1. Introduction
Companies are finding it difficult to accurately forecast customer demand using traditional demand-forecasting approaches, preferring to employ data science approaches for demand-forecasting modeling due to the explosion of competition and information technology in the market [
1,
2]. Companies can use predictive analytics to respond to changes in future market trends to enhance their competitive advantage. Predictive analytics is a critical tool for understanding future needs. Since customer demand is the basis for all activity planning, it is time-varying. Thus, accurate demand forecasting will prevent stock-outs and increase customer satisfaction [
3].
In lean manufacturing, inventory is one of the significant wastes. Inventory is a major bottleneck in a company’s operating costs. Demand forecasting can reduce inventory, so establishing an accurate demand-forecasting system is a primary objective for enhancing competitiveness. Demand forecasting has been used in various fields, such as electricity demand forecasting [
4], tourism demand forecasting [
5,
6], restaurant demand forecasting [
7], oil production forecasting [
8], and stock market forecasting [
9]. Most of them can initially attain the expected accuracy using statistical approaches or machine learning models, but after some time, they fail to generate the expected answers due to over-reliance on time. The most crucial aspect of forecasting is to respond effectively to trends, and managers focus on continually reducing the error between forecast and actual values. To enhance forecast accuracy, the development of models overtime is necessary. Thus, rolling forecasts are crucial steps to facilitate model correction. The error in the rolling prediction increases with the number of prediction steps due to white noise in the time series, causing the prediction to deteriorate with the number of steps. The error compensation approach employs historical forecast error to correct the future forecast values based on multi-step forecasting to compensate for each forecasted error value [
10]. Furthermore, the air quality index (AQI) indicator only provides current forecasts and cannot provide valid values for those who will be outdoors in the next few hours. Liang et al. proposed a rolling AQI prediction model for the next 6 h for seven air quality regions in Taiwan using characteristic curves [
11]. The mean absolute normalized coarse-error margins for rolling forecasts are all below 9%. The results demonstrate that a rolling forecast model that is built using the monthly characteristic curve can produce highly accurate forecasts.
The COVID-19 pandemic has triggered a global public health crisis, forcing many to work from home [
12]. In this globally connected world, every country will be affected by the disruption that has been caused by the pandemic. This has led to total lockdowns in many countries around the world. In this case, all business activities in all industries have come to a complete halt. With social restrictions and closing city gates to prevent the epidemic spread of the virus, companies have launched strategies such as remote office working and video conferencing [
13]. Therefore, the demand for notebook computers and tablet computers has also increased.
Integrated circuit (IC) trays have a protective effect on electronic products’ packaging. During packaging and testing, the IC components are placed in trays and then placed into test machines for testing. IC trays are one of the indispensable materials for precision parts IC components packaging tools, as well as a necessity for packaging and testing. The demand for plastic IC trays has grown with the electronics industry’s development [
14]. In addition to supply and demand factors, the price of plastic raw materials is closely related to oil. COVID-19, supply–demand imbalances, and volatility in international financial markets are all associated with global oil demand, as is the collapse in the industrial feedstock oil’s price. However, price fluctuations can offer some gains or risks to the economies in the relevant chain. The related relevant chain includes raw material for IC trays (modified polyphenylene oxide), as well as packaging and testing manufacturers. Therefore, the Organization of Petroleum Exporting Countries member countries and allies have met to negotiate production cuts to save oil prices. However, the breakdown of negotiations between Saudi Arabia and Russia increased oil volumes instead of decreasing them, causing an oil price war that brought oil prices to a new low, affecting the prices of plasticized products [
15]. If we can predict IC tray demand, we can purchase raw materials at low prices to reduce costs and increase profits, which becomes an advantage of low-price inventory and can react rapidly to market changes.
The demand for IC trays has been increasing due to various strategies adopted by various countries to combat the epidemic. The price of raw materials for producing IC trays has changed because of the unstable international situation arising from different external factors. Thus, if we know the demand for IC trays in advance, we can purchase the number of raw materials that are required to produce them in advance, in order to rapidly respond to the changes in market demand and maintain the competitiveness of our company. Manufacturers’ requirements for the accuracy of forecast results are increasing as information technology improves. Companies can reduce costs, increase profits, and enhance customer satisfaction by improving demand-forecasting accuracy. Thus, this study proposes an error compensation mechanism that captures nonlinear data with a rolling long short-term memory (LSTM) and then compensates for the residuals with the rolling autoregressive moving average (ARMA) model, which can only reduce the forecasting model’s maintenance cost and reduce the time for model correction and training.
2. Materials and Methods
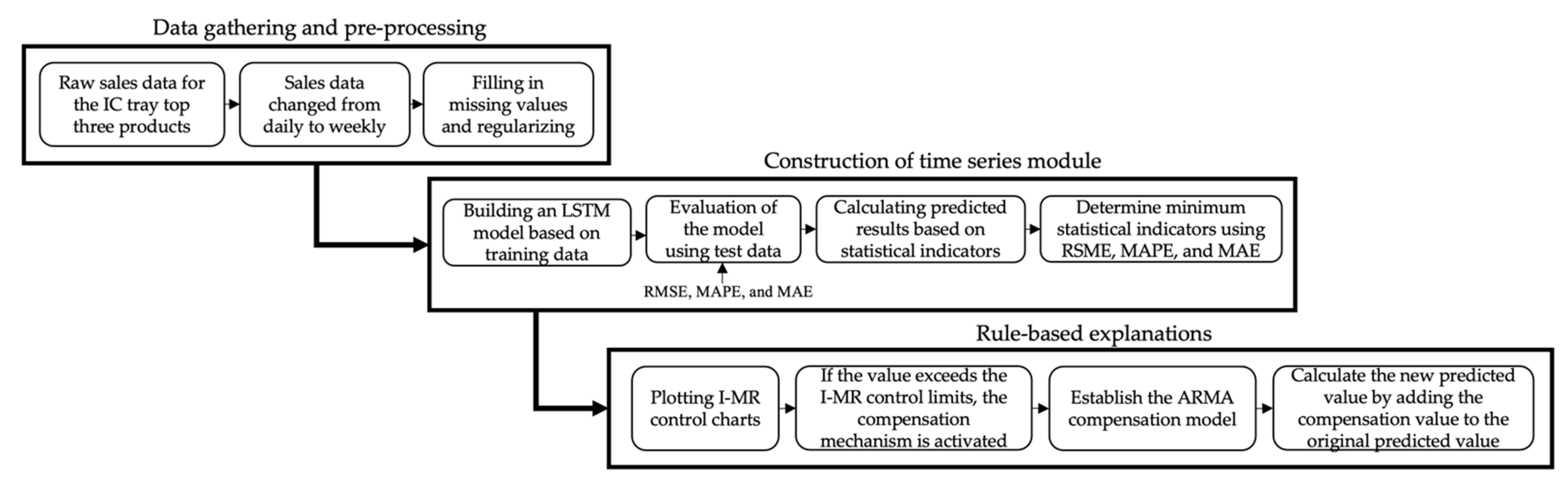
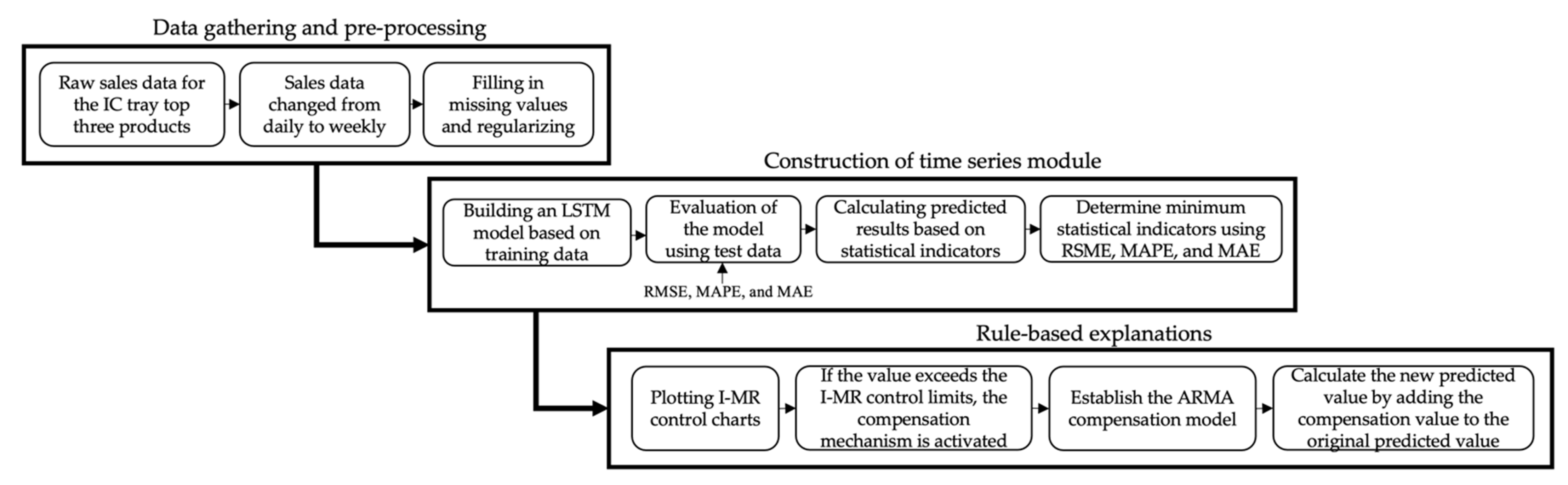
In this study, we propose a solution for an IC tray manufacturer’s data characteristics in Taiwan using industry–academia cooperation as an example, and verify the method’s feasibility. Recently, manufacturers of IC trays have been moving toward a less sample, more volume model, as customers’ requirements for IC shapes and sizes frequently change due to product diversification. The IC tray industry’s service characteristics emphasize order acceptance and speed of delivery, resulting in shorter production times. To reduce demand uncertainty’s impact and risk caused by market fluctuations, a systematic and highly accurate demand-forecasting model to assist in decision-making is urgently needed. The flowchart shown in
Figure 1 was designed to include data gathering and pre-processing, the construction of a time series module, and rule-based explanations.
2.1. Data Collection and Preprocessing
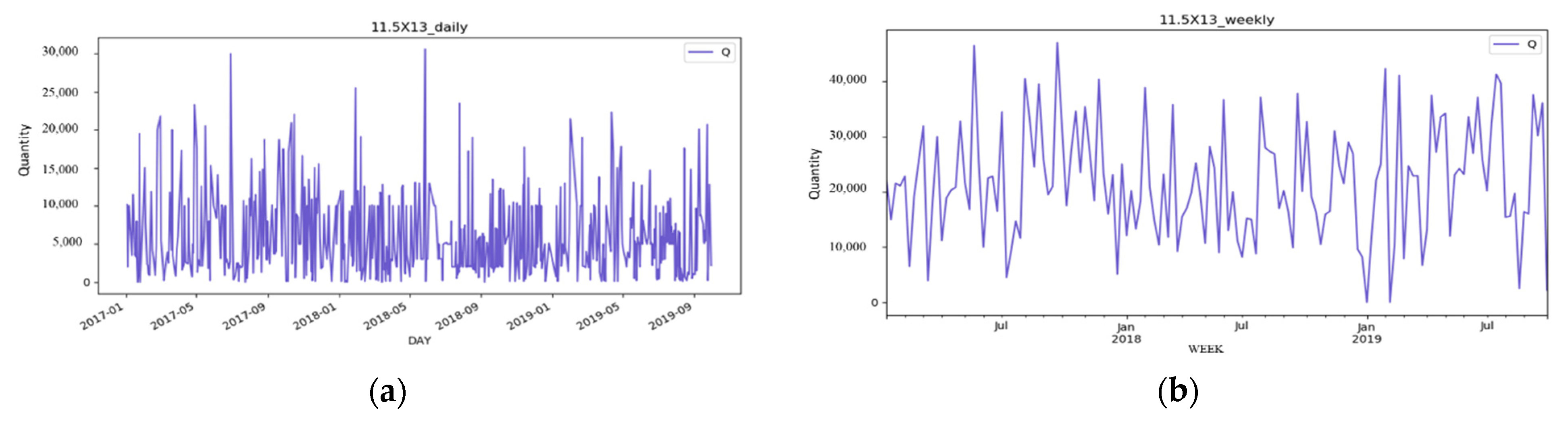
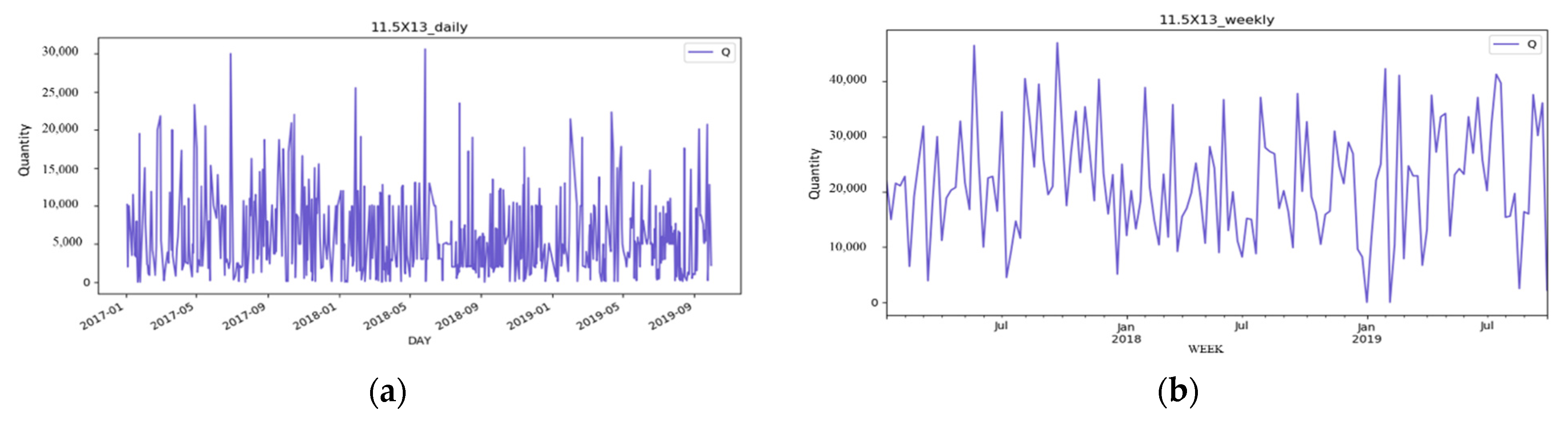
Based on the top three products offered by Industry–Academy Cooperation from 1 January 2017 to 29 September 2019, the proposed approach was validated. Time series are continuous data, and the approach of adding zeros is employed to deal with missing values in this study. The main reason is that, from a practical perspective, missing values show that no products were sold on that day, and the system does not record what caused the missing values. Since the case company calculates sales data every day, IC trays calculate material purchases every week. This study converts data measurement frequency from daily to weekly to forecast raw material demand.
Figure 2 shows the BGA 11.5X13 product converted from daily to weekly units.
2.2. Long Short-Term Memory Rolling Algorithm
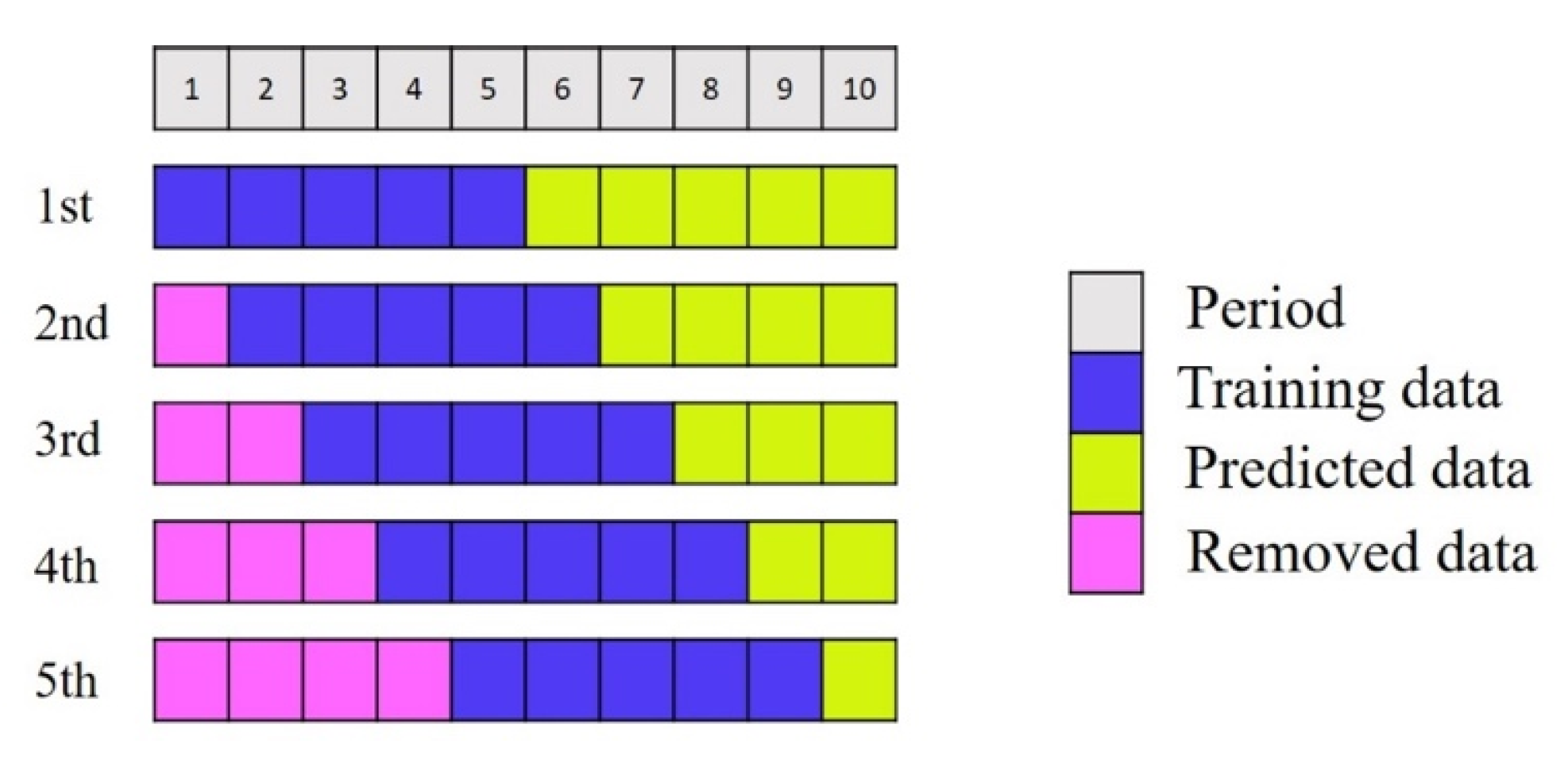
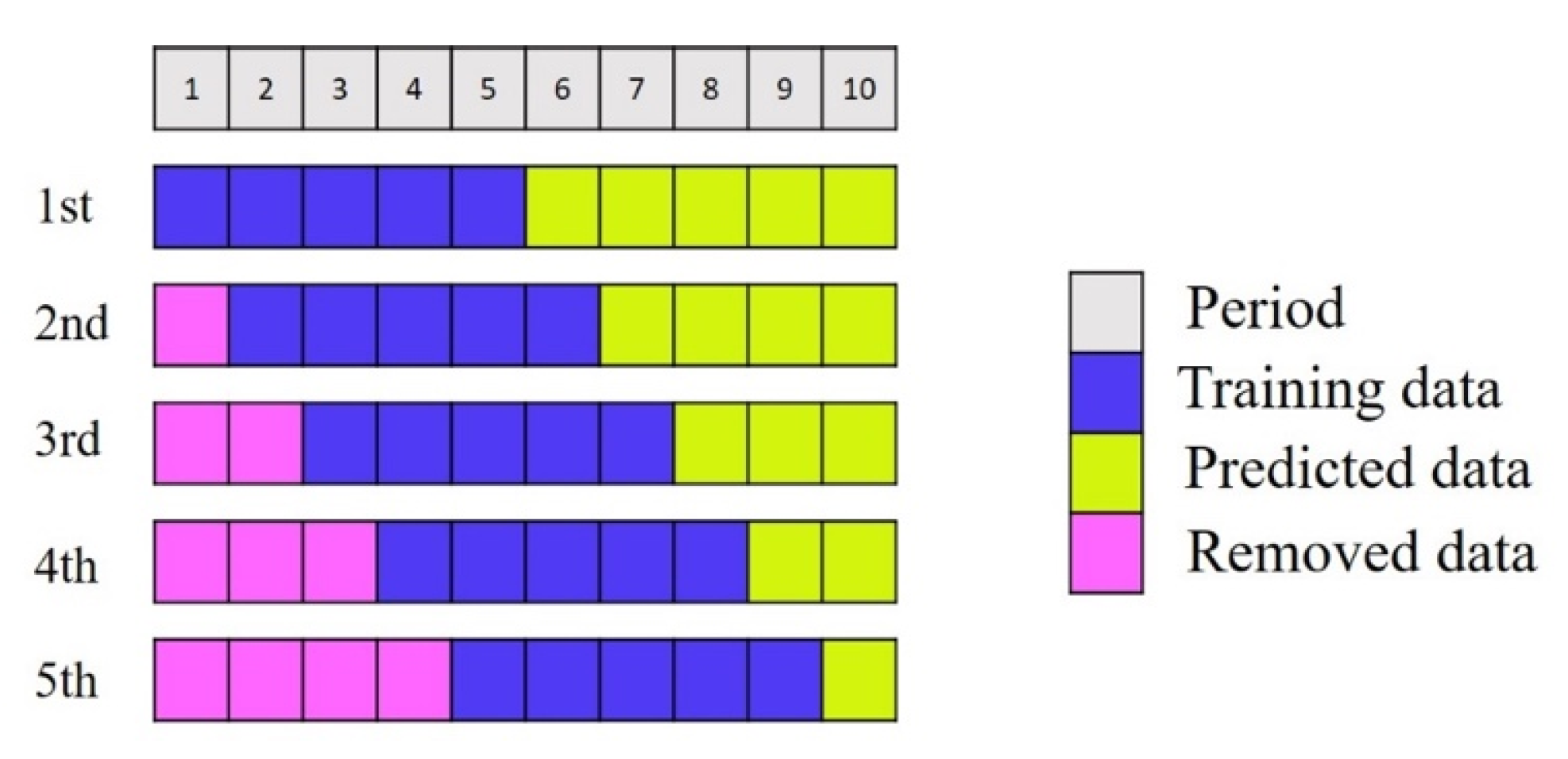
Rolling forecasts are a type of dynamic forecasting. The main idea of this method is to add new data and delete old data simultaneously in a rolling manner while maintaining the length of the data. Forecasting results become more accurate through continuous learning, correction, and adjustment. The forecasting capability of an enterprise is thus enhanced so that it can respond promptly to customer needs [
16].
Figure 3 illustrates a rolling forecasting process.
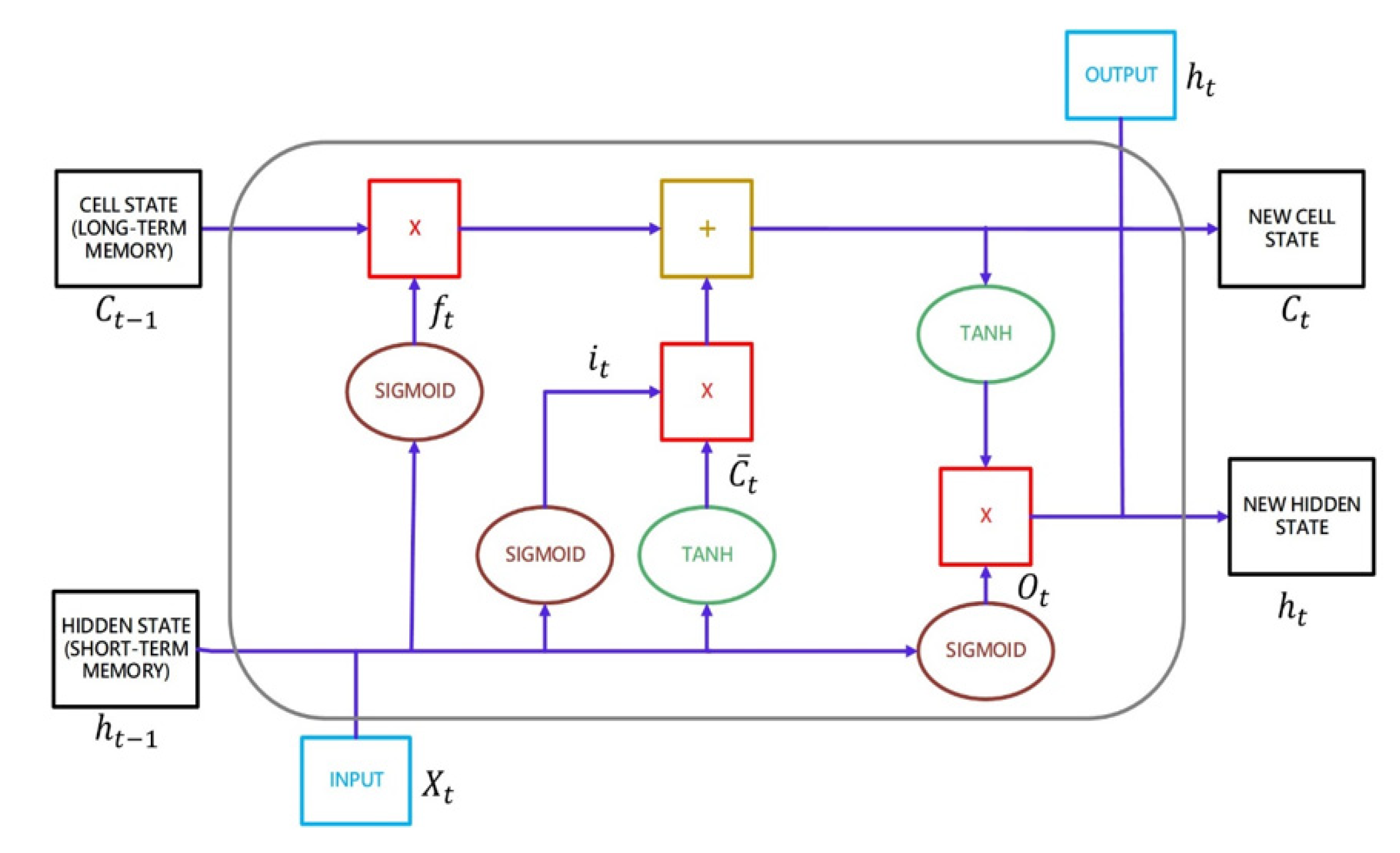
In 1997, Hochreiter proposed LSTM, a neural network model that solves the vanishing gradient problem for time series data [
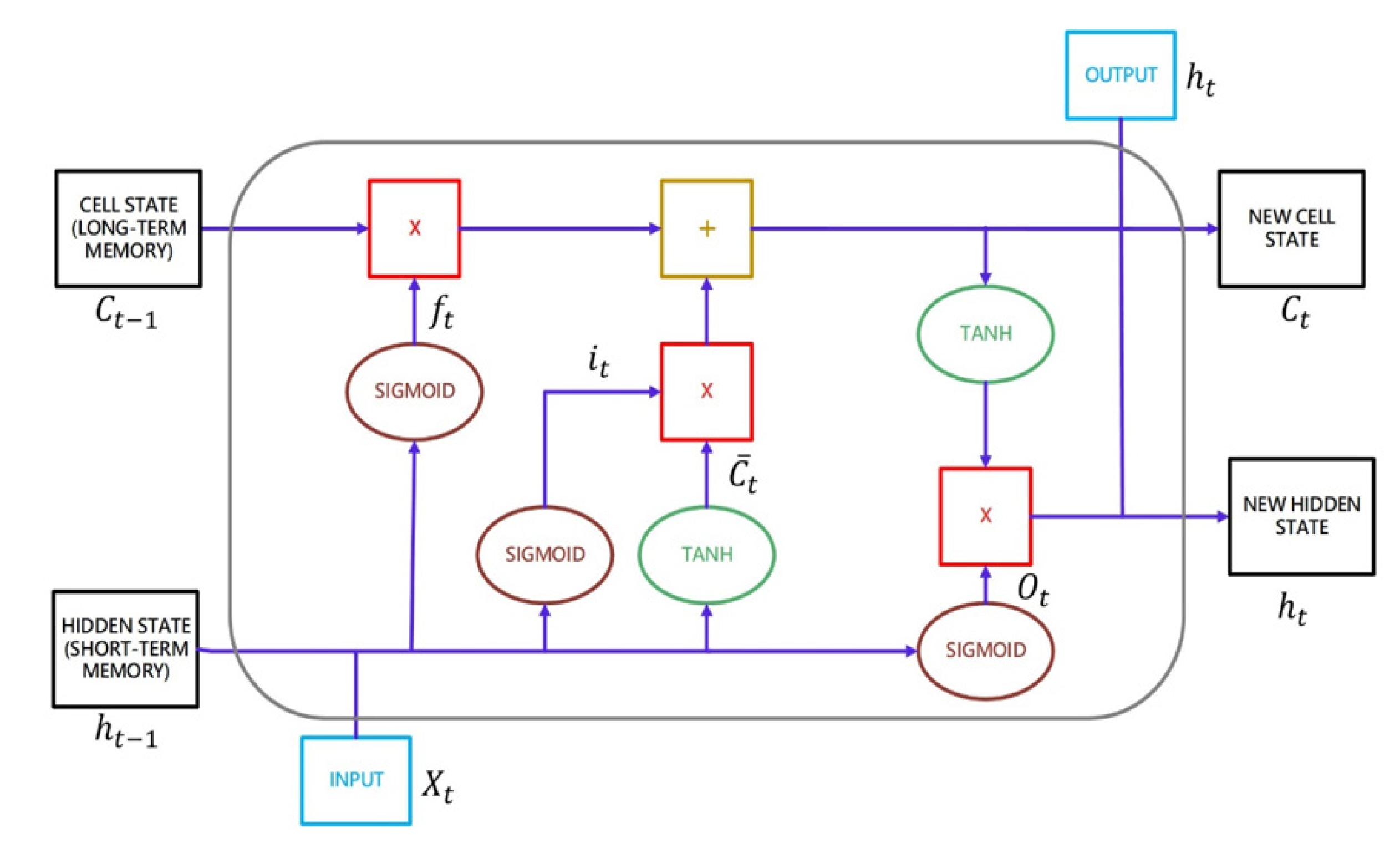
17]. LSTM regulates information flow, passes relevant information, and forecasts outcomes based on the incoming information. The previous hidden state is passed on to the next unit through the tanh activation function during the operation. A neural network’s hidden state acts as its memory, storing data it has seen in the past. A gate (forgetting, input, and output gates) allows the unit to decide whether to retain or delete information before passing it on to the next unit.
Figure 4 shows the LSTM structure. The LSTM’s core, including input, output, and forgetting gates, is described below [
18].
Forgetting gate: Based on the weights and the current input, the sigmoid function calculates a value
between 0 and 1, determining which data will be retained and forgotten. Forgetting the data implies that they have been permanently removed from long-term memory. The forgetting gate’s equation is as follows:
where σ is the sigmoid function, ∙ is the dot product,
is a vector of input data,
is the forgetting-gate weight, and
is the forgetting-gate bias vector.
Input gate: Given the weight, hidden state, and current input, the sigmoid function calculates
, a value between 0 and 1. This value is between 0 and 1, multiplied by the tanh activation function to calculate the cell status and determine which messages in long-term memory must be updated, including updated data and data that must be replaced to be employed in the future. The input gate’s equation is as follows
where
is the sigmoid function,
is the dot product,
is a vector of input data,
is the input gate weight, and
is the input gate bias vector.
To update the long-term memory from
at
to
at
, tanh computes the following equation, where
is the tanh weight and
is the tanh bias vector.
If there are data that the forgetting gate and input gate wish to remove and add, respectively, the formula is as follows. First, to remove the forgetting gate’s data,
is multiplied element by element, then the data that the input gate wishes to add are added element by element to update
to the long-term memory.
Output gate: According to the weight, hidden state, and current output, the sigmoid function computes
, which is between 0 and 1, and multiplies that value with the tanh activation function to determine which data should be removed from long-term memory
to
for further use. The output gate equation is as follows, where
is the sigmoid function, ∙ is the dot product operation,
vector is the input data,
is the output gate weight, and
is the output gate bias vector.
In
Figure 4, at the top right,
are the output data sent to the output layer, and at the bottom,
are the input data sent to
. The output data
are obtained by multiplying the
by the tanh activation function element by element after computing the output data
.
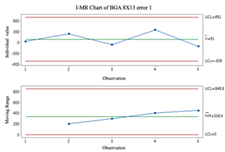
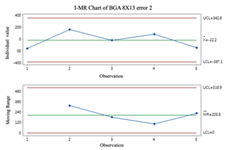
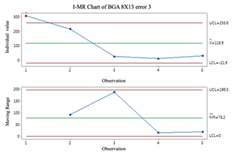
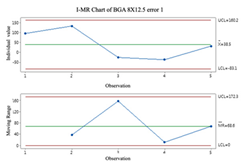
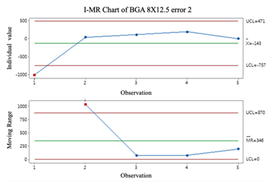
2.3. Individuals and Moving-Range (I-MR) Control Chart
Individual and moving-range charts comprise I and MR charts. I control charts are employed to demonstrate the means and variances of individual values, and MR control charts monitor the data’s variation. To effectively monitor all prediction processes, this study employs the I-MR control chart to determine whether error compensation is needed. If a point exceeds the control limits of the I-MR control chart, the error compensation mechanism is activated, and vice versa. The following are the steps to build an I-MR chart [
19]:
- Step 1.
Calculate the moving range (
MR). The
MR is calculated by calculating the distance between the 2 adjacent points.
- Step 2.
Calculate average
and Moving Range average
.
where
is the observed value of the
i-th sample,
k is the number of samples to establish the control chart.
- Step 3.
Construct the control charts for the Individual and moving range.
where,
d2,
D3, and
D4 are control chart constants [
19].
It is important to remember that data that do not follow a normal distribution can affect the results when using I-MR control charts. Before using I-MR control charts, it is essential to check if the data are the normal distribution. It is recommended that the Box-Cox conversion method be used prior to plotting the I-MR chart if the data are not normally distributed.
2.4. Error Compensation Using ARMA Technique
It is difficult to develop an accurate model since the prediction error is uncertain [
20]. The prediction results would be improved if an error compensation approach could be developed. More accurate prediction results can be obtained by compensating for the errors that are generated during training and combining them with the original prediction results [
21].
Numerous scholars employ the ARMA model, which consists of autoregressive (AR) and moving average (MA), as an approach for error compensation, since it can determine the time series trend and predict future results. To study the evaporation process of alumina, Qian proposed particle-swarm optimization and ARMA error compensation [
22]. Furthermore, microelectromechanical system gyroscopes are extensively employed in dynamic measurement devices. However, their measurement accuracy cannot be very accurate due to the external environment’s influence. Chen and Gao used the ARMA model for compensation to enhance the measurement accuracy of microelectromechanical system gyroscopes, which resulted in a 3.75% reduction in the measurement error [
23].
In this study, the LSTM model was first developed. Then, the ARMA compensation model was developed by filtering the rolling prediction results by selected indicators (maximum, minimum, median, average, and the recent predicted results) and calculating the error from the actual values. This study employed the ARMA model since it does not need differencing, and the prediction results were corrected using the compensation values that were predicted by the ARMA model. The ARMA formula is as follows.
where
is the time series observation at time
t; α is the constant;
is the parameter of
when the lag time is
i;
is the white noise at time
t;
p is the maximum lag-time step;
is the white noise when the lag-time step is
i;
is the constant of
when the lag-time step is
i;
q is the maximum lag-time step; and ARMA (
p,
q) is the ARMA model with the maximum lag-time step of the self-regression term
p and the maximum lag-time step of the MA term
q.
In constructing an ARMA model, the first step is to visualize the data and determine whether there are missing values. If there are missing values, this study will employ the zero-completion approach. Thereafter, the ARMA model’s parameters (p,q) are estimated, and the combination of parameters is obtained from the autocorrelation and partial autocorrelation functions., Along with the model, this is validated to determine whether the fitted model’s residual series is white noise. In the residual sequence, white noise is checked and the Akaike Information Criterion is employed to compute different levels and select the (p,q) combination with the lowest akaike information criterion (AIC) value. Finally, (p,q) is substituted into the ARMA model for prediction. Based on the error compensation, the prediction steps are as follows:
- Step 1.
Calculate the mean absolute percentage error (MAPE), mean absolute error (MAE), and root mean squared error (RMSE) of each indicator, and select the one with the lowest error rate from the LSTM model.
- Step 2.
Determine whether compensation is required by calculating the indicators’ errors and plotting the I-MR control chart.
- Step 3.
In rolling LSTM, the number of products are predicted and multiple predictions are obtained for the test set.
- Step 4.
The prediction result is filtered to based on the index that is selected in Step 1.
- Step 5.
If compensation is needed, develop a rolling ARMA compensation model and calculate the compensation value .
- Step 6.
To obtain the compensation result
, add the compensation value
to the filtered prediction result
:
- Step 7.
Calculate the error between the actual value and , i.e., , which are the data for the next compensation model.
2.5. Data Partitioning and Parameter Setting
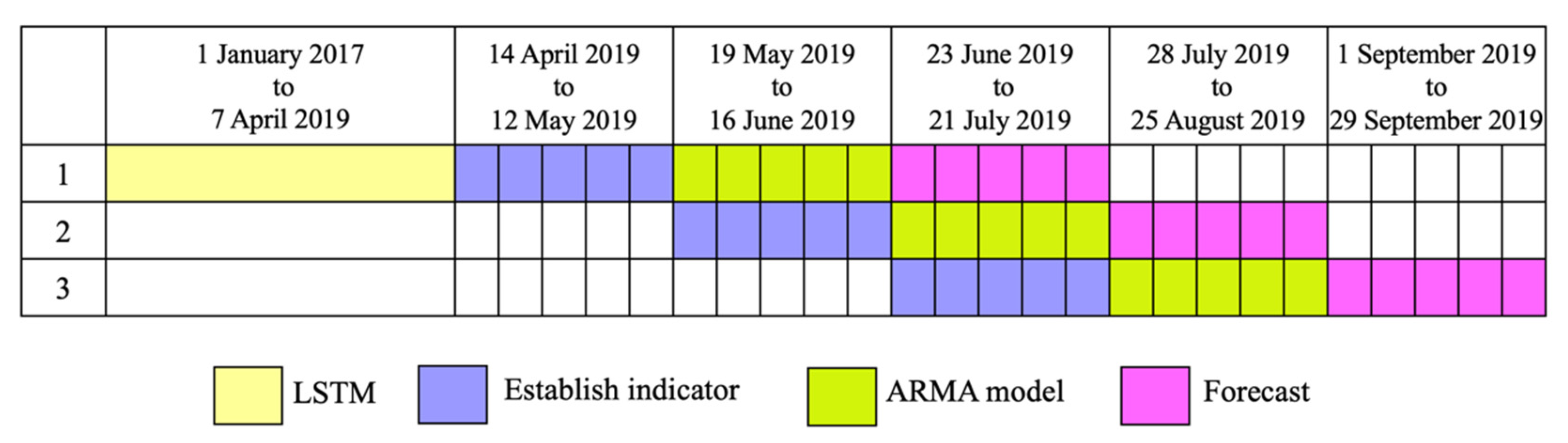
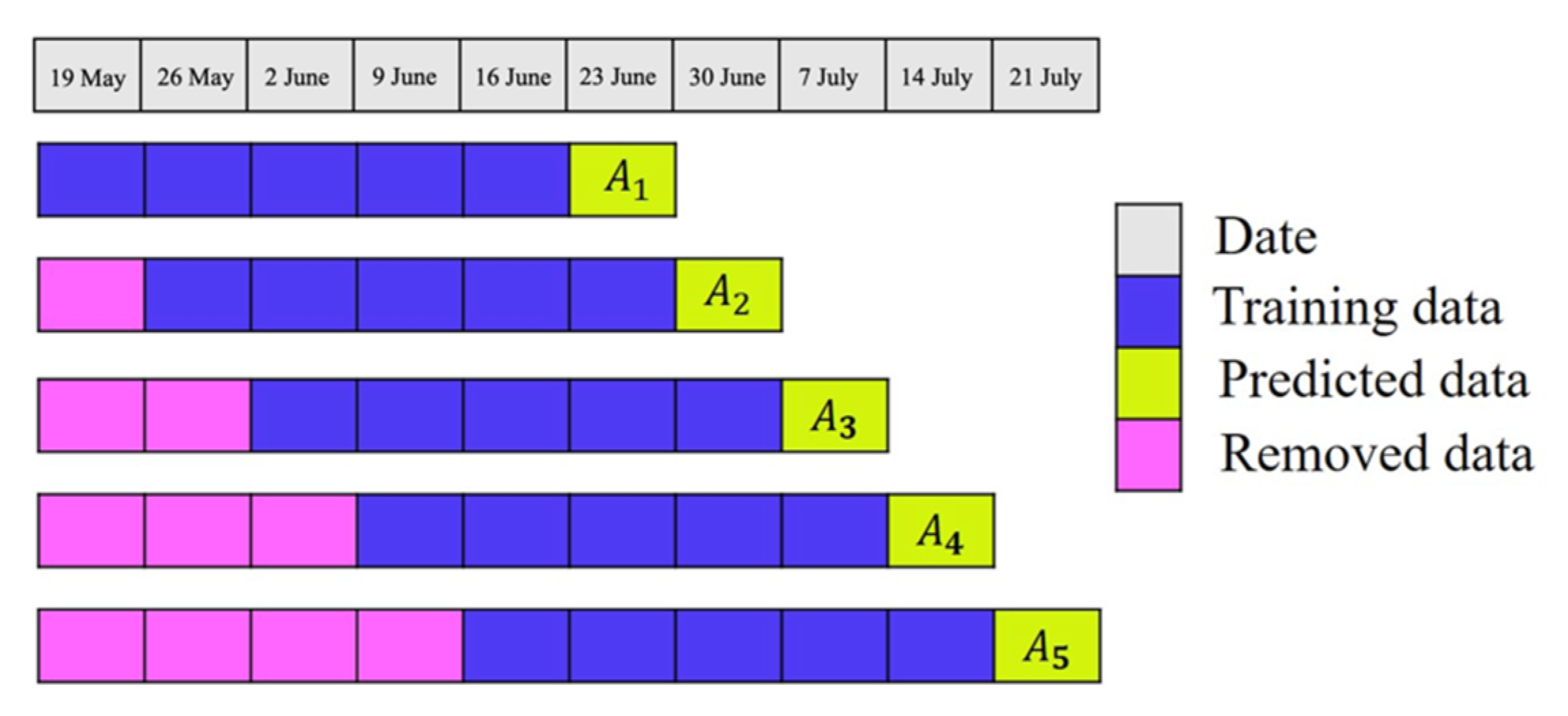
Figure 5 shows the rolling prediction process. As a first rollup, the data were divided into 118 weeks of yellow data from 1 January 2017 to 7 April 2019, five weeks of purple data from 14 April 2019 to 12 May 2019, and five weeks of green data from 19 May 2019 to 16 June 2019 for LSTM model training, indicators establishment, and compensation model building, respectively. Forecasting was based on pink section data from 23 June 2019 to 21 July 2019. The second rollup is based on the first compensation model values (19 May 2019–16 June 2019), a compensation model that was built using the first prediction (23 June 2019–21 July 2019), and a prediction of the last five data (28 July 2019–25 August 2019). This third rollup consists of an indicator that was constructed using the values from the second compensation model 23 June 2019–21 July 2019) and an indicator to the compensation model’s construction using the results from the second prediction (23 June 2019–21 July 2019). The third rollup uses the second compensation model (23 June 2019–21 July 2019), the second forecast (28 July 2019–25 August 2019) and predicts the last five data (1 September 2019–29 September 2019), and so on. In this study, only three cuts and rolls were made to the data to test the proposed approach.
After the training samples are calculated,
Table 1 shows the estimated LSTM rolling pattern parameters.
2.6. Model Performance Indicator
Different indicators are used to evaluate a model’s predictive power. Leonardo designed a forecasting model for sugarcane yield and compared the root mean squared error, mean absolute error, and mean absolute percentage error as indicators of the model’s predictive ability [
24]. To predict the number of COVID-19 confirmations in Iran, Nasrin et al., developed a predictive model and evaluated the model’s performance using RMSE and MAE. The findings show that Iran was probably the most affected and needed more preventative measures [
25]. Chang et al., developed a prediction model for air pollution and evaluated the model’s performance using the MAE, RMSE, and MAPE. The findings indicated that the model considerably enhanced the prediction’s accuracy [
26]. MAE, RMSE, and MAPE, commonly used evaluation indicators in practice, are employed in this study as the criteria for model evaluation. This formula is defined as follows. When the index calculation result is small, predictability is better.
MAE: The mean absolute error between the predicted
and actual values
of each datum is measured using the following formula:
RMSE: A measure of prediction error (
) standard deviation. The formula is as follows:
MAPE: This model overcomes the limitations of both mean absolute deviation (MAD) and RMSE using the relative prediction error of each data, which has overly large calculation results due to the large value of each data.
is the actual value, is the predicted value, and k is the sample size. Mean square error (MSE) and MAPE are unaffected by unit and value sizes and are evaluated objectively; the larger the sample size, the higher the RMSE.
4. Discussion and Conclusions
The prediction model results’ accuracy improved due to the demand of competitors in the market. The forecasting model that is developed in this study is based on actual data from the case companies and is compared with the way that it was previously used. This study had three primary findings. At one time, forecasts were performed for one point at a time, i.e., tomorrow’s results were predicted as they would be. We forecast five points at a time, i.e., tomorrow, the day after tomorrow, the day after tomorrow, the day after tomorrow, etc. In the case of a later forecast, there is not only one forecast, but also the findings from the current period, the previous period, and the previous period before that. Several values are filtered using indicators, instead of using the most recent result as the final forecast. Second, in the past, we would pause the model and reload the data for new model training if we encountered poor prediction results, but this process was tedious and complicated. Finally, in the past, error compensation was activated regardless of the prediction results. The proposed error compensation mechanism is based on the I-MR control chart that is plotted by the difference between the indicators’ filtered and actual values, and the need for error compensation is determined as opposed to simply activating compensation regardless of the prediction results.
LSTM, rolling LSTM combined with an index, and LSTM-ARMA are compared, and the LSTM-ARMA approach proves to be more accurate when the error compensation is required. Furthermore, the rolling LSTM combined with the index offers better predictions than the firm’s rule of thumb and LSTM when no residential error compensation is required.
Table 11 shows the evaluation of the ARIMA model, demonstrating that the LSTM-ARMA method is more accurate when error compensation is required.
As a contribution to academic work, we have proposed an approach to determine whether an error compensation is necessary using rolling data for forecasting. In cases of model inaccuracy, the original model can be used without model correction. Combining LSTM and ARMA rolling forecasting approaches can generate more accurate forecasting results and eliminate the bottleneck problems that have been experienced in the past. In the past, regarding industry contribution, models were trained and tested before going online, and once they were employed, they gradually became inaccurate and needed to be recorrected, which took a long time. This study develops a model that uses error compensation to reduce the time and cost of pausing the model correction when past forecasts are inaccurate and compares it with empirical rules that are employed by companies to offer more accurate forecasting results.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}