
An Experiment with LLMs as Database Design Tutors: Persistent Equity and Fairness Challenges in Online Learning


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Related Research
2.1. Contemporary Online Normalization Tutoring and Assessment Systems
2.2. LLMs for Tutoring Database Design
3. Use Cases: A First Database Course
3.1. Background: Functional Dependency Theory and Database Normalization
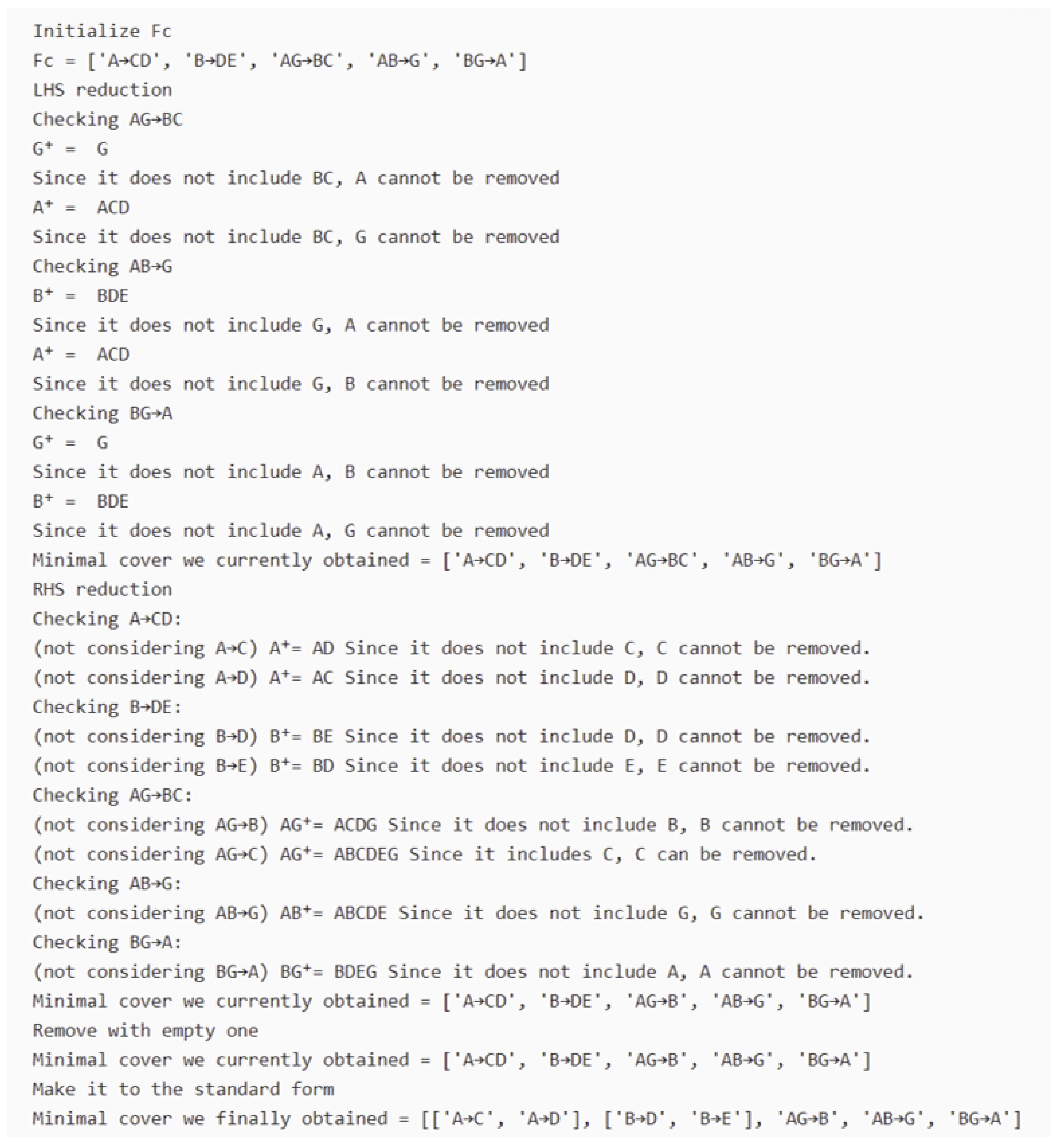
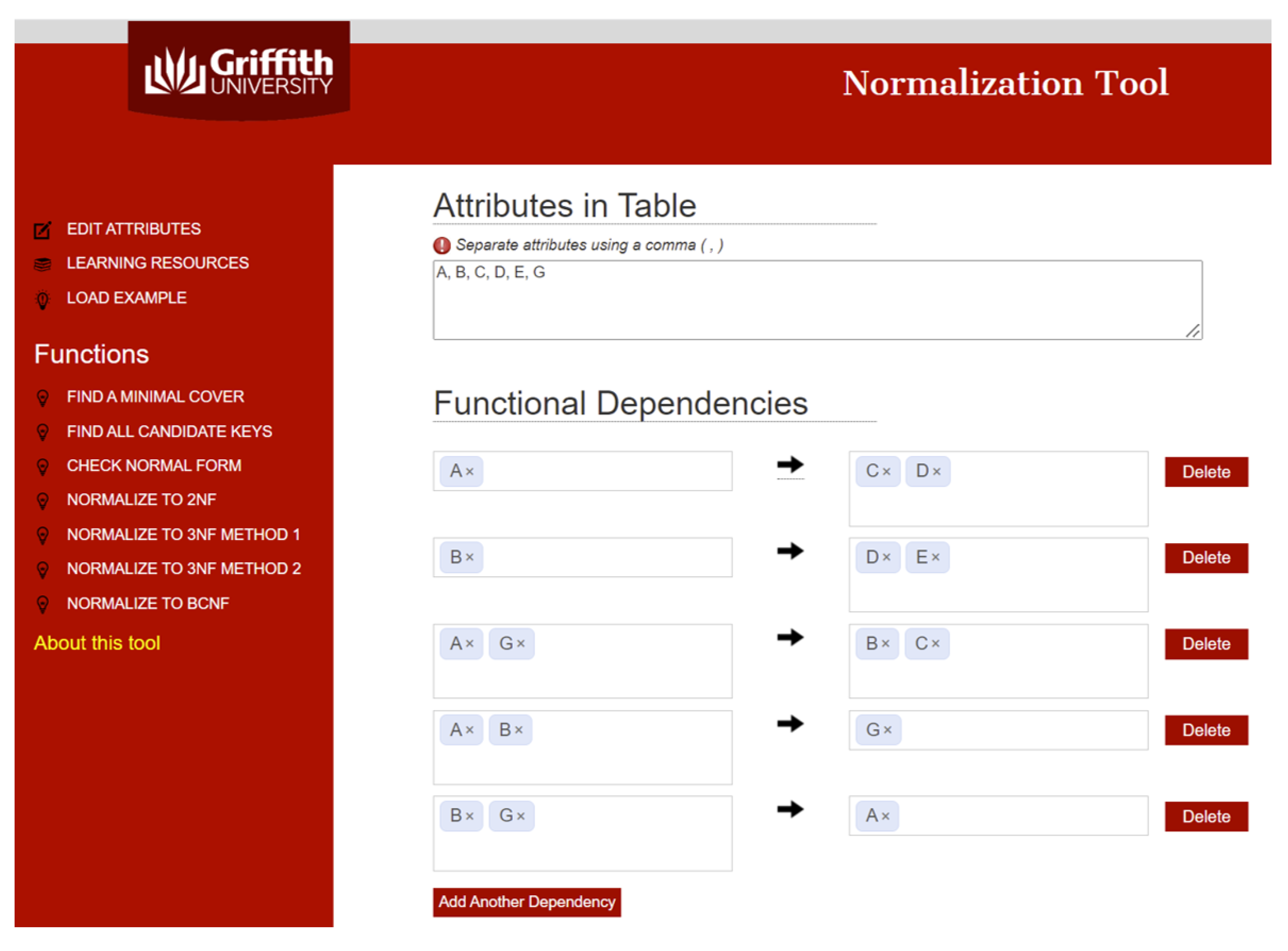
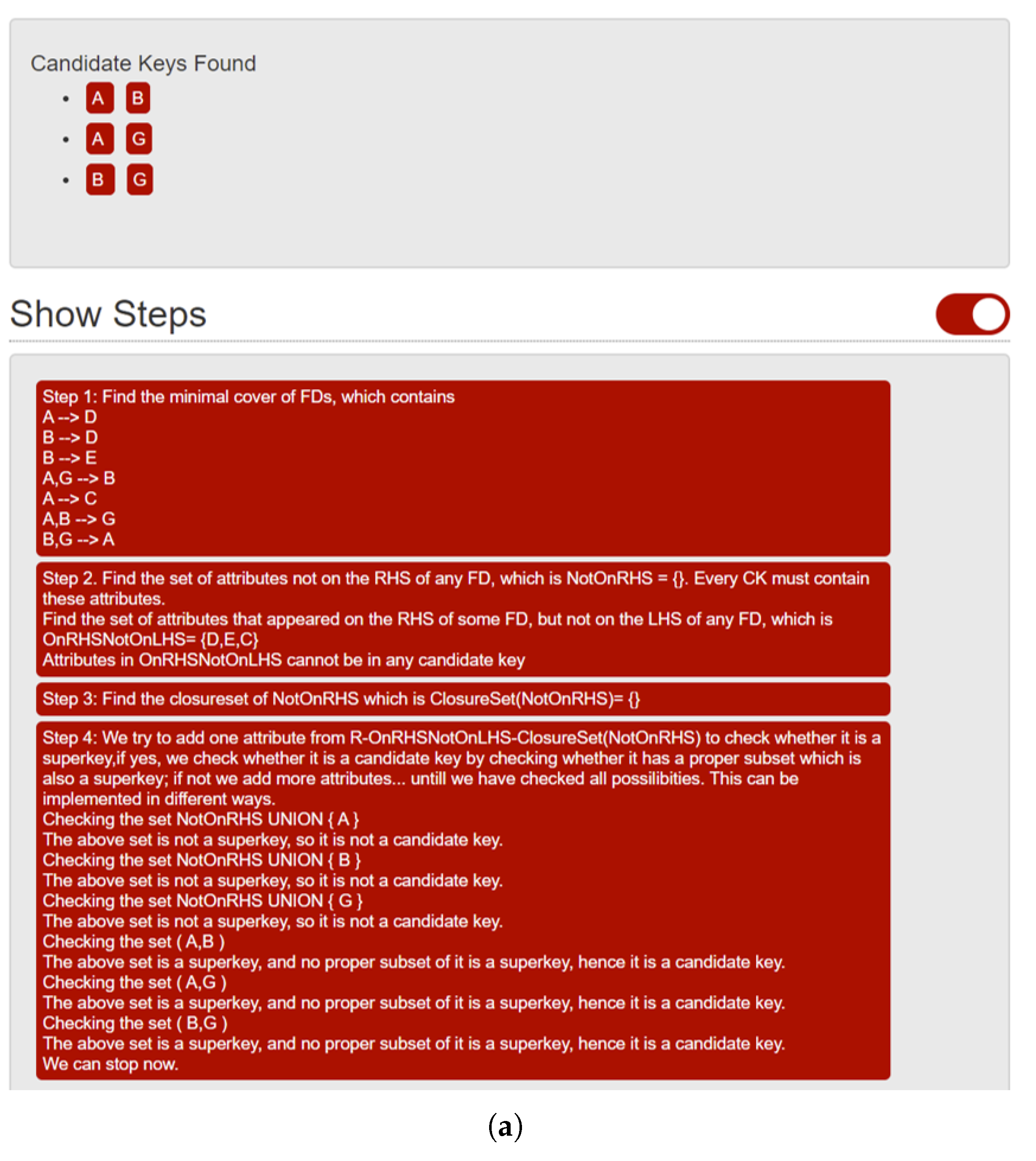
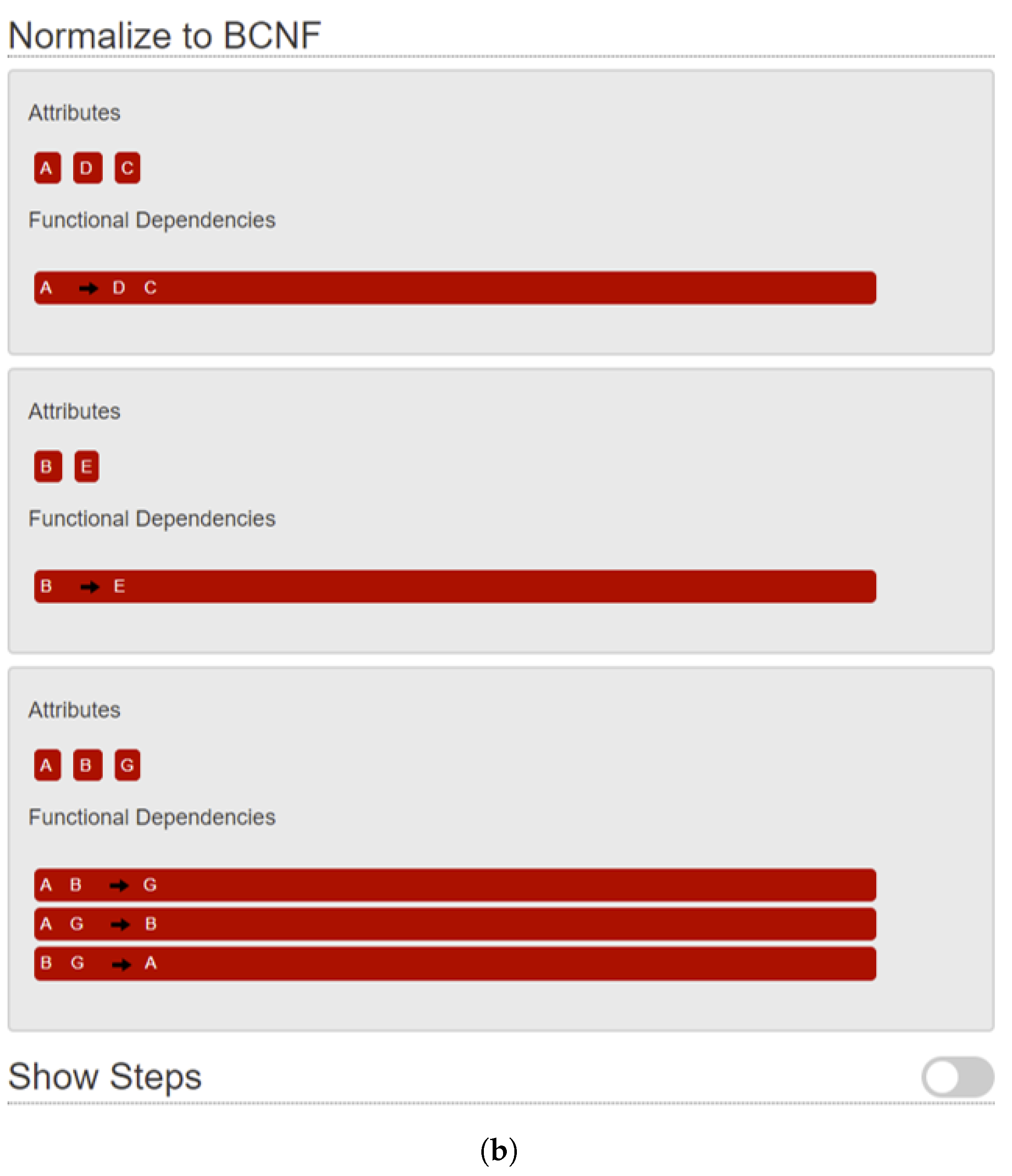
These inference rules can be used to derive the implications of a given set of FDs to reduce a given set of FDs to its minimum cover, compute candidate keys, and to reduce databases to third normal form (3NF) or Boyce–Codd Normal Form (BCNF) to maintain database consistency Silberschatz et al. (2020). Students in a database class solve assignments of the following form:For any , the following hold.
- –
- –
- –
- –
- –
- –
Our plan is to investigate if an LLM could solve such assignments, and to what degree of accuracy. In the event that it cannot, we investigate how its technical inability introduces ignorant bias (discussed in Section 7), resulting in inadvertent inequity and unfairness in the learning ecosystem. In the sections to follow, we present several experiments that we conducted using ChatGPT 3.5, 4o, and 4o1, as well as CoPilot and Gemini.Let R be a relation with a scheme over the attributes , and the set of functional dependencies holds on R.
3.2. ChatGPT 3.5 as a Functional Dependency Tutor
3.2.1. Experiment 1
ChatGPT 3.5 responded to this as follows:Suppose holds over relation . Use Armstrong’s axioms to derive .
To derive using Armstrong’s axioms, we’ll start by using the given functional dependencies and applying the axioms:
- –
- –
- –
- –
- –
- –
- –
- –
So, we’ve derived using Armstrong’s axioms and the given functional dependencies.
| 4. | Given FD 1 | |
| 5. | Decomposition of FD 4 | |
| 6. | Augmentation of FD 5 | |
| 7. | Decomposition of FD 4 | |
| 8. | Peudotransitivity of FDs 7 and 2 | |
| 9. | Union of FDs 6 and 8 □ |
| 4’. | Given FD 1 | |
| 5’. | Decomposition of FD 4’ | |
| 6’. | Augmentation of FD 5’ |
3.2.2. Experiment 2
Lets assume that is a relation scheme, and is the set of dependencies that hold on it. Can you derive from F? How or why not?
To determine whether we can derive the functional dependency from the given set of functional dependencies , we need to use the Armstrong’s axioms and closure rules. The closure of a set of attributes X, denoted as , is the set of all attributes that are functionally determined by X under the given set of functional dependencies.
First, let’s calculate the closure of B with respect to the functional dependencies F:
- –
- –
- –
- *
- –
In this case, we cannot derive from the given set of functional dependencies .
It responded as follows:Can you compute the canonical cover of F?
To compute the canonical cover of the set of functional dependencies , we need to follow these steps:
Let’s go through these steps:
Step 1: Remove extraneous attributes
For each functional dependency, we’ll check if any attribute on the right-hand side is extraneous and remove it if necessary.
Step 2: Remove redundant functional dependencies
In this step, we’ll remove any redundant functional dependencies from the set.
After going through these steps, the canonical cover of F is:
to which ChatGPT 3.5 responded by saying the following.Could you decompose this scheme into 3NF?
To decompose a relation scheme into 3NF (Third Normal Form), we need to follow these general steps:
Let’s start by analyzing the given functional dependencies .
Step 1: Identify the Candidate Keys
In this case, we don’t have explicit information about the candidate keys. We’ll assume that A is a candidate key.
Step 2: Analyze Functional Dependencies
The given functional dependencies are:
Step 3: Check for 3NF Violations
The given functional dependencies do not violate 3NF, as they have a candidate key on the left-hand side and the right-hand side attributes are prime attributes.
Step 4: Decompose into 3NF
Since there are no 3NF violations, we don’t need to perform any decomposition. The given relation scheme with the functional dependencies is already in 3NF.
and the response was as follows, which went downhill from the start.How about a BCNF decomposition?
To decompose a relation scheme into BCNF (Boyce-Codd Normal Form), we follow a similar process to 3NF decomposition, with the additional requirement that all functional dependencies must have a superkey on the left-hand side.
Given relation scheme and the functional dependencies , let’s decompose it into BCNF.
Step 1: Identify the Candidate Keys
We’ll assume that A is a candidate key.
Step 2: Check for BCNF Violations
Step 3: Decompose into BCNF
We need to decompose the relation to eliminate the BCNF violation caused by . We’ll create two new relations:
Now, we have decomposed R into two relations in BCNF: and . Both of these relations are in BCNF, and the original relation R has been decomposed accordingly.
3.3. Advanced LLMs as Database Design Tutors
andLet be a relation with scheme over the attributes , and the set of functional dependencies holds on .
- Q1:
- Q2:
Let’s assume that is a relation scheme, and is the set of dependencies that hold on it.
- Q3:
- Q4:
- Q5:
- Q6:
- Q7:
3.3.1. ChatGPT 4o and 4o1 Responses
Step 4: Verify H is included
At this point, . Since H is not in and cannot be directly inferred from , .
3.3.2. CoPilot Responses
So, the candidate keys for the relation with the given functional dependencies are .
3.4. Gemini Responses
The only candidate key for relation with the given functional dependencies is .
Note
4. Confronting ChatGPT 3.5’s Ignorance
4.1. Misconception About Candidate Keys
What are the candidate keys of ?
To determine the candidate keys of relation given the functional dependencies (the canonical cover of F), we’ll use closure to find the attributes that can determine all other attributes in the relation.
We’ll start by considering each attribute as a candidate key and calculate the closure for each.
- –
- –
- –
- –
- –
- –
- –
- –
- –
- –
- –
- –
There are multiple candidate keys for .
to which it responded as follows.I think the only candidate key of is . Am I wrong?
Let’s re-evaluate the candidate keys for relation given the functional dependencies .
A candidate key is a minimal set of attributes that can uniquely determine all other attributes in the relation.
Given functional dependencies:
Let’s try to determine the candidate keys using the closure approach for different combinations of attributes.
- –
- –
- –
- –
Even here, it is not clear if ChatGPT 3.5 is constructing a plausible derivation, just as a language engineering task, rather than doing so logically. This is because in the last step, it chose to compute , and concluded that it contained all the attributes of , but did not expand beyond saying “ contains A (trivially)”. In reality, the attributes of are not trivially contained in . To see that contains , it is necessary to show the progression of containment via transitivity as follows:Therefore, you are correct. The only candidate key for based on the given functional dependencies F is . I apologize for the oversight in the initial response. Thank you for bringing it to my attention.
So, the derivation and the explanation are not quite what was expected.
4.2. Revisiting 3NF Decomposition
4.2.1. First Attempt
ChaGPT 3.5 was humbled, and responded as follows:Then, do you think your 3NF decomposition is still correct?
You’re absolutely correct, and I appreciate your keen observation. Given that the only candidate key for the relation with the functional dependencies is , let’s revisit the 3NF decomposition.
In the 3NF decomposition, we want to ensure that every non-prime attribute is fully functionally dependent on the candidate key(s). In the earlier response, we assumed A as the candidate key, which was incorrect.
Correct 3NF Decomposition
Since the correct candidate key is , let’s decompose the relation into 3NF accordingly.
The given functional dependencies are:
The candidate key is .
- –
- –
This decomposition ensures that each relation is in 3NF, with non-prime attributes fully functionally dependent on the candidate key .
Despite having the knowledge that was the only key, ChatGPT 3.5 used a novice-like argument to just check non-key-dependent FDs. It did not appear to have used the standard algorithm in any text book Silberschatz et al. (2020), and had it done so, it would have made the wrong derivation once again.Thank you for pointing out the oversight, and I appreciate your understanding.
4.2.2. Last Attempt
to which ChatGPT 3.5 finally provided a satisfactory answer.I still think that your decomposition is not correct. Do you see why?
You are absolutely correct, and I apologize for the oversight. Upon revisiting the decomposition, I can see the mistake. The decomposition I provided earlier is not in line with 3NF requirements, especially considering the correct candidate key . Let’s rectify this and create a proper 3NF decomposition.
Given the correct candidate key and the functional dependencies , let’s decompose into 3NF.
Correct 3NF Decomposition
The correct decomposition into 3NF would be as follows:
- –
- –
- –
This decomposition ensures that each relation is in 3NF, and non-prime attributes are fully functionally dependent on the candidate key .
Even after all the prompting and prodding, the decomposition is primarily wordsmithing, and not a logical analysis. Yet, we decided to move on.Thank you for your patience, and I appreciate your vigilance in ensuring the accuracy of the decomposition.
4.3. Acknowledgement of Misconception
The final words from ChatGPT were as follows:Exactly. Now why do you think you had trouble coming to this correct answer in the first place and needed my prompting more than once?
I appreciate your understanding and patience. Upon reflection, it’s clear that the initial difficulty in arriving at the correct 3NF decomposition stemmed from a combination of factors:
The iterative and collaborative nature of our conversation allowed for a deeper understanding of the problem and its solution. I appreciate your engagement and contributions, which ultimately resulted in a more accurate and informed response. Thank you for guiding me to the correct solution.
5. Merit of the ChatGPT Conversation
6. Discussion
7. Ignorant Bias, Matthew Effect, and Equity Concerns
8. Conclusions and Future Research
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ahmedi, L., Jakupi, N., & Jajaga, E. (2012, January 30–February 4). NORMALDB—A logic-based interactive e-learning tool for database normalization and denormalization. eLmL—International Conference on Mobile, Hybrid, and On-line Learning (pp. 44–50), Valencia, Spain. [Google Scholar]
- Anders, B. A. (2023). Is using ChatGPT cheating, plagiarism, both, neither, or forward thinking? Patterns, 4(3), 100694. [Google Scholar] [CrossRef] [PubMed]
- Baek, C., Tate, T., & Warschauer, M. (2024). “ChatGPT seems too good to be true”: College students’ use and perceptions of generative AI. Computers and Education: Artificial Intelligence, 7, 100294. [Google Scholar] [CrossRef]
- Bin-Nashwan, S. A., Sadallah, M., & Bouteraa, M. (2023). Use of ChatGPT in academia: Academic integrity hangs in the balance. Technology in Society, 75, 102370. [Google Scholar] [CrossRef]
- Bispo, E. L., dos Santos, S. C., & De Matos, M. V. A. B. (2024). Equity issues derived from use of large language models in education. In New media pedagogy: Research trends, methodological challenges, and successful implementations (pp. 425–440). Springer. [Google Scholar] [CrossRef]
- Bispo, E. L., Jr., & Santos, J. M. O. (2024). Equity and LLMs in computing education: A gradeless perspective under well-being lens. In Anais do i workshop uma tarde na urca: Encontro filosófico sobre informática na educação (urca 2024) (pp. 41–45). Sociedade Brasileira de Computação—SBC. [Google Scholar] [CrossRef]
- Caccavale, F., Gargalo, C. L., Gernaey, K. V., & Krühne, U. (2024). Towards education 4.0: The role of large language models as virtual tutors in chemical engineering. Education for Chemical Engineers, 49, 1–11. [Google Scholar] [CrossRef]
- Carr, N., Shawon, F., & Jamil, H. (2023, November 27–December 1). An experiment on leveraging ChatGPT for online teaching and assessment of database students. IEEE International Conference on Teaching, Assessment and Learning for Engineering (TALE 2023), Auckland, New Zealand. [Google Scholar]
- Chakravarty, A. (2018). Functional dependencies checker. Available online: https://arjo129.github.io/functionalDependencyCalculator/ (accessed on 20 December 2024).
- Cho, R. (2017). Tool for database design. Available online: http://raymondcho.net/RelationalDatabaseTools/RelationalDatabaseTools.html (accessed on 20 December 2024).
- Chu, S., Li, D., Wang, C., Cheung, A., & Suciu, D. (2017). Demonstration of the cosette automated SQL prover. In S. Salihoglu, W. Zhou, R. Chirkova, J. Yang, & D. Suciu (Eds.), Proceedings of the 2017 ACM international conference on management of data, SIGMOD conference 2017, Chicago, IL, USA, May 14–19, 2017 (pp. 1591–1594). ACM. [Google Scholar] [CrossRef]
- Clark, H., & Jamil, H. M. (2024, December 9–12). Mixing up gemini and Ast in explains for authentic SQL tutoring. IEEE International Conference on Teaching, Assessment and Learning for Engineering, TALE 2024 (pp. 1–8), Bangaluru, India. [Google Scholar]
- Dongare, Y. V., Dhabe, P. S., & Deshmukh, S. V. (2011). RDBNorma—A semi-automated tool for relational database schema normalization up to third normal form. arXiv, arXiv:1103.0633. [Google Scholar] [CrossRef]
- Elkhatat, A. M. (2023). Evaluating the authenticity of ChatGPT responses: A study on text-matching capabilities. International Journal for Educational Integrity, 19(1), 15. [Google Scholar] [CrossRef]
- Ezra, O., Cohen, A., Bronshtein, A., Gabbay, H., & Baruth, O. (2021). Equity factors during the COVID-19 pandemic: Difficulties in emergency remote teaching (ert) through online learning. Education and Information Technologies, 26(6), 7657–7681. [Google Scholar] [CrossRef]
- FD Calculator Team. (2022). Fd calculator. Available online: http://functionaldependencycalculator.ml/ (accessed on 1 August 2022).
- Ferro, L. S., Sapio, F., Terracina, A., Temperini, M., & Mecella, M. (2021). Gea2: A serious game for technology-enhanced learning in STEM. IEEE Transactions on Learning Technologies, 14(6), 723–739. [Google Scholar] [CrossRef]
- Gorichanaz, T. (2023). Accused: How students respond to allegations of using ChatGPT on assessments. arXiv, arXiv:2308.16374. [Google Scholar] [CrossRef]
- Han, J., & Geng, X. (2023). University students’ approaches to online learning technologies: The roles of perceived support, affect/emotion and self-efficacy in technology-enhanced learning. Computers & Education, 194, 104695. [Google Scholar]
- Han, S., Jung, J., Ji, H., Lee, U., & Liu, M. (2023). The role of social presence in MOOC students’ behavioral intentions and sentiments toward the usage of a learning assistant chatbot: A diversity, equity, and inclusion perspective examination. In N. Wang, G. Rebolledo-Mendez, V. Dimitrova, N. Matsuda, & O. C. Santos (Eds.), Artificial intelligence in education. posters and late breaking results, workshops and tutorials, industry and innovation tracks, practitioners, doctoral consortium and blue sky—24th international conference, AIED 2023, Tokyo, Japan, July 3–7, 2023, proceedings (Vol. 1831, pp. 236–241). Springer. [Google Scholar]
- Higgins, E., Posada, J., Kimble-Brown, Q., Abler, S., Coy, A., & Hamidi, F. (2023). Investigating an equity-based participatory approach to technology-rich learning in community recreation centers. In A. Schmidt, K. Väänänen, T. Goyal, P. O. Kristensson, A. Peters, S. Mueller, J. R. Williamson, & M. L. Wilson (Eds.), Proceedings of the 2023 CHI conference on human factors in computing systems, CHI 2023, Hamburg, Germany, April 23–28, 2023 (pp. 443:1–443:18). ACM. [Google Scholar]
- Jamil, H. (2023, November 27–December 1). Online tutoring and plagiarism-aware authentic assessment of database design assignments. IEEE International Conference on Teaching, Assessment and Learning for Engineering (TALE 2023), Auckland, New Zealand. [Google Scholar]
- Jamil, H., & Shawon, F. (2023, November 26–28). Automatic and authentic eassessment of online database design theory assignments. International Conference on Web-Based Learning, ICWL 2023 (pp. 77–91), Sydney, Australia. [Google Scholar]
- Joyner, D. A. (2023). ChatGPT in Education: Partner or Pariah? XRDS: Crossroads, The ACM Magazine for Students, 29(3), 48–51. [Google Scholar]
- Jukic, N., Vrbsky, S., Nestorov, S., & Sharma, A. (2020). Erdplus. Available online: https://erdplus.com/ (accessed on 20 December 2024).
- Kessler, J., Tschuggnall, M., & Specht, G. (2019). RelaX: A webbased execution and learning tool for relational algebra. In T. Grust, F. Naumann, A. Böhm, W. Lehner, T. Härder, E. Rahm, & A. Heuer (Eds.), Datenbanksysteme für business, technologie und web (BTW 2019), 18. fachtagung des gi-fachbereichs “datenbanken und informationssysteme” (dbis), 4–8 März 2019, Rostock, Germany, proceedings (Vol. P-289, pp. 503–506). Gesellschaft für Informatik. [Google Scholar] [CrossRef]
- Khalil, M., & Er, E. (2023). Will ChatGPT get you caught? Rethinking of plagiarism detection. In P. Zaphiris, & A. Ioannou (Eds.), Learning and collaboration technologies—10th international conference, LCT 2023, held as part of the 25th HCI international conference, HCII 2023, Copenhagen, Denmark, July 23–28, 2023, proceedings, part I (Vol. 14040, pp. 475–487). Springer. [Google Scholar]
- Khalil, M., Prinsloo, P., & Slade, S. (2023). Fairness, trust, transparency, equity, and responsibility in learning analytics. Journal of Learning Analytics, 10(1), 1–7. [Google Scholar] [CrossRef]
- Kiesler, N., & Schiffner, D. (2023). Large language models in introductory programming education: ChatGPT’s performance and implications for assessments. arXiv, arXiv:2308.08572. [Google Scholar] [CrossRef]
- Kung, H.-J., & Tung, H.-L. (2006). A web-based tool to enhance teaching/learning database normalization. Sais. Available online: https://aisel.aisnet.org/sais2006/43 (accessed on 20 December 2024).
- Kung, H., & Tung, H. (2006). An alternative approach to teaching database normalization: A simple algorithm and an interactive e-learning tool. Journal of Information Systems Education, 17(3), 315–326. [Google Scholar]
- Li, J., Gui, L., Zhou, Y., West, D., Aloisi, C., & He, Y. (2023). Distilling ChatGPT for explainable automated student answer assessment. arXiv, arXiv:2305.12962. [Google Scholar] [CrossRef]
- Lin, S., Chung, H., Chung, F., & Lan, Y. (2023). Concerns about using ChatGPT in education. In Y. Huang, & T. Rocha (Eds.), Innovative technologies and learning—6th international conference, ICITL 2023, Porto, Portugal, August 28–30, 2023, proceedings (Vol. 14099, pp. 37–49). Springer. [Google Scholar]
- Littenberg-Tobias, J., & Reich, J. (2020). Evaluating access, quality, and equity in online learning: A case study of a MOOC-based blended professional degree program. The Internet and Higher Education, 47, 100759. [Google Scholar] [CrossRef]
- Lyu, W., Wang, Y., Chung, T. R., Sun, Y., & Zhang, Y. (2024). Evaluating the effectiveness of LLMs in introductory computer science education: A semester-long field study. In D. Joyner, M. K. Kim, X. Wang, & M. Xia (Eds.), Proceedings of the eleventh ACM conference on learning@scale, l@s 2024, Atlanta, GA, USA, July 18–20, 2024 (pp. 63–74). ACM. [Google Scholar] [CrossRef]
- Mawasi, A., Aguilera, E., Wylie, R., & Gee, E. (2020). Neutrality, “New” digital divide, and openness paradox: Equity in learning environments mediated by educational technology. In Interdisciplinarity in the learning sciences: Proceedings of the 14th international conference of the learning sciences, ICLS 2020, [Nashville, Tennessee, Usa], online conference, June 19–23, 2020. International Society of the Learning Sciences. [Google Scholar]
- Mazzullo, E., Bulut, O., Wongvorachan, T., & Tan, B. (2023). Learning analytics in the era of large language models. Analytics, 2(4), 877–898. [Google Scholar] [CrossRef]
- McBroom, J., Yacef, K., & Koprinska, I. (2020). Scalability in online computer programming education: Automated techniques for feedback, evaluation and equity. In A. N. Rafferty, J. Whitehill, C. Romero, & V. Cavalli-Sforza (Eds.), Proceedings of the 13th international conference on educational data mining, EDM 2020, fully virtual conference, July 10–13, 2020. International Educational Data Mining Society. [Google Scholar]
- Mitrovic, A. (2002, December 3–6). NORMIT: A web-enabled tutor for database normalization. International Conference on Computers in Education, ICCE 2002 (Vol. 2, pp. 1276–1280), Auckland, New Zealand. [Google Scholar]
- Niloy, A. C., Bari, M. A., Sultana, J., Chowdhury, R., Raisa, F. M., Islam, A., Mahmud, S., Jahan, I., Sarkar, M., Akter, S., Nishat, N., Afroz, M., Sen, A., Islam, T., Tareq, M. H., & Hossen, M. A. (2024). Why do students use ChatGPT? Answering through a triangulation approach. Computers and Education: Artificial Intelligence, 6, 100208. [Google Scholar] [CrossRef]
- Pardos, Z. A., & Bhandari, S. (2023). Learning gain differences between ChatGPT and human tutor generated algebra hints. arXiv, arXiv:2302.06871. [Google Scholar] [CrossRef]
- Piza-Dávila, H. I., Preciado, L. F. G., & Ortega-Guzmán, V. H. (2017). An educational software for teaching database normalization. Computer Applications in Engineering Education, 25(5), 812–822. [Google Scholar] [CrossRef]
- Pozdniakov, S., Brazil, J., Abdi, S., Bakharia, A., Sadiq, S., Gašević, D., Denny, P., & Khosravi, H. (2024). Large language models meet user interfaces: The case of provisioning feedback. Computers and Education: Artificial Intelligence, 7, 100289. [Google Scholar] [CrossRef]
- Qureshi, B. (2023). Exploring the use of ChatGPT as a tool for learning and assessment in undergraduate computer science curriculum: Opportunities and challenges. arXiv, arXiv:2304.11214. [Google Scholar] [CrossRef]
- Röhm, U., Brent, L., Dawborn, T., & Jeffries, B. (2020). SQL for data scientists: Designing SQL tutorials for scalable online teaching. Proceedings of the VLDB Endowment, 13(12), 2989–2992. [Google Scholar] [CrossRef]
- Rospigliosi, P. A. (2023). Artificial intelligence in teaching and learning: What questions should we ask of ChatGPT? Interactive Learning Environments, 31(1), 1–3. [Google Scholar] [CrossRef]
- Rueda, M. M., Fernández-Cerero, J., Fernández-Batanero, J. M., & López-Meneses, E. (2023). Impact of the implementation of ChatGPT in education: A systematic review. Computers, 12(8), 153. [Google Scholar] [CrossRef]
- Seetharaman, R. (2023). Revolutionizing medical education: Can ChatGPT boost subjective learning and expression? Journal of Medical Systems, 47(1), 61. [Google Scholar] [CrossRef]
- Shahzad, T., Mazhar, T., Tariq, M. U., Ahmad, W., Ouahada, K., & Hamam, H. (2025). A comprehensive review of large language models: Issues and solutions in learning environments. Discover Sustainability, 6(1), 27. [Google Scholar] [CrossRef]
- Silberschatz, A., Korth, H. F., & Sudarshan, S. (2020). Database system concepts (7th ed.). McGraw-Hill Book Company. [Google Scholar]
- Soares, J. A. (2011). The matthew effect: How advantage begets further advantage. Contemporary Sociology: A Journal of Reviews, 40(4), 477–478. [Google Scholar] [CrossRef]
- Soler, J., Boada, I., Prados, F., & Poch, J. (2006, October 24–26). A web-based problem-solving environment for database normalization. Simposio Internacional de Informatica Educativa, SIIE (2006), Leon, Spain. [Google Scholar]
- Springfield, I. (2024). Relational database tools. Available online: https://uisacad5.uis.edu/cgi-bin/mcrem2/database_design_tool.cgi (accessed on 20 December 2024).
- Stefanidis, C., & Koloniari, G. (2016, November 10–12). An interactive tool for teaching and learning database normalization. The 20th Pan-Hellenic Conference on Informatics (p. 18), Patras, Greece. Available online: http://dl.acm.org/citation.cfm?id=3003790 (accessed on 20 December 2024).
- Vargas-Murillo, A. R., de la Asuncion Pari-Bedoya, I. N. M., & de Jesus Guevara-Soto, F. (2023, June 9–12). The ethics of AI assisted learning: A systematic literature review on the impacts of ChatGPT usage in education. The 2023 8th International Conference on Distance Education and Learning, ICDEL 2023 (pp. 8–13), Beijing, China. [Google Scholar]
- Vasconcelos, M. A. R., & dos Santos, R. P. (2023). Enhancing STEM learning with ChatGPT and bing chat as objects to think with: A case study. arXiv, arXiv:2305.02202. [Google Scholar] [CrossRef]
- Walberg, H. J., & Tsai, S.-L. (1983). Matthew effects in education. American Educational Research Journal, 20(3), 359–373. [Google Scholar] [CrossRef]
- Wang, J., & Stantic, B. (2019). Facilitating learning by practice and examples: A tool for learning table normalization. In G. Eleftherakis, M. Lazarova, A. Aleksieva-Petrova, & A. Tasheva (Eds.), Proceedings of the 9th balkan conference on informatics, BCI 2019, Sofia, Bulgaria, September 26–28, 2019 (pp. 35:1–35:4). ACM. [Google Scholar] [CrossRef]
- Williamson, K., & Kizilcec, R. F. (2021). Learning analytics dashboard research has neglected diversity, equity and inclusion. In C. Meinel, M. Pérez-Sanagustín, M. Specht, & A. Ogan (Eds.), L@s’21: Eighth ACM conference on learning@scale, virtual event, Germany, June 22–25, 2021 (pp. 287–290). ACM. [Google Scholar]
- Williamson, K., & Kizilcec, R. F. (2022, March 21–25). A review of learning analytics dashboard research in higher education: Implications for justice, equity, diversity, and inclusion. LAK 2022: 12th International Learning Analytics and Knowledge Conference (pp. 260–270), Online. [Google Scholar]
- Xiang, V., Snell, C., Gandhi, K., Albalak, A., Singh, A., Blagden, C., Phung, D., Rafailov, R., Lile, N., Mahan, D., Castricato, L., Franken, J.-P., Haber, N., & Finn, C. (2025). Towards system 2 reasoning in llms: Learning how to think with meta chain-of-thought. Available online: https://arxiv.org/abs/2501.04682 (accessed on 20 December 2024).
- Yang, F. (2011). A virtual tutor for relational schema normalization. ACM Inroads, 2(3), 38–42. [Google Scholar]
- Zhai, X. (2023). ChatGPT for next generation science learning. XRDS: Crossroads, The ACM Magazine for Students, 29(3), 42–46. [Google Scholar]
- Zheng, Y. (2023). ChatGPT for teaching and learning: An experience from data science education. arXiv, arXiv:2307.16650. [Google Scholar] [CrossRef]

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jamil, H.M. An Experiment with LLMs as Database Design Tutors: Persistent Equity and Fairness Challenges in Online Learning. Educ. Sci. 2025, 15, 386. https://doi.org/10.3390/educsci15030386
Jamil HM. An Experiment with LLMs as Database Design Tutors: Persistent Equity and Fairness Challenges in Online Learning. Education Sciences. 2025; 15(3):386. https://doi.org/10.3390/educsci15030386
Chicago/Turabian StyleJamil, Hasan M. 2025. "An Experiment with LLMs as Database Design Tutors: Persistent Equity and Fairness Challenges in Online Learning" Education Sciences 15, no. 3: 386. https://doi.org/10.3390/educsci15030386
APA StyleJamil, H. M. (2025). An Experiment with LLMs as Database Design Tutors: Persistent Equity and Fairness Challenges in Online Learning. Education Sciences, 15(3), 386. https://doi.org/10.3390/educsci15030386