
Enhanced Graph Learning for Recommendation via Causal Inference

Abstract
:1. Introduction
- We explore the effectiveness of neighbor information of entities (including users and items) for enhancing entity representation.
- We propose enhanced graph learning for recommendation via causal inference (EGCI). On both the user side and the item side, we aggregate the neighborhood information of entities through graph convolutional networks to help improve the accuracy of recommendations.
- We introduce the operator to understand the causality in the data and remove the effects of confounding factors.
- Ablation experiments were conducted with different settings of key hyperparameters, and the effectiveness of EGCI was verified on each of three widely used datasets.
2. Related Work
3. Problem Definition and Notation
4. Proposed Methodology
4.1. Biases Caused by Confounding Factors in the Recommender System

4.2. Introducing Causal Inference to Identify and Remove Confounding Biases
- Figure 2 shows the real world (i.e., observation data, provided by the dataset), users and items will be simultaneously affected by confounding factors, so they cannot be independent.
- Figure 3 shows the imaginary world (i.e., experimental data, which cannot be provided by datasets, and therefore, do not exist in reality). In this ideal world, users and items are not affected by confounding factors, so they are independent.

4.3. User Representation
4.4. Item Representation
4.5. User–Item Interaction
4.6. Optimization Methods
5. Experimental Results and Analysis
5.1. Experimental Setup
5.1.1. Dataset Description
5.1.2. Evaluation Metrics
5.1.3. Baseline Approaches
5.1.4. Parameter Settings
5.2. Experimental Results and Analysis
5.2.1. Comparison of Performance with Baseline 1 Methods (RQ1)
- From the data, EGCI has advantages. By carefully observing these three portions of results, we can see the advantages and disadvantages of its performance. (1) With hetrec2011-movielens-2k, the RMSE of EGCI was developing in a good direction. The increase rate of data was in the range of 1.12% to 13.99%. The average value reached 6.37%. EGCI is much better than NCF because the latter method was used for a long time. However, NCF is a classical algorithm that cannot be ignored. Compared with other algorithms in the table, the performance was superior. (2) The first two, hetrec2011-delicious-2k and hetrec2011-lastfm-2k, improved by 6.14% and 7.07% respectively. Compared with 6.37%, those results are similar, indicating that EGCI has a certain amount of stability.
- Among the algorithms used for comparison, the trend was not completely consistent. Although EGCI did not surpass them too much, EGCI was always the best. The reason for this is that EGCI can alleviate the sparsity of data.
- In terms of data alone, NCF performed generally well. Second was CFN. This is mainly because they are relatively early starters. Other algorithms do not put more information into embedding.
- EGCI made some progress over our ADAR. This is mainly because EGCI adds user relationships to embedding. The combination of item attributes and user embedding, and adding these vectors to each other, changes the direction of the original vector, and makes it possible to adjust the similarity deviation between users and items in the dataset. The experimental results also confirm the rationality of this.
5.2.2. Comparison of Performance with Baseline 2 Methods (RQ2)
- Among all the data, EGCI is the most prominent. Among the four evaluation values, although the best among other methods changes, EGCI is consistent. For example, on the dataset hetrec2011-delicious-2k, the average improvement ratio of EGCI was 6.69%, 6.43%, 7.44%, or 3.80%. The other two experiments went the same.
- Compared with all models, except Adar, EGCI made more progress. From this point, it can be observed that the improvement method of embedding in EGCI is better. The ADAR method developed by using item attributes is also relatively advantageous, which shows that our research direction is correct.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Hetrec2011-delicious-2k | |||||||
|---|---|---|---|---|---|---|---|---|
| P@5 | EGCI | P@10 | EGCI | R@5 | EGCI | R@10 | EGCI | |
| ↑ | Impr. | ↑ | Impr. | ↑ | Impr. | ↑ | Impr. | |
| mostPOP | 0.487 | 13.96% | 0.482 | 10.24% | 0.049 | 12.50% | 0.073 | 7.59% |
| BPRMF | 0.515 | 9.01% | 0.492 | 8.38% | 0.050 | 10.71% | 0.076 | 3.80% |
| GMF | 0.524 | 7.42% | 0.489 | 8.94% | 0.051 | 8.93% | 0.078 | 1.27% |
| SLIM | 0.538 | 4.95% | 0.508 | 5.40% | 0.054 | 3.57% | 0.076 | 3.80% |
| NeuMF | 0.546 | 3.53% | 0.515 | 4.10% | 0.052 | 7.14% | 0.075 | 5.06% |
| ADAR | 0.559 | 1.24% | 0.529 | 1.49% | 0.055 | 1.79% | 0.078 | 1.27% |
| EGCI | 0.566 | - | 0.537 | - | 0.056 | - | 0.079 | - |
| Impr. Avg | 6.69% | 6.43% | 7.44% | 3.80% | ||||
| Method | Hetrec2011-lastfm-2k | |||||||
|---|---|---|---|---|---|---|---|---|
| P@5 | EGCI | P@10 | EGCI | R@5 | EGCI | R@10 | EGCI | |
| ↑ | Impr. | ↑ | Impr. | ↑ | Impr. | ↑ | Impr. | |
| mostPOP | 0.487 | 15.89% | 0.479 | 12.43% | 0.049 | 14.04% | 0.079 | 9.20% |
| BPRMF | 0.519 | 10.36% | 0.493 | 9.87% | 0.049 | 14.04% | 0.084 | 3.45% |
| GMF | 0.536 | 7.43% | 0.492 | 10.05% | 0.052 | 8.77% | 0.085 | 2.30% |
| SLIM | 0.541 | 6.56% | 0.512 | 6.40% | 0.055 | 3.51% | 0.085 | 2.30% |
| NeuMF | 0.548 | 5.35% | 0.517 | 5.48% | 0.055 | 3.51% | 0.086 | 1.15% |
| ADAR | 0.561 | 3.11% | 0.529 | 3.29% | 0.056 | 1.75% | 0.083 | 4.60% |
| EGCI | 0.579 | - | 0.547 | - | 0.057 | - | 0.087 | - |
| Impr. Avg | 8.12% | 7.92% | 7.60% | 3.83% | ||||
| Method | Hetrec2011-movielens-2k | |||||||
|---|---|---|---|---|---|---|---|---|
| P@5 | EGCI | P@10 | EGCI | R@5 | EGCI | R@10 | EGCI | |
| ↑ | Impr. | ↑ | Impr. | ↑ | Impr. | ↑ | Impr. | |
| mostPOP | 0.508 | 12.86% | 0.485 | 11.17% | 0.050 | 15.25% | 0.081 | 11.96% |
| BPRMF | 0.525 | 9.95% | 0.498 | 8.79% | 0.052 | 11.86% | 0.087 | 5.43% |
| GMF | 0.537 | 7.89% | 0.497 | 8.97% | 0.054 | 8.47% | 0.087 | 5.43% |
| SLIM | 0.546 | 6.35% | 0.504 | 7.69% | 0.057 | 3.39% | 0.086 | 6.52% |
| NeuMF | 0.551 | 5.49% | 0.519 | 4.95% | 0.055 | 6.78% | 0.091 | 1.09% |
| ADAR | 0.565 | 3.09% | 0.532 | 2.56% | 0.058 | 1.69% | 0.086 | 6.52% |
| EGCI | 0.583 | - | 0.546 | - | 0.059 | - | 0.092 | - |
| Impr. Avg | 7.61% | 7.36% | 7.91% | 6.16% | ||||
5.2.3. Impact of the Number of Attribute Features on Performance (RQ3)
- EGCI-a and EGCI- are derived from EGCI. In fact, they are combined once and twice by the latter. We can see from Table 8 that both of them are inferior to EGCI-, that is, EGCI. This proves the validity of item attributes involved in user embedding.
- It can also be seen from the data in Table 8 that the performances of , , and gradually increase. Among them, is the worst and is the best. This shows that the idea of this paper is correct.
5.2.4. Impacts of Model Depth and Embedding Size on Performance (RQ4)
- (1)
- Model depth
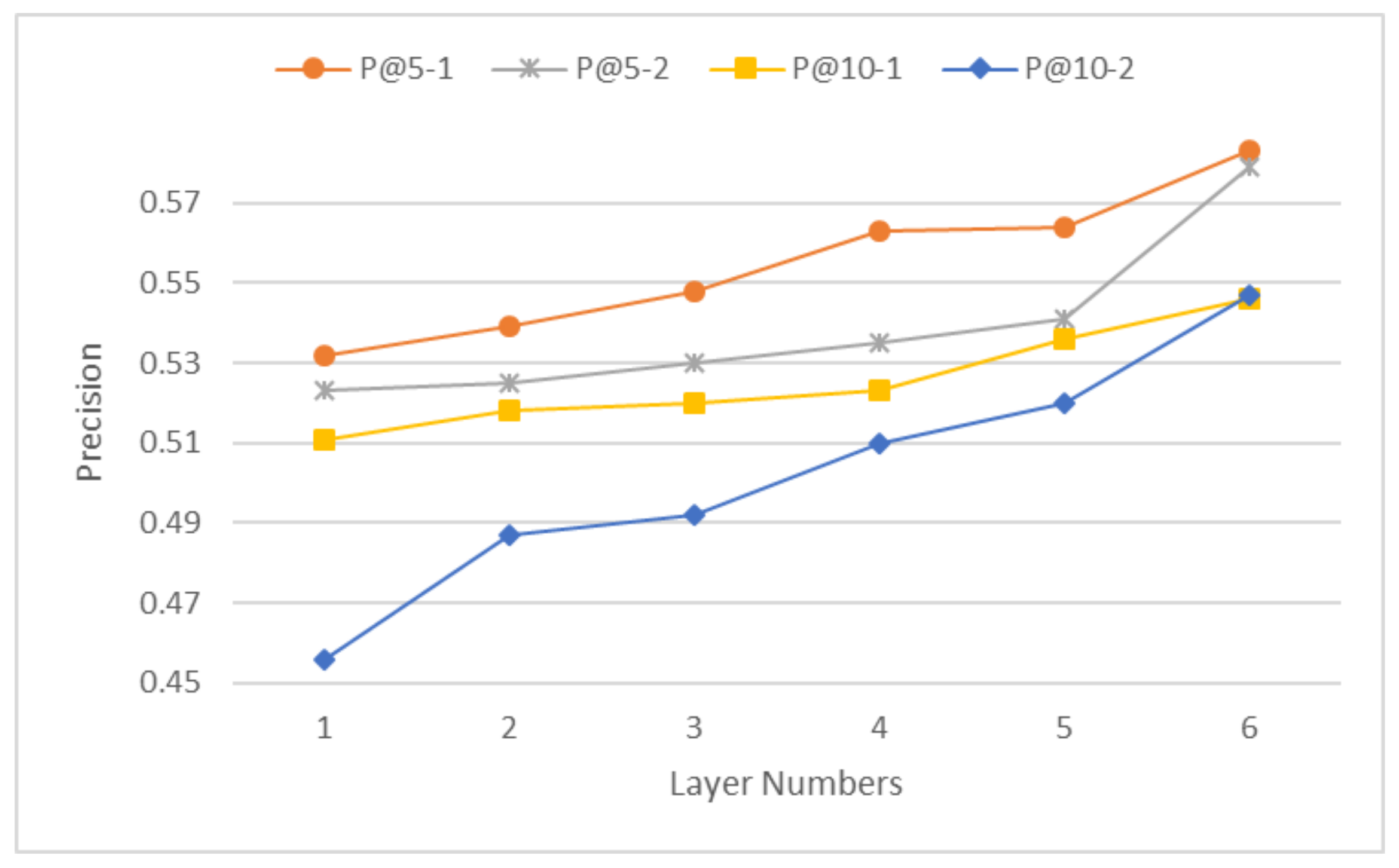
- In Figure 6, Figure 7 and Figure 8, we can see the influence of the number of layers on the algorithm. Basically, the performances of all algorithms are directly proportional to the number of layers. This is also the same in much of the literature. The number of layers is directly proportional to the accuracy.
- Once the number of layers is sufficiently high, the performance will not be improved indefinitely. In this round of experiments, when the number of layers was equal to 5, the effect was basically at its peak. Further increasing this value was no longer beneficial in the experiment.
- (2)
- Embedding size
- Embedding is similar to the number of layers. It is also closely related to the advantages and disadvantages of EGCI, and the two are directly proportional. The figure shows that when the value of embedding is 150, the best results will be obtained in an experiment on hetrec2011-movielens-2k.
- When the size of embedding is 200, the best result is obtained on hetrec2011-lastfm-2k. When it is 300, it works best on the other dataset. After analysis, we believe that this is related to the sparsity of the data itself.
6. Summary and Outlook
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Da’U, A.; Salim, N. Recommendation system based on deep learning methods: A systematic review and new directions. Artif. Intell. Rev. 2020, 53, 2709–2748. [Google Scholar] [CrossRef]
- Seol, J.; Ko, Y.; Lee, S.G. Exploiting Session Information in BERT-based Session-aware Sequential Recommendation. arXiv 2022, arXiv:2204.10851. [Google Scholar]
- Marin, N.; Makhneva, E.; Lysyuk, M.; Chernyy, V.; Oseledets, I.; Frolov, E. Tensor-based Collaborative Filtering with Smooth Ratings Scale. arXiv 2022, arXiv:2205.05070. [Google Scholar]
- He, X.; Liao, L.; Zhang, H.; Nie, L.; Chua, T.S. Neural Collaborative Filtering. arXiv 2017, arXiv:1708.05031. [Google Scholar]
- Carroll, M.; Hadfield-Menell, D.; Russell, S.; Dragan, A. Estimating and Penalizing Induced Preference Shifts in Recommender Systems. arXiv 2022, arXiv:2204.11966. [Google Scholar]
- Ferrara, A.; Espín-Noboa, L.; Karimi, F.; Wagner, C. Link recommendations: Their impact on network structure and minorities. arXiv 2022, arXiv:2205.06048. [Google Scholar]
- Dareddy, M.R.; Xue, Z.; Lin, N.; Cho, J. Bayesian Prior Learning via Neural Networks for Next-item Recommendation. arXiv 2022, arXiv:2205.05209. [Google Scholar]
- Ni, Y.; Ou, D.; Liu, S.; Li, X.; Ou, W.; Zeng, A.; Si, L. Perceive Your Users in Depth: Learning Universal User Representations from Multiple E-commerce Tasks. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018. [Google Scholar]
- Rashed, A.; Elsayed, S.; Schmidt-Thieme, L. CARCA: Context and Attribute-Aware Next-Item Recommendation via Cross-Attention. arXiv 2022, arXiv:2204.06519. [Google Scholar]
- Paudel, B.; Bernstein, A. Random Walks with Erasure: Diversifying Personalized Recommendations on Social and Information Networks. Proc. Web Conf. 2021, 2021, 2046–2057. [Google Scholar]
- Balloccu, G.; Boratto, L.; Fenu, G.; Marras, M. Post Processing Recommender Systems with Knowledge Graphs for Recency, Popularity, and Diversity of Explanations. arXiv 2022, arXiv:2204.11241. [Google Scholar]
- Sheth, P.; Guo, R.; Cheng, L.; Liu, H.; Candan, K.S. Causal Disentanglement with Network Information for Debiased Recommendations. arXiv 2022, arXiv:2204.07221. [Google Scholar]
- Yang, Y.; Kim, K.S.; Kim, M.; Park, J. GRAM: Fast Fine-tuning of Pre-trained Language Models for Content-based Collaborative Filtering. arXiv 2022, arXiv:2204.04179. [Google Scholar]
- Tran, L.V.; Tay, Y.; Zhang, S.; Cong, G.; Li, X. HyperML: A Boosting Metric Learning Approach in Hyperbolic Space for Recommender Systems. In Proceedings of the WSDM ’20: The Thirteenth ACM International Conference on Web Search and Data Mining, Houston, TX, USA, 3–7 February 2020. [Google Scholar]
- A Survey of the Usages of Deep Learning for Natural Language Processing. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 604–624.
- Lee, D.; Oh, B.; Seo, S.; Lee, K.H. News Recommendation with Topic-Enriched Knowledge Graphs. In Proceedings of the CIKM ’20: The 29th ACM International Conference on Information and Knowledge Management, Virtual Event, Ireland, 19–23 October 2020. [Google Scholar]
- Nazari, Z.; Charbuillet, C.; Pages, J.; Laurent, M.; Charrier, D.; Vecchione, B.; Carterette, B. Recommending Podcasts for Cold-Start Users Based on Music Listening and Taste. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, China, 25–30 July 2020. [Google Scholar]
- Satuluri, V.; Wu, Y.; Zheng, X.; Qian, Y.; Lin, J. SimClusters: Community-Based Representations for Heterogeneous Recommendations at Twitter. In Proceedings of the KDD ’20: The 26th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Virtual Event, CA, USA, 6–10 July 2020. [Google Scholar]
- Le, W.; Sun, P.; Hong, R.; Yong, G.; Meng, W. Collaborative Neural Social Recommendation. IEEE Trans. Syst. Man Cybern. Syst. 2018, 51, 464–476. [Google Scholar]
- Rendle, S.; Krichene, W.; Zhang, L.; Anderson, J. Neural Collaborative Filtering vs. Matrix Factorization Revisited. In Proceedings of the Fourteenth ACM Conference on Recommender Systems, Virtual Event, Brazil, 22–26 September 2020. [Google Scholar]
- Wang, S.; Wang, Y.; Sheng, Q.Z.; Orgun, M.; Lian, D. A Survey on Session-based Recommender Systems. arXiv 2020, arXiv:1902.04864. [Google Scholar] [CrossRef]
- Batmaz, Z.; Yurekli, A.; Bilge, A.; Kaleli, C. A review on deep learning for recommender systems: Challenges and remedies. Artif. Intell. Rev. 2019, 52, 1–37. [Google Scholar] [CrossRef]
- Iqbal, M.; Kovac, A.; Aryafar, K. A Multimodal Recommender System for Large-scale Assortment Generation in E-commerce. arXiv 2018, arXiv:1806.11226. [Google Scholar]
- Kwon, Y.; Rhu, M. Training Personalized Recommendation Systems from (GPU) Scratch: Look Forward not Backwards. arXiv 2022, arXiv:2205.04702. [Google Scholar]
- Alom, M. “Are We Really Making Much Progress? A Worrying Analysis of Recent Neural Recommendation Approaches” by Ferrari Dacrema et al. Technical Assessment. arXiv 2021, arXiv:1907.06902. [Google Scholar]
- Strub, F.; Gaudel, R.; Mary, J. Hybrid Recommender System based on Autoencoders. In Proceedings of the 1st Workshop on Deep Learning for Recommender Systems, Boston, MA, USA, 15–19 September 2016; pp. 11–16. [Google Scholar]
- Yue, L.; Sun, X.X.; Gao, W.Z.; Feng, G.Z.; Zhang, B.Z. Multiple Auxiliary Information Based Deep Model for Collaborative Filtering. J. Comput. Sci. Technol. 2018, 33, 668–681. [Google Scholar] [CrossRef]
- Li, S.; Kawale, J.; Fu, Y. Deep Collaborative Filtering via Marginalized Denoising Auto-encoder. In Proceedings of the CIKM ’15: Proceedings of the 24th ACM International on Conference on Information and Knowledge Management, Melbourne, VIC, Australia, 19–23 October 2015. [Google Scholar]
- Shi, C.; Zhang, Z.; Luo, P.; Yu, P.S.; Yue, Y.; Wu, B. Semantic Path based Personalized Recommendation on Weighted Heterogeneous Information Networks. In Proceedings of the ACM International on Conference on Information & Knowledge Management, Melbourne, VIC, Australia, 19–23 October 2015. [Google Scholar]
- Sun, X.; Zhang, L.; Wang, Y.; Yu, M.; Yin, M.; Zhang, B. Attribute-aware deep attentive recommendation. J. Supercomput. 2021, 77, 5510–5527. [Google Scholar] [CrossRef]
- Rendle, S.; Freudenthaler, C.; Gantner, Z.; Schmidt-Thieme, L. BPR: Bayesian Personalized Ranking from Implicit Feedback. arXiv 2012, arXiv:1205.2618. [Google Scholar]
- Ning, X.; Karypis, G. [SSLIM] Sparse linear methods with side information for Top-N recommendations. In Proceedings of the Sixth ACM Conference on Recommender Systems, Dublin, Ireland, 9–13 September 2012; p. 581. [Google Scholar]







| Notataions | Descripition |
|---|---|
| U = {} | Set of all users |
| I = {} | Set of all items |
| User u | |
| Item i | |
| User–item rating matrix | |
| Popularity of item i | |
| Adjacency matrix between all users | |
| Adjacency matrix between all items | |
| Features matrix of all users | |
| Features matrix of all items | |
| user u embedding representiation | |
| item i embedding representiation | |
| True rating of u to i, stored in | |
| Predicted u rating for i |
| Dataset | Hetrec2011- movielens-2k | Hetrec2011- lastfm-2k | Hetrec2011- delicious-2k |
|---|---|---|---|
| #users | 2113 | 1892 | 1867 |
| #items | 10,197 (movies) | 17,632 (artists) | 38,581 (URLs) |
| #interactions | 855,598 (ratings) [1–5] | 92,834 (user-listened artist relations) | 104,799 (user-bookmarks -URLs relations) |
| #attribute1 | 20,809 (genre assignments) | 186,479 (tag assignments) | 437,593 (tag assignments) |
| #attribute2 | 4060 (directors) | 17,632 (artist names and urls) | 53,388 (tags) |
| #attribute3 | 95,321 (actor assignments) | 12,717 (user friend relations) | 7668 (user relations) |
| #attribute4 | 10,197 (country assignments) | _ | _ |
| #attribute5 | 47,957 (tag assignments) | _ | _ |
| Sparsity | 3.97% | 0.28% | 0.15% |
| Dataset | d | L | Batch Size | |||||
|---|---|---|---|---|---|---|---|---|
| Hetrec2011- movielens-2k | 150 | 3 | 300 | 200 | 150 | 2 × 10 | 2 × 10 | 256 |
| Hetrec2011- lastfm-2k | 150 | 3 | 300 | 200 | 150 | 10 | 5 × 10 | 128 |
| Hetrec2011- delicious-2k | 200 | 3 | 400 | 300 | 200 | 10 | 10 | 128 |
| Method | Hetrec2011- delicious-2k | Hetrec2011- lastfm-2k | Hetrec2011- movielens-2k | |||
|---|---|---|---|---|---|---|
| RMSE | EGCI Impr. | RMSE | EGCI Impr. | RMSE | EGCI Impr. | |
| NCF | 0.8764 | 13.48% | 0.8794 | 14.91% | 0.8693 | 13.99% |
| U-CFN | 0.8741 | 13.25% | 0.8709 | 14.08% | 0.8584 | 12.90% |
| U-CFN++ | 0.8476 | 10.54% | 0.8435 | 11.29% | 0.8406 | 11.05% |
| I-CFN | 0.7992 | 5.12% | 0.7968 | 6.09% | 0.8137 | 8.11% |
| mSDA-CF | 0.7884 | 3.82% | 0.7884 | 5.09% | 0.7827 | 4.47% |
| I-CFN++ | 0.7802 | 2.81% | 0.7781 | 3.83% | 0.7689 | 2.76% |
| SemRe-DCF | 0.7774 | 2.46% | 0.7836 | 4.50% | 0.7638 | 2.11% |
| SemRec | 0.7736 | 1.98% | 0.7643 | 2.09% | 0.7536 | 0.78% |
| ADAR | 0.7721 | 1.79% | 0.7615 | 1.73% | 0.7562 | 1.12% |
| EGCI | 0.7583 | - | 0.7483 | - | 0.7477 | - |
| Impr. Avg | 6.14% | 7.07% | 6.37% | |||
| Data | Performance | Model | ||
|---|---|---|---|---|
| EGCI- | EGCI- | EGCI- | ||
| Hetrec2011-movielens-2k | P@5 ↑ | 0.572 | 0.581 | 0.584 |
| R@5 ↑ | 0.052 | 0.058 | 0.060 | |
| P@10 ↑ | 0.505 | 0.542 | 0.547 | |
| R@10 ↑ | 0.080 | 0.082 | 0.093 | |
| Hetrec2011-lastfm-2k | P@5 ↑ | 0.566 | 0.574 | 0.580 |
| R@5 ↑ | 0.051 | 0.052 | 0.057 | |
| P@10 ↑ | 0.499 | 0.537 | 0.542 | |
| R@10 ↑ | 0.072 | 0.078 | 0.091 | |
| Hetrec2011-delicious-2k | P@5 ↑ | 0.552 | 0.564 | 0.575 |
| R@5 ↑ | 0.048 | 0.052 | 0.055 | |
| P@10 ↑ | 0.486 | 0.490 | 0.528 | |
| R@10 ↑ | 0.067 | 0.071 | 0.089 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, S.; Ji, H.; Yin, M.; Wang, Y.; Lu, M.; Sun, H. Enhanced Graph Learning for Recommendation via Causal Inference. Mathematics 2022, 10, 1881. https://doi.org/10.3390/math10111881
Wang S, Ji H, Yin M, Wang Y, Lu M, Sun H. Enhanced Graph Learning for Recommendation via Causal Inference. Mathematics. 2022; 10(11):1881. https://doi.org/10.3390/math10111881
Chicago/Turabian StyleWang, Suhua, Hongjie Ji, Minghao Yin, Yuling Wang, Mengzhu Lu, and Hui Sun. 2022. "Enhanced Graph Learning for Recommendation via Causal Inference" Mathematics 10, no. 11: 1881. https://doi.org/10.3390/math10111881
APA StyleWang, S., Ji, H., Yin, M., Wang, Y., Lu, M., & Sun, H. (2022). Enhanced Graph Learning for Recommendation via Causal Inference. Mathematics, 10(11), 1881. https://doi.org/10.3390/math10111881