Emotion Recognition from Speech Using the Bag-of-Visual Words on Audio Segment Spectrograms †


Abstract
:1. Introduction
2. Related Work
2.1. Non-Linguistic Approaches for Emotion Recognition
2.2. Emotion Recognition in Education
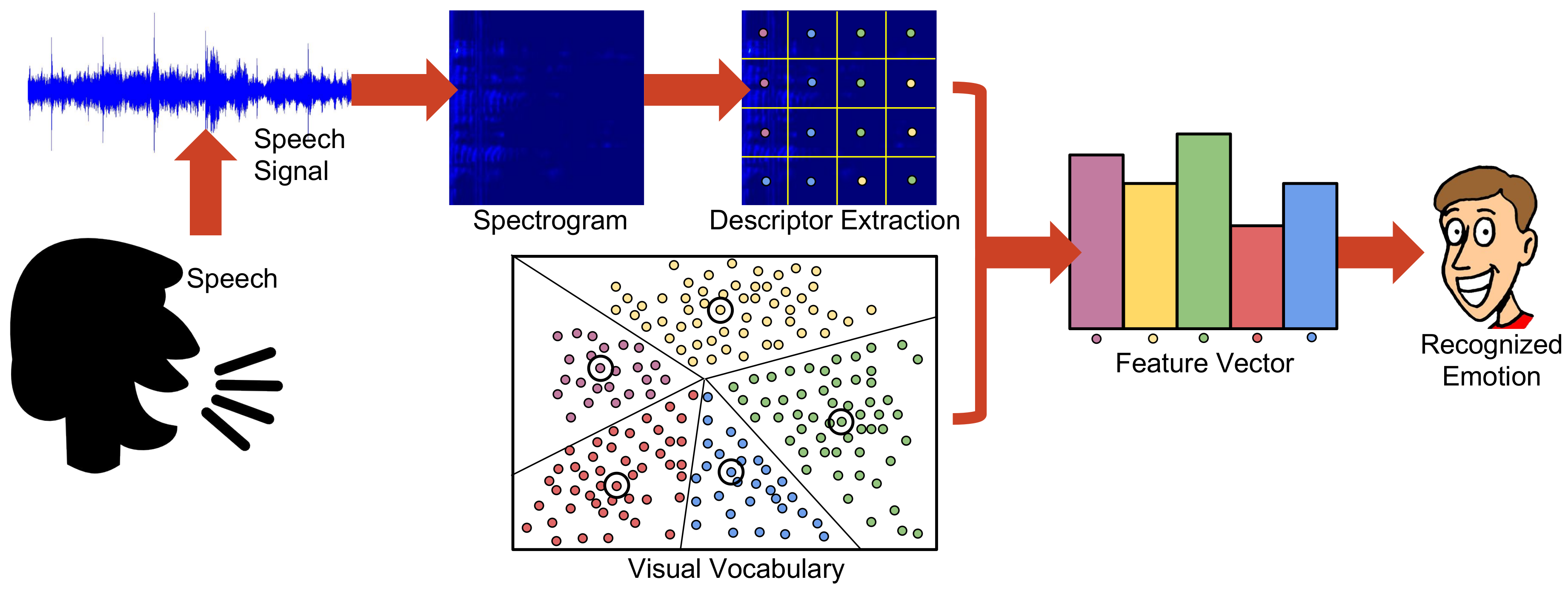
3. Emotion Recognition from Spectrograms Using BoVW
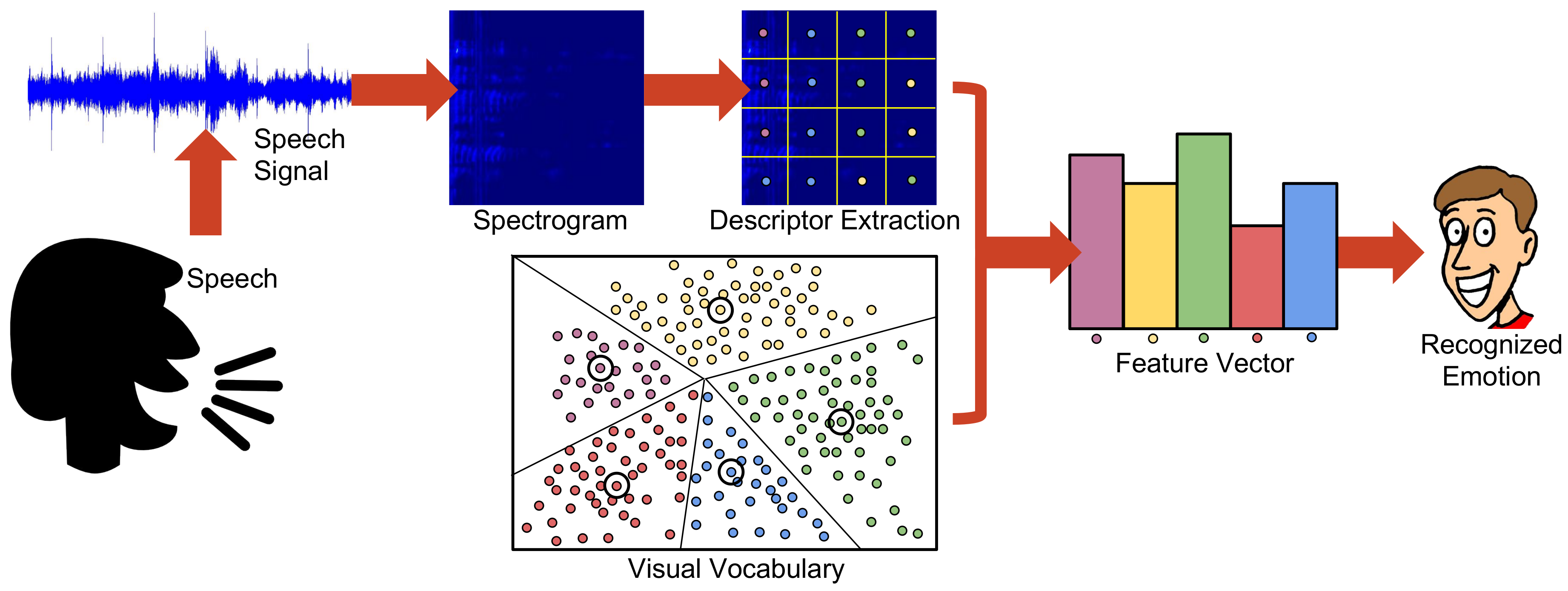
3.1. The BoVW Model
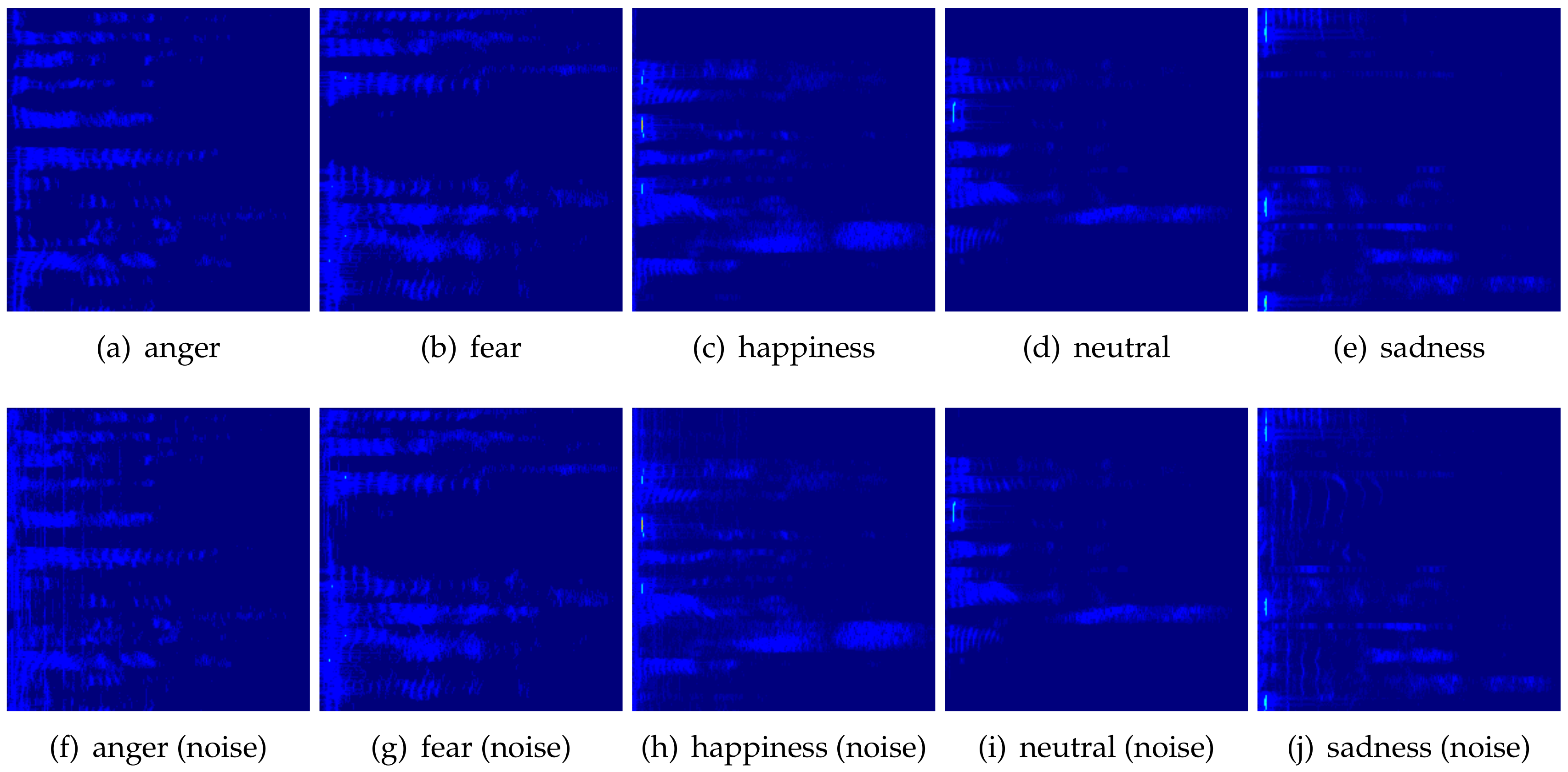
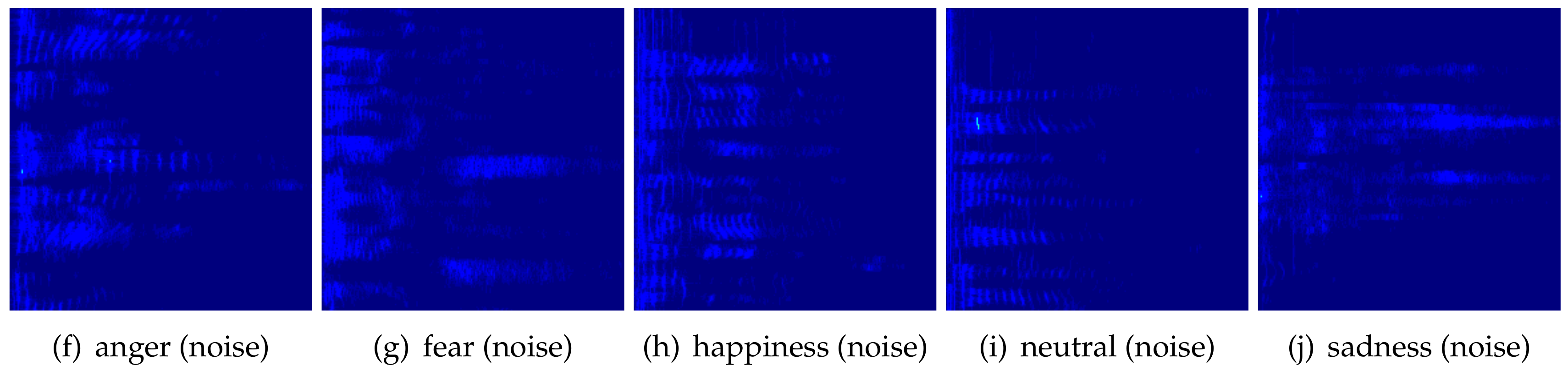
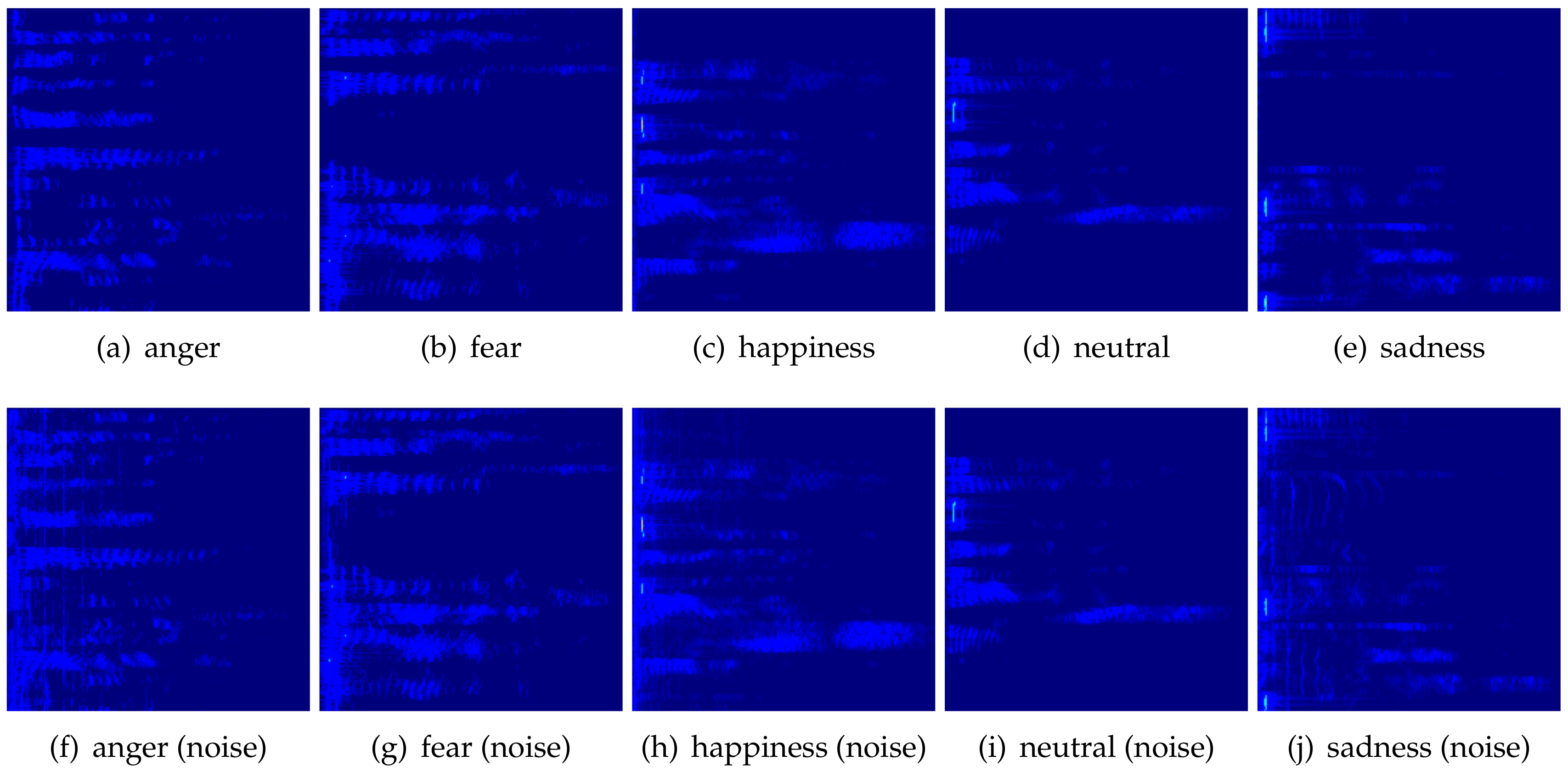
3.2. Spectrogram Generation
3.3. Emotion Recognition Using BoVW
4. Experiments
4.1. Artificial Datasets
4.2. Real-Life Classroom Experiment
4.3. Results
5. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Cowie, R.; Douglas-Cowie, E.; Tsapatsoulis, N.; Votsis, G.; Kollias, S.; Fellenz, W.; Taylor, J.G. Emotion recognition in human-computer interaction. IEEE Signal Process. Mag. 2001, 18, 32–80. [Google Scholar] [CrossRef]
- Poria, S.; Chaturvedi, I.; Cambria, E.; Hussain, A. Convolutional MKL based multimodal emotion recognition and sentiment analysis. In Proceedings of the 2016 IEEE 16th International Conference on Data Mining, Barcelona, Spain, 12–15 December 2016; pp. 439–448. [Google Scholar]
- Zeng, E.; Mare, S.; Roesner, F. End user security and privacy concerns with smart homes. In Proceedings of the Third Symposium on Usable Privacy and Security (SOUPS), Pittsburgh, PA, USA, 18–20 July 2007. [Google Scholar]
- Anagnostopoulos, C.N.; Iliou, T.; Giannoukos, I. Features and classifiers for emotion recognition from speech: A survey from 2000 to 2011. Artif. Intell. Rev. 2015, 43, 155–177. [Google Scholar] [CrossRef]
- El Ayadi, M.; Kamel, M.S.; Karray, F. Survey on speech emotion recognition: Features, classification schemes, and databases. Pattern Recognit. 2011, 44, 572–587. [Google Scholar] [CrossRef]
- Alibali, M.W.; Knuth, E.J.; Hattikudur, S.; McNeil, N.M.; Stephens, A.C. A Longitudinal Examination of Middle School Students’ Understanding of the Equal Sign and Equivalent Equations. Math. Think. Learn. 2007, 9, 221–247. [Google Scholar] [CrossRef]
- Fei-Fei, L.; Perona, P. A bayesian hierarchical model for learning natural scene categories. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005; Volume 2, pp. 524–531. [Google Scholar]
- Spyrou, E.; Giannakopoulos, T.; Sgouropoulos, D.; Papakostas, M. Extracting emotions from speech using a bag-of-visual-words approach. In Proceedings of the 12th International Workshop on Semantic and Social Media Adaptation and Personalizationon, Bratislava, Slovakia, 9–10 July 2017; pp. 80–83. [Google Scholar]
- Wang, Y.; Guan, L. Recognizing human emotional state from audiovisual signals. IEEE Trans. Multimedia 2008, 10, 936–946. [Google Scholar] [CrossRef]
- Nwe, T.L.; Foo, S.W.; De Silva, L.C. Speech emotion recognition using hidden Markov models. Speech Commun. 2003, 41, 603–623. [Google Scholar] [CrossRef]
- Hanjalic, A. Extracting moods from pictures and sounds: Towards truly personalized TV. IEEE Signal Process. Mag. 2006, 23, 90–100. [Google Scholar] [CrossRef]
- Lu, L.; Liu, D.; Zhang, H.J. Automatic mood detection and tracking of music audio signals. IEEE Trans. Audio Speech Lang. Process. 2006, 14, 5–18. [Google Scholar] [CrossRef]
- Yang, Y.H.; Lin, Y.C.; Su, Y.F.; Chen, H.H. A regression approach to music emotion recognition. IEEE Trans. Audio Speech Lang. Process. 2008, 16, 448–457. [Google Scholar] [CrossRef]
- Wöllmer, M.; Eyben, F.; Reiter, S.; Schuller, B.; Cox, C.; Douglas-Cowie, E.; Cowie, R. Abandoning emotion classes-towards continuous emotion recognition with modelling of long-range dependencies. In Proceedings of the INTERSPEECH 9th Annual Conference of the International Speech Communication Association, Brisbane, Australia, 22–26 September 2008; pp. 597–600. [Google Scholar]
- Giannakopoulos, T.; Pikrakis, A.; Theodoridis, S. A dimensional approach to emotion recognition of speech from movies. In Proceedings of the 2009 IEEE International Conference on Acoustics, Speech and Signal Processing, Taipei, Taiwan, 19–24 April 2009; pp. 65–68. [Google Scholar]
- Grimm, M.; Kroschel, K.; Mower, E.; Narayanan, S. Primitives-based evaluation and estimation of emotions in speech. Speech Commun. 2007, 49, 787–800. [Google Scholar] [CrossRef]
- Robert, P. Emotion: Theory, Research, and Experience. Vol. 1: Theories of Emotion; Academic Press: Cambridge, MA, USA, 1980. [Google Scholar]
- Lee, H.; Pham, P.; Largman, Y.; Ng, A.Y. Unsupervised feature learning for audio classification using convolutional deep belief networks. In Proceedings of the 22nd International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 7–10 December 2009; pp. 1096–1104. [Google Scholar]
- Zhang, T.; Kuo, C.C.J. Audio content analysis for online audiovisual data segmentation and classification. IEEE Trans. Speech Audio Process. 2001, 9, 441–457. [Google Scholar] [CrossRef]
- He, L.; Lech, M.; Maddage, N.; Allen, N. Stress and emotion recognition using log-Gabor filter analysis of speech spectrograms. In Proceedings of the 3rd International Conference on Affective Computing and Intelligent Interaction and Workshops, Amsterdam, Netherlands, 10–12 September 2009; pp. 1–6. [Google Scholar]
- Mao, Q.; Dong, M.; Huang, Z.; Zhan, Y. Learning salient features for speech emotion recognition using convolutional neural networks. IEEE Trans. Multimedia 2014, 16, 2203–2213. [Google Scholar] [CrossRef]
- Papakostas, M.; Spyrou, E.; Giannakopoulos, T.; Siantikos, G.; Sgouropoulos, D.; Mylonas, P.; Makedon, F. Deep Visual Attributes vs. Hand-Crafted Audio Features on Multidomain Speech Emotion Recognition. Computation 2017, 5, 26. [Google Scholar] [CrossRef]
- Picard, R.W.; Papert, S.; Bender, W.; Blumberg, B.; Breazeal, C.; Cavallo, D.; Machover, T.; Resnick, M.; Roy, D.; Strohecker, C. Affective learning—A manifesto. BT Technol. J. 2004, 22, 253–269. [Google Scholar] [CrossRef]
- Mahn, H.; John-Steiner, V. The gift of confidence: A Vygotskian view of emotions. In Learning for Life in the 21st Century: Sociocultural Perspectives on the Future of Education; Wiley: Hoboken, NJ, USA, 2002; pp. 46–58. [Google Scholar] [CrossRef]
- Kołakowska, A.; Landowska, A.; Szwoch, M.; Szwoch, W.; Wrobel, M.R. Emotion recognition and its applications. Hum. Comput. Syst. Interact. Backgr. Appl. 2014, 3, 51–62. [Google Scholar]
- Sutton, R.E.; Wheatley, K.F. Teachers’ emotions and teaching: A review of the literature and directions for future research. Educ. Psychol. Rev. 2003, 15, 327–358. [Google Scholar] [CrossRef]
- Howes, C. Social-emotional classroom climate in child care, child-teacher relationships and children’s second grade peer relations. Soc. Dev. 2000, 9, 191–204. [Google Scholar] [CrossRef]
- Sutton, R.E. Emotional regulation goals and strategies of teachers. Soc. Psychol. Educ. 2004, 7, 379–398. [Google Scholar] [CrossRef]
- Fried, L. Teaching teachers about emotion regulation in the classroom. Aust. J. Teach. Educ. 2011, 36, 3. [Google Scholar] [CrossRef]
- Macklem, G.L. Practitioner’s Guide to Emotion Regulation in School-Aged Children; Springer Science and Business Media: New York, NY, USA, 2007. [Google Scholar]
- Macklem, G.L. Boredom in the Classroom: Addressing Student Motivation, Self-Regulation, and Engagement in Learning; Springer: New York, NY, USA, 2015; Volume 1. [Google Scholar]
- Linnenbrink, E.A.; Pintrich, P.R. Multiple pathways to learning and achievement: The role of goal orientation in fostering adaptive motivation, affect, and cognition. In Intrinsic and Extrinsic Motivation: The Search for Optimal Motivation and Performance; Sansone, C., Harackiewicz, J.M., Eds.; Academic Press: San Diego, CA, USA, 2000; pp. 195–227. [Google Scholar] [CrossRef]
- Weare, K. Developing the Emotionally Literate School; Sage: London, UK, 2003. [Google Scholar]
- Martiínez, J.G. Recognition and emotions. A critical approach on education. Procedia Soc. Behav. Sci. 2012, 46, 3925–3930. [Google Scholar] [CrossRef]
- Tickle, A.; Raghu, S.; Elshaw, M. Emotional recognition from the speech signal for a virtual education agent. J. Phys. Conf. Ser. 2013, 450, 012053. [Google Scholar] [CrossRef]
- Bahreini, K.; Nadolski, R.; Westera, W. Towards real-time speech emotion recognition for affective e-learning. Educ. Inf. Technol. 2016, 21, 1367–1386. [Google Scholar] [CrossRef]
- Bahreini, K.; Nadolski, R.; Qi, W.; Westera, W. FILTWAM—A framework for online game-based communication skills training—Using webcams and microphones for enhancing learner support. In The 6th European Conference on Games Based Learning (ECGBL); Felicia, P., Ed.; Academic Conferences and Publishing International: Reading, UK, 2012; pp. 39–48. [Google Scholar]
- Arroyo, I.; Cooper, D.G.; Burleson, W.; Woolf, B.P.; Muldner, K.; Christopherson, R. Emotion sensors go to school. AIED 2009, 200, 17–24. [Google Scholar]
- Kim, Y.; Soyata, T.; Behnagh, R.F. Towards emotionally aware AI smart classroom: Current issues and directions for engineering and education. IEEE Access 2018, 6, 5308–5331. [Google Scholar] [CrossRef]
- Spyrou, E.; Vretos, N.; Pomazanskyi, A.; Asteriadis, S.; Leligou, H.C. Exploiting IoT Technologies for Personalized Learning. In Proceedings of the 2018 IEEE Conference on Computational Intelligence and Games (CIG), Maastricht, The Netherlands, 14–17 August 2018; pp. 1–8. [Google Scholar]
- Tsatsou, D.; Pomazanskyi, A.; Hortal, E.; Spyrou, E.; Leligou, H.C.; Asteriadis, S.; Vretos, N.; Daras, P. Adaptive Learning Based on Affect Sensing. Int. Conf. Artif. Intell. Educ. 2018, 10948, 475–479. [Google Scholar]
- Harris, Z.S. Distributional structure. Word 1954, 10, 146–162. [Google Scholar] [CrossRef]
- Sivic, J.; Zisserman, A. Efficient visual search of videos cast as text retrieval. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 591–606. [Google Scholar] [CrossRef] [PubMed]
- Costantini, G.; Iaderola, I.; Paoloni, A.; Todisco, M. Emovo corpus: An italian emotional speech database. In Proceedings of the International Conference on Language Resources and Evaluation (LREC 2014), Reykjavik, Iceland, 26–31 May 2014; pp. 3501–3504. [Google Scholar]
- Burkhardt, F.; Paeschke, A.; Rolfes, M.; Sendlmeier, W.F.; Weiss, B. A database of German emotional speech. In Proceedings of the Ninth European Conference on Speech Communication and Technology, Lisbon, Portugal, 4–8 September 2005. [Google Scholar]
- Haq, S.; Jackson, P.J.; Edge, J. Speaker-dependent audio-visual emotion recognition. In Proceedings of the 2009 International Conference on Auditory-Visual Speech Processing, Norwich, UK, 10–13 September 2009; pp. 53–58. [Google Scholar]
- Bay, H.; Ess, A.; Tuytelaars, T.; Van Gool, L. Speeded-up robust features (SURF). Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Alfanindya, A.; Hashim, N.; Eswaran, C. Content Based Image Retrieval and Classification using speeded-up robust features (SURF) and grouped bag-of-visual-words (GBoVW). In Proceedings of the 2013 International Conference on Technology, Informatics, Management, Engineering and Environment, Bandung, Indonesia, 23–26 June 2013. [Google Scholar]
- Tuytelaars, T. Dense interest points. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 2281–2288. [Google Scholar]
- Mindstorms. Available online: https://www.lego.com/en-us/mindstorms (accessed on 3 February 2019).
- Scratch. Available online: https://scratch.mit.edu/ (accessed on 3 February 2019).
- Audacity. Available online: https://www.audacityteam.org/ (accessed on 3 February 2019).
- MATLAB and Computer Vision Toolbox Release, 2017a; The MathWorks, Inc.: Natick, MA, USA.
- Giannakopoulos, T. pyaudioanalysis: An open-source python library for audio signal analysis. PLoS ONE 2015, 10, e0144610. [Google Scholar] [CrossRef] [PubMed]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Guo, Z.; Zhang, L.; Zhang, D. A completed modeling of local binary pattern operator for texture classification. IEEE Trans. Image Process. 2010, 19, 1657–1663. [Google Scholar] [PubMed]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Train | Test | With Noise | Without Noise | ||
|---|---|---|---|---|---|
| Vocabulary Size N | Best Mean-F Score | Vocabulary Size N | Best Mean-F Score | ||
| EMOVO, EMO-DB | EMOVO, EMO-DB | 1100 | 0.50 | 1400 | 0.51 |
| EMOVO, movies | EMOVO, movies | 500 | 0.39 | 1100 | 0.40 |
| EMOVO, SAVEE | EMOVO, SAVEE | 500 | 0.41 | 800 | 0.41 |
| EMOVO | EMOVO | 1100 | 0.49 | 800 | 0.54 |
| EMO-DB, movies | EMO-DB, movies | 800 | 0.49 | 1300 | 0.49 |
| EMO-DB, SAVEE | EMO-DB, SAVEE | 1000 | 0.50 | 1100 | 0.55 |
| EMO-DB | EMO-DB | 1500 | 0.65 | 500 | 0.64 |
| movies, SAVEE | movies, SAVEE | 1200 | 0.40 | 1500 | 0.39 |
| movies | movies | 1400 | 0.47 | 200 | 0.41 |
| SAVEE | SAVEE | 1500 | 0.43 | 1500 | 0.49 |
| EMOVO | EMO-DB | 200 | 0.40 | 100 | 0.43 |
| EMOVO | SAVEE | 1500 | 0.18 | 1500 | 0.18 |
| EMO-DB | EMOVO | 1500 | 0.37 | 100 | 0.37 |
| EMO-DB | SAVEE | 1400 | 0.14 | 700 | 0.14 |
| SAVEE | EMOVO | 1200 | 0.16 | 300 | 0.13 |
| SAVEE | EMO-DB | 1300 | 0.16 | 1500 | 0.14 |
| EMOVO | movies | 1300 | 0.22 | 200 | 0.20 |
| EMO-DB | movies | 500 | 0.24 | 700 | 0.29 |
| movies | EMOVO | 1300 | 0.28 | 500 | 0.30 |
| movies | EMO-DB | 900 | 0.38 | 400 | 0.35 |
| movies | SAVEE | 800 | 0.24 | 600 | 0.32 |
| SAVEE | movies | 1400 | 0.28 | 500 | 0.20 |
| SAVEE, movies, EMO-DB | EMOVO | 400 | 0.34 | 1300 | 0.34 |
| EMOVO, movies, SAVEE | EMO-DB | 300 | 0.43 | 400 | 0.48 |
| EMOVO, EMO-DB, SAVEE | movies | 200 | 0.27 | 1200 | 0.25 |
| EMOVO, EMO-DB, movies | SAVEE | 900 | 0.24 | 400 | 0.24 |
| Proposed | Baseline 1 | Baseline 2 | |
|---|---|---|---|
| EMOVO | 0.49 | 0.42 | 0.45 |
| SAVEE | 0.43 | 0.32 | 0.30 |
| EMO-DB | 0.65 | 0.68 | 0.80 |
| movies | 0.47 | 0.39 | 0.32 |
| kids | 0.83 | 0.73 | 0.75 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Spyrou, E.; Nikopoulou, R.; Vernikos, I.; Mylonas, P. Emotion Recognition from Speech Using the Bag-of-Visual Words on Audio Segment Spectrograms. Technologies 2019, 7, 20. https://doi.org/10.3390/technologies7010020
Spyrou E, Nikopoulou R, Vernikos I, Mylonas P. Emotion Recognition from Speech Using the Bag-of-Visual Words on Audio Segment Spectrograms. Technologies. 2019; 7(1):20. https://doi.org/10.3390/technologies7010020
Chicago/Turabian StyleSpyrou, Evaggelos, Rozalia Nikopoulou, Ioannis Vernikos, and Phivos Mylonas. 2019. "Emotion Recognition from Speech Using the Bag-of-Visual Words on Audio Segment Spectrograms" Technologies 7, no. 1: 20. https://doi.org/10.3390/technologies7010020
APA StyleSpyrou, E., Nikopoulou, R., Vernikos, I., & Mylonas, P. (2019). Emotion Recognition from Speech Using the Bag-of-Visual Words on Audio Segment Spectrograms. Technologies, 7(1), 20. https://doi.org/10.3390/technologies7010020