1. Introduction
Current time-series inferences heavily rely on the stationary process assumption that statistical properties are supposed to steady over time. In fact, a time series is often nonstationary, which can appear as seasonality, trends, random walks, or other evolutionary incidences. Such nonstationary series are by definition unpredictable and cannot be modelled. As a result, this violates the stationarity assumptions in the process of time-series analysis, and it may result in spurious and unreliable statistical inferences (
Khinchine 1934;
Kolmogorov 1931;
Vinod 2006). In practice, a series tends to be constant in a short period and nonstationary in a longer duration. Additionally, an observed time series
on random variable
X can perform as a stochastic process corresponding to the certain period of time (
t), such as days, months, years, etc. It is important to take into account the presence of stationary and nonstationary series. Model misspecification is a regular problem in statistical data analysis in several methods. Such models offer biased coefficients and error terms, and these show invalid parameter estimations. Moreover, in the misspecified models dealing with the asymptotic theory, inferences employing usual statistics lead to spurious regressions (
Phillips 1986;
Shin and Sarkar 1997).
An updated technique undertaken in the nonparametric bootstrap methodology is the maximum entropy bootstrap (MEboot), proposed by
Vinod (
2006). The MEboot is a powerful tool for highly dependent nonstationary time series and it can overcome unnecessary distributional assumptions of stationary. In addition, creating the simulations beyond the historical time series can guarantee what the relevant information means and how the future may unfold. The MEboot algorithm can intensively generate random samples called ensemble
Ω based upon the empirical cumulative distribution function (CDF), which ensures it as an underlying process in cases of nonstationary or regime-switching in the time series (
Vinod 2013;
Vinod and Lopez-de-Lacalle 2009). This method also satisfies the ergodic theorem and the central limit theorem (
Chaiboonsri and Chaitip 2013;
Srivastav and Simonovic 2014).
In a broad swing of the global economy, the Association of Southeast Asian Nations (ASEAN) has been shifting towards trade liberalization and international capital mobility. Foreign direct investment (FDI) has been expanding and is greatly facilitated by agreement among trade partner countries, especially in advanced ASEAN economies consisting of Singapore, Thailand, Malaysia, Indonesia, Vietnam, and the Philippines that perform as the top six counties attracting FDI. Despite ASEAN being one of the major destinations of FDI and playing a crucial role in promoting economic growth in the region, each ASEAN member country should achieve its true potential, raising a question of who dominates FDI in ASEAN economy. Having said that, the global competition in trade liberalization comes up with high challenges to the host countries, so it is necessary for ASEAN member states to know their true competitive positions for investment in order to prepare more FDI attractive activities, and the competitive positioning is the ultimate concern for long-term performance of FDI.
For that reason, simulation-based econometrics such as the entropy-based inferential models including maximum entropy (ME) method, cross-entropy (CE) algorithm, and the MEboot approach are particularly applicable to reach the best experimental model fitting. The objectives of this research are to computationally seek the efficient estimator by applying empirical evidence to determine the predominant nation of FDI attractiveness and to deeply clarify the structural dependence of capital flows among ASEAN countries. The rest of this article is organized as follows. We briefly summarize the maximum entropy bootstrapping estimator, maximum entropy and cross-entropy principles, stochastic dominance criteria, and C-vine copula model. In
Section 3, data descriptive, empirical applications of the proposed methods are presented, and
Section 4 concludes.
2. Methodology
The procedure of this research can be broadly divided into five parts, as detailed in the following sections.
2.1. AR-GARCH Model
Recently, the world economy has confronted economic crises due to the globalized economic environment. Likewise, the uncertainty on FDI flows has commonly appeared in host countries. Such volatile FDI may affect those macroeconomies; underlying the interaction behind volatile FDI is essential. To capture suitably the unobservable process, the volatile series of FDI is generated via a class of general autoregressive processes under white noises participating conditional heteroscedastic variances, which is the GARCH-type modelling. The growth rate of FDI, namely
, is called an autoregressive process of order
k with a GARCH noise for order
p,
q for
Therefore, the AR(
k)-GARCH (
p,
q) processes proposed by
Bollerslev (
1986) are defined by the following three equations:
where
is the growth rate of FDI for each nation,
and
k in Equation (1) represent the parameters and the order of AR,
in Equation (2) performs as a white noise (iid(0,1)), and
satisfies Equation (3).
and
in Equation (3) refer to the parameters of GARCH (
p,
q). Then, Var
, and
. Hence, we can employ these estimations to obtain the generalized residuals and further calculate the CDF to carry out the maximum entropy.
2.2. Maximum Entropy Bootstrapping Estimator (MEboot)
Vinod (
2006), and further studied by
Vinod and Lopez-de-Lacalle (
2009), invented the MEboot approach, which is a technique for bootstrapping time series to avoid unnecessary distributional assumptions like unit root and structural change relating to shape-destroying conversions and complicated asymptotic to attain stationarity. The maximum entropy bootstrapping estimator (MEboot) can use to treat the likelihood and obtain unknown parameters. Moreover, the MEboot approach efficiently offers a certain parameter rather than employing the maximum likelihood estimator (MLE) (
Wannapan and Chaiboonsri 2018). The MEboot evokes a maximum entropy density
respective to certain mass-and mean-preserving constraints. Let
be the density of
, thus the maximizing the Shannon information is defined by:
According to
Vinod (
2006), an intensive formation of a plausible ensemble
Ω generated from a density was accomplished and satisfied the maximum entropy (ME) principle. The MEboot algorithm employs quantiles, which are routed through the
Ω from the inverse evident CDF of the ME density, denoting
, for
The entire mean of all
is definitely equivalent to the mean of
ex post without a doubt of asymptotic behaviors over time points
. The constructed replicates satisfy the ergodic theorem and the central limit theorem and ensure to preserve the original properties of a time series, such as shapes, autocorrelation, and partial autocorrelation functions.
Chaitip and Chaiboonsri (
2013) concisely summarized Vinod’s seven-step to MEboot algorithm to generate a random realization of
.
2.3. Maximum Entropy (ME) Principle
The principle of ME is to extract meaningful constraints that predicate the observed signals originated by the system. Following the concept of
Jaynes (
1963) since 1957, if the probability distribution function (PDF) of a given parameter
, being continuous distribution, is unknown and some parts of the parameter distribution are known, we can adopt the ME algorithm as demonstrated by
Muoz-Cobo et al. (
2017) to obtain the parameter distribution. In the case of
taking a compact aspect being
with
, the Shannon information entropy is expressed:
where
denotes the information entropy defined by
Shannon (
1948).
is the PDF of the random parameter
, and
is the CDF. Considering the PDF in general form in Equation (6), the
functions assign the different moments of the distribution function of the parameter
, where the number
is taken from
to
as follows:
The ME can be solved to achieve the PDF definition
that maximizes the information entropy. Taking the Lagrange multiplier method of Equation (6) gives:
The first variation of the functional
] is
] and the interference
equals to zero, and we receive the PDF of the parameter as:
More generally, a nonlinear approach is required to obtain the values of , which are procured from the observed information on the distribution moments.
2.4. Cross-Entropy (CE) Analysis
A general problem in various fields of economic research is finding the expected value of a random quantity such as:
where
denotes a vector with the PDF
and
refers to an arbitrary real-valued function in
. To estimate
, the samples
are assumed to be independent and identically distributed
from an approximately chosen PDF
, and the
is estimated by:
The PDF
has to dominate
in the absolutely continuous aspect. This quotes,
where
stands for the support of the corresponding function. We seek to find the best parameter
. At the present,
Rubinstein (
1997) introduced the cross-entropy method to estimate the parameter
such that g(·; θ∗) minimizes the Kullback–Leibler cross entropy corresponding to the zero-variance PDF
. In common, a certain stochastic optimization problem is necessary to solve for
(
Homem-de-Mello 2007).
2.5. Stochastic Dominance Analysis
Given and be the two interesting variables at any point in time and the observations, are not necessarily , suppose that refers to the sequence of all Von Neumann–Morgenstern utility functions, , such that (increasing). stands for the class of all utility functions in within (strict concavity). Let and denote the CDF, respectively.
Definition 1. first-order stochastic dominates, denoted that, if and only if:
- (1)
for allwith strict inequality for some; or
- (2)
for allwith strict inequality for some.
Definition 2. second-order stochastic dominates, denoted that, if and only if either:
- (1)
for allwith strict inequality for some; or
- (2)
for allwith strict inequality for some.
2.6. The C-Vine Copula Model
The fundamental theorem is based on the concept of
Sklar (
1959), and this can be shown in Equation (13) as follow:
F: n-dimensional distribution with marginal ;
: random vectors;
C: n-copula for all .
The function is a distribution function that has uniform margins between zero and one, and it is labelled as the copula function. It binds the univariate margins and to produce bivariate distribution .
The vine copula models are a graphical representation to specify pair copula constructions (PCCs). Basically, a principle for constructing multivariate copula generated from the product of bivariate pair copula was statistically explained as canonical (C-) vines. This contribution was a flexible model since bivariate copulas can accommodate complex structural dependences such as asymmetric dependences or strong joint-tail behaviors (
Nikoloulopoulos et al. 2012;
Charfeddine and Benlagha 2016). Consequently, the estimated patterns of relation among FDI flows in ASEAN are defined as
with marginal distribution function
. The
n-dimensional density (
n = 6) corresponding to a C-vine copula is formulated as:
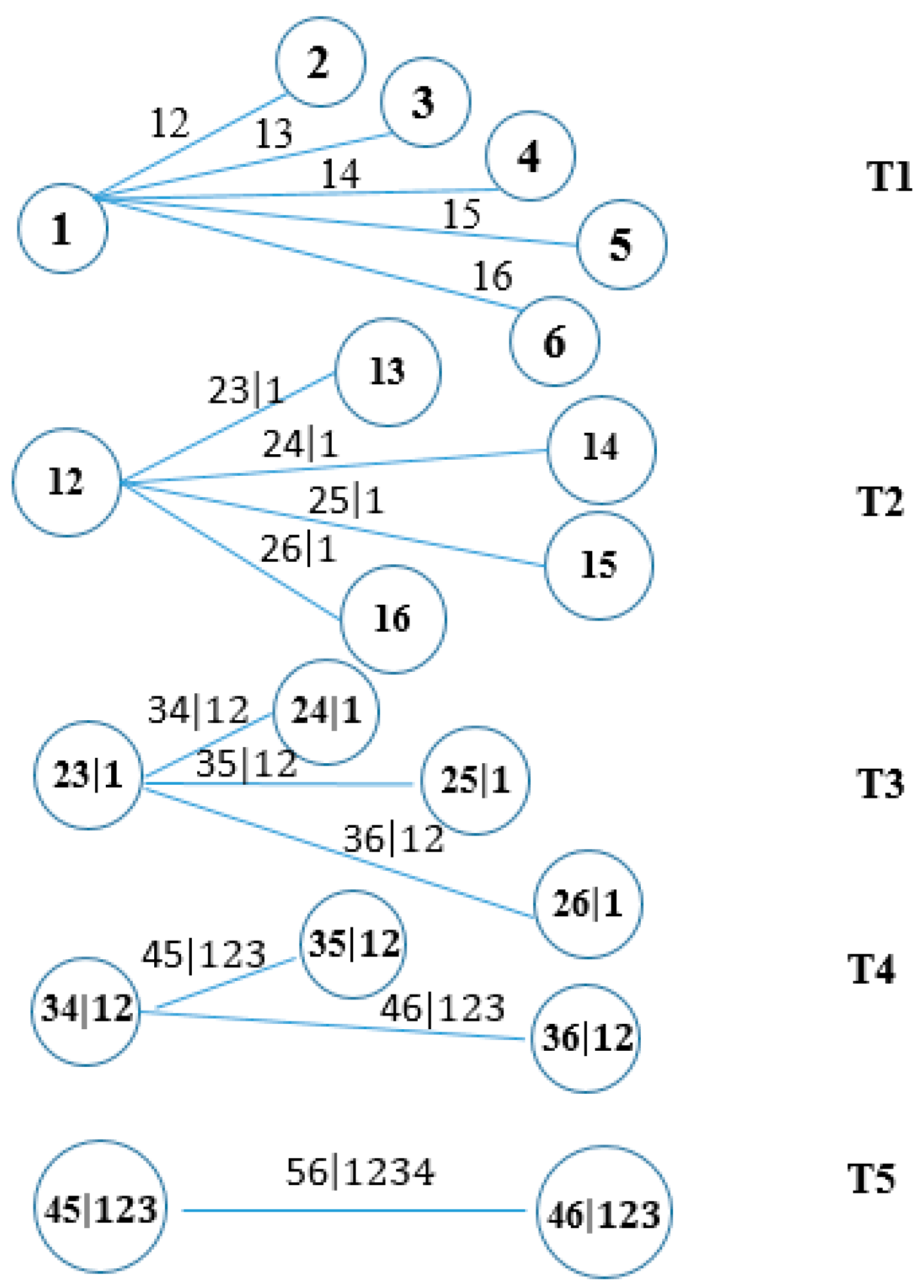
where the C-vine comprises of five trees (
j = 1, 2, …, 5) and 15 edges. Each edge associates with a pair-copula. Then, the C-vine copula log-likelihood function is defined as:
where
denotes a set of the C-vine parameters and the time series contains
independent observations. So, a C vine with six variables, five trees and 15 edges is displayed in
Figure 1.
3. Data and Empirical Results
In this section, we present data description. Then, we show the application for the computational experiment for the past observations of a time series.
3.1. Data Analysis
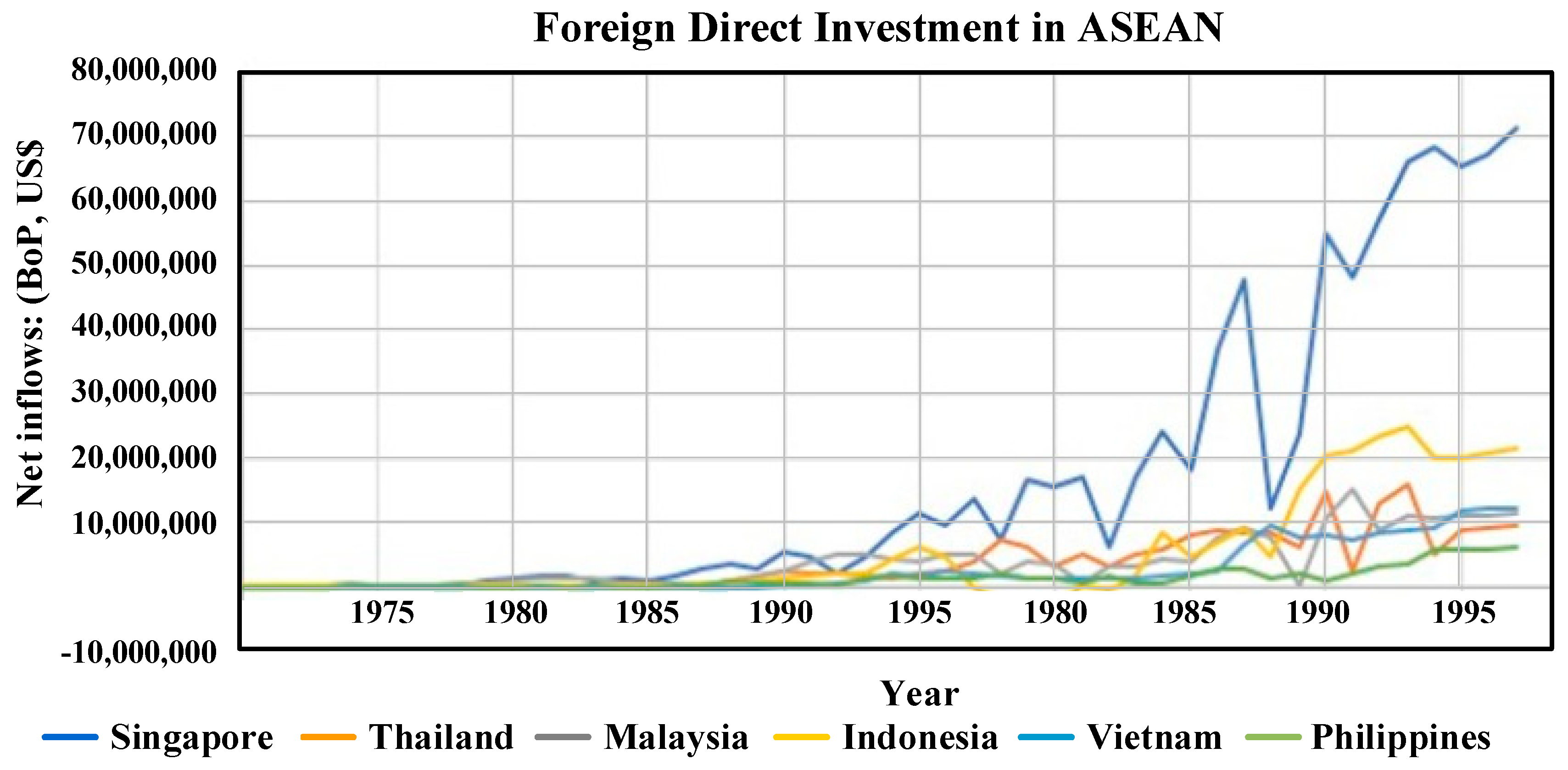
To examine which country is the main indicator for FDI inflows in ASEAN, a series of FDI from the annual reports by the World Bank Development Indicators (WDI) database were collected during 1970 to 2017. For a brief insight of the underlying data, the plots of FDI series display a growing trend over full periods and are not normally distributed for all ASEAN-6 countries, as shown in
Figure 2.
Then, those FDI series were transformed to be a growth rate, which typically shows the changed annualized rate of growth of the FDI in order to inform certain properties of parameterized distributions.
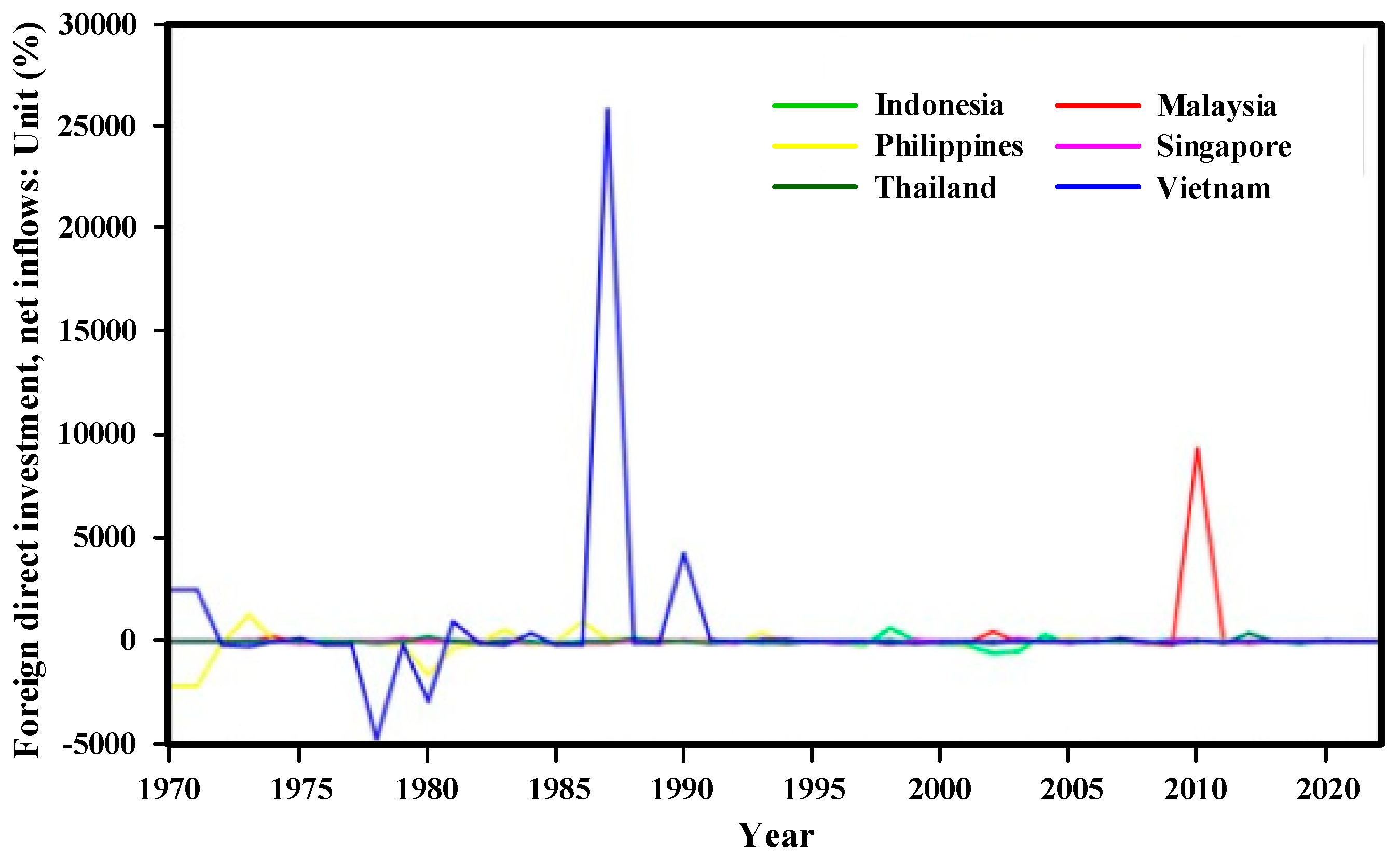
Figure 3 demonstrates the plots of the FDI’s growth rate. It can be clearly seen that there was low stability at the beginning of the FDI historical performance in Vietnam. Later, Vietnam established a transitional economy and opened the economy to the global market. As a result, it was extraordinary for Vietnam to enhance FDI from 1986 up to mid-1990 (
Schaumburg-Mller 2002). Whereas, other nations have remained constant in FDI scales, excepting Malaysia that increased dramatically in 2010 due to its stimulating FDI policy.
Table 1 summarizes the descriptive statistics involving mean–medium and maximum–minimum FDI volumes, standard deviation, and normality properties. To simply determine whether the data set is a normal distribution, the skewness values of all nations were found, and they are greater than 1, indicating that the distribution is highly skewed. The kurtosis ranks for the whole are also leptokurtic. Moreover, the big Jarque–Bera test value and the tiny probability mean that the null hypothesis of normality distribution is rejected at the 5% significance level. Consequently, the FDI data series for all countries have no normal distribution. Even though Singapore is the largest destination of FDI inflows, they would not be able to utilize the mean value to perform as a higher position country in terms of averaging to dominate other countries in ASEAN.
3.2. Correlation Analysis
In order to explore who dominates FDI direction in ASEAN, we initially began by determining if there is an association between two countries.
Table 2 represents the correlation analyses in terms of parametric and nonparametric correlations. According to the simple Person’s correlation, it indicates that Singapore has a mostly positive relationship to other countries considered. It should be noted that the Person’s correlation analysis attempts to draw a linear association between two variables, but those variables might be inconsistent. If the relationship is not linear, then the interpretation is meaningless. To further verify that those certain variables are related to each other, we used the nonparametric correlations (Kendall’s tau and Spearman’s rho) to measure the strength and direction of association between the two involved variables. Unlike with the Person’s correlation, Indonesia has a strong and positive relationship to other countries at the 0.01 and 0.05 levels of significance of both Kendall’s tau and Spearman’s rho ranks.
3.3. The Empirical Applications of the Entropy-Based Inferential Models
Afterwards, we constructed the AR-GARCH model. The simulated data sets were carried out using the MEboot estimation, which efficiently offers a precise parameter. The residuals were obtained and converted into the CDF terms, which execute to be a real-valued random variable. Then, we utilized those CDF sets to compute on the entropy formula. Furthermore, the cross-entropy approach was calculated to implicitly measure the minimum underlying set of events. The results of the entropy and the CE method are reported in
Table 3. Empirically, Indonesia has apparently the nearest CE value (8.083) comparing to the overall Entropy value (6.491), followed by Thailand (8.245) and Singapore (8.504). Theoretically, the CE approach offers more accuracy to solve classification problems since it computes the actual probability of FDI series
(X) for each time
t associated with the realized entropy (
Q) following a particular probability distribution within the entire observations. Like using a neural network to execute classification, this calculation statistically yields to the CE between
X and
Q, in which we can verify and evaluate the division of FDI. In short, we are cross-checking which country dominates FDI direction in ASEAN economy. Consequently, Indonesia, Thailand, and Singapore can be viewed as the key indicators of FDI inflows among ASEAN-6 host economies. It is consistent with the nonparametric correlation analysis above, implying that the flow directions of FDI in Indonesia, Thailand, and Singapore are more straightforward than elsewhere in ASEAN.
Interestingly, Indonesia in recent years is one of the most popular prospective FDI host countries for FDI, and its FDI growth coincides with the global FDI growth. The FDI is playing a crucial role in the economic expansion, mainly driven by mining, chemical, pharmaceutical, transportation, and telecommunication industries. The Government has reformed many regulations and bureaucracies to create a good investment climate, and its global credit rating can also be graded. This influences the country’s allure as an investment destination, providing its wealth of good strategies, political stability, and skilled workforce. Thailand is becoming more attractive as an FDI destination. The government has promoted several investment funds for technology and infrastructure to enhance in public–private partnerships. The target FDI sectors are in the areas of commerce, entrepreneurship, and innovation.
Even Singapore remains center stage as a regional hub for oversea trade and investment. It is relatively the largest share recipient of FDI in ASEAN. Though, those FDI inflows are mainly classified in the financial and insurance services and wholesale and retail trade sectors, while the manufacturing and real estate sectors play only a minor capacity. Consequently, this seems to be a weak link between recorded FDI flows and real economic activities in foreign-owned companies in Singapore (
Sjöholm 2016). FDI performances undertaken by Singapore are likely untrustworthy. In addition, since Singapore is voluntarily open internationally, its economy indeed depends on the global economy. Hence, it is vulnerable with the world economy and its main trading partner’s economic situations.
3.4. Stochastic Dominance Analysis
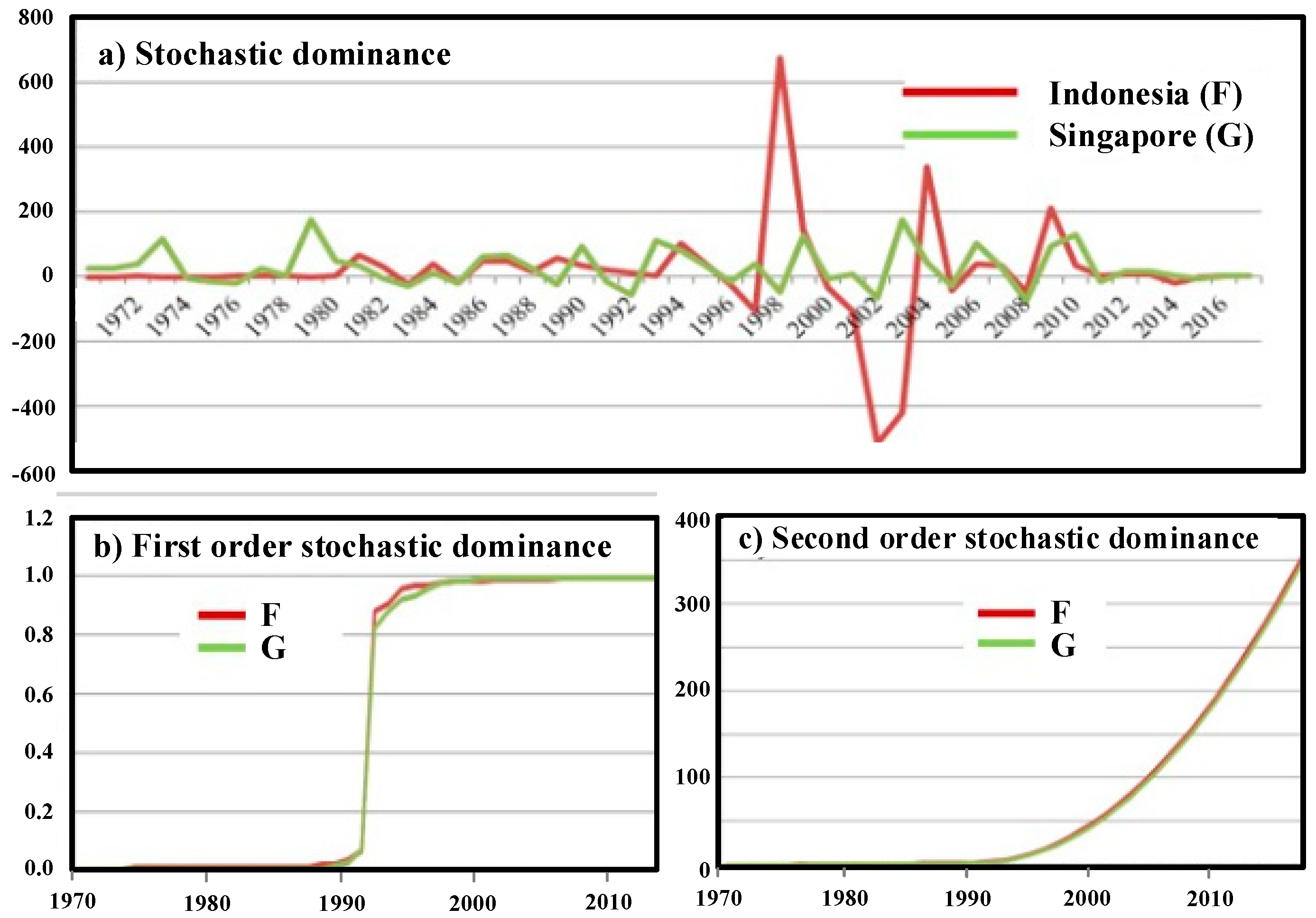
To deeply look inside more accurate results of the FDI analyses, we applied the stochastic dominance-based entropy approach between Indonesia and Singapore. Let
F and
G denote the CDF of FDI for Indonesia and Singapore, respectively. It is clearly seen that the distribution of FDI-based MEboot method in Indonesia dominates that of the relevant parts in Singapore’s both first- and second-order stochastic dominance analyses, as depicted in
Figure 4b,c.
Since FDI occupies a special place in the link between economic progression and globalization, consequently, each host country should reach its actual relative position of FDI against competitors in order to enhance more competitiveness. This finding reveals that the directions of FDI in Indonesia (in particular), Thailand, and Singapore are the good representatives of all ASEAN-6 nations. In response, governments elsewhere should recognize that Indonesia, Thailand, and Singapore can display vital signs or leadership to boost up or slow down the FDI situation across ASEAN region. On the other hand, Malaysia, Vietnam, and the Philippines performed as followers and should improve their competitiveness by using government policies for attracting FDI, such as reforming business regulations, reforming and opening up policies, etc.
3.5. The Structural Dependence of Capital Flows in ASEAN by the C-Vine Copula Approach
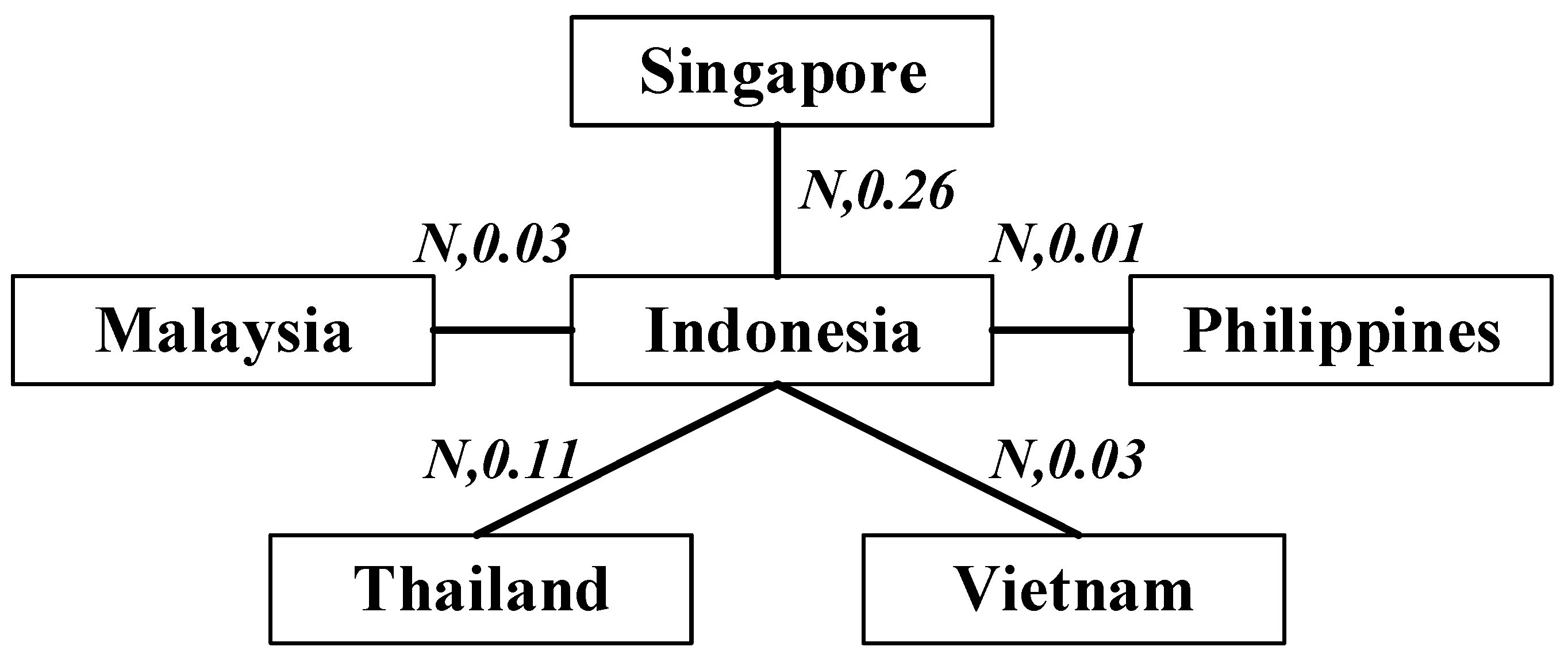
Technically, the FDI in Indonesia is determined as a leadership, which is the predominant sign for capital movements among ASEAN-6 nations. The consequence of variables is evidently supported by the CE and the stochastic dominant analyses as mentioned above. In the first levels, we estimated the empirical dependence measure using pairwise maximum likelihood estimation. Based on the C-vine copula structure (six variables, five5 trees and 15 edges), the estimated C-vine pair-copula parameters are 0.19, 0.38, 0.07, 0.05, 0.01, 0.22, 0.04, 0.19, −0.01, 0.45, −0.01, −0.01, 0.15, −0.03, and 0.02, and the log likelihood is 27.02. Then, we employed all of those relevant variables, which maximize the sum of empirical dependencies using the spanning tree algorithm, to graphically draw the tree of the specified C-vine corresponding to the pair-copula parameters as edge labels. Considering the details of
Figure 5, it is obvious that structural dependences dominated by Indonesian’s net capital flows are positive and influence the FDI directions for others. To summarize, Indonesia shows moderately positive dependencies with Singapore, within a Gaussian copula (
) with correlation
= 0.5, and Thailand (
, 0.11), whereas it has relatively low effects on Malaysia (
, 0.03), Vietnam (
, 0.03), and the Philippines (
, 0.01).
4. Conclusions
Since a time series regularly behaves as stochastic processes, the approaches using normal statistics may occur misspecified models. In the global economy, FDI has long been a key pillar in investment dynamic. Especially in ASEAN economy, FDI can enhance economic expansion at various levels of development. FDI flows to ASEAN have been rising since 2000, and the upward trend is reflective of attraction and confidence for oversea investment in the region. This causes ASEAN member states to rely more on the adoption of FDI. Then, this study sought to measure the competitive positions of each ASEAN nation. The findings would enhance the competitiveness of those ASEAN countries to understand, monitor and expedite FDI strategies in order to achieve effective aboard investment and attain competitive advantages across ASEAN economy. Consequently, we adopted the nonparametric methodology for multiprocessing analyses, including maximum entropy bootstrap method, cross-entropy algorithm, and the stochastic dominance analyses. For computational modelling, the AR-GARCH model was generated to obtain residual terms using the MEboot method. Furthermore, the C-vine copula model was applied to determine the structural dependence of FDI in ASEAN. The main findings can be drawn as follows:
From basically testing and measuring the correlations between two variables, we found Indonesia has a more positive influence than other nations using the nonparametric correlations of Kendall’s tau and Spearman’s rho at the 0.01 and 0.05 levels of significance ranks.
For advanced investigations on the classification tasks, the CE was preferred instead of the classification on parametric correlation, since it incorporates with entropy (information content) when handling all of the probabilities. It works with a very specific set of possible output values to evaluate the quality of the system network. Empirically, Indonesia performs the narrowest CE point compared to the overall Entropy point, followed by Thailand and Singapore, implying that Indonesia, Thailand, and Singapore can be identified as the main indicators for the FDI directions in the ASEAN.
Being precisely supported by the first- and second-order stochastic dominance analyses, Indonesia is perceived as a leading indicator of FDI direction in ASEAN.
Moreover, the structural dependence model called the C-vine copula strongly emphasized that the net capital flows in ASEAN rely on the capital movements in Indonesia. The positive dependences are obvious for the overall analysis.
This study has some policy implications. Therefore, the performances of FDI in Indonesia, Thailand, and Singapore can be evidently viewed as the key indicators for trends and developments of FDI in the ASEAN region. The Governments of Malaysia, Vietnam, and the Philippines should create more incentives toward FDI policies, such as competitive positioning, investment promotion, a degree of economic stability, etc. According to a positive correlation between FDI inflows, the enhancement to strengthen the ASEAN economic integration can bring benefits across the ASEAN economy.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}