
Fairness-Aware Predictive Graph Learning in Social Networks


Abstract
:1. Introduction
- Biases Formulation: We formally define two biases, i.e., Preference and Favoritism that widely exist in current predictive learning models. Based on the formulation, we utilize modularity maximization to distinguish weak and strong links.
- Fairness-aware Predictive Graph Learning: We propose ACE, a novel predictive learning framework that seamlessly integrates link strength to differentiate the learning process and a dual propagation process.
- Real-world Social Networks Evaluation: We empirically verify the efficacy by experiments on link prediction. Experimental results demonstrate that ACE achieves great improvement and smaller extents of the two biases than nine baseline methods.
2. Related Work
3. Preliminaries
3.1. Graph
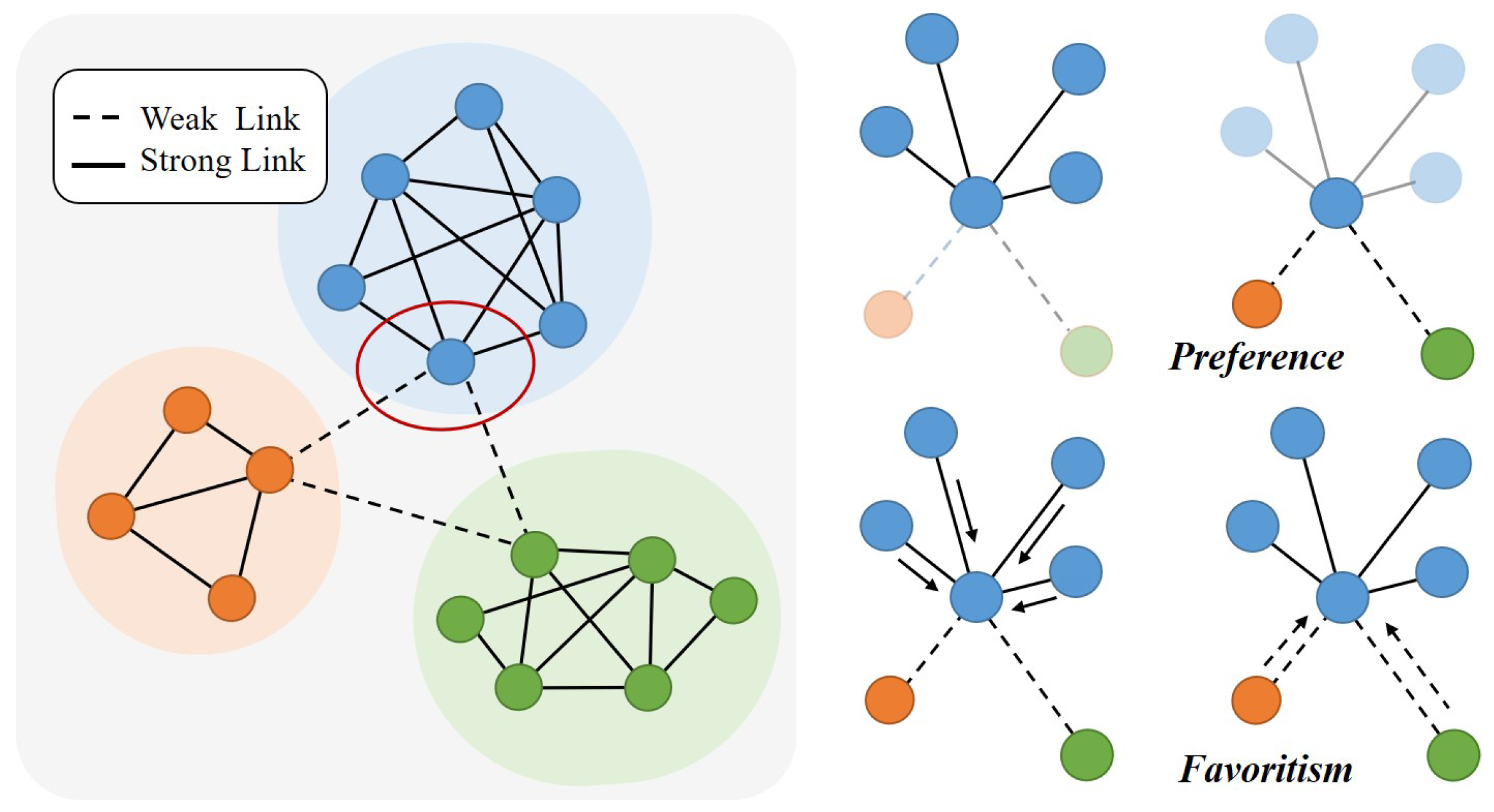
3.2. Biases
- Preference: If one method shows Preference to one side, it prefers to perform link prediction on that side so that it performs link prediction better on one side than on the other side.
- Favoritism: If one method shows Favoritism to one side, it favors one side and neglects the other side so that it gives higher scores to one side when performing link prediction.
4. The Design of ACE
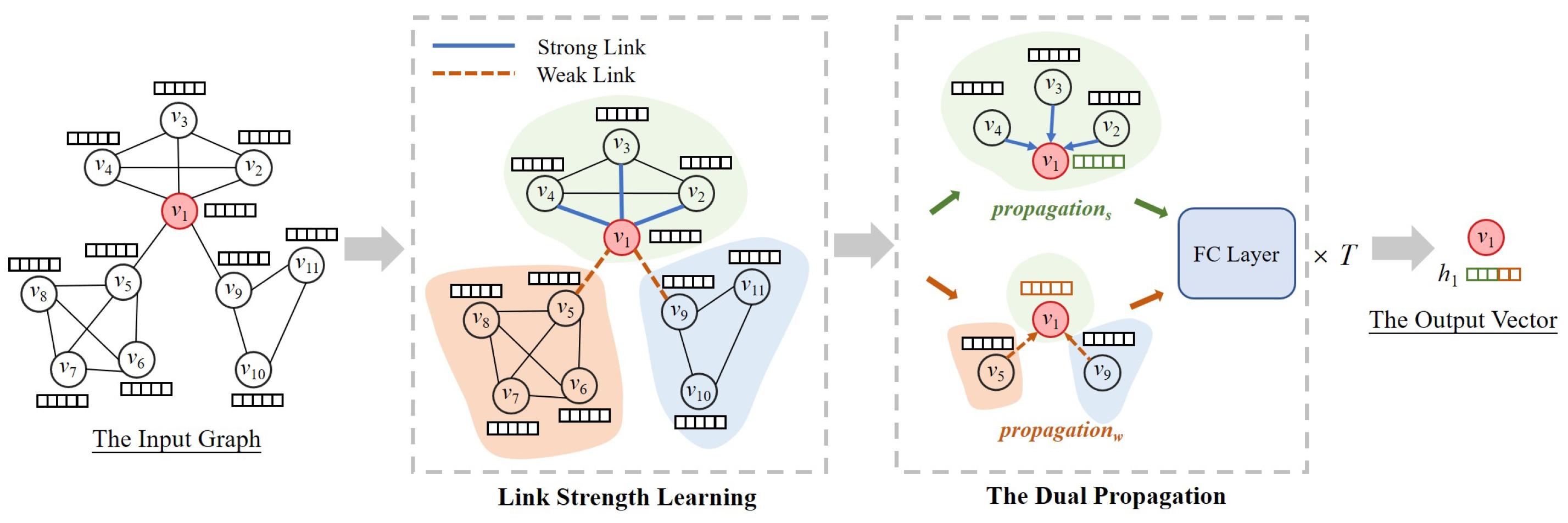
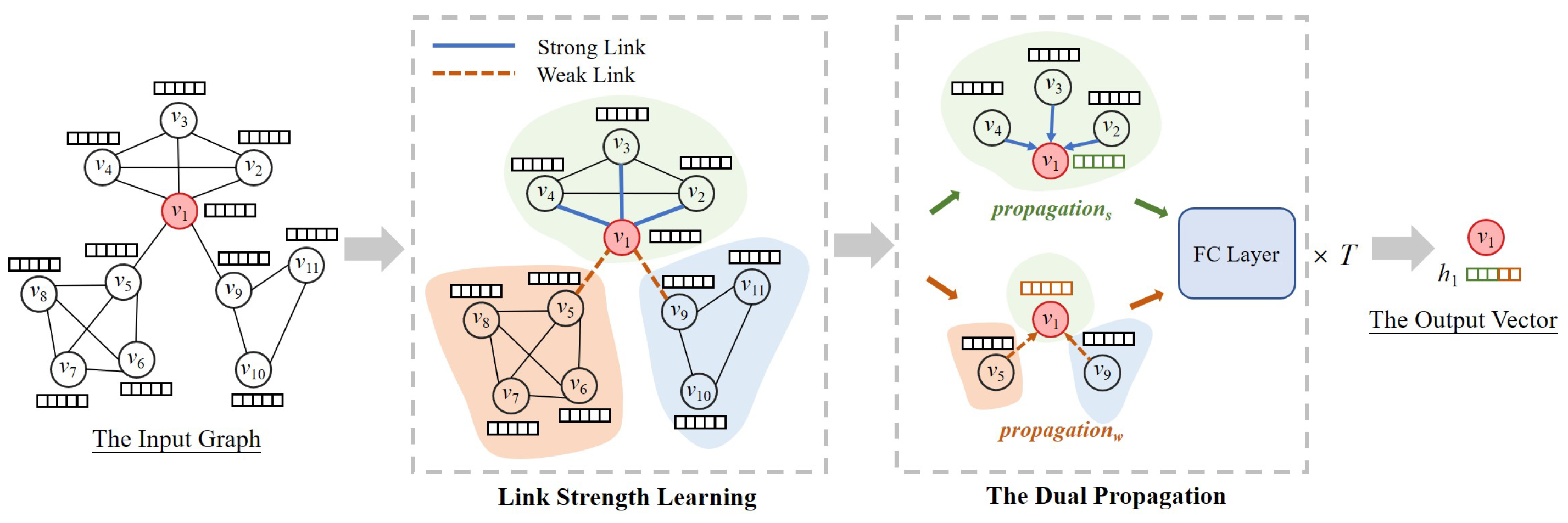
4.1. Link Strength Learning
4.2. Dual Propagation
4.3. Supervised Learning
| Algorithm 1 Training Process of ACE. |
|
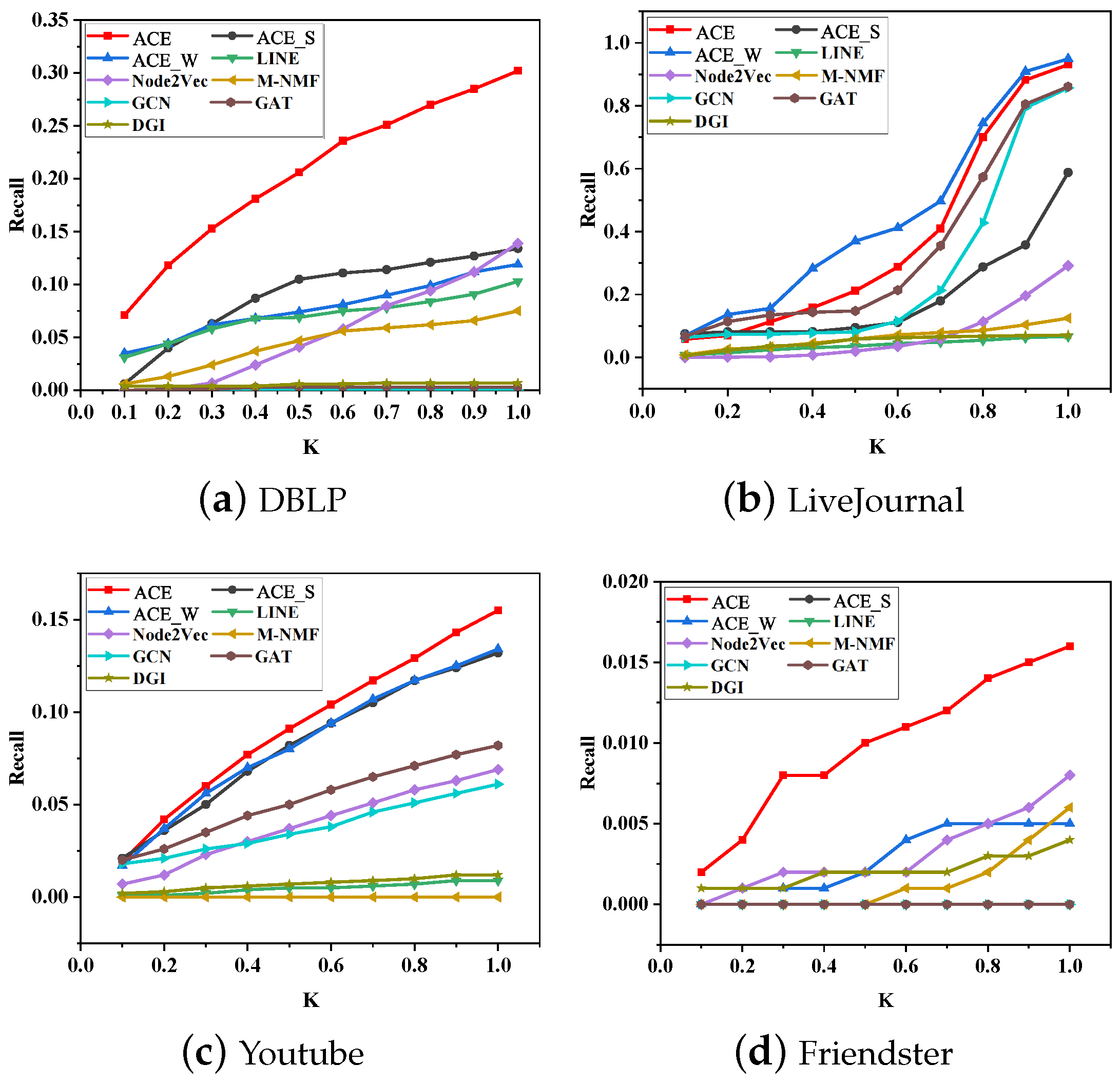
5. Experiments
5.1. Datasets
- Node2vec learns embedding vectors through vertices sequences sampled by a random walk. LINE learns embedding vectors by preserving both first-order and second-order proximities. M-NMF captures community structure through modularity and preserves second-order proximities to learn embedding vectors.
- GCN [25], GAT [26], and DGI [27] are three GNN-based methods. GCN defines a layer-wise propagation rule by spectral graph convolutions. GAT uses self-attention to assign a weight to each neighbor and employs multi-head attention to keep stability. DGI learns vector representations by maximizing mutual information between patch representations and corresponding high-level summaries of graphs.
- ACE_S: It only uses one part of the dual propagation.
- ACE_W: It only uses one part of the dual propagation.
- : the example set of existent strong links.
- : the example set of existent weak links.
- : the example set of nonexistent strong links.
- : the example set of nonexistent weak links.
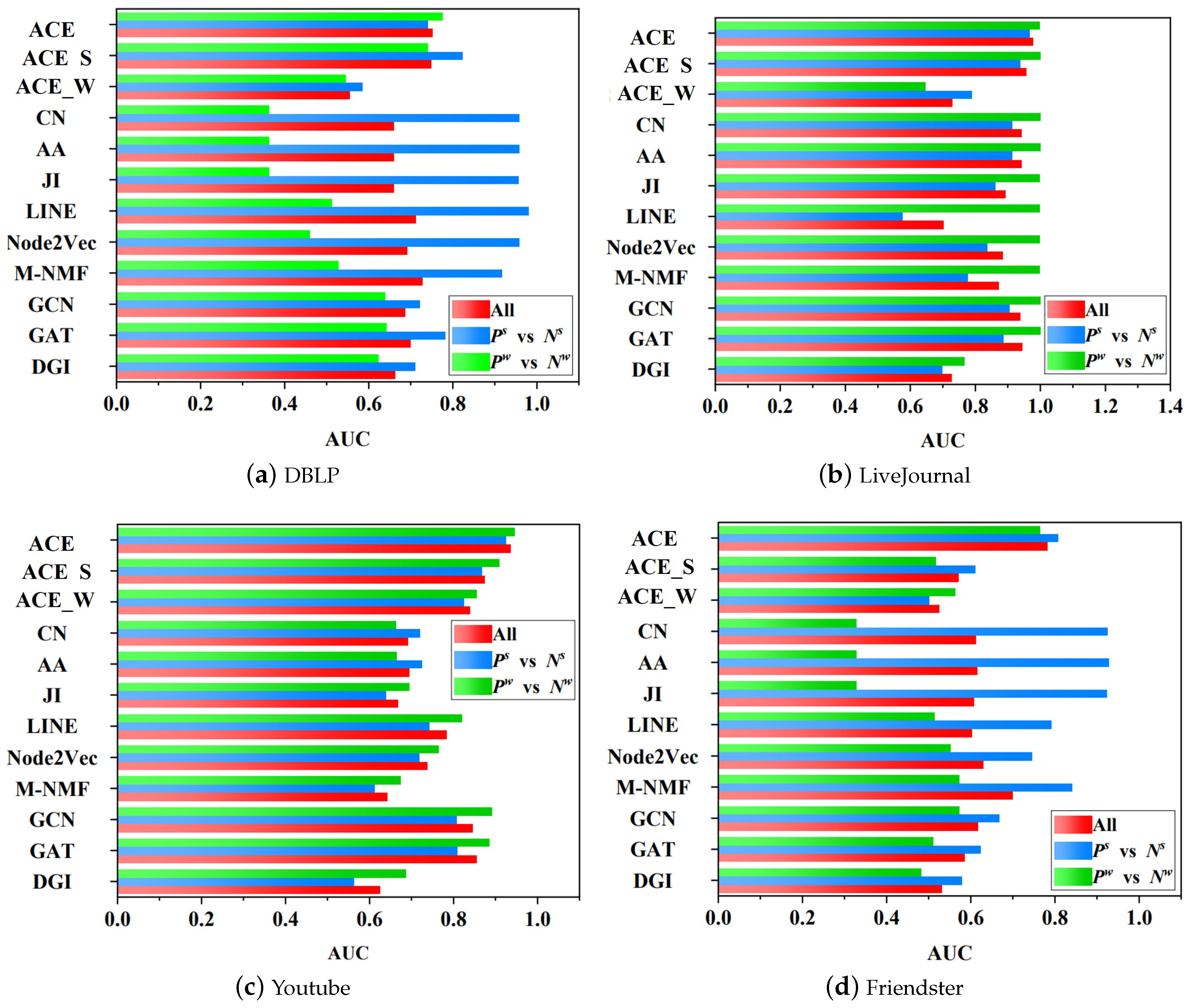
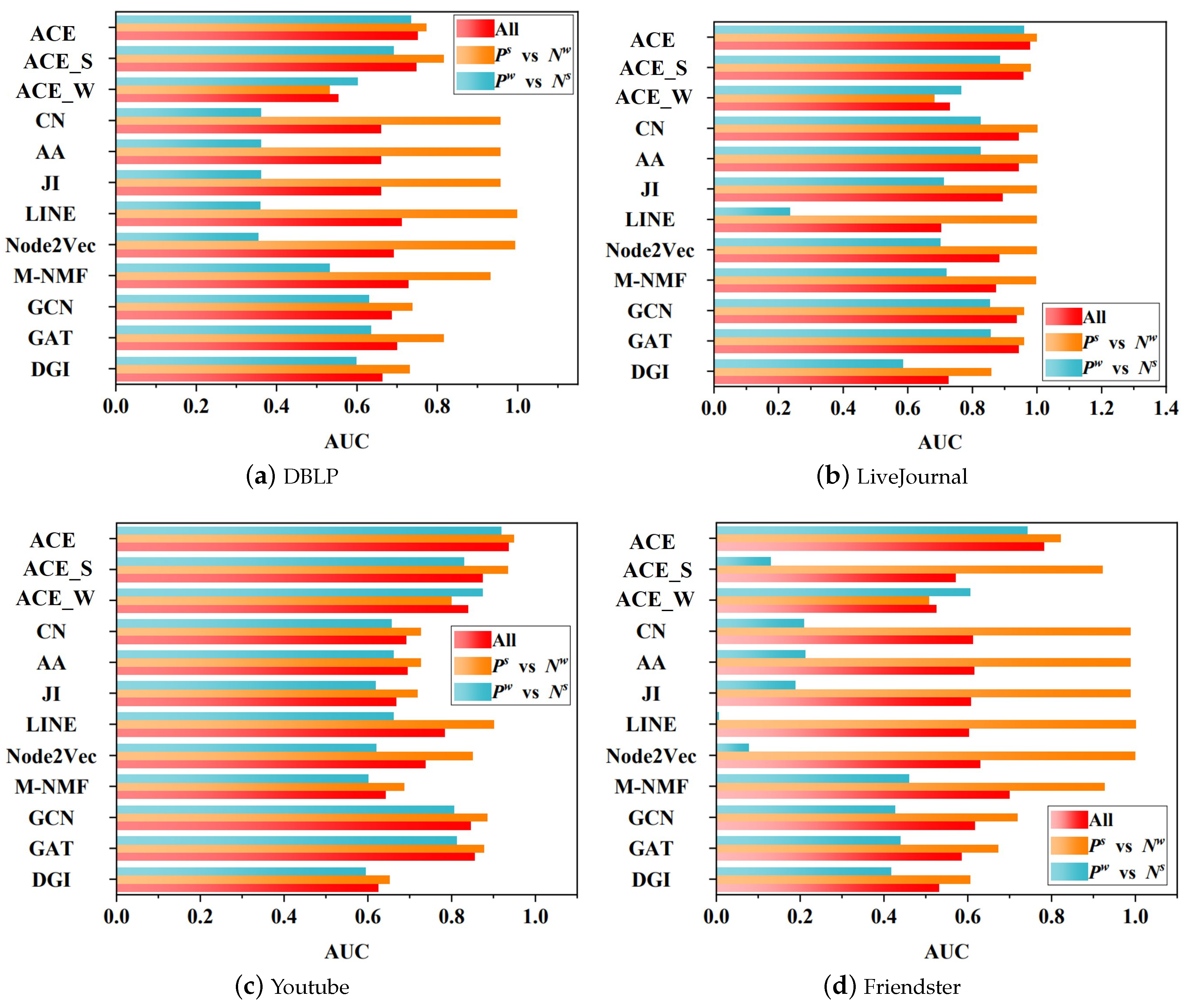
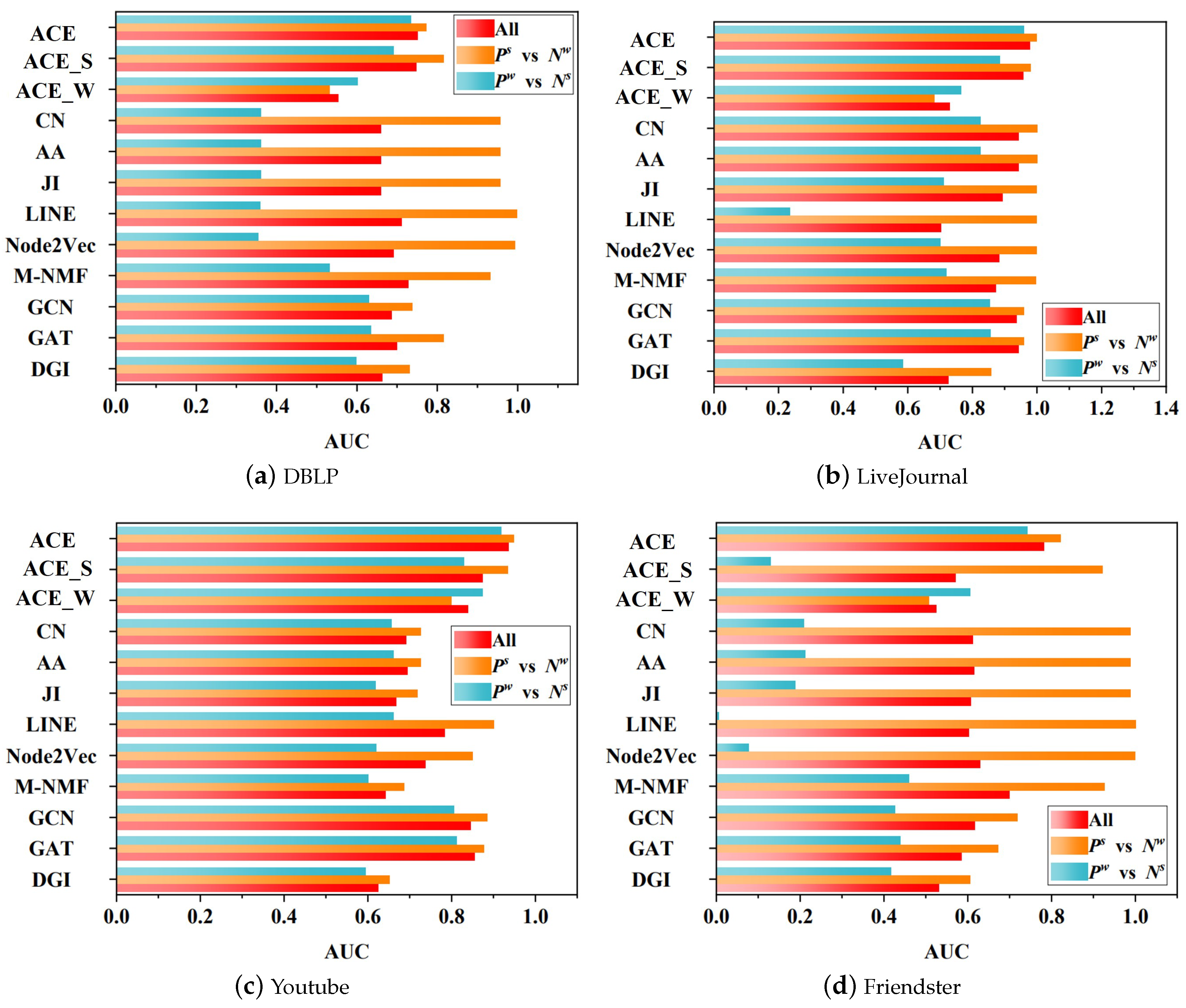
5.2. Fairness Analysis
- vs. : The experiment on it tells us the capacity with respect to predicting positive links on strong links.
- vs. : The experiment on it tells us the capacity with respect to predicting positive links on weak links.
- vs. : The experiment on it tells us the capacity with respect to predicting positive strong links that are mingled with negative weak links.
- vs. : The experiment on it tells us the capacity with respect to predicting positive weak links that are mingled with negative strong links.
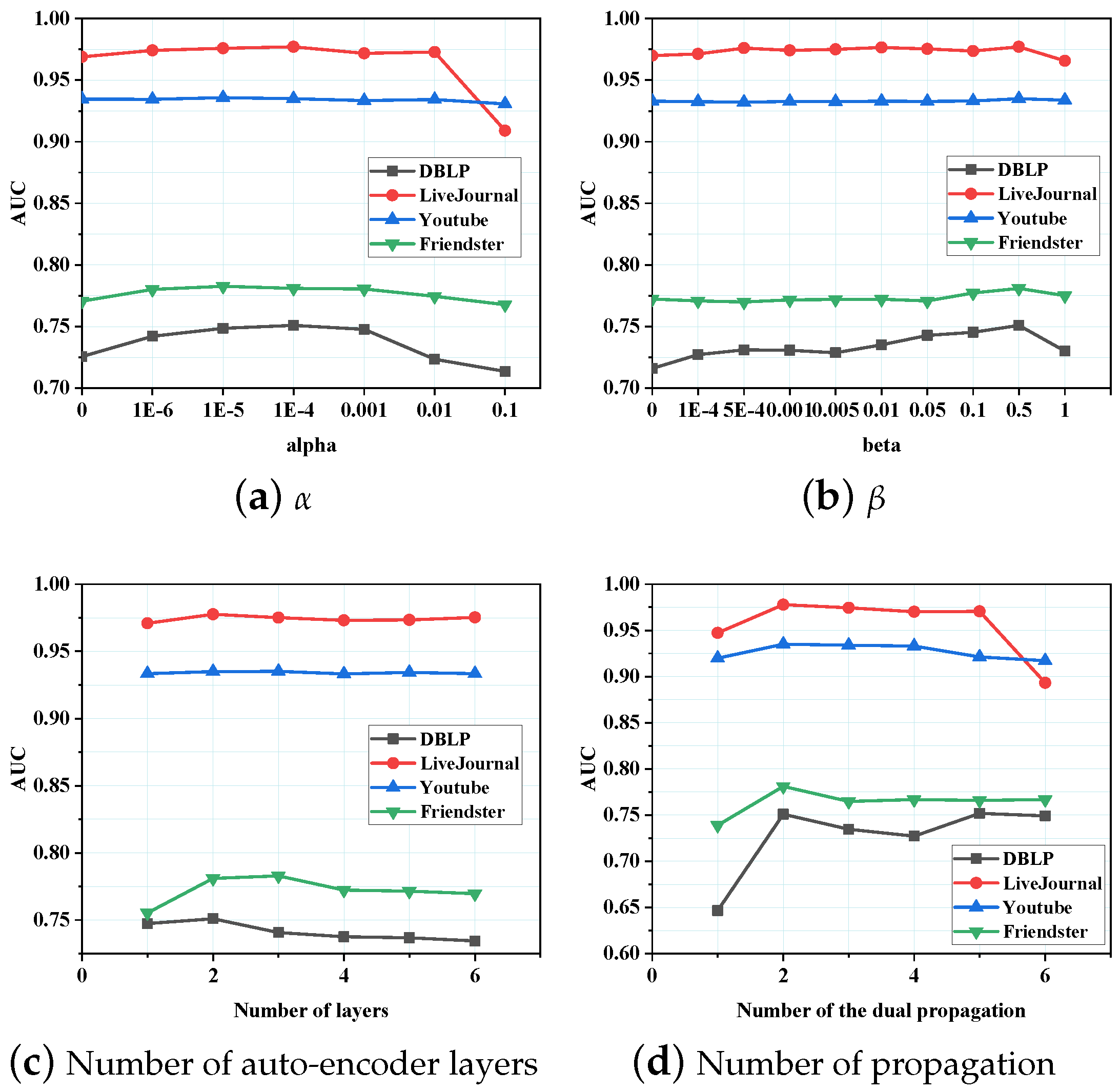
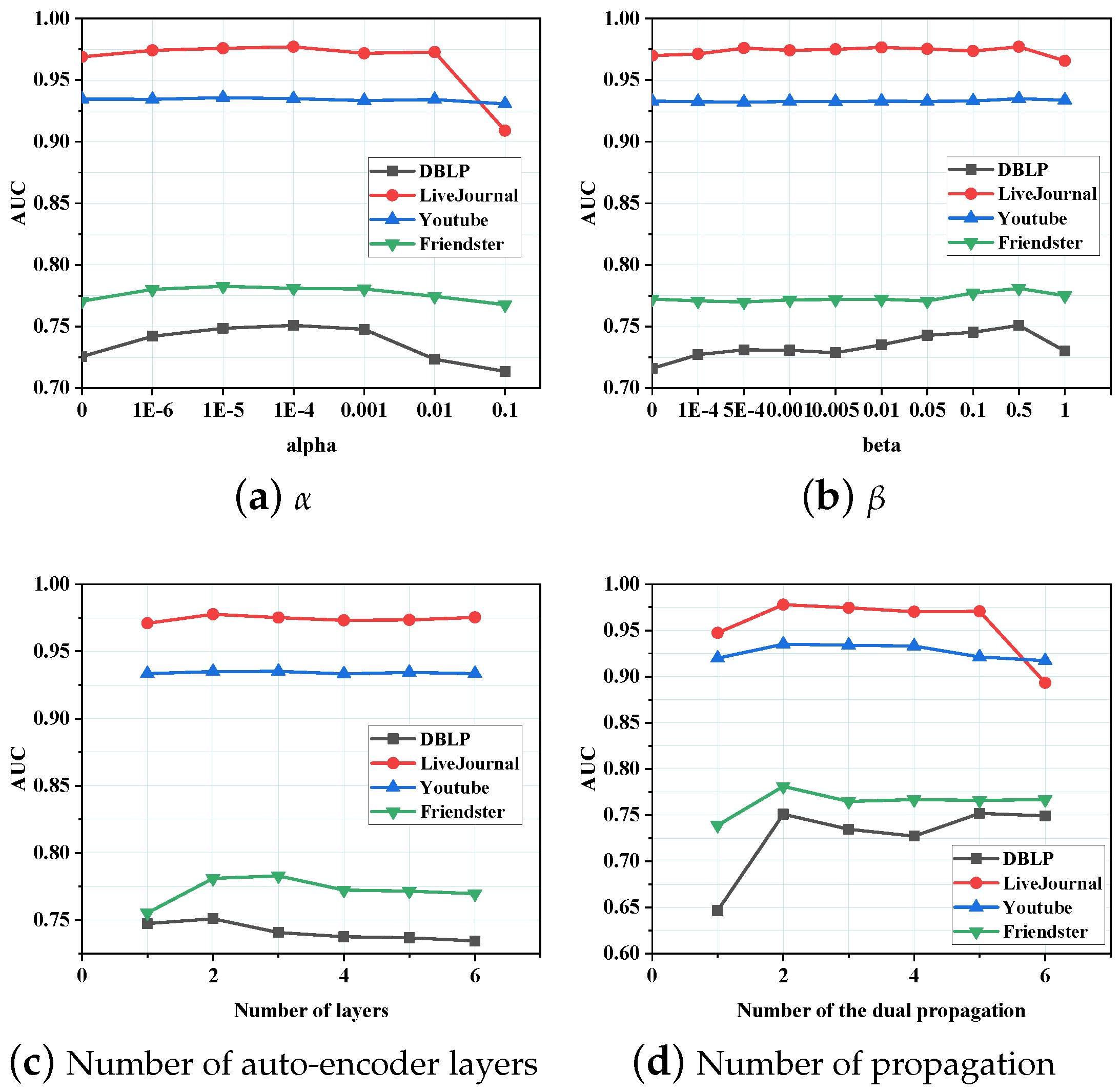
5.3. Parameter Sensitivity
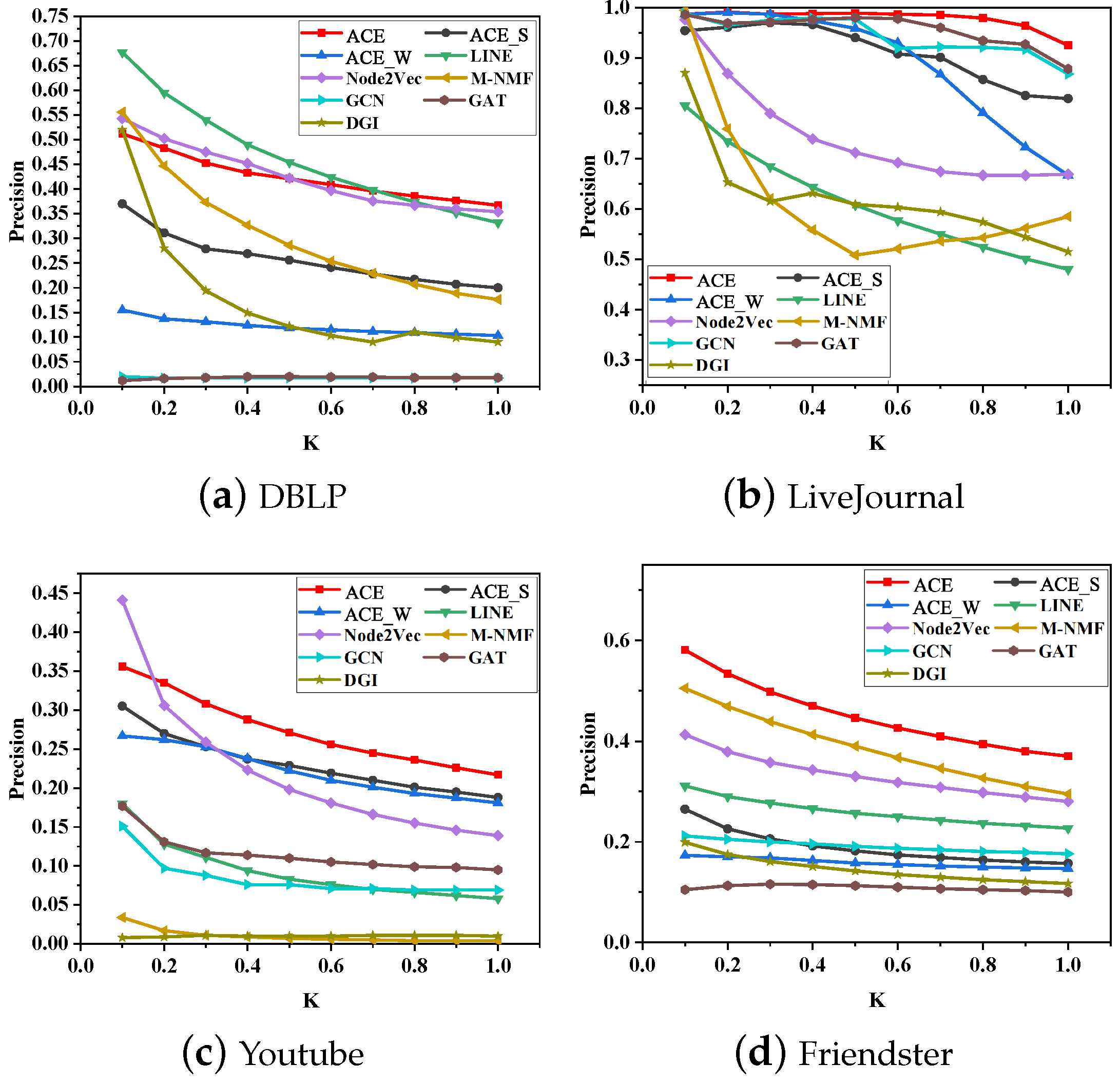
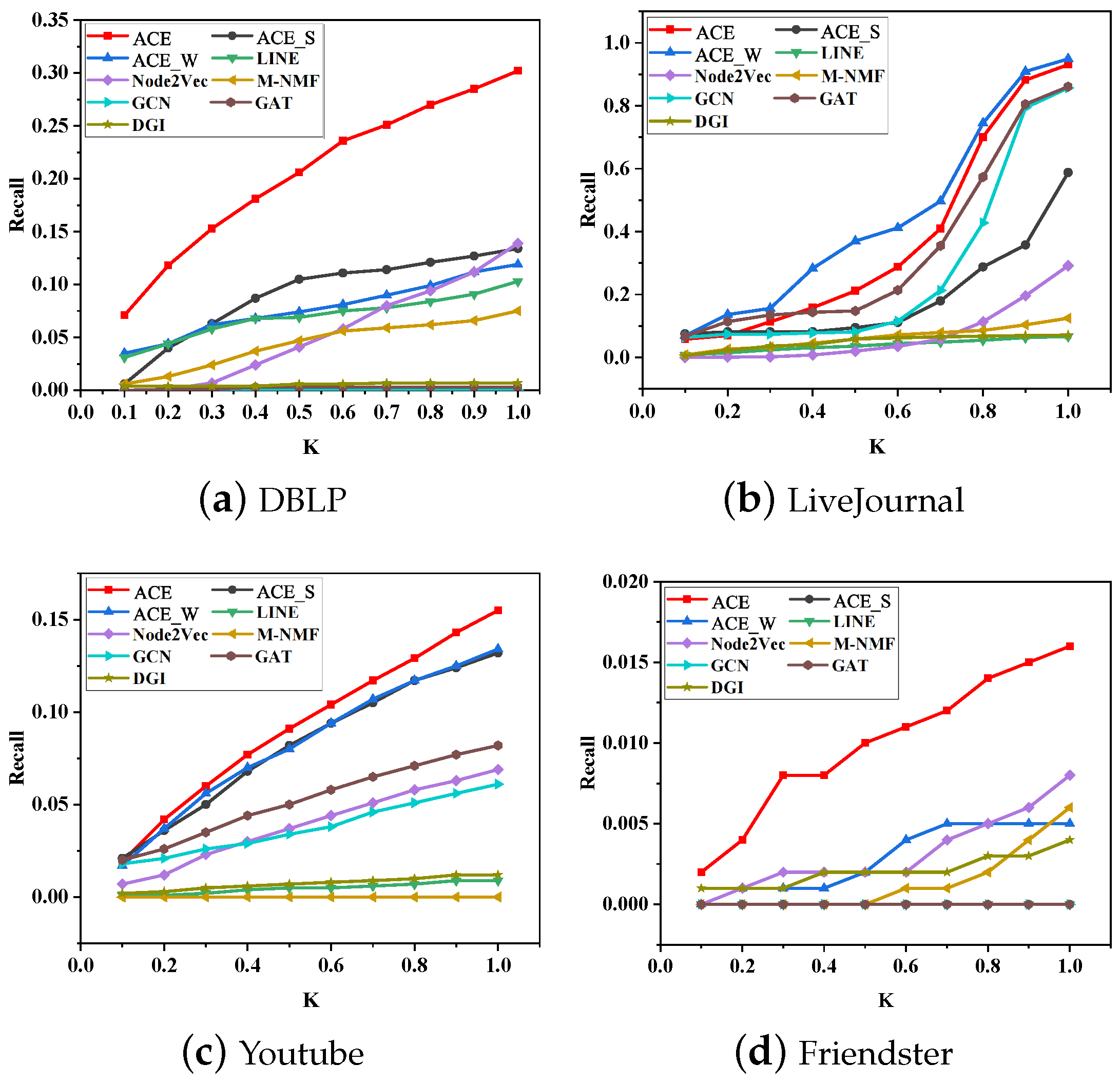
5.4. Network Reconstruction
5.5. Gain Rate
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wang, W.; Gong, Z.; Ren, J.; Xia, F.; Lv, Z.; Wei, W. Venue topic model–enhanced joint graph modelling for citation recommendation in scholarly big data. ACM Trans. Asian Low-Resour. Lang. Inf. Process. (TALLIP) 2020, 20, 1–15. [Google Scholar] [CrossRef]
- Kong, X.; Wang, K.; Hou, M.; Xia, F.; Karmakar, G.; Li, J. Exploring Human Mobility for Multi-Pattern Passenger Prediction: A Graph Learning Framework. IEEE Trans. Intell. Transp. Syst. 2022, 1–13. [Google Scholar] [CrossRef]
- Liu, J.; Xia, F.; Feng, X.; Ren, J.; Liu, H. Deep Graph Learning for Anomalous Citation Detection. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 2543–2557. [Google Scholar] [CrossRef] [PubMed]
- Rahmattalabi, A.; Vayanos, P.; Fulginiti, A.; Rice, E.; Wilder, B.; Yadav, A.; Tambe, M. Exploring Algorithmic Fairness in Robust Graph Covering Problems. In Proceedings of the 33rd International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Curran Associates Inc.: Red Hook, NY, USA, 2019. [Google Scholar]
- Tsioutsiouliklis, S.; Pitoura, E.; Tsaparas, P.; Kleftakis, I.; Mamoulis, N. Fairness-Aware PageRank. In Proceedings of the WWW’21 Web Conference 2021, Ljubljana, Slovenia, 19–23 April 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 3815–3826. [Google Scholar] [CrossRef]
- Xia, F.; Sun, K.; Yu, S.; Aziz, A.; Wan, L.; Pan, S.; Liu, H. Graph Learning: A Survey. IEEE Trans. Artif. Intell. 2021, 2, 109–127. [Google Scholar] [CrossRef]
- Hou, M.; Ren, J.; Febrinanto, F.; Shehzad, A.; Xia, F. Cross Network Representation Matching with Outliers. In Proceedings of the 2021 International Conference on Data Mining Workshops (ICDMW), Auckland, New Zealand, 7–10 December 2021; pp. 951–958. [Google Scholar]
- Bedru, H.D.; Yu, S.; Xiao, X.; Zhang, D.; Wan, L.; Guo, H.; Xia, F. Big networks: A survey. Comput. Sci. Rev. 2020, 37, 100247. [Google Scholar] [CrossRef]
- He, W.J.; Ai, D.X.; Wu, C. A recommender model based on strong and weak social Ties: A Long-tail distribution perspective. Expert Syst. Appl. 2021, 184, 115483. [Google Scholar]
- Tu, J. The role of dyadic social capital in enhancing collaborative knowledge creation. J. Inf. 2020, 14, 101034. [Google Scholar] [CrossRef]
- Xian, X.; Wu, T.; Liu, Y.; Wang, W.; Wang, C.; Xu, G.; Xiao, Y. Towards link inference attack against network structure perturbation. Knowl. Based Syst. 2021, 218, 106674. [Google Scholar] [CrossRef]
- Han, D.; Li, X. How the weak and strong links affect the evolution of prisoner’s dilemma game. New J. Phys. 2019, 21, 015002. [Google Scholar] [CrossRef] [Green Version]
- Rêgo, L.C.; dos Santos, A.M. Co-authorship model with link strength. Eur. J. Oper. Res. 2019, 272, 587–594. [Google Scholar]
- Hou, M.; Ren, J.; Zhang, D.; Kong, X.; Zhang, D.; Xia, F. Network embedding: Taxonomies, frameworks and applications. Comput. Sci. Rev. 2020, 38, 100296. [Google Scholar] [CrossRef]
- Zhang, J.; Wang, W.; Xia, F.; Lin, Y.R.; Tong, H. Data-driven Computational Social Science: A Survey. Big Data Res. 2020, 21, 100145. [Google Scholar] [CrossRef]
- Liben-Nowell, D.; Kleinberg, J. The link-prediction problem for social networks. J. Am. Soc. Inf. Sci. Technol. 2007, 58, 1019–1031. [Google Scholar] [CrossRef] [Green Version]
- Jaccard, P. Étude comparative de la distribution florale dans une portion des Alpes et des Jura. Bull. Soc. Vaud. Sci. Nat. 1901, 37, 547–579. [Google Scholar]
- Adamic, L.A.; Adar, E. Friends and neighbors on the web. Soc. Netw. 2003, 25, 211–230. [Google Scholar] [CrossRef] [Green Version]
- Perozzi, B.; Al-Rfou, R.; Skiena, S. Deepwalk: Online learning of social representations. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 701–710. [Google Scholar]
- Grover, A.; Leskovec, J. Node2vec: Scalable feature learning for networks. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 855–864. [Google Scholar]
- Tang, J.; Qu, M.; Wang, M.; Zhang, M.; Yan, J.; Mei, Q. Line: Large-scale information network embedding. In Proceedings of the 24th International Conference on World Wide Web, International World Wide Web Conferences Steering Committee, Florence, Italy, 18–22 May 2015; pp. 1067–1077. [Google Scholar]
- Feng, R.; Yang, Y.; Hu, W.; Wu, F.; Zhuang, Y. Representation Learning for Scale-free Networks. AAAI Conf. Artif. Intell. 2018, 32, 282–289. [Google Scholar] [CrossRef]
- Liao, L.; He, X.; Zhang, H.; Chua, T.S. Attributed Social Network Embedding. IEEE Trans. Knowl. Data Eng. 2018, 30, 2257–2270. [Google Scholar] [CrossRef] [Green Version]
- Scarselli, F.; Gori, M.; Tsoi, A.C.; Hagenbuchner, M.; Monfardini, G. The graph neural network model. IEEE Trans. Neural Netw. 2009, 20, 61–80. [Google Scholar] [CrossRef] [Green Version]
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. In Proceedings of the ICLR: International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Velickovic, P.; Cucurull, G.; Casanova, A.; Romero, A.; Liò, P.; Bengio, Y. Graph Attention Networks. In Proceedings of the ICLR: International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Veličković, P.; Fedus, W.; Hamilton, W.L.; Liò, P.; Bengio, Y.; Hjelm, R.D. Deep Graph Infomax. In Proceedings of the ICLR: International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Li, P.; Wang, Y.; Zhao, H.; Hong, P.; Liu, H. On Dyadic Fairness: Exploring and Mitigating Bias in Graph Connections. In Proceedings of the International Conference on Learning Representations, Virtual Event, Austria, 3–7 May 2021. [Google Scholar]
- Zhu, Z.; Hu, X.; Caverlee, J. Fairness-Aware Tensor-Based Recommendation. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management, Torino, Italy, 22–26 October 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 1153–1162. [Google Scholar]
- Masrour, F.; Wilson, T.; Yan, H.; Tan, P.N.; Esfahanian, A. Bursting the Filter Bubble: Fairness-Aware Network Link Prediction. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 841–848. [Google Scholar]
- Gao, J.; Schoenebeck, G.; Yu, F.Y. The volatility of weak ties: Co-evolution of selection and influence in social networks. In Proceedings of the 18th International Conference on Autonomous Agents and MultiAgent Systems, Montreal, QC, Canada, 13–17 May 2019; pp. 619–627. [Google Scholar]
- Yazdanparast, S.; Havens, T.C.; Jamalabdollahi, M. Soft overlapping community detection in large-scale networks via fast fuzzy modularity maximization. IEEE Trans. Fuzzy Syst. 2020, 29, 1533–1543. [Google Scholar] [CrossRef]
- Wang, X.; Cui, P.; Wang, J.; Pei, J.; Zhu, W.; Yang, S. Community preserving network embedding. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; pp. 203–209. [Google Scholar]
- Li, J.; Cai, T.; Deng, K.; Wang, X.; Sellis, T.; Xia, F. Community-diversified Influence Maximization in Social Networks. Inf. Syst. 2020, 92, 101522. [Google Scholar] [CrossRef]
- Lee, D.D.; Seung, H.S. Algorithms for non-negative matrix factorization. In Proceedings of the Advances in Neural Information Processing, Denver, CO, USA, 1 January 2000; pp. 535–541. [Google Scholar]
- Ali, S.; Shakeel, M.H.; Khan, I.; Faizullah, S.; Khan, M.A. Predicting attributes of nodes using network structure. ACM Trans. Intell. Syst. Technol. (TIST) 2021, 12, 1–23. [Google Scholar] [CrossRef]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gilmer, J.; Schoenholz, S.S.; Riley, P.F.; Vinyals, O.; Dahl, G.E. Neural message passing for Quantum chemistry. In Proceedings of the International Conference on Machine Learning Research, Sydney, Australia, 6–11 August 2017; Volume 70, pp. 1263–1272. [Google Scholar]
- Yang, J.; Leskovec, J. Defining and evaluating network communities based on ground-truth. Knowl. Inf. Syst. 2015, 42, 181–213. [Google Scholar] [CrossRef] [Green Version]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010; pp. 249–256. [Google Scholar]
- Kingma, D.P.; Ba, J.L. Adam: A Method for Stochastic Optimization. In Proceedings of the ICLR: International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Liu, J.; Xia, F.; Wang, L.; Xu, B.; Kong, X.; Tong, H.; King, I. Shifu2: A Network Representation Learning Based Model for Advisor-advisee Relationship Mining. IEEE Trans. Knowl. Data Eng. 2019, 33, 1763–1777. [Google Scholar] [CrossRef]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Holzinger, A.; Malle, B.; Saranti, A.; Pfeifer, B. Towards multi-modal causability with Graph Neural Networks enabling information fusion for explainable AI. Inf. Fusion 2021, 71, 28–37. [Google Scholar] [CrossRef]
- Holzinger, A.; Saranti, A.; Molnar, C.; Biecek, P.; Samek, W. Explainable AI Methods—A Brief Overview. In xxAI—Beyond Explainable AI: International Workshop, Held in Conjunction with ICML 2020, 18 July 2020, Vienna, Austria, Revised and Extended Papers; Holzinger, A., Goebel, R., Fong, R., Moon, T., Müller, K.R., Samek, W., Eds.; Springer International Publishing: Cham, Switzerland, 2022; pp. 13–38. [Google Scholar] [CrossRef]
- Holzinger, A. Interactive machine learning for health informatics: When do we need the human-in-the-loop? Brain Inform. 2016, 3, 119–131. [Google Scholar] [CrossRef] [Green Version]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notations | Definitions |
|---|---|
| The given graph G, node set V, and edge set E | |
| The set of weak link edges | |
| The set of strong link edges | |
| The set of edges in graph | |
| The set of neighbors linked to node i | |
| The set of strong neighbors linked to node i | |
| The set of weak neighbors linked to node i | |
| The attribute matrix of graph | |
| The adjacency matrix of graph | |
| The degree matrix of graph | |
| The training parameters | |
| The batch size in training model | |
| The attribute information matrix | |
| K | The layer number of auto-encoder |
| T | The number of the dual propagation |
| Dataset | Link Strength | ACE_S | ACE_W | LINE | Node2Vec |
|---|---|---|---|---|---|
| DBLP | Strong | 83.5% | 258.2% | 9.2% | 2.8% |
| Weak | 124.6% | 152.9% | 192.2% | 116.5% | |
| LiveJournal | Strong | 12.1% | 40.2 % | 88.7% | 36.4% |
| Weak | 58.3% | −1.9% | 1289.6% | 218.8% | |
| Youtube | Strong | 16.6% | 21.5% | 231.4% | 46.7% |
| Weak | 17.4% | 15.7% | 1622.2% | 124.6% | |
| Friendster | Strong | 136.1% | 152.0% | 62.1% | 31.8% |
| Weak | inf | 220.0% | inf | 100% | |
| Dataset | link strength | M-NMF | GCN | GAT | DGI |
| DBLP | Strong | 107.3% | 2070.6% | 1950.0% | 301.1% |
| Weak | 301.3% | inf | 9933.3% | 4200.0% | |
| LiveJournal | Strong | 55.5% | 6.7% | 5.4% | 75.9% |
| Weak | 644.8% | 8.6 | 8.1% | 1211.3% | |
| Youtube | Strong | 4540% | 231.4% | 136.7% | 2220.0% |
| Weak | inf | 154.1 | 89.0% | 1191.2% | |
| Friendster | Strong | 25.6% | 109.6% | 269.3% | 216.1% |
| Weak | 166.7% | inf | inf | 300.0% |
| Dataset | ACE | ACE_S | ACE_W | CN | AA | JI |
|---|---|---|---|---|---|---|
| DBLP | 0.751 | 0.748 | 0.554 | 0.659 | 0.659 | 0.659 |
| LiveJournal | 0.977 | 0.957 | 0.729 | 0.942 | 0.942 | 0.892 |
| Youtube | 0.935 | 0.874 | 0.839 | 0.692 | 0.694 | 0.667 |
| Friendster | 0.781 | 0.570 | 0.525 | 0.612 | 0.615 | 0.607 |
| Dataset | LINE | Node2Vec | M-NMF | GCN | GAT | DGI |
| DBLP | 0.712 | 0.691 | 0.727 | 0.686 | 0.700 | 0.663 |
| LiveJournal | 0.702 | 0.883 | 0.872 | 0.937 | 0.943 | 0.726 |
| Youtube | 0.783 | 0.738 | 0.643 | 0.845 | 0.855 | 0.624 |
| Friendster | 0.603 | 0.630 | 0.700 | 0.617 | 0.585 | 0.531 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, L.; Yu, S.; Febrinanto, F.G.; Alqahtani, F.; El-Tobely, T.E. Fairness-Aware Predictive Graph Learning in Social Networks. Mathematics 2022, 10, 2696. https://doi.org/10.3390/math10152696
Wang L, Yu S, Febrinanto FG, Alqahtani F, El-Tobely TE. Fairness-Aware Predictive Graph Learning in Social Networks. Mathematics. 2022; 10(15):2696. https://doi.org/10.3390/math10152696
Chicago/Turabian StyleWang, Lei, Shuo Yu, Falih Gozi Febrinanto, Fayez Alqahtani, and Tarek E. El-Tobely. 2022. "Fairness-Aware Predictive Graph Learning in Social Networks" Mathematics 10, no. 15: 2696. https://doi.org/10.3390/math10152696
APA StyleWang, L., Yu, S., Febrinanto, F. G., Alqahtani, F., & El-Tobely, T. E. (2022). Fairness-Aware Predictive Graph Learning in Social Networks. Mathematics, 10(15), 2696. https://doi.org/10.3390/math10152696