


Many-Dimensional Model of Adolescent School Enjoyment: A Test Using Machine Learning from Behavioral and Social-Emotional Problems


Abstract
1. Introduction
1.1. Power of the Item
1.2. Toward a Many-Dimensional Adolescent Psychopathology
1.3. Present Study
2. Materials and Methods
2.1. Participants
2.2. Measures
2.3. Machine Learning
2.3.1. Variables
2.3.2. Data and Machine Learning Workflow
2.3.3. Model Explainability
3. Results
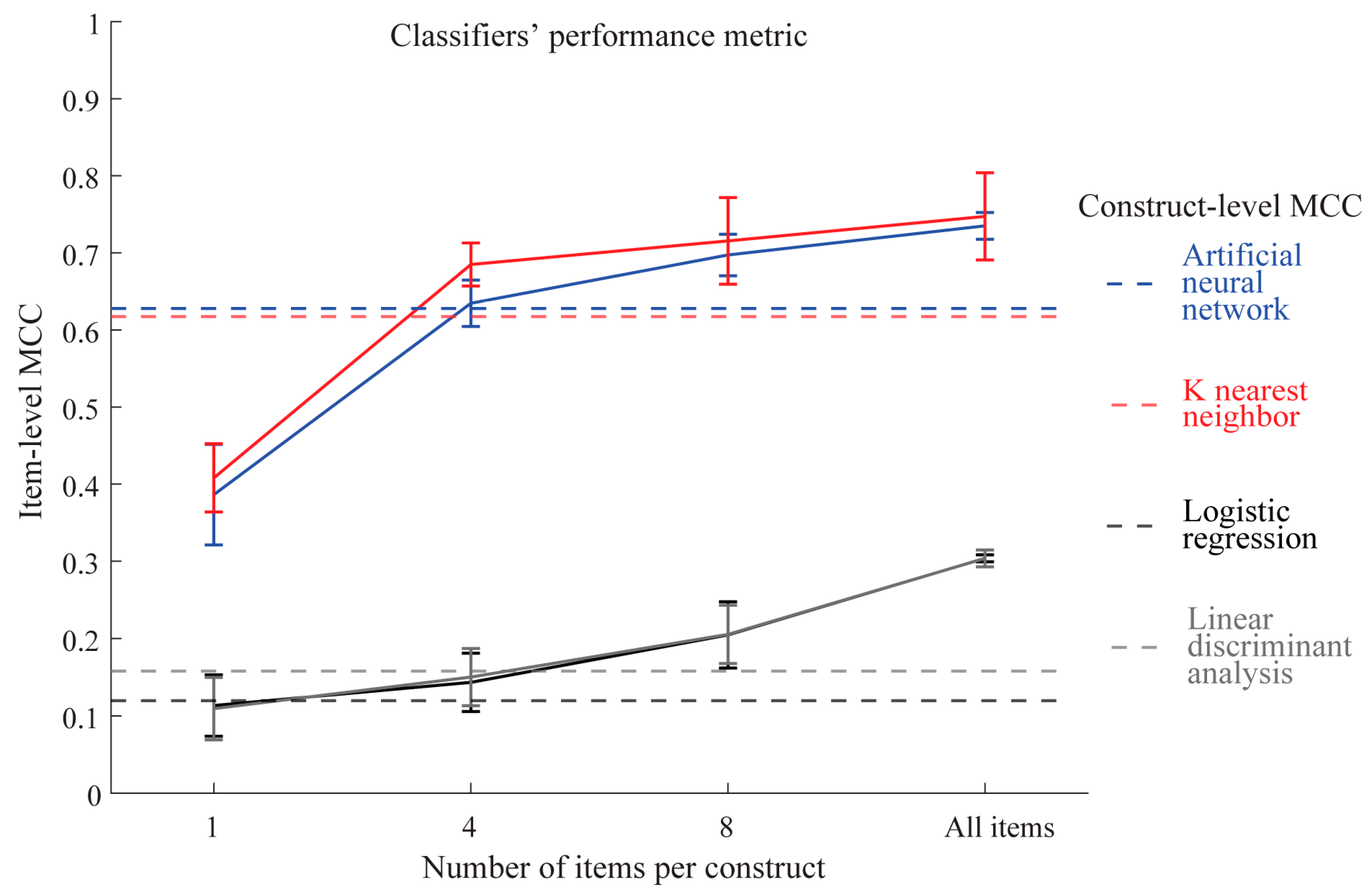
3.1. Items Versus Constructs
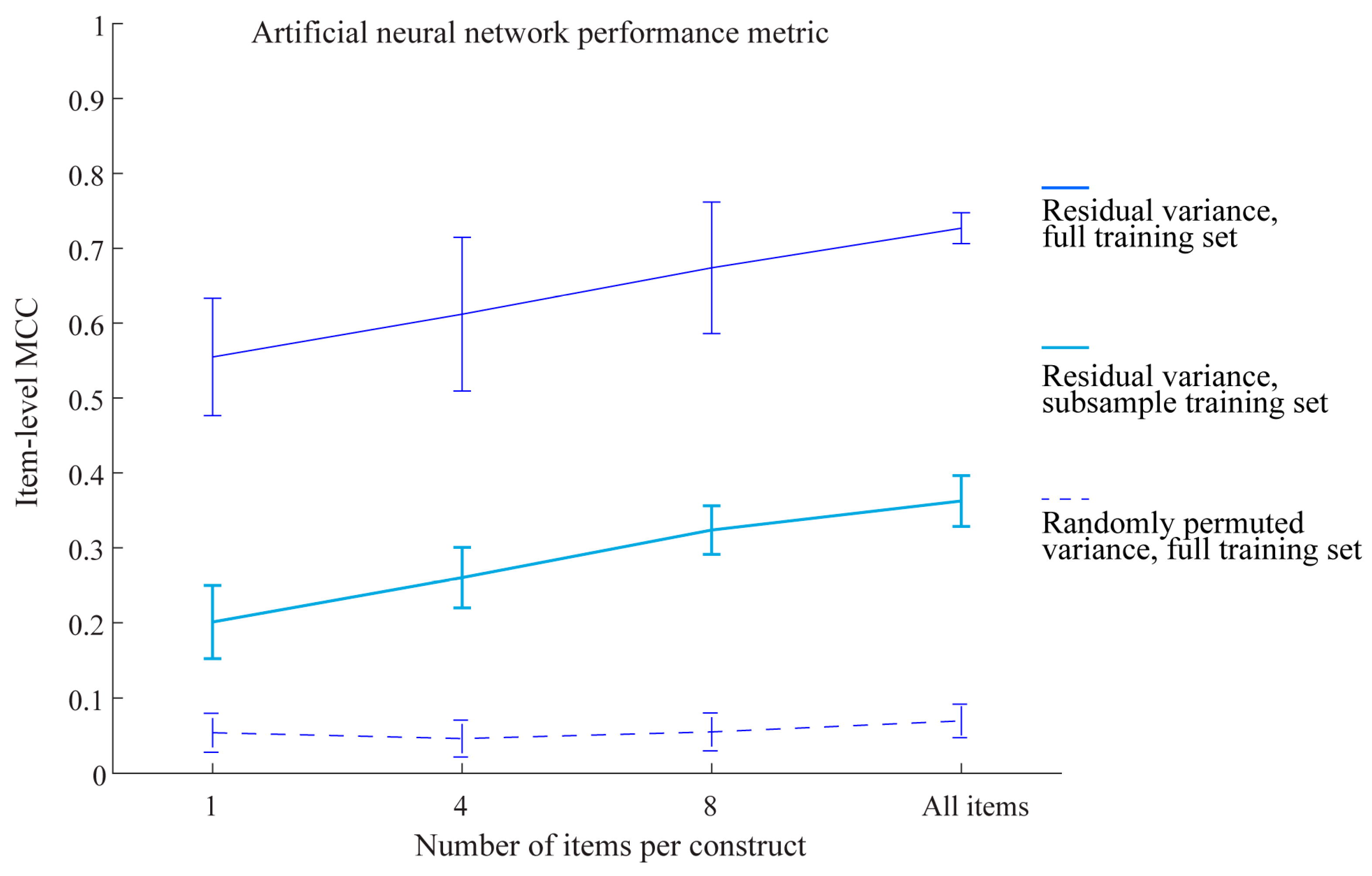
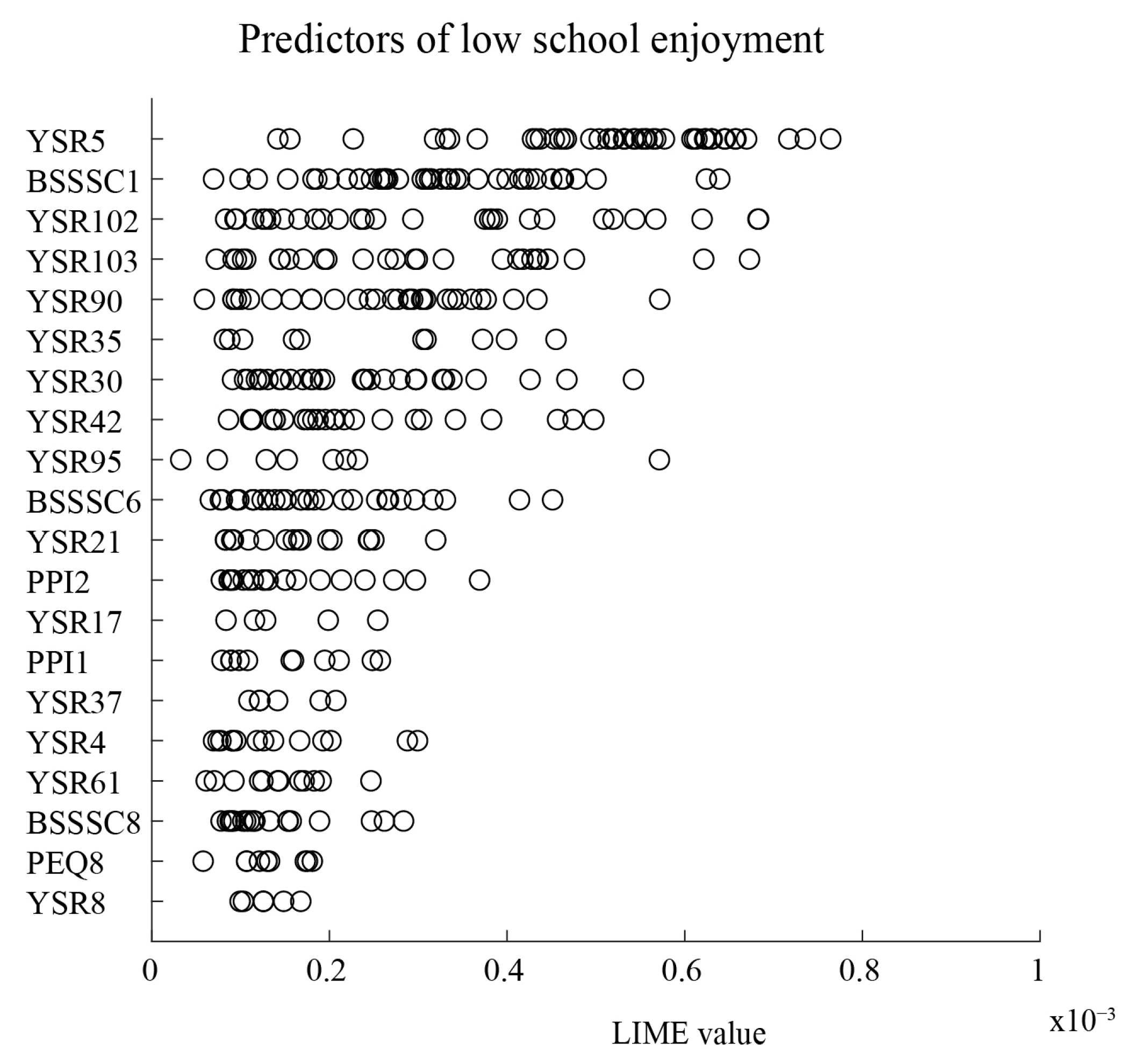
3.2. Model Explainability
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ang, R.P.; Huan, V.S.; Chan, W.T.; Cheong, S.A.; Leaw, J.N. The role of delinquency, proactive aggression, psychopathy and behavioral school engagement in reported youth gang membership. J. Adolesc. 2015, 41, 148–156. [Google Scholar] [CrossRef] [PubMed]
- Yusof, N.; Oei, T.P.S.; Ang, R.P. Voices of adolescents on school engagement. Asia-Pac. Educ. Res. 2018, 27, 23–32. [Google Scholar] [CrossRef]
- Traub, R.E. Classical test theory in historical perspective. Educ. Meas. 1997, 16, 8–13. [Google Scholar] [CrossRef]
- Edwards, J.R.; Bagozzi, R.P. On the nature and direction of relationships between constructs and measures. Psychol. Methods 2000, 5, 155. [Google Scholar] [CrossRef] [PubMed]
- Cronbach, L.J.; Meehl, P.E. Construct validity in psychological tests. Psychol. Bull. 1955, 52, 281–302. [Google Scholar] [CrossRef] [PubMed]
- Moilanen, K.L.; Shaw, D.S.; Maxwell, K.L. Developmental cascades: Externalizing, internalizing, and academic competence from middle childhood to early adolescence. Dev. Psychopathol. 2010, 22, 635–653. [Google Scholar] [CrossRef] [PubMed]
- Kaufman, T.M.; Kretschmer, T.; Huitsing, G.; Veenstra, R. Caught in a vicious cycle? Explaining bidirectional spillover between parent-child relationships and peer victimization. Dev. Psychopathol. 2020, 32, 11–20. [Google Scholar] [CrossRef]
- Seeboth, A.; Mõttus, R. Successful explanations start with accurate descriptions: Questionnaire items as personality markers for more accurate predictions. Eur. J. Pers. 2018, 32, 186–201. [Google Scholar] [CrossRef]
- Mõttus, R.; Kandler, C.; Bleidorn, W.; Riemann, R.; McCrae, R.R. Personality traits below facets: The consensual validity, longitudinal stability, heritability, and utility of personality nuances. J. Pers. Soc. Psychol. 2017, 112, 474–490. [Google Scholar] [CrossRef]
- Hang, Y.; Speyer, L.G.; Haring, L.; Murray, A.L.; Mõttus, R. Investigating general and specific psychopathology factors with nuance-level personality traits. Personal. Ment. Health 2023, 17, 67–76. [Google Scholar] [CrossRef]
- McCrae, R.R. A more nuanced view of reliability: Specificity in the trait hierarchy. Pers. Soc. Psychol. Rev. 2015, 19, 97–112. [Google Scholar] [CrossRef]
- Mõttus, R.; Rozgonjuk, D. Development is in the details: Age differences in the Big Five domains, facets, and nuances. J. Pers. Soc. Psychol. 2021, 120, 1035–1048. [Google Scholar] [CrossRef]
- Revelle, W.; Dworak, E.M.; Condon, D.M. Exploring the persome: The power of the item in understanding personality structure. Personal. Individ. Differ. 2021, 169, 109905. [Google Scholar] [CrossRef]
- Weiss, A.; Gale, C.R.; Batty, G.D.; Deary, I.J. A questionnaire-wide association study of personality and mortality: The Vietnam Experience Study. J. Psychosom. Res. 2013, 74, 523–529. [Google Scholar] [CrossRef] [PubMed][Green Version]
- Ozer, D.J.; Benet-Martinez, V. Personality and the prediction of consequential outcomes. Annu. Rev. Psychol. 2006, 57, 401–421. [Google Scholar] [CrossRef] [PubMed]
- Pantelis, C.; Papadimitriou, G.N.; Papiol, S.; Parkhomenko, E.; Pato, M.T.; Paunio, T.; Pejovic-Milovancevic, M.; Perkins, D.O.; Pietiläinen, O. Biological insights from 108 schizophrenia-associated genetic loci. Nature 2014, 511, 421–427. [Google Scholar]
- Lee, J.J.; Wedow, R.; Okbay, A.; Kong, E.; Maghzian, O.; Zacher, M.; Nguyen-Viet, T.A.; Bowers, P.; Sidorenko, J.; Karlsson Linnér, R. Gene discovery and polygenic prediction from a genome-wide association study of educational attainment in 1.1 million individuals. Nat. Genet. 2018, 50, 1112–1121. [Google Scholar] [CrossRef] [PubMed]
- Mõttus, R.; Bates, T.C.; Condon, D.M.; Mroczek, D.K.; Revelle, W.R. Leveraging a more nuanced view of personality: Narrow characteristics predict and explain variance in life outcomes. PsyArXiv 2022. [Google Scholar] [CrossRef]
- Freichel, R.; Pfirrmann, J.; de Jong, P.J.; Cousijn, J.; Franken, I.H.; Oldehinkel, A.; Veer, I.; Wiers, R. Executive functioning and the interplay of internalizing and externalizing symptoms–understanding developmental dynamics through panel network approaches. PsyArxiv 2023. [Google Scholar] [CrossRef]
- Branje, S. Development of parent–adolescent relationships: Conflict interactions as a mechanism of change. Child. Dev. Perspect. 2018, 12, 171–176. [Google Scholar] [CrossRef]
- Allen, A.N.; Kilgus, S.P.; Burns, M.K.; Hodgson, C. Surveillance of internalizing behaviors: A reliability and validity generalization study of universal screening evidence. Sch. Ment. Health 2019, 11, 194–209. [Google Scholar] [CrossRef]
- Cadman, T.; Hughes, A.; Wright, C.; Lopez-Lopez, J.A.; Morris, T.; Rice, F.; Smith, G.D.; Howe, L.D. The role of school enjoyment and connectedness in the association between depressive and externalising symptoms and academic attainment: Findings from a UK prospective cohort study. J. Affect. Disord. 2021, 295, 974–980. [Google Scholar] [CrossRef]
- Tze, V.M.; Daniels, L.M.; Klassen, R.M. Evaluating the relationship between boredom and academic outcomes: A meta-analysis. Educ. Psychol. Rev. 2016, 28, 119–144. [Google Scholar] [CrossRef]
- Morris, T.T.; Dorling, D.; Davies, N.M.; Davey Smith, G. Associations between school enjoyment at age 6 and later educational achievement: Evidence from a UK cohort study. npj Sci. Learn. 2021, 6, 18. [Google Scholar] [CrossRef]
- Baker, J.A. Teacher-student interaction in urban at-risk classrooms: Differential behavior, relationship quality, and student satisfaction with school. Elem. Sch. J. 1999, 100, 57–70. [Google Scholar] [CrossRef]
- Wasberg, A. Investigating Associations between Early Adolescents’ School Enjoyment, Perceived Social Support and Social Emotions in a Finnish High School: Results from an Explorative Study Based on Cross-Sectional and Intense Longitudinal Data from the REBOOT-project. Master’s Thesis, Åbo Akademi University, Vaasa, Finland, 2020. [Google Scholar]
- Ang, R.P.; Li, X.; Huan, V.S.; Liem, G.A.D.; Kang, T.; Wong, Q.; Yeo, J.Y. Profiles of antisocial behavior in school-based and at-risk adolescents in Singapore: A latent class analysis. Child. Psychiatry Hum. Dev. 2020, 51, 585–596. [Google Scholar] [CrossRef] [PubMed]
- Ali, F.; Ang, R.P. Predicting how well adolescents get along with peers and teachers: A machine learning approach. J. Youth Adolesc. 2022, 51, 1241–1256. [Google Scholar] [CrossRef] [PubMed]
- Achenbach, T.M.; Rescorla, L.A. Manual for the ASEBA School-Age Forms and Profiles; University of Vermont, Research Center for Children, Youth & Families: Burlington, VT, USA, 2001. [Google Scholar]
- Ivanova, M.Y.; Achenbach, T.M.; Dumenci, L.; Rescorla, L.A.; Almqvist, F.; Weintraub, S.; Bilenberg, N.; Bird, H.; Chen, W.J.; Dobrean, A. Testing the 8-syndrome structure of the child behavior checklist in 30 societies. J. Clin. Child. Adolesc. Psychol. 2007, 36, 405–417. [Google Scholar] [CrossRef]
- Chen, X.; Li, F.; Nydegger, L.; Gong, J.; Ren, Y.; Dinaj-Koci, V.; Sun, H.; Stanton, B. Brief sensation seeking scale for Chinese–cultural adaptation and psychometric assessment. Personal. Individ. Differ. 2013, 54, 604–609. [Google Scholar] [CrossRef] [PubMed]
- Clasen, D.R.; Brown, B.B. The multidimensionality of peer pressure in adolescence. J. Youth Adolesc. 1985, 14, 451–468. [Google Scholar] [CrossRef]
- Elkins, I.J.; McGue, M.; Iacono, W.G. Genetic and environmental influences on parent–son relationships: Evidence for increasing genetic influence during adolescence. Dev. Psychol. 1997, 33, 351–363. [Google Scholar] [CrossRef]
- Rothenberg, W.A.; Bizzego, A.; Esposito, G.; Lansford, J.E.; Al-Hassan, S.M.; Bacchini, D.; Bornstein, M.H.; Chang, L.; Deater-Deckard, K.; Di Giunta, L. Predicting Adolescent Mental Health Outcomes Across Cultures: A Machine Learning Approach. J. Youth Adolesc. 2023, 52, 1595–1619. [Google Scholar] [CrossRef]
- Senior, M.; Fanshawe, T.; Fazel, M.; Fazel, S. Prediction models for child and adolescent mental health: A systematic review of methodology and reporting in recent research. JCPP Adv. 2021, 1, e12034. [Google Scholar] [CrossRef]
- Christodoulou, E.; Ma, J.; Collins, G.S.; Steyerberg, E.W.; Verbakel, J.Y.; Van Calster, B. A systematic review shows no performance benefit of machine learning over logistic regression for clinical prediction models. J. Clin. Epidemiol. 2019, 110, 12–22. [Google Scholar] [CrossRef]
- Thurber, S.; Sheehan, W. Note on truncated T scores in discrepancy studies with the Child Behavior Checklist and Youth Self Report. Arch. Psychol. 2012, 2, 73–80. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Urban, C.J.; Gates, K.M. Deep learning: A primer for psychologists. Psychol. Methods 2021, 26, 743–773. [Google Scholar] [CrossRef]
- Cunningham, P.; Delany, S.J. k-Nearest neighbour classifiers-A Tutorial. ACM Comput. Surv. (CSUR) 2021, 54, 1–25. [Google Scholar] [CrossRef]
- Yu, T.; Zhu, H. Hyper-parameter optimization: A review of algorithms and applications. arXiv 2020, arXiv:2003.05689. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why should I trust you?” Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Caliński, T.; Harabasz, J. A dendrite method for cluster analysis. Commun. Stat.-Theory Methods 1974, 3, 1–27. [Google Scholar] [CrossRef]
- Leibenluft, E. Irritability in children: What we know and what we need to learn. World Psychiatry 2017, 16, 100. [Google Scholar] [CrossRef]
- Ritakallio, M.; Koivisto, A.M.; von der Pahlen, B.; Pelkonen, M.; Marttunen, M.; Kaltiala-Heino, R. Continuity, comorbidity and longitudinal associations between depression and antisocial behaviour in middle adolescence: A 2-year prospective follow-up study. J. Adolesc. 2018, 31, 355–370. [Google Scholar] [CrossRef]
- Michelini, G.; Barch, D.M.; Tian, Y.; Watson, D.; Klein, D.N.; Kotov, R. Delineating and validating higher-order dimensions of psychopathology in the Adolescent Brain Cognitive Development (ABCD) study. Transl. Psychiatry 2019, 9, 261. [Google Scholar] [CrossRef]
- Chabris, C.F.; Lee, J.J.; Cesarini, D.; Benjamin, D.J.; Laibson, D.I. The fourth law of behavior genetics. Curr. Dir. Psychol. Sci. 2015, 24, 304–312. [Google Scholar] [CrossRef]
- Allen, K.-A.; Jamshidi, N.; Berger, E.; Reupert, A.; Wurf, G.; May, F. Impact of school-based interventions for building school belonging in adolescence: A systematic review. Educ. Psychol. Rev. 2022, 34, 229–257. [Google Scholar] [CrossRef]
- Waters, L. A review of school-based positive psychology interventions. Aust. Educ. Dev. Psychol. 2011, 28, 75–90. [Google Scholar] [CrossRef]
- Rusk, R.D.; Waters, L. A psycho-social system approach to well-being: Empirically deriving the five domains of positive functioning. J. Posit. Psychol. 2015, 10, 141–152. [Google Scholar] [CrossRef]
- Mavridis, D.; Giannatsi, M.; Cipriani, A.; Salanti, G. A primer on network meta-analysis with emphasis on mental health. BMJ Ment. Health 2015, 18, 40–46. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cluster 1 |
| BSSSC1, I’m interested in almost everything that is new (negatively related) PEQ11, My parent sometimes hits me in anger (negatively related) BSSSC6, Going on adventures always makes me happy (negatively related) |
| Cluster 2 |
| PPI2, How often do you feel the need to be part of a group in school? (negatively related) YSR90, I swear or use dirty language BSSSC1, I’m interested in almost everything that is new (negatively related) |
| Cluster 3 |
| YSR30, I am afraid of going to school YSR42, I would rather be alone than with others YSR61, My school work is poor |
| Cluster 4 |
| BSSSC6, Going on adventures always makes me happy (negatively related) YSR42, I would rather be alone than with others BSSSC8, To pursue new experiences and excitement, I can go against rules and regulations |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ali, F.; Ang, R.P. Many-Dimensional Model of Adolescent School Enjoyment: A Test Using Machine Learning from Behavioral and Social-Emotional Problems. Educ. Sci. 2023, 13, 1103. https://doi.org/10.3390/educsci13111103
Ali F, Ang RP. Many-Dimensional Model of Adolescent School Enjoyment: A Test Using Machine Learning from Behavioral and Social-Emotional Problems. Education Sciences. 2023; 13(11):1103. https://doi.org/10.3390/educsci13111103
Chicago/Turabian StyleAli, Farhan, and Rebecca P. Ang. 2023. "Many-Dimensional Model of Adolescent School Enjoyment: A Test Using Machine Learning from Behavioral and Social-Emotional Problems" Education Sciences 13, no. 11: 1103. https://doi.org/10.3390/educsci13111103
APA StyleAli, F., & Ang, R. P. (2023). Many-Dimensional Model of Adolescent School Enjoyment: A Test Using Machine Learning from Behavioral and Social-Emotional Problems. Education Sciences, 13(11), 1103. https://doi.org/10.3390/educsci13111103