
A Neural Network Model Secret-Sharing Scheme with Multiple Weights for Progressive Recovery


Abstract
:1. Introduction
2. Related Works
2.1. Shamir’s Secret-Sharing Scheme
2.2. Weighted Polynomial-Based Secret-Image Sharing Scheme
2.3. Probabilistic Selection Strategy
3. The Proposed Scheme
3.1. Motivation
3.2. NNSS with Multiple Weights for Progressive Recovery
3.2.1. Sharing Phase
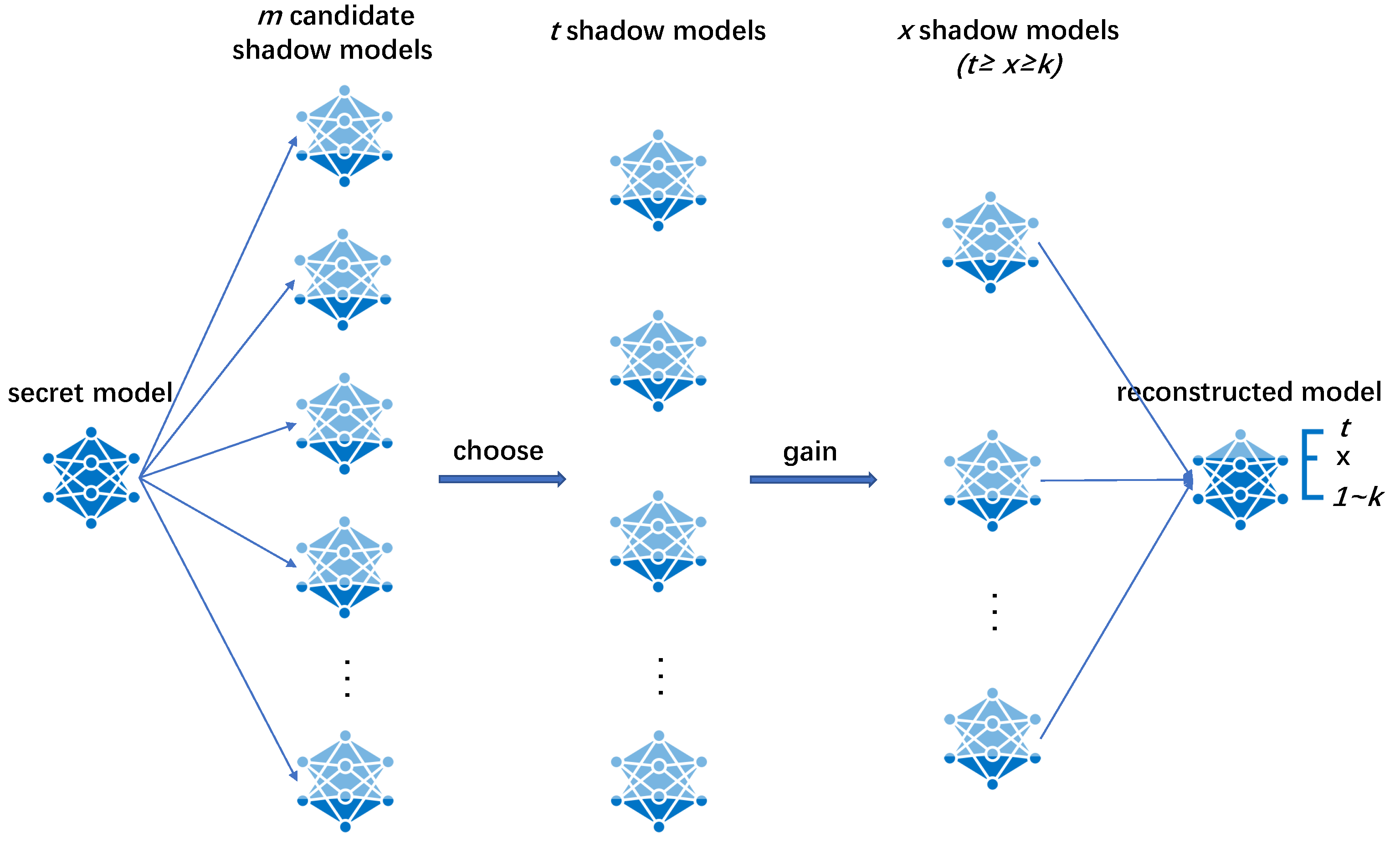
- Calculate . m is the number of candidate shadow models. m is calculated based on the following. When obtaining t shadow models, the secret parameters can be recovered by t shadow parameters at any position of the model. In other words, even if t shadow parameters contain all invalid parameters, there are at least k valid parameters, i.e., .Next, m candidate shadow models are generated, from which t models are selected and assigned to t participants. Each participant has exactly one shadow model.
- According to the scenario, weights are assigned to the m candidate shadow models. The size of the weights is set manually. Generally, the shadow models held by the participants with the least important weight and the excess shadow models are assigned as 1. The weights of other shadow models are assigned a number greater than 1 according to their importance difference. The importance of the shadow model can be measured by the participant’s contribution to the model training process, such as the amount of data provided, the number of CPU operations provided, etc.
- Determine the SS phase’s finite domain . Assign m candidate secret models with mutually different m integers in the finite domain to generate shadow parameters.
- Use PSS to extract important parameters of the secret model.
- Convert important parameters to integers in a finite field. It is well-known that traditional SS is for non-negative integers. However, the parameters in the secret model are floating-point numbers, so consider transforming floating-point numbers into a finite field for SSS. is the set of parameters for the deep-learning model. Floating-point numbers are converted to non-negative integer space by Equation (5):The larger U is the more decimal places the parameters retain, and the higher the accuracy of the parameters of the reconstructed model. However, the converted integer must be in , so U must satisfy . Thus, this paper calculates the specific value of U by Equation (6).
- Iterate through the generated integers. Perform the -threshold SSS for each integer using polynomials to generate n integers in a finite field. These n integers are called valid integers In addition, generate invalid integers . can be calculated by Equations (7).where H is a positive integer and P is the number of finite field features in Equation (1).
- Assign integers based on the candidate-shadow-model weights. The higher the weight of the candidate shadow model, the easier it is to assign a valid integer. The details of this operation are shown in Algorithm 1.
Algorithm 1 Assign integers based on the candidate shadow model weights. - Require:
- The number of candidate shadow models m, the number of effective shadows n, list of weights of candidate shadow models , set of valid integers, set of invalid integers
- Ensure:
- allocation of integers
- 1:
- while There are valid integers that have not been assigned do
- 2:
- 3:
- Generate empty list
- 4:
- while to m do
- 5:
- 6:
- Append t to
- 7:
- end while
- 8:
- Generate a random number in (0,1)
- 9:
- 10:
- while to m do
- 11:
- if then
- 12:
- 13:
- Stop the loop
- 14:
- end if
- 15:
- end while
- 16:
- Take any valid integer and assign it to the candidate shadow model with index.
- 17:
- 18:
- end while
- 19:
- Randomly assign invalid integers to candidate shadow models that have not yet been assigned.
This step enables the recovery phase to acquire with a certain probability a sufficient number of shadow parameters used to recover the secret parameters. As the number of shadow models acquired increases, the probability becomes larger. When all t shadow models are gained, the reconstructed model has the performance of the secret model. The performance of the extracted models is related to the participants’ weights in the recovery phase. Now, each important parameter selected corresponds to m integers that have been assigned to the candidate shadow model. - Embed integers into candidate shadow models. Each candidate shadow model takes a copy of the secret model as its initial state. Fill the generated shadow parameter to the corresponding positions of their corresponding candidate shadow model by solving the system of equations shown in Equation (8) for each integer. Finally, m copies of the candidate shadow models are generated. Select t of these candidate shadow models to assign to t participants based on their weights, with each participant having exactly one copy of the shadow model.where I is the integer currently being processed, and p is the secret parameter at the corresponding location. H corresponds to the eponymous parameter in the system of Equation (7). represents the deviation that determines both the performance of the participant’s shadow model and the reconstructed model’s starting performance. R is the precision that controls the precision of the effect of on performance.
3.2.2. The Recovery Phase
- Select any shadow model as the initial state of the reconstructed model.
- Iterate through the positions of all model parameters. It is skipped if all the shadow models have the same parameters at the current position. Otherwise, it means that the parameters of the shadow models at the current position hide the shadow parameters. At this time, the integers I are extracted from parameter p of the shadow model at the current position by Equation (9).where R and H mean the same as they do in Equation (8).When the number of valid integers in the extracted integers is k or more, the Lagrangian interpolation formula, as shown in Equation (2), is used to recover the integers x corresponding to the secret parameter at the current position. Then, x is converted to the secret parameter by Equation (10) and filled to the corresponding positions in the reconstructed model.where U and mean the same as they do in Equation (5).The corresponding parameter of any of the shadow models is selected to fill the corresponding position of the reconstructed model when the number of valid integers among the extracted integers is less than k.
3.3. Validity Analyses
3.3.1. Progressivity Analyses
- The expected performance of the reconstructed model at a certain x needs to be considered to measure progressivity. Therefore, x shadow models are chosen randomly.
- is for a location where the secret parameter is hidden, not for the whole recovery phase. Considering the huge number of parameters, there must be the case where in the whole recovery phase.
- Calculate the probability of the combination of all candidate shadow models with getting valid integers in one process of assigning n valid integers to m candidate shadow models, i.e.,There are different valid integer-assignment orders for each . The probability of each assignment order is not the same. is equal to the sum of the probabilities of all assignment orders, and its solution algorithm is shown in Algorithm 2.
Algorithm 2 Solution for the probability of the combination of all candidate shadow models with obtaining valid integers. - Require:
- , the list of participants’ weights W
- Ensure:
- 1:
- Compute all possible full permutations of and their combination is called .
- 2:
- Initialize .
- 3:
- while There are still unretrieved permutations in . do
- 4:
- Take any of the permutations a in
- 5:
- Reset W
- 6:
- 7:
- while There are still unretrieved model number indexs in a do
- 8:
- Find the smallest index in a
- 9:
- Calculate the probability list according to W
- 10:
- 11:
- 12:
- end while
- 13:
- 14:
- end while
- t shadow models are selected from m candidate shadow models according to their weights, and their combination is . Since the number of valid integers in is related to both and , but is a constant for the entire the recovery phase, it is determined after all important model parameters have been shared. Let the number of valid integers contained in be during a certain parameter sharing phase. Consider the number j of valid integers extracted at any one location when x shadow models are randomly selected from . The range of values of j is [,]. Where means that all invalid integers in are included in the x person selected at the current position. At determination, the probability is as shown in Equation (11) for each value j taken.where denotes the number of cases in which any j integers are selected from all valid integers of . Furthermore, denotes the number of cases in which any integers are selected from all invalid integers of . In addition, denotes the number of cases in which any x integers are selected from .
- when x is a variable is shown in Equation (12).where S represents the combination of all possible cases of .
3.3.2. Weight Validity Analyses
- Calculate according to Algorithm 2.
- In the case where is determined, t shadow models are selected from m candidate shadow models according to their weights, and their combination is . The is considered when selecting specific x shadow models from . In the case that and are determined, the number of valid integers contained in is also determined. For the whole of the recovery phase, is a constant, so let the number of valid integers contained in be . Thus, when the chosen x shadow models are determined, is calculated as shown in Equations (13) and (14).
4. Experiments and Comparisons
4.1. Experiments and Analyses
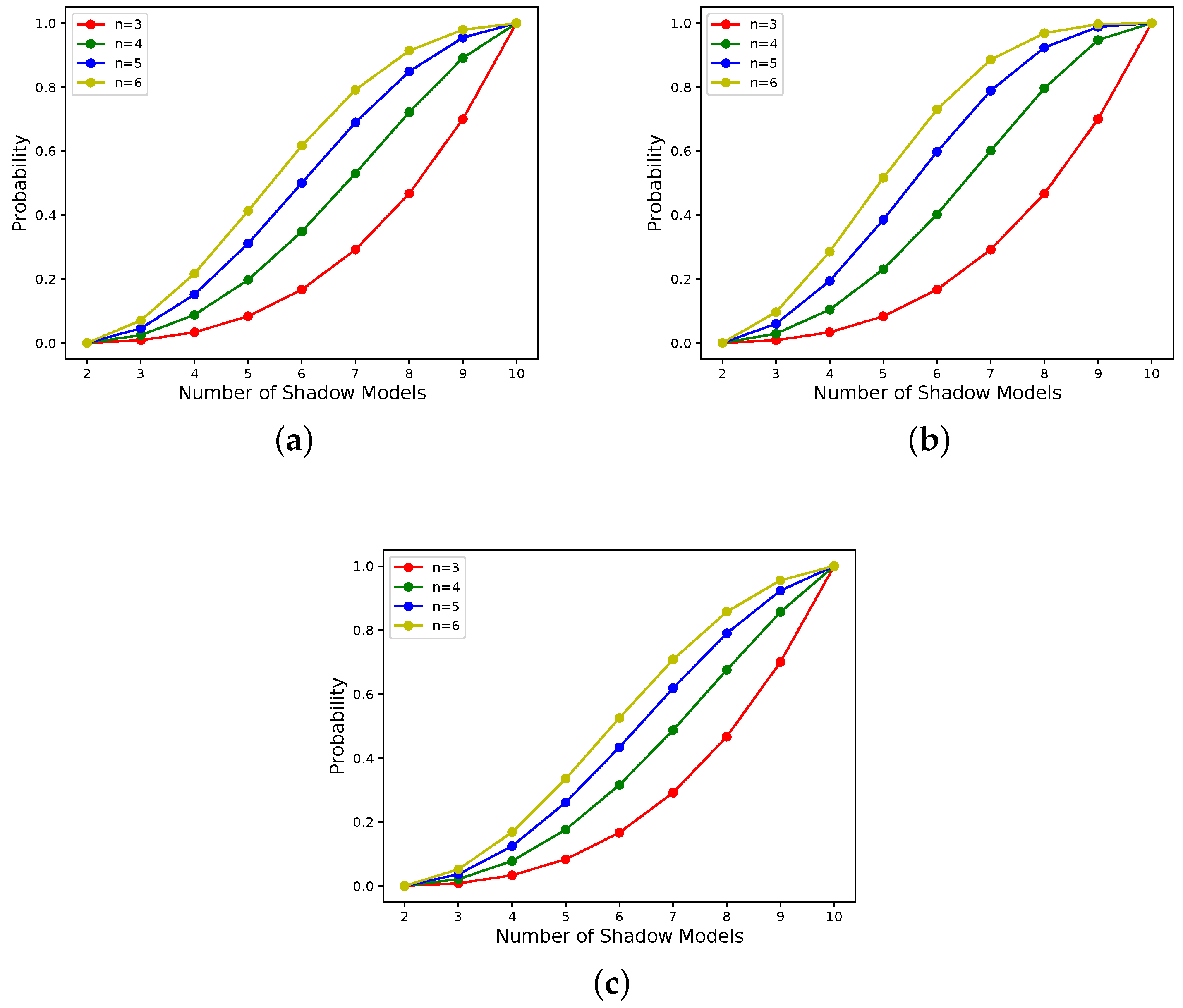
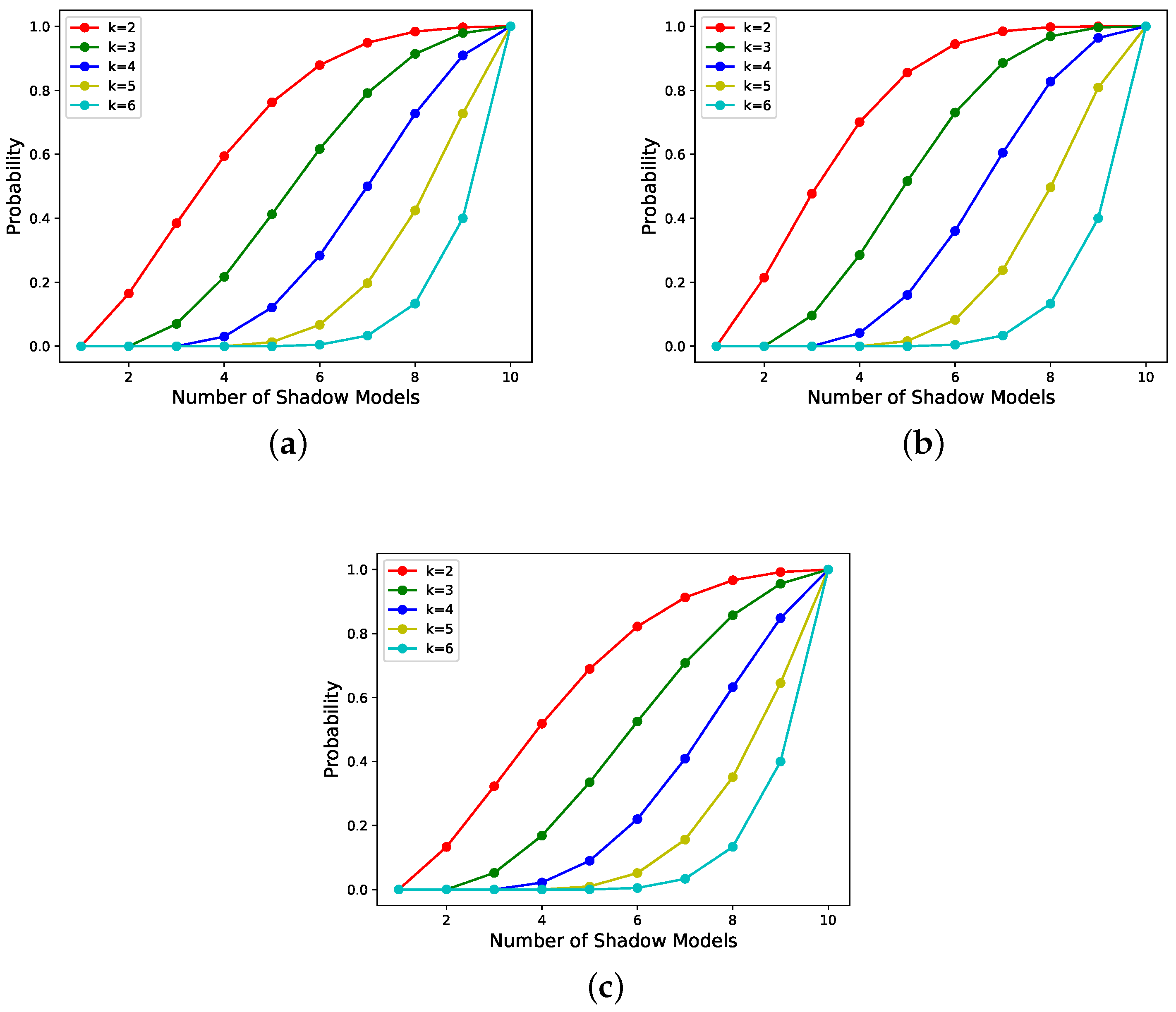
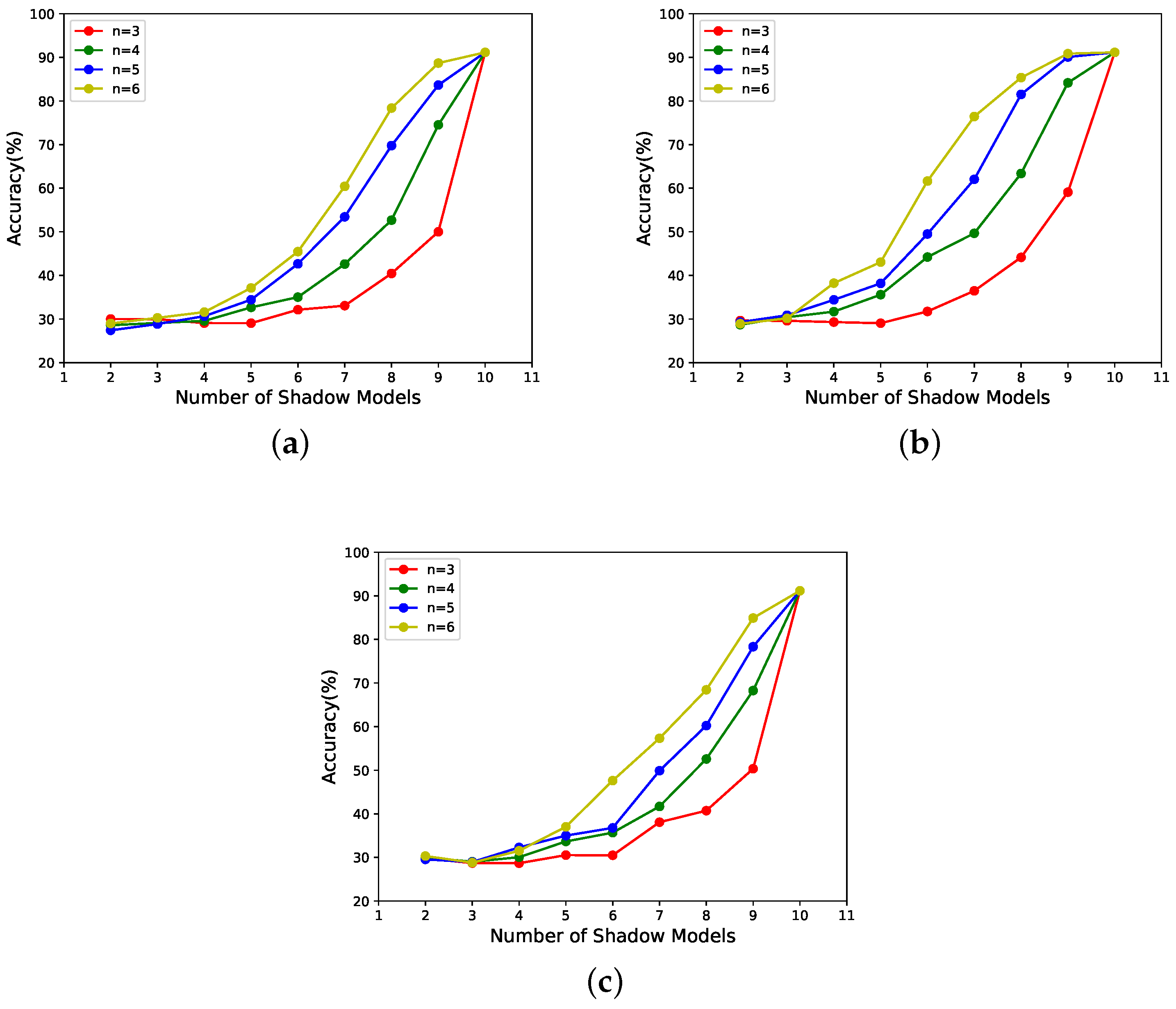
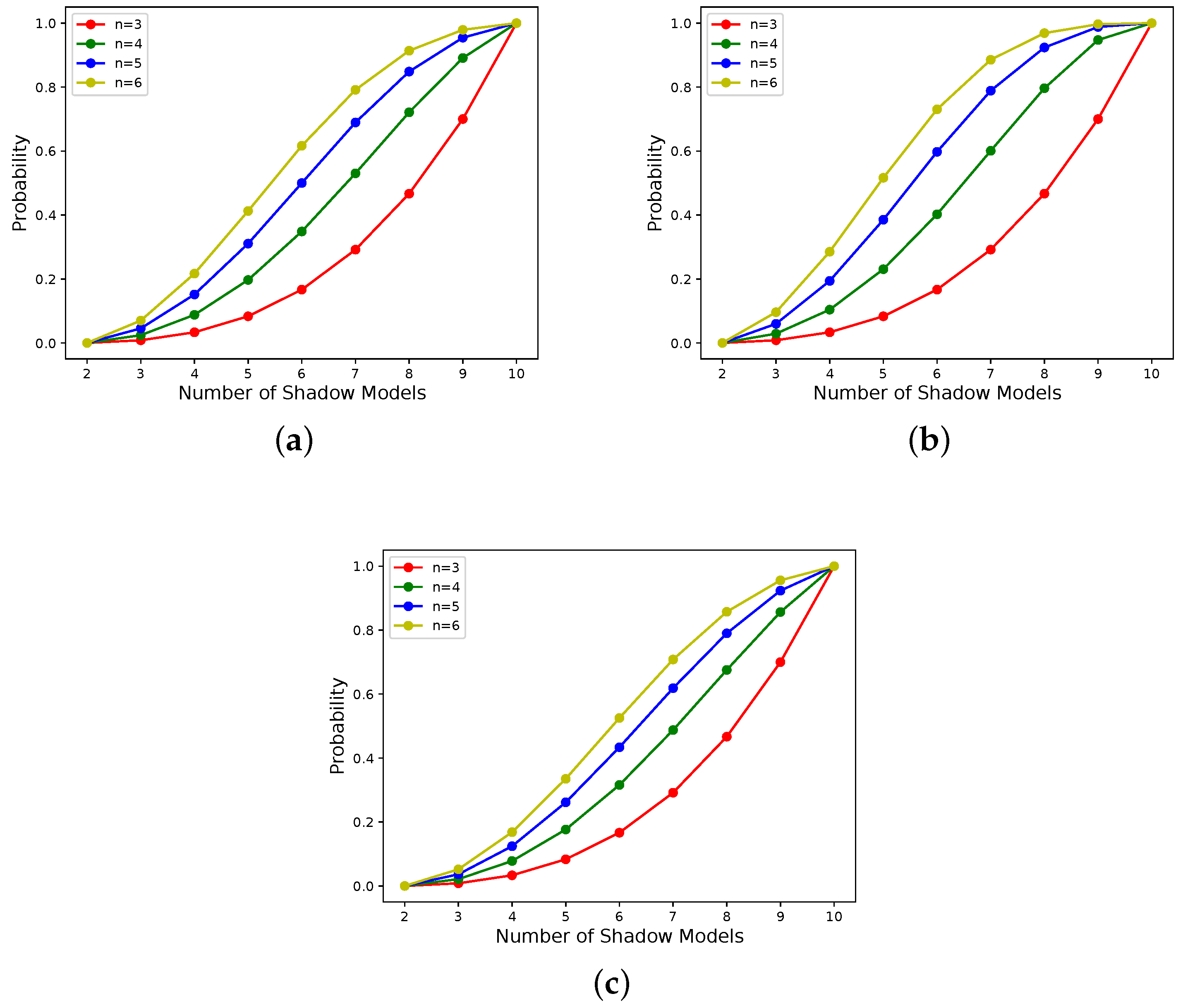
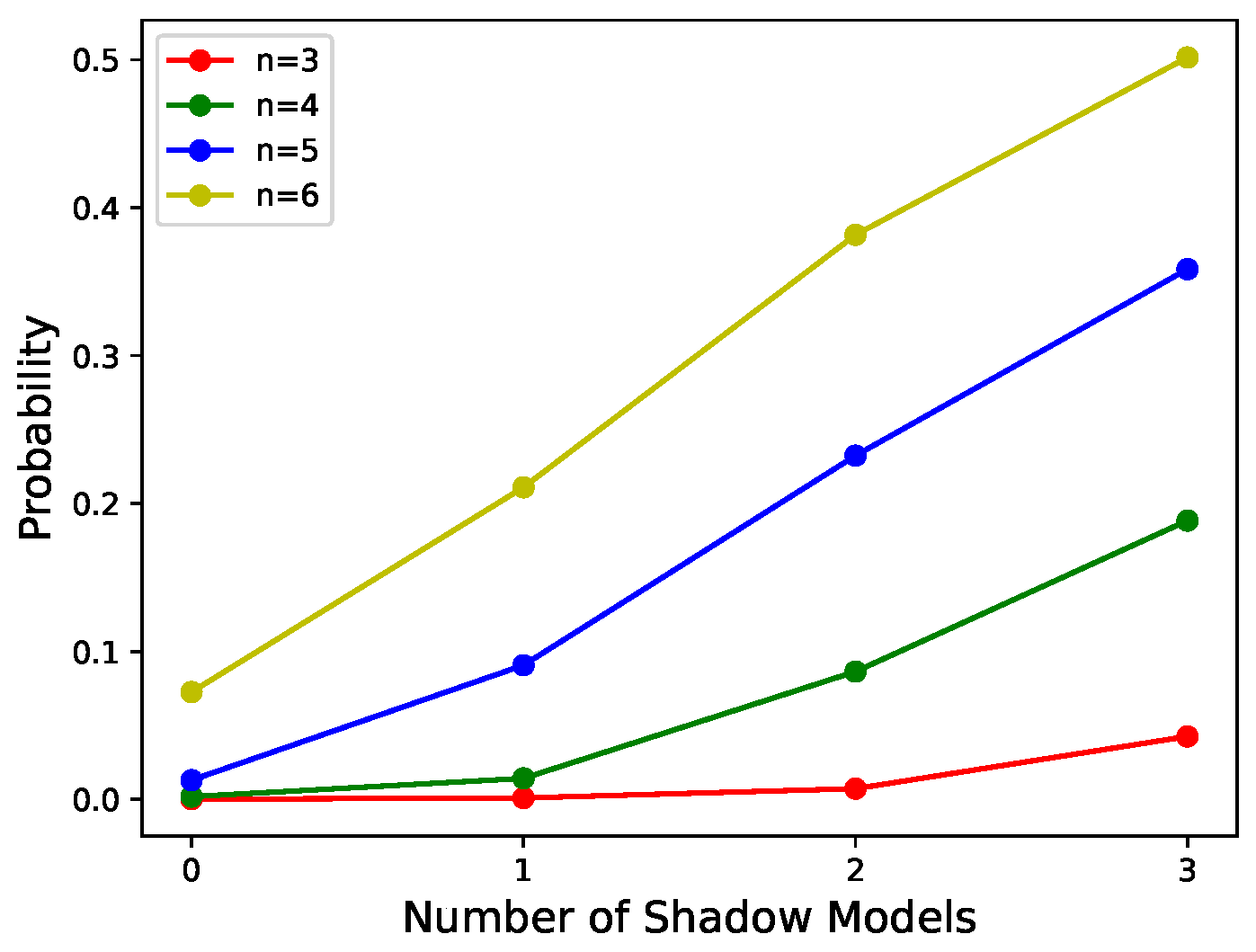
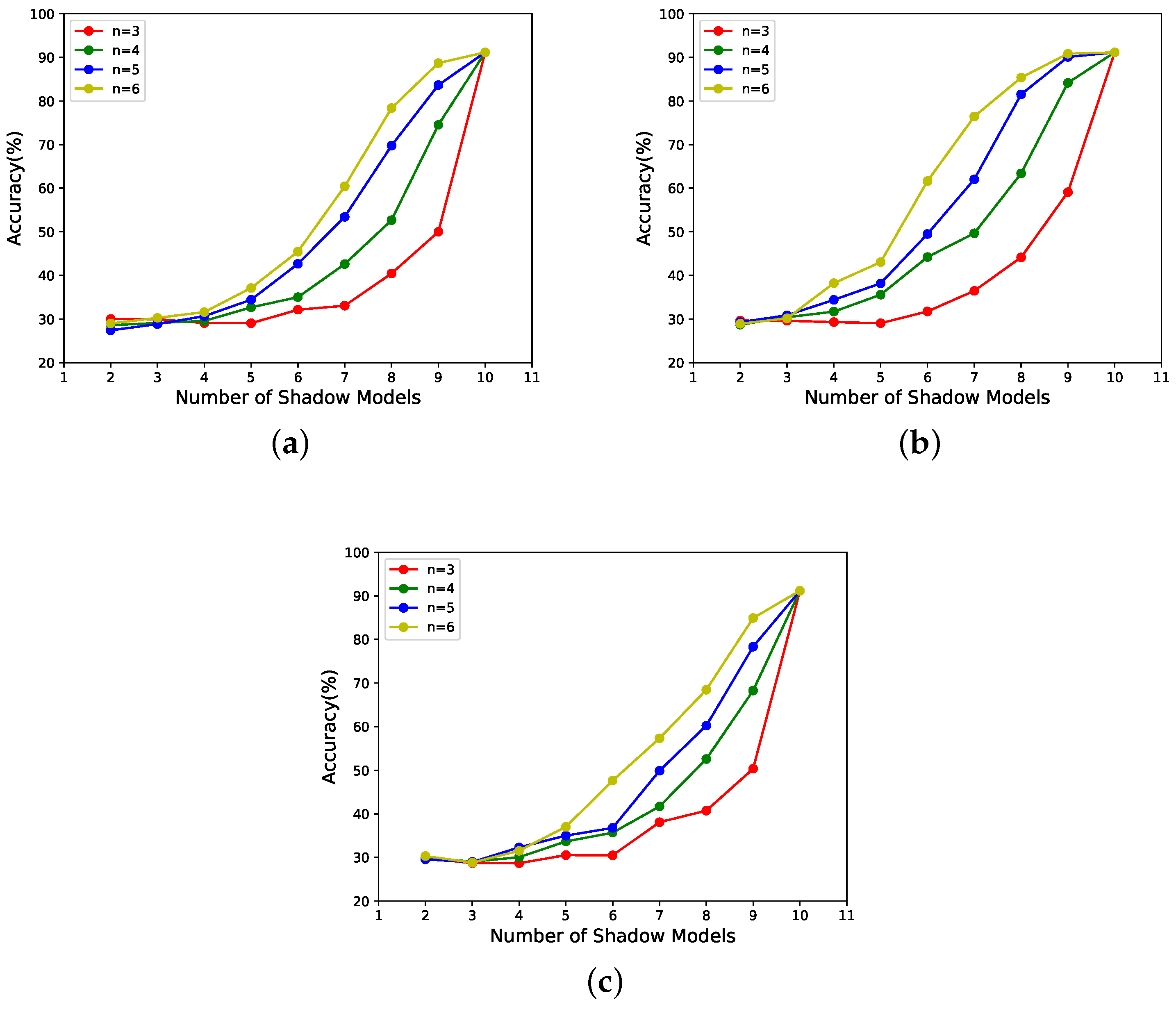
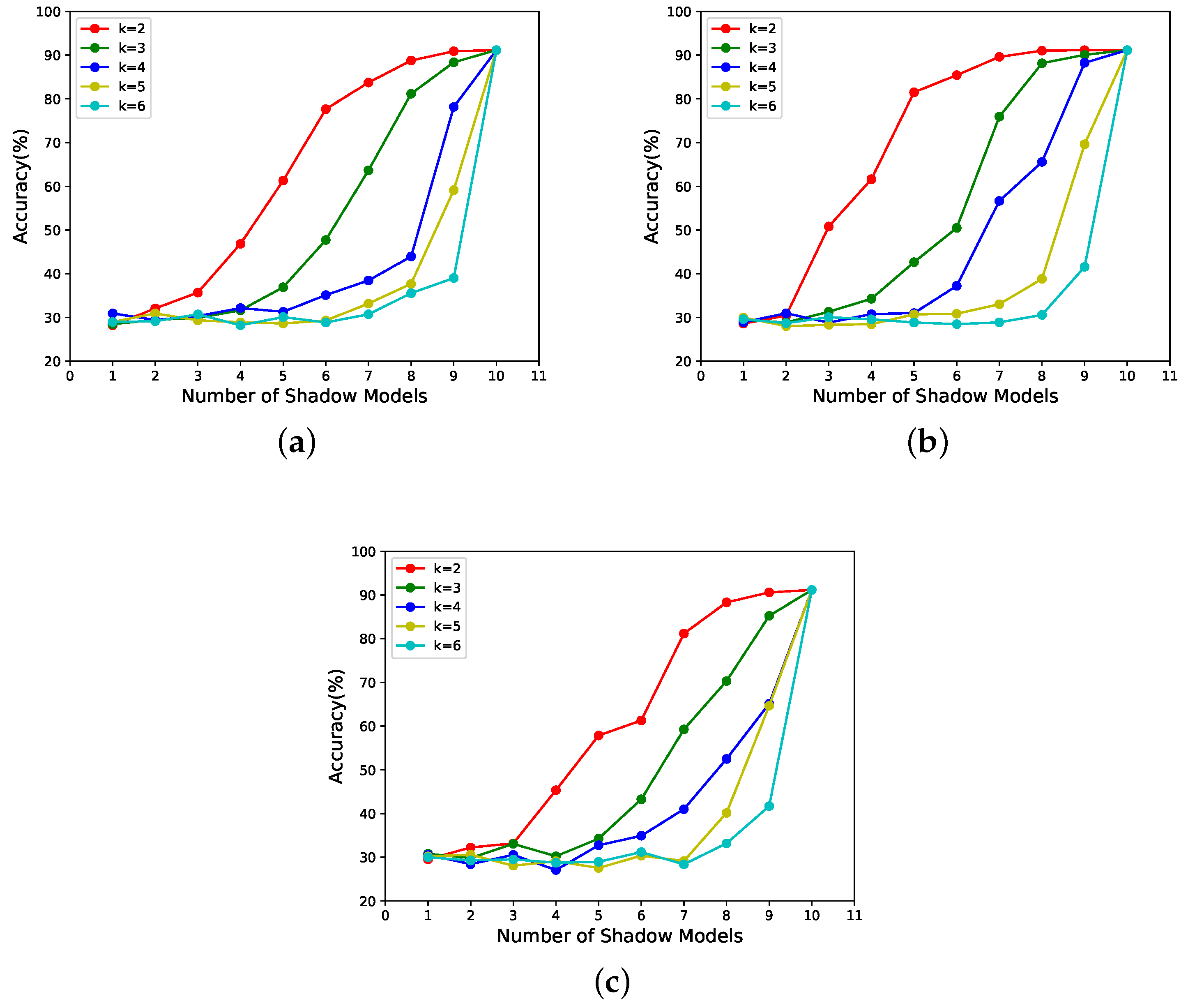
- According to Figure 6 and Figure 7, it can be seen that the scheme proposed in this paper is progressive. In addition, the progressive effect is consistent with that postulated in the last paragraph, in Section 3.3.1.
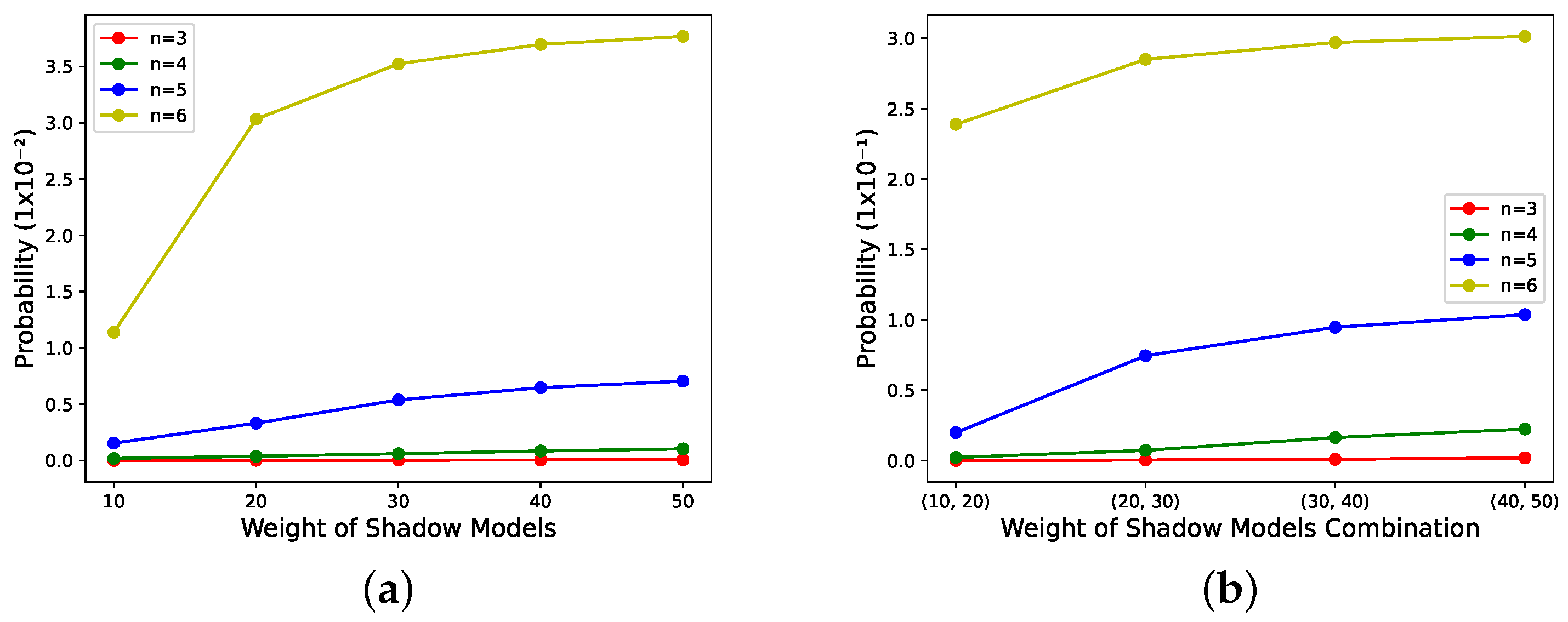
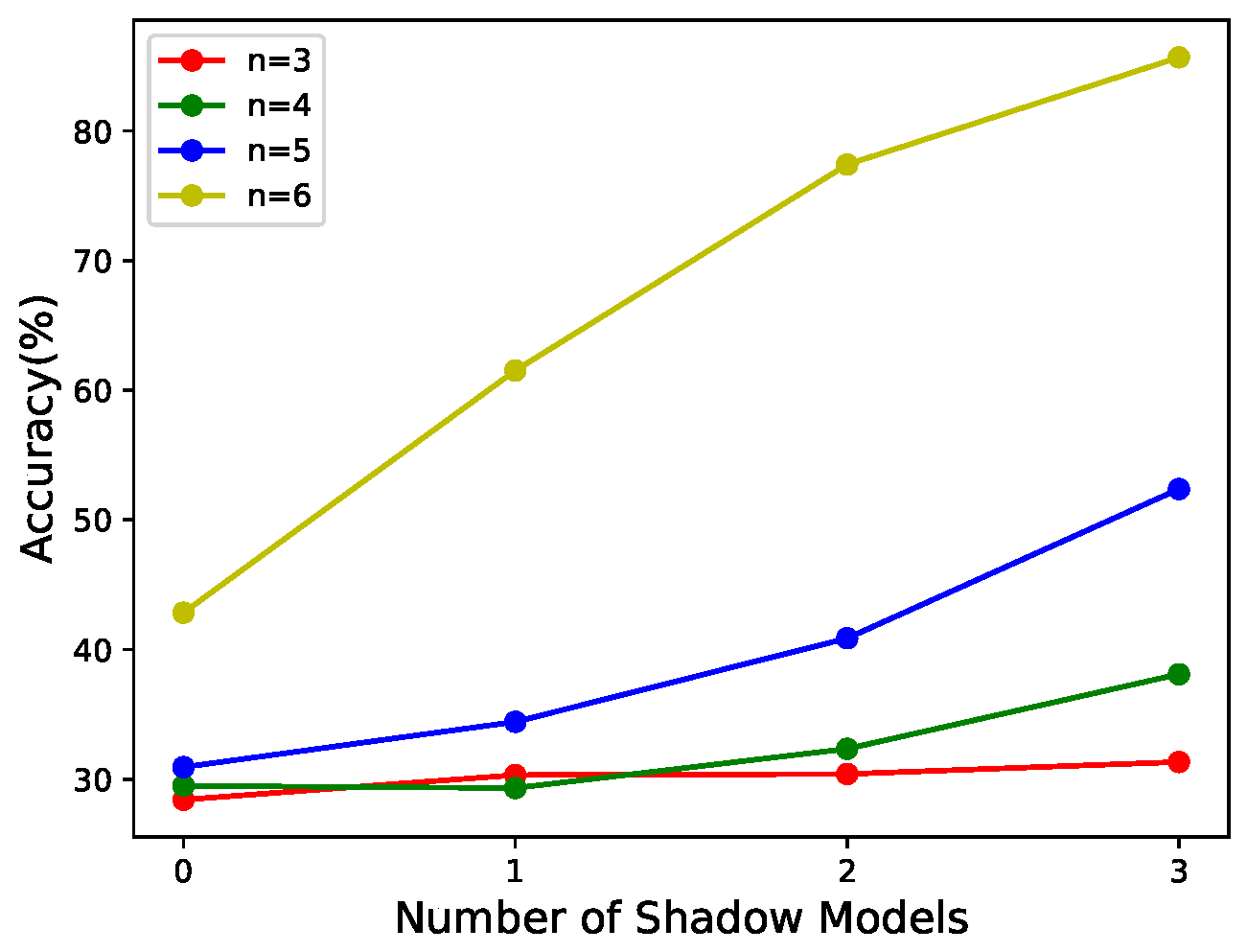
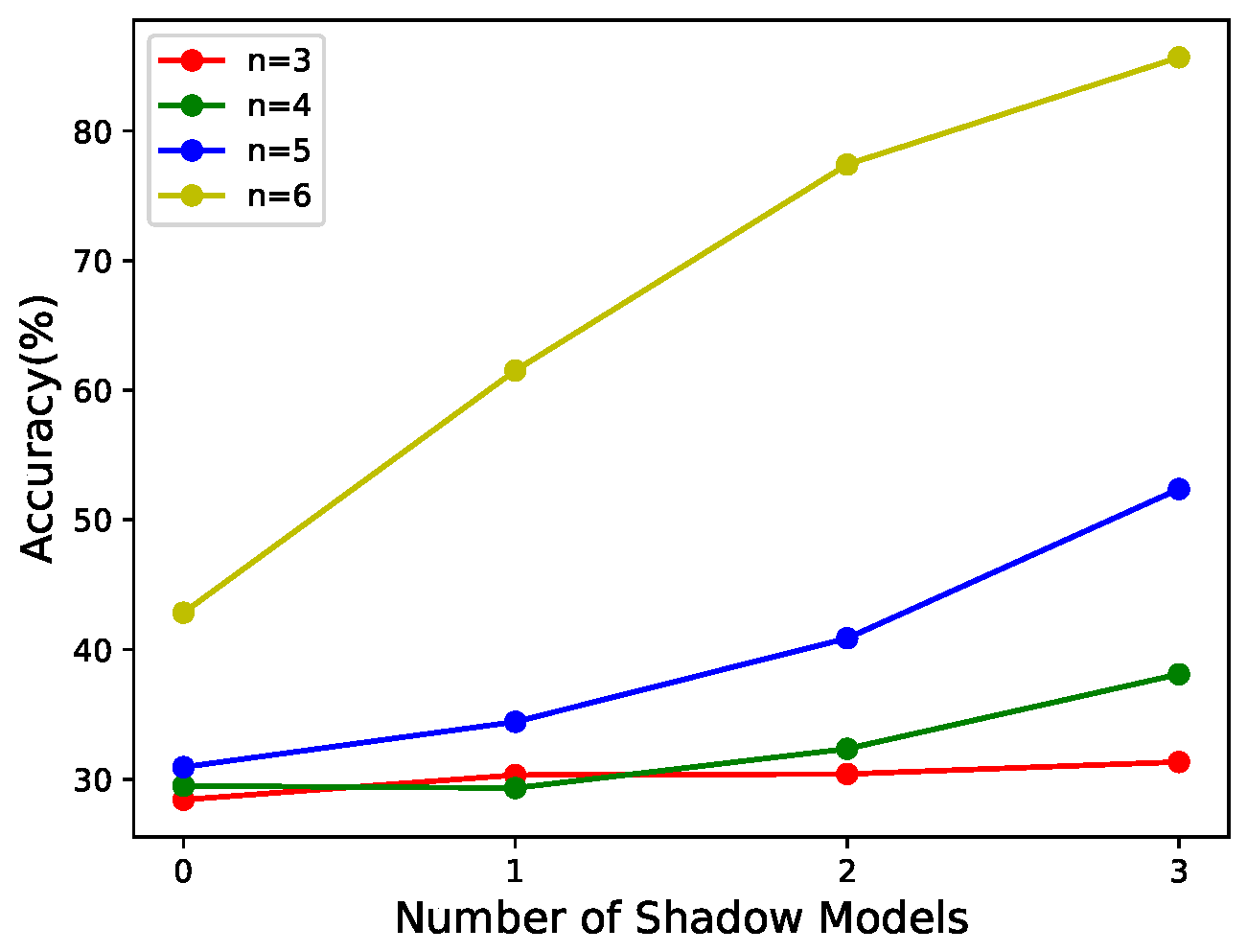
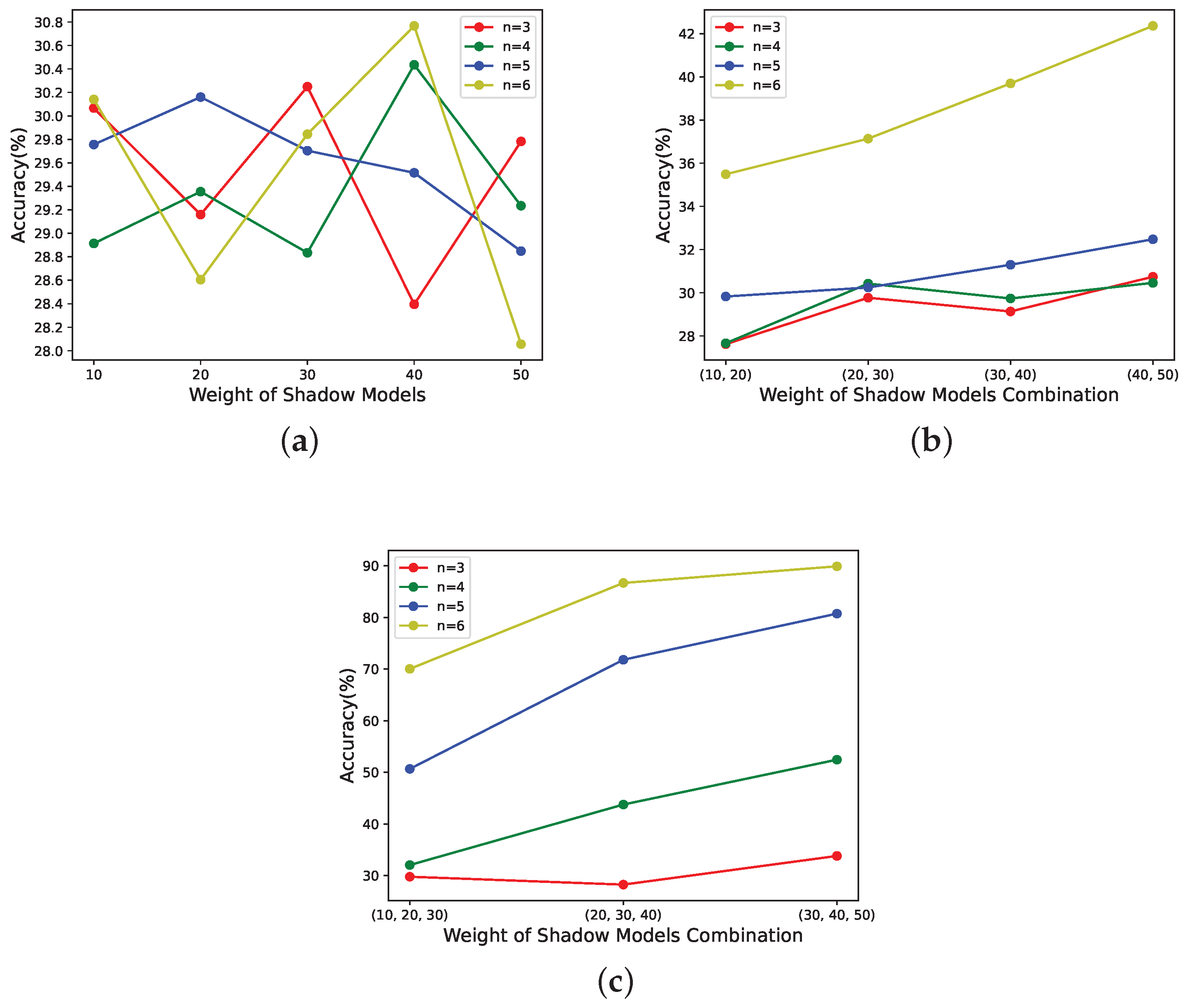
- According to Figure 9a, when the number of shadow models with large weights involved in the recovery phase is much smaller than k, the performance of the reconstructed model does not correlate with the weights of the shadow models in the recovery phase. The reason may be that the number of significant parameters recovered is so tiny that it does not offset the performance impact of the randomness of the recovered parameters. The low number of important parameters was described in the last paragraph of Section 3.3.2.
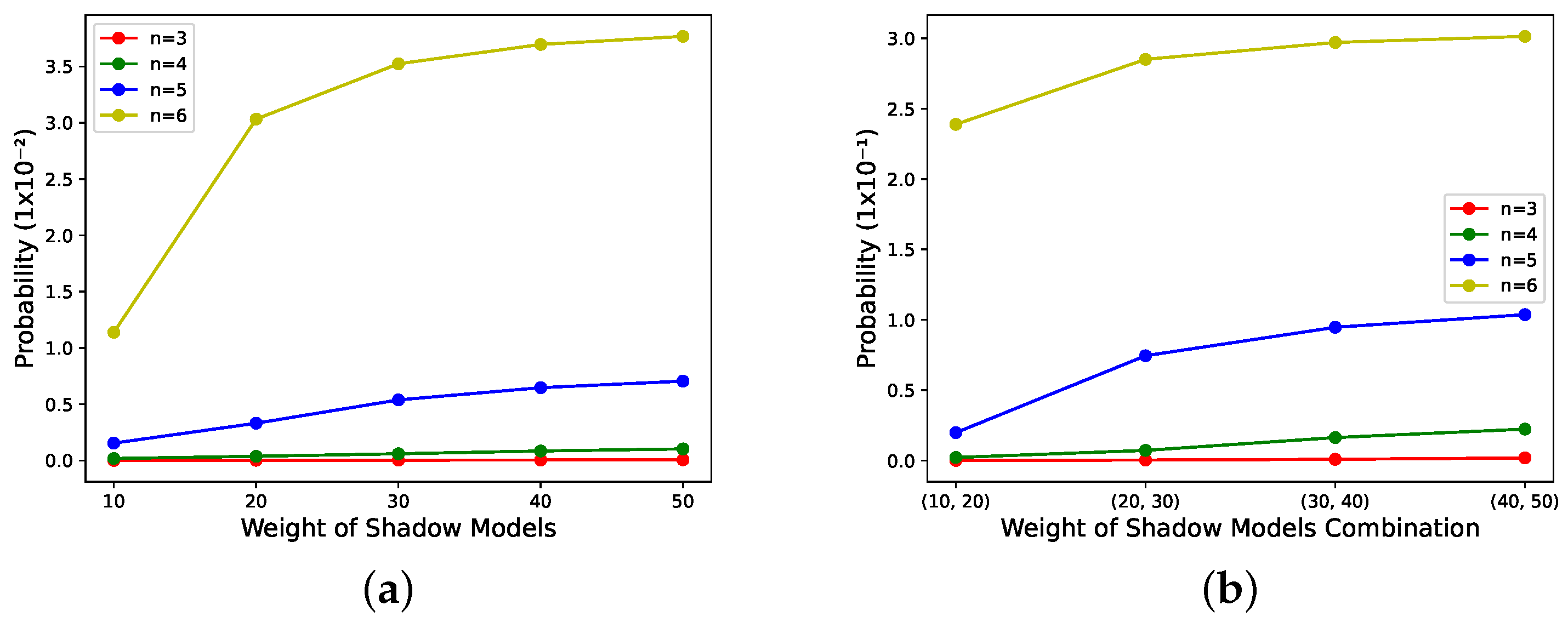
- According to Figure 8 and Figure 9b,c, it can be seen that this scheme has weight validity when the number of shadow models with large weights is involved in the recovery, and the values of n are large. The larger their values are, the stronger the correlation between the performance of the reconstructed model and the weights of the shadow models in the recovery phase.
4.2. Comparison with Other Schemes
5. Conclusions
- It is currently only applicable to classification models and may be challenging for applications on models with a high complexity of output results, such as style migration.
- There is a minimum number of participants k in the recovery phase. It will not be possible to calculate any important parameter values for the reconstructed model for fewer than k participants.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Esteva, A.; Chou, K.; Yeung, S.; Naik, N.; Madani, A.; Mottaghi, A.; Liu, Y.; Topol, E.; Dean, J.; Socher, R. Deep learning-enabled medical computer vision. NPJ Digit. Med. 2021, 4, 1–9. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Voulodimos, A.; Doulamis, N.; Doulamis, A.; Protopapadakis, E. Deep learning for computer vision: A brief review. Comput. Intell. Neurosci. 2018, 2018, 7068349. [Google Scholar] [CrossRef] [PubMed]
- Rebai, I.; BenAyed, Y.; Mahdi, W.; Lorré, J.P. Improving speech recognition using data augmentation and acoustic model fusion. Procedia Comput. Sci. 2017, 112, 316–322. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Sennrich, R.; Haddow, B.; Birch, A. Neural machine translation of rare words with subword units. arXiv 2015, arXiv:1508.07909. [Google Scholar]
- Wu, Y.; Schuster, M.; Chen, Z.; Le, Q.V.; Norouzi, M.; Macherey, W.; Krikun, M.; Cao, Y.; Gao, Q.; Macherey, K.; et al. Google’s neural machine translation system: Bridging the gap between human and machine translation. arXiv 2016, arXiv:1609.08144. [Google Scholar]
- Young, T.; Hazarika, D.; Poria, S.; Cambria, E. Recent trends in deep learning based natural language processing. IEEE Comput. Intell. Mag. 2018, 13, 55–75. [Google Scholar] [CrossRef]
- Karim, M.R.; Beyan, O.; Zappa, A.; Costa, I.G.; Rebholz-Schuhmann, D.; Cochez, M.; Decker, S. Deep learning-based clustering approaches for bioinformatics. Brief. Bioinform. 2021, 22, 393–415. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Min, S.; Lee, B.; Yoon, S. Deep learning in bioinformatics. Brief. Bioinform. 2017, 18, 851–869. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hitaj, D.; Mancini, L.V. Have you stolen my model? Evasion attacks against deep neural network watermarking techniques. arXiv 2018, arXiv:1809.00615. [Google Scholar]
- Zhang, J.; Gu, Z.; Jang, J.; Wu, H.; Stoecklin, M.P.; Huang, H.; Molloy, I. Protecting intellectual property of deep neural networks with watermarking. In Proceedings of the 2018 on Asia Conference on Computer and Communications Security, Incheon, Korea, 4 June 2018; pp. 159–172. [Google Scholar]
- Wang, J.; Wu, H.; Zhang, X.; Yao, Y. Watermarking in deep neural networks via error back-propagation. Electron. Imaging 2020, 2020, 22-1–22-9. [Google Scholar] [CrossRef]
- Rivest, R.L.; Shamir, A.; Adleman, L. A method for obtaining digital signatures and public-key cryptosystems. Commun. ACM 1978, 21, 120–126. [Google Scholar] [CrossRef]
- Verma, A. Encryption and Real Time Decryption for protecting Machine Learning models in Android Applications. arXiv 2021, arXiv:2109.02270. [Google Scholar]
- Tian, J.; Zhou, J.; Duan, J. Probabilistic Selective Encryption of Convolutional Neural Networks for Hierarchical Services. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 2205–2214. [Google Scholar]
- Chen, M.; Wu, M. Protect your deep neural networks from piracy. In Proceedings of the 2018 IEEE International Workshop on Information Forensics and Security (WIFS), Hong Kong, China, 11–13 December 2018; pp. 1–7. [Google Scholar]
- Shamir, A. How to share a secret. Commun. ACM 1979, 22, 612–613. [Google Scholar] [CrossRef]
- Blakley, G.R. Safeguarding cryptographic keys. In Proceedings of the Managing Requirements Knowledge, International Workshop on. IEEE Computer Society, New York, NY, USA, 4–7 June 1979; p. 313. [Google Scholar]
- Hou, Y.C.; Quan, Z.Y.; Tsai, C.F. A privilege-based visual secret sharing model. J. Vis. Commun. Image Represent. 2015, 33, 358–367. [Google Scholar] [CrossRef]
- Liu, F.; Yan, X.; Liu, L.; Lu, Y.; Tan, L. Weighted visual secret sharing with multiple decryptions and lossless recovery. Math. Biosci. Eng. 2019, 16, 5750–5764. [Google Scholar] [CrossRef] [PubMed]
- Yu, Y.; Li, L.; Lu, Y.; Yan, X. On the value of order number and power in secret image sharing. Secur. Commun. Netw. 2020, 2020, 6627178. [Google Scholar] [CrossRef]
- Wang, Y.; Chen, J.; Gong, Q.; Yan, X.; Sun, Y. Weighted Polynomial-Based Secret Image Sharing Scheme with Lossless Recovery. Secur. Commun. Netw. 2021, 2021, 5597592. [Google Scholar] [CrossRef]
- Zhang, J.; Chen, D.; Liao, J.; Fang, H.; Zhang, W.; Zhou, W.; Cui, H.; Yu, N. Model watermarking for image processing networks. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12805–12812. [Google Scholar]
- Morcos, A.S.; Barrett, D.G.; Rabinowitz, N.C.; Botvinick, M. On the importance of single directions for generalization. arXiv 2018, arXiv:1803.06959. [Google Scholar]
- Shrikumar, A.; Greenside, P.; Kundaje, A. Learning important features through propagating activation differences. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 3145–3153. [Google Scholar]
- Yu, R.; Li, A.; Chen, C.F.; Lai, J.H.; Morariu, V.I.; Han, X.; Gao, M.; Lin, C.Y.; Davis, L.S. Nisp: Pruning networks using neuron importance score propagation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 9194–9203. [Google Scholar]
- Papernot, N.; McDaniel, P.; Sinha, A.; Wellman, M.P. Sok: Security and privacy in machine learning. In Proceedings of the 2018 IEEE European Symposium on Security and Privacy (EuroS&P), London, UK, 24–26 April 2018; pp. 399–414. [Google Scholar]
- Wang, X.; Lu, Y.; Yan, X.; Yu, L. Wet Paper Coding-Based Deep Neural Network Watermarking. Sensors 2022, 22, 3489. [Google Scholar] [CrossRef] [PubMed]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Subfigure Number | Candidate Shadow Models’ Weight | Shadow Models’ Weight |
|---|---|---|
| a | all of them are 1 | all of them are 1 |
| b | 3 of them are 10, the rest are 1 | 3 of them are 10, the rest are 1 |
| c | 3 of them are 1, the rest are 10 | 3 of them are 1, the rest are 10 |
| Parameter | Value |
|---|---|
| The number of layers where important parameters are located in VGG19 | 1, 2, 3 |
| Ratio of important parameters per layer | 2% |
| Finite field prime P | 40,009 |
| Deviation | 1.5 |
| Precision R | 2 |
| Complexity | The NNSS Scheme | General Encryption Scheme | Encryption Scheme with Selection Strategy |
|---|---|---|---|
| Time Complexity | |||
| Space Complexity |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, X.; Shan, H.; Yan, X.; Yu, L.; Yu, Y. A Neural Network Model Secret-Sharing Scheme with Multiple Weights for Progressive Recovery. Mathematics 2022, 10, 2231. https://doi.org/10.3390/math10132231
Wang X, Shan H, Yan X, Yu L, Yu Y. A Neural Network Model Secret-Sharing Scheme with Multiple Weights for Progressive Recovery. Mathematics. 2022; 10(13):2231. https://doi.org/10.3390/math10132231
Chicago/Turabian StyleWang, Xianhui, Hong Shan, Xuehu Yan, Long Yu, and Yongqiang Yu. 2022. "A Neural Network Model Secret-Sharing Scheme with Multiple Weights for Progressive Recovery" Mathematics 10, no. 13: 2231. https://doi.org/10.3390/math10132231
APA StyleWang, X., Shan, H., Yan, X., Yu, L., & Yu, Y. (2022). A Neural Network Model Secret-Sharing Scheme with Multiple Weights for Progressive Recovery. Mathematics, 10(13), 2231. https://doi.org/10.3390/math10132231