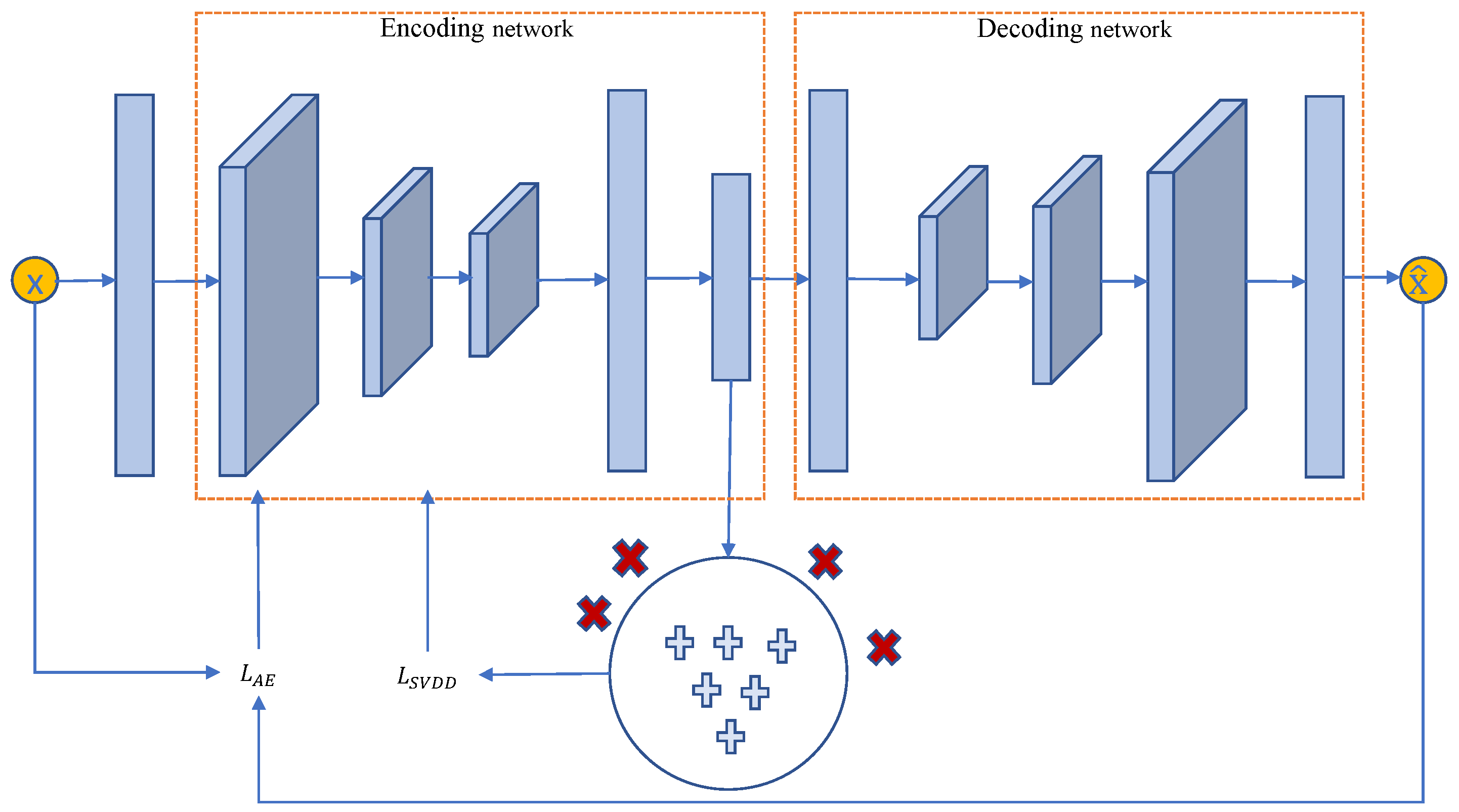
In this paper, we propose a novel deep learning model for the intrusion detection task of an industrial control network, as shown in
Figure 1. The proposed model is composed of two parts. The 1DCAE is utilized to extract the characteristics of industrial normal traffic flow, and SVDD is applied as the intrusion detection classifier. The features extracted via the encoder of 1DCAE are transferred to subsequent SVDD to learn a hypersphere, and the decoder of 1DCAE handles these representations to reconstruct the input. The next sections describe the motivation and technical details of the two parts, respectively, and propose objective functions. Then, the complete detection process and training process of the model are presented.
4.1. Autoencoder for Feature Learning and Motivation Analysis
In recent years,
AE has been introduced as a solution for intrusion detection in various environments [
5]. The variants of the autoencoder have been applied in many studies. This work applies
AE to extract key features. Therefore, this section first carries out the analysis on typical variants of the autoencoder and the selection of hidden layers, and explains the motivation for selecting 1DCAE.
The sparse
AE [
27] assumes that high-dimensional sparse features are good features, which is feasible in other fields. However, this work combines deep learning with a traditional classifier. The traditional classifier usually achieves poor efficiency and accuracy when processing massive high-dimensional data. Therefore, high-dimensional features play a negative role in the proposed model. The stacked
AE obtains the deep feature expression of the original input by training multiple AE structures in stages. However, in the process of multiple training,
AE excessively pursues dimension reduction and does not consider the subsequent processing of the extracted features, which cannot ensure that all the key information of intrusion detection is retained. The denoising
AE adds noise by randomly changing some features to 0 at the input to extract more robust features. However, some attack samples are highly similar to normal samples. By eliminating some features, the distance between the two samples will be further narrowed, or it may be entirely removed. Variational
AE [
28] has been a widely recognized generative model in recent years. The main task of
AE in this paper is to extract key features, whereas variational
AE aims to learn potential distribution, which is irrelevant to the purpose of this paper. According to extensive experiments, there is little difference in the final result between a traditional
AE structure and variational
AE. In order to simplify the model structure, VAE structure is not used in this paper. Asymmetric structure is a common implementation method, which is not analyzed as a major variant in this paper.
In order to extract specific features, we also need to select a specific hidden layer network structure. The RNN (recurrent neural network) and its variants are widely used in many studies of industrial intrusion detection [
5]. After experimental analysis, this paper believes the application of RNN is based on the following assumptions. Firstly, the information traces recorded by the attack are considered time-dependent. Some attacks, such as DoS (denial of service), can generate multiple connection records at different times, and there are temporal correlations between these records. In addition, the industrial control network is composed of specific protocols. Each protocol specifies a specific data packet receiving and sending sequence; i.e., the data packets of the network traffic have temporal characteristics. This paper utilizes the network traffic flow feature of normal samples, which has no temporal correlation. Although RNN is widely used in intrusion detection research [
5], due to the above considerations, the proposed model does not integrate the RNN structure. Some studies use CNNs to extract local spatial features [
5] between features, which are also based on a certain assumption: that adjacent features are correlated. For common datasets, which divide features into several categories, the adjacent features of each category are often semantically related. For 2D CNNs, the traffic features are converted into a 2D structure, and then the spatial features are extracted with a 2D convolution kernel. However, some completely unrelated features may appear in the same region after being converted into a two-dimensional picture. Extracting the correlations of these features will introduce redundant features to mislead the neural network and subsequent classifiers. The one-dimensional convolution will not cause this problem. The one-dimensional convolution kernel is performed from front to back along the feature vector. The features covered by each convolution kernel usually belong to the same category of features and have a potential correlation. The 1DCAE extracts more valuable feature representations, considering the relationships between the features which are more meaningful for intrusion detection. Considering the above reasons, we adopted 1DCAE to extract the key features of intrusion detection. The specific model structure and calculation process are described below.
Significantly, the structure of the AE has a great impact on the performance of subsequent classifiers. In this work, a series of experiments were carried out, and the AE network structure shown in the figure was finally determined. Each cube in the encoder part represents a combination of convolution, batch normalization, activation and pooling. The number of filters in each layer from the front to the back is halved in turn, and the size of convolution cores remains . This structure can eliminate redundant features and effectively reduce the dimensions of the feature map. Each convolution is followed by a max pooling layer with a size of to obtain the basic characteristics of network traffic and improve the feature expression ability. Then, the feature map is expanded into vector form. The full connection layer of the encoder integrates features and further reduces dimensions to enhance the generalization ability of the model. The decoder first uses the full connection layer to recover the dimensions of the expanded vector, and then applies the deconvolution and up-sampling corresponding to the encoder to recover the dimensions of the input data.
The deep learning architecture of 1DCAE consists of multiple hidden layers. The calculation process of obtaining hidden feature representations at each layer can be defined recursively, expressed as follows:
where
l is the number of layers.
represents the original input vector
X.
is the output of
AE.
This work applies mean squared error (MSE) as the reconstruction error of 1DCAE between the original network traffic input vector and the reconstructed network traffic output vector. Given some training samples
, the objective function of 1DCAE can be defined as:
where
donates the output of AE,
.
4.2. The Object Function of SVDD in the Model
As mentioned above, SVDD aims to teach a hypersphere to contain as much training data as possible to distinguish normal and abnormal patterns. In order to utilize the advantages of deep learning in feature mapping, this work applied the DSVDD objective function proposed by Ruff [
29]. Given the input vector
X, let
represent the mapped data points. In order to minimize the volume of the hypersphere, the objective of DSVDD can be defined as:
where the second term is a penalty term for points outside the hypersphere. The last term is the regularizer.
W represents the parameters of the mapping network.
and
control the trade-off between the two terms. We fix
c as the mean of the latent representations by employing an initial forward pass with some training data instances [
29].
According to the code provided by Ruff, the percentage division method is used to select
R considering the distances from all data points to the spherical center. This method is similar to the sampling operation when there is no gradient to be calculated. Therefore, the first term of R in the objective function will not affect the back-propagation process. We propose a simplified version of the objective function as:
We only use normal network samples. If the assumption that most of the data samples in the training set are normal samples is true, a simplified objective of SVDD can be defined as:
where the first term penalizes the distance of every mapped point
from the center.
The two objective functions are, respectively, used to train the same network model. The experimental results representing the latter can usually obtain higher accuracy. However, the former has its own advantages. After the training, the former can automatically obtain a decision boundary. The latter can only obtain a set of abnormal scores, and we have to manually set the decision boundary according to experiments and prior information of test set. To obtain the best performance of model, the last objective function was used in the subsequent work of this paper.
4.3. Deep 1DCAE-SVDD Model
Notably, the ability of DSVDD to obtain good classification results depends on the proper training of the neural network [
30]. Therefore, there are many strict restrictions on the training process and network structure of DSVDD. First, the spherical center vector C cannot be set to 0 and cannot be a free variable, which may mislead the neural network, resulting in
and
. In addition, each neuron of the neural network cannot have bia items. Otherwise, the neural network obtains the result of
= constant and
[
30]. For similar reasons, neural networks cannot use bounded activation functions. If limitations are not met, all data samples may be mapped to the same point. Consequently, the learned
R is equal to 0 and SVDD fails to divide normal and abnormal points, which is called hypersphere collapse. The cause of these limitations is that the optimization process only aims to minimize the volume of the hypersphere, not considering retaining the necessary data information for classification tasks.
The training process of the
AE is similar to that of DSVDD. By specifying the dimensions of the bottleneck layer,
AE can achieve a satisfactory trade-off between dimension reduction and feature extraction. However,
AE can not guarantee that the bottleneck layer contains the necessary information for subsequent tasks [
17]. Some information may not be important for reconstructing input, but can play an important role in subsequent tasks. According to the objective function and model structure, AE only focuses on reducing dimensions and reconstructing input, without prior information of subsequent intrusion detection tasks.
To solve the common problems of
AE and DSVDD in intrusion detection applications, we created the solution of joint optimization of
AE and DSVDD, called 1DCAE-SVDD. The main scheme is to construct a neural network structure with a joint optimization objective combining two objective functions. One objective is to compact the mapping data points as closely to the mapping center as possible and holds necessary information for intrusion detection tasks in the bottleneck layer. Another objective is to preserve the original information by reconstructing the network input. If the encoding network maps all data samples to the same point, the decoding network fails to reconstruct different input data samples, resulting in great reconstruction error, which effectively avoids the hypersphere collapse. Given original samples
X, the 1DCAE-SVDD optimization objective is defined as:
where
is the encoding network of
AE and
is the parameter of the encoder.
is the
AE network, and
is the parameter of the
AE.
and
control the trade-off between reconstruction error and the distance from a mapped point to the center
c.
4.4. Intrusion Detection with 1DCAE-SVDD
In this work, the distance between a mapped point of the original data and the spherical center in the latent space is defined as the anomaly score of the network traffic sample vector. For a given test point
, the anomaly score of
X can be expressed as:
where
is the encoding network.
c is the center of hypersphere, which is a trainable parameter. The higher the value of
, the more likely network traffic sample
X is to be attacked. The purpose of the proposed method is to construct a hypersphere containing most data sample points in the latent space. The hypersphere is defined by the sphere’s center and radius. The radius
R is the classification boundary of anomaly scores. All the training samples are normal samples. Theoretically, all normal samples can be included if the radius R is the maximum value of the abnormal score. However, the training samples contain many outliers, it is deviating. The hypersphere formed by applying the maximum distance as the radius r has a lot of free space, leading to a large rate of false positives in the test set. Therefore, we think the proper balance between accuracy and sphere volume should be considered. We set
R as the 93th percentile of anomaly scores of training set. The anomaly score calculated by the formula is compared with the radius R. If it is greater than
R, the mapped point will fall outside the sphere, which is considered as attack traffic and vice versa, as shown in lines 21–25 of Algorithm 1.
| Algorithm 1 The working procedure of 1DCAE-SVDD |
| Require: Training set , |
| training epoch , |
| learning rate |
| 1: Initialize with kaiming algorithm |
| 2: for do |
| 3: |
| 4: |
| 5: Calculate with (8) |
| 6: |
| 7: end for |
| 8: Initialize the center c; |
| 9: for do |
| 10: |
| 11: Calculate with (11) |
| 12: |
| 13: end for |
| 14: for do |
| 15: |
| 16: |
| 17: Calculate with (12) |
| 18: |
| 19: end for |
| 20: return and the centre of sphere c |
| 21: Calculating the anomaly score of of with (13). |
| 22: percentile of the anomaly scores of all training samples. |
| 23: Extracting the latent feature of each test samples with (1). |
| 24: Obtaining the anomaly score of mapped point with (13). |
| 25: Comparing with R. |
4.5. Train Optimization
This section introduces the training process of the model. Only normal network traffic samples are utilized in the entire training process. In order to solve the problems of AE and DSVDD, this work introduces a joint optimization solution. However, there are some problems with applying the joint optimization framework.
The experiments represent that if the joint optimization method is used in the initial stage of training, the speed of loss reduction is slower than that of two-stage training, and the detection accuracy is not significantly improved after 100 epochs. We think that at the initial stage of training, the loss of a single objective decreases rapidly and the network parameters change dramatically. The multi-objective learning affects the training process of the encoding network simultaneously. A certain objective has a greater impact, interfering with the learning process of another objective. As a result, both objectives are not achieved, instead of benefiting from multiple objectives. Theoretically, the influences of AE and DSVDD on the encoding network can be balanced by adjusting the hyperparameters and . However, the actual influence of reconstruction error consists of hyperparameters and the weight of the decoding network. The decoding network’s weight changes sharply at the beginning of training, and the hyperparameters can not effectively control the influence of reconstruction error on the encoding network. In order to obtain better detection accuracy of IDCAE-SVDD, the following three-stage optimization procedures were designed.
First, the 1DCAE is pre-trained by normal samples. Specifically, for each data sample, the reconstruction result can be obtained by (1) and (2), and the reconstruction objective is calculated by (8) to update the weights of encoding network and decoding network (lines 1–7). Then, we extract the encoding network of AE and combine it with the SVDD classifier (lines 8–13). For all data samples of each batch, the extracted result is obtained by (1). The mapped point is subsequently processed by SVDD, and the hypersphere loss is calculated by (11). Only the encoding network weight is updated in second stage. Next, in the joint training phase (lines 14–19), the mapped points are calculated by applying (1). The point is used to reconstruct the input vector and construct the hypersphere simultaneously. The joint objective loss can be obtained by (12) to update all the trainable parameters of the model. The working procedure of 1DCAE-SVDD is shown in Algorithm 1.





{kind=link}
{kind=link}