In this section, we first describe preliminary details and the overall architecture of our method. Then, we introduce each module in detail.
3.1. Preliminaries
In semi-supervised image aesthetic assessment prediction, a dataset can be expressed as . The dataset contains l labeled examples and unlabeled examples. The labeled examples for , denoted by , are labeled according to with , where is a discrete label set for c classes. The remaining unlabeled examples are denoted as . The goal in semi-supervised learning (SSL) is to use all examples X and labels to train a classifier that maps previously unseen samples to class labels.
In supervised learning, the network is trained by minimizing the following supervised loss term:
where
is the parameters of the network and
is the forward function of the network.
The supervised loss applies only to labeled data in
. The loss function in classification is cross-entropy (CE) loss under standard conditions, which is given by
where
y is the label and
p is the predict logits.
In semi-supervised learning, pseudo-labeling is the process of using the labeled data trained model to assign labels for unlabeled data. The additional pseudo-label loss term is defined as follows:
where
denote the collection of pseudo-labels for
, and the
can be any supervised loss function, such as cross-entropy.
3.3. Theme-Aware Attention Network
In recent years, the attention mechanism has been shown to be effective in capturing important information from raw features in either linguistic or visual representations [
22]. In contrast to the above approaches, we propose theme-aware attention to jointly exploit attention mechanisms to encode the theme features. Inspired by the success of self-attention, the proposed theme-aware attention module can capture the complex interactions between the theme features and different spatial locations in the input image.
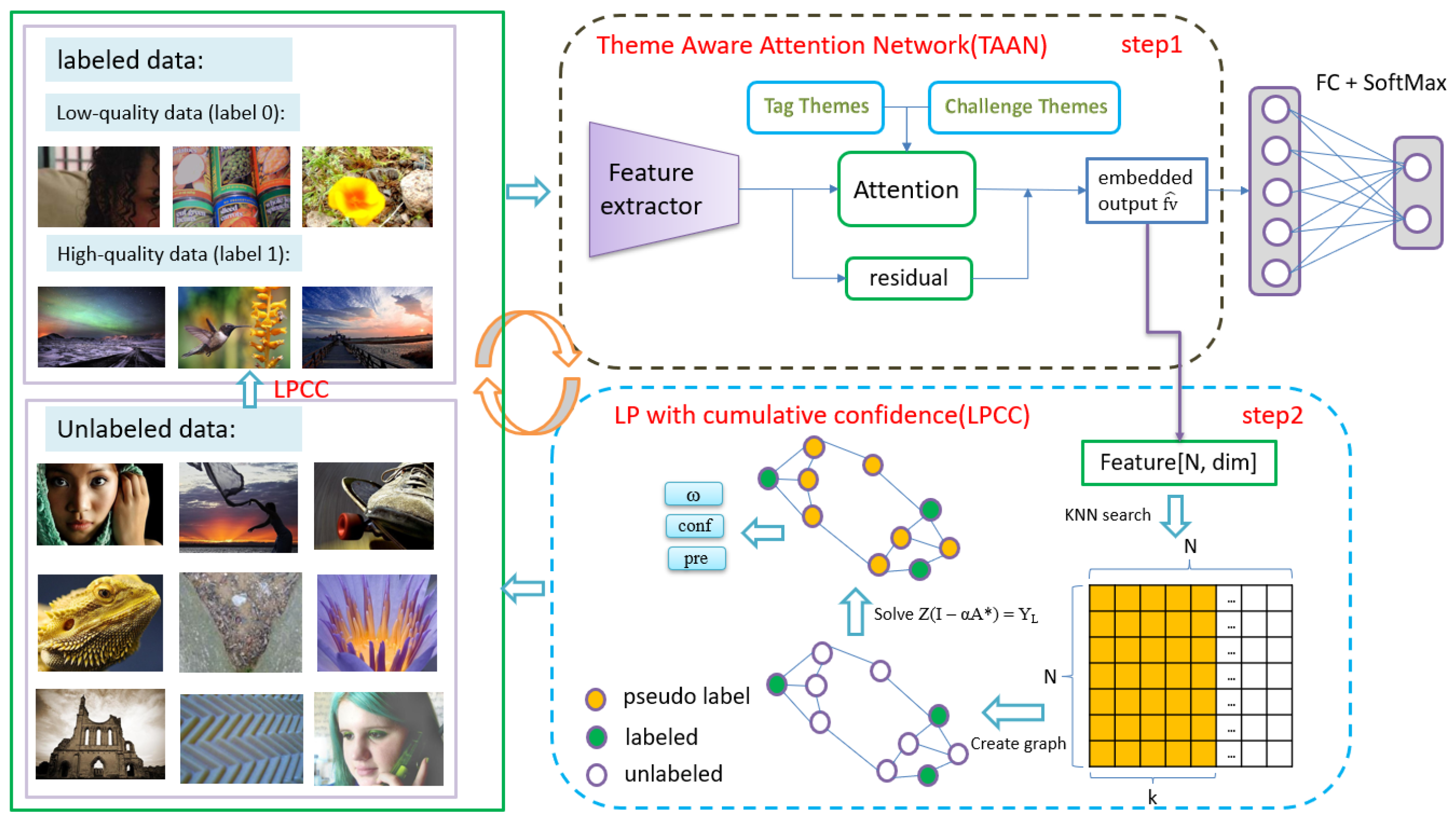
The pipeline of our proposed theme-aware attention network (TAAN) is shown in
Figure 2, which consists of the following three parts: an image feature extractor (backbone), a self-attention-based theme encoder and a residual connection module. Given the image, the image feature extractor firstly extracts high level features. Then these features are sent into the self-attention-based theme encoder. Finally, the visual features and the theme-based features are combined via a residual connection module.
| Algorithm 1 Label propagation with cumulative confidence. |
- 1:
procedureLPCC() - 2:
- 3:
fordo ▹step 1 - 4:
- 5:
- 6:
end for - 7:
fordo ▹step 2 - 8:
▹ extract features - 9:
▹ knn search for the graph - 10:
▹ create the adjacency matrix of the graph - 11:
▹ symmetric affinity - 12:
▹ normalize the graph - 13:
▹ solve the equation - 14:
▹ get pseudo-label - 15:
▹ get entropy weight - 16:
▹ cumulative confidence weight - 17:
▹ update cumulative info - 18:
- 19:
- 20:
end for - 21:
end procedure
|
The image feature extractor is a residual network with 18 layers, as described in [
23], pretrained on ImageNet [
24]. Images in the AVA dataset not only have semantic tag information (such as Macro, Animals and Portraiture), but also have challenge information (such as Fairy Tales, Flowers, Black and White, Street Photography). The tag information and challenge information both encode the theme information. Thus, we turn the tag information and challenge information into one-hot codes, and then process the one-hot codes with a fully connected layer to extract the theme features. Given the extracted visual feature
and theme features
, the self-attention-based theme encoder first produces a set of query, key and value pairs by linear transformations as
,
,
,
, where
are part of the model parameters to be learned. Then the tag-theme-based attention and the challenge-theme-based attention are computed as follows:
where
and
denote the tag-theme-based attention and the challenge-theme-based attention, respectively. Then the final theme-attentive features
are computed as follows:
We then combine the theme-attentive features with visual features via a residual connection. This allows the insertion of the proposed module into any backbone network without disrupting its initial behavior. The operations can be defined as follows:
where
is the theme-attentive features,
is the extracted visual feature, and
denotes theme-attentive features with residual features.
3.4. Label Propagation with Cumulative Confidence Algorithm
The label propagation algorithm is an iterative process for semi-supervised learning. More specifically, we first construct a nearest neighbor graph and perform label propagation on the whole training set. Then, we calculate an entropy weight reflecting the uncertainty of label propagation for each unlabeled example. Inspired by [
25], we believe that the results obtained from early propagation should also be considered as a constraint, so we propose a cumulative confidence weight to improve the traditional label propagation [
21]. Finally, we inject the obtained pseudo-labels into the network training process. This method is described in detail below; the process of the proposed approach is demonstrated in Algorithm 1.
K-nearest neighbor search for the graph. Given an image feature matrix with dimensions , we first calculate the similarity between every two points (the Euclidean distance or cosine similarity can be used).
Create the adjacency matrix of the graph. For the first
k nearest neighbors of each point, the similarity is the weight of the edge, and the weight of the edge after more than
k is set to 0. A sparse affinity matrix
is constructed as follows:
where
denotes the set of the first
k nearest neighbors in
X, and
is a parameter following work on a manifold-based search [
26]. So far, we obtain the adjacency matrix
A.
Normalize the graph. Since the full affinity matrix is not tractable, it may lead to the following problems: node
a is the k-nearest neighbor of node
b, but node
b is not the k-nearest neighbor of node
a, so we symmetrize it and turn it into a real undirected graph. The operation is defined in Equation (
8). Then we use regularization of the Laplace matrix for the adjacency matrix
A to build its symmetrically normalized counterpart
, which is defined in Equation (
9);
where
A is the adjacency matrix,
D is the degree matrix of
A, which is defined as
, where
is the all-ones n-vector, and
is the normalized adjacency matrix.
Diffusion for transductive learning [27]. The label matrix
is defined with elements:
where
L represents the index of labeled data. This means that the rows of the label matrix
Y corresponding to the labeled examples are one-hot encoded labels. The remaining elements are zero. The diffusion process is equivalent to the solution of linear equations:
where
is the adjustable parameter and
I is the identity matrix. Because matrix
is positive-definite, we can use the conjugate gradient (CG) method to solve the linear system. This solution is known to be faster than the iterative solution. Finally, we infer the pseudo-labels:
where
is the row-wise normalized counterpart of
Z and
are the predicted pseudo-labels.
Entropy weight. We need to evaluate the reliability of the predicted pseudo-labels. Firstly, we consider the credibility of a single round. The prediction matrix
Z we obtained has a probability prediction value for the category to which each sample point belongs. For points with small entropy, we think it is more credible, while for points with large entropy, we think it is less credible, so our weight is calculated by the following:
where
is the row-wise normalized counterpart of
Z and
c is the number of classes, so
is the maximum possible entropy.
Cumulative confidence weight. To improve the fault tolerance and reliability of label propagation, we propose a second weight, the cumulative confidence weight
. We maintain an array
to record the average value of the previous prediction.
reflects the reliability of the prediction (higher
means higher reliability).
denotes the similarity between
and the pseudo-labels in each epoch; it can be directly multiplied with the previous entropy weight. We have also designed three similarity functions and can manually select the appropriate one to deploy to the final architecture.
is calculated by the following equation:
where
denote the pseudo-labels of unlabeled data. So, the final loss with weight is calculated by the following formula:
where
denote the image features of unlabeled data,
denote the pseudo-labels of unlabeled data,
denote the entropy weights in index
i and
denote the cumulative confidence weights in
i.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}