
The Application of Machine Learning to Educational Process Data Analysis: A Systematic Review



Abstract
1. Introduction
- RQ1. Which type of process data is the most used based on the current literature?
- RQ2. What specific measurement issues can be effectively addressed through the use of process data?
- RQ3. How can ML approaches be employed to fully leverage the information derived from process data?
2. Materials and Methods
2.1. Definition of Process Data
2.2. Operational Definition of Machine Learning
2.3. Literature Search Strategy
2.4. Inclusion and Exclusion Criteria
3. Results
3.1. Research Landscape Analysis
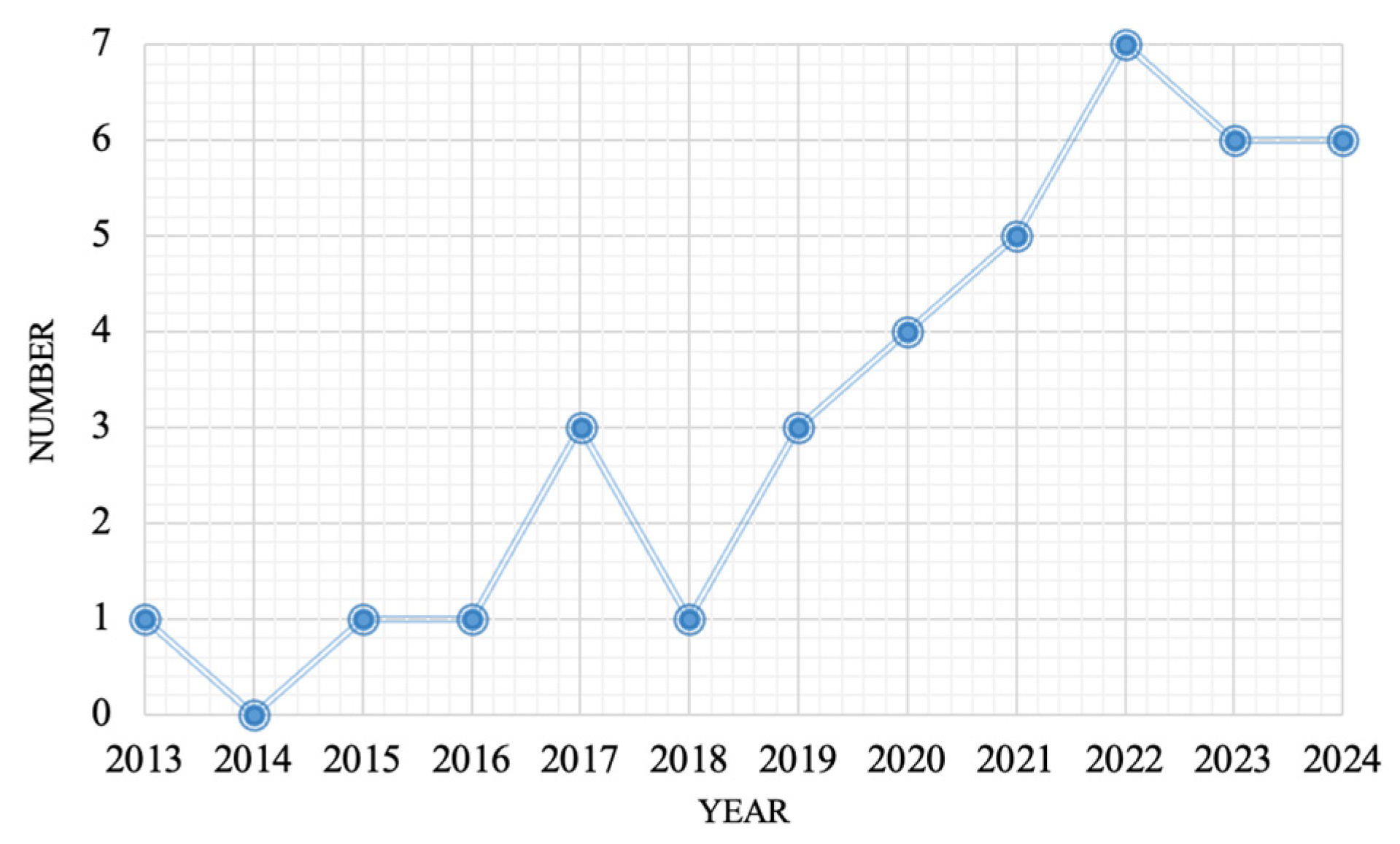
3.1.1. Demographic Trends
3.1.2. Thematic Mapping
3.2. Research Questions
3.2.1. RQ1: Which Type of Process Data Is the Most Used Based on the Current Literature?
3.2.2. RQ2: What Specific Measurement Issues Can Be Effectively Addressed Through the Use of Process Data?
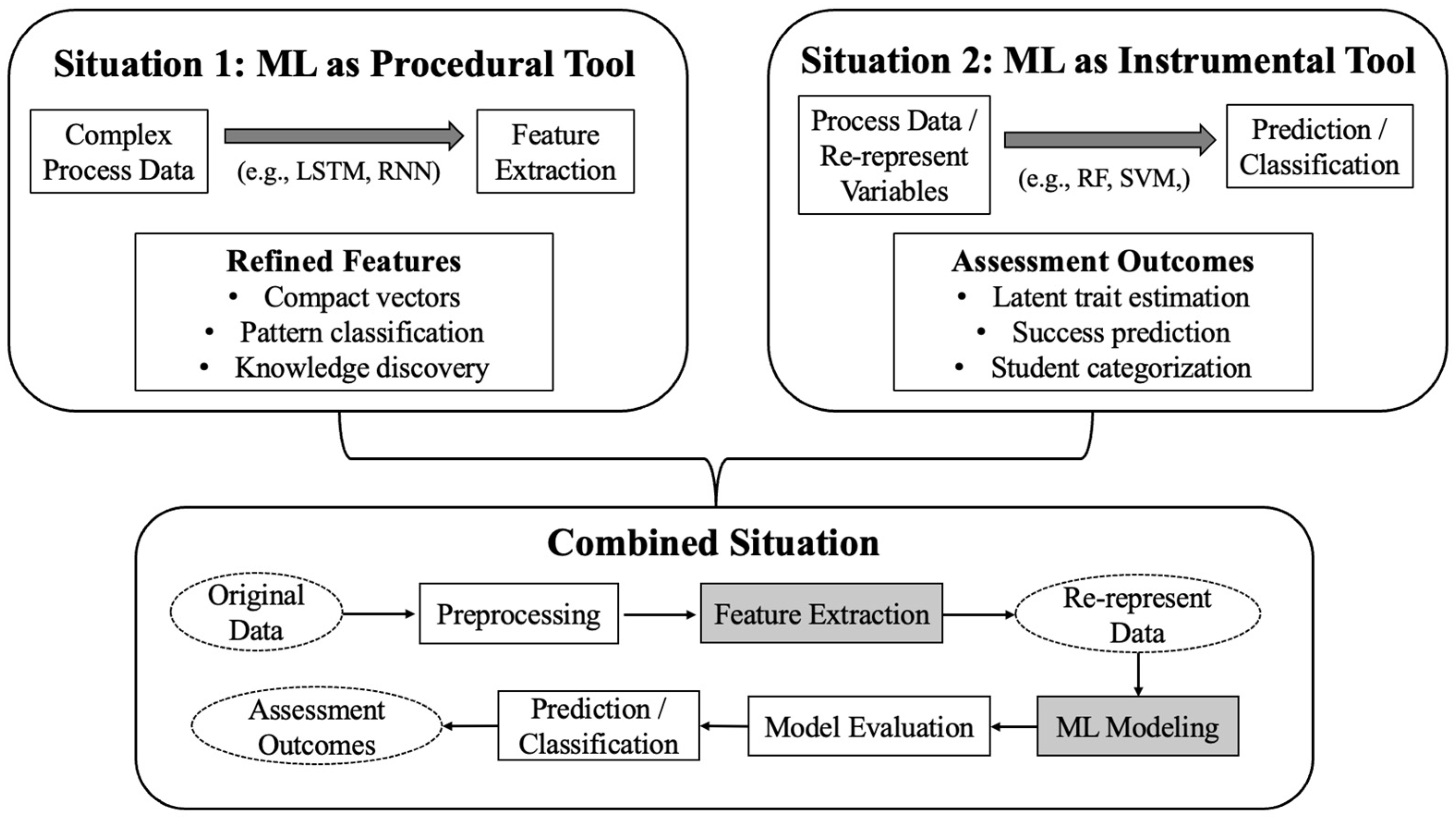
3.2.3. RQ3: How Can ML Approaches Be Employed to Fully Leverage the Information Derived from Process Data?
4. Discussion
4.1. Challenges and Opportunities in This Field
4.1.1. Challenges for Feature Extraction or Selection
4.1.2. Challenges for Estimation and Results Analysis
4.2. Implications for Future Studies
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
| Ref. 1 | PD 2 Type | ML 3 Methods | Research Aims/ML Functions | Competency/Fulfilled |
| Salles et al. (2020) | Clickstream | RF, DBSCAN, K-means, K-means++ | Determining predictive power of models and most predictive features and categorizing students’ mathematical strategic behaviors and procedures | Mathematics |
| S. Li et al. (2021) | Clickstream | LSTM, GRU | Characterizing temporary knowledge state; Knowledge tracing | Knowledge Tracking |
| Singh (2023) | Clickstream | SVM, DT, KNN | Predicting students’ academic performance | Innovation |
| Rohani et al. (2024) | Clickstream | ClickTree, CatBoost | Predicting students’ scores | Mathematics |
| Qiu et al. (2022) | Clickstream | SVC, NB, KNN | Predicting online students’ behavior classification | Learning performance on 7 course modules |
| Tang et al. (2021) | Clickstream | RNN, LSTM, GRU | Creating an autoencoder to extract features | Problem-solving ability |
| Guo et al. (2024) | Clickstream and Response Time | LSTM, RF, SVM | Compressing the input sequential data and categorizing students into different process profiles | Mathematics |
| Chen and Cui (2020) | Clickstream | LSTM | Predicting learning outcomes and analyzing the learner and item-skill associations | Mathematics |
| Wang et al. (2023) | Clickstream | RNN, GRU, HMM, eHMM | Predicting action sequences to decompose each response process into several subprocesses and identify corresponding subtasks | Problem-solving strategies |
| Han et al. (2019) | Clickstream | RF | Selecting features | Problem-solving ability |
| Liao and Wu (2022) | Clickstream | RF, SVM, FCNN, LSTM | Categorizing discourse into statistics-relevant or -irrelevant messages | Learning engagement |
| Ludwig et al. (2024) | Clickstream and Keystroke | RF | Predicting students’ problem-solving success | Scenario-based problem-solving ability |
| Sun et al. (2019) | Clickstream | CART, SVM | Predicting students’ correct answers; Knowledge tracing | Knowledge Tracking |
| Bosch and Paquett (2017) | Clickstream | DNN, RNN, VAE, CNN, ANS | Extracting embedded representations (embeddings) | Learning engagement |
| Cao et al. (2020) | Keystroke Logging | CART | Evaluating the effectiveness of key predictors on differentiating students’ writing performance | Scenario-based writing processes |
| Ahadi et al. (2015) | Keystroke Logging | NB, BN, DT, RF, DS | Detecting high- and low-performing students | Programming ability in Java |
| Fernández-Fontelo et al. (2023) | Mouse Movement | DT, RF, GBM, DNN, SVM | Prediction for item difficulty | Employment research items |
| Richters et al. (2023) | Clickstream | SVC, RF, GBM | Predicting diagnostic accuracy | Collaborative diagnostic reasoning ability |
| Guan et al. (2022) | Eye Tracking | DT, RF | Characterizing the predictive effect of behavior indicators on reading performance | English reading skill |
| Pejić and Molcer (2021) | Clickstream | NB, LR, DT, RF, GBM. | Predicting the outcome of the Climate Control problem-solving task | Problem-solving ability |
| Sinharay et al. (2019) | Keystroke Logging | CART, SGBM | Predicting essay scores | Writing process ability |
| Ulitzsch et al. (2023) | Clickstream | XGBoost | Predicting the risk of failure at an early stage on interactive tasks | Problem-solving ability |
| Xu et al. (2020) | Clickstream | HBCM | Clustering the event types | Problem-solving ability |
| Schroeders et al. (2022) | Response Time | SGBM | Identifying careless respondents | Careless/aberrant responding |
| N. Zhang et al. (2022) | Clickstream | AST, SPM | Predicting students’ computational model-building performance and assessing students learning behaviors | Strategic Learning Behaviors |
| Sabourin et al. (2013) | Clickstream | DBN | Detecting whether students’ off-task behaviors are cases of emotional self-regulation | Learning engagement |
| Levin (2021) | Clickstream | XGBoost | Categorizing students based on whether they would use their time efficiently | Mathematics |
| Bosch (2021) | Clickstream | TSFRESH, Featuretools, CART, ET | Extracting predictive and unique features | Mathematics |
| J. Zhang et al. (2022) | Clickstream | XGBoost, LR, Lasso, DT, RF | Detecting self-regulated behaviors automatically; predicting the presence or absence of the self-regulated learning constructs | Mathematics |
| Hoq et al. (2024) | Clickstream | Stacked Ensemble Model (KNN, SVM, XGBoost) | Predicting final programming exam grades | Programming |
| Ohmoto et al. (2024) | Multimodal | SVM | Predicting participants’ interactive-constructive-active-passive state | Collaborative state |
| Lu et al. (2024) | Clickstream | Unsupervised ML (SVD et al.) Ensemble Learning (SVC, RF et al.) | Conducting dimension reduction and identifying intersectional latent variables across feature sets and categorizing students into “Low” and “High” groups | Problem-solving ability |
| Al-Azazi and Ghurab (2023) | Clickstream | LSTM | Predicting the class of student performance | Learning performance on 7 course modules |
| Petkovic et al. (2016) | Clickstream | RF | Predicting the effectiveness of software engineering teamwork learning and discovering factors that contribute to prediction | Student learning effectiveness in software engineering teamwork |
| Bertović et al. (2022) | Clickstream | SVC, RF, LR, Gaussian NB, DT | Predicting students’ grades | Programming ability in Python |
| Yu et al. (2018) | Clickstream | RNN, LSTM, GRU | Predicting the next URL for each student | Learning pathways |
| Pardos et al. (2017) | Clickstream | RNN, LSTM | Modeling navigation behavior and predicting the most likely next course URL | Self-regulated learning |
| Y. Li et al. (2017) | Clickstream | NN, RNN, SVM | Predicting learners’ state for the next two consecutive weeks | Course engagement |
| Note: 1 Ref. means reference. 2 PD means process data. 3 ML means machine learning. For the ML (machine learning) methods, NN is neural network, NB is naive Bayes, BN is Bayesian network, DBN is dynamic Bayesian network, DNN is deep neural network, RNN is recurrent neural network, KNN is K-nearest neighbor, VAE is variational autoencoder, CNN is convolutional neural network, ANS is asymmetric network structure, HMM is hidden Markov model, eHMM is an extension of HMM, AST is abstract syntax tree, SPM is sequential pattern mining, SVC is support vector classifier, RF is random forest, ET is extra tree, LSTM is long short-term memory, GRU is gate recurrent unit, GBM is gradient boosting machine, SGBM is stochastic gradient boosting machine, FCNN is fully connected neural network, DT is decision tree, XGBoost is extreme gradient boosting, CART is classification and regression tree, LR is logistic regression, DBSCAN is density-based spatial clustering of applications with noise, DS is decision stump, DKT is deep knowledge tracing, TSFRESH is time series feature extraction on the basis of scalable hypothesis testing, HBCM is a hierarchical Bayesian continuous-time model, and SVD is singular value decomposition. | ||||
References
- Ahadi, A., Lister, R., Haapala, H., & Vihavainen, A. (2015, August 9–13). Exploring machine learning methods to automatically identify students in need of assistance. Eleventh Annual International Conference on International Computing Education Research (pp. 121–130), Omaha, NE, USA. [Google Scholar]
- Al-Azazi, F. A., & Ghurab, M. (2023). ANN-LSTM: A deep learning model for early student performance prediction in MOOC. Heliyon, 9(4), e15382. [Google Scholar] [CrossRef]
- Alsuwaiket, M., Blasi, A. H., & Al-Msie’deen, R. F. (2020). Formulating module assessment for improved academic performance predictability in higher education. arXiv, arXiv:2008.13255. [Google Scholar] [CrossRef]
- Baker, R., Xu, D., Park, J., Yu, R., Li, Q., Cung, B., Fischer, C., Rodriguez, F., Warschauer, M., & Smyth, P. (2020). The benefits and caveats of using clickstream data to understand student self-regulatory behaviors: Opening the black box of learning processes. International Journal of Educational Technology in Higher Education, 17, 1–24. [Google Scholar] [CrossRef]
- Bertović, D., Mravak, M., Nikolov, K., & Vidović, N. (2022, September 22–24). Using moodle test scores to predict success in an online course. 2022 International Conference on Software, Telecommunications and Computer Networks (SoftCOM) (pp. 1–7), Split, Croatia. [Google Scholar]
- Bleidorn, W., & Hopwood, C. J. (2019). Using machine learning to advance personality assessment and theory. Personality and Social Psychology Review, 23(2), 190–203. [Google Scholar] [CrossRef] [PubMed]
- Bosch, N. (2021). AutoML feature engineering for student modeling yields high accuracy, but limited interpretability. Journal of Educational Data Mining, 13(2), 55–79. [Google Scholar]
- Bosch, N., & Paquette, L. (2017, June 25–28). Unsupervised deep autoencoders for feature extraction with educational data. Deep Learning with Educational Data Workshop at the 10th International Conference on Educational Data Mining, Wuhan, China. [Google Scholar]
- Cao, Y., Chen, J., Zhang, M., & Li, C. (2020). Examining the writing processes in scenario—Based assessment using regression trees. ETS Research Report Series, 2020(1), 1–16. [Google Scholar] [CrossRef]
- Cetintas, S., Si, L., Xin, Y. P., & Hord, C. (2009, July 1–3). Predicting correctness of problem solving from low-level log data in intelligent tutoring systems. 2nd International Working Group on Educational Data Mining, Cordoba, Spain. Available online: https://files.eric.ed.gov/fulltext/ED539041.pdf (accessed on 7 May 2025).
- Chang, H. H., Wang, C., & Zhang, S. (2021). Statistical applications in educational measurement. Annual Review of Statistics and Its Application, 8(1), 439–461. [Google Scholar] [CrossRef]
- Chen, F., & Cui, Y. (2020). LogCF: Deep collaborative filtering with process data for enhanced learning outcome modeling. Journal of Educational Data Mining, 12(4), 66–99. [Google Scholar]
- Estacio, R. R., & Raga, R. C., Jr. (2017). Analyzing students online learning behavior in blended courses using Moodle. Asian Association of Open Universities Journal, 12(1), 52–68. [Google Scholar] [CrossRef]
- Fernández-Fontelo, A., Kieslich, P. J., Henninger, F., Kreuter, F., & Greven, S. (2023). Predicting question difficulty in web surveys: A machine learning approach based on mouse movement features. Social Science Computer Review, 41(1), 141–162. [Google Scholar] [CrossRef]
- Gardner, J., O’Leary, M., & Yuan, L. (2021). Artificial intelligence in educational assessment: ‘Breakthrough? Or buncombe and ballyhoo?’. Journal of Computer Assisted Learning, 37(5), 1207–1216. [Google Scholar] [CrossRef]
- Guan, X., Lei, C., Huang, Y., Chen, Y., Du, H., Zhang, S., & Feng, X. (2022, March 21–23). An analysis of reading process based on real-time eye-tracking data with web-camera—Focus on English reading at higher education level. Proceedings of the 4th Workshop on Predicting Performance Based on the Analysis of Reading Behavior, California, CA, USA. [Google Scholar]
- Guo, H., Johnson, M., Ercikan, K., Saldivia, L., & Worthington, M. (2024). Large-scale assessments for learning: A human-centred AI approach to contextualizing test performance. Journal of Learning Analytics, 11(2), 229–245. [Google Scholar] [CrossRef]
- Han, Z., He, Q., & Von Davier, M. (2019). Predictive feature generation and selection using process data from PISA interactive problem-solving items: An application of random forests. Frontiers in Psychology, 10, 2461. [Google Scholar] [CrossRef]
- Hao, J., Smith, L., Mislevy, R., von Davier, A., & Bauer, M. (2016). Taming log files from game/simulation—Based assessments: Data models and data analysis tools. ETS Research Report Series, 2016(1), 1–17. [Google Scholar] [CrossRef]
- Hilbert, S., Coors, S., Kraus, E., Bischl, B., Lindl, A., Frei, M., Wild, J., Krauss, S., Goretzko, D., & Stachl, C. (2021). Machine learning for the educational sciences. Review of Education, 9(3), e3310. [Google Scholar] [CrossRef]
- Hoq, M., Brusilovsky, P., & Akram, B. (2024). Explaining explainability: Early performance prediction with student programming pattern profiling. Journal of Educational Data Mining, 16(2), 115–148. [Google Scholar]
- Levin, N. A. (2021). Process mining combined with expert feature engineering to predict efficient use of time on high-stakes assessments. Journal of Educational Data Mining, 13(2), 1–15. [Google Scholar]
- Li, S., Xu, L., Wang, Y., & Xu, L. (2021, September 24–26). Self-learning tags and hybrid responses for deep knowledge tracing. Web Information Systems and Applications: 18th International Conference, WISA 2021 (Proceedings 18) (pp. 121–132), Kaifeng, China. [Google Scholar]
- Li, Y., Fu, C., & Zhang, Y. (2017, June 25–28). When and who at risk? Call back at these critical points. Proceedings of the International Educational Data Mining Society (pp. 25–28), Wuhan, China. [Google Scholar]
- Liao, C. H., & Wu, J. Y. (2022). Deploying multimodal learning analytics models to explore the impact of digital distraction and peer learning on student performance. Computers & Education, 190, 104599. [Google Scholar]
- Lu, W., Laffey, J., Sadler, T., Griffin, J., & Goggins, S. (2024). A scalable, flexible, and interpretable analytic pipeline for stealth assessment in complex digital game-based learning environments: Towards generalizability. Journal of Educational Data Mining, 16(2), 214–303. [Google Scholar]
- Ludwig, S., Rausch, A., Deutscher, V., & Seifried, J. (2024). Predicting problem-solving success in an office simulation applying N-grams and a random forest to behavioral process data. Computers & Education, 218, 105093. [Google Scholar]
- Mongeon, P., & Paul-Hus, A. (2016). The journal coverage of Web of Science and Scopus: A comparative analysis. Scientometrics, 106, 213–228. [Google Scholar] [CrossRef]
- Ohmoto, Y., Shimojo, S., Morita, J., & Hayashi, Y. (2024). Estimation of ICAP states based on interaction data during collaborative learning. Journal of Educational Data Mining, 16(2), 149–176. [Google Scholar]
- Page, M. J., McKenzie, J. E., Bossuyt, P. M., Boutron, I., Hoffmann, T. C., Mulrow, C. D., Shamseer, L., Tetzlaff, J. M., Akl, E. A., Brennan, S. E., Chou, R., Glanville, J., Grimshaw, J. M., Hróbjartsson, A., Lalu, M. M., Li, T., Loder, E. W., Mayo-Wilson, E., McDonald, S., … Moher, D. (2021). The PRISMA 2020 statement: An updated guideline for reporting systematic reviews. BMJ, 372, n71. [Google Scholar] [CrossRef]
- Pardos, Z. A., Tang, S., Davis, D., & Le, C. V. (2017, April 20–21). Enabling real-time adaptivity in MOOCs with a personalized next-step recommendation framework. Proceedings of the Fourth (2017) ACM Conference on Learning@ Scale (pp. 23–32), Cambridge, MA, USA. [Google Scholar]
- Pejić, A., & Molcer, P. S. (2021). Predictive machine learning approach for complex problem solving process data mining. Acta Polytechnica Hungarica, 18(1), 45–63. [Google Scholar] [CrossRef]
- Petkovic, D., Sosnick-Pérez, M., Okada, K., Todtenhoefer, R., Huang, S., Miglani, N., & Vigil, A. (2016, October 12–15). Using the random forest classifier to assess and predict student learning of software engineering teamwork. 2016 IEEE Frontiers in Education Conference (FIE) (pp. 1–7), Eire, PA, USA. [Google Scholar]
- Qiu, F., Zhang, G., Sheng, X., Jiang, L., Zhu, L., Xiang, Q., Jiang, B., & Chen, P. K. (2022). Predicting students’ performance in e-learning using learning process and behaviour data. Scientific Reports, 12(1), 453. [Google Scholar] [CrossRef] [PubMed]
- Requena, B., Cassani, G., Tagliabue, J., Greco, C., & Lacasa, L. (2020). Shopper intent prediction from clickstream e-commerce data with minimal browsing information. Scientific Reports, 10(1), 16983. [Google Scholar] [CrossRef]
- Richters, C., Stadler, M., Radkowitsch, A., Schmidmaier, R., Fischer, M. R., & Fischer, F. (2023). Who is on the right track? Behavior-based prediction of diagnostic success in a collaborative diagnostic reasoning simulation. Large-Scale Assessments in Education, 11(1), 3. [Google Scholar] [CrossRef]
- Rohani, N., Rohani, B., & Manataki, A. (2024). ClickTree: A tree-based method for predicting math students’ performance based on clickstream data. arXiv, arXiv:2403.14664. [Google Scholar]
- Sabourin, J. L., Rowe, J. P., Mott, B. W., & Lester, J. C. (2013). Considering alternate futures to classify off-task behavior as emotion self-regulation: A supervised learning approach. Journal of Educational Data Mining, 5(1), 9–38. [Google Scholar]
- Salles, F., Dos Santos, R., & Keskpaik, S. (2020). When didactics meet data science: Process data analysis in large-scale mathematics assessment in France. Large-Scale Assessments in Education, 8(1), 7. [Google Scholar] [CrossRef]
- Schroeders, U., Schmidt, C., & Gnambs, T. (2022). Detecting careless responding in survey data using stochastic gradient boosting. Educational and Psychological Measurement, 82(1), 29–56. [Google Scholar] [CrossRef] [PubMed]
- Singh, S. N. (2023, May 11–12). Creativity: Mining of innovative thinking using educational data. 2023 International Conference on Disruptive Technologies (ICDT) (pp. 445–449), Greater Noida, India. [Google Scholar]
- Sinharay, S., Zhang, M., & Deane, P. (2019). Prediction of essay scores from writing process and product features using data mining methods. Applied Measurement in Education, 32(2), 116–137. [Google Scholar] [CrossRef]
- Sun, X., Zhao, X., Ma, Y., Yuan, X., He, F., & Feng, J. (2019, May 17–19). Muti-behavior features based knowledge tracking using decision tree improved DKVMN. ACM Turing Celebration Conference-China (pp. 1–6), Chengdu, China. [Google Scholar]
- Tang, X., Wang, Z., He, Q., Liu, J., & Ying, Z. (2020). Latent feature extraction for process data via multidimensional scaling. Psychometrika, 85(2), 378–397. [Google Scholar] [CrossRef]
- Tang, X., Wang, Z., Liu, J., & Ying, Z. (2021). An exploratory analysis of the latent structure of process data via action sequence autoencoders. British Journal of Mathematical and Statistical Psychology, 74(1), 1–33. [Google Scholar] [CrossRef]
- Ulitzsch, E., Ulitzsch, V., He, Q., & Lüdtke, O. (2023). A machine learning-based procedure for leveraging clickstream data to investigate early predictability of failure on interactive tasks. Behavior Research Methods, 55(3), 1392–1412. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z., Tang, X., Liu, J., & Ying, Z. (2023). Subtask analysis of process data through a predictive model. British Journal of Mathematical and Statistical Psychology, 76(1), 211–235. [Google Scholar] [CrossRef] [PubMed]
- Wei, S., Lei, Q., Chen, Y., & Xin, Y. P. (2023). The Effects of visual cueing on students with and without math learning difficulties in online problem solving: Evidence from eye movement. Behavioral Sciences, 13(11), 927. [Google Scholar] [CrossRef]
- Xu, H., Fang, G., & Ying, Z. (2020). A latent topic model with Markov transition for process data. British Journal of Mathematical and Statistical Psychology, 73(3), 474–505. [Google Scholar] [CrossRef]
- Yu, R., Jiang, D., & Warschauer, M. (2018, June 26–28). Representing and predicting student navigational pathways in online college courses. Fifth Annual ACM Conference on Learning at Scale (pp. 1–4), London, UK. [Google Scholar]
- Zhang, J., Andres, J. M. A. L., Hutt, S., Baker, R. S., Ocumpaugh, J., Nasiar, N., Mills, C., Brooks, J., Sethuaman, S., & Young, T. (2022). Using machine learning to detect SMART model cognitive operations in mathematical problem-solving process. Journal of Educational Data Mining, 14(3), 76–108. [Google Scholar]
- Zhang, N., Biswas, G., & Hutchins, N. (2022). Measuring and analyzing students’ strategic learning behaviors in open-ended learning environments. International Journal of Artificial Intelligence in Education, 32, 931–970. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, J.; Xin, Y.P.; Chang, H.H. The Application of Machine Learning to Educational Process Data Analysis: A Systematic Review. Educ. Sci. 2025, 15, 888. https://doi.org/10.3390/educsci15070888
Huang J, Xin YP, Chang HH. The Application of Machine Learning to Educational Process Data Analysis: A Systematic Review. Education Sciences. 2025; 15(7):888. https://doi.org/10.3390/educsci15070888
Chicago/Turabian StyleHuang, Jing, Yan Ping Xin, and Hua Hua Chang. 2025. "The Application of Machine Learning to Educational Process Data Analysis: A Systematic Review" Education Sciences 15, no. 7: 888. https://doi.org/10.3390/educsci15070888
APA StyleHuang, J., Xin, Y. P., & Chang, H. H. (2025). The Application of Machine Learning to Educational Process Data Analysis: A Systematic Review. Education Sciences, 15(7), 888. https://doi.org/10.3390/educsci15070888