
Multi-View Graph Clustering by Adaptive Manifold Learning



Abstract
:1. Introduction
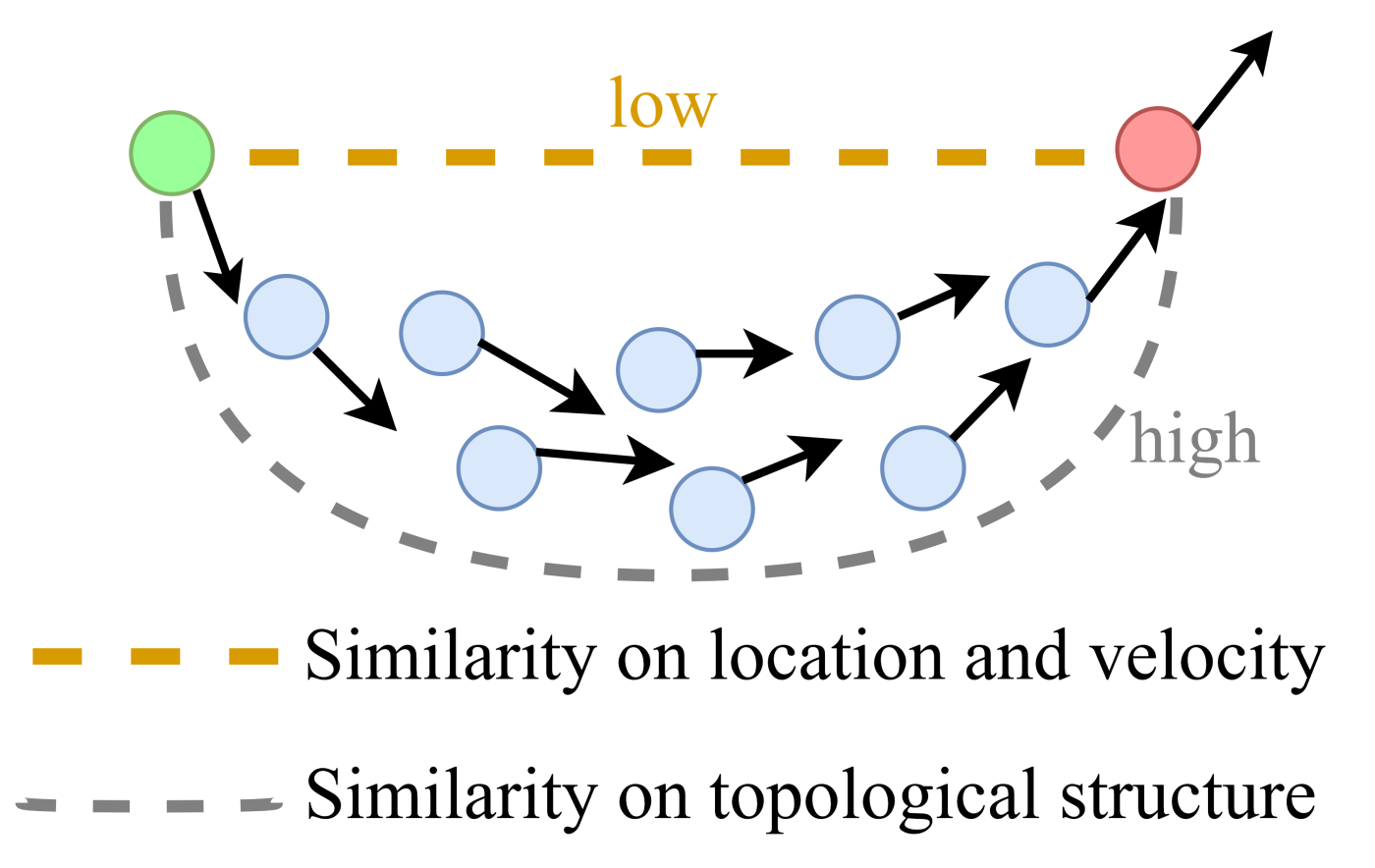
- The proposed multi-view graph clustering method, for the first time to the best of our knowledge, explores the topological manifold structure from multiple adaptive graphs such that the topological relevance across multiple views can be explicitly detected.
- Essentially as an end-to-end single-stage learning paradigm, our model seamlessly achieves three subtasks: It constructs the adaptive graphs for each view, explores the topological manifold structure across multiple graphs, and allocates the discrete cluster label for each sample.
- An iterative updating algorithm is carefully designed to solve the optimization problem. Experiments on several benchmark datasets demonstrate the effectiveness of the proposed model.
2. Preliminary Work
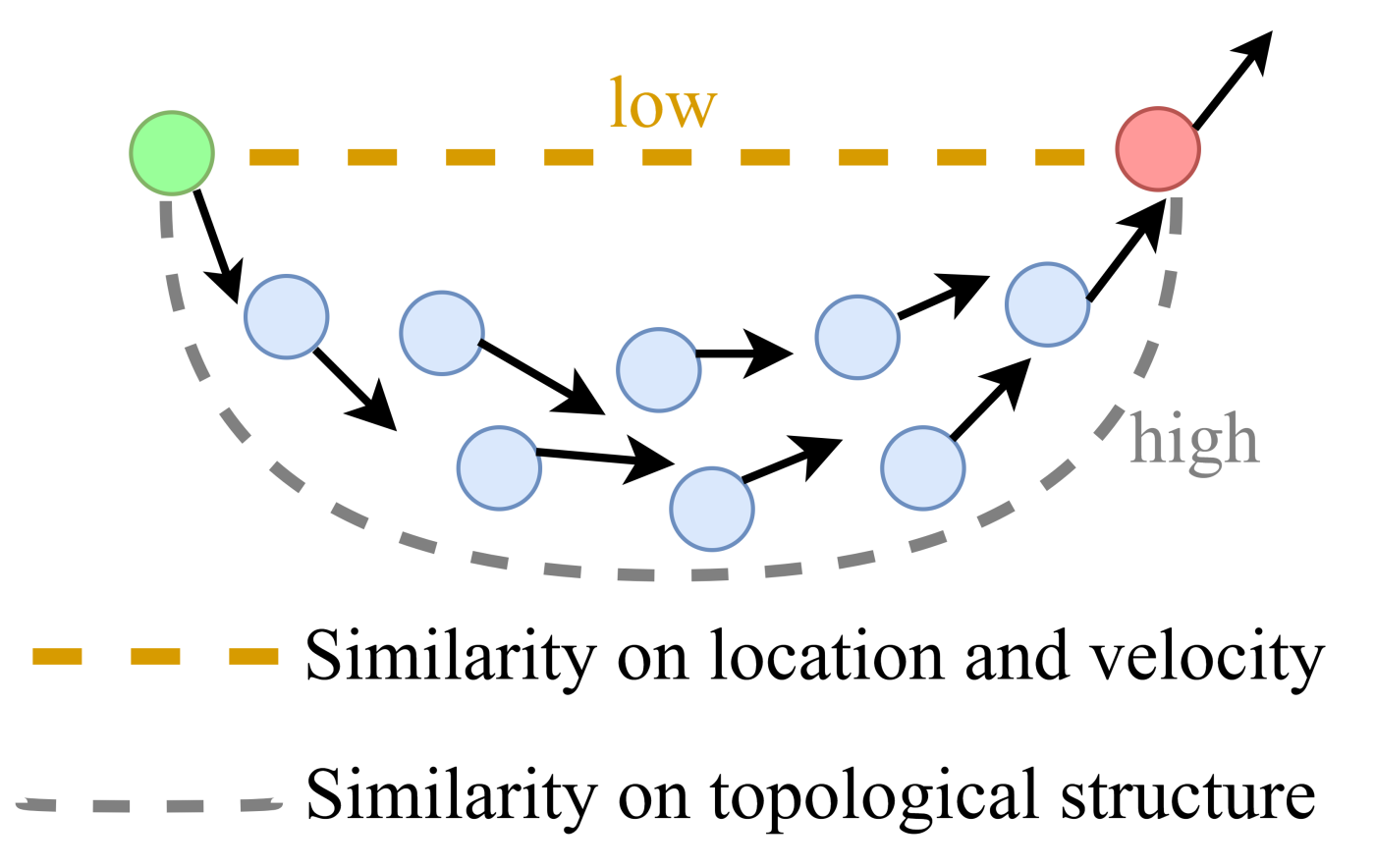
3. The Proposed Model
4. Optimization
4.1. Update
4.2. Update
| Algorithm 1: Algorithm to solve Equation (17). |
| Require: a nonzero matrix A and a nonzero vector b. |
| Set 1 < ρ < 2, initialize η > 0, q. |
| Ensure: S. |
| 1: repeat |
| 2: Update p according to (20). |
| 3: Update si according to (21). |
| 4: Update η ← ρη. |
| 5: Update q ← q + η (si − p). |
| 1: until converge |
4.3. Update F
| Algorithm 2: The algorithm for our model. |
| Require: multi-view data with m views, cluster number c, parameters and . |
| Initialize the weight of each view . |
| Initialize for each view by (2). |
| Initialize the consensus graph . |
| Ensure: The target with exactly c connected components, and the cluster indicator matrix F. |
| 1: repeat |
| 2: Update according to Equation (10). |
| 3: Update S by Algorithm 1. |
| 4: Update F according to Equation (22). |
| 5: Update according to Equation (6). |
| 6: Until converge |
4.4. Time Complexity Analysis
4.5. Convergence Analysis
5. Experiments
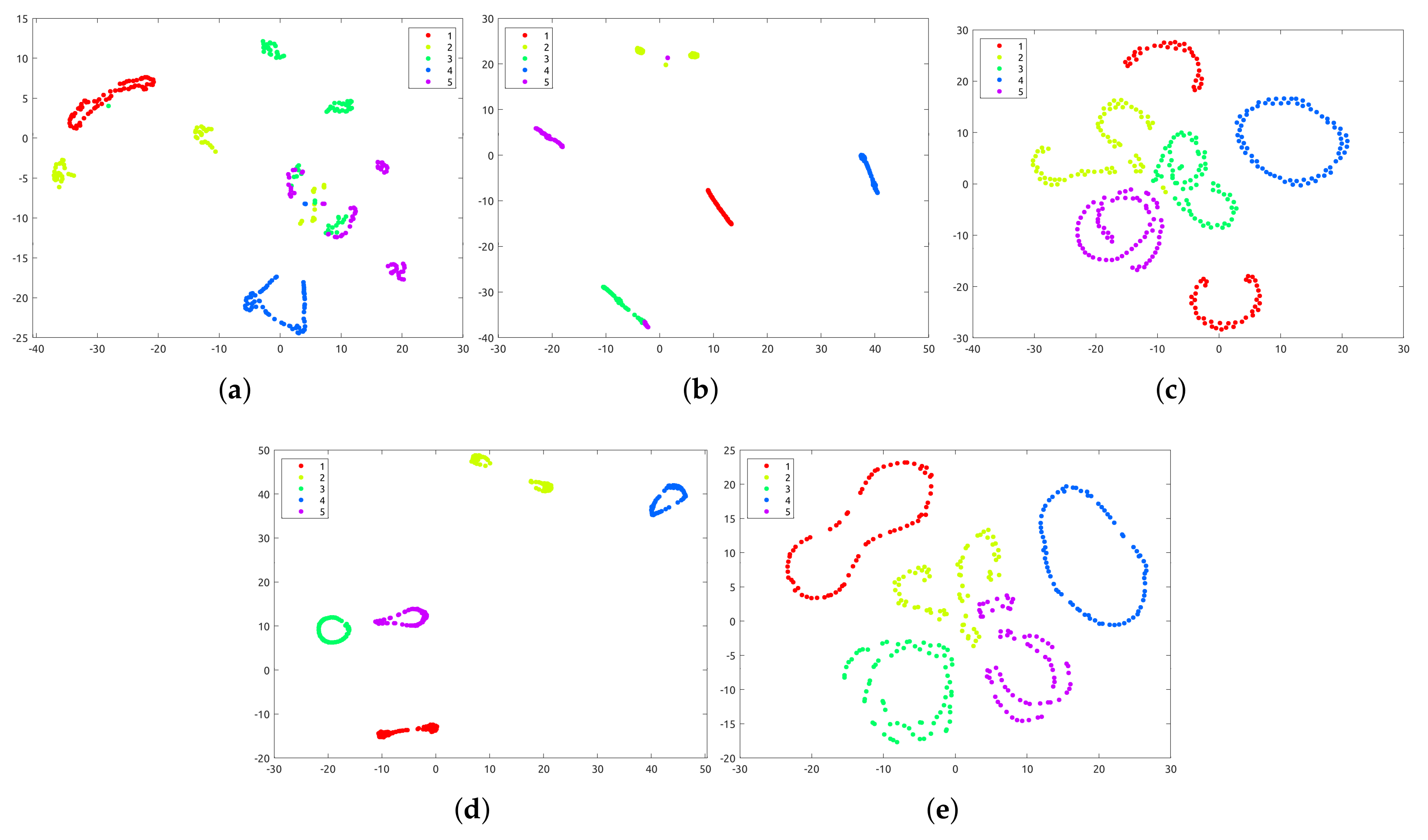
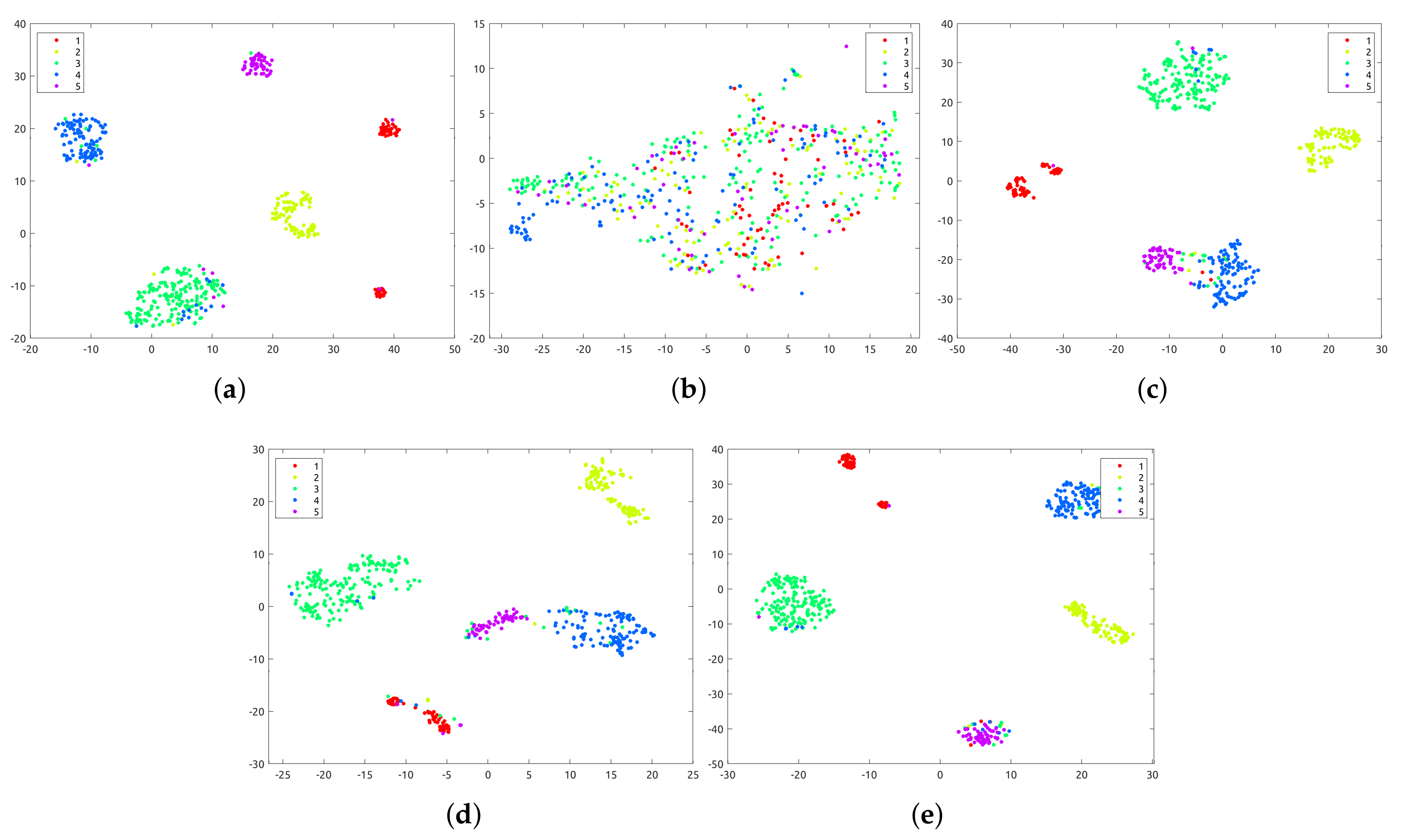
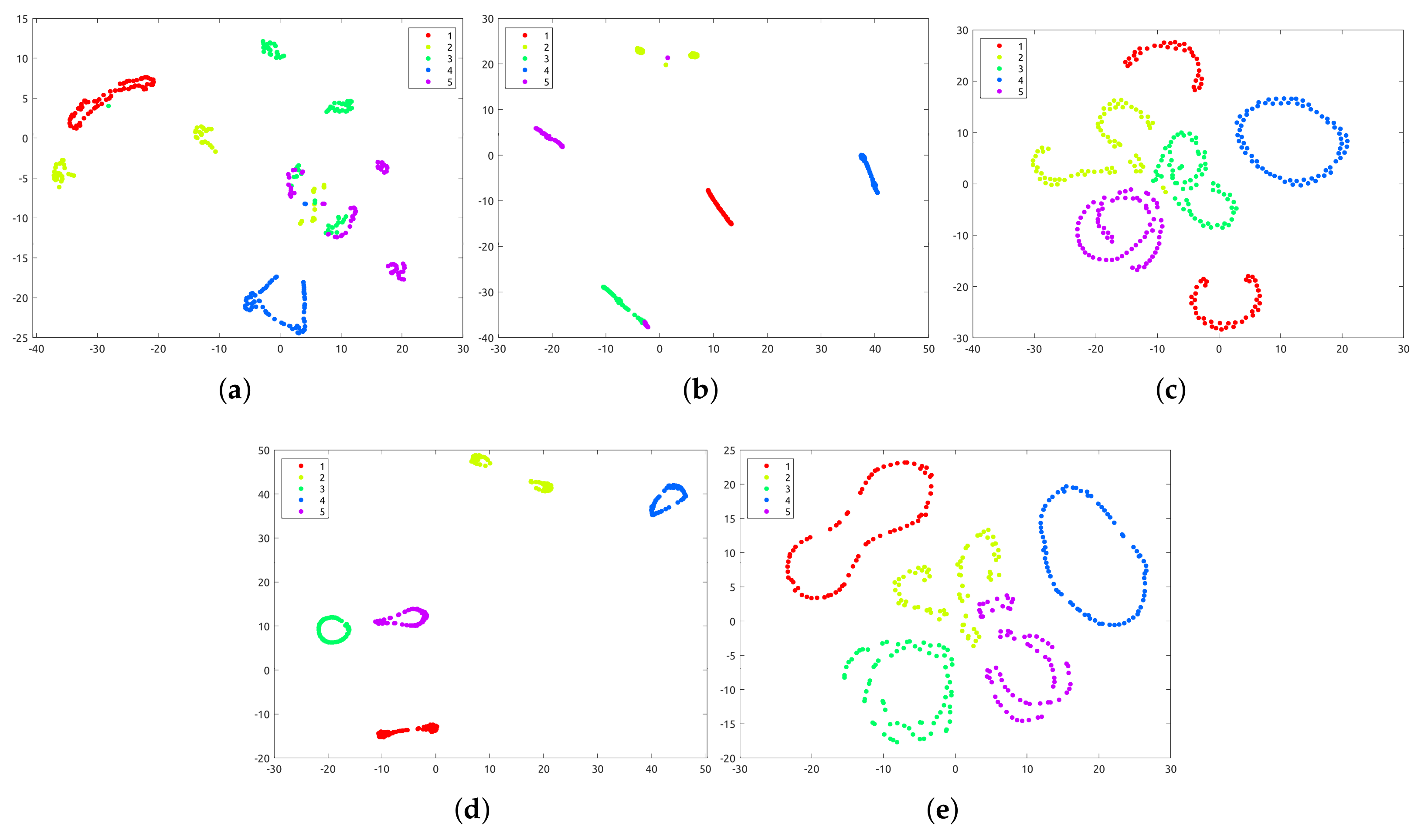
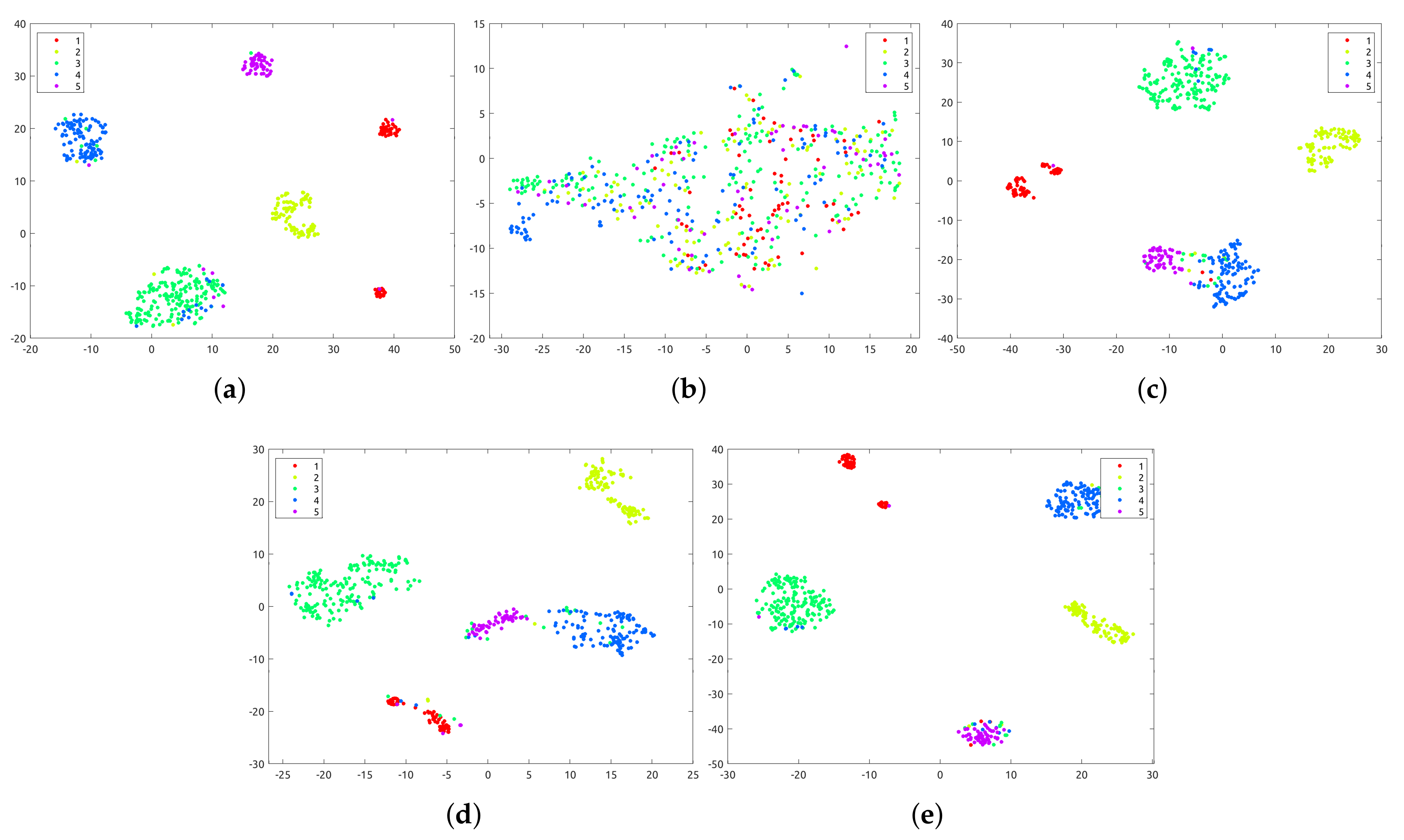
5.1. Clustering Results
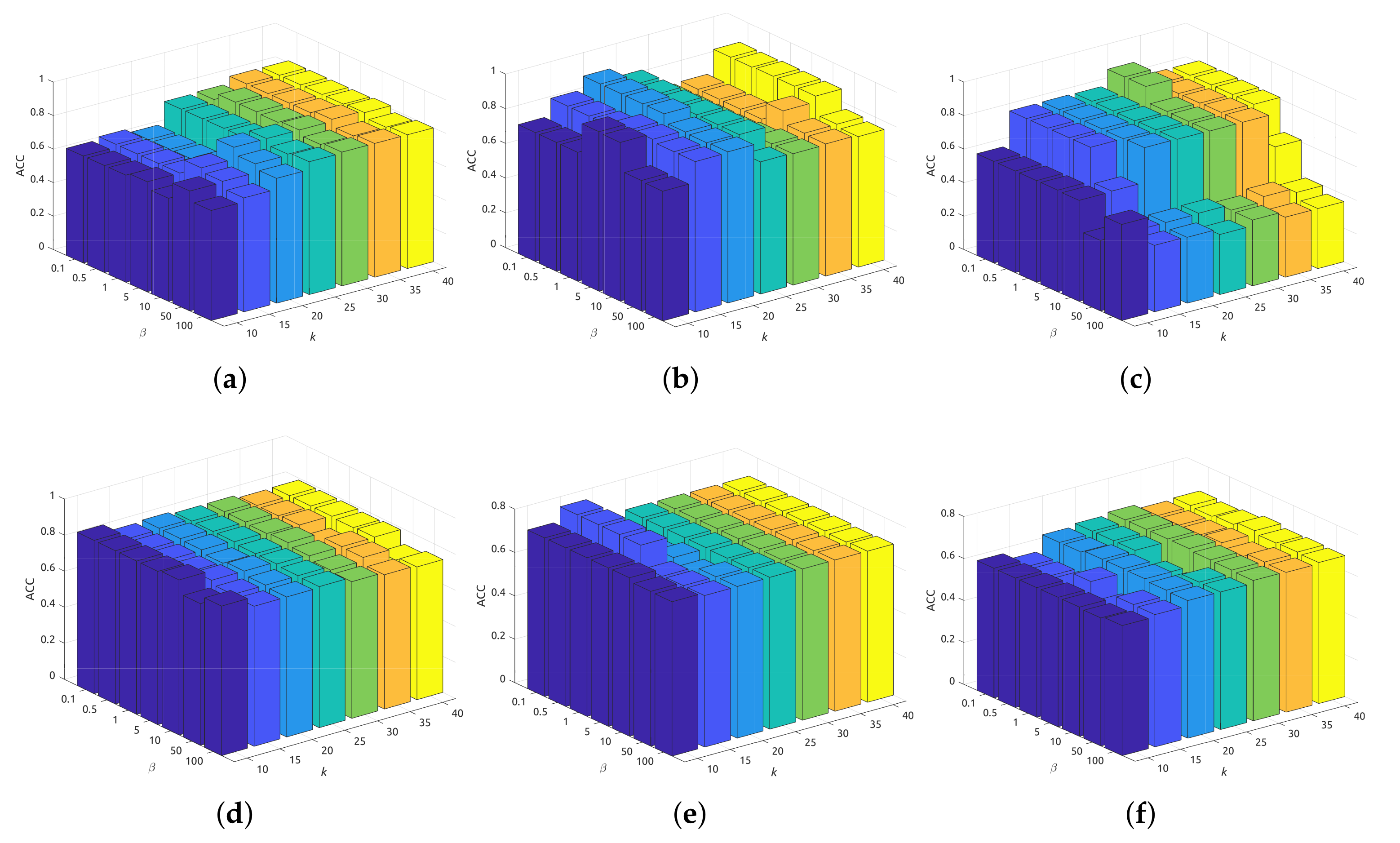
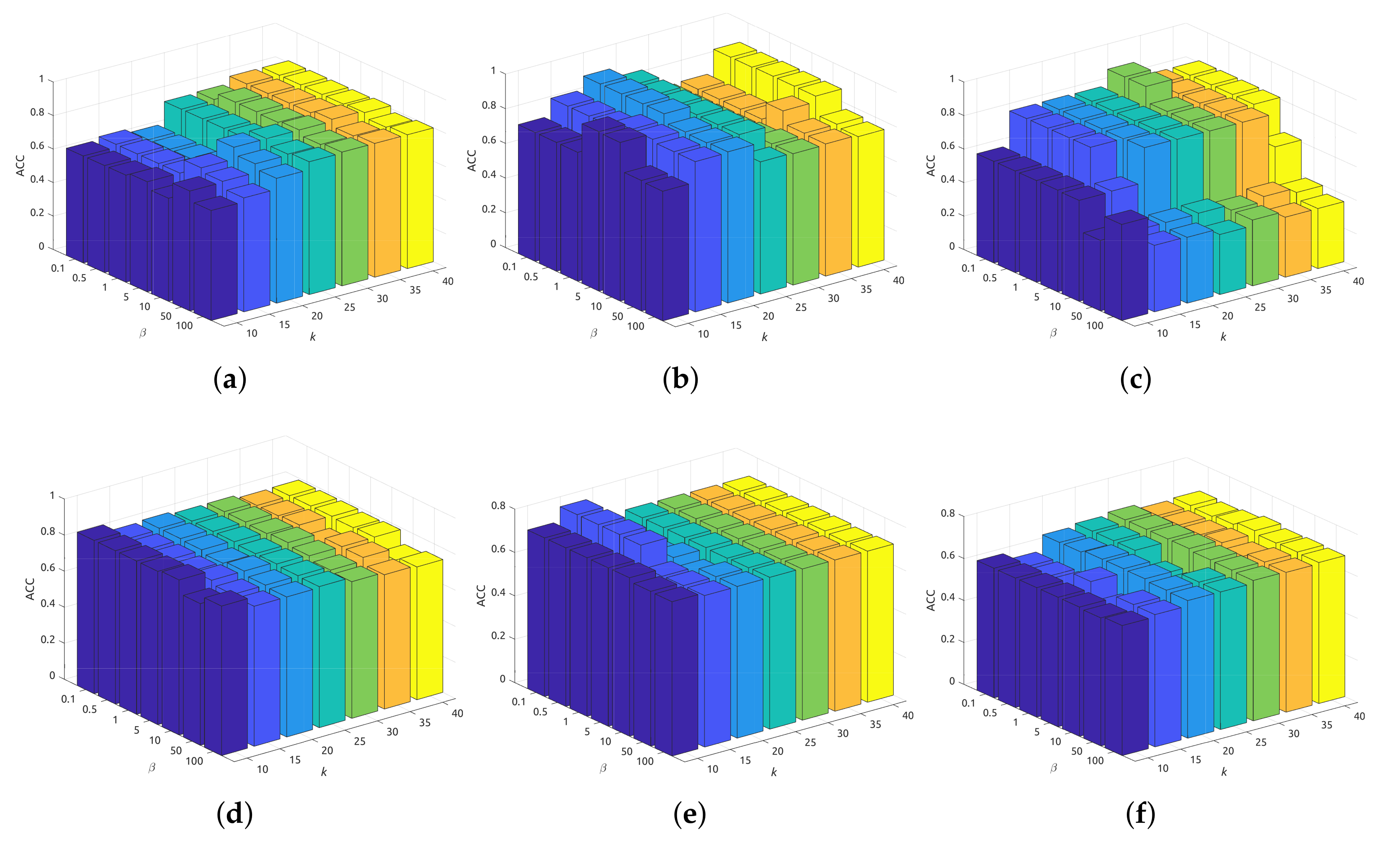
5.2. Sensitivity Analysis
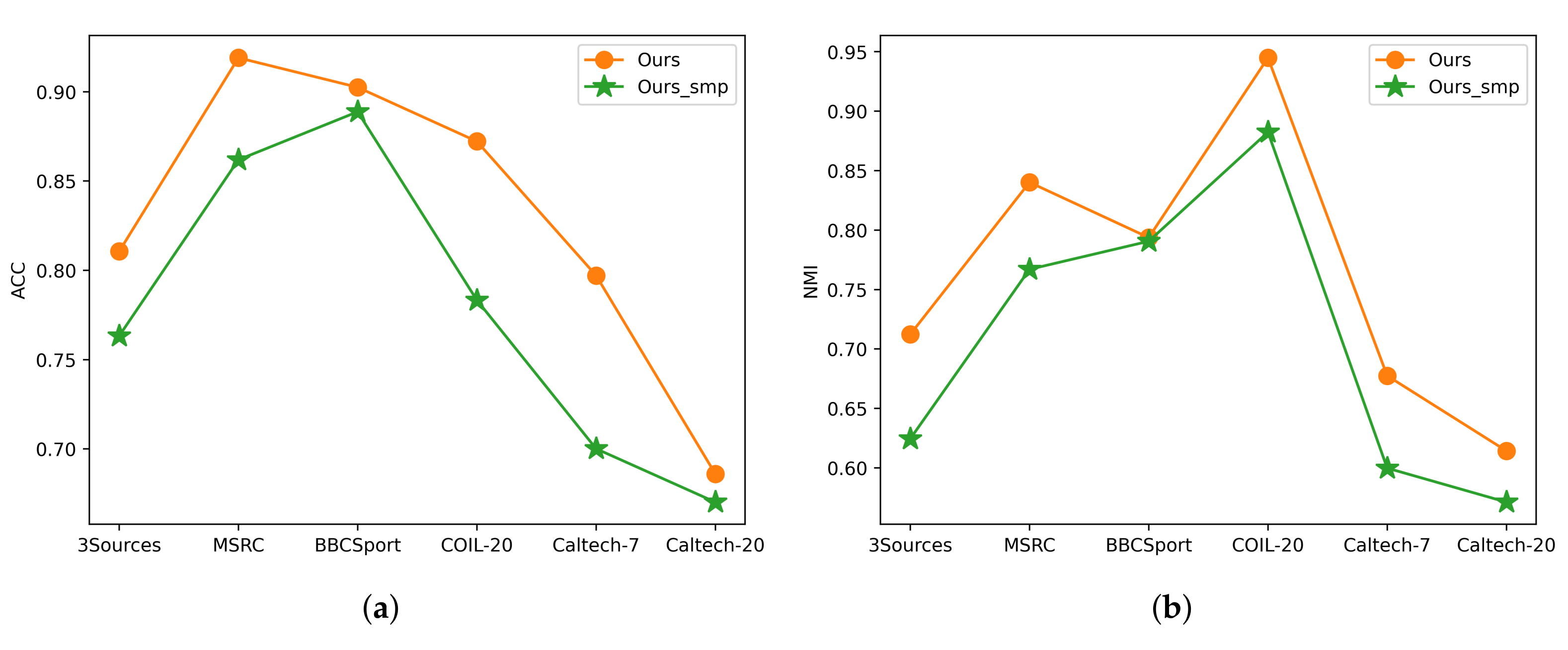
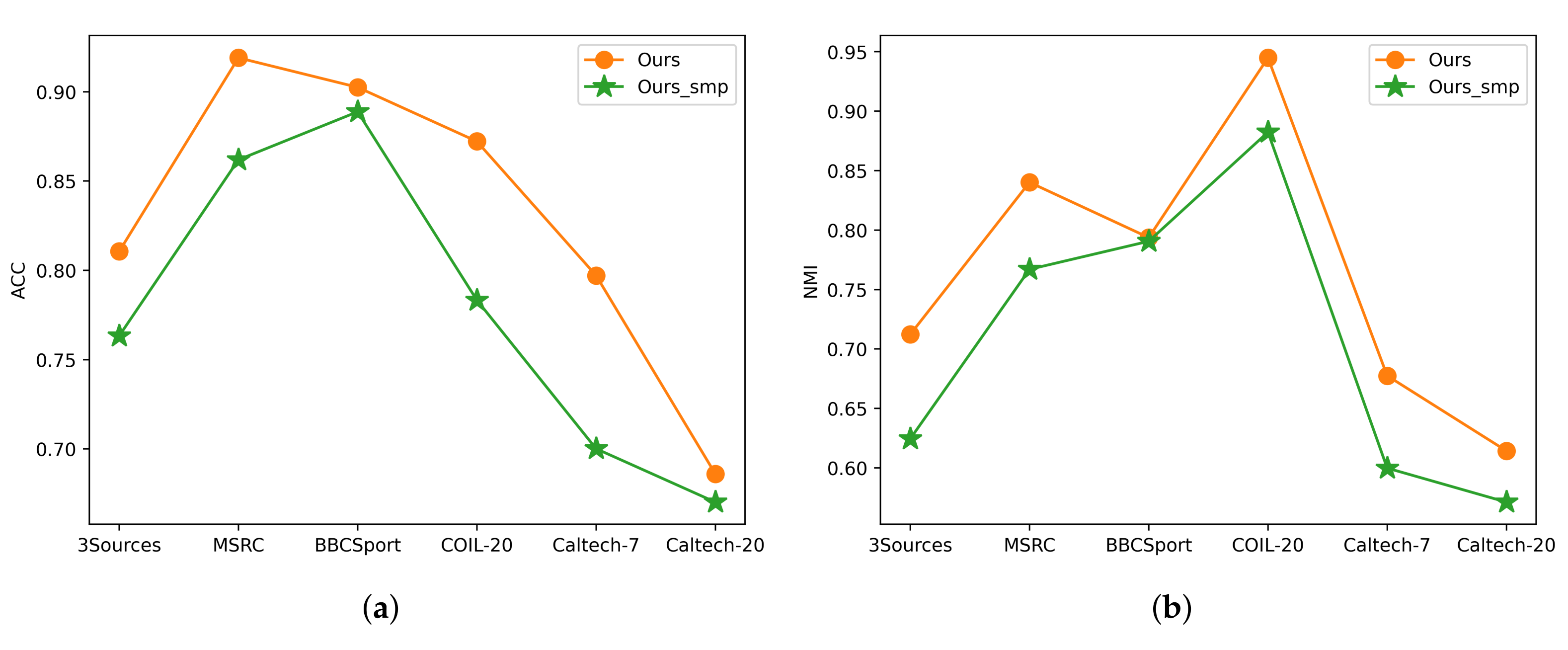
5.3. Ablation Study
5.4. Computational Performance
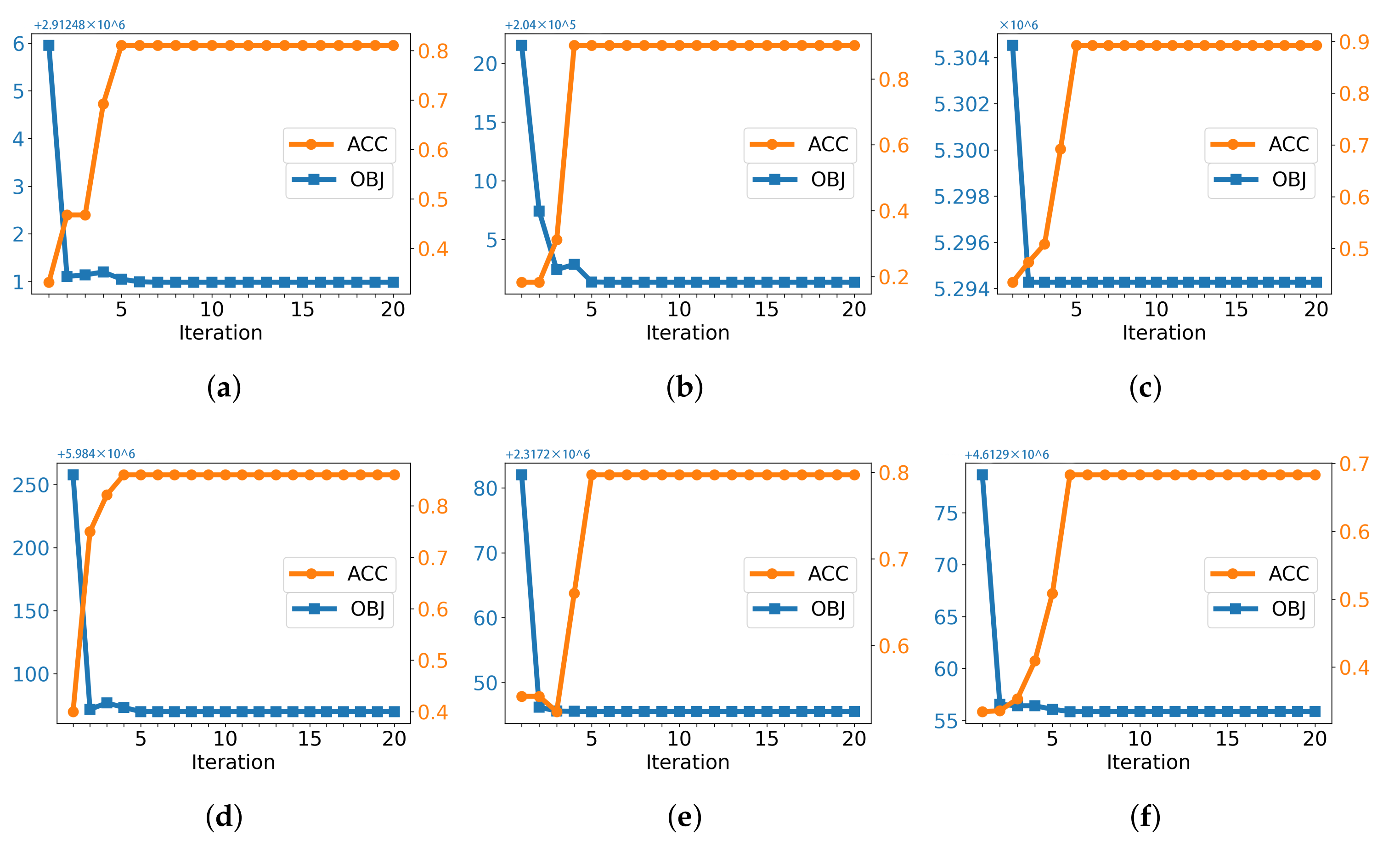
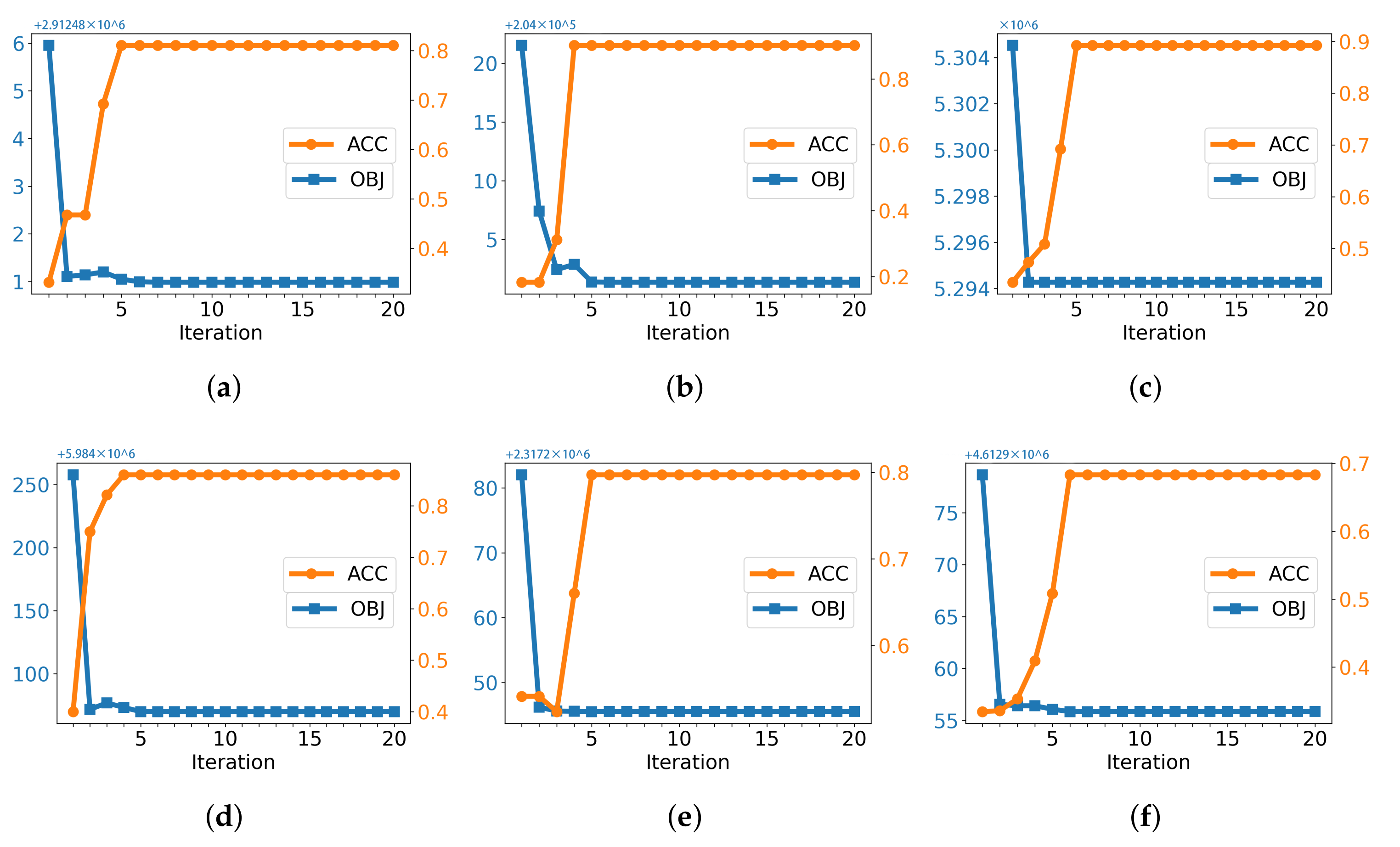
5.5. Convergence Study
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Tang, C.; Zhu, X.; Liu, X.; Li, M.; Wang, P.; Zhang, C.; Wang, L. Learning a Joint Affinity Graph for Multiview Subspace Clustering. IEEE Trans. Multimed. 2019, 21, 1724–1736. [Google Scholar] [CrossRef]
- Zhang, C.; Fu, H.; Hu, Q.; Cao, X.; Xie, Y.; Tao, D.; Xu, D. Generalized latent multi-view subspace clustering. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 42, 86–99. [Google Scholar] [CrossRef] [PubMed]
- Fan, S.; Wang, X.; Shi, C.; Lu, E.; Lin, K.; Wang, B. One2multi graph autoencoder for multi-view graph clustering. In Proceedings of the Web Conference 2020, Taipei, Taiwan, 20–24 April 2020; pp. 3070–3076. [Google Scholar]
- Liu, J.; Liu, X.; Yang, Y.; Guo, X.; Kloft, M.; He, L. Multiview Subspace Clustering via Co-Training Robust Data Representation. IEEE Trans. Neural Networks Learn. Syst. 2021, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Jiang, R.; Yin, D.; Wang, Z.; Wang, Y.; Deng, J.; Liu, H.; Cai, Z.; Deng, J.; Song, X.; Shibasaki, R. DL-Traff: Survey and Benchmark of Deep Learning Models for Urban Traffic Prediction. In Proceedings of the 30th ACM International Conference on Information & Knowledge Management, Gold Coast, Australia, 1–5 November 2021; pp. 4515–4525. [Google Scholar]
- Wu, H.; Lv, J.; Wang, J. Automatic Cataract Detection with Multi-Task Learning. In Proceedings of the International Joint Conference on Neural Networks, Shenzhen, China, 18–22 July 2021; pp. 1–8. [Google Scholar]
- Nie, F.; Li, J.; Li, X. Self-weighted multiview clustering with multiple graphs. In Proceedings of the IJCAI, Melbourne, Australia, 19–25 August 2017; pp. 2564–2570. [Google Scholar]
- Wang, X.; Fan, S.; Kuang, K.; Shi, C.; Liu, J.; Wang, B. Decorrelated clustering with data selection bias. In Proceedings of the IJCAI, Yokohama, Japan, 11–17 July 2020. [Google Scholar]
- Kang, Z.; Shi, G.; Huang, S.; Chen, W.; Pu, X.; Zhou, J.T.; Xu, Z. Multi-graph fusion for multi-view spectral clustering. Knowl.-Based Syst. 2020, 189, 105102. [Google Scholar] [CrossRef] [Green Version]
- Nie, F.; Wang, X.; Huang, H. Clustering and projected clustering with adaptive neighbors. In Proceedings of the KDD, New York, NY, USA, 24–27 August 2014; pp. 977–986. [Google Scholar]
- Zhan, K.; Zhang, C.; Guan, J.; Wang, J. Graph learning for multiview clustering. IEEE Trans. Cybern. 2017, 48, 2887–2895. [Google Scholar] [CrossRef] [PubMed]
- Nie, F.; Cai, G.; Li, X. Multi-View Clustering and Semi-Supervised Classification with Adaptive Neighbours. In Proceedings of the AAAI, San Francisco, CA, USA, 4–9 February 2017; pp. 2408–2414. [Google Scholar]
- Zhuge, W.; Nie, F.; Hou, C.; Yi, D. Unsupervised single and multiple views feature extraction with structured graph. IEEE Trans. Knowl. Data Eng. 2017, 29, 2347–2359. [Google Scholar] [CrossRef]
- Wang, H.; Yang, Y.; Liu, B. GMC: Graph-based Multi-view Clustering. IEEE Trans. Knowl. Data Eng. 2020, 32, 1116–1129. [Google Scholar] [CrossRef]
- Zhan, K.; Nie, F.; Wang, J.; Yang, Y. Multiview consensus graph clustering. IEEE Trans. Image Process. 2018, 28, 1261–1270. [Google Scholar] [CrossRef] [PubMed]
- Li, Z.; Tang, C.; Liu, X.; Zheng, X.; Yue, G.; Zhang, W.; Zhu, E. Consensus Graph Learning for Multi-view Clustering. IEEE Trans. Multimed. 2021, 24, 2461–2472. [Google Scholar] [CrossRef]
- Wen, J.; Yan, K.; Zhang, Z.; Xu, Y.; Wang, J.; Fei, L.; Zhang, B. Adaptive graph completion based incomplete multi-view clustering. IEEE Trans. Multimed. 2020, 23, 2493–2504. [Google Scholar] [CrossRef]
- Tkachenko, R.; Izonin, I. Model and principles for the implementation of neural-like structures based on geometric data transformations. In Proceedings of the International Conference on Computer Science, Engineering and Education Applications, Kiev, Ukraine, 18–20 January 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 578–587. [Google Scholar]
- Tkachenko, R. An Integral Software Solution of the SGTM Neural-Like Structures Implementation for Solving Different Data Mining Tasks. In Proceedings of the International Scientific Conference “Intellectual Systems of Decision Making and Problem of Computational Intelligence”, Zalizny Port, Ukraine, 24–28 May 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 696–713. [Google Scholar]
- Roweis, S.T.; Saul, L.K. Nonlinear dimensionality reduction by locally linear embedding. Science 2000, 290, 2323–2326. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, Z.; Wang, J.; Zha, H. Adaptive manifold learning. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 34, 253–265. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Minh, H.Q.; Bazzani, L.; Murino, V. A unifying framework in vector-valued reproducing kernel hilbert spaces for manifold regularization and co-regularized multi-view learning. J. Mach. Learn. Res. 2016, 17, 1–72. [Google Scholar]
- Wang, Q.; Chen, M.; Li, X. Quantifying and detecting collective motion by manifold learning. In Proceedings of the AAAI, San Francisco, CA, USA, 4–9 February 2017; pp. 4292–4298. [Google Scholar]
- Huang, S.; Tsang, I.; Xu, Z.; Lv, J.C. Measuring Diversity in Graph Learning: A Unified Framework for Structured Multi-view Clustering. IEEE Trans. Knowl. Data Eng. 2021, 1–15. [Google Scholar] [CrossRef]
- Nie, F.; Li, J.; Li, X. Parameter-free auto-weighted multiple graph learning: A framework for multiview clustering and semi-supervised classification. In Proceedings of the IJCAI, New York, NY, USA, 9–15 July 2016; pp. 1881–1887. [Google Scholar]
- Huang, S.; Kang, Z.; Tsang, I.W.; Xu, Z. Auto-weighted multi-view clustering via kernelized graph learning. Pattern Recognit. 2019, 88, 174–184. [Google Scholar] [CrossRef]
- Fan, K. On a theorem of Weyl concerning eigenvalues of linear transformations I. Proc. Natl. Acad. Sci. USA 1949, 35, 652–655. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Huang, J.; Nie, F.; Huang, H. A new simplex sparse learning model to measure data similarity for clustering. In Proceedings of the IJCAI, Buenos Aires, Argentina, 25–31 July 2015; pp. 3569–3575. [Google Scholar]
- Bertsekas, D.P. Nonlinear programming. J. Oper. Res. Soc. 1997, 48, 334. [Google Scholar] [CrossRef]
- Bazaraa, M.S.; Sherali, H.D.; Shetty, C.M. Nonlinear Programming: Theory and Algorithms; John Wiley & Sons: Hoboken, NJ, USA, 2013. [Google Scholar]
- Nie, F.; Huang, H.; Cai, X.; Ding, C.H. Efficient and robust feature selection via joint ℓ2,1-norms minimization. In Proceedings of the Advances in Neural Information Processing Systems, Virtual, 6–12 December 2010; pp. 1813–1821. [Google Scholar]
- Nie, F.; Tian, L.; Li, X. Multiview clustering via adaptively weighted procrustes. In Proceedings of the KDD, London, UK, 19–23 August 2018; pp. 2022–2030. [Google Scholar]
- Zong, L.; Zhang, X.; Liu, X.; Yu, H. Weighted multi-view spectral clustering based on spectral perturbation. In Proceedings of the AAAI, New Orleans, LA, USA, 2–7 February 2018; pp. 4621–4628. [Google Scholar]
- Luo, S.; Zhang, C.; Zhang, W.; Cao, X. Consistent and Specific Multi-View Subspace Clustering. In Proceedings of the AAAI, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Zhang, P.; Liu, X.; Xiong, J.; Zhou, S.; Zhao, W.; Zhu, E.; Cai, Z. Consensus One-step Multi-view Subspace Clustering. IEEE Trans. Knowl. Data Eng. 2020. [Google Scholar] [CrossRef]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Steps | Calculation | Complexity |
|---|---|---|
| Equation (10) | update | |
| Algorithm 1 | update | |
| Equation (22) | c eigenvectors of | |
| Equation (6) | view weight | |
| Total | ||
| Data Set | n | m | c | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 3Sources | 169 | 3 | 6 | 3560 | 3631 | 3068 | – | – | – |
| MSRC | 210 | 5 | 7 | 24 | 576 | 512 | 256 | 254 | – |
| BBCSport | 544 | 2 | 5 | 3183 | 3203 | – | – | – | – |
| COIL-20 | 1440 | 3 | 20 | 1024 | 3304 | 6750 | – | – | – |
| Caltech-7 | 1474 | 6 | 7 | 48 | 40 | 254 | 1984 | 512 | 928 |
| Caltech-20 | 2386 | 6 | 20 | 48 | 40 | 254 | 1984 | 512 | 928 |
| Dataset | SwMC | MLAN | AWP | WMSC | MCGC | CSMSC | GMC | COMSC | CGL | Ours |
|---|---|---|---|---|---|---|---|---|---|---|
| ACC | ||||||||||
| 3Sources | 39.64 | 79.88 | 54.44 | 57.81 | 56.80 | 78.28 | 69.23 | 57.22 | 56.27 | 81.06 |
| MSRC | 72.38 | 51.48 | 63.33 | 68.81 | 74.86 | 80.48 | 74.76 | 80.48 | 81.90 | 91.90 |
| BBCSport | 35.85 | 87.50 | 59.74 | 35.29 | 47.13 | 82.35 | 80.70 | 47.50 | 79.78 | 90.25 |
| COIL-20 | 86.39 | 75.28 | 66.46 | 76.08 | 77.22 | 72.94 | 79.10 | 65.42 | 56.57 | 87.22 |
| Caltech-7 | 40.77 | 63.30 | 58.96 | 38.89 | 55.22 | 63.49 | 69.20 | 58.30 | 61.47 | 79.71 |
| Caltech-20 | 55.11 | 53.91 | 51.55 | 33.43 | 47.53 | 47.22 | 45.64 | 42.17 | 54.82 | 68.60 |
| NMI | ||||||||||
| 3Sources | 11.81 | 64.12 | 45.88 | 49.20 | 34.21 | 70.71 | 54.80 | 39.70 | 61.91 | 71.23 |
| MSRC | 71.78 | 45.24 | 54.88 | 59.30 | 70.18 | 71.43 | 74.21 | 69.91 | 74.43 | 84.02 |
| BBCSport | 11.51 | 76.52 | 43.06 | 20.94 | 22.01 | 68.22 | 72.26 | 27.88 | 71.92 | 79.37 |
| COIL-20 | 94.29 | 83.06 | 78.24 | 83.90 | 89.86 | 83.61 | 91.89 | 76.54 | 76.07 | 94.49 |
| Caltech-7 | 23.38 | 54.66 | 46.25 | 28.07 | 47.00 | 54.35 | 60.56 | 37.28 | 54.16 | 67.75 |
| Caltech-20 | 47.02 | 59.00 | 57.90 | 41.66 | 54.57 | 58.17 | 38.46 | 42.97 | 60.62 | 61.43 |
| Purity | ||||||||||
| 3Sources | 44.38 | 80.47 | 63.31 | 71.54 | 65.09 | 83.61 | 74.56 | 64.97 | 76.33 | 84.61 |
| MSRC | 77.14 | 52.43 | 63.33 | 71.19 | 80.95 | 80.48 | 79.05 | 79.52 | 81.90 | 91.90 |
| BBCSport | 36.58 | 87.50 | 66.54 | 42.10 | 47.13 | 82.35 | 84.38 | 52.06 | 83.64 | 94.11 |
| COIL-20 | 89.86 | 76.41 | 68.13 | 77.76 | 82.92 | 76.01 | 84.79 | 71.86 | 62.51 | 90.00 |
| Caltech-7 | 56.24 | 88.74 | 83.04 | 79.58 | 82.97 | 87.84 | 88.47 | 76.07 | 86.50 | 88.60 |
| Caltech-20 | 67.98 | 77.12 | 73.39 | 67.19 | 68.65 | 78.11 | 55.49 | 62.37 | 78.92 | 77.66 |
| F-score | ||||||||||
| 3Sources | 35.95 | 72.67 | 42.46 | 50.66 | 51.58 | 73.09 | 60.47 | 51.88 | 55.56 | 75.10 |
| MSRC | 66.19 | 46.47 | 53.76 | 57.29 | 69.68 | 70.13 | 72.46 | 68.70 | 71.87 | 84.33 |
| BBCSport | 38.35 | 84.27 | 47.42 | 30.23 | 48.70 | 74.09 | 79.43 | 41.21 | 78.32 | 88.38 |
| COIL-20 | 84.44 | 71.68 | 63.15 | 72.80 | 75.57 | 69.84 | 79.20 | 57.12 | 51.69 | 85.26 |
| Caltech-7 | 45.98 | 61.87 | 61.83 | 37.76 | 58.78 | 63.91 | 72.17 | 52.21 | 62.63 | 82.98 |
| Caltech-20 | 38.98 | 45.26 | 53.43 | 30.21 | 40.17 | 42.24 | 34.03 | 36.26 | 49.34 | 55.79 |
| Dataset | SwMC | MLAN | AWP | WMSC | MCGC | CSMSC | GMC | COMSC | CGL | Ours |
|---|---|---|---|---|---|---|---|---|---|---|
| 3Sources | 0.51 | 0.11 | 0.08 | 0.16 | 0.50 | 0.19 | 0.22 | 27.29 | 0.34 | 0.66 |
| MSRC | 1.05 | 0.12 | 0.09 | 0.19 | 0.22 | 0.08 | 0.29 | 29.31 | 0.58 | 0.84 |
| BBCSport | 2.67 | 0.90 | 0.45 | 0.61 | 1.00 | 0.85 | 0.76 | 103.04 | 1.66 | 1.99 |
| COIL-20 | 192.25 | 13.48 | 8.41 | 12.98 | 16.03 | 9.85 | 11.15 | 2015.47 | 26.08 | 10.94 |
| Caltech-7 | 143.45 | 13.15 | 16.60 | 50.01 | 17.31 | 6.78 | 12.62 | 3493.87 | 54.16 | 19.89 |
| Caltech-20 | 679.34 | 66.75 | 74.00 | 224.91 | 78.76 | 27.28 | 39.94 | 12484.65 | 201.20 | 75.11 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, P.; Wu, H.; Huang, S. Multi-View Graph Clustering by Adaptive Manifold Learning. Mathematics 2022, 10, 1821. https://doi.org/10.3390/math10111821
Zhao P, Wu H, Huang S. Multi-View Graph Clustering by Adaptive Manifold Learning. Mathematics. 2022; 10(11):1821. https://doi.org/10.3390/math10111821
Chicago/Turabian StyleZhao, Peng, Hongjie Wu, and Shudong Huang. 2022. "Multi-View Graph Clustering by Adaptive Manifold Learning" Mathematics 10, no. 11: 1821. https://doi.org/10.3390/math10111821
APA StyleZhao, P., Wu, H., & Huang, S. (2022). Multi-View Graph Clustering by Adaptive Manifold Learning. Mathematics, 10(11), 1821. https://doi.org/10.3390/math10111821