
A Joint Learning Model to Extract Entities and Relations for Chinese Literature Based on Self-Attention


Abstract
:1. Introduction
- We designed the BiLSTM-Self-Attention-CRF model to realize the Chinese named entity recognition. The BiLSTM model is used to obtain the text features. The feature weights are calculated by combining the self-attention mechanism. Finally, CRF is used to decode, and the entity recognition results are obtained.
- We designed the BiLSTM-Multilevel-Attention model to realize relation extraction. The BiLSTM is used to consider the context and semantic connection of the text entirely, and the key feature words are obtained by combining a multilevel attention mechanism.
- We put forward a joint model to make the data information of the two parts more closely linked and fully capture the inline information of the two tasks.
2. Related Work
2.1. Named Entity Recognition
2.2. Relation Extraction
2.3. Joint Learning
3. Model Framework
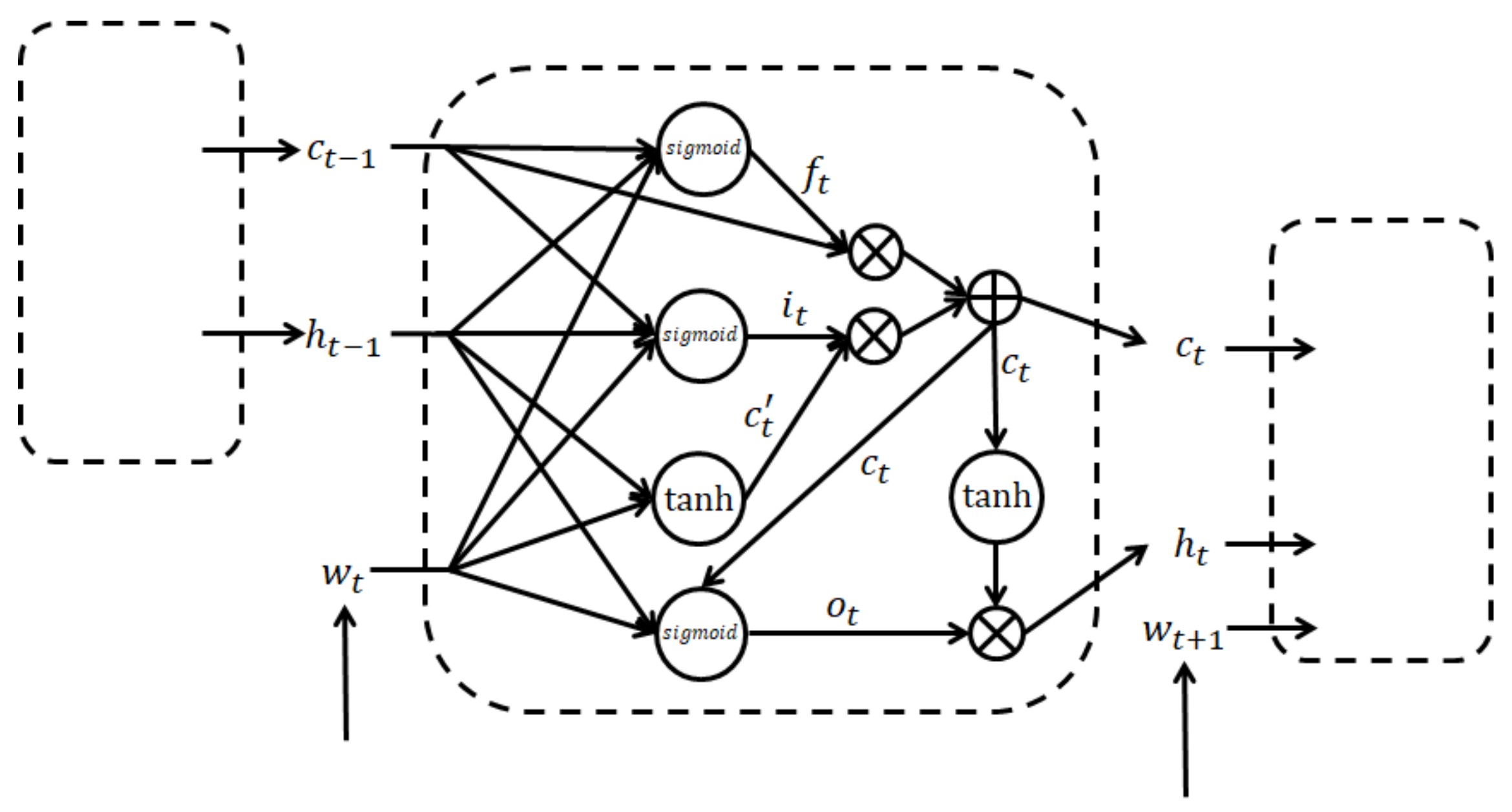
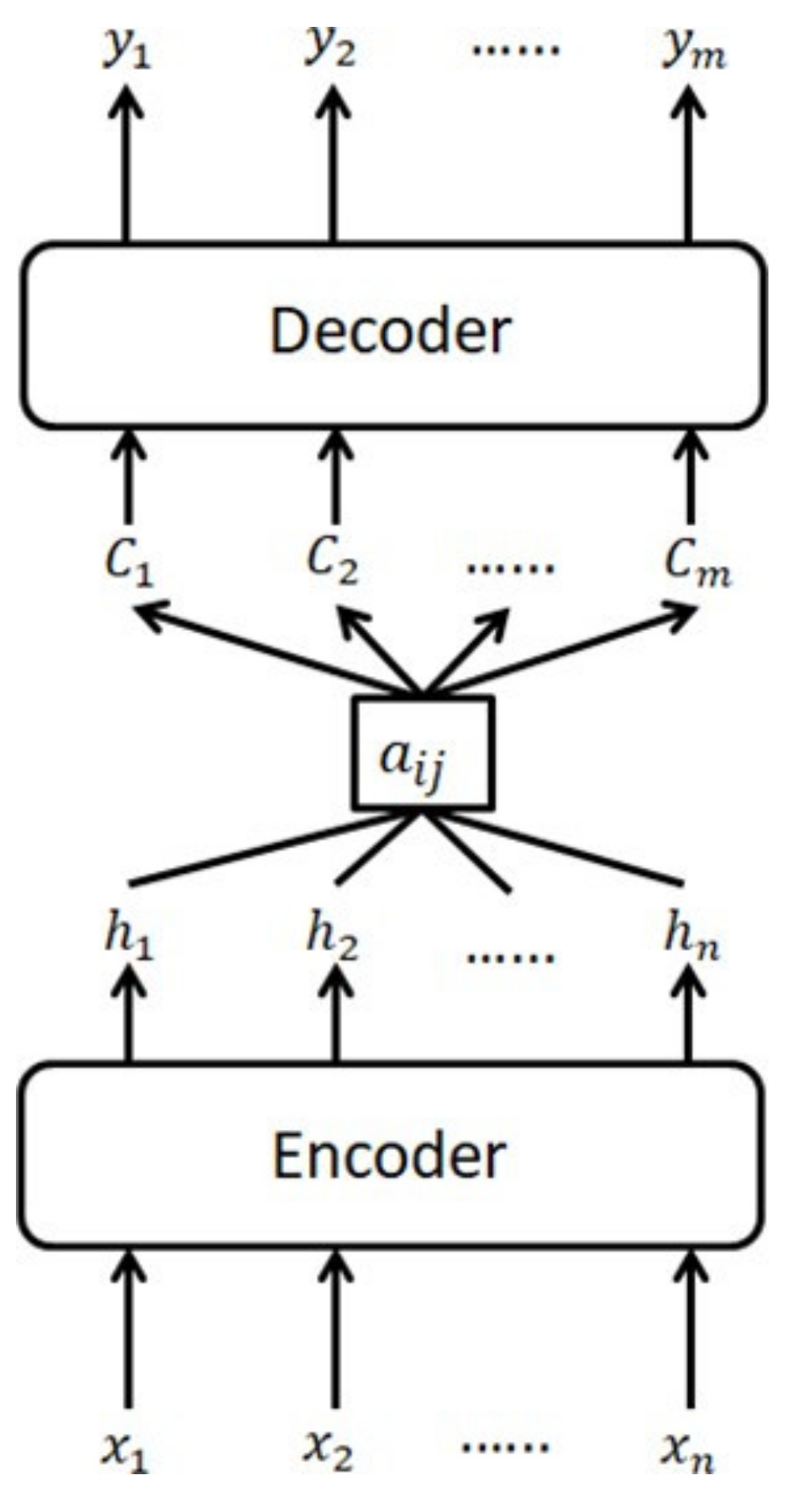
3.1. Long-Term and Short-Term Memory Networks
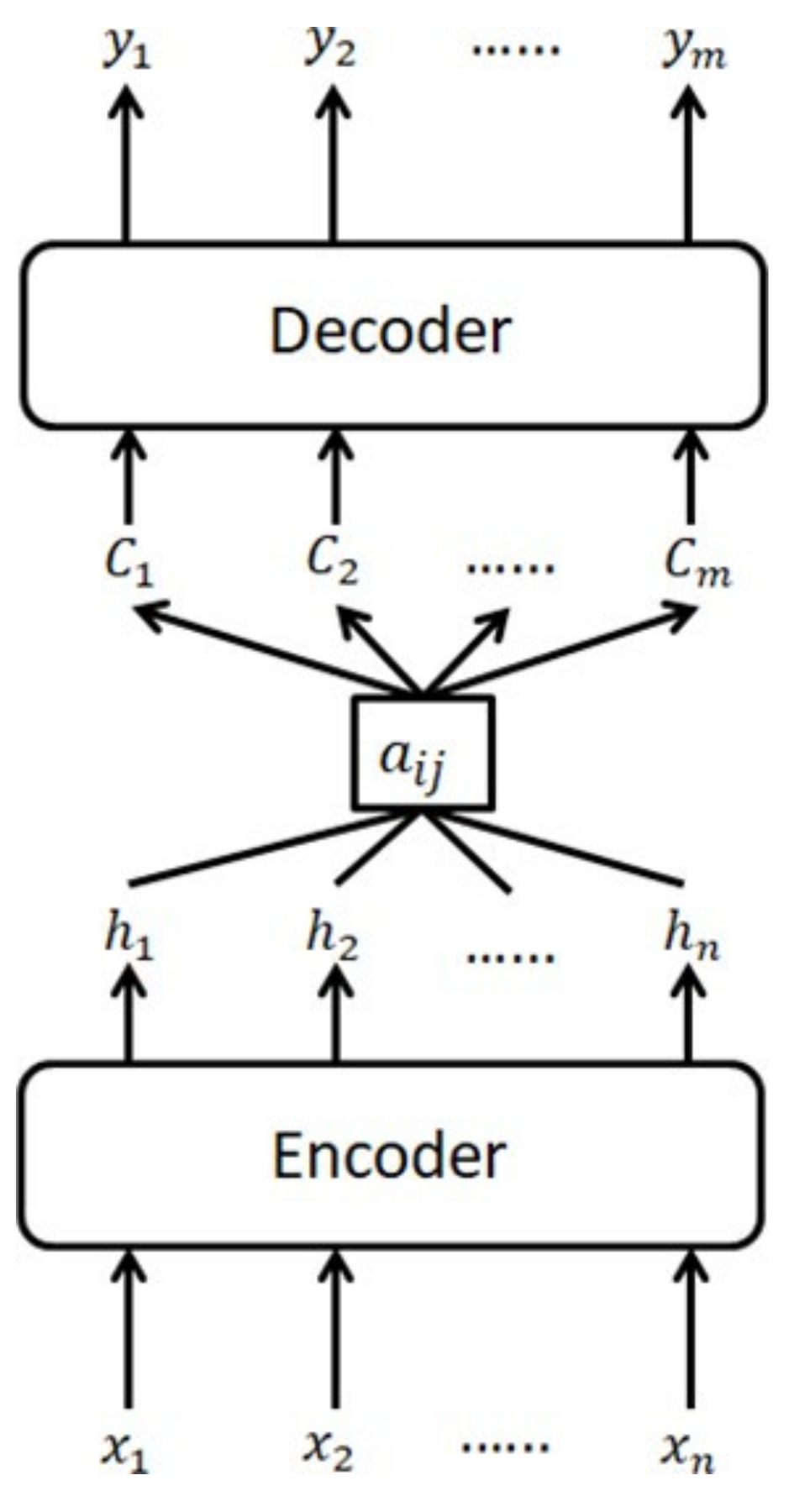
3.2. Traditional Attention Mechanism and Self-Attention Mechanism
3.3. Joint Learning Model
3.3.1. Shared Underlying Module
3.3.2. Named Entity Recognition Module Based on Self-Attention-CRF
3.3.3. Relation Extraction Module Based on Multilevel-Attention
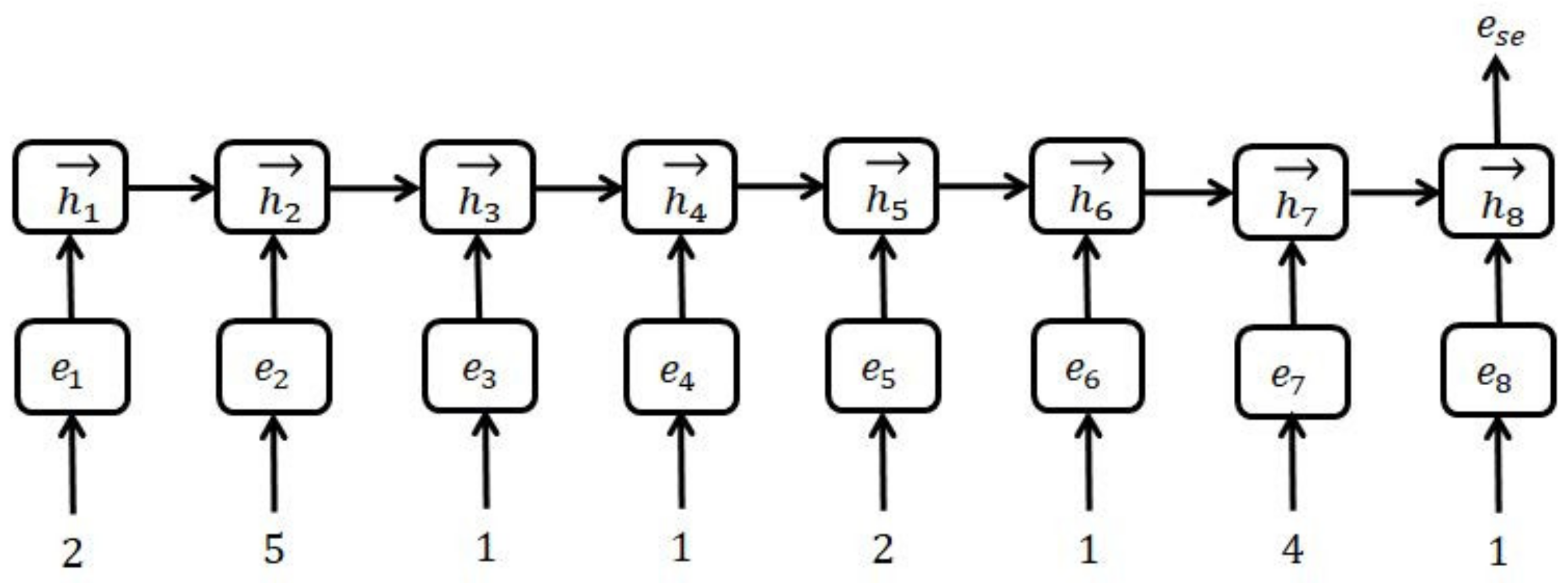
- Relative entity location feature. There are two values, which represent the distance between the current word and entity 1 and entity 2, respectively. For example, in the statement “Guangzhou is the capital of Guangdong”, the values of relative entity location feature of each word for the entity pair <Guangzhou, Guangdong> are shown in Table 1.
- Entity type feature. There are two values, entity type 1 of entity 1 and entity type 2 of entity 2. As shown in the above example, the entity pairs <Guangzhou, Guangdong> are both place name entities, and their corresponding entity type features are location.
4. Experiment and Analysis
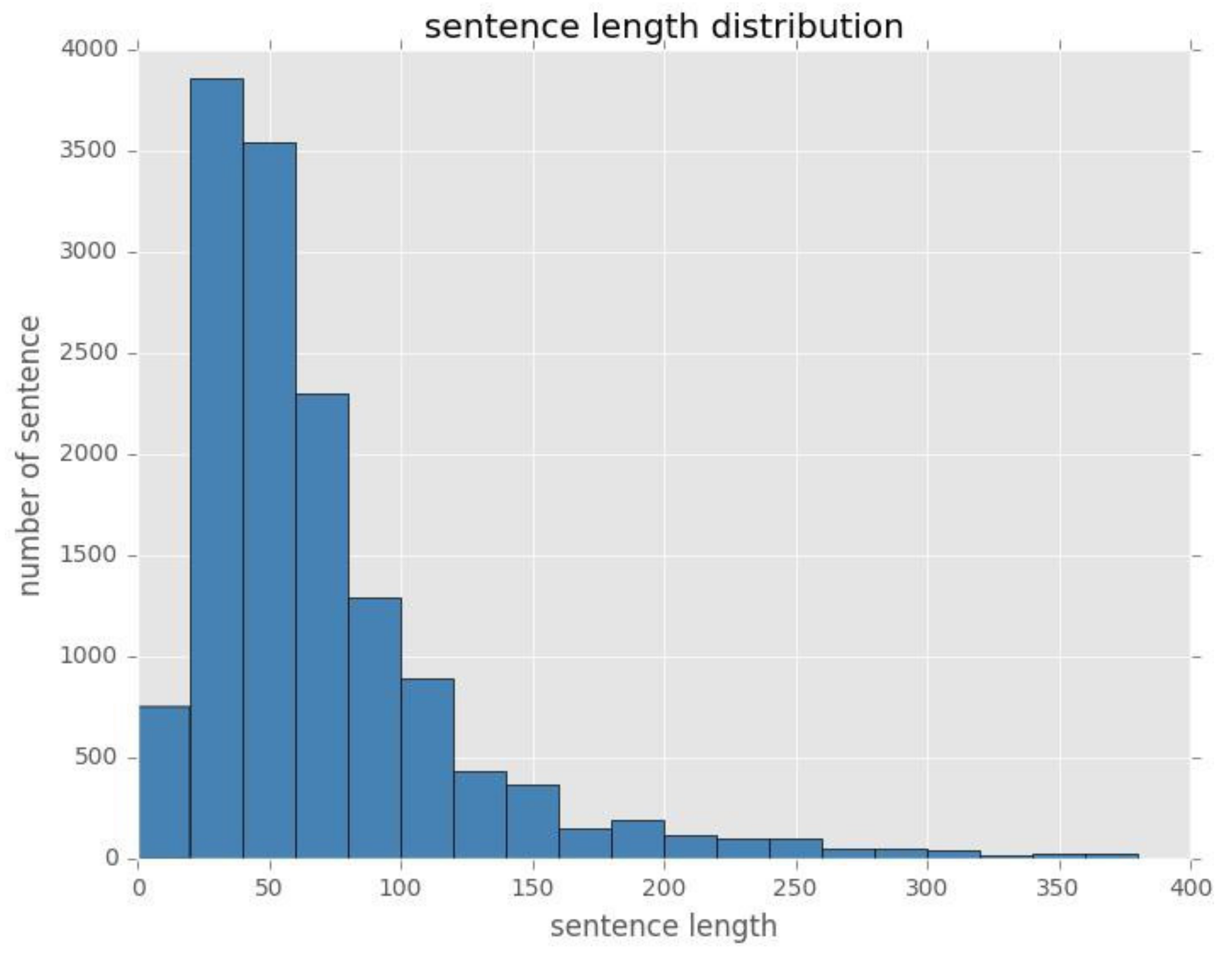
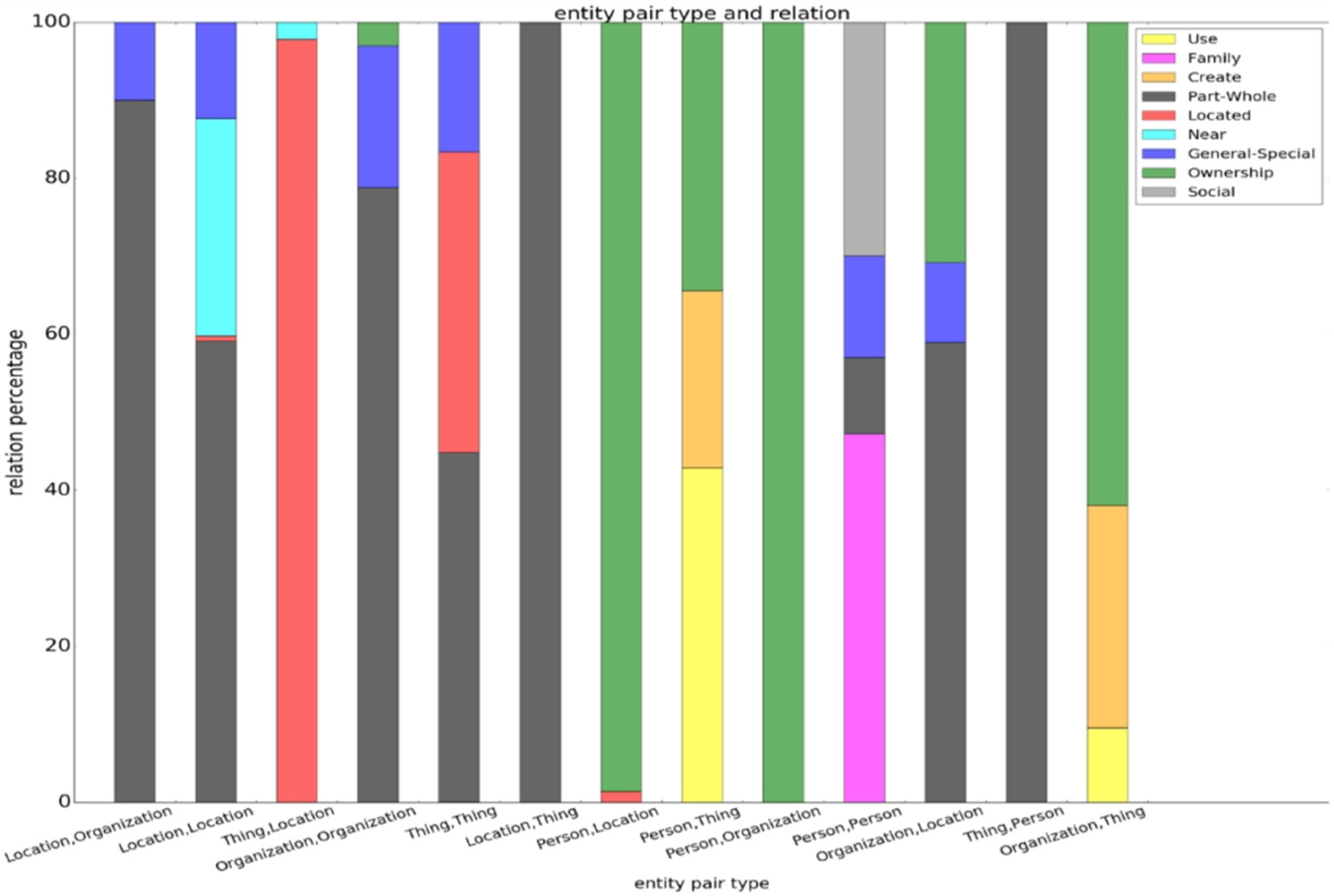
4.1. Corpus
4.2. Metrics
4.3. Experimental Results and Analysis
4.3.1. Named Entity Recognition Task
- The mutual influence between entities of the same type contributes to the labeling of the entity in the sentence. As shown in Figure 6, the words “Guizhou”, “Hunan” and “province” have far- reaching influence on “Jiangxi”, a lot more than the influence of other words; the influence of the words “Guizhou”, “Jiangxi” and “province” on “Hunan” is much greater than the influence of other words. These influences tend to increase the probability that “Jiangxi” and “Hunan” are labeled as the same type of location as “Guizhou”.
- The interaction between entities with referential relationships contributes to the labeling of entities in sentences. As shown in Figure 7, the influence of “wetland” on “paradise” is much greater than the influence of other words in sentences. The influence of the referential relationship tends to increase the probability that the “paradise” is labeled as the same type of location as the ”wetland”.
- The attention between words and words in a longer entity contributes to the accurate labeling of the long entity. As shown in Figure 8, the influence of the eight words in the “1960s and 1970s” entity is much greater than the influence of other words.
- The influence of verbs in sentences contributes to the recognition of noun entities. As shown in Figure 9, the influence of “crawl” on “body” is much greater than the influence of other words.
4.3.2. Relation Extraction Task
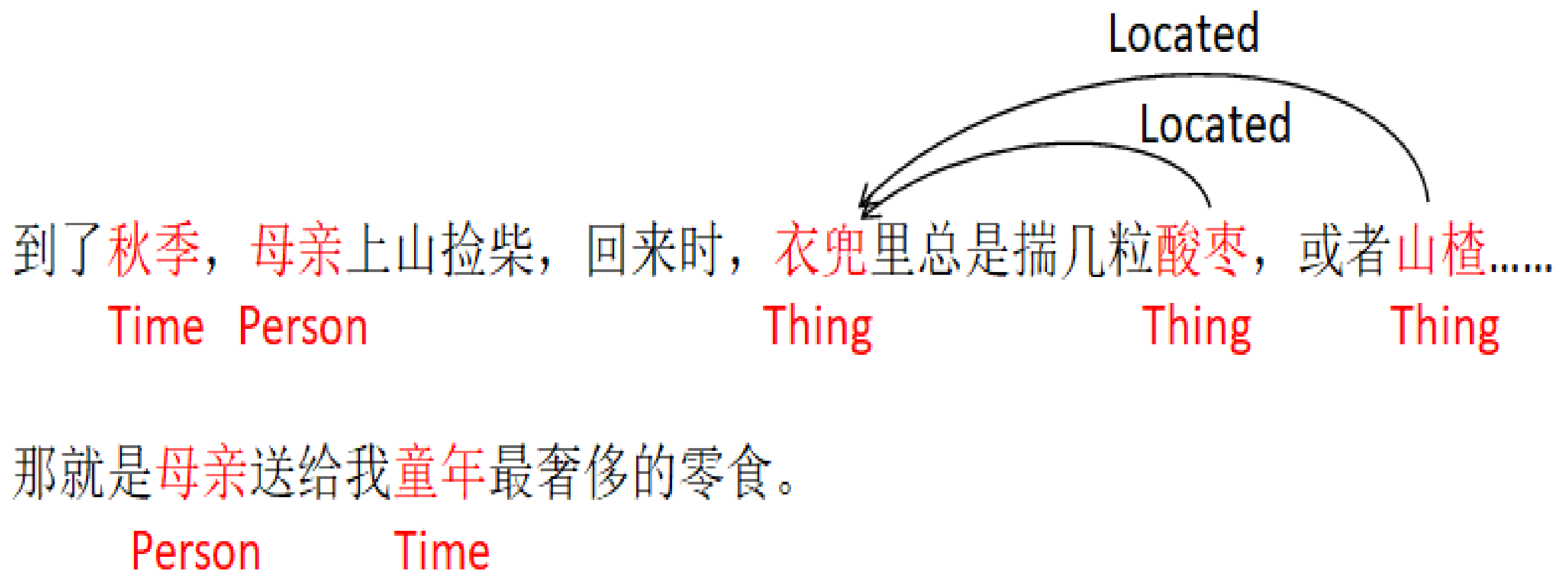
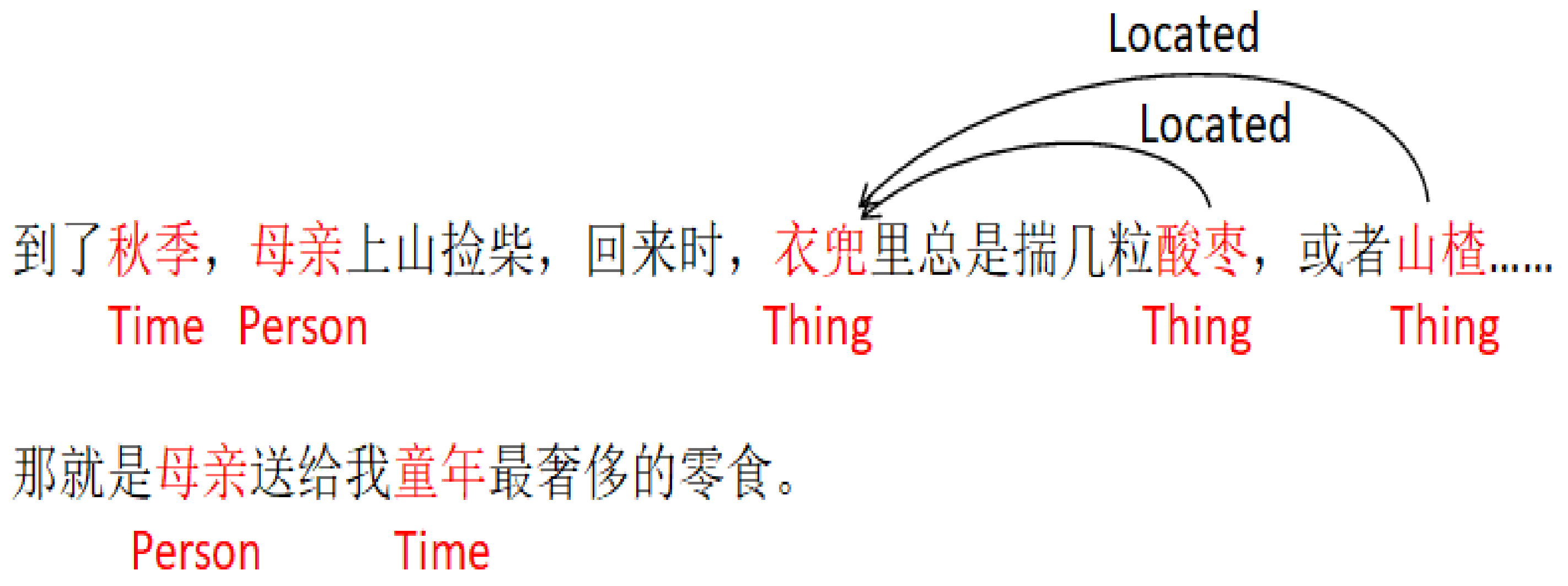
- As shown in Figure 10, in the relationship visualization example of “In the autumn, mother goes up the mountain and chops, when she comes back, her pocket always carries a few grains of sour jujube, or hawthorn……that is the most extravagant snacks of childhood mother gives me.”, it can be seen that the matrix pays more attention to the words such as “pocket”, “inside” and “carries”, which greatly affects the entity pair ¡several jujube, and the pocket¿ to be judged as the social relationship.
- As shown in Figure 11, in the relationship visualization example of “Sun Jinyou’s home is holding a blue tile in the south of Wuye’s house; and only a short wall away from his east neighbor Wang Endian”, it can be seen that the words “east”, “and” and “neighbor” have greatly influenced the entity pair “Sun Jinyou, Wang Endian” to be judged as the social relationship.
5. Conclusions
- Exploring the capability of using artificial feature functions to improve the performance of named entity recognition, such as complex organizational names;
- Optimize the characteristics of the Chinese and English corpora in other fields to improve the universality of the model.
Author Contributions
Funding
Conflicts of Interest
References
- Aone, C.; Ramos-Santacruz, M. REES: A large-scale relation and event extraction system. In Proceedings of the Sixth Conference on Applied Natural Language Processing, Washington, DC, USA, 29 April–4 May 2000; pp. 76–83. [Google Scholar]
- Bikel, D.M.; Schwartz, R.; Weischedel, R.M. An algorithm that learns what’s in a name. Mach. Learn. 1999, 34, 211–231. [Google Scholar] [CrossRef]
- Bender, O.; Och, F.J.; Ney, H. Maximum entropy models for named entity recognition. In Proceedings of the Seventh Conference on Natural Language Learning at HLT-NAACL 2003, Edmonton, AB, Canada, 31 May–1 June 2003; Volume 4, pp. 148–151. [Google Scholar]
- McCallum, A.; Li, W. Early results for named entity recognition with conditional random fields, feature induction and web-enhanced lexicons. In Proceedings of the Seventh Conference on Natural Language Learning at HLT-NAACL 2003, Edmonton, AB, Canada, 31 May–1 June 2003; Volume 4, pp. 188–191. [Google Scholar]
- Jiang, J.; Zhai, C.X. A systematic exploration of the feature space for relation extraction. In Human Language Technologies 2007: The Conference of the North American Chapter of the Association for Computational Linguistics, Proceedings of the Main Conference, Rochester, NY, USA, 22–27 April 2007; Omnipress Inc.: Madison, WI, USA, 2007; pp. 113–120. [Google Scholar]
- Collobert, R.; Weston, J.; Bottou, L.; Karlen, M.; Kavukcuoglu, K.; Kuksa, P. Natural language processing (almost) from scratch. J. Mach. Learn. Res. 2011, 12, 2493–2537. [Google Scholar]
- Chiu, J.P.C.; Nichols, E. Named entity recognition with bidirectional LSTM-CNNs. Trans. Assoc. Comput. Linguist. 2016, 4, 357–370. [Google Scholar] [CrossRef]
- Lample, G.; Ballesteros, M.; Subramanian, S.; Kawakami, K.; Dyer, C. Neural Architectures for Named Entity Recognition. In Proceedings of the 15th Annual Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 17 2016; pp. 260–270. [Google Scholar]
- Ma, X.; Hovy, E. End-to-end Sequence Labeling via Bi-directional LSTM-CNNs-CRF. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; pp. 1064–1074. [Google Scholar]
- Rei, M.; Crichton GK, O.; Pyysalo, S. Attending to characters in neural sequence labeling models. In Proceedings of the COLING 2016, the 26th International Conference on Computational Linguistics, Osaka, Japan, 11–16 December 2016; pp. 309–318. [Google Scholar]
- Bharadwaj, A.; Mortensen, D.R.; Dyer, C.; Carbonell, J.G. Phonologically aware neural model for named entity recognition in low resource transfer settings. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; pp. 1462–1472. [Google Scholar]
- Peng, N.; Dredze, M. Named entity recognition for chinese social media with jointly trained embeddings. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 548–554. [Google Scholar]
- Peng, N.; Dredze, M. Improving named entity recognition for chinese social media with word segmentation representation learning. In Proceedings of the Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; pp. 149–155. [Google Scholar]
- Chen, X.; Qiu, X.; Zhu, C.; Liu, P.; Huang, X.J. Long short-term memory neural networks for chinese word segmentation. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 1197–1206. [Google Scholar]
- Zhang, Q.; Qian, J.; Guo, Y.; Zhou, Y.; Huang, X.J. Generating Abbreviations for Chinese Named Entities Using Recurrent Neural Network with Dynamic Dictionary. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; pp. 721–730. [Google Scholar]
- Dong, C.; Zhang, J.; Zong, C.; Hattori, M.; Di, H. Character-Based LSTM-CRF with Radical-Level Features for Chinese Named Entity Recognition. In Proceedings of the International Conference on Computer Processing of Oriental Languages National CCF Conference on Natural Language Processing and Chinese Computing, Kunming, China, 2–6 December 2016; pp. 239–250. [Google Scholar]
- Ni, J.; Florian, R. Improving Multilingual Named Entity Recognition with Wikipedia Entity Type Mapping. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; pp. 1275–1284. [Google Scholar]
- Nguyen, T.H.; Grishman, R. Relation extraction: Perspective from convolutional neural networks. In Proceedings of the 1st Workshop on Vector Space Modeling for Natural Language Processing, Denver, CO, USA, 5 June 2015; pp. 39–48. [Google Scholar]
- Santos, C.N.; Xiang, B.; Zhou, B. Classifying relations by ranking with convolutional neural networks. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing, Beijing, China, 26–31 July 2015; Volume 1, pp. 626–634. [Google Scholar]
- Xu, Y.; Mou, L.; Li, G.; Chen, Y.; Peng, H.; Jin, Z. Classifying Relations via Long Short Term Memory Networks along Shortest Dependency Paths. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 1785–1794. [Google Scholar]
- Cai, R.; Zhang, X.; Wang, H. Bidirectional recurrent convolutional neural network for relation classification. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; Volume 1, pp. 756–765. [Google Scholar]
- Zhou, P.; Shi, W.; Tian, J.; Qi, Z.; Li, B.; Hao, H.; Xu, B. Attention-based bidirectional long short-term memory networks for relation classification. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; Volume 2, pp. 207–212. [Google Scholar]
- Wang, L.; Cao, Z.; De Melo, G.; Liu, Z. Relation classification via Multilevel-Attention cnns. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; Volume 1, pp. 1298–1307. [Google Scholar]
- Zeng, D.; Liu, K.; Chen, Y.; Zhao, J. Distant supervision for relation extraction via piecewise convolutional neural networks. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 1753–1762. [Google Scholar]
- Miwa, M.; Bansal, M. End-to-end relation extraction using lstms on sequences and tree structures. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; pp. 1105–1116. [Google Scholar]
- Zheng, S.; Hao, Y.; Lu, D.; Bao, H.; Xu, J.; Hao, H.; Xu, B. Joint entity and relation ex- traction based on a hybrid neural network. Neurocomputing 2017, 257, 59–66. [Google Scholar] [CrossRef]
- Zheng, S.; Wang, F.; Bao, H.; Hao, Y.; Zhou, P.; Xu, B. Joint Extraction of Entities and Relations Based on a Novel Tagging Scheme. In Proceedings of the 55th annual meeting of the association for computational linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; pp. 1227–1236. [Google Scholar]
- Xu, J.; Wen, J.; Sun, X.; Su, Q. A Discourse-Level Named Entity Recognition and Relation Extraction Dataset for Chinese Literature Text. arXiv 2017, arXiv:1711.07010. [Google Scholar]
- Wen, J.; Sun, X.; Ren, X.; Su, Q. Structure Regularized Neural Network for Entity Relation Classification for Chinese Literature Text. arXiv 2018, arXiv:1803.05662. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Word | 广 | 州 | 是 | 广 | 东 | 的 | 省 | 会 | . |
|---|---|---|---|---|---|---|---|---|---|
| Feature pos1 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| Feature pos2 | 3 | 2 | 1 | 0 | −1 | −2 | −3 | −4 | −5 |
| Category | Example | Quantity | Ratio |
|---|---|---|---|
| Thing | Apple | 56,940 | 35.6% |
| Person | Li Qiu | 52,265 | 32.7% |
| Location | Paris | 27,442 | 17.2% |
| Time | One Day | 11,757 | 7.4% |
| Metric | One Liter | 5818 | 3.6% |
| Organization | Guerrillas | 3275 | 2.0% |
| Category | Example | Quantity | Ratio |
|---|---|---|---|
| Located | Youlan valley-Valley | 5730 | 39.5% |
| Part–Whole | Hongkong-China | 3254 | 22.4% |
| Family | Liu Pi-Liu Bei | 1395 | 9.6% |
| General–Special | Fish-Sole | 949 | 6.5% |
| Social | Mother-Neighborhood | 884 | 6.1% |
| Ownership | Village-villager | 838 | 5.8% |
| Use | Grandpa-quill | 697 | 4.8% |
| Create | Ba Jin-Home | 383 | 2.6% |
| Near | Fo Shan-Guang Zhou | 371 | 2.6% |
| Parameter | Value |
|---|---|
| epoch | 100 |
| batch size | 32 |
| learning rate | 0.001 |
| L2 regularization | 0.0001 |
| dropout rate | 0.5 |
| optimizer | AdaDelta |
| Chinese character embedding size | 200 |
| stroke num embedding size | 5 |
| stroke sequence LSTM output size | 10 |
| LSTM embedding size | 200 |
| entity relative position embedding size | 5 |
| entity type embedding size | 5 |
| L | 50 |
| embedding initializer | Xavier |
| Model | Indicator | Thing | Person | Location | Organization | Time | Metric | All |
|---|---|---|---|---|---|---|---|---|
| P | 67.07 | 80.30 | 58.09 | 0 | 64.47 | 46.15 | 70.52 | |
| BiLSTM [28] | R | 62.37 | 78.50 | 46.79 | 0 | 45.51 | 22.18 | 62.36 |
| F | 64.63 | 79.39 | 51.83 | 0 | 53.36 | 29.96 | 66.19 | |
| P | 75.72 | 87.92 | 68.41 | 46.69 | 76.20 | 70.50 | 77.72 | |
| CRF [28] | R | 65.42 | 82.27 | 50.98 | 45.26 | 60.93 | 38.42 | 65.91 |
| F | 70.19 | 85.00 | 58.42 | 45.96 | 67.72 | 49.74 | 71.33 | |
| P | 71.96 | 87.04 | 60.4 | 55.20 | 67.52 | 52.77 | 74.79 | |
| BiLSTM-CRF [8] | R | 69.05 | 86.99 | 60.13 | 28.40 | 61.10 | 47.04 | 72.84 |
| F | 70.48 | 87.01 | 60.26 | 37.50 | 64.15 | 49.74 | 73.80 (+2.47) | |
| P | 64.89 | 84.46 | 63.44 | 47.22 | 73.85 | 66.44 | 72.99 | |
| BiLSTM-Encoder-Decoder [26] | R | 72.49 | 88.06 | 56.35 | 27.28 | 56.80 | 32.57 | 73.37 |
| F | 68.48 | 86.23 | 59.69 | 35.14 | 64.21 | 43.71 | 73.18 (+1.85) | |
| P | 70.62 | 86.15 | 62.61 | 51.13 | 72.66 | 59.91 | 75.30 | |
| BiLSTM-Self-Attention-CRF | R | 70.80 | 89.16 | 59.15 | 27.98 | 54.03 | 43.75 | 74.10 |
| F | 70.71 | 87.63 | 60.83 | 36.17 | 61.98 | 50.57 | 74.51 (+3.18) | |
| P | 70.51 | 85.85 | 62.82 | 51.01 | 72.81 | 59.75 | 75.12 | |
| NER RE joint learning | R | 70.98 | 89.51 | 59.01 | 28.55 | 53.79 | 44.23 | 74.30 |
| F | 70.75 | 87.63 | 60.82 | 36.57 | 61.86 | 50.80 | 74.53 (+3.20) |
| Model | Feature | F1 |
|---|---|---|
| SVM | Word embeddings, NER, WordNet, HowNet, POS, dependency parse, Google n-gram | 48.9 |
| RNN | Word embeddings + POS, NER, WordNet | 48.3 49.1 |
| CNN | Word embeddings + word position embeddings,NER,WordNet | 47.6 52.4 |
| CR-CNN | Word embeddings + word position embeddings | 52.7 54.1 |
| SDP-LSTM | Word embeddings + POS,NER,WordNet | 54.9 55.3 |
| DepNN | Word embeddings, WordNet | 55.2 |
| BRCNN | Word embeddings + POS, NER, WordNet | 55.0 55.6 |
| SR-BRCNN | Word embeddings + POS, NER, WordNet | 65.2 65.9 |
| BiLSTM-Attention | Word embeddings | 64.6 |
| BiLSTM-Multilevel-Attention | Word embeddings + stroke embeddings | 73.3 (+7.4) 73.6 (+7.7) |
| NER RE joint learning | Word embeddings + stroke embeddings | 78.8 (+12.9) 79.2 (+13.3) |
| L | 5 | 10 | 30 | 50 | 70 | 100 | 200 |
|---|---|---|---|---|---|---|---|
| F1 | 71.3 | 71.5 | 73.1 | 73.6 | 72.7 | 71.9 | 70.3 |
| Feature | Word Embeddings | +Relative Position | +Entity Type | +Stroke Embeddings | +All |
|---|---|---|---|---|---|
| F1 | 67.4 | 69.8 (+2.4) | 71.4 (+4.0) | 67.9 (+0.5) | 73.6 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liang, L.-X.; Lin, L.; Lin, E.; Wen, W.-S.; Huang, G.-Y. A Joint Learning Model to Extract Entities and Relations for Chinese Literature Based on Self-Attention. Mathematics 2022, 10, 2216. https://doi.org/10.3390/math10132216
Liang L-X, Lin L, Lin E, Wen W-S, Huang G-Y. A Joint Learning Model to Extract Entities and Relations for Chinese Literature Based on Self-Attention. Mathematics. 2022; 10(13):2216. https://doi.org/10.3390/math10132216
Chicago/Turabian StyleLiang, Li-Xin, Lin Lin, E Lin, Wu-Shao Wen, and Guo-Yan Huang. 2022. "A Joint Learning Model to Extract Entities and Relations for Chinese Literature Based on Self-Attention" Mathematics 10, no. 13: 2216. https://doi.org/10.3390/math10132216
APA StyleLiang, L.-X., Lin, L., Lin, E., Wen, W.-S., & Huang, G.-Y. (2022). A Joint Learning Model to Extract Entities and Relations for Chinese Literature Based on Self-Attention. Mathematics, 10(13), 2216. https://doi.org/10.3390/math10132216