1. Introduction
Multimedia data with different modalities, such as image, text, video, and audio, are mixed together and represent comprehensive knowledge needed in order to perceive the real world [
1,
2,
3,
4,
5,
6]. Exploring the cross-modal retrieval between image and natural language has recently attracted great interest among researchers, due to its great importance in various applications, such as bi-directional image and text retrieval, natural language object retrieval, image captioning, and visual question answering [
7]. The image–text cross-modal retrieval algorithms can return samples with the same semantic label, but with a different modality from the query sample.
Figure 1 illustrates the image–text cross-modal retrieval tasks, which include image retrieving text and text retrieving image. In
Figure 1, there are airplane images as well as texts describing the airplane number, flight status, airplane type, etc. A critical task for cross-modal retrieval is to measure the similarity between the image and text. To achieve this goal, many existing cross-modal retrieval algorithms propose to deep-learning network that can map different modal features into the common space. As shown in
Figure 1, we mapped airplane images and texts into the common space using the pre-trained deep network, and measured their similarity relationship by computing the distances among the different modal features.
In order to obtain an excellent cross-modal retrieval performance, different modal features need to be mapped into the common space by preserving their original semantic neighbor information. Firstly, the cross-modal retrieval algorithm aims to retrieve the nearest neighbor with a different modality from the query sample. So, the semantic relationship among the different modal samples needs to be preserved. Secondly, the cross-modal retrieval algorithms usually return more than one neighbor. Thus, the preservation of the intra-modal semantic relationship also needs to be taken into consideration.
Generally, most cross-modal retrieval algorithms only focus on preserving different modal similarity relationships in the common space, while ignoring the similarity relationship preserving problem in each single-modal space. As a result, many dissimilar samples could have similar feature representations. Unfortunately, the noise would further make these dissimilar samples have almost the same feature representations, and these dissimilar samples would be incorrectly returned as the nearest neighbors. Furthermore, different modal features have inconsistent distributions and representations. However, many existing methods learn the common representations without aligning their distributions [
8]. To solve the above-mentioned problems, we propose a novel cross-modal network based on an adversarial learning algorithm, as shown in
Figure 2.
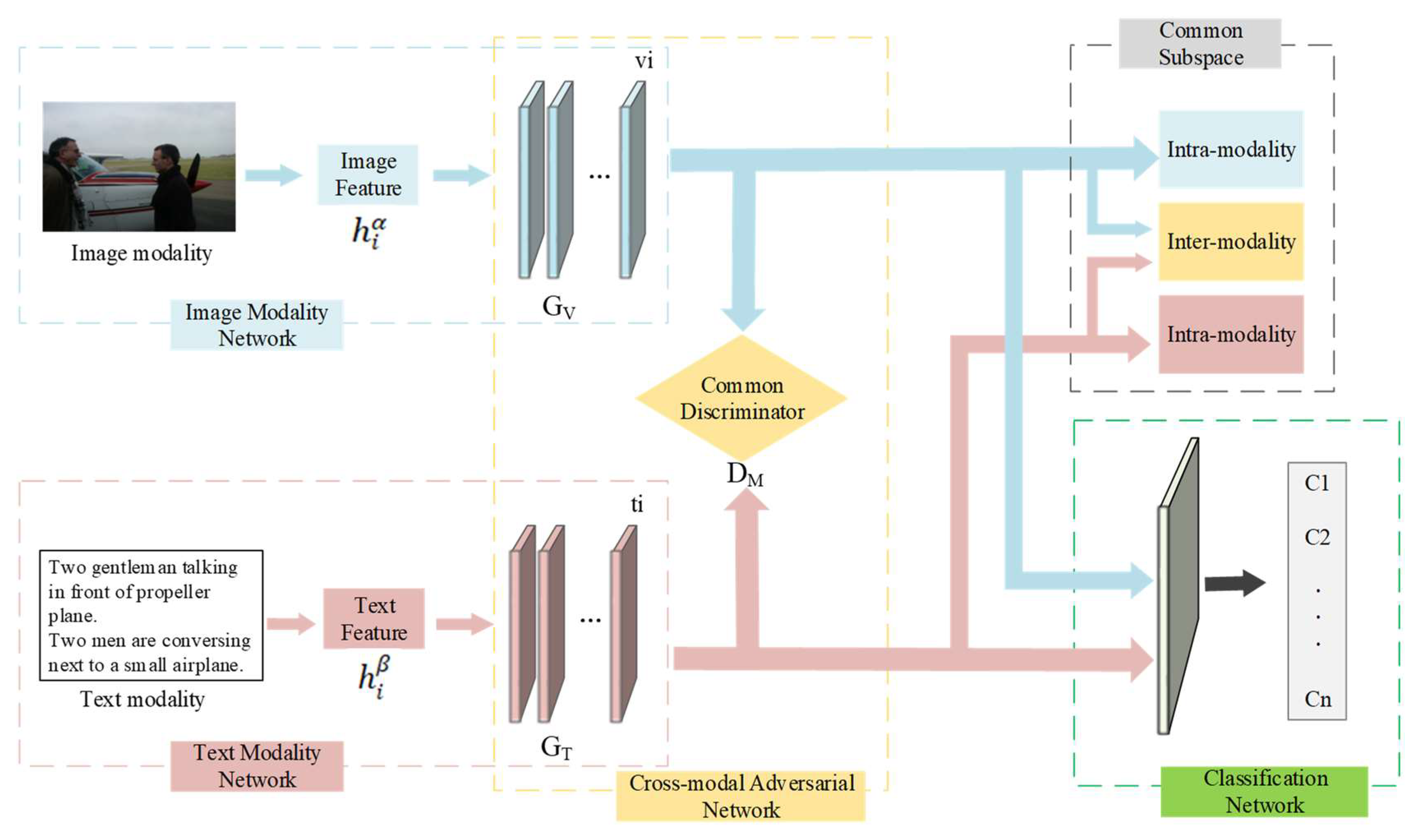
The proposed method consists of the following parts: the image modal network, the text modal network, the cross-modal adversarial network, the common space network, and the classification network. (1) For the image modality, we pre-trained VGG-19 [
9] on ImageNet and considered the 4096-dimensional vector generated by the fc7 layer as the image modal feature
hiα. Then, three full-connected layers were employed to learn the image representation
vi in the common space. (2) For the text modality, we used the Doc2Vec [
10] model to generate the 300-dimensional text modal feature
hiβ. Similarly, three full-connected layers were employed to learn the text representation
ti in the common space. (3) For the cross-modal adversarial network, we considered the fully connected layers in each modality as the image generator
Gv and the text generator
Gt. Furthermore, we established a common discriminator
DM to distinguish the input feature’s modality information. Adversarial learning utilized the mini-max mechanism to train the generator networks
Gv and
Gt and the discriminator network
DM. During the iterative training process, the generators aimed to minimize the probability of being correctly recognized by the discriminator. In contrast, the discriminator tried to maximize the probability of correctly recognizing the sample’s modal information. When the algorithm converged, we could align the feature distributions between the different modalities. (4) For the common space network, we established the triplet similarity preserving function to preserve the inter- and intra-modal similarity relationship. (5) For the classification network, we utilized a linear projection function to classify the sample features, and required the classification results to be consistent with the original semantic labels. Thus, the generated features had the same semantic information as the sample’s label.
The main contributions were as follows:
- (1)
We employed the generative adversarial network to learn different modal features in the common space, which could reduce the distribution difference between the different modal features using the mini-max mechanism;
- (2)
In the common, image, and text spaces, we separately designed the triplet similarity preserving function to preserve both the inter- and intra-modal similarity relationship. This could also boost the retrieval results for robustness to noise;
- (3)
To avoid the loss of semantic information during learning image and text features, we established a linear function to predict the generated feature labels, and required that the prediction labels were identical to the original semantic labels.
2. Related Work
The cross-modal retrieval algorithm can retrieve similar samples with different modalities, which helps to comprehensively perceive and recognize the query sample. However, different modal features have different distributions and diverse representations, which lead to the heterogeneity gap. Thus, to directly compute the different modal similarity relationship, different modalities need to be mapped into a common space [
7,
11,
12,
13]. Traditionally, linear projection functions with an optimized target statistical value are utilized to map different modal features into a common space [
14]. The canonical correlation analysis (CCA) [
11] finds a linear combination to maximize the pairwise correlations between the two data sets, and associates different modal features by projecting them into a common space. The cross-modal factor analysis (CFA) [
12] learns different modalities’ common space by minimizing the data pair’s Frobenius norm. Joint representation learning (JRL) [
13] learns the sparse projection matrices, and adds the unlabeled data to improve the diversity of the training data. The deep-learning-based cross-modal retrieval methods employ the scalable nonlinear transformation to learn the sample’s content representation [
14]. Ngiam et al. [
15] proposed a bimodal auto-encoder to learn different modal correlations, and applied the restricted Boltzmann machine (RBM) to generate the common space. The multimodal deep neural network (MDNN) [
16] utilizes the deep convolutional neural network (CNN) to learn the image feature and employs the neural language model (NLM) to learn the text feature. Furthermore, MDNN establishes the correlation between different modal features by projecting them into a common space.
Generally, the cross-modal retrieval algorithms can be divided into three categories, namely unsupervised approaches [
11,
17,
18], pairwise approaches [
19,
20], and supervised approaches [
14,
21]. The unsupervised methods directly exploit different modal feature information to learn their common representations [
7]. For example, CCA [
11], Deep-CCA [
17], and Deep Canonical Correlated Auto-encoder (DCCAE) [
18] utilize the correlations between heterogeneous data to learn the common representations. The pairwise-based methods, such as the multiview metric learning with global consistency and local smoothness (MVML-GL) method [
22] and the modality-specific deep structure (MSDS) method [
20], generate the similarity metrics according to the similarity relationship between different modal sample pairs [
7]. The supervised methods try to preserve the original semantic label information in the common space. Sharma et al. [
23] proposed the generalized multi-view analysis (GMA) method based on CCA, which supervises learning the common representations using the semantic category labels. In [
14] and [
21], generative adversarial networks [
24] are used to generate different modal features and reduce the distribution difference.
3. The Proposed Method
3.1. Notations
The notations used in this paper are given as follows. O = {ai,bi}ni = 1 denotes n pairs of image and text. ai is the image and bi is the text. yi = [yi1,yi2,…,yic]∈ℝc is the semantic label vector, where c is the number of the categories. If the i-th instance belongs to the j-th category, yij = 1, otherwise yij = 0. Y = [y1,y2,…,yn]∈ℝc×n is the label matrix. f(x) and g(x) represent the image and text feature learning network. vi = f(ai)∈ℝdv is the feature of image ai and V = [v1,v2,…,vn]∈ℝdv×n is the image feature matrix. ti = g(bi)∈ℝdt is text feature and T = [t1,t2,…,tn]∈ℝdt×n is the text feature matrix. dv and dt represent the number of dimensions.
3.2. The Triplet Similarity Relationship Preserving Function
The cross-modal retrieval algorithm measures the similarity relationship between different modal samples in the common space, and returns the samples with minimal distance between the nearest neighbors. To obtain an excellent cross-modal retrieval performance, the distance between the same category samples should be smaller than that between different categories samples. In
Figure 3a, the anchor and positive samples belong to the same category. In contrast, the anchor and negative samples belong to different categories. Thus, in
Figure 3b, the anchor’s feature should be similar to the positive sample and different from the negative sample. This ensures the positive samples can first be returned as the nearest neighbors of the anchor.
To achieve the above goal, we proposed to simultaneously preserve the inter- and intra-modal triplet similarity relationship.
In this paper, we designed the triplet loss function between the image–text, image−image, and text−text, respectively.
The triplet similarity preserving function between image–text is defined as in Equation (1):
In Equation (1), Lo represents the image–text loss. d(∙) is the Euclidean distance. Va, Vp, and Vn represent the anchor, positive, and negative images, respectively. Ta, Tp, and Tn represent the anchor, positive, and negative texts, respectively. α is the error margin.
Generally, most of the existing methods only focus on preserving the similarity relationship between different modal samples, while not preserving the similarity relationship among the same modal samples [
25]. As shown in
Figure 4a, samples that belong to different categories may have a small distance, which may lead to incorrect retrieval results.
To solve the above problem, we designed the intra-modal triplet similarity preserving function as in Equation (2). It ensures that the distances among similar samples are smaller than those among dissimilar samples in the image- or text- modality, respectively.
In Equation (2), Lv is the image-modal triplet similarity preserving function, and Lt is the text-modal triplet similarity preserving function.
In this paper, we aimed to preserve both the inter- and intra-modal triplet similarity relationship and to define the triplet similarity preserving objective function as in Equation (3).
By simultaneously minimizing the value of
Lo,
Lv, and
Lt, we ensured the distance between the same category samples is small and between the different categories samples it is large, as shown in
Figure 4b. As a result, the proposed method is robust to noise.
3.3. The Minimal Semantic Information Loss
The proposed method utilizes the floating-point feature representing the sample content in the triplet similarity preserving function. Therefore, to guarantee the cross-modal search performance, the sample features should have the same semantic information as its labels.
In this paper, we learned the samples’ features using a deep neural network. Due to information loss, the deep learning features may not accurately preserve the original semantic information.
To solve the above problem, we employed a linear projection function to classify the deep feature, and required that the predicted label be identical to the sample label, as shown in
Figure 5. We formulate the above procedure as in Equation (4), which minimizes the difference between the features’ classification results and the samples’ semantic labels.
In Equation (4), ‖∙‖F is the Frobenius norm. P is the matrix of the linear projection function.
3.4. The Cross-Modal Adversarial Learning
To directly compute the similarity relationship between the different modal samples, different modal features should have the same distribution in the common space.
As generative adversarial networks (GANs) have a strong ability for modeling data distribution and learning discriminative representation [
26], we used the GANs to align the distribution between the different modal features.
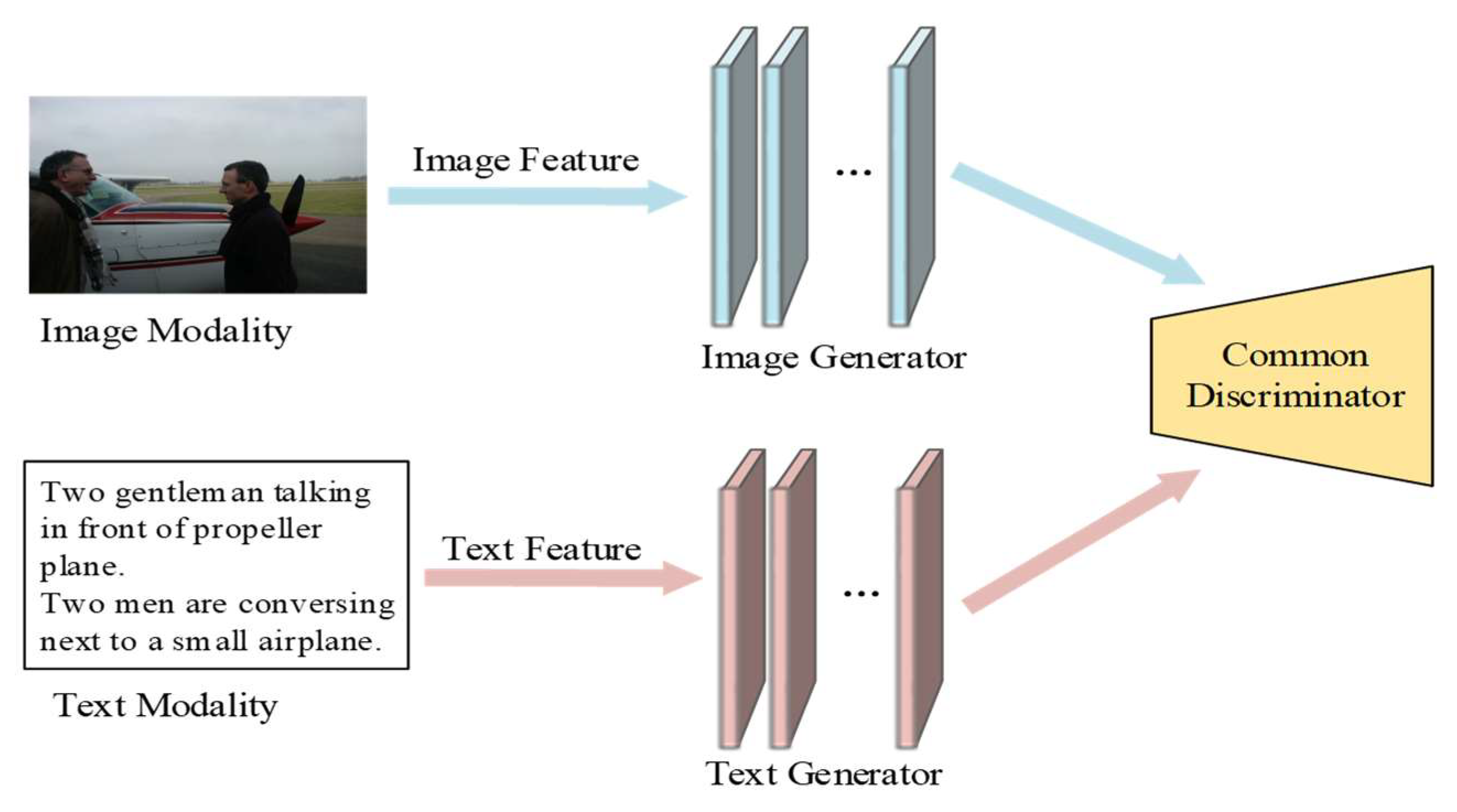
Figure 6 shows the adversarial learning procedure. We regarded the fully connected layers of the image modal network as the image generator
GV and the fully connected layers of the text modal network as the text generator
GT. Initially, the discriminator
DM regards the image features generated by
GV as the real samples, and considered the text features generated by
GT as the fake samples. In Equation (5), adversarial loss is defined as the difference between different modal feature distributions. Both the generator and discriminator utilize Equation (5) as the objective function. During the training procedure, we employed the min−max mechanism. The discriminator tries to maximize the objective value and the generators aims to minimize the objective value. When the algorithm converges,
DM can only randomly distinguish the sample’s modal information. Finally, the image and text features have the same distribution.
In this paper, we define the final objective function
L as in Equation (6), which can achieve the following three tasks: (1) preserve the inter- and intra-modal relative similarity relationship, (2) minimize the semantic loss during learning the deep features, and (3) align the different modal features’ distribution.
In Equation (6),
λ and
η are the weight parameters. We optimized the objective function
L using the stochastic gradient descent algorithm [
27].
4. The Comparative Experiments
In this paper, we conducted comparative experiments on widely used datasets, namely the Pascal Sentence dataset [
28] and the Wikipedia dataset [
29]. These two datasets are publicly available. The retrieval tasks included image retrieving text and text retrieving image. To verify the effectiveness of our proposed methods, we employed five state-of-the-art methods, namely, CCA [
11], JRL [
13], CMDN [
30], Deep-SM [
19], and DSCMR [
7], as the comparative methods. We implemented the model development and data analysis using the PyTorch deep learning framework.
4.1. The Datasets and Settings
The Pascal Sentence dataset [
28] includes 1000 image–text pairs and a total of 20 categories. Each image is described by five sentences in a document. We divided the Pascal Sentence dataset into three parts, namely, the training, test, and validation sets. We randomly selected 800 image–text pairs as the training set and 100 image–text pairs as the test set. The proposed method generated the 4096-dimensional vector as the image feature, and the text feature had 300-dimensions.
The Wikipedia dataset [
29] includes 2866 image–text pairs that can be divided into 10 categories. Each pair consists of an image and several text paragraphs. We randomly selected 2173 pairs as the training set, and considered the remaining 693 pairs as the test set. The dimension of the image feature was 4096, and the text feature had 300-dimensions.
The proposed algorithm employed the deep adversarial network to learn different modal features in the common space. Both GV and GT had two fully connected layers, and utilized tanh(∙) as the activate function. At the end, GV and GT had a fully connected layer that shared the weight values. The discriminator DM consisted of three fully connected layers and employed the sigmoid function at the activation layer. For the triplet similarity preserving function in the common space, the value of α was set as 0.3. For the objective function L, λ = 0.001, η = 0.1.
4.2. Evaluation Metric
In this paper, we used mAP (mean average precision) and PR (precision−recall) curves to measure the cross-modal retrieval performance.
MAP [
31] is the mean value of the average precision of all of the query sample retrieval results, and its definition is shown in Equation (7).
Q represents the number of query samples. Ki represents the number of the i-th query sample’s ground truth. j is the numerical order of the j-th ground truth. rank (j) returns the ranking order of the j-th true positive data in the retrieval result.
4.3. The Parameters Values
In this paper, we set the parameters
λ and
η to balance the effect between the triplet similarity preserving the loss and adversarial loss during the training process. We compared the cross-modal retrieval performances with different values of
λ and
η on both the Pascal Sentence and Wikipedia datasets. The experimental results are shown in
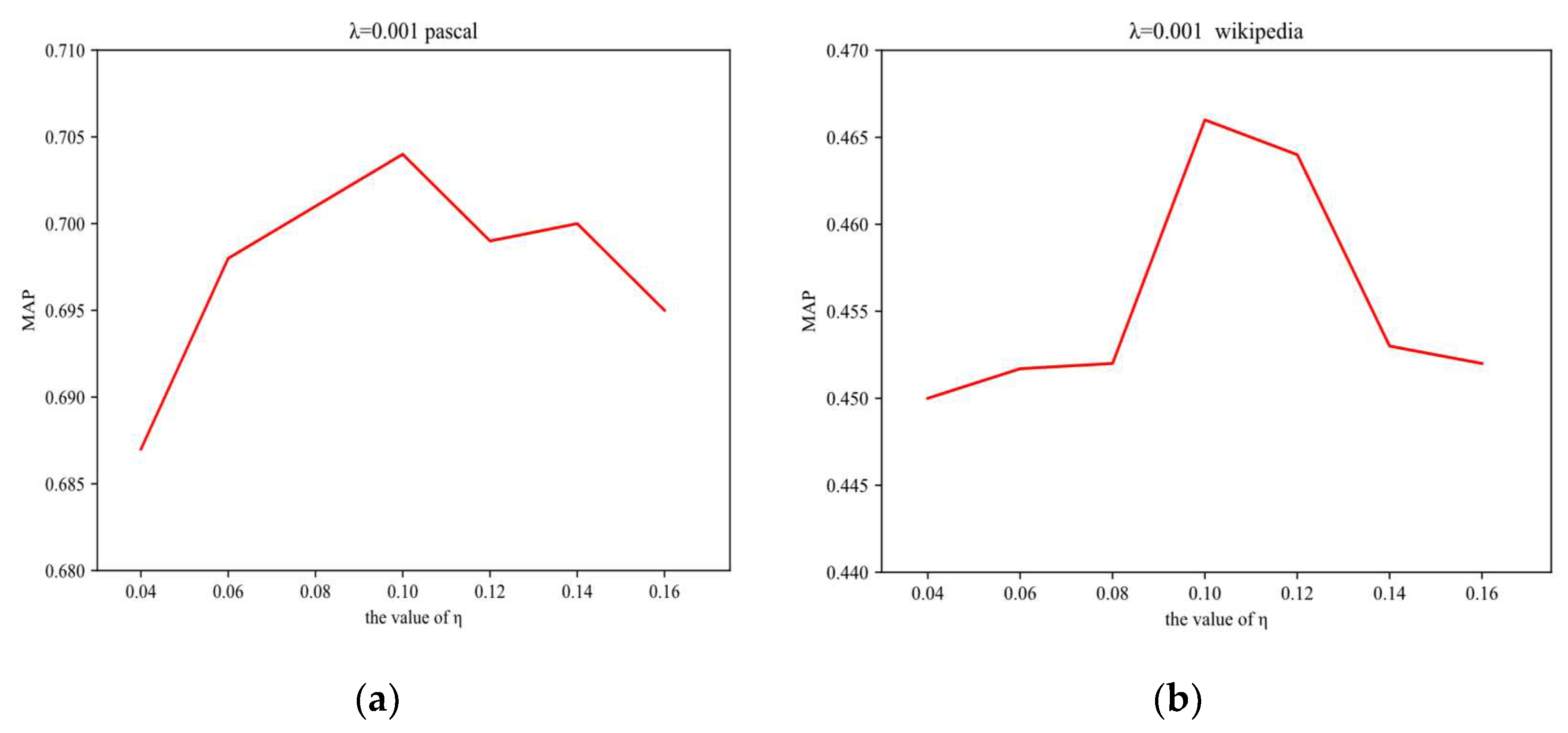
Figure 7 and
Figure 8. In
Figure 7, the value of
λ is fixed and the value of
η gradually increases from 0.04 to 0.16. The best cross-modal retrieval performance occurs when
η = 0.1. In
Figure 8,
η is fixed and the value of
λ changes from 0.0004 to 0.0016. When
λ = 0.001, we achieved the best cross-modal retrieval performance. As described above, we set the value of
η as 0.1 and
λ as 0.001 in this paper.
4.4. Experimental Results and Analysis
The comparison algorithms include CCA [
11], JRL [
13], CMDN [
30], Deep-SM [
19] and DSCMR [
7]. CCA [
11] learns the common space which maximizes the pairwise interrelationships between two sets of heterogeneous data. JRL [
13] learns different modal features by multi-metric learning. CCA and JRL belong to the traditional methods. CMDN [
30] employs both the intra- and inter-modal information, and utilizes the hierarchical learning to correlate the connections between different modalities. Deep-SM [
19] uses deep semantic matching to retrieve different modalities with multi-labels. The supervised DSCMR [
7] learns the features by minimizing the discriminative loss between the label and common spaces. CMDN, Deep-SM and DSCMR are deep learning based methods.
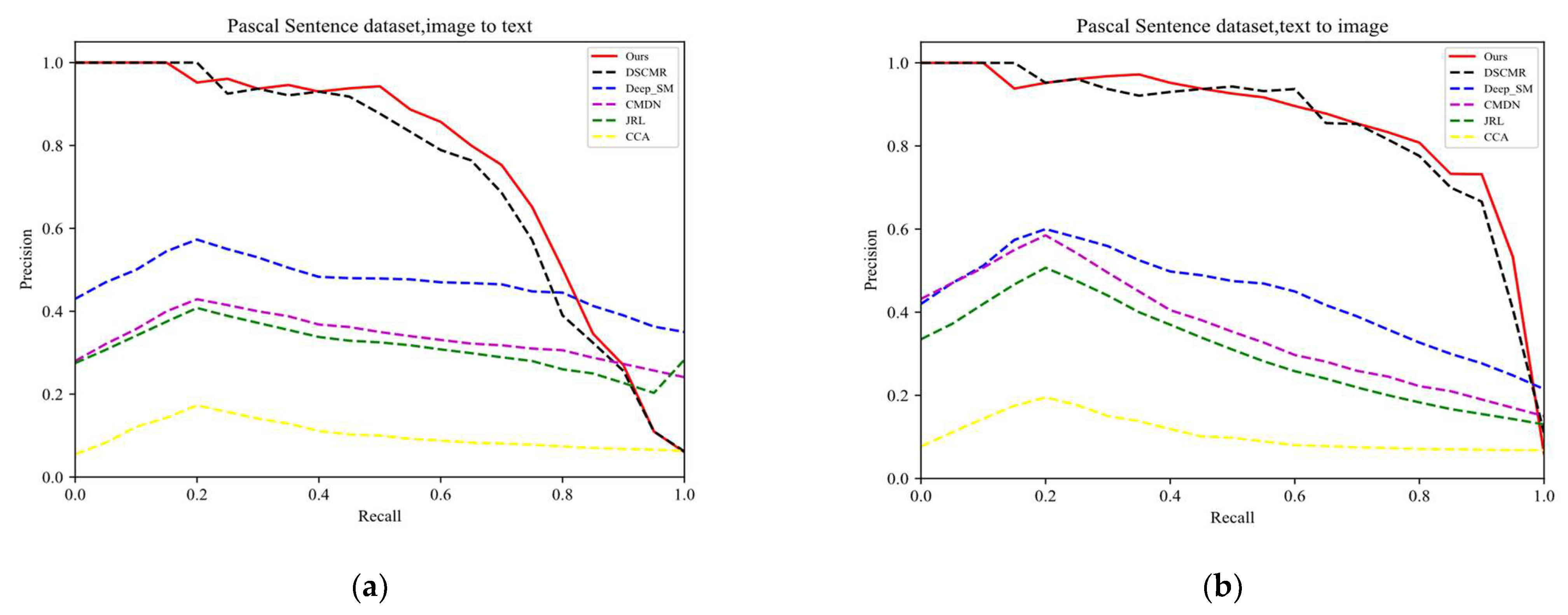
Table 1 and
Table 2 show the mAP values on the Wikipedia and Pascal Sentence datasets, respectively. Correspondingly,
Figure 9 and
Figure 10 show the PR curves. The experimental results verify that our method outperforms the best-of-the-art methods.
CCA only uses the mutual relationship to study the correlation between two groups, so it cannot understand the class labels’ high-level semantic information. As a result, CCA has a weak ability to discriminate the samples in the common space. JRL learns different modal sparse projection matrices and utilizes unlabeled data to improve the diversity of the training data. CCA and JRL use traditional methods to correlate different modal connections, which cannot make full use of samples’ semantic information. To solve the above-mentioned problem, the deep learning mechanism is employed to further improve cross-modal retrieval performance. CMDN hierarchically combines the intra- and inter-modal features, and uses a two-level network strategy to learn the cross-modal correlations. However, the different modal distributions are diverse, and CMDN does not align the generated features’ distribution. Deep-SM extracts visual features by a pre-trained network, and adopts a deep semantic matching method to achieve the cross-modal retrieval of the samples with multiple labels. However, Deep-SM does not take the same modal correlation into account. The supervised DSCMR learns the discriminative features and minimizes the discriminative loss between the label and common spaces. Moreover, DSCMR adopts a weight-sharing strategy to reduce the differences between different the modal high-level semantic information. However, DSCMR does not consider the intra-modal correlation during the training procedure. In this paper, the proposed method uses the adversarial network to jointly model the heterogeneous data and generate their feature representations in the common space, which can reduce the differences between the different modalities’ feature distributions. Furthermore, it preserves both the inter- and intra-modal triplet similarity relationship. This measure can avoid retrieving negative samples, which may have similar intra-modal feature representations, and boost robustness to noise. In each modal space, a linear projection function is built to classify the generated feature, and the feature’s prediction label is required to be consistent with the sample’s label. As a result, the generated feature can correctly represent the sample’s semantic information. Thanks to the above measures, the cross-modal retrieval task can be achieved directly based on different modal features’ similarity relationship. Finally, the experimental results show that the proposed method is better than the state-of-the-art algorithms.
4.5. The Ablation Study on Constraints
In this paper, to guarantee the cross-modal retrieval performance, we designed three loss functions: (1) the cross-modal learning loss (
LRet), which simultaneously preserved the inter- and intra-modal similarity relationship; (2) the discrimination loss (
LDis), which aimed to preserve the semantic information and improve the intra-modal discriminative ability during generating features; and (3) the cross-modal adversarial loss (
LAdv), which aligned different modalities’ feature distributions in the common space. To verify the effect of the above loss functions in the cross-modal retrieval task, we conducted the ablation study on the Wikipedia and Pascal Sentence datasets, and the comparison algorithms are shown in
Table 3. The final experimental results are shown in
Table 4 and
Table 5, and in
Figure 11 and
Figure 12.
The experimental results show that the deep adversarial triplet similarity preserving cross-modal retrieval algorithm achieved the best performance on both datasets. This means all three loss functions played important roles in achieving the cross-modal retrieval task. When we generated the feature using the end to end network, LDis could preserve the semantic information. Moreover, LDis ensured the model could discriminate the samples belonging to different categories in the common space. Thus, the performance of OnlyLDis was better than NoLDis. OnlyLAdv had a poor performance, because it only aligned different modal feature distributions, while ignoring preserving the similarity relationship among the intra-modal samples. In the common space, the cross-modal learning module minimized the distance between the same category samples and maximized the distance between the different categories’ samples. Assisted by the cross-modal learning module, we could return the samples similar to the query sample as the retrieval results.
4.6. The Ablation Study on Triplet Similarity Preserving Constraint
In this paper, to preserve the similarity relationship among samples, we designed the triplet similarity preserving objective function LRet, which included three parts, the inter-modal triplet similarity preserving constraint LO, the image intra-modal triplet similarity preserving constraint Lv, and the text intra-modal triplet similarity preserving constraint Lt. During the training process, we learned different modal features by simultaneously minimizing the values of LO, Lv, and Lt in the common space.
To further illustrate the importance of
LO,
Lv, and
Lt, we separately conducted the ablation experiments on the Pascal Sentence and Wikipedia datasets.
Table 6 shows the final experimental results, which included the image to text and the text to image.
The experimental results show that the cross-modal retrieval performance with minimal LRet was better than that with minimal LO. By minimizing LO, we could only guarantee the triplet similarity relationship among the different modal samples. Unfortunately, the intra-modal samples that belonged to the different categories may have similar features without preserving the intra-modal triplet similarity relationship. As a result, the cross-modal retrieval task may return the negative samples as the nearest neighbors. In contrast, by minimizing the value of LRet, we could simultaneously preserve the inter- and intra-modal triplet similarity relationship. This could guarantee that the distances among the inter- and intra-modal similar samples were smaller than those among the dissimilar samples. Thus, the inter- and intra-modal nearest neighbors were assigned similar features. Finally, we could improve the cross-modal retrieval performance assisted by LRet.
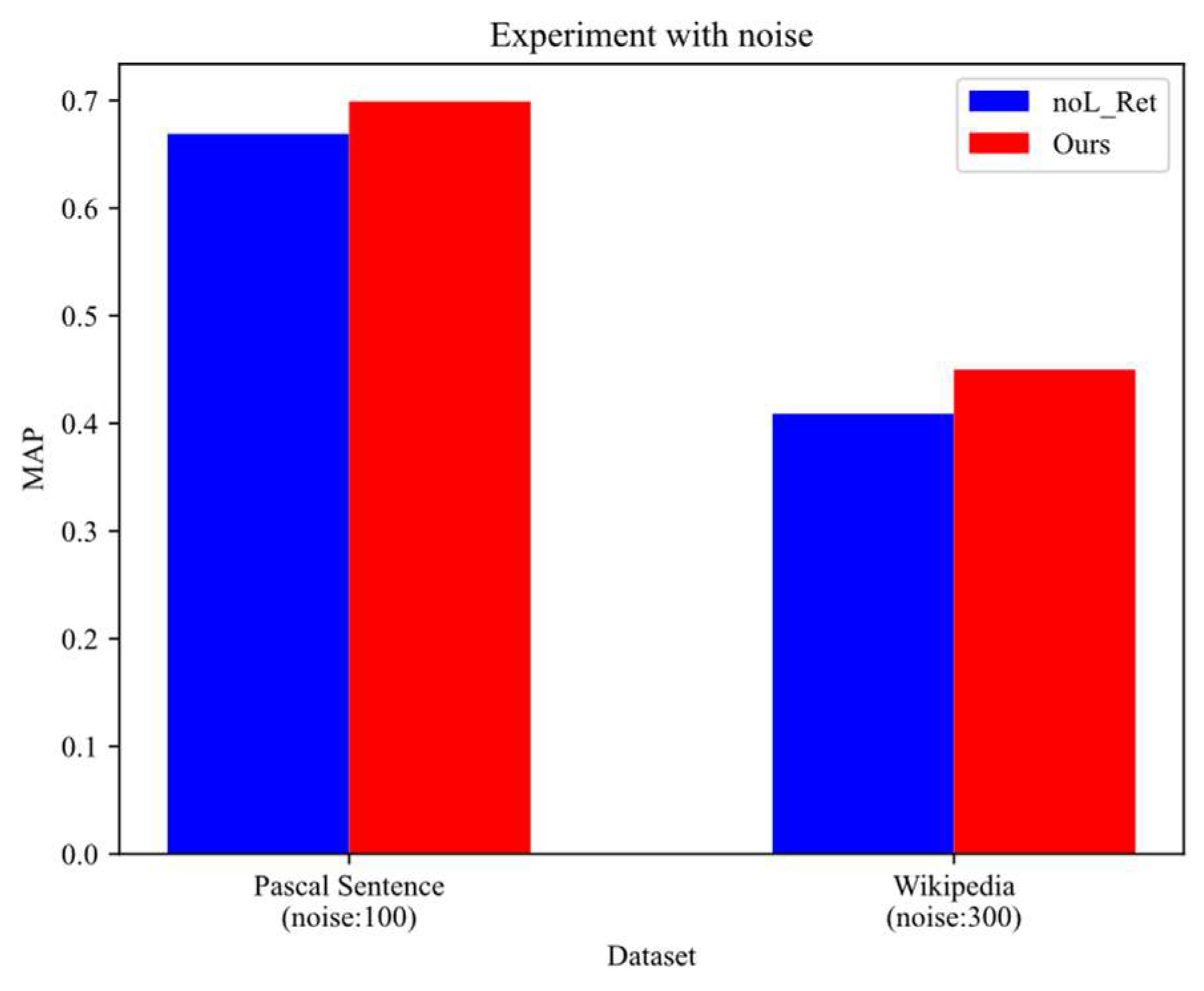
4.7. The Noise Robustness Experiments
In this section, we aimed to verify that the proposed triplet similarity relationship preserving constraint could boost the algorithm’s robustness to noise. We randomly generate uniform noise, and separately put them into the Pascal Sentence and Wikipedia datasets. The cross-modal retrieval experiments are shown in
Table 7 and
Figure 13. We removed the triplet similarity relationship constraint (
LRet) from the comparative algorithm. The final experimental results showed that the proposed triplet similarity preserving constraint
LRet could effectively boost the algorithm’s robustness to noise.


 ,
, 













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}