Fuzzy Logic and Regression Approaches for Adaptive Sampling of Multimedia Traffic in Wireless Computer Networks †


Abstract
:1. Introduction
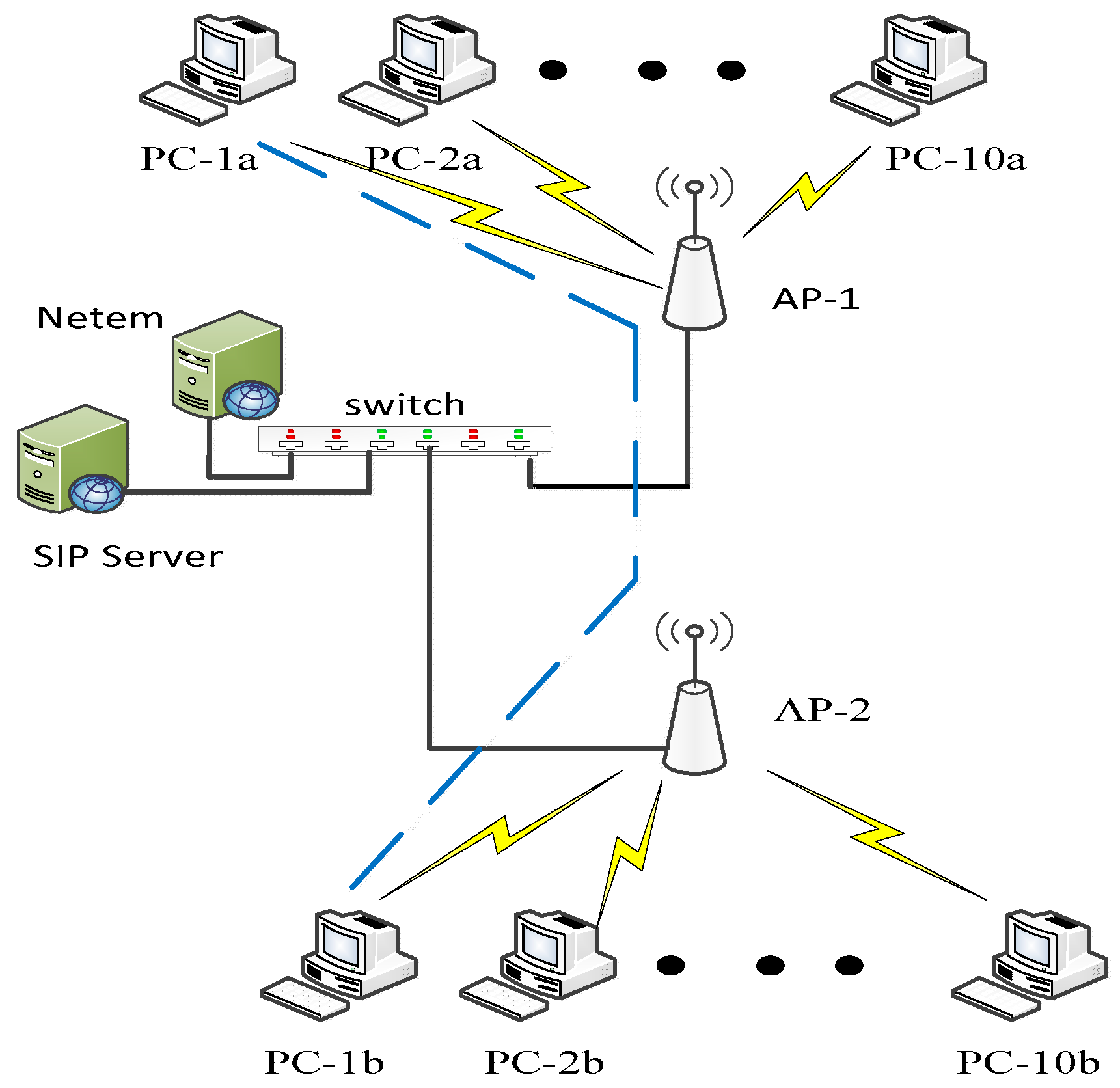
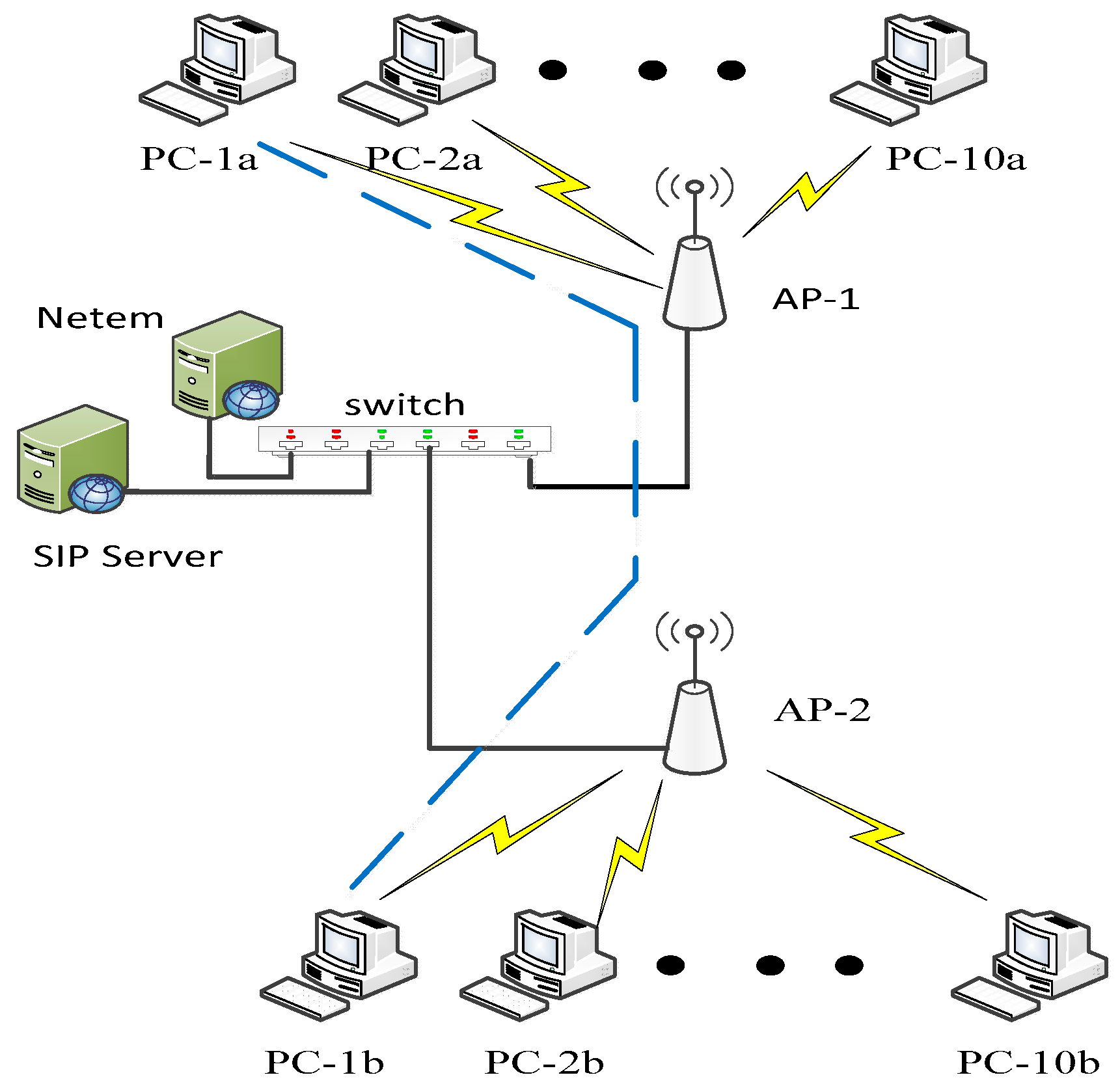
2. Materials and Methods
Network Traffic Parameters
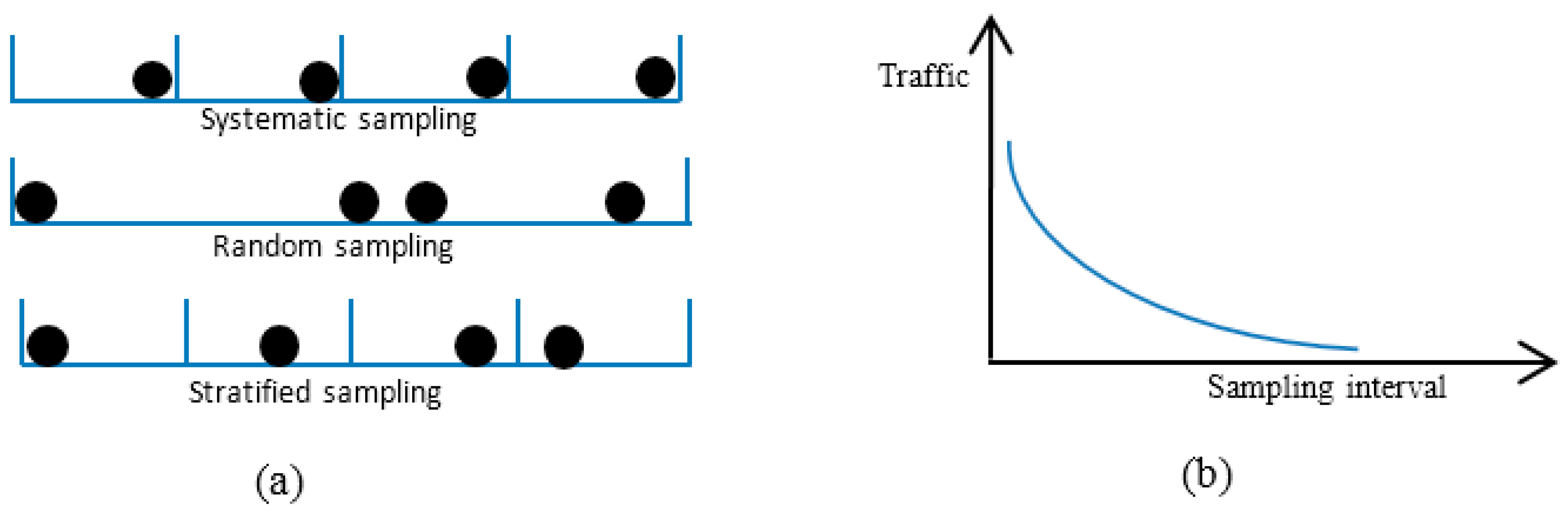
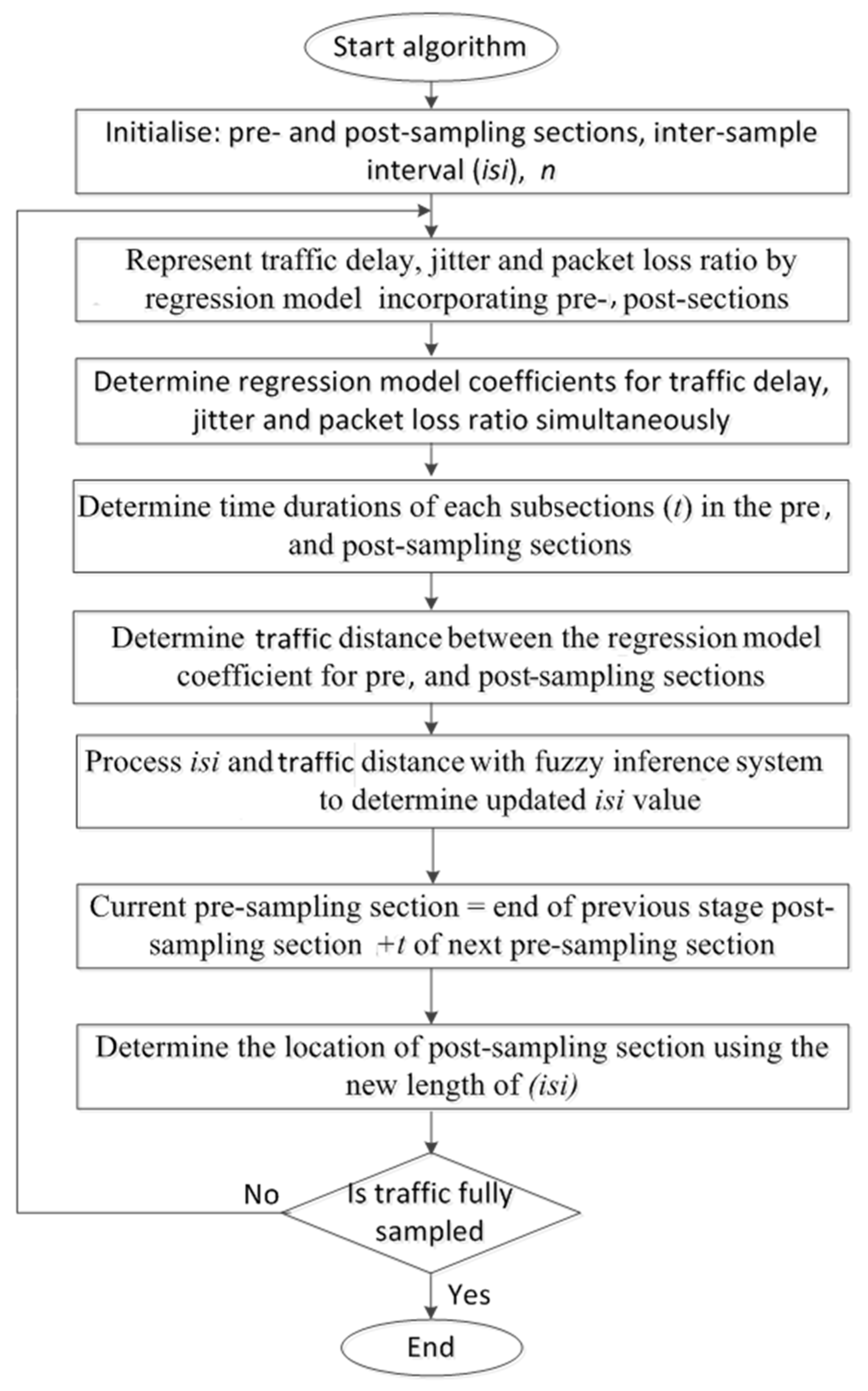
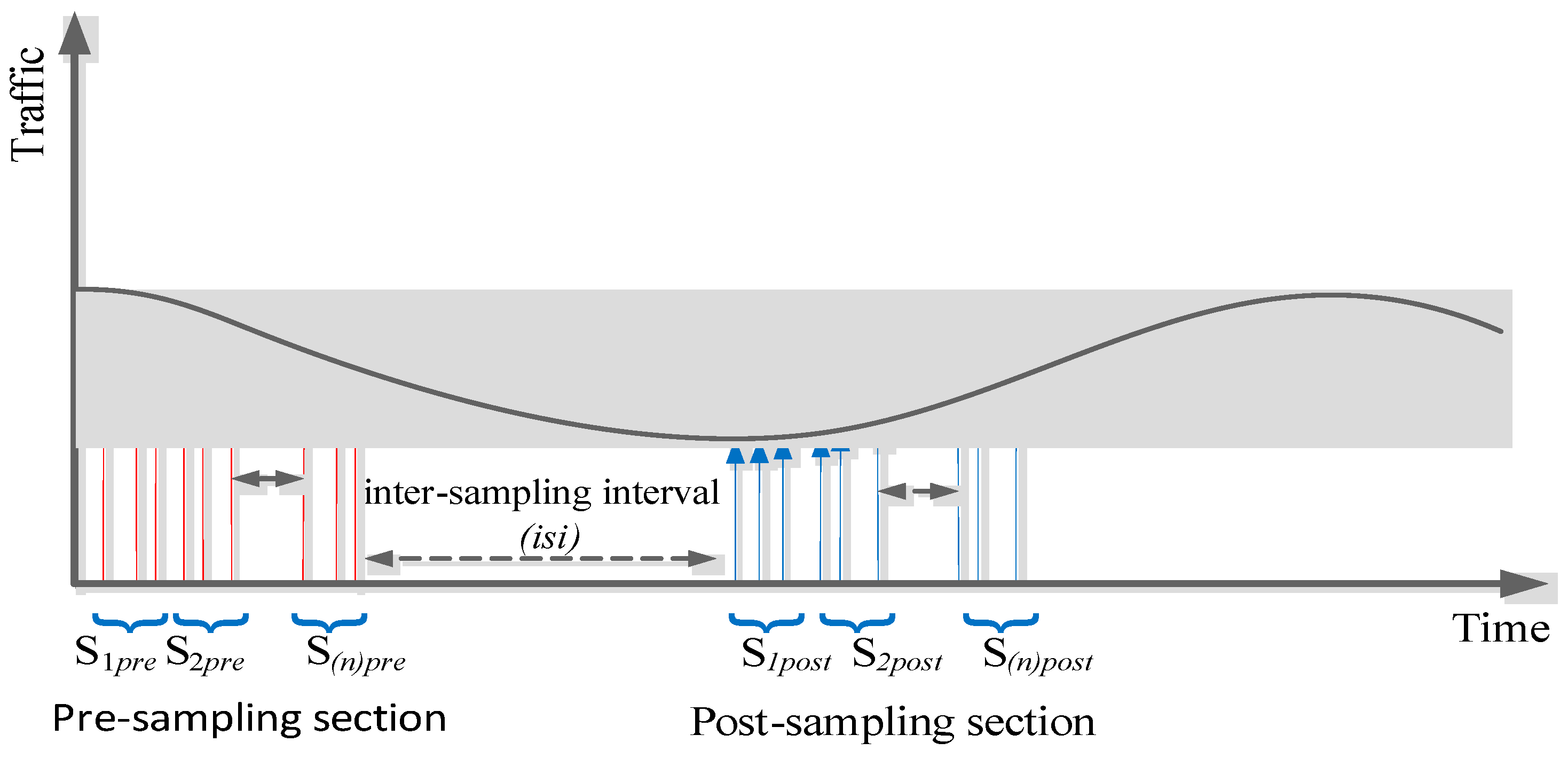
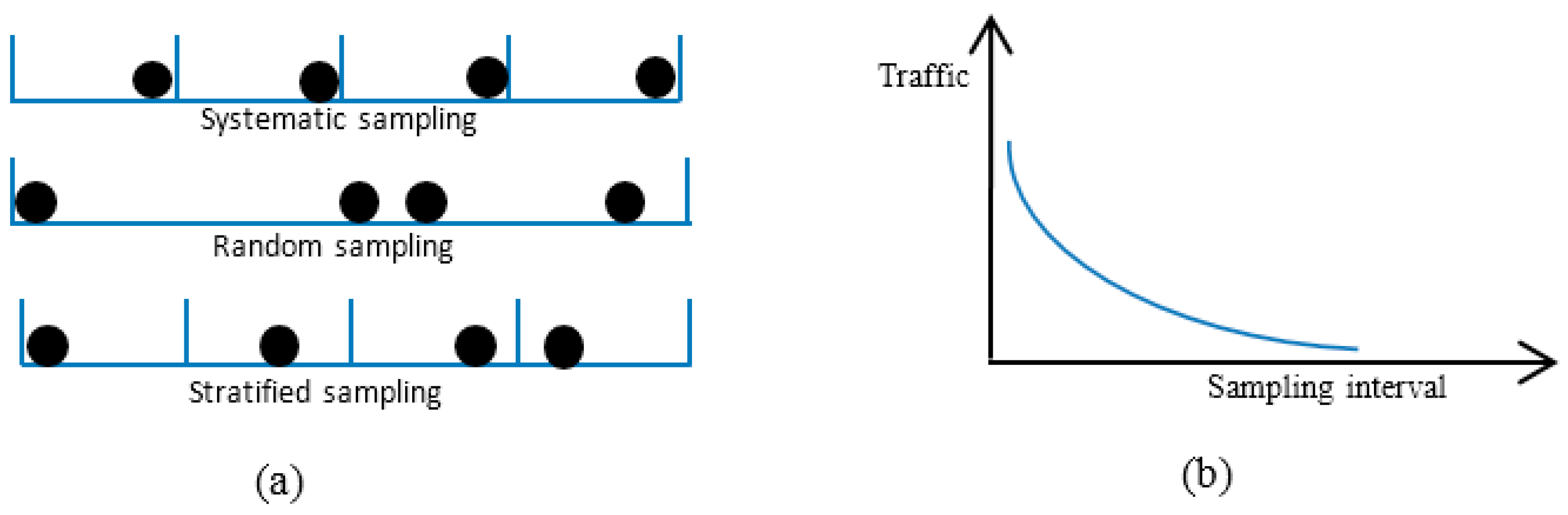
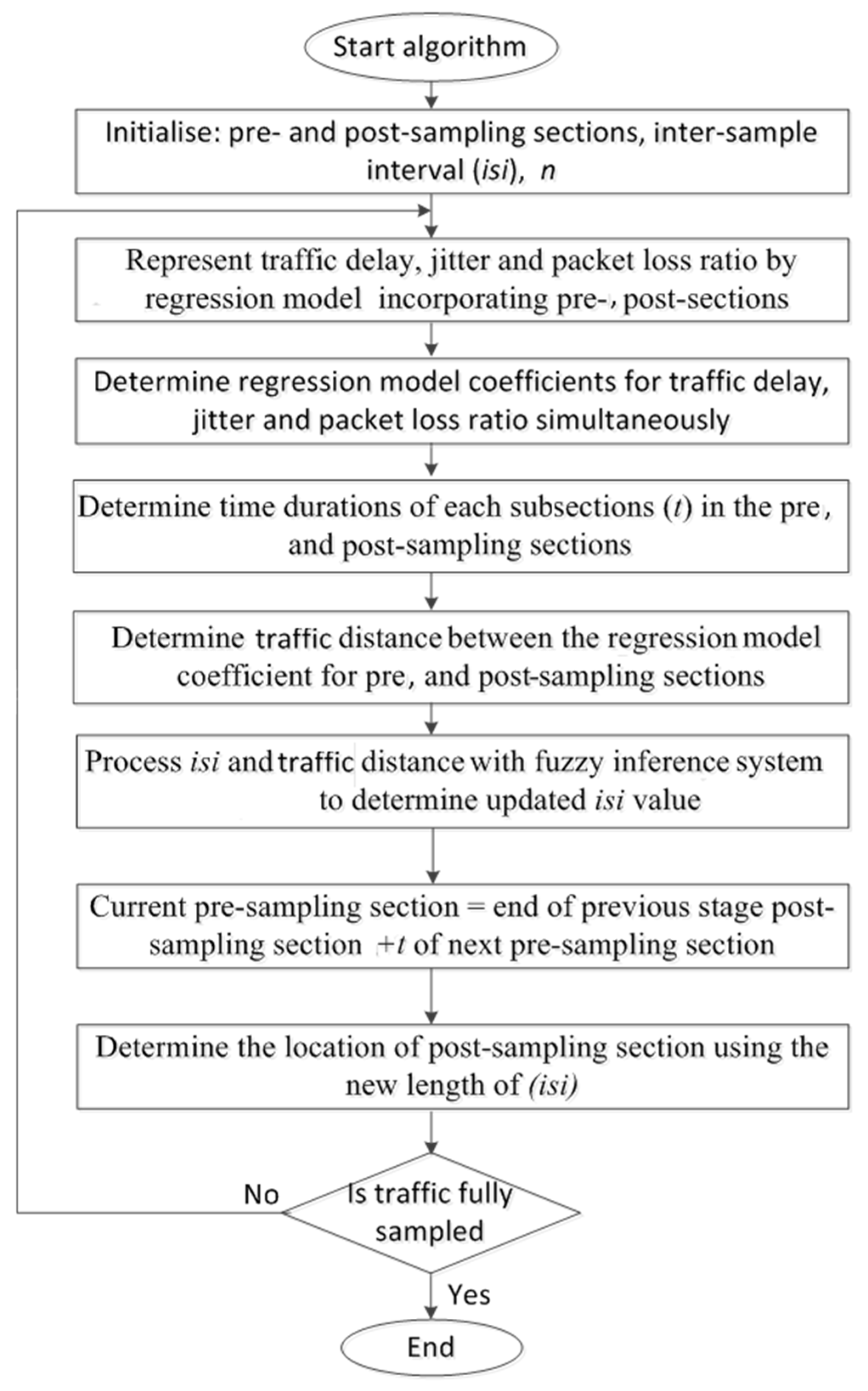
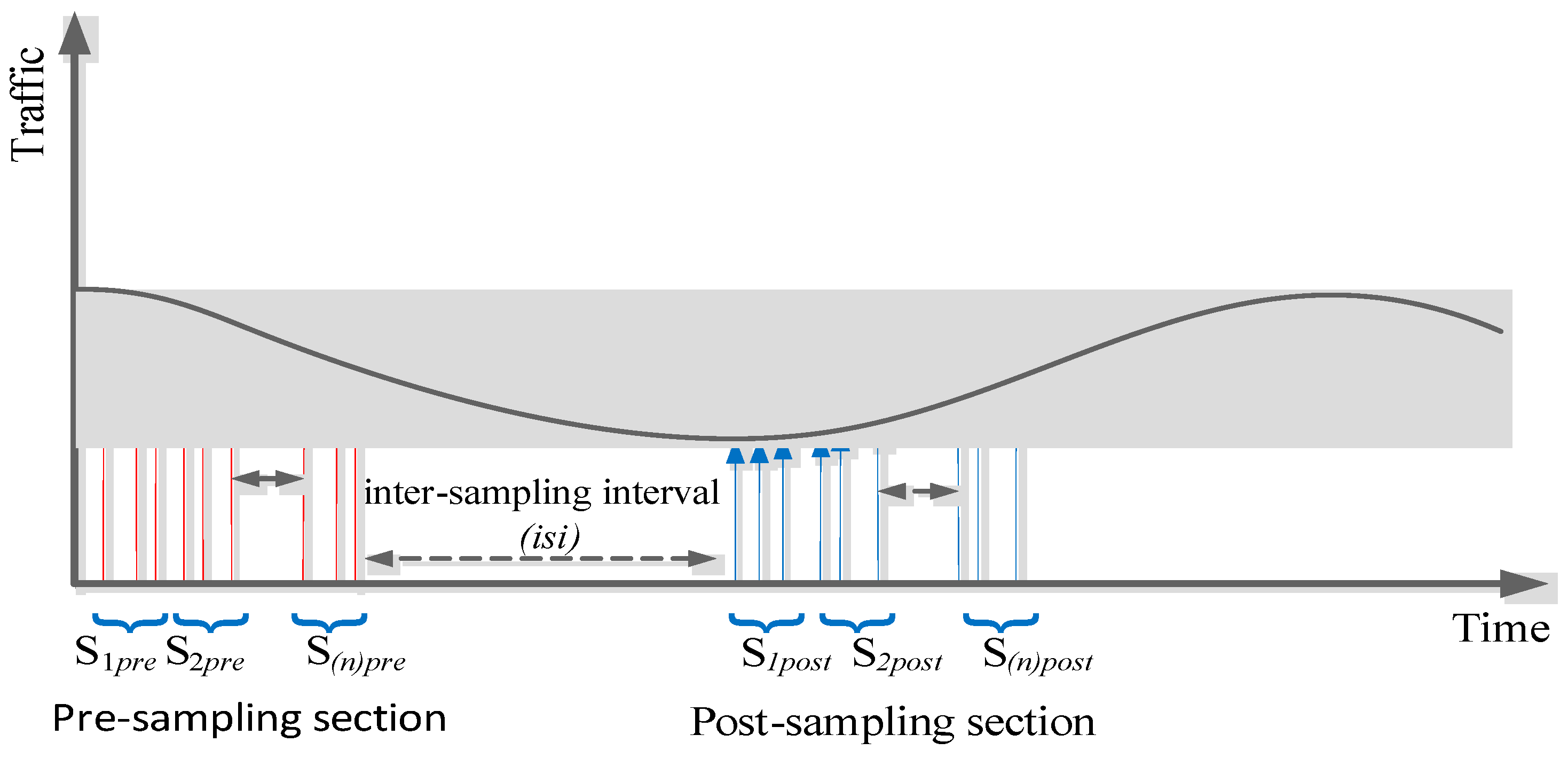
- Pre- and post-sampling sections: These sections contain the traffic that needs to be sampled. The durations of these sections are kept fixed (predefined) and do not change during the sampling process.
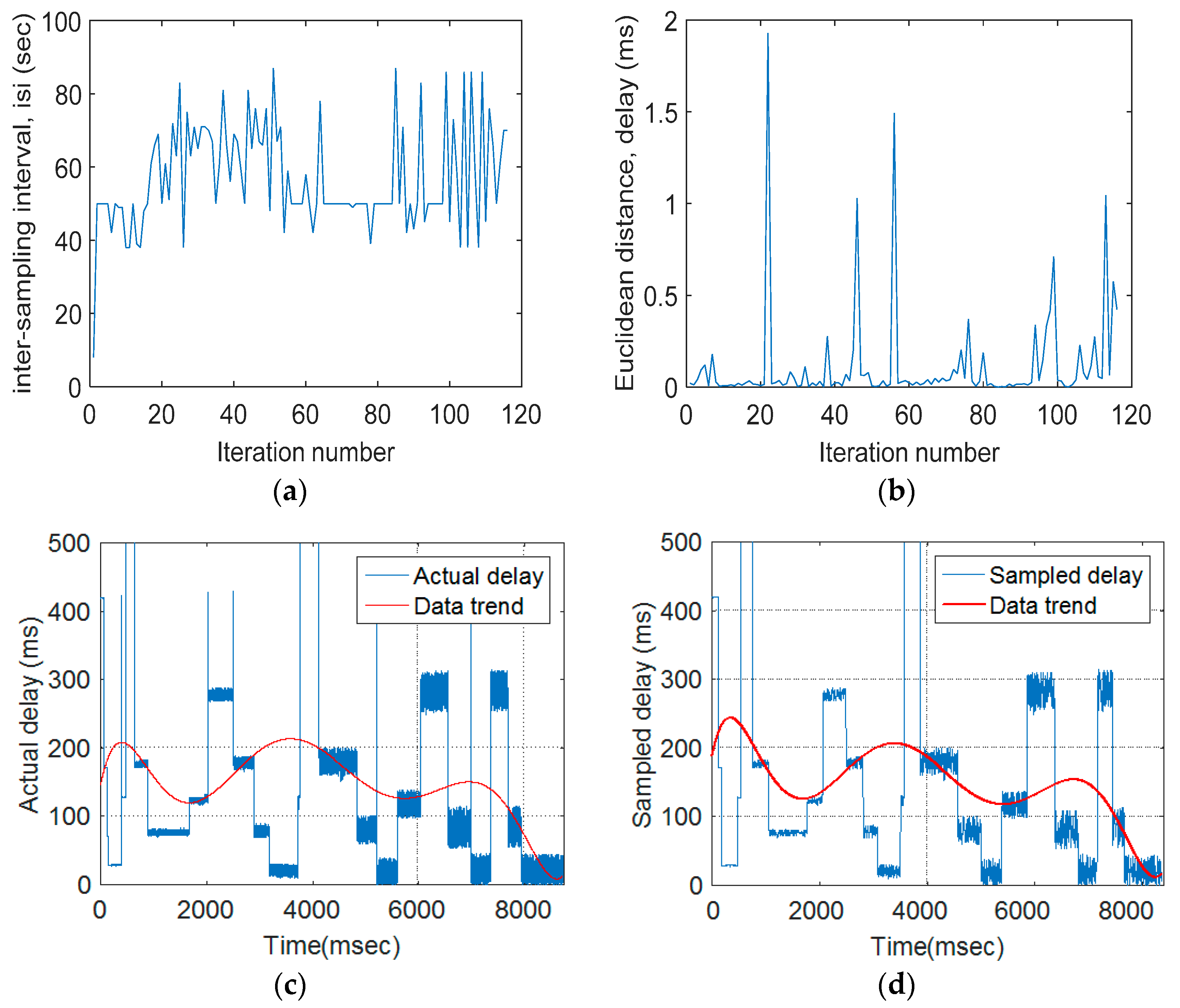
- Inter-section interval (isi): This interval is between the pre- and post-sampling sections. Its duration is adaptively updated by the FIS.
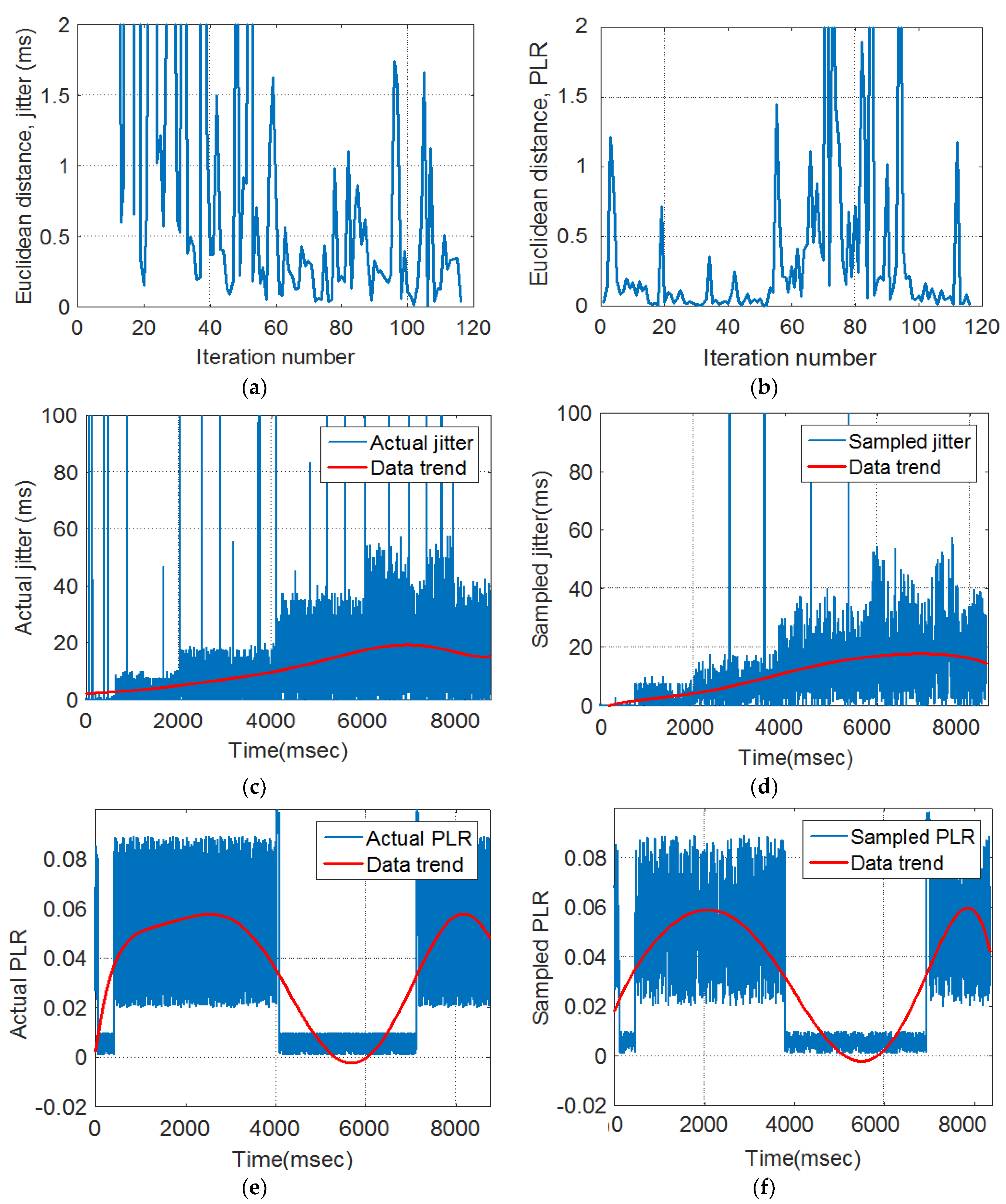
- Regression model: The traffic parameter (i.e., delay, jitter, and percentage packet loss ratio) were represented by an n × n matrix to allow regression analysis, where n is the number of subsections in the pre- and post-sampling sections. Each subsection contained n packets.
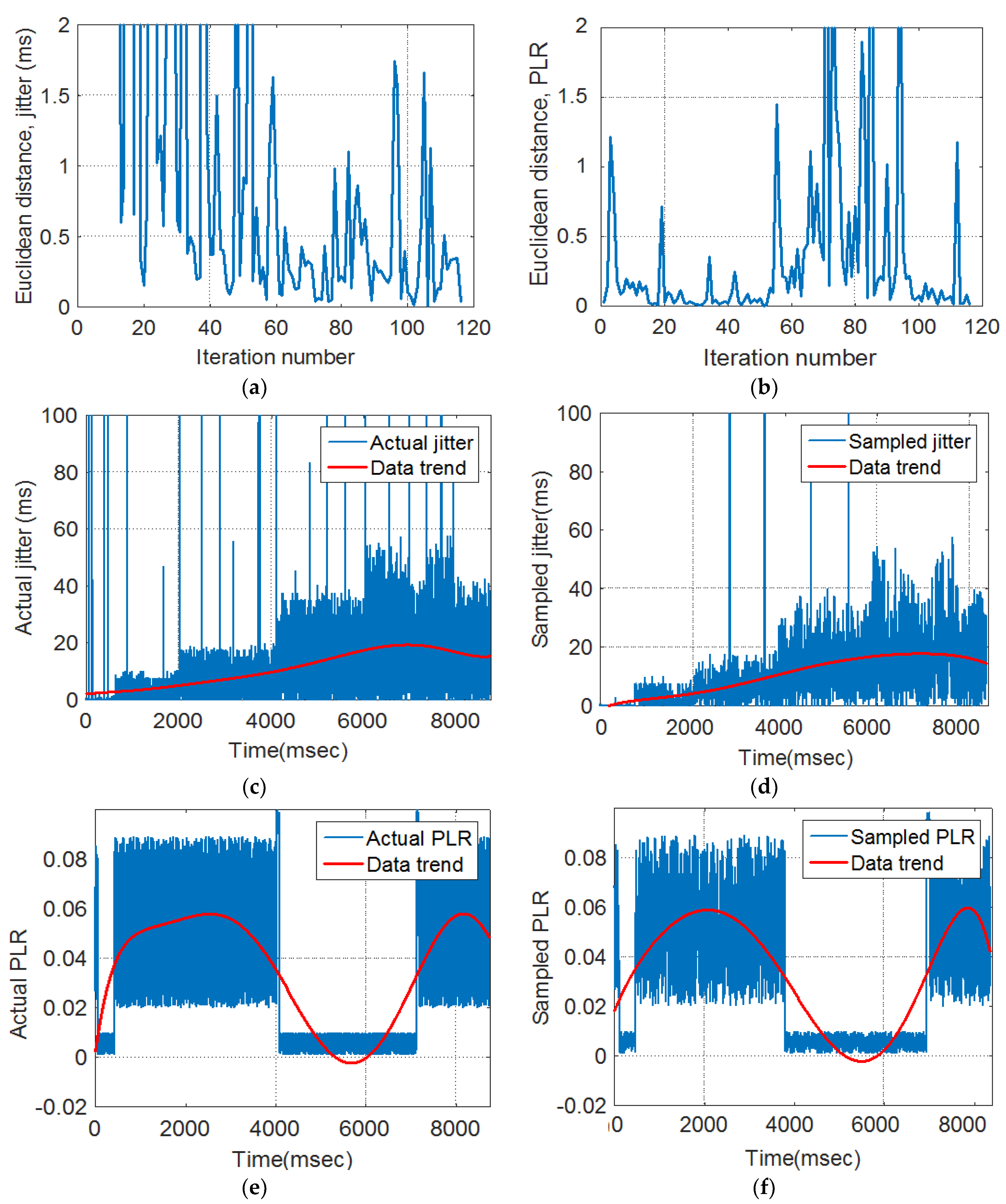
- Euclidean distance (ED): ED was used to quantify the extent of traffic variations between the pre- and post-sampling sections.
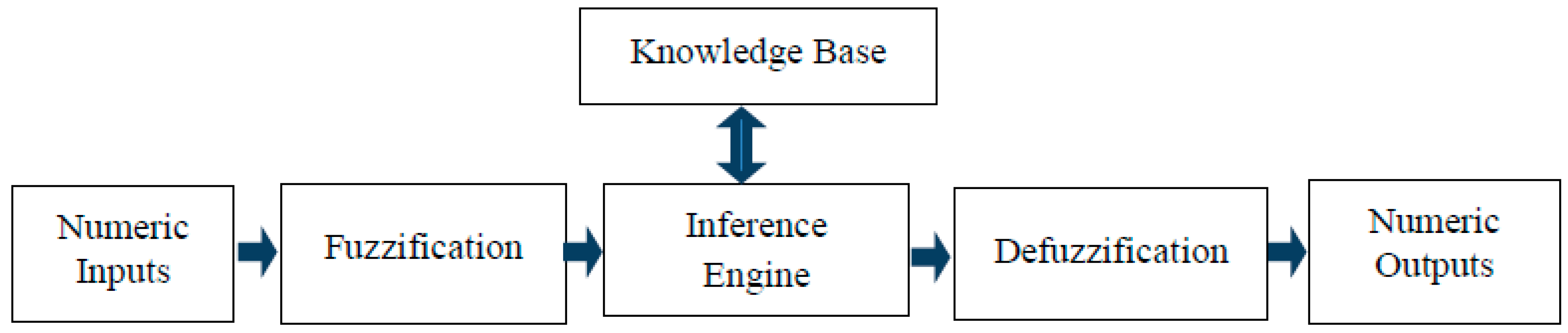
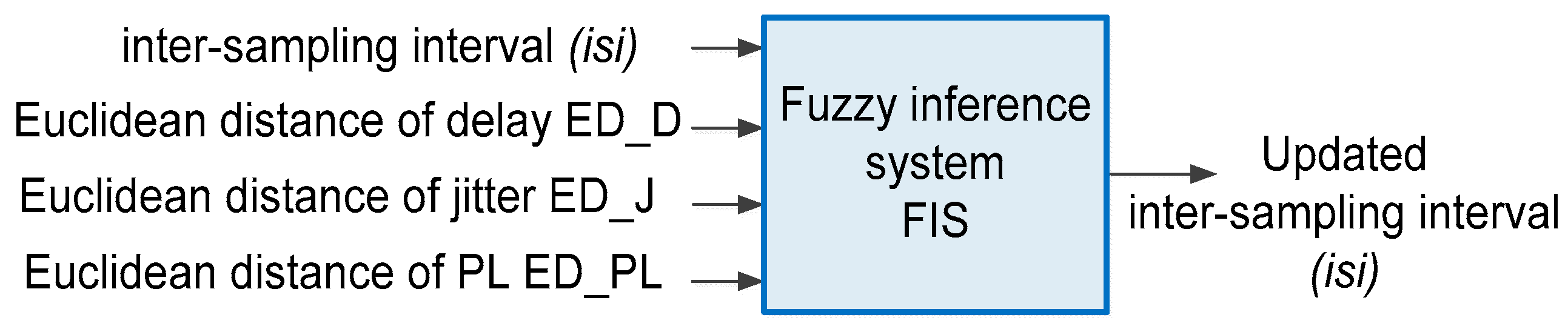
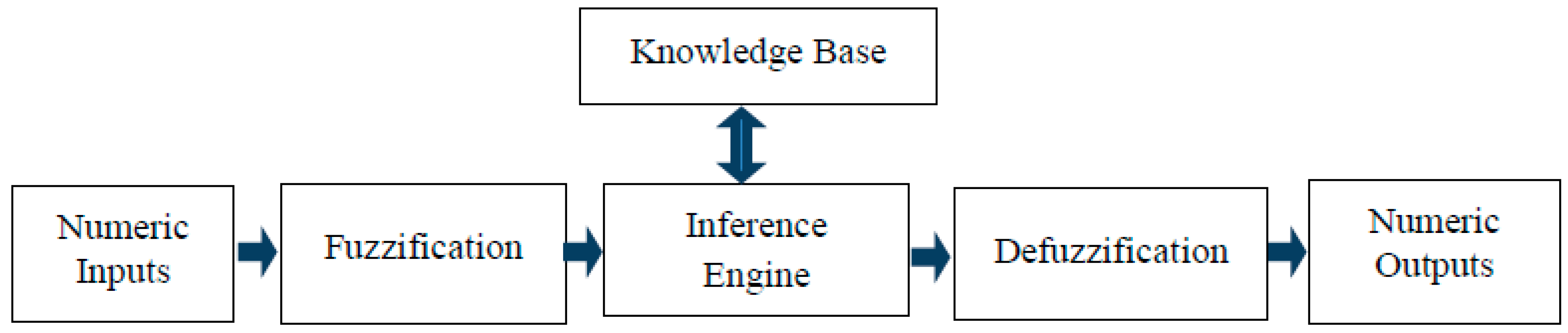
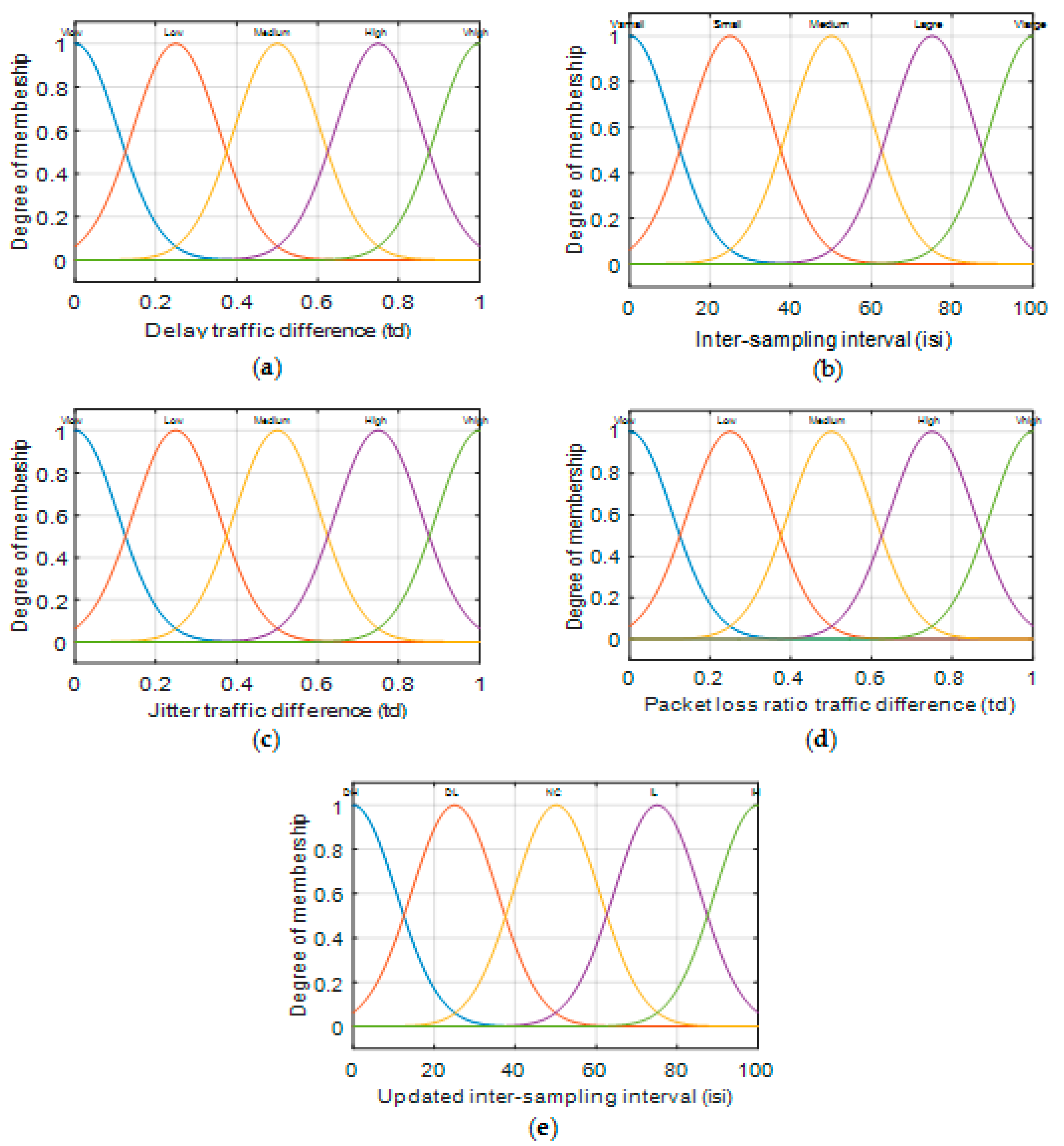
- Fuzzy inference system: FIS was used to update the duration of the isi based on its current value and the ED measures.
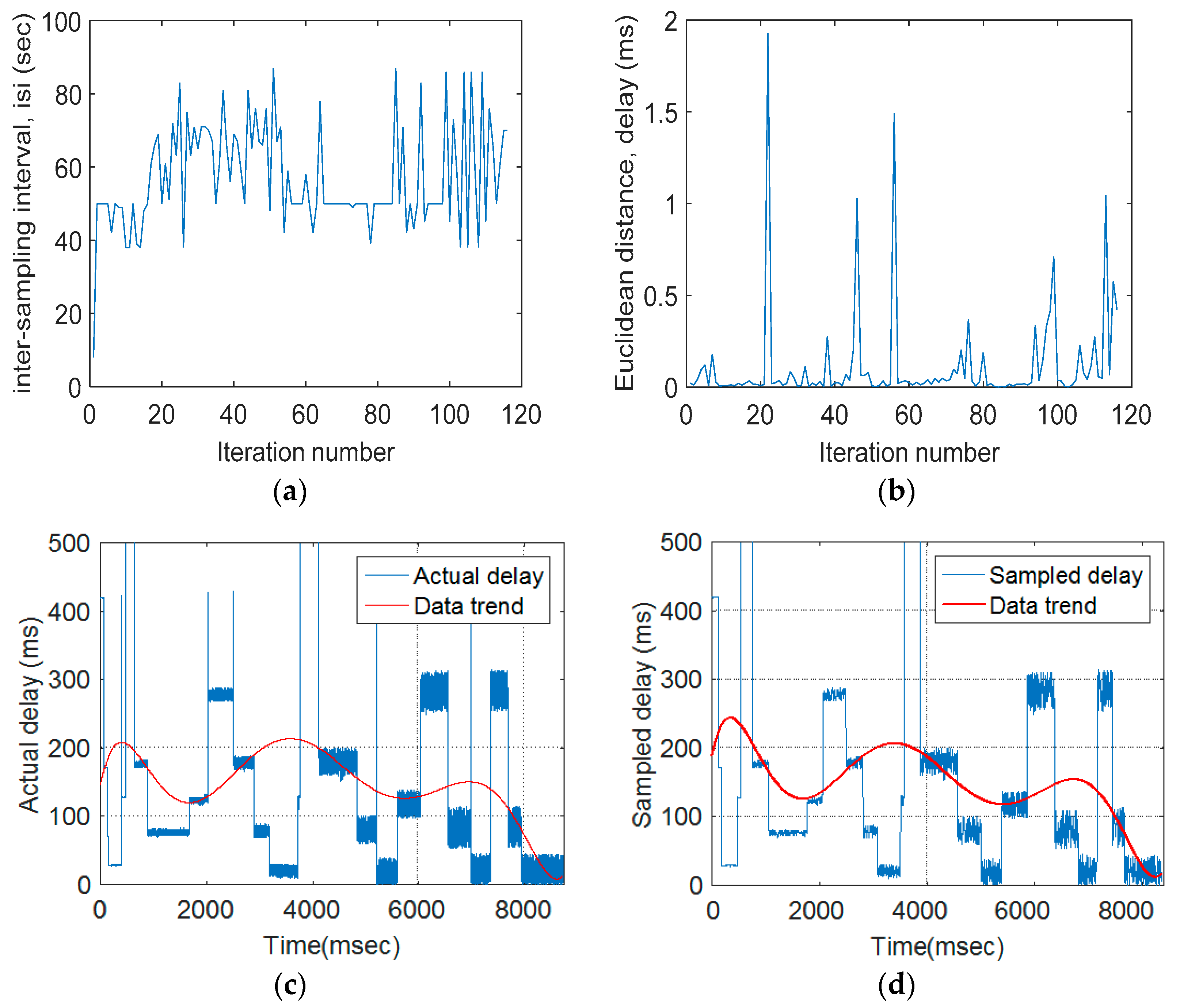
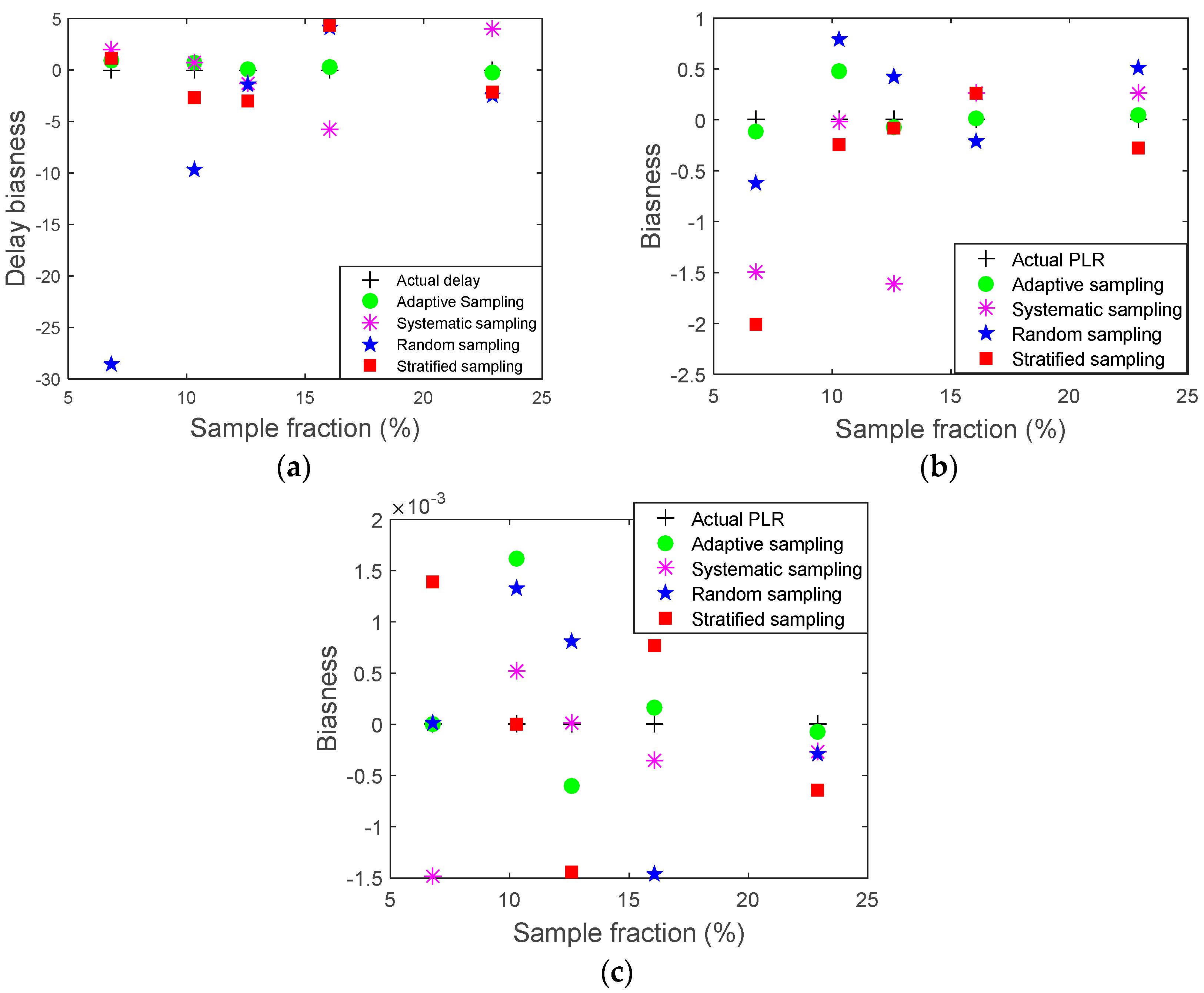
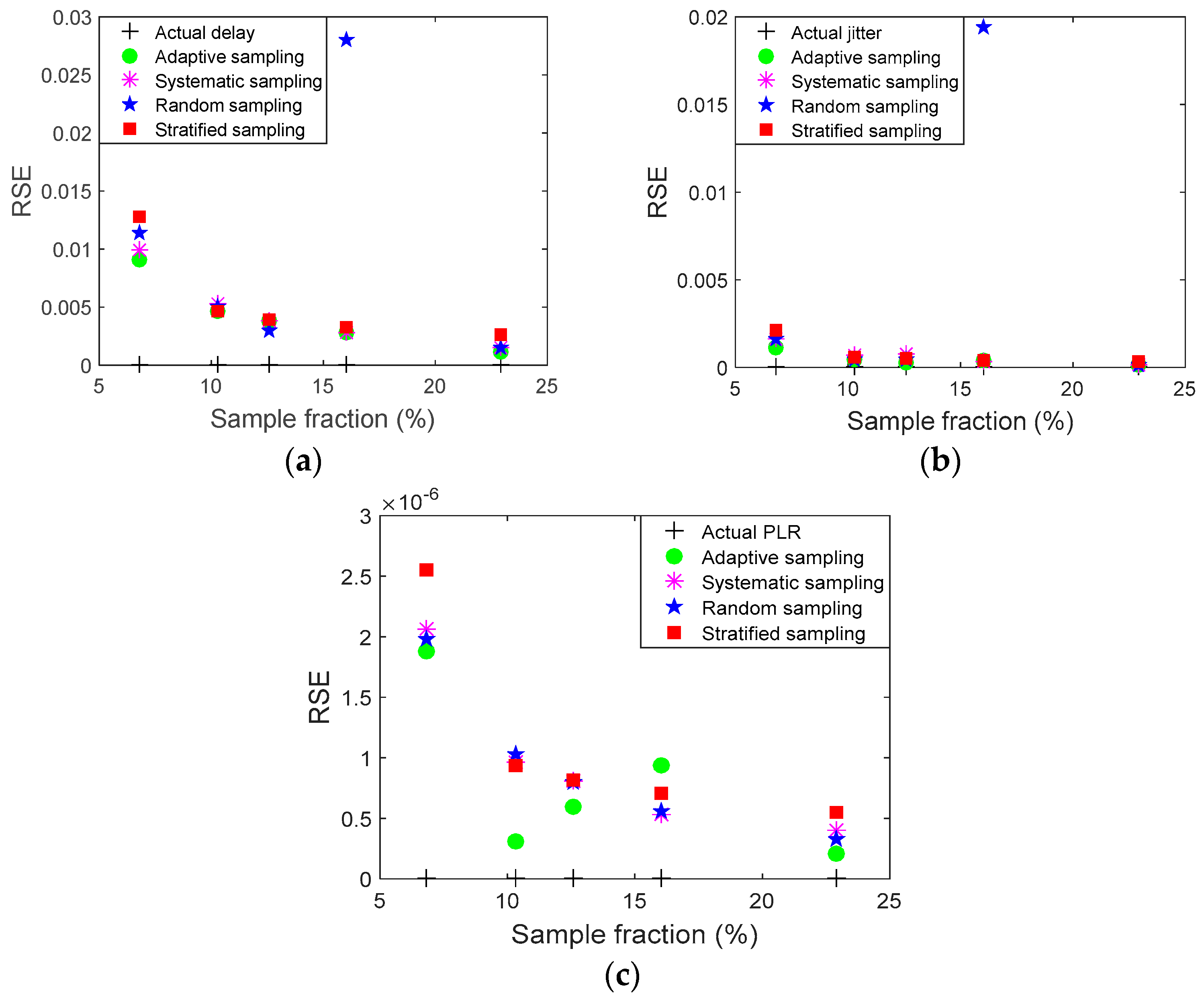
3. Results and Discussion
4. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Lazakidou, A.; IIiopoulou, D. Useful applications of computers and smart mobile technologies in the health sector. J. Appl. Med. Sci. 2012, 1, 27–60. [Google Scholar]
- Robitza, W.; Ahmad, A.; Kara, P.A.; Atzori, L.; Martini, M.G.; Raake, A.; Sun, L. Challenges of future multimedia QoE monitoring for internet service providers. Multimed. Tools Appl. 2017, 76. [Google Scholar] [CrossRef]
- Rodíguez, M.A.V.; Muñoz, E.C. Review of quality of service (QoS) mechanisms over IP multimedia subsystems (IMS). Ing. Desarro. 2017, 35, 262–281. [Google Scholar] [CrossRef]
- Wesseler, M.; Saatchi, R.; Burke, D. Child-friendly wireless remote health monitoring system. In Proceedings of the IEEE 9th International Symposium on Communication Systems, Networks and Digital Signal Processing, Manchester, UK, 23–25 July 2014; pp. 198–202. [Google Scholar]
- Clarke, A.; Steele, R. Health participatory sensing networks. Mob. Inf. Syst. 2014, 10, 229–242. [Google Scholar] [CrossRef]
- González, F.C.J.; Villegas, O.O.V.; Ramírez, D.E.T.; Sánchez, V.G.C.; Domínguez, H.O. Smart multi-level tool for remote patient monitoring based on a wireless sensor network and mobile augmented reality. Sensors 2014, 14, 17212–17232. [Google Scholar] [CrossRef] [PubMed]
- Ghamari, M.; Janko, B.; Sherratt, R.S.; Harwin, W.; Piechockic, R.; Soltanpour, C. A survey on wireless body area networks for eHealthcare systems in residential environments. Sensors 2016, 16, 831. [Google Scholar] [CrossRef] [PubMed]
- Van Halteren, A.; Bults, R.; Wac, K.; Dokovsky, N.; Koprinkov, G.; Widya, I.; Konstantas, D.; Jones, V. Wireless body area networks for healthcare: The mobiHealth project. Stud. Health Technol. Inform. 2004, 108, 121–126. [Google Scholar]
- Varshney, U.; Sneha, S. Patient monitoring using ad hoc wireless networks: Reliability and power management. IEEE Commun. Mag. 2006, 44, 49–55. [Google Scholar] [CrossRef]
- Manfredi, S. Performance evaluation of healthcare monitoring system over heterogeneous wireless networks. E-Health Telecommun. Syst. Netw. 2012, 1, 27–36. [Google Scholar] [CrossRef]
- Lin, R.; Li, O.; Li, Q.; Dai, K. Exploring adaptive packet-sampling measurements for multimedia traffic classification. J. Commun. 2014, 9, 971–979. [Google Scholar]
- Salama, A.; Saatchi, R.; Burke, D. Quality of Service Evaluation and Assessment Methods in Wireless Networks. In Proceedings of the 4th International Conference on Information and Communication Technologies for Disaster Management, Munster, Germany, 11–13 December 2017. [Google Scholar]
- AL-Sbou, Y.A.; Saatchi, R.; Al-Kyayatt, S.; Ayyash, M.; Saraireh, M. A novel quality of service assessment of multimedia traffic over wireless ad hoc networks. In Proceedings of the 2nd International Conference on Next Generation Mobile Applications, Services and Technologies, Cardiff, UK, 16–19 September 2008; pp. 479–484. [Google Scholar]
- Silva, J.M.C.; Paulo, C.; Solange, R.L. Inside packet sampling techniques: Exploring modularity to enhance network measurements. Int. J. Commun. Syst. 2017, 30. [Google Scholar] [CrossRef]
- Bělohlávek, R.; George, J.K.; Dauben, J.W. Fuzzy Logic and Mathematics: A Historical Perspective; Oxford University Press: Oxford, UK, 2017. [Google Scholar]
- Yuste, A.J.; Triviño, A.; Casilari, E. Using fuzzy logic in hybrid multihop wireless networks. Int. J. Wirel. Mobil. Netw. 2010, 2, 96–108. [Google Scholar] [CrossRef]
- Ross, T.J. Fuzzy Logic with Engineering Applications, 4th ed.; Wiley: Hoboken, NJ, USA, 2017. [Google Scholar]
- Dogman, A.; Saatchi, R.; Al-Khayatt, S.; Nwaizu, H. Adaptive statistical sampling of VoIP traffic in WLAN and wired networks using fuzzy inference system. In Proceedings of the 2011 7th International Wireless Communications and Mobile Computing Conference, Istanbul, Turkey, 4–8 July 2011; pp. 1731–1736. [Google Scholar]
- Dogman, A.; Saatchi, R.; Al-Khayatt, S. An adaptive statistical sampling technique for computer network traffic. In Proceedings of the 7th International Symposium on Communication Systems Networks and Digital Signal Processing (CSNDSP), Newcastle upon Tyne, UK, 21–23 July 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 479–483. [Google Scholar]
- Fan, J.; Liao, Y.; Liu, H. An overview of the estimation of large covariance and precision matrices. Econom. J. 2016, 19, C1–C32. [Google Scholar] [CrossRef]
- Faraway, J.J. Extending the Linear Model with R: Generalized Linear, Mixed Effects and Nonparametric Regression Models; CRC Press: Boca Raton, FL, USA, 2016; Volume 124. [Google Scholar]
- Zhang, B.; Liu, Y.; He, J.; Zou, Z. An energy efficient sampling method through joint linear regression and compressive sensing. In Proceedings of the 2013 Fourth International Conference on Intelligent Control and Information Processing (ICICIP), Beijing, China, 9–11 June 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 447–450. [Google Scholar]
- Pacheco de Carvalho, J.A.R.; Veiga, H.; Ribeiro Pacheco, C.F.; Reis, A.D. Performance evaluation of IEEE 802.11 a, g laboratory open point-to-multipoint links. In Proceedings of the World Congress on Engineering (WCE), London, UK, 1–3 July 2015; Volume 1. [Google Scholar]
- Sanders, C. Practical Packet Analysis: Using Wireshark to Solve Real-World Network Problems; No Starch Press: San Francisco, CA, USA, 2017. [Google Scholar]
- Yohannes, D.; Dilip, M. Effect of delay, packet loss, packet duplication and packet reordering on voice communication quality over WLAN. TECHNIA 2016, 8, 1071–1075. [Google Scholar]
- Salama, A.; Saatchi, R.; Burke, D. Adaptive sampling technique for computer network traffic parameters using a combination of fuzzy system and regression model. In Proceedings of the 2017 4th International Conference on Mathematics and Computers in Science in Industry (MCSI 2017), Corfu Island, Greece, 24–26 August 2017; IEEE: Piscataway, NJ, USA, 2017. [Google Scholar]
- Salama, A.; Saatchi, R.; Burke, D. Adaptive sampling technique using regression modelling and fuzzy inference system for network traffic. In Harnessing the Power of Technology to Improve Lives; Cudd, P., De Witte, L., Eds.; Studies in Health Technology and Informatics (242); IOS Press: Amsterdam, The Netherlands, 2017; pp. 592–599. [Google Scholar]
- Salama, A.; Saatchi, R.; Burke, D. Adaptive sampling for QoS traffic parameters using fuzzy system and regression model. Math. Model. Methods Appl. Sci. 2017, 11, 212–220. [Google Scholar]
- Saraireh, M.; Saatchi, R.; Al-Khayatt, S.; Strachan, R. Assessment and improvement of quality of service in wireless networks using and hybrid genetic-fuzzy approaches, Artif. Intell. Rev. 2007, 27, 95–111. [Google Scholar] [CrossRef]
- Zseby, T. Comparison of sampling methods for non-intrusive SLA validation. In Proceedings of the Second Workshop on End-to-End Monitoring Techniques and Services (E2EMon), San Diego, CA, USA, 3 October 2004. [Google Scholar]
- Wan, X.; Li, Y.; Xia, C.; Wu, M.; Liang, J.; Wang, N. A T-wave alternans assessment method based on least squares curve fitting technique. Measurement 2016, 86, 93–100. [Google Scholar] [CrossRef]
- Guruswami, V.; Zuckerman, D. Robust Fourier and polynomial curve fitting. In Proceedings of the 2016 IEEE 57th Annual Symposium on Foundations of Computer Science (FOCS), New Brunswick, NJ, USA, 9–11 October 2016; IEEE: Piscataway, NJ, USA, 2016. [Google Scholar]
- Lindfield, G.; Penny, J. Numerical Methods: Using MATLAB; Academic Press: Cambridge, MA, USA, 2012. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
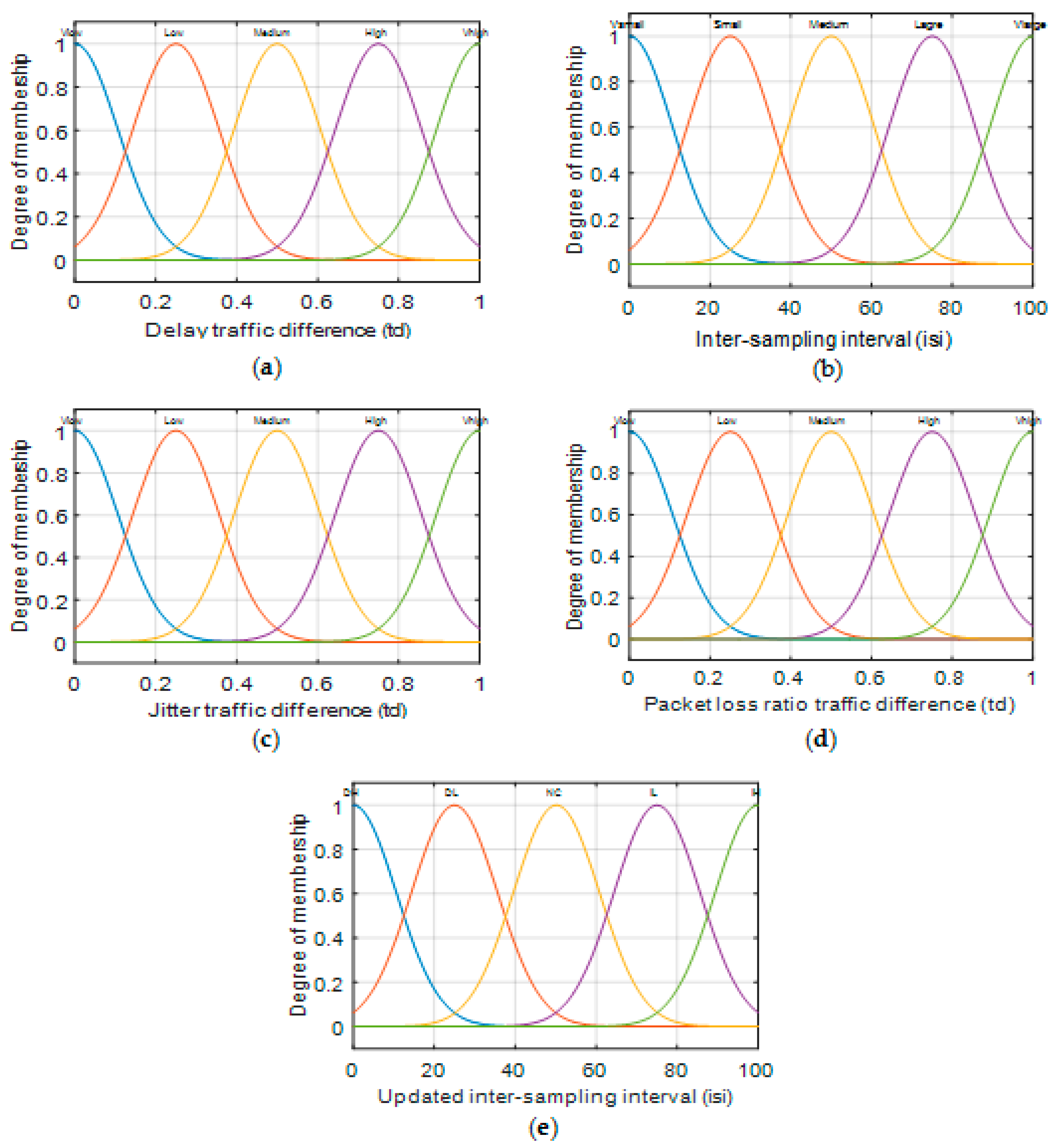
| Membership Functions | (Mean, Standard Deviation (Std)) for ED Delay, ED Jitter, ED of %PLR |
|---|---|
| Very low | 0.1, 0 |
| Low | 0.1, 0.25 |
| Medium | 0.1, 0.5 |
| High | 0.1, 0.75 |
| Very high | 0.1, 1 |
| Membership Functions for Current isi | Membership Functions Updated isi | (Mean, Standard Deviation) for Current and Updated isi |
|---|---|---|
| Very small | Decrease low (DL) | 10, 0 |
| Small | Decrease High (DH) | 10, 25 |
| Medium | No change (NC) | 10, 50 |
| Large | Increase low (IL) | 10, 75 |
| Very large | Increase high (IH) | 10, 100 |
| Rule | Current isi | TD Delay | TD Jitter | TD Packet Loss Ratio | Updated isi |
|---|---|---|---|---|---|
| 1 | Very small | Very low | Very low | None | Increase high (IH) |
| 2 | Very small | Very low | None | Very low | Increase high (IH) |
| 3 | Very small | None | Very low | Very low | Increase high (IH) |
| 4 | None | Very low | Very low | Very low | Increase high (IH) |
| 5 | None | Low | Low | Low | Increase low (IL) |
| 6 | Small | None | Low | Low | Increase low (IL) |
| 7 | Small | Low | None | Low | Increase low (IL) |
| 8 | Small | Low | Low | None | Increase low (IL) |
| 9 | Medium | Medium | Medium | None | No change (NC) |
| 10 | Medium | Medium | None | Medium | No change (NC) |
| 11 | Medium | None | Medium | Medium | No change (NC) |
| 12 | None | Medium | Medium | Medium | No change (NC) |
| 13 | None | High | High | High | Decrease low (DL) |
| 14 | Large | None | High | High | Decrease low (DL) |
| 15 | Large | High | None | High | Decrease low (DL) |
| 16 | Large | High | High | None | Decrease low (DL) |
| 17 | None | Very high | Very high | Very high | Decrease low (DH) |
| 18 | Very large | None | Very high | Very high | Decrease low (DH) |
| 19 | Very large | Very high | None | Very high | Decrease High (DH) |
| 20 | Very large | Very high | Very high | None | Decrease High (DH) |
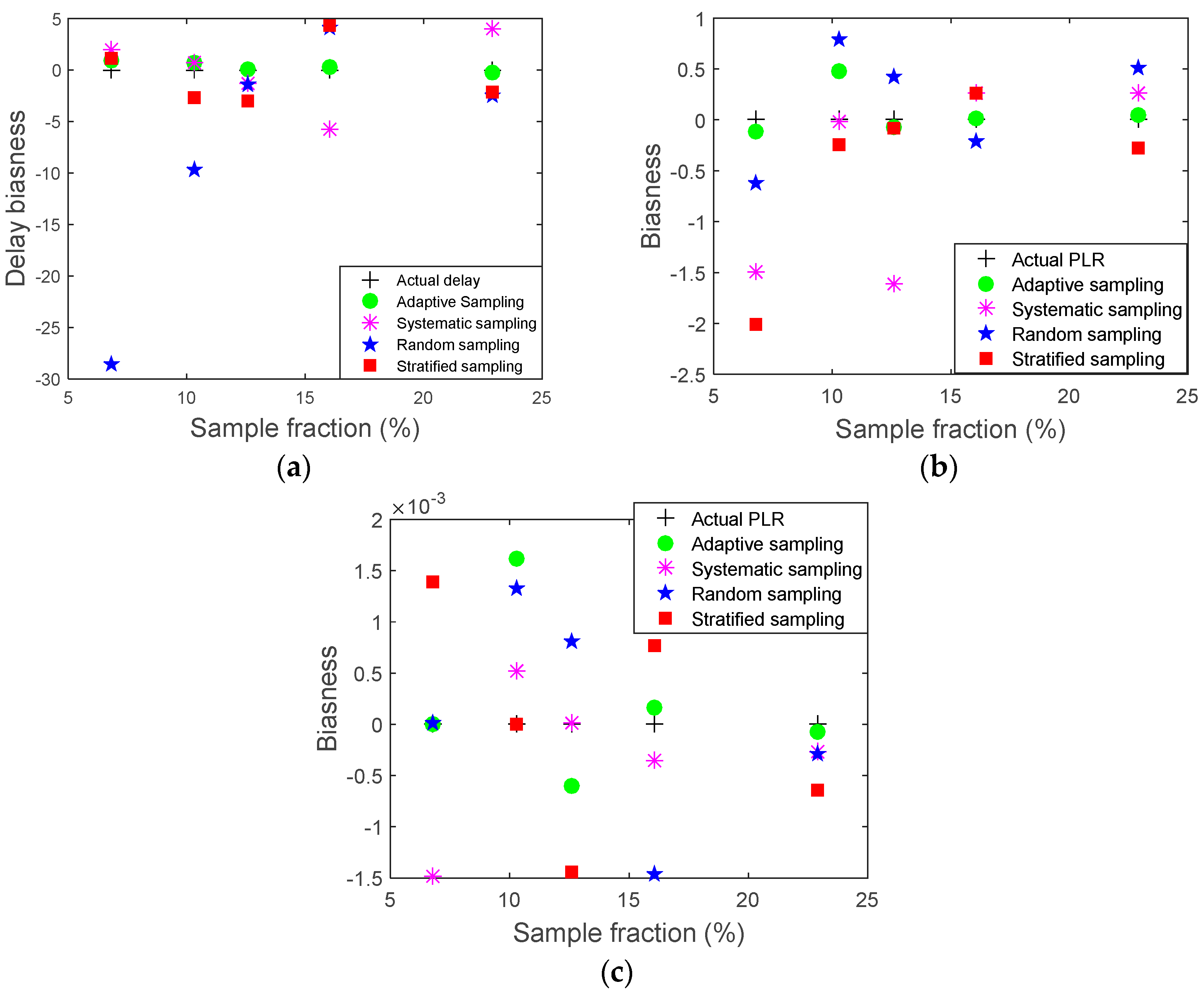
| Unit | Sample Fractions % | ||||
|---|---|---|---|---|---|
| 0 | 6.1 | 10.2 | 13 | 22.9 | |
| Adaptive sampling method | |||||
| Mean | 146 | 147 | 147 | 147 | 147 |
| Std. | 141 | 141 | 141 | 142 | 141 |
| Bias | 0 | 0.875 | 0.683 | 0.067 | −0.262 |
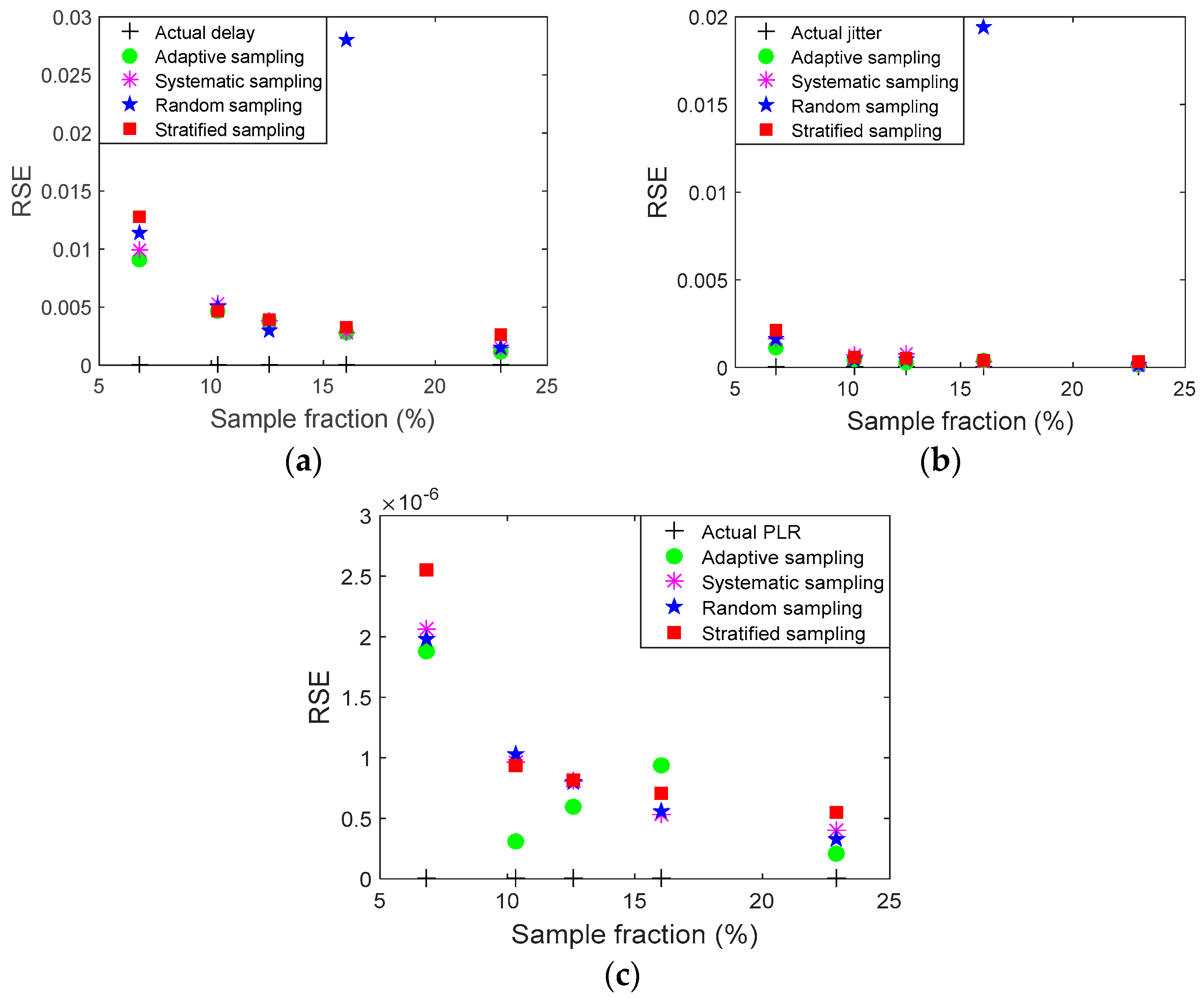
| RSE | 0 | 0.0090 | 0.0040 | 0.0030 | 0.0011 |
| Systematic sampling | |||||
| Mean | 147 | 145 | 146 | 148 | 143 |
| Std. | 141 | 146 | 142 | 141 | 138 |
| Bias | 0 | 1.9740 | 0.725 | −1.279 | 3.960 |
| RSE | 0 | 0.0099 | 0.0052 | 0.0038 | 0.0019 |
| Random sampling | |||||
| Mean | 147 | 176 | 157 | 149 | 150 |
| Std. | 141 | 165 | 152 | 149 | 142 |
| Bias | 0 | −28.551 | −9.741 | −1.401 | −2.432 |
| RSE | 0 | 0.0113 | 0.0050 | 0.0029 | 0.0014 |
| Stratified sampling | |||||
| Mean | 147 | 146 | 150 | 150 | 149 |
| Std. | 141 | 143 | 149 | 142 | 139 |
| Bias | 0 | 1.0932 | −2.74034 | −2.9770 | −2.1844 |
| RSE | 0 | 0.0127 | 0.0046 | 0.00389 | 0.00265 |
| Unit | Sample Fractions % | ||||
|---|---|---|---|---|---|
| 0.0 | 6.1 | 10.2 | 13 | 22.9 | |
| Adaptive sampling method | |||||
| Mean | 11.116 | 11.235 | 10.6386 | 11.1855 | 11.0730 |
| Std. | 17.493 | 17.479 | 11.636 | 14.073 | 17.4936 |
| Bias | 0 | −0.1185 | 0.478 | −0.0689 | 0.0435 |
| RSE | 0 | 0.00112 | 4.31 × 10−4 | 2.69 × 10−4 | 1.5 × 10−4 |
| Systematic sampling | |||||
| Mean | 11.116 | 12.6123 | 11.133 | 12.732 | 10.855 |
| Std. | 17.493 | 23.7784 | 21.049 | 26.650 | 12.120 |
| Bias | 0 | −1.4956 | −0.016 | −1.615 | 0.261 |
| RSE | 0 | 0.00161 | 6.97 × 10−4 | 7.40 × 10−4 | 1.66 × 10−4 |
| Random sampling | |||||
| Mean | 11.116 | 11.733 | 10.325 | 10.691 | 10.608 |
| Std. | 17.493 | 23.990 | 13.723 | 21.510 | 14.770 |
| Bias | 0 | −0.6166 | 0.790 | 0.425 | 0.508 |
| RSE | 0 | 0.00165 | 4.53 × 10−4 | 4.34 × 10−4 | 1.55 × 10−4 |
| Stratified sampling | |||||
| Mean | 11.116 | 13.127 | 11.357 | 11.202 | 11.389 |
| Std. | 17.493 | 23.601 | 19.236 | 18.428 | 18.681 |
| Bias | 0 | −2.011 | −0.241 | −0.085 | −0.272 |
| RSE | 0 | 0.002 | 6.08 × 10−4 | 5.05 × 10−4 | 3.5 × 10−4 |
| Unit | Sample Fractions % | ||||
|---|---|---|---|---|---|
| 0.0 | 6.1 | 10.2 | 13 | 22.9 | |
| Adaptive sampling method | |||||
| Mean | 0.0356 | 0.035 | 0.034 | 0.036 | 0.035 |
| Std. | 0.0291 | 0.0292 | 0.0290 | 0.029 | 0.029 |
| Bias | 0 | 6.23 × 10−6 | 0.0016 | −5.96 × 10−4 | −7.22 × 10−5 |
| RSE | 0 | 1.88 × 10−6 | 3.05 × 10−7 | 5.93 × 10−7 | 2.08 × 10−7 |
| Systematic sampling | |||||
| Mean | 0.0356 | 0.037 | 0.035 | 0.035 | 0.035 |
| Std. | 0.0291 | 0.029 | 0.0290 | 0.028 | 0.029 |
| Bias | 0 | −0.0014 | 5.20 × 10−4 | 7.95 × 10−6 | −2.72 × 10−4 |
| RSE | 0 | 2.06 × 10−6 | 9.62 × 10−7 | 8.05 × 10−7 | 3.99 × 10−7 |
| Random sampling | |||||
| Mean | 0.0356 | 0.035 | 0.0343 | 0.034 | 0.035 |
| Std. | 0.0291 | 0.029 | 0.027877 | 0.028954 | 0.029492 |
| Bias | 0 | 1.65 × 10−5 | 0.0013 | 8.07 × 10−4 | −2.90 × 10−4 |
| RSE | 0 | 1.98 × 10−6 | 1.03 × 10−6 | 7.94 × 10−7 | 3.30 × 10−7 |
| Stratified sampling | |||||
| Mean | 0.0356 | 0.034 | 0.035 | 0.037 | 0.036 |
| Std. | 0.0291 | 0.028 | 0.029 | 0.029 | 0.0286 |
| Bias | 0 | 0.0013 | 1.03 × 10−6 | −0.0014 | −6.45 × 10−4 |
| RSE | 0 | 2.55 × 10−6 | 9.35 × 10−7 | 8.13 × 10−7 | 5.47 × 10−7 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Salama, A.; Saatchi, R.; Burke, D. Fuzzy Logic and Regression Approaches for Adaptive Sampling of Multimedia Traffic in Wireless Computer Networks. Technologies 2018, 6, 24. https://doi.org/10.3390/technologies6010024
Salama A, Saatchi R, Burke D. Fuzzy Logic and Regression Approaches for Adaptive Sampling of Multimedia Traffic in Wireless Computer Networks. Technologies. 2018; 6(1):24. https://doi.org/10.3390/technologies6010024
Chicago/Turabian StyleSalama, Abdussalam, Reza Saatchi, and Derek Burke. 2018. "Fuzzy Logic and Regression Approaches for Adaptive Sampling of Multimedia Traffic in Wireless Computer Networks" Technologies 6, no. 1: 24. https://doi.org/10.3390/technologies6010024
APA StyleSalama, A., Saatchi, R., & Burke, D. (2018). Fuzzy Logic and Regression Approaches for Adaptive Sampling of Multimedia Traffic in Wireless Computer Networks. Technologies, 6(1), 24. https://doi.org/10.3390/technologies6010024