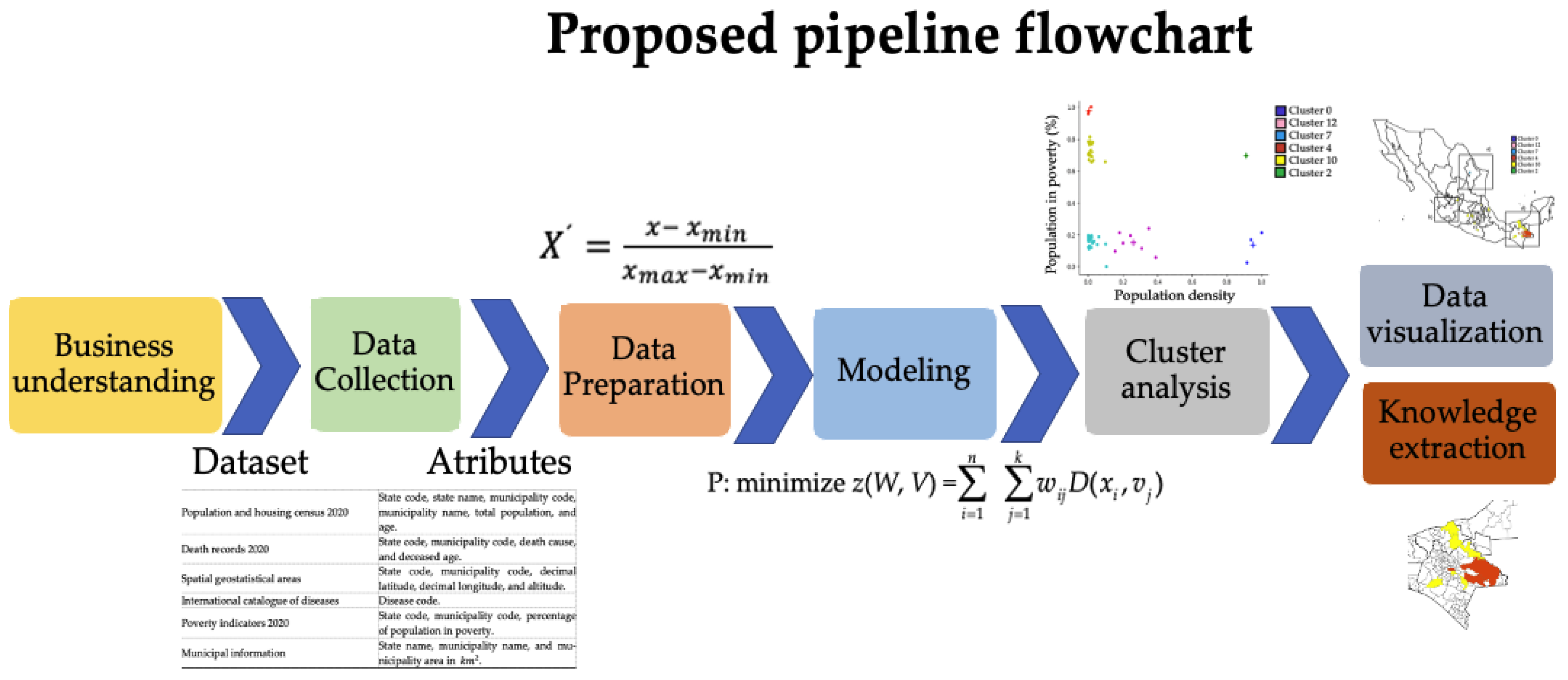
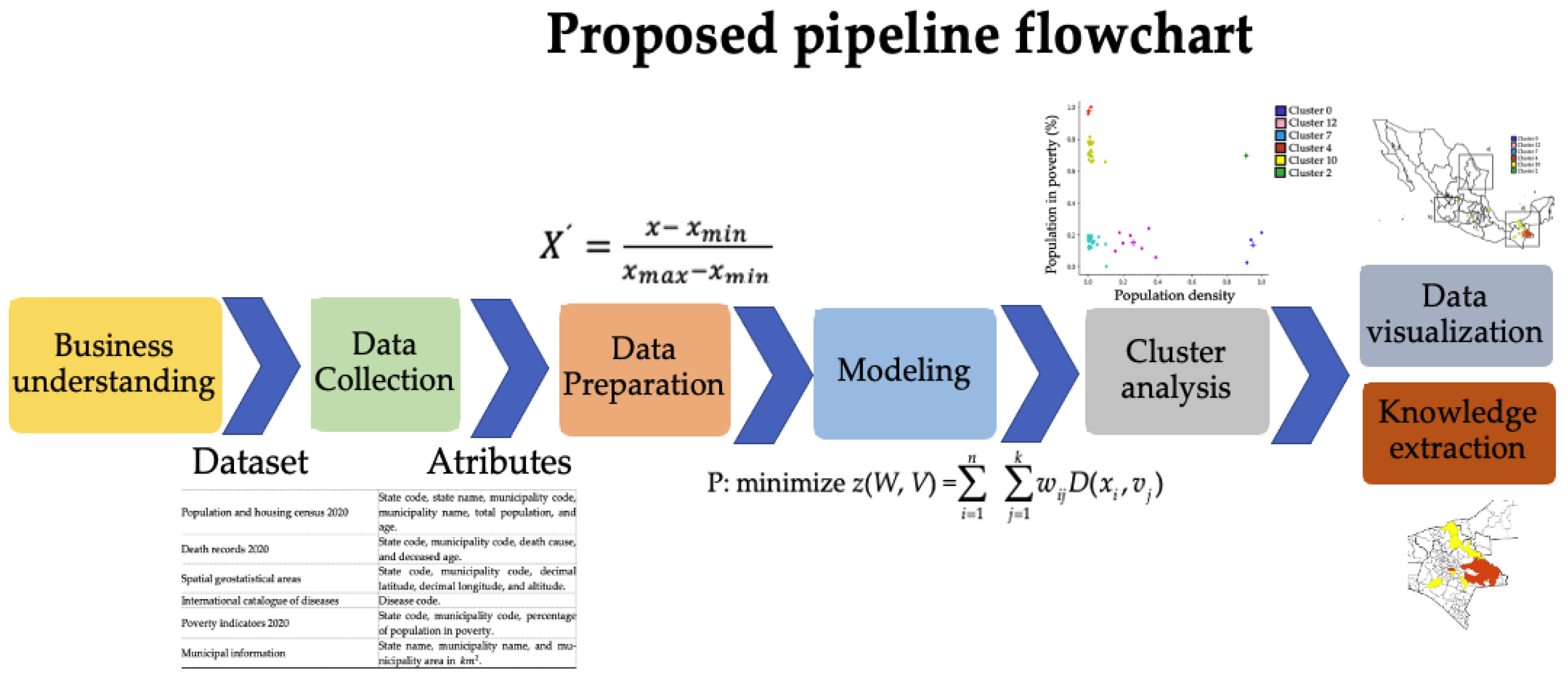
This section is divided into two subsections, the Results and the Discussion. The first shows the results of the Cluster analysis, Data visualization and Knowledge extraction tasks. In the second subsection, we contrast our results with other related research.
3.1. Results
In this subsection, the main results obtained from cluster analysis are described. Several clustering experiments were conducted using different configurations and attributes. For example, experiments were performed which included the latitude, longitude and altitude of municipalities; however, it was not found that they were determinant, so they were excluded. In particular, it was observed that population density and percentage of population in poverty were determinant for generating clusters whose elements had similar values of mortality rate for COVID-19.
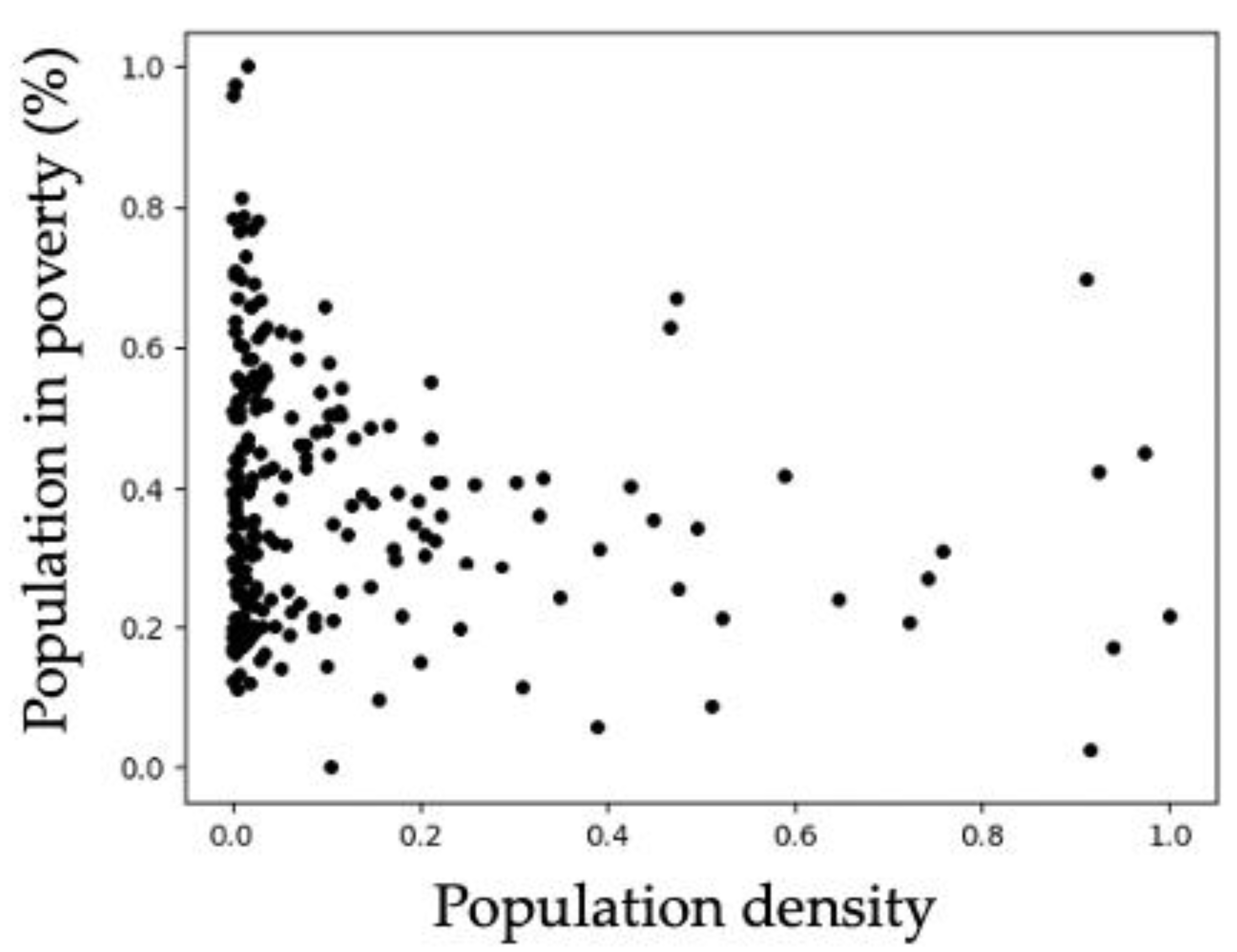
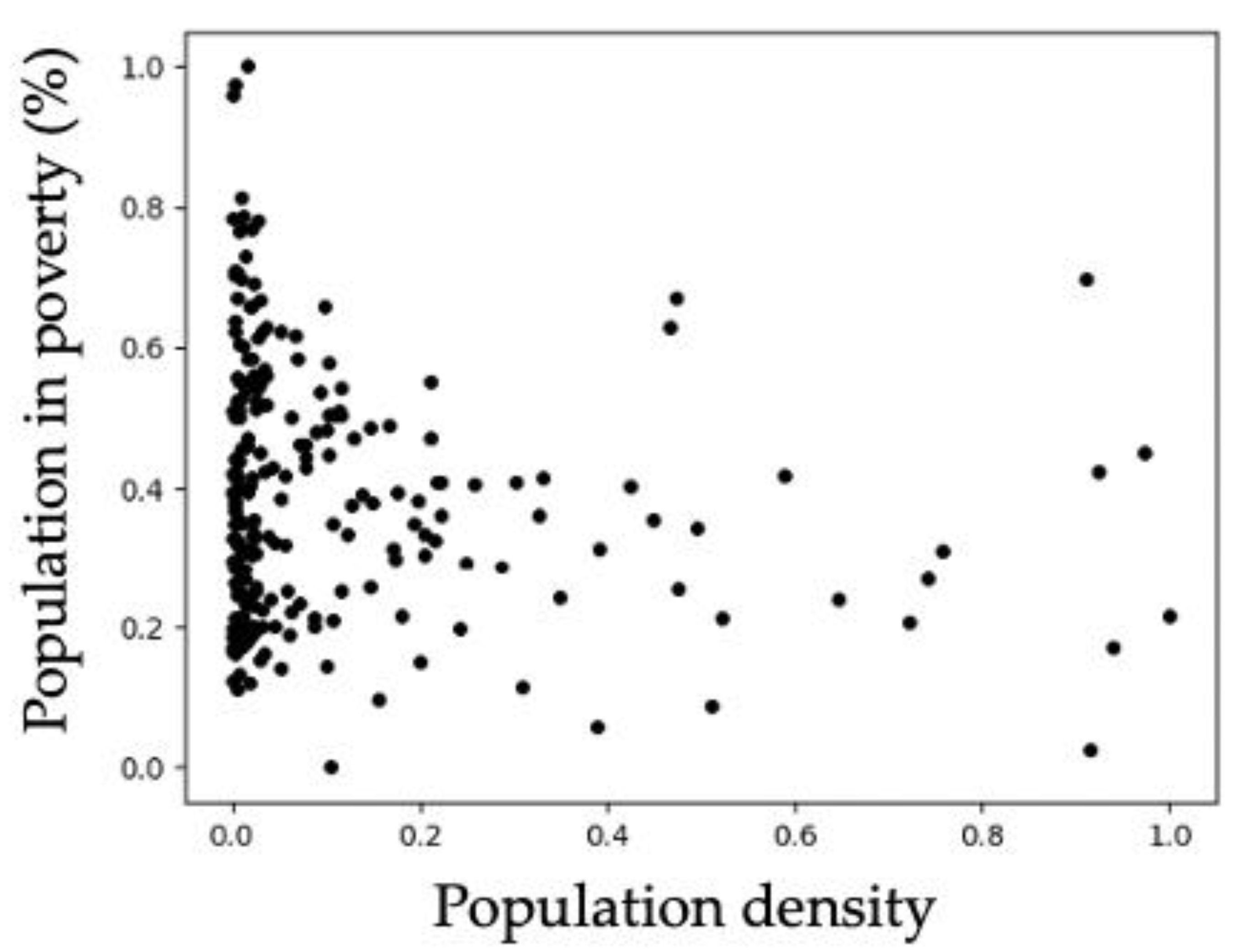
For visualizing the distribution of municipalities according to population density and poverty percentage, the graph of
Figure 2 was generated, which shows municipalities represented by dots. The values of the attributes are normalized in the range from 0 to 1. Notice that most of the dots have low values of population density. Additionally, the dots show that the values of poverty are more dispersed.
Table 4 shows the clustering results for 233 municipalities in a partition of 16 clusters. The first three rows correspond to the clusters with the highest mortality rates, and the last three rows correspond to the lowest mortality. These clusters are called
extreme clusters. The first column contains the cluster identifier, the second and third columns include the cluster centroids, which have population density and percentage of poverty as attributes. The fourth column shows the number of municipalities in each cluster, and the last column includes the average mortality rate of the municipalities in the cluster. The values of the last two columns were determined after the clustering.
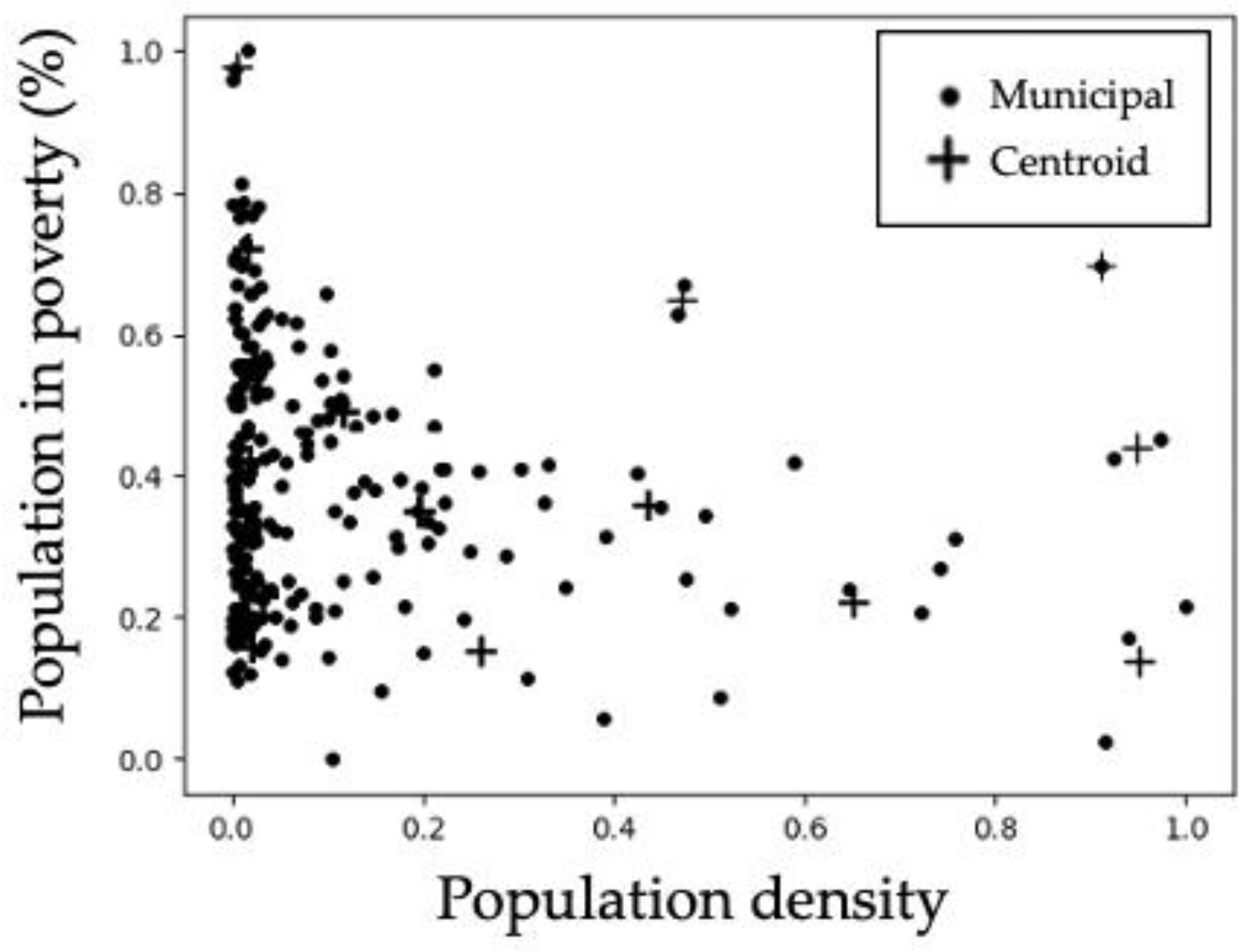
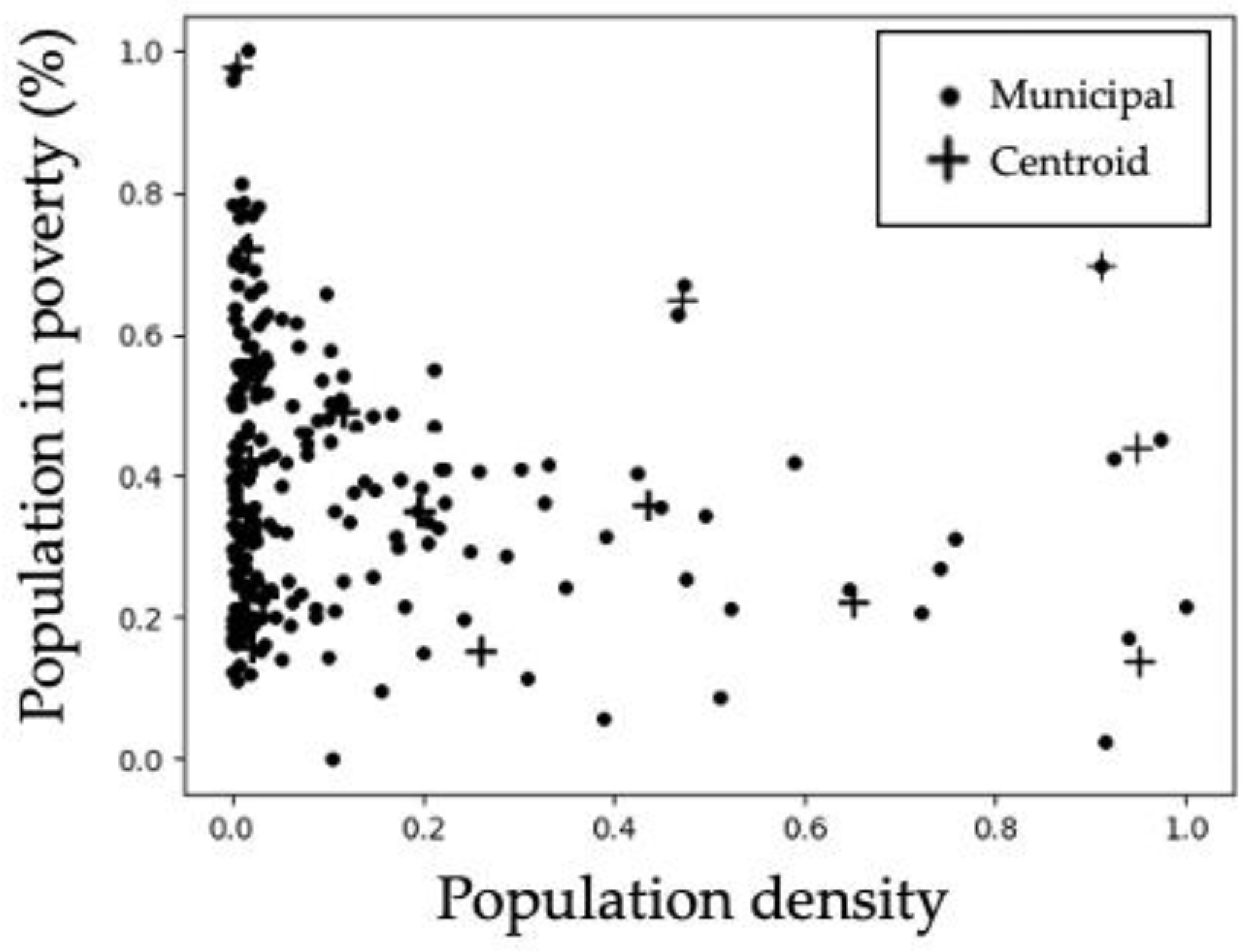
Figure 3 allows visualizing the distribution of the cluster centroids and the municipalities close to the centroids. Some of the centroids are overlapped in the areas of high dots density.
Table 5 includes only the extreme clusters (distinguished with colors) from
Table 4 for facilitating their identification.
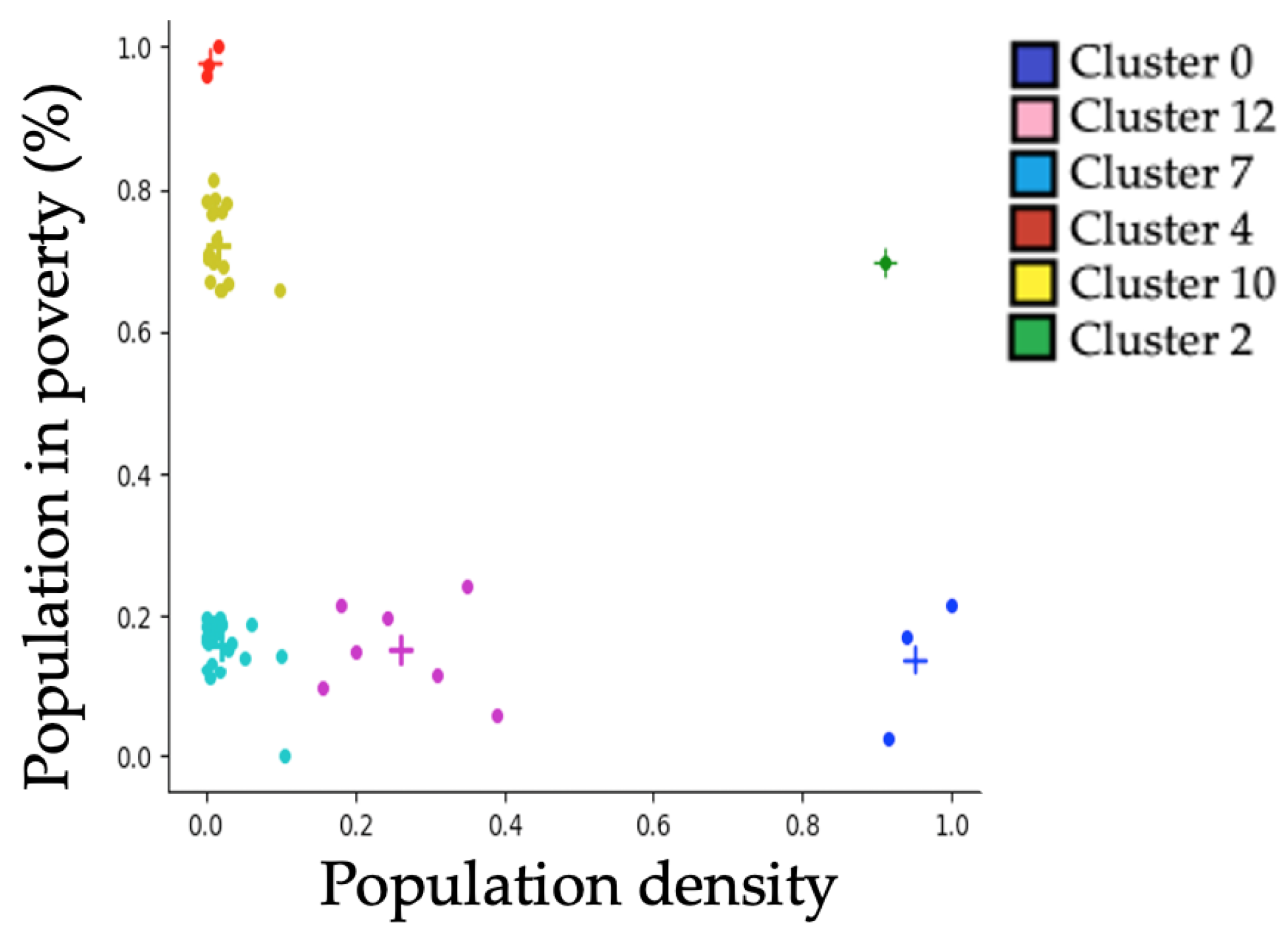
In order to visualize the distribution of municipalities in extreme clusters, the graph in
Figure 4 was generated, which shows municipalities represented by dots and cluster centroids denoted by crosses. The color of each dot corresponds to the color of the cluster of which the municipality is a member. It is worth mentioning that the cluster with the highest mortality rate lies in the lower right corner, while the cluster with the lowest mortality rate is in the upper left corner.
Table 6 shows the municipalities that are members of each of the following clusters: 0, 12, 7, 2, 10 and 4.
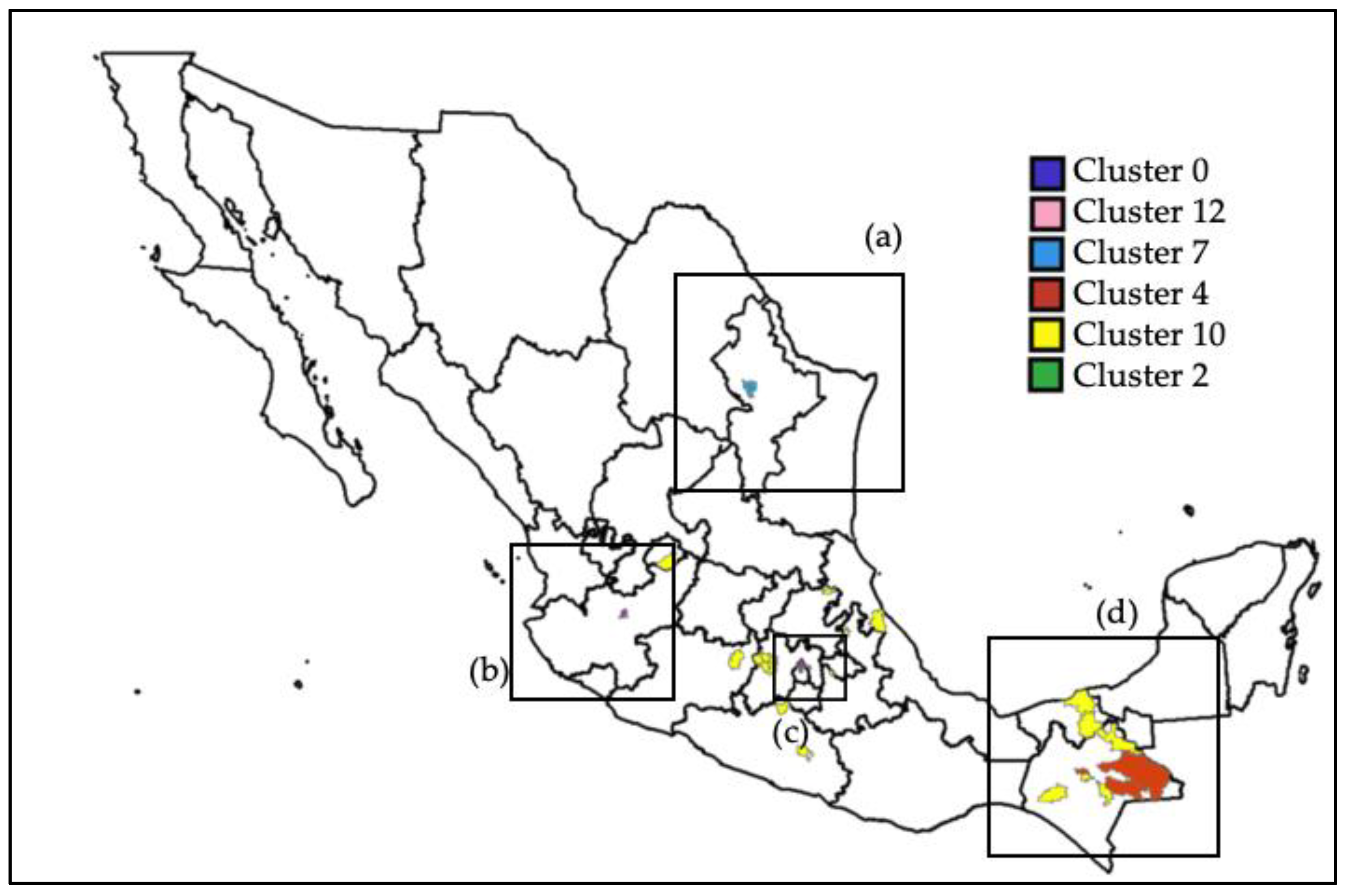
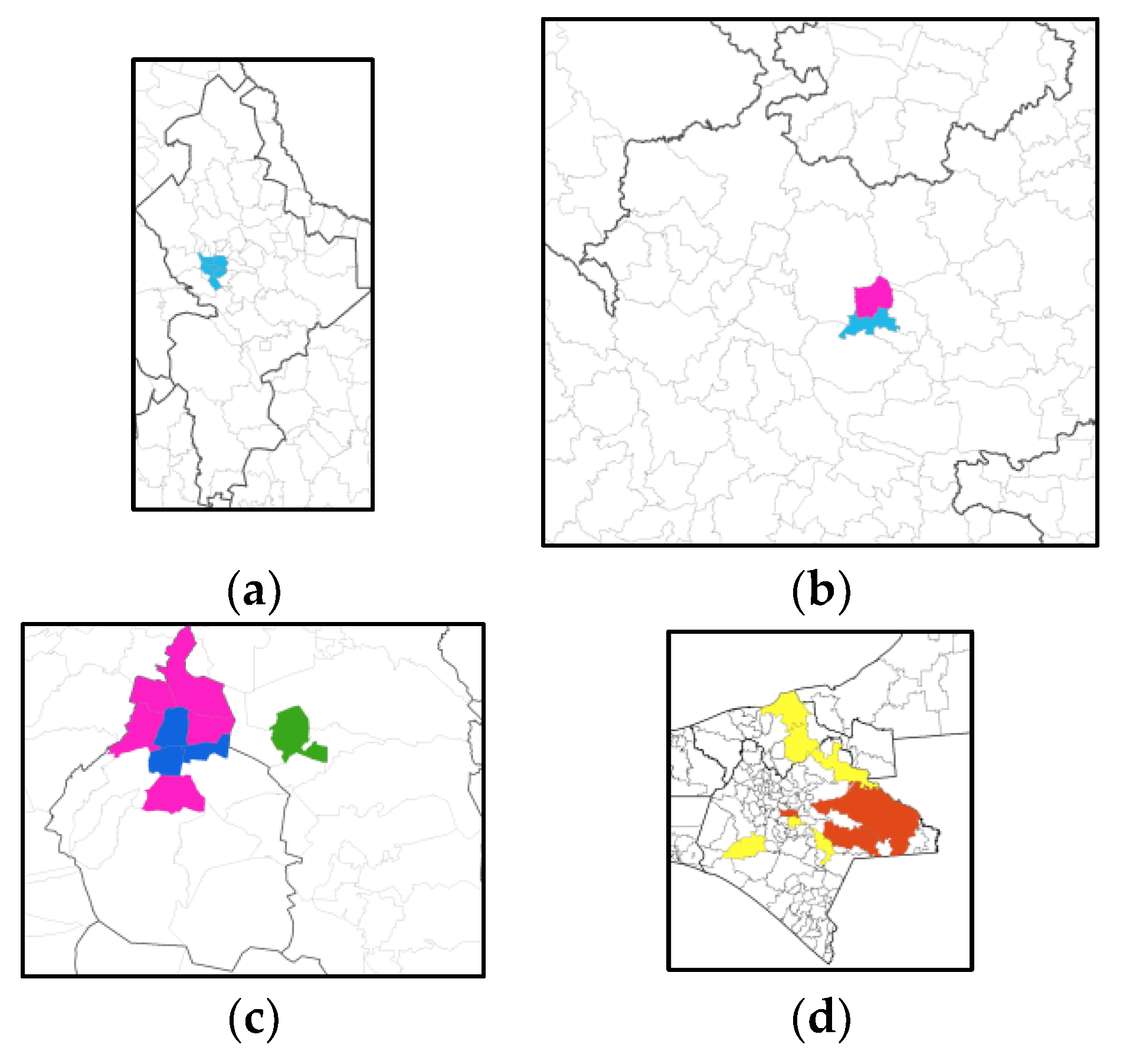
Figure 5 shows a map of Mexico where each municipality is highlighted according to the cluster where it is a member. Square (a) includes several municipalities of the state of Nuevo León; notice that these municipalities have high mortality values. Square (b) contains the municipality of Guadalajara, which also has a high mortality level. Square (c) comprises the three municipalities of the cluster with the highest mortality rates, the highest population densities and the lowest percentages of population in poverty. Notice the contrast to the municipalities in square (d), where those painted in orange are the ones in the cluster with the lowest mortality rate, the lowest population density and the highest percentage of population in poverty. Magnified reproductions of these squares are shown in
Figure 6.
3.2. Discussion
The results of this study, through a methodology that combines the most relevant aspects of epidemiology within a Data Science framework, provide valuable information on clustering of the COVID-19 mortality according to sociodemographic factors at the municipal level in Mexico. This allows us to characterize the shapes of COVID-19 mortality rate curves in different clusters that describe the geospatial variability in mortality rates.
Among the previous studies that have used clustering algorithms to analyze mortality data from COVID-19, as in our study, but for several countries, there is that of Cerqueti et al. 2022, in which the analysis of conglomerates of 35 countries was carried out selected based on new deaths per million COVID-19 data and using a K-means approach to clustering. In this study, the main determinants for the grouping between countries were the days with peak deaths, the stability of the number of victims and the waves of COVID-19 endured, which showed similarities and divergences between the countries described by the results of the procedure grouping [
21]. Gohari et al. propose a three-step approach to pool specific COVID-19 mortality trends for 203 countries and territories, and they consider a K-means pooling algorithm as well. As a relevant finding, they report that countries such as Germany, Greece, Canada, the Russian Federation, Ukraine, and Mexico apparently had more success in controlling the spread of the disease than in patient survival [
3].
Likewise, Garg et al. grouped 208 countries with similar values of risk factors for COVID-19 using an unsupervised machine learning model (K-means) and determined as shared risk factors in the countries grouped with the highest mortality rate by COVID-19, a high median age, as well as a high proportion of people over 65 years of age, a high gross domestic product (GDP) per capita, low population, greater population of women smokers, considerable number of hospital beds per 1000, and human development index [
22]. Cornelius et al. evaluated the prediction of COVID-19 patient mortality using demographics data in the United States through a machine learning approach. Clustering K-means allowed them to observe clear trends of minority older people in the northeast and south who are at elevated risk of COVID-19 mortality and to rank the severity of outcome for COVID-19 patients [
23].
Another study conducted by Vahabi et al. evaluated the growth trajectories of the COVID-19 mortality/incidence ratio and found contiguous United States county-level clusters with similarities over time. In this study, cardiac complications and cancer were statistically significant pre-existing comorbidities related to the mortality/incidence ratio of COVID-19 in the United States. Tuberculosis, drug use disorder, Human Immunodeficiency Virus (HIV)/Acquired Immunodeficiency Syndrome (AIDS), diabetes and hepatitis were explicitly associated with a higher probability of being in the most vulnerable group [
24].
In the Latin American context, Martin-Barreiro et al. 2021 used disjoint and functional principal components analysis to classify ten South American countries (Argentina, Bolivia, Brazil, Chile, Colombia, Ecuador, Peru, Paraguay, Uruguay and Venezuela) with respect to the number of infected and deaths due to COVID-19. In addition, they designed an algorithm that allows summarizing the multivariate methods used to detect changes in the data using a sensor and thus have an updated analysis. Finally, they carried out an analysis of alternating clusters of k-means for the formation of groups within the countries, highlighting more reliable results with the analysis of principal components [
25].
The research question that was formulated in this study was the following: what sociodemographic factors do the Mexican municipalities with similar mortality rates have in common? One of the remarkable results of the study was uncovering that the indicators of population density and percentage of population in poverty are related to the mortality rates for COVID-19 at the municipal level. Because such indicators are constituted by other factors, they allowed us to indirectly measure other variables. For example, high population density is associated with factors such as mobility in mass transport systems such as subways and commuter trains, among others. It was observed that there exists a high direct correlation between mortality rate and percentage of population density. However, an inverse correlation was found between mortality rate and percentage of population in poverty.
This relationship between COVID-19 mortality rates and low percentage of poor was recently reported by Yao et al., where they found higher COVID-19 mortality rates in high-income or developed countries associated with multiple factors, including transportation, population density and population aging [
55]. Similarly, the direct correlation between mortality rate and population density found in the present study is supported by Chang et al., who show that population density has a significantly positive effect on confirmed deaths, confirming that this demographic factor plays a facilitating role in the speed of spread of the virus [
56].
Our findings are backed by previous national and international studies that have found geographic clusters of infections, hospitalizations and deaths from COVID-19 [
57,
58,
59,
60].
Individual risk factors or a combination, such as a high population density and a high proportion of vulnerable population, may influence the spatial clustering of people infected with COVID-19, which increases the risk in close neighboring municipalities [
10,
61]. Similarly, the mobility of residents in very densely populated areas may facilitate the introduction, propagation and persistence of COVID-19. Thus, it has been reported that population density might be an indicator of a high rate of contact due to mobility rather than physical proximity [
62].
In the context of Mexico, similar findings have been reported in previous studies in relation to the association between higher mortality rates for COVID-19 and higher population density and overcrowding conditions. Ríos et al. found that patients lived in municipalities with the highest overcrowding had a higher risk of dying from COVID-19 as compared to those who lived in a municipality with low overcrowding [
63]. Likewise, Contreras et al. and Villa et al. reported population density as a factor associated to higher mortality rates and adverse results for COVID-19, respectively [
64,
65].
Initially in Mexico, the propagation of COVID-19 started among people of a high socioeconomic level that live in the most developed municipalities of the country. Considering that the hospital and diagnosis infrastructure is concentrated in large cities, therefore, records of positive diagnosis and access to hospital treatment and death from COVID-19 at hospitals were more prevalent in municipalities with a high-income level. In agreement, a study where the level of social deprivation was evaluated which estimates social disadvantage and structural inequality at the municipal level based on census data found a rural–urban dissociation of factors that affecting mortality from COVID-19 in Mexico.
In contrast to what was found in the previous study, as the pandemic evolved, some studies have documented that living in municipalities with overcrowding conditions is associated with a higher risk of mortality from COVID-19 in the Mexican adult population. Similarly, Arce et al. in 2022 mentioned that those with lower income levels had four times more probability of being hospitalized and undergo a more serious disease than wealthier people.
Other studies that have aimed at evaluating the spatial distribution by clusters of mortality from COVID-19 and associated factors in Mexico have used excess mortality data, which include deaths from all the causes directly or indirectly related to the pandemic. Additionally, the estimation was performed with data reported up to April 2020, thus finding that population density was a factor associated with higher mortality from COVID-19. Specifically, the latter study reports findings similar to the present study regarding the unexpected association of lower mortality rates and municipalities with high poverty rates in the state of Chiapas.
Our study has strengths and limitations. Its main strength is the use of a new hybrid clustering algorithm as a useful tool in the analysis of groups of municipalities with similar mortality rates and sociodemographic factors. A key contribution of this work is that it is the first study in Mexico where the analysis of mortality is conducted at the municipal level and algorithms are used to group by similarity in sociodemographic factors, which is relevant given that in our study, we show that even municipalities in the same state can have very different values of mortality rates from COVID-19. In addition to the fact that due to the lag in the availability of official mortality data in Mexico, there are few studies based on COVID-19 death records, most of the studies with data from the year 2020 come from COVID-19 tests.
The main limitation of this study is the use of data collected from COVID-19 death records, since the database was reviewed and validated only by the Mexican Ministry of Health. Finally, this study was conducted for the Mexican population, so caution should be applied in generalizing its results to other populations with a different demographic profile.


 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}