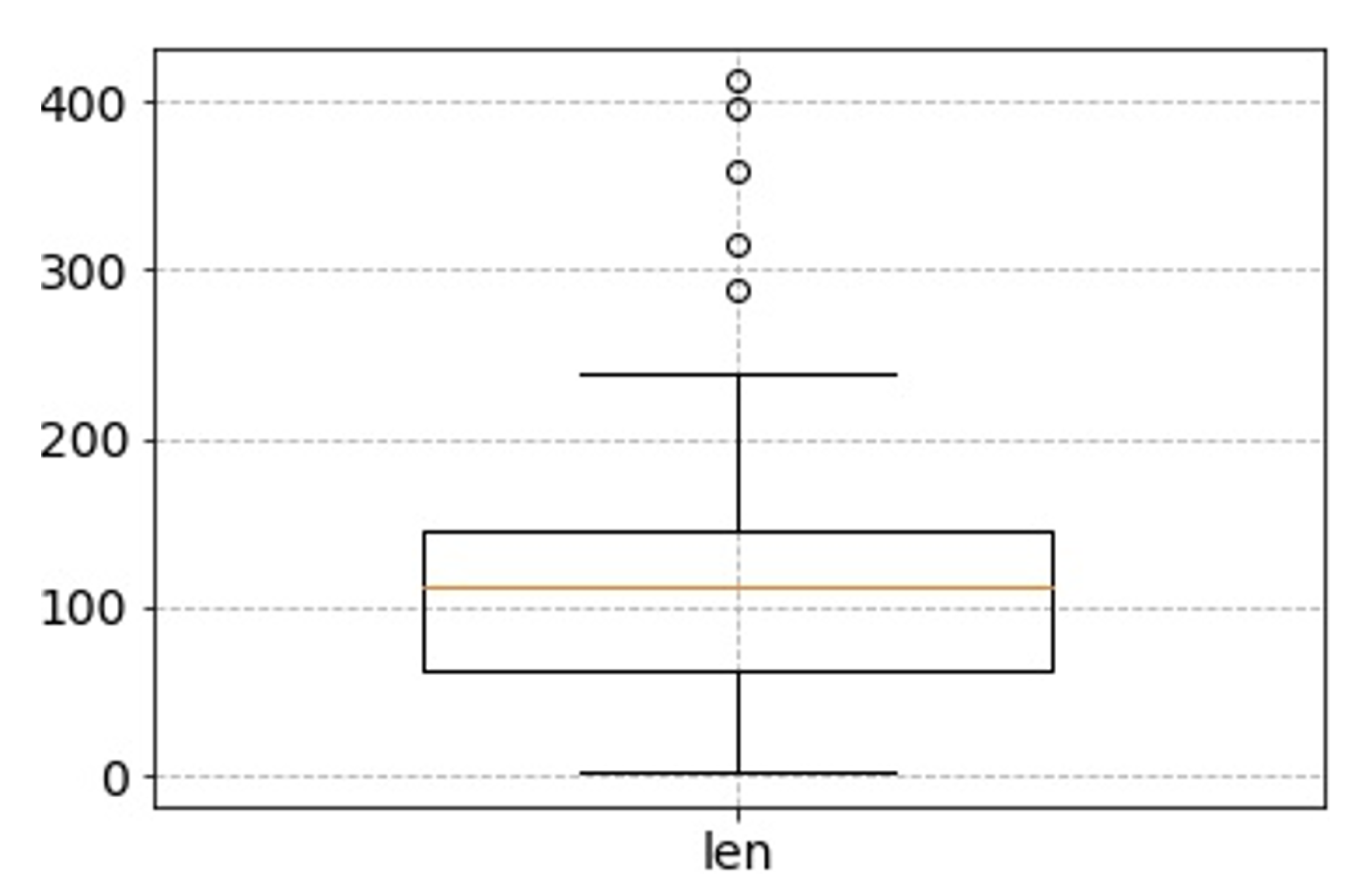
First, the length of the input affects the detection speed, the training time, and the accuracy of the model detection. Accordingly, it is necessary to find a reasonable value for the input data’s length. After the preprocessing steps, the box plot of the length distribution of all training data, including web injection attacks samples and benign traffic data, is shown in
Figure 6. The “len” indicates the total length of the URL and the content of the POST body.
According to
Figure 6, the median length of the training data is around 100, and the 3/4 quantile is about 150. It indicates that about 75% of the training sample data is less than 150. Therefore, the input lengths of 100, 150, and 200 are used for experimental comparison here to verify the influence on the accuracy and speed of the model with different data lengths. Other settings of the experiment here are the same.
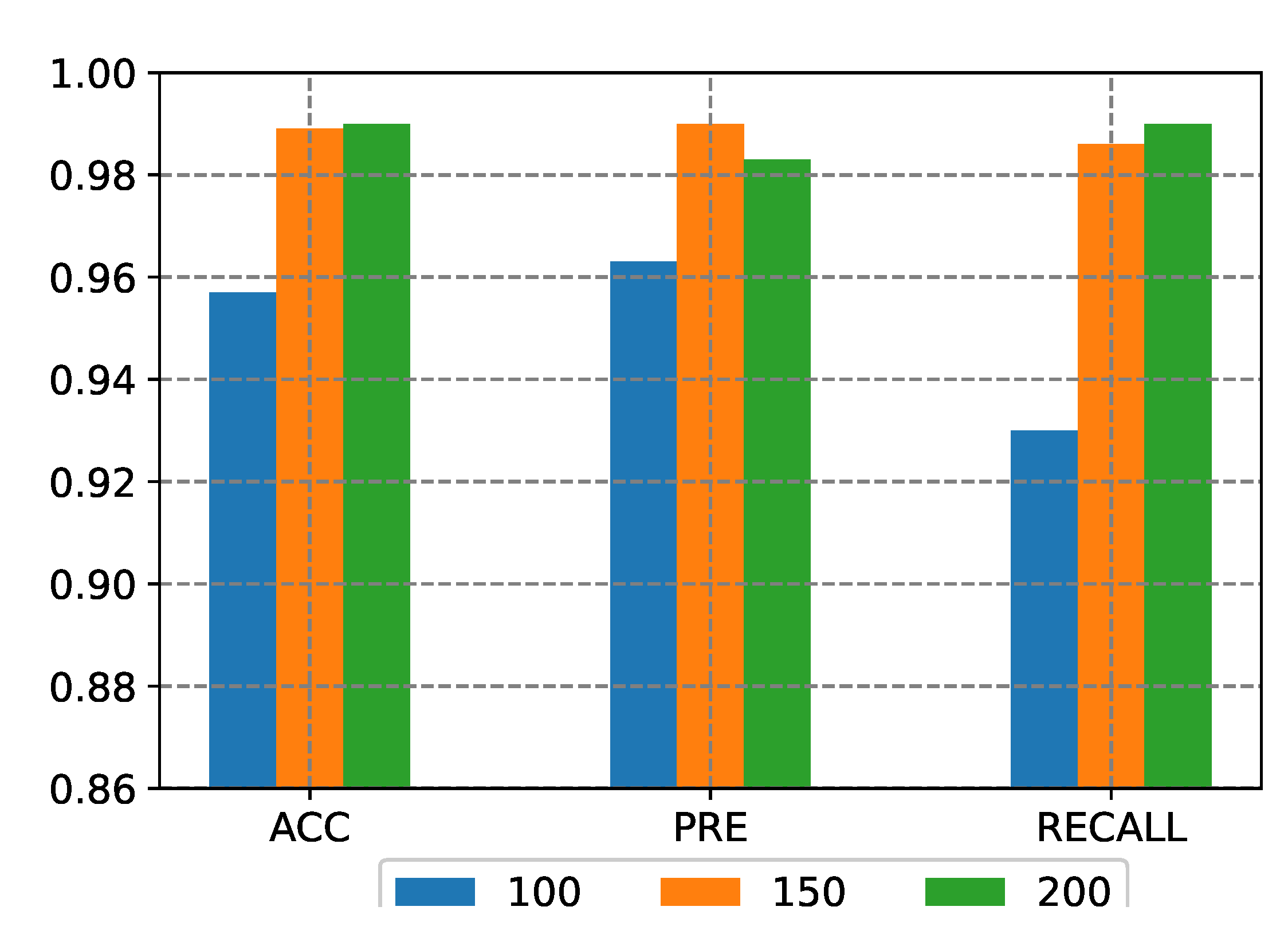
The results of model detection with different input lengths are in
Figure 7. The time required for training models to detect more than 75,000 web request traffic data in the test set based on three different input lengths is in
Table 8. We can see that when the input length is 100, the model detection speed is the fastest, but the results of the detection model are generally low, especially since the recall is only about 93%. When the input length is 100, it is not enough for the detection model to capture the features of the input data. When the input length is 150, the values of accuracy (ACC), precision (PRE), and recall (RECALL) have increased. It is about 4% higher than the average result when the input length is 100, and the three evaluation indicators have exceeded 98%. When the input model length is 200, the values of accuracy and recall are slightly improved based on the input length of 150. However, the model detection speed is significantly reduced compared with the input length of 150.
Table 8 shows that when the input model data length is 200, the detection time is increased by 235 s compared with the input length of 150, and the detection speed is reduced by about 44%. We choose 150 as the final input length of the model in this work under the consideration of speed and accuracy.
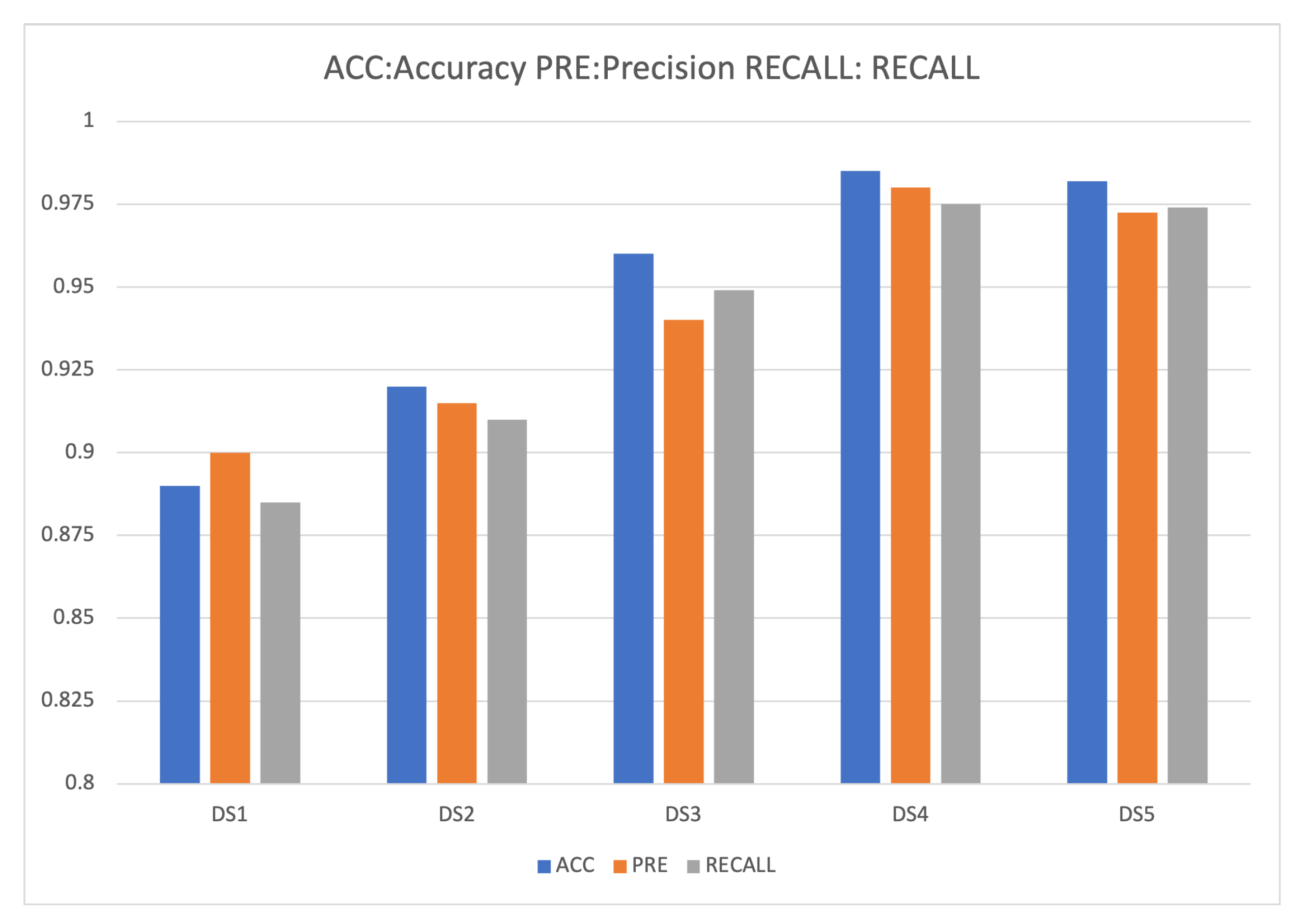
Then, we compare the model effects of general machine learning methods (such as Logistic Regression, Naive Bayes, and SVM). We train all models with the datasets shown in
Table 6. The comparison results are shown in
Table 9. It can be seen from the table that in the detection of web injection attacks, although Logistic regression and the Naive Bayes algorithm have relatively reasonable precision values, the results of precision and recall are different from the precision values, which indicates that there is a high rate of false negative in the detection results. It represents that many malicious requests are identified as benign requests, which shows that the two algorithms have not really learned the characteristics that can identify benign and malicious traffic. Compared with the two algorithms, the experimental results of the SVM algorithm are much better. The accuracy rate, precision rate and recall rate all exceed 90% and even the precision rate reaches 95.03%, which shows that the SVM has identified the difference between benign and malicious traffic in a certain extent. The detection model proposed in this paper is superior to the above three general machine learning methods in three performance indicators. The results of the three performance indicators all exceed 99%, which also shows that the deep learning model has certain advantages in detection performance compared with machine learning.
Then, we compare the multi-class detection method of injection attack based on feature fusion with other neural network classification models. We choose the single model and fusion model as control models. We used the C-LSTM model [
28], which is a combination of long short-term memory network and convolutional neural network, in the mixed control model, and the model eXpose [
29], which performs convolution and splices based on four different windows, is used as the second mixed control model. The single-model control experiments used two models: Char-GRU and Char-CNN [
30].
Char-GRU comes from the char-RNN model [
31]. We use GRU [
25] to replace the RNN model, which solves the problem of gradient disappearance or gradient explosion of the basic RNN model in long series [
32], and the effect of Gru and LSTM is similar but simpler than LSTM [
33]. Char-GRU performs character embedding on the sample data, and extracts time series features with the GRU deep learning model, finally uses a fully connected layer for classification. Char-CNN uses a convolutional neural network to automatically extract text features after character embedding on the input sample data, and finally uses a fully connected layer to classify the sample data.
Table 10 shows the comparison of the classification effects of the web injection attack of the detection model based on feature fusion and the control model on the test set.
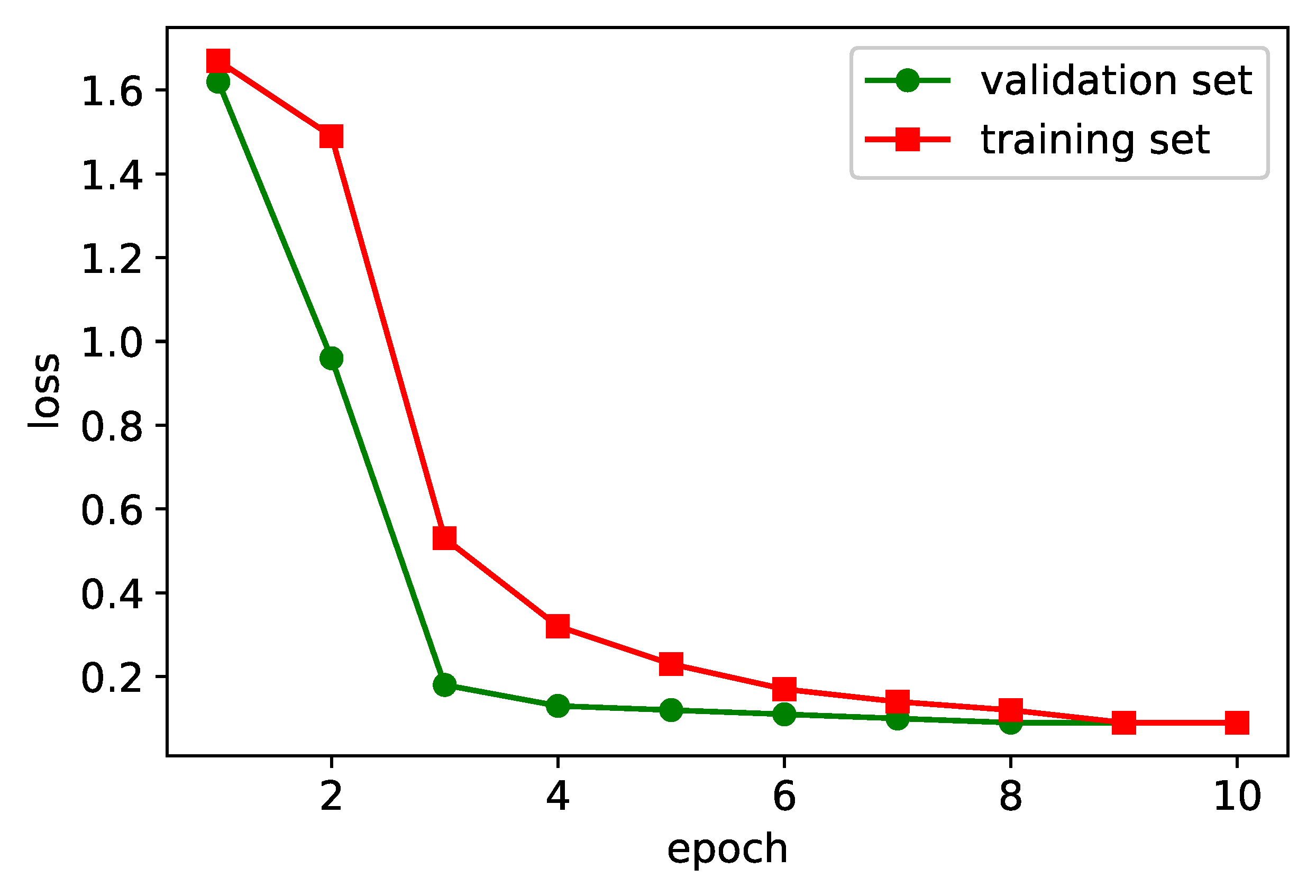
To fully represent the detection effect of each control model, we set the dropout parameter of each model to 0.5, and stop when the performance index of the neural network model does not change after five consecutive cycles on the validation set training to prevent overfitting. The initial learning rate of the model is set to 0.01, and the learning rate decays exponentially every five epochs.
According to
Table 10, the overall performance of the deep learning model is pretty good. The performance of the single model is inferior to the fusion control model, mainly because the deep fusion model fully extracts multi-level sample features. The accuracy of the Char-CNN model is higher than that of the Char-GRU, indicating that the false positive rate of the CNN model is lower. However, the accuracy and recall rate of the GRU model are higher than those of the CNN model, indicating that the performance of the GRU model is better than the CNN model in terms of feature mining and learning.
Our proposed feature fusion model outperforms the eXpose model on every metric. Our model guarantees low false negative and false positive rates while maintaining high accuracy. Compared with the eXpose model, the discrete features extracted by us are more complementary to the temporal features automatically extracted by the GRU neural network model. At the same time, it shows that our model can learn the performance characteristics of Web injection attacks well.
The C-LSTM model shows the best performance among all the comparative models, with each index exceeding 99%, and the F1-value reaching 99.26%. The reason C-LSTM can achieve this effect is that it integrates the advantages of Convolutional Neural Networks and Recurrent Neural Networks. The C-LSTM uses the convolutional neural network to obtain the local abstract features, extracts the sequence features with the recurrent neural network, and puts them together to the classifier for classification. However, the C-LSTM model has higher structural complexity compared with our model, so our model outperforms it in training time and memory consumption. In addition, the performance of our model is also better than that of the C-LSTM, because our proposed multi-classification model based on feature fusion adds discrete features derived from expert knowledge based on time series features. To a certain extent, our model reduces the parameter quantity and structural complexity, and ensures the adequacy and complementarity of feature extraction at the same time.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}