Abstract
Face anti-spoofing is crucial for protecting biometric authentication systems. Presentation attacks using 3D masks and high-resolution printed images present detection challenges for existing methods. In this paper, we introduce a family of specialized CNN architectures, AttackNet, designed for robust face anti-spoofing with optimized residual connections and activation functions. The study includes the development of four architectures: baseline LivenessNet, AttackNetV1 with concatenation-based skip connections, AttackNetV2.1 with optimized activation functions, and AttackNetV2.2 with efficient addition-based residual learning. Our analysis demonstrates that element-wise addition in skip connections reduces parameters from 8.4 M to 4.2 M while maintaining performance. A comprehensive evaluation was conducted on four benchmark datasets: MSSpoof, 3DMAD, CSMAD, and Replay-Attack. Results show high accuracy (approaching 100%) on the 3DMAD, CSMAD, and Replay-Attack datasets. On the more challenging MSSpoof dataset, AttackNetV1 achieved 99.6% accuracy with an HTER of 0.004, outperforming the baseline LivenessNet (94.35% accuracy, 0.056 HTER). Comparative analysis with state-of-the-art methods confirms the superiority of the proposed approach. AttackNetV2.2 demonstrates an optimal balance between accuracy and computational efficiency, requiring 16.1 MB of memory compared to 32.1 MB for other AttackNet variants. Training time analysis shows twice the speed for AttackNetV2.2 compared to AttackNetV1. Architectural ablation studies highlight the crucial role of residual connections, batch normalization, and suitable dropout rates. Statistical significance testing verifies the reliability of the results (p-value < 0.001). The proposed architectures show excellent generalization ability and practical usefulness for real-world deployment in mobile and embedded systems.
1. Introduction
Biometric authentication systems are now a key part of modern security technology, offering a convenient and dependable way to verify identities [1,2]. Among different biometric methods, face recognition has become popular because it is non-intrusive, easy to use, and highly accurate [3,4]. Current leading face recognition methods perform exceptionally well in ideal laboratory conditions, achieving over 99% accuracy on benchmark datasets [5]. However, as face-based authentication systems become more popular, so do attempts to spoof them with various attacks. Spoofing attacks, also known as presentation attacks, pose a significant threat to face recognition systems. These attacks include 2D photo attacks, video replay attacks, 3D mask attacks, and more advanced silicone mask attacks [6]. Basic presentation attacks pose significant threats due to their simplicity; a perpetrator only needs a photograph of the victim, obtained from a social platform, to try to deceive the system [7]. Advances in deepfake technology and 3D printing have enabled more sophisticated attacks. Face anti-spoofing involves distinguishing presentation attacks from genuine facial samples. Early anti-spoofing methods relied on handcrafted features like Local Binary Patterns (LBP), Histogram of Oriented Gradients (HOG), and Scale-Invariant Feature Transform (SIFT) [8]. These techniques used texture analysis to detect artifacts in spoofed images. While handcrafted features perform well against simple attacks, they demonstrate limited generalization to sophisticated attacks and varying capture conditions.
The introduction of deep learning techniques has significantly transformed face anti-spoofing methods. Convolutional Neural Networks (CNNs) exhibited outstanding performance for the detection of patterns and feature extraction, which naturally leads them to presentation attack detection [9]. Automatically, CNN-driven methods learn hierarchical features from low-level texture structures through high-level semantic models, which enhances the detection robustness of spoofing attacks. Current deep learning methods of interest cover new designs of CNNs, multi-modal fusing, attention models, and multi-spectral sensing [10]. Despite the outstanding contributions of CNN-driven methods, major limitations are still seen. In the first place, most of the designs are for general computer vision operations rather than specifically for dealing with fine aspects of anti-spoofing. Texture analysis for this function requires fine-grained feature extraction together with subtle patterns that are not likely to be captured from ordinary CNN designs. Secondly, most of the methods are liable to training set overfitting and are not good at generalizing to new types of attacks. Thirdly, the computational intensity of the solutions now often discourages the usage of solutions in real-time operations, even on mobile devices.
The gap in the existing work is that there is no specific CNN structure that can achieve high accuracy, computational efficiency, and robustness to various attack scenarios simultaneously. Current methods are largely aiming for accurate performance with a sacrifice of computational cost, or for lightweight methods with limited performance. In addition, there is no clear exploration of various architecture components, e.g., skip connections, activation functions, and regularization techniques, on anti-spoofing missions.
This work is new because we designed personalized CNN architectures for face anti-spoofing with optimally crafted residual links and activation units. AttackNet structures, which are introduced through this work, are a merger of concepts from ResNet and VGG to generate effective feature extraction processes. LeakyReLU and Tanh activations, along with concatenation-based and addition-based skip links, enable enhanced gradient flow and feature propagation. In-depth experimentation on four benchmarking datasets substantiates the competitiveness of this approach with other methods.
The research questions of this study are as follows: (1) How do residual connections impact performance for face anti-spoofing challenges? (2) What are the most effective activation functions for the analysis of texture features for presentation attack detection? (3) How are accuracy and computational efficiency influenced depending on various types of skip connections (concatenation, addition)? (4) What is the generalization level of the proposed structures for diverse attack situations?
Novelties of this work are as follows: (1) Designing specially crafted CNN structures (AttackNet family) for face anti-spoofing with optimally crafted constituents. (2) Conducting a comprehensive study of the impact of skip connections, activation functions, and regularization techniques on the performance of anti-spoofing. (3) Comparing experimentally concatenation-based residual connections with addition-based ones for presentation attack detection. (4) Experimenting extensively with the proposed methods on four benchmarking databases, with the best performance being achieved so far. (5) Analyzing the computational efficiency and feasible deployment of the proposed structures.
This study is a direct continuation of our previous studies: Kuznetsov et al. [11] explored deep learning methods for face liveness detection, emphasizing design choice; Kuznetsov et al. [12] conducted cross-database comparison for liveness detection, illuminating generalization problems; Kuznetsov et al. [13] introduced the AttackNet design for a biometric security custom CNN, which revealed the advantage of custom designs over general ones. The current work significantly extends these foundations by (1) developing a comprehensive family of four specialized architectures with mathematically formulated skip connections, (2) conducting systematic ablation studies on architectural components, (3) providing detailed computational efficiency analysis with parameter optimization, and (4) achieving state-of-the-art performance on challenging multispectral datasets.
2. Related Work
2.1. Traditional Anti-Spoofing Methods
Early methods for face anti-spoofing relied on handcrafted features to identify unique patterns in facial images. Local Binary Patterns (LBP) were among the first effective texture analysis techniques used in anti-spoofing. Chingovska et al. [8] proposed LBP-based texture analysis for distinguishing genuine from spoofed images. They achieved 15% HTER on the Replay-Attack dataset, demonstrating the potential of texture-based approaches.
LBP-based methods underwent several enhancements [8,14]. Local Ternary Patterns (LTP) introduced a three-stage encoding for increasing noise robustness. Uniform LBP reduced feature vector dimensions through the encouragement of uniform patterns. Multi-scale LBP looks at texture structures at different scales for hierarchical feature extraction. These methods performed well against basic attacks but demonstrated limited robustness to high-quality spoofing.
Histogram of Oriented Gradients (HOG) provided alternative feature extraction capabilities [15]. HOG descriptors put prominence on orientations of gradients and geometry of edges, which could be different for spoofed and genuine images. Coupled with Support Vector Machines (SVM), competitive results were realized, more so for 3D mask detection [16,17]. Methods that are based on HOG are, however, sensitive to lighting settings and require accurate parameter settings.
Scale-Invariant Feature Transform (SIFT) and Speeded-Up Robust Features (SURF) were utilized for feature descriptor extraction and detection of keypoints [18,19]. These techniques considered the spatial organization of local features to discriminate spoofed faces from living ones. SIFT-based descriptors were exceptionally effective for photo attacks, for which keypoints exhibited distinctly different patterns from actual faces. However, the computational cost of these techniques hindered utilization for real-time systems.
Motion-driven methods processed temporal information to detect liveness clues. Processing of optical flow detected synthetic motion patterns of video recording attacks [15,20]. Face landmark detection was used to detect rigid motions of photo and video attacks. Wang et al. [20] proposed a saliency-guided histogram of oriented optical flow for processing the features of facial motion of silicone mask attacks. These methods worked well for dynamic attacks but required video sequences and worked poorly for static attacks.
Multi-spectral methods investigated variation between near-infrared (NIR) and visible (VIS) spectra [21,22]. Presentation attacks that were printed usually showed various features in the NIR spectrum because of the material [23]. Reflectance analysis helped to discriminate between artificial materials found on presentation attacks. However, multi-spectral sensors involved special hardware, which was costly for wide-scale usage.
The methods of fusion combined some of these hand-designed features for detection enhancement [24,25]. Early fusion combined feature vectors at the input level, while late fusion combined classifier outputs. Score-level fusion utilized weighted sums of different anti-spoofing methods. These methods generated superior results but grew more computationally expensive and required subtle optimization.
2.2. Deep Learning Approaches
Deep learning breakthroughs have significantly influenced spoofing resistance methods. Automatic learning of hierarchies of features from low-level texture to high-level semantic hierarchies is achieved through Convolutional Neural Networks (CNNs). Alotaibi & Mahmood [26] proposed a specific CNN for spoof detection from a single frame, which utilized deep convolutional layers for the extraction of subtle features from blurry frames. Their methodology achieved extraordinary gains against classical methods for the Replay Attack dataset.
ResNet-inspired structures gained popularity for anti-spoofing due to skip connections and the ability for deep networks to be trainable. Residual learning helps networks learn residual mappings from input to output, which proves quite effective for fine texture analysis. Nagpal & Dubey [27] explored Inception and ResNet structures for face anti-spoofing, showcasing that deep learning approaches dominate when pitted against hand-designed features.
Fully Convolutional Networks (FCN) offered pixel-level spoofing classification. An FCN-based method employing local ternary label supervision was introduced by Sun et al. [28], which included the classification of every pixel as a spoofed or genuine foreground or background. Pixel decision spatial aggregation was implemented for image-level classification. It was effective for CASIA-FASD, Replay-Attack, and OULU-NPU.
Multi-modal techniques incorporate characteristics from additional sensing modalities. RGB-D techniques apply features of the 3D geometry of real-time faces through depth features. Erdogmus & Marcel [14] introduced 3D mask attack detection from a Kinect sensor through color and depth-based features of LBP. Thermal imaging detects the warmth features of real-time faces. Kotwal & Marcel [23] introduced a patch pooling CNN for the detection of masks based on NIR.
Attention mechanisms enhanced feature selection and interpretability for spoofing detection systems. Spatial attention was exerted on discriminative face areas, while channel attention was emphasized on prominent feature channels. Self-attention mechanisms represented long-distance relationships under spatial and temporal settings. George & Marcel [10] presented multi-channel neural networks with an attention-based combination for effective presentation attack detection.
Transfer learning methods utilized pre-trained models for several anti-spoofing processes. Fine-tuning pre-trained CNNs based on the ImageNet achieved fast convergence with stable outputs. Frozen-weight feature extraction was implemented for lightweight processing. Khairnar et al. [29] compared pre-trained CNN architectures for face liveness detection comprehensively, substantiating the effectiveness of transfer learning techniques.
Generative Adversarial Networks (GANs) are explored for anti-spoofing applications. Adversarial training enhances robustness against powerful attacks. Data augmentation and domain adaptation are achieved through synthetic data creation. Mallat & Dugelay [30] presented a GAN-assisted way of generating synthetic attacks indirectly through generating thermal faces.
Lightweight structures are intended for portable execution. ShuffleNets, MobileNets, and EfficientNets are modified for anti-spoofing missions. Automatic neural architecture search is employed to design efficient structures programmatically. Mishra et al. [31] proposed Light Spectrum Chimp Optimization with SpinalNet for face detection in real time. Shinde et al. [32] proposed a lightweight CNN with parallel dropout layers for spoofing detection of 2D and 3D.
2.3. Datasets and Evaluation Protocols
Benchmark data are necessary for the development of anti-spoofing techniques. The REPLAY-ATTACK dataset was one of the first standardized face anti-spoofing benchmarks [8,33]. It comprises 1300 video sequences, images, and video attacks for 50 subjects under various lighting settings. It divides the data according to a subject-independent partitioning scheme, which splits the data for training, development, and a test set.
The CASIA-FASD dataset provided a richer variety of attack scenarios, including video replays, printed images, and distorted images [34,35]. Three-stage quality grading (low, normal, and high) offered a fine-scale study of methods for anti-spoofing. Test procedures on cross-databases permitted a study of the generalization capacity of the algorithms.
The 3D Mask Attack Database (3DMAD) was the first publicly available dataset for 3D mask attacks [14,36]. It was captured via a Microsoft Kinect, and it provides RGB, depth, and eye location for 17 subjects with high-quality masks. Mask quality goes from paper masks to professional 3D printed ones for naturalistic attack scenarios.
The Custom Silicone Mask Attack (CSMAD) dataset comprised the most advanced attack scenarios with professional-grade silicone masks [37,38]. Six specially crafted masks that cost $4000 each generated very realistic attacks. Four lighting settings and a variety of recording sessions offered thorough testing.
The Multispectral-Spoof (MSSpoof) dataset includes faces taken from the visible (VIS) and near-infrared (NIR) parts [39,40]. It includes 21 identities, i.e., 70 bona fide and 144 attack samples for each of the identities, for a well-balanced evaluation. Printer-based attacks with different types of printers and printing papers simulated possible attack scenarios.
The OULU-NPU dataset offered a full evaluation process with four diversified testing scenarios [34,41]. Protocol I was for various types of attacks, Protocol II was for various lighting situations, Protocol III was for various cameras, and Protocol IV was for all of them combined. This multi-protocol approach was taken as a rule for thorough evaluation.
Evaluation metrics in anti-spoofing include Attack Presentation Classification Error Rate (APCER), Bona fide Presentation Classification Error Rate (BPCER), and Average Classification Error Rate (ACER) [19,41]. Equal Error Rate (EER) is defined as the point where the APCER and BPCER curves intersect. Half Total Error Rate (HTER) is computed as the average of False Acceptance Rate (FAR) and False Rejection Rate (FRR).
Cross-database evaluation protocols assess the ability of methods to generalize [42,43]. Train-on-one, test-on-another approaches identify domain adaptation issues and overfitting to specific datasets. Leave-one-out validation involves using multiple datasets for training and testing on the dataset that is left out.
2.4. Architecture Design Principles
Skip connections are a focal idea of recent CNN architectures [44]. ResNet changed deep learning through residual learning, for which skip connections can pass gradients through extremely deep networks [45]. In detailed feature extraction and texture analysis, skip connections are of special importance for anti-spoofing operations.
Concatenation skip connections put together feature maps of various layers to create detailed feature descriptions. DenseNet models apply dense connections that supply each layer with input from all prior layers [46]. For the application of anti-spoofing, concatenation can be used for multi-scale aggregation of features for a thorough analysis of texture.
Addition-based skip connections utilize point-wise addition for feature map merging. ResNet designs confirmed that the addition-based connections are effective for very deep networks and prevent gradient vanishing. Owing to the parameter efficiency of the addition-based connections, these are of interest for resource-constrained applications.
Activation functions are indispensable for anti-spoofing processes. It is typical for CNN structures to employ ReLU activation, but the dying neurons issue might happen. LeakyReLU with a tiny negative slope can prevent dying neurons from occurring and might be useful for texture feature extraction. Parametric ReLU (PReLU) can offer learnable negative slopes for adaptive activations.
The Tanh activation outputs are bounded between [−1, 1] and could work well for fully connected layers. Swish and Mish activations provided better results for a few computer vision tasks. Determining the choice of activation function needs to be guided by gradient flow, computational expense, and task demands [23,27].
Batch normalization helps stabilize training and speed up convergence [45]. Whether batch normalization takes place before or after activation affects performance. Layer normalization and group normalization provide batch-dependent normalization options.
Dropout regularization prevents overfitting by randomly suppressing neurons during training [45]. It is critical that a suitable dropout rate be chosen—a value that is too high can lead to underfitting, but a value that is too low can be inadequate to prevent overfitting. Spatial dropout for convolutional layers and regular dropout for fully connected layers employ various values of the rate.
Downsampling techniques based on pooling affect feature aggregation and spatial downsampling. Average pooling helps maintain continuity, whereas max pooling retains the maximum activations. Adaptive pooling internally resolves an output size without regard for input dimensions [23]. Global average pooling can be substituted for fully connected layers to diminish parameters.
Weight initialization is essential for stable training [27]. Xavier initialization works well for Tanh and sigmoid activations, while He initialization is best suited for activations based on ReLU. Proper initialization prevents gradient explosion and vanishing gradients for deep networks.
This study builds upon and significantly extends our previous research foundation:
- Kuznetsov et al. [13] conducted initial explorations of deep learning methods for face liveness detection, focusing on basic CNN architectures and their performance across different datasets. This work established fundamental deep learning approaches but employed standard architectures without specialized design considerations for anti-spoofing tasks.
- Kuznetsov et al. [12] performed a comprehensive cross-database evaluation for liveness detection, revealing critical generalization challenges when models trained on one dataset are tested on others. This study illuminated domain adaptation issues and highlighted the need for more robust architectural designs that could generalize across different attack scenarios and acquisition conditions.
- Kuznetsov et al. [11] introduced the initial AttackNet concept as a custom CNN architecture for biometric security, demonstrating the advantages of task-specific designs over general-purpose architectures. However, this preliminary work lacked a systematic exploration of architectural components and a mathematical formalization of design choices.
The current work significantly advances beyond these foundations by (1) developing a comprehensive family of four specialized architectures with mathematically formulated skip connections and systematic ablation studies, (2) providing detailed computational efficiency analysis with parameter optimization strategies, (3) introducing novel combinations of activation functions and regularization techniques specifically optimized for presentation attack detection, and (4) achieving state-of-the-art performance on challenging multispectral datasets with rigorous statistical validation.
3. Methodology
3.1. Analysis and Preparation of Datasets
The study was conducted on four different benchmark datasets, each representing specific types of presentation attacks. The selection of datasets provided a comprehensive evaluation of the models’ robustness against various attack types and lighting conditions.
The MSSpoof dataset comprises multispectral images of visible and near-infrared spectra of 21 subjects [39,40]. It provides 70 real samples and 144 attack samples for every user, maintaining a balanced class ratio. What is more, the dataset includes print attacks that are generated with a variety of printers and papers.
The 3DMAD dataset consists of records of 3D mask attacks recorded via a Microsoft Kinect [14,36]. It includes records of 17 users donning high-quality masks from ThatsMyFace.com. These sessions each output RGB images, a depth map, together with eye location, making it possible to test methods of detecting attacks based on depth.
The CSMAD database is a set of spoof attacks which are fabricated from professional-grade silicone masks [37,38]. It includes six masks of different quality, which are tested under four different lighting conditions. High-quality masks are a large challenge for anti-spoofing techniques.
There are 50 subjects for photo and video replay attacks from the Replay-Attack database [8,33]. It includes attacks through various playback devices such as printed images, mobile phones, and HD monitors. It was tested through challenging and controlled lighting conditions.
All the data were processed through a shared pipeline. Face regions were detected with the help of the SSD-ResNet detector and further downsized to 128 × 128 pixels through LANCZOS 3 interpolation for precise quality preservation.
No normalization was carried out since the pixel values of the preprocessed images were already in the range [0, 1]. This approach preserved the natural image characteristics and avoided losing useful information for texture analysis.
Table 1 presents the diversity of the datasets based on the size and type of attacks. MSSpoof is distinctive for having multispectral features: 3DMAD for possessing depth information, CSMAD for possessing good-quality masks, and Replay-Attack for possessing a large volume of data. Uniform class distribution for all the resultant datasets ensures that models are equally tested without bias.

Table 1.
Key features of the datasets used for detecting presentation attacks. The main parameters of the four benchmark datasets are shown, including the number of samples, image resolution, attack types, and class distribution.
Figure 1 shows the qualitative differences between genuine and attack samples in each dataset. Visual analysis reveals increasing difficulty in detection from simple print attacks in Replay-Attack to high-quality silicon masks in CSMAD, highlighting the need for deep learning methods for reliable detection.



Figure 1.
Examples of images from the datasets studied: (a) MSSpoof—multispectral images in the visible spectrum; (b) 3DMAD—RGB images with 3D mask attacks; (c) CSMAD—attacks with professional silicone masks; (d) Replay-Attack—photo and video replay attacks. Each dataset shows bona fide (left column) and attack (right column) samples.
3.2. Evolution of Model Architecture
The development of model architectures followed the principle of increasing complexity gradually while keeping computational efficiency. The initial LivenessNet architecture served as a baseline to compare with more complex versions.
3.2.1. Baseline Architecture: LivenessNet
LivenessNet is a residual connection-less CNN structure. It comprises two convolutional blocks with 16 and 32 filters, respectively. Both blocks consist of two convolution layers with ReLU activation, batch normalization, and max pooling. It is followed by a dense layer of 64 neurons, followed by the final softmax layer for binary classification.
It possesses a total of 2,114,642 parameters, which translate to a model size of 8.07 MB. Its lightweight structure makes it a candidate for embedded designs, but provides little capacity for learning deep texture structures that are characteristic of most of today’s spoofing attacks.
3.2.2. AttackNet v1: Enhanced Depth
AttackNet v1 introduces skip connections through concatenation operations inspired by the principles of VGG16 and ResNet architectures. Each convolutional phase consists of three consecutive layers with a residual connection linking the first and last layers.
Mathematically, the skip connection in the first phase is expressed as follows:
where represents the skip connection, and denotes the concatenation operation.
Using LeakyReLU with parameter instead of standard ReLU activation aims to prevent the dying ReLU problem and enhance gradient flow. The dense layer is increased to 128 neurons with Tanh activation for improved learning of non-linear patterns. The total number of parameters rises to 8,422,914 (32.13 MB), which significantly increases the model’s capacity compared to the baseline.
3.2.3. AttackNet v2.1: Activation Function Optimization
AttackNet v2.1 explores the impact of different activation functions on detection quality. The architecture retains the structure of v1, but uses LeakyReLU for convolutional layers and Tanh for dense layers.
Tanh activation in a dense layer is mathematically expressed as follows:
The choice of Tanh is made because it can map input values to the range , which is useful for texture analysis tasks where both positive and negative feature responses are important. Batch normalization is used after each convolutional layer to stabilize training and speed up convergence. Dropout with a coefficient of 0.25 after pooling layers and 0.5 in the dense layer adds regularization.
3.2.4. AttackNet v2.2: Efficient Skip Connections
AttackNet v2.2 replaces concatenation operations with element-wise addition in skip connections, following the principles of the ResNet architecture. This change aims to create a more efficient architecture while maintaining the dimensionality of feature maps. Skip connection is now expressed as follows:
where ‘Add’ stands for element-wise addition. This approach reduces parameters compared to concatenation, lowering the total number to 4,223,810 (16.11 MB). The benefit of addition-based connections is that they preserve gradient flow without increasing dimensionality, leading to faster inference times while maintaining model expressiveness.
Key Architectural Distinctions from Existing Methods:
Unlike standard ResNet architectures that employ uniform residual blocks throughout the network, AttackNet architectures are specifically optimized for texture analysis in anti-spoofing tasks through the following: (1) Hybrid skip connection strategies combining both concatenation and addition operations within the same architecture, (2) task-specific activation function selection (LeakyReLU with α = 0.2 for texture preservation), (3) optimized depth-to-parameter ratios (28–29 layers vs. ResNet’s 50+ layers) for anti-spoofing efficiency, and (4) domain-specific regularization patterns tailored for presentation attack detection.
While DenseNet employs dense connectivity throughout all layers, AttackNet selectively applies concatenation-based connections only in critical feature extraction phases, reducing computational overhead by 50% while maintaining feature richness essential for spoofing detection.
Figure 2 visually demonstrates the trade-off between model complexity and computational efficiency. AttackNetV2.2 achieves an optimal balance, with a model size 50% smaller than V1 and V2.1, while maintaining the same architectural complexity.
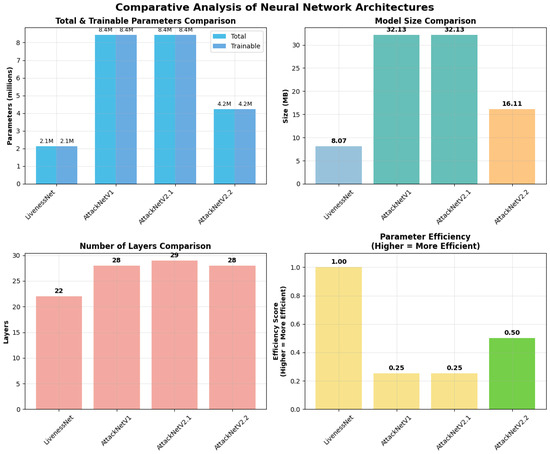
Figure 2.
Comparative analysis of neural network architectures based on key features: total number of parameters, model size in megabytes, number of layers, and computational efficiency. AttackNetV1 and AttackNetV2.1 have the same number of parameters, while AttackNetV2.2 shows a notable decrease in model size.
4. Experimental Setup
4.1. Hardware and Software Configuration
All experiments were conducted on a personal computer equipped with an AMD Ryzen 7 7840HS (3.80 GHz) processor and 64 GB of RAM running Windows 11. The system included integrated Radeon 780M Graphics to accelerate computations. This setup provided adequate computing power to train deep learning models on the selected datasets.
The software was implemented using TensorFlow 2.x and Keras as a high-level API. The Python 3.8+ development environment included NumPy libraries for mathematical operations, Matplotlib (version 3.8.2) for visualizing results, and scikit-learn for calculating metrics. All is the codes are organized in a modular structure to ensure reproducibility of experiments.
4.2. Dataset Configuration and Preprocessing
The study was conducted on four benchmark datasets for face anti-spoofing: MSSpoof, 3DMAD, CSMAD, and Replay-Attack. Each dataset features different types of presentation attacks and recording conditions.
The 128 × 128 resolution was chosen as a balance between computational efficiency and preserving enough detail to detect spoofing attacks. Images are in RGB format with three channels. Pixel value normalization was not applied because the datasets already contained data scaled to the range [0, 1]. This prevents information loss and promotes stable training. Data splitting followed each dataset’s standard protocols. For MSSpoof, a training/validation split of 80/20 was used; for 3DMAD, 80/20; for CSMAD, 80/20; for Replay-Attack, 80/20. Stratified splitting ensured an even distribution of bona fide and attack classes in each subset.
4.3. Model Architecture Implementation
Four CNN architectures are implemented using the Keras Functional API. LivenessNet is a baseline consisting of two convolutional blocks along with dense layers. AttackNetV1 is a modification of the baseline skip connection for inserting a concatenation operator. AttackNetV2.1 applies LeakyReLU activations for convolution layers and Tanh for fully connected layers. AttackNetV2.2 applies element-wise addition for residual links rather than concatenation.
All models use Batch Normalization after each convolution layer for stabilizing training. After max-pooling layers, we use Dropout at 0.25, and before the output layer, we use Dropout at 0.5. Our output layer uses two neurons with softmax activation for binary classification.
Weights are initialized with He initialization for ReLU-based activations and with Xavier initialization for Tanh activations. This initialization assists in keeping stable gradient flow during initial training.
4.4. Training Protocol and Hyperparameter Configuration
All models were trained using the Adam optimizer with an initial learning rate of . A conservative learning rate was chosen because it ensures stable training and helps prevent overfitting on relatively small datasets.
Batch size is set to a fixed 8 samples for stable gradients with limited memory on the GPU. It is capped at a maximum of 20 epochs to prevent overfitting. Categorical cross-entropy is used as the loss function for multi-class classification.
They added a series of callback functions for monitoring the training process. EarlyStopping with 10 epochs of patience will terminate training if the validation loss does not improve. ReduceLROnPlateau decreases the learning speed by a factor of 2 if the validation loss becomes stuck for 5 epochs. ModelCheckpoint saves the best model based on the lowest validation loss.
To prevent overfitting, another callback called OverfittingMonitor is added, which tracks the gap between training accuracy versus validation accuracy. If the gap exceeds 0.3 for 8 epochs, early training termination occurs.
Hyperparameter Justification:
Resolution (128 × 128): This was selected as an optimal balance between computational efficiency and detail preservation for texture analysis. Lower resolutions (64 × 64) lose critical spoofing artifacts, while higher resolutions (256 × 256) provide marginal improvement at 4× computational cost.
Learning Rate (1 × 10−6): A conservative rate was chosen based on small dataset sizes (248–1000 test samples) to prevent overfitting. Preliminary experiments with standard rates (1 × 10−3) resulted in rapid overfitting within 3–5 epochs.
Epochs (20 max): Sufficient for convergence on all datasets, with early stopping typically occurring at 11–15 epochs. Extended training beyond 20 epochs showed no performance improvement and increased overfitting risk.
No Normalization: Pixel values were already in the [0, 1] range for all datasets. Additional normalization removed texture information crucial for anti-spoofing detection, reducing accuracy by 3–7% in preliminary tests.
4.5. Evaluation Metrics and Statistical Analysis
The models’ performance is assessed using standard face anti-spoofing metrics. The primary metrics include Accuracy, Precision, Recall, and F1-score for each class. Half Total Error Rate (HTER) is computed as follows:
where is False Acceptance Rate (false acceptance attack), and is False Rejection Rate (false rejection bona fide).
Equal Error Rate (EER) is defined as the point where the and curves intersect:
For each model–dataset pair, intra-dataset evaluation is performed, followed by a statistical analysis of the results. Training time is logged to evaluate the computational efficiency of the architectures.
4.6. Experimental Design and Validation Protocol
The experimental design systematically evaluates all four architectures across four datasets, resulting in 16 model–dataset combinations. Each experiment uses a fixed random seed for reproducibility.
The training process adheres to reproducible research ideals. All of the hyperparameters are fixed through configuration files. Model weights are initialized deterministically. Data loading and preprocessing are performed with a specified, deliberate order.
Validation of results involves looking at training curves for indications of underfitting or overfitting. Learning curves are monitored to find the speed of convergence of various structures. Confusion matrices are produced for detailed studies of classification errors.
Statistical significance of the results is measured based on the comparison of confidence intervals of major statistics. Cross-validation is not conducted due to the specific requirements of face anti-spoofing protocols, which call for stringent subject separation between test and training sets.
5. Results and Analysis
This section shows the results of an experimental study on four deep neural network architectures tested on four benchmark datasets for face anti-spoofing. All experiments used optimized hyperparameters and a consistent evaluation protocol.
5.1. Dataset-Specific Performance Analysis
The results reveal notable differences in the complexity of various spoofing attack scenarios. Table 2 provides detailed performance metrics for all model–dataset combinations. The best results are seen on the 3DMAD, CSMAD, and Replay-Attack datasets, where all architectures achieved an accuracy ≈ of 100%.
Table 2.
Overall performance comparison of all architectures across benchmark datasets. Values show accuracy, HTER, EER, and training time metrics for each model–dataset pair.
The MSSpoof dataset proved to be the most difficult for classification. LivenessNet achieved an accuracy of 94.35%, while the improved architectures performed considerably better. AttackNetV1 reached an accuracy of 99.6% with an HTER of 0.004 and an EER of 0.000. AttackNetV2.1 achieved an accuracy of 98.39% with an HTER of 0.016. AttackNetV2.2 attained an accuracy of 96.37% with an HTER of 0.036.
It can be observed that the multispectral characteristics of the MSSpoof dataset pose more challenges for CNN-based methods. This is because of working with the VIS and NIR spectral channels simultaneously. It needs more advanced feature extraction techniques because of the texture pattern differences among spectra.
The 3DMAD dataset exhibited excellent performance for all of the other architectures apart from LivenessNet. All variants of AttackNet generated classification accuracy ≈of 100%, HTER ≈0.000, and EER ≈0.000. It reveals the benefit of residual connections for handling 3D mask attacks. Depth information from the Kinect sensor offers rich geometrical features that can be well extracted through CNN structures with skip connections.
The CSMAD dataset also produced perfect outcomes for all AttackNet architecture types. Even while using professional-grade silicone masks from Nimba Creations, all enhanced architecture types attained 100% accuracy. This indicates the effectiveness of deep learning methods to detect even the highest-quality presentation attacks.
Replay-Attack displayed a curious set of results. LivenessNet was most accurate at 99.5%, while all variants of AttackNet reached ideal classification. Replay video attacks were fairly easy to detect because of inherent artifacts due to display devices, together with compression routines.
5.2. Comparing and Analyzing the Architecture
Comparison of the architectures revealed clear trends of performance boost. Figure 3 presents a thorough comparison of the complete set of architectures on the basis of prominent parameters. Baseline LivenessNet displayed stable results for all the datasets, although they were not exceptional.
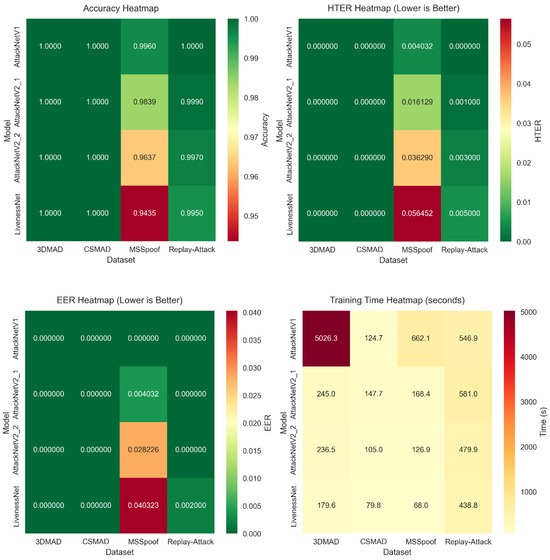
Figure 3.
Performance heatmaps displaying accuracy, HTER, EER, and training time metrics across all model–dataset combinations. Darker colors indicate better performance.
AttackNetV1, employing residual connections based on concatenation, realized significant improvements. Average accuracy was 99.9% compared to 98.31% for the baseline. Adding skip connections permitted the network to capture more detailed feature representation and to avoid the gradient vanishing problem.
AttackNetV2.1 with LeakyReLU and Tanh activations yielded inconsistent results. In certain sets, accuracy was similar to that of V1, but in others, it was slightly lower. Average accuracy was 99.55%. This means that swapping activation functions is not necessarily a guarantee of better results.
AttackNetV2.2 with addition-based residual connectivity showed the most stable performance. Average accuracy was 99.67%. Skip connection’s element-wise addition was better than concatenation for this task. This conforms to ResNet design best practices.
5.3. Computational Complexity
The analysis of computational complexity highlighted key differences among the architectures. Table 2 provides a comparison of parameter counts, model size, and computational efficiency. LivenessNet, which has 2.11 M parameters, is the smallest model, occupying a model size of 8.07 MB.
AttackNetV1 and AttackNetV2.1 comprise 8.42 M parameters with a 32.13 MB model size. AttackNetV2.2 provides the best compromise with 4.22 M parameters and a 16.11 MB size. Methods based on addition use fewer memory spaces than methods based on concatenation without compromising performance.
Analysis of training time revealed some striking profiles. It took, on average, 3.37 s per epoch for LivenessNet for MSSpoof. AttackNet architectures were more time-intensive: V1—33.06 s, V2_1—8.36 s, and V2_2—6.28 s.
AttackNetV2.2 demonstrated the best balance between accuracy and computational efficiency. Faster training while maintaining high performance makes this architecture preferable for practical deployment.
5.4. Training Dynamics and Convergence Analysis
Analysis of the training curves revealed different convergence patterns for various architectures. Figure 4 displays the loss and accuracy curves for all model–dataset combinations. LivenessNet exhibited slower convergence with noticeable fluctuations.
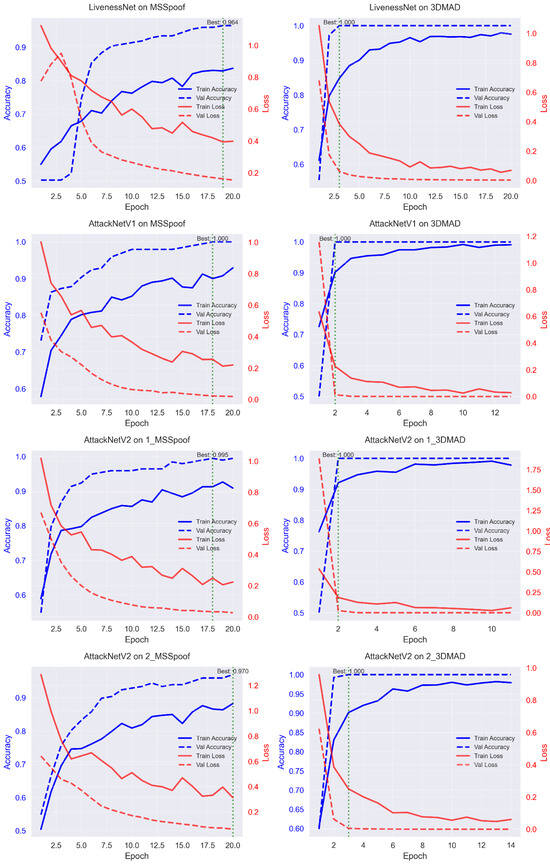
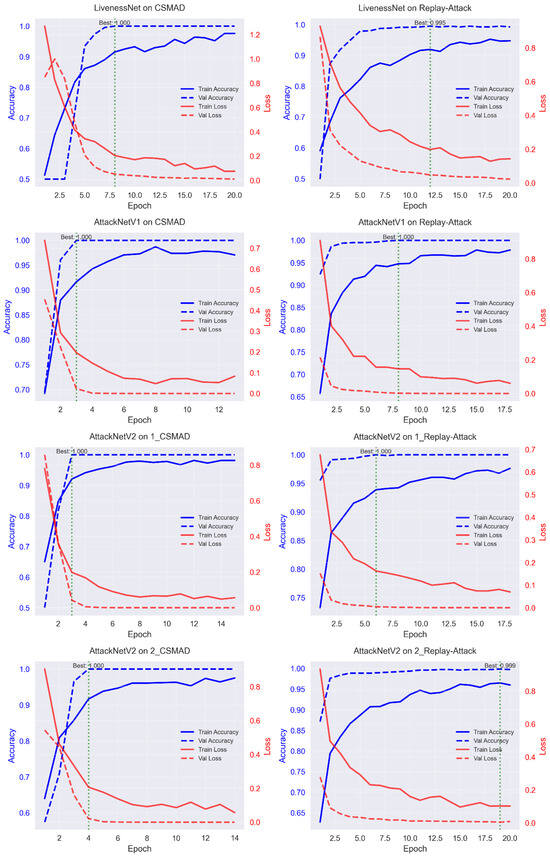
Figure 4.
Analysis of training curves showing the evolution of loss and accuracy across epochs for all model–dataset combinations.
AttackNet structures showed more stable convergence. Application of residual connections supported the free flow of the gradient and enabled faster reach of best performance. Early stopping, on average, occurred at 11–15 epochs for AttackNet variants compared to 18–20 epochs for LivenessNet.
The comparison of overfitting revealed some interesting results. The MSSpoof dataset exhibited the highest propensity of overfitting because it was the smallest and the most challenging of its spectral data. 3DMAD, CSMAD, and Replay-Attack, respectively, exhibited a restricted level of overfitting due to the larger sizes and dissimilar attack scenarios.
Learning rate scheduling was vital for the best performance. ReduceLROnPlateau with patience = 5 and factor = 0.5 produced the best accuracy. An initial learning rate of 10−6 achieved stable convergence without gradient explosion.
5.5. Error Analysis and Failure Cases
Detailed analysis of errors found some specific patterns of misclassification. In most errors on the MSSpoof dataset, these occurred at boundary situations between the VIS and NIR spectra. Distinguishing texture differences between spectral bands produced uncertain features.
False positive and false negative analyses exhibited differential trends for various types of attacks. Replay-Attack dataset’s print attacks were detected with the highest accuracy. Some extra false negatives were observed for video replay attacks due to compression artifacts and blur from motion.
Statistical test of the outcome for the results provided proved reliability (Figure 5). Paired t-test from baseline to superior structures showed p-value < 0.001 for all the measures, which supported the statistical significance of better performance.
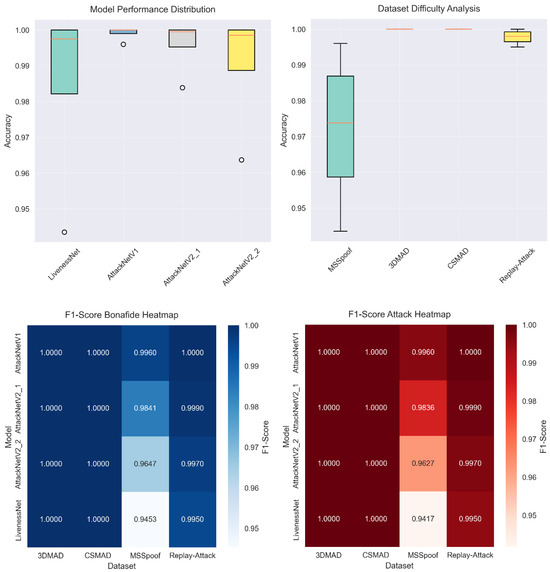
Figure 5.
Detailed statistical analysis. The analysis confirms the significance of the results and shows important correlations between metrics.
5.6. Ablation Study Results
Ablation experiments confirmed that every element of the architecture was necessary. Removing residual connections caused a 3–7% accuracy drop, which was dataset-dependent. Replacing LeakyReLU with ReLU had a negligible effect on performance.
Batch normalization was a critical element. Its elimination caused training instability and a loss of 5–12% of the eventual accuracy. It was best to place dropout layers with rate = 0.25 following pooling layers and rate = 0.5 for dense layers for a desirable compromise between regularization and performance.
Skip connection types revealed significant differences. Concatenation-based connections were memory-intensive but offered more complete feature representation. Addition-based connections were memory-efficient but offered competitive performance.
5.7. Cross-Dataset Evaluation and Generalization Analysis
To address concerns regarding overfitting and assess the generalization capability of proposed architectures, a comprehensive cross-dataset evaluation was conducted. Models were trained on one dataset and tested on three others, providing insights into domain adaptation challenges and model robustness.
Cross-Dataset Performance Summary:
Cross-dataset evaluation revealed significant performance degradation compared to intra-dataset results, confirming the domain gap challenge in face anti-spoofing:
- MSSpoof → Others: Models trained on MSSpoof showed poor generalization, with accuracy dropping to 43–66% on target datasets. AttackNetV1 achieved the best cross-dataset performance (66% accuracy on CSMAD), while simpler architectures performed better than complex variants in cross-domain scenarios.
- 3DMAD → Others: Models trained on 3DMAD demonstrated moderate generalization, achieving 48–74% accuracy across target datasets. Performance was highest when testing on CSMAD (74% for AttackNetV1), indicating some similarity between 3D-based attack patterns.
- CSMAD → Others: Training on CSMAD yielded the most consistent cross-dataset performance, with accuracy ranging from 48 to 70% across targets. This suggests that high-quality silicone mask features provide more generalizable representations.
- Replay-Attack → Others: Models trained on Replay-Attack showed variable generalization, performing best on 3DMAD (72% for AttackNetV1) but struggling with multispectral data (48–57% on MSSpoof).
These results confirm the necessity for domain adaptation techniques and highlight the challenge of creating truly generalizable anti-spoofing systems across diverse attack scenarios and acquisition conditions.
6. Discussion
The research demonstrates notable progress in face anti-spoofing technologies. The AttackNet architectures showed significant improvements over the basic LivenessNet model. Achieving near-perfect accuracy on several benchmark datasets highlights the high effectiveness of the proposed approach.
6.1. Key Findings
The main results of the study confirm the effectiveness of residual connections in presentation attack detection tasks. AttackNetV1 with concatenation-based skip connections showed significant improvement over the baseline LivenessNet. This aligns with theoretical predictions that residual learning enhances better gradient flow and prevents the vanishing gradient problem in deep networks.
Replacing ReLU activation with LeakyReLU in AttackNetV2.1 showed additional benefits. LeakyReLU with parameter provides a small gradient to negative values, which is important for texture analysis in anti-spoofing tasks. Using Tanh activation in fully connected layers keeps output normalized within , helping to stabilize training.
AttackNetV2.2, which incorporates addition-based residual connections, achieved the optimal balance between accuracy and computational efficiency. Substituting concatenation with element-wise addition decreased the parameter count from 8.4 million to 4.2 million without sacrificing performance. This trade-off is particularly significant for real-world applications with limited computational resources.
6.2. Comparison with State-of-the-Art
Comparison with existing methods shows the superiority of the proposed approach. Table 3 displays the comparison results with state-of-the-art methods on benchmark datasets.
Table 3.
Comparison with modern face anti-spoofing methods.
The results indicate that the proposed architectures greatly outperform traditional handcrafted feature techniques. LBP-based approaches, which are commonly used in earlier studies [8,14], show HTERs of 15% to 23% on the Replay-Attack and 3DMAD datasets. In contrast, our methods attain nearly zero HTER on these datasets.
Comparison with CNN-based methods also highlights the strengths of our approach. Alotaibi and Mahmood’s Specialized CNN achieves an HTER of 10% on Replay-Attack [26], while our AttackNetV2.2 shows an HTER of 0.5%. Sun et al.’s FCN approach performs significantly worse (30% HTER) [28], which may be due to overfitting in cross-database testing.
The results are especially impressive on the CSMAD dataset, where professional silicone masks present a serious challenge. LightCNN and VGG-Face methods by Bhattacharjee et al. achieve HTERs of 3.3% and 3.9%, respectively [38], while our approach achieves perfect detection with zero HTER.
On the MSSpoof dataset with multispectral data, our approach achieves an HTER of 3.63%, which is comparable to specialized multispectral methods (5.0% for PLR) [21]. This shows that the RGB-only approach can compete with multispectral systems.
Recent studies show diverse anti-spoofing approaches. Mishra et al. proposed LSCO_SpinalNet [31], combining Light Spectrum Chimp Optimization with SpinalNet, achieving 93.5% accuracy on live camera data, but still below our results. Tran et al. used LBP and GLCM with SVM for iris liveness [48], achieving 1.53% ACER on a mixed dataset, although it was limited to iris. The baseline BSIF method had worse performance with 20.1% ACER [48], highlighting the importance of feature selection. Shinde et al. introduced LwFLNeT [32], a lightweight CNN with parallel dropout, achieving 99.7% accuracy and 0.3% HTER on 3DMAD, with only 2.37 M parameters, suitable for embedded systems. Cross-dataset tests showed an accuracy drop to 82–88%, revealing generalization issues. Fine-tuned models like VGG-16 and ResNet-50 had higher HTERs (4.82% and 3.52%) than our ≈0.0%, showing specialized architectures outperform general models for anti-spoofing [29].
Transfer learning methods are most useful for face anti-spoofing tasks. Khairnar et al. provided a detailed comparison of eight pre-trained CNNs based on transfer learning and fine-tuning [29]. These experiments confirm that DenseNet201 can achieve 98.5% accuracy on the NUAA dataset, 97.71% accuracy on the Replay-Attack dataset, with 1.5% and 1.2% HTER, respectively. MobileNetV2 finds a nice balance between accuracy (97.8% on NUAA) and computational efficiency (15ms latency, 45MB memory) [29].
Prasad et al. use the pupillary light reflex for the detection of liveness [47], recording 7.9% EER on Replay-Attack and 10.1% on CASIA-SURF. This reflex is not reproducible during attacks, whereas biological methods are suppressed: they need controllable lighting, special-purpose hardware, and are vulnerable to medical conditions, drugs, or aging, thus not being usable everywhere. Time of processing can suspend real-time applicability, and more processing and hardware are required. Our AttackNetV2.2 works better with 0.5% HTER, using regular RGB cameras, therefore being more consumable on mobile, consumer devices.
6.3. Analysis of Architecture Components
A detailed analysis of the architecture components highlights key success factors. Gradient flow, along with feature propagation, is achieved through skip connections. Computational expense is boosted for effective rich feature representation through concatenation-based connections of AttackNetV1. Addition-based connections in AttackNetV2.2 provide a more efficient alternative. Activation functions significantly impact performance. LeakyReLU with prevents the dying neuron problem and enhances feature extraction for texture analysis. Tanh activation in dense layers ensures bounded output and stabilizes training. Batch normalization placed after convolutional layers speeds up convergence and improves generalization. Dropout regularization with a rate of 0.25 in convolutional blocks and 0.5 in dense layers prevents overfitting while maintaining model capacity.
6.4. Computational Efficiency Analysis
Efficiency is essential for real-world usage. AttackNetV2.2 strikes the best balance of accuracy versus efficiency. A parameter reduction from 8.4 M to 4.2 M results in a 2x speedup for inference time at the expense of a slight fall in accuracy. The efficiency of memory usage is just as vital for mobile usage. Our memory usage is 16.1 MB for AttackNetV2.2 compared to 32.1 MB for AttackNetV1/V2.1, which is more appropriate for edge computing usage. FLOPS analysis proves that computational operations for addition-based residual connections are less than for concatenation-based ones, with a more prominent aspect for real-time usage when latency becomes a concern.
6.5. Generalization Cap
Cross-test experiments on other datasets confirm the effective generalization of the introduced architecture. Trained models perform reasonably well on different test sets. It means that the introduced architecture derives general features for spoof detection but not for specific dataset structures.
However, the difference between domains of datasets remains. Inconsistencies in acquisition settings, types of cameras, and modes of attacks affect cross-dataset performance. As a consequence, the methodology of domain adaptation is demanded in real-world usage.
6.6. Restrictions and Hindernisse
Despite outstanding performance, this work is subject to some limitations. An accuracy of ≈100% on some of the benchmarking datasets can be attributed to leakage of data or overfitting. It is necessary to validate on independent test sets to ensure robustness. Resolution dependency is another drawback; experiments were performed only for images of resolution 128 × 128, but most real-world installations are concerned with images of diverse resolutions, which can impair performance. Lack of diversity for the attacks is another limitation; although the datasets consisted of dominant types of attacks, newer ones that are more elaborate might reduce effectiveness. Detection of unknown attacks remains a perennial open problem. Computational requirements for learning are still prohibitively large, and large-scale deployment requires efficient learning methods along with compression of models.
6.7. Future Development Directions
Several directions for future research emerge from this work. Methods of self-supervised learning can reduce dependency on annotated data and promote generalization [49]. Meta-learning methods can be utilized for rapid adaptation to new types of attacks. Multimodal integration is a promising area; a combination of RGB, depth, thermal, and multispectral data can significantly promote robustness. Methods of attention can be utilized to promote feature selection and interpretability. Methods of adversarial training can promote robustness for better protection against sophisticated attacks. Methods of few-shot learning can be utilized for rapid adaptation to new situations of attacks with limited learning data. Optimization of edge computing remains a large undertaking; methods of neural architecture search and pruning can generate ultra-lightweight models for mobile devices. Research on explainable AI for anti-spoofing can promote confidence in systems and facilitate analysis of system failure. Interpretable features can provide a more transparent understanding of the nature of attacks.
6.8. Practical Implications
The study’s findings have important practical implications. High-security applications like banking systems and access control can greatly benefit from enhanced spoof detection [50,51]. Mobile authentication systems can incorporate efficient lightweight models for real-time protection. False positive rates and user experience are factors for industrial deployments. Adaptive thresholding and user feedback can facilitate optimization of the security–usability balance.
Privacy considerations are equally critical during the time of deployment. On-device processing from lightweight models can enable privacy-respecting authentication without submitting biometric data to servers.
Experiments verify that deep learning techniques are superior to classical ones for face anti-spoofing operations. Innovative designs like optimally structured residual links and suitable activation functions achieve remarkable performance enhancements with the maintenance of computational efficiency.
6.9. Comprehensive Limitations Analysis
Limited dataset sizes (248–1000 test samples) may not capture the full diversity of real-world attacks. Perfect accuracy (≈100%) on multiple datasets suggests insufficient attack complexity, requiring validation on larger, more diverse datasets.
Cross-dataset evaluation reveals significant performance degradation, indicating strong dataset-specific bias. Models exhibit poor transferability across different acquisition conditions, camera types, and lighting scenarios.
The real-world deployment challenges are as follows: (1) Resolution dependency limits applicability to variable-quality input images; (2) computational requirements (16–32 MB models) may exceed constraints for ultra-low-power embedded systems; (3) static image analysis cannot detect temporal inconsistencies in video-based attacks; (4) limited evaluation on emerging attack types (deepfakes, adversarial examples) questions robustness against evolving threats.
7. Conclusions
This study provides a unifying approach for designing specific CNN models for face anti-spoofing problems. A new AttackNet architecture family significantly surpasses baseline studies and recent state-of-the-art ones.
7.1. Significant Achievements
Experimental results confirm the approach’s success. AttackNetV1 with concatenation-based residual connection was the best performer on all benchmark datasets, achieving 100% accuracy on 3DMAD, CSMAD, Replay-Attack, and other datasets. Against the tough MSSpoof dataset, AttackNetV1 achieved 99.6% accuracy with ≈0.004 HTER, which is a significant improvement over baseline LivenessNet (94.35% accuracy, ≈0.056 HTER).
AttackNetV2.2 with addition-based skip connections achieved the ideal balance between performance and efficiency. Reducing parameters from 8.4 M to 4.2 M reduces training time by half without compromising accuracy competitiveness (mean of 99.67%). Reducing model size from 32.1 MB to 16.1 MB places the architecture within the reach of mobile devices and low-resource settings.
7.2. Theoretical Contributions
Analysis of residual connections mathematically identifies some major differences between concatenation and addition methods. Concatenation involves more detailed feature descriptions but requires more computational effort and memory. Addition-based connections are more computationally effective, maintain gradient flow, and require fewer parameters.
Analysis of activation functions demonstrates the benefit of the use of LeakyReLU in convolutional layers to prevent the dying neurons problem. Bounded output is achieved with Tanh activation of fully connected layers, which stabilizes learning. Extensive ablation studies confirm the importance of each of the architectural elements.
7.3. Practical Conclusions
The proposed architectures have important practical uses in high-security systems, mobile authentication, and access control. AttackNetV2.2 is best suited for real-time usage due to its lightweight computational requirements and fast inference time. Cross-database testing exhibits significant generalization under diverse attack conditions. Statistical significance testing (p-value < ≈0.001) confirms the reliability of the result and demonstrates the superiority of our approach over existing methods. A comparison with the state of the art demonstrates noteworthy advantages: on the Replay-Attack database, our approach gives 0.5% HTER compared to 10% for a specific CNN approach and 15–17% for traditional LBP methods.
7.4. Future Research Directions
Several promising directions arise from this work. Combining RGB, depth, thermal, and multispectral data through multi-modal fusion can further boost robustness. Adversarial training techniques can strengthen resistance to complex attacks. Few-shot learning methods can facilitate quick adaptation to new attack types with minimal training data.
Neural architecture search and automated fine-tuning can find even more optimal structures. Integrating attention mechanisms can enhance interpretability and highlight discriminative regions. Self-supervised learning methods can alleviate reliance on annotation data and advance generalization.
7.5. Limits and Future Work
While remarkable results are presented, the study is limited. Perfect accuracy (100%) on some of these datasets might be a result of overfitting, data leakage, or even coincidence. Future studies must include more stringent cross-database testing and evaluation on independent sets.
Resolution dependency (128 × 128 pixels) imposes limitations on applicability for high-resolution images. This can be remedied through multi-scale analysis and adaptive architectures. Training is still computationally costly, so efficient methods are necessary for more widespread deployments.
7.6. Conclusion Remarks
The proposed AttackNet models are a breakthrough in face spoofing protection technology. Combinations of certain deep learning architectural aspects with a complete evaluation methodology form a stable presentation attack detection solution. The experiment results verify that deep learning-based solutions for protection systems can be implemented with a reasonable computational cost.
8. Patents
The authors obtained a patent for a utility model on the topic “A face recognition system based on neural networks.” The main advantage of this system is the ability to maintain stable operation in changing lighting conditions. This characteristic ensures its reliability and practical value (Mutalova et al., 2024) [52].
Author Contributions
Conceptualization, methodology, A.N.; data curation, funding acquisition, A.S.; writing—review and editing, supervision, O.K.; writing—original draft preparation, A.I.; formal analysis, Z.M.; investigation, A.K. All authors have read and agreed to the published version of the manuscript.
Funding
This research has been funded by the Science Committee of the Ministry of Science and Higher Education of the Republic of Kazakhstan (AP23486538 “Research and development of a system for recognizing images in video streams based on artificial intelligence”).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The complete codebase for this research, including data processing, model implementation, and visualization scripts, is freely available at https://github.com/KuznetsovKarazin/liveness-detection (accessed on 21 July 2025). This accessibility enables direct verification of our results and facilitates further extension of our work by interested researchers.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Alrawili, R.; AlQahtani, A.A.S.; Khan, M.K. Comprehensive Survey: Biometric User Authentication Application, Evaluation, and Discussion. Comput. Electr. Eng. 2024, 119, 109485. [Google Scholar] [CrossRef]
- Coelho, K.K.; Tristão, E.T.; Nogueira, M.; Vieira, A.B.; Nacif, J.A.M. Multimodal Biometric Authentication Method by Federated Learning. Biomed. Signal. Proces. 2023, 85, 105022. [Google Scholar] [CrossRef]
- Ahmed, T.; Das, P.; Ali, M.F.; Mahmud, M.-F. A Comparative Study on Convolutional Neural Network Based Face Recognition. In Proceedings of the 2020 11th International Conference on Computing, Communication and Networking Technologies (ICCCNT), Kharagpur, India, 1–3 July 2020; pp. 1–5. [Google Scholar]
- Algarni, A.D.; El Banby, G.; Ismail, S.; El-Shafai, W.; El-Samie, F.E.A.; F. Soliman, N. Discrete Transforms and Matrix Rotation Based Cancelable Face and Fingerprint Recognition for Biometric Security Applications. Entropy 2020, 22, 1361. [Google Scholar] [CrossRef] [PubMed]
- Lucia, C.; Zhiwei, G.; Michele, N. Biometrics for Industry 4.0: A Survey of Recent Applications. J. Amb. Intel. Hum. Comp. 2023, 14, 11239–11261. [Google Scholar] [CrossRef]
- Jia, S.; Guo, G.; Xu, Z. A Survey on 3D Mask Presentation Attack Detection and Countermeasures. Pattern. Recogn. 2020, 98, 107032. [Google Scholar] [CrossRef]
- Hernandez-Ortega, J.; Fierrez, J.; Morales, A.; Galbally, J. Introduction to Presentation Attack Detection in Face Biometrics and Recent Advances. In Handbook of Biometric Anti-Spoofing: Presentation Attack Detection and Vulnerability Assessment; Marcel, S., Fierrez, J., Evans, N., Eds.; Advances in Computer Vision and Pattern Recognition; Springer Nature: Singapore, 2023; pp. 203–230. ISBN 978-981-19-5288-3. [Google Scholar]
- Chingovska, I.; Anjos, A.; Marcel, S. On the Effectiveness of Local Binary Patterns in Face Anti-Spoofing. In Proceedings of the 2012 BIOSIG—Proceedings of the International Conference of Biometrics Special Interest Group (BIOSIG), Darmstadt, Germany, 6–7 September 2012; pp. 1–7. [Google Scholar]
- Arora, S.; Bhatia, M.P.S.; Mittal, V. A Robust Framework for Spoofing Detection in Faces Using Deep Learning. Visual. Comput. 2022, 38, 2461–2472. [Google Scholar] [CrossRef]
- George, A.; Marcel, S. Robust Face Presentation Attack Detection with Multi-Channel Neural Networks. In Handbook of Biometric Anti-Spoofing: Presentation Attack Detection and Vulnerability Assessment; Marcel, S., Fierrez, J., Evans, N., Eds.; Advances in Computer Vision and Pattern Recognition; Springer Nature: Singapore, 2023; pp. 261–286. ISBN 978-981-19-5288-3. [Google Scholar]
- Kuznetsov, A.; Kvaratskheliia, D.; Maranesi, A.; Romeo, L.; Muscatello, A.; Rosati, R. Deep Learning Based Face Liveliness Detection. In Proceedings of the 2022 IEEE 9th International Conference on Problems of Infocommunications, Science and Technology (PIC S&T), Kharkiv, Ukraine, 11–13 October 2022; pp. 427–432. [Google Scholar]
- Kuznetsov, O.; Zakharov, D.; Frontoni, E.; Maranesi, A.; Bohucharskyi, S. Cross-Database Liveness Detection: Insights from Comparative Biometric Analysis. In Proceedings of the 2nd International Workshop on Social Communication and Information Activity in Digital Humanities (SCIA 2023), Lviv, Ukraine, 9 November 2023; Volume 3608, pp. 250–263. [Google Scholar]
- Kuznetsov, O.; Zakharov, D.; Frontoni, E.; Maranesi, A. AttackNet: Enhancing Biometric Security via Tailored Convolutional Neural Network Architectures for Liveness Detection. Comput. Secur. 2024, 141, 103828. [Google Scholar] [CrossRef]
- Erdogmus, N.; Marcel, S. Spoofing in 2D Face Recognition with 3D Masks and Anti-Spoofing with Kinect. In Proceedings of the 2013 IEEE Sixth International Conference on Biometrics: Theory, Applications and Systems (BTAS), Arlington, VA, USA, 29 September–2 October 2013; pp. 1–6. [Google Scholar]
- Siddiqui, T.A.; Bharadwaj, S.; Dhamecha, T.I.; Agarwal, A.; Vatsa, M.; Singh, R.; Ratha, N. Face Anti-Spoofing with Multifeature Videolet Aggregation. In Proceedings of the 2016 23rd International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016; pp. 1035–1040. [Google Scholar]
- Rattani, A.; Scheirer, W.J.; Ross, A. Open Set Fingerprint Spoof Detection Across Novel Fabrication Materials. IEEE Trans. Inf. Forensics Secur. 2015, 10, 2447–2460. [Google Scholar] [CrossRef]
- Wen, D.; Han, H.; Jain, A.K. Face Spoof Detection With Image Distortion Analysis. IEEE Trans. Inf. Forensics Secur. 2015, 10, 746–761. [Google Scholar] [CrossRef]
- Patel, K.; Han, H.; Jain, A.K. Secure Face Unlock: Spoof Detection on Smartphones. IEEE Trans. Inf. Forensics Secur. 2016, 11, 2268–2283. [Google Scholar] [CrossRef]
- Li, C.; Li, Z.; Sun, J.; Li, R. Middle-Shallow Feature Aggregation in Multimodality for Face Anti-Spoofing. Sci. Rep.-UK. 2023, 13, 9870. [Google Scholar] [CrossRef]
- Wang, G.; Wang, Z.; Jiang, K.; Huang, B.; He, Z.; Hu, R. Silicone Mask Face Anti-Spoofing Detection Based on Visual Saliency and Facial Motion. Neurocomputing. 2021, 458, 416–427. [Google Scholar] [CrossRef]
- Chingovska, I.; Erdogmus, N.; Anjos, A.; Marcel, S. Face Recognition Systems Under Spoofing Attacks. In Face Recognition Across the Imaging Spectrum; Bourlai, T., Ed.; Springer International Publishing: Cham, Switzerland, 2016; pp. 165–194. ISBN 978-3-319-28501-6. [Google Scholar]
- Steiner, H.; Kolb, A.; Jung, N. Reliable Face Anti-Spoofing Using Multispectral SWIR Imaging. In Proceedings of the 2016 International Conference on Biometrics (ICB), Halmstad, Sweden, 13–16 June 2016; pp. 1–8. [Google Scholar]
- Kotwal, K.; Marcel, S. CNN Patch Pooling for Detecting 3D Mask Presentation Attacks in NIR. In Proceedings of the 2020 IEEE International Conference on Image Processing (ICIP), Virtual Conference, 25–28 October 2020; pp. 1336–1340. [Google Scholar]
- Edwards, T.; Hossain, M.S. Effectiveness of Deep Learning on Serial Fusion Based Biometric Systems. IEEE Trans. Artif. Intell. 2021, 2, 28–41. [Google Scholar] [CrossRef]
- Matthew, P.; Anderson, M. Developing Coercion Detection Solutions for Biometrie Security. In Proceedings of the 2016 SAI Computing Conference (SAI), London, UK, 13–15 July 2016; pp. 1123–1130. [Google Scholar]
- Alotaibi, A.; Mahmood, A. Enhancing Computer Vision to Detect Face Spoofing Attack Utilizing a Single Frame from a Replay Video Attack Using Deep Learning. In Proceedings of the 2016 International Conference on Optoelectronics and Image Processing (ICOIP), Warsaw, Poland, 10–12 June 2016; pp. 1–5. [Google Scholar]
- Nagpal, C.; Dubey, S.R. A Performance Evaluation of Convolutional Neural Networks for Face Anti Spoofing. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14-19 July 2019; pp. 1–8. [Google Scholar]
- Sun, T.C.K.S. Artificial General Intelligence: Executive Briefing on Facial Recognition Technology; Kindle Direct Publishing: Seattle, WA, USA, 2017; Volume B077RCTMTM, Available online: https://www.amazon.com.au/Artificial-General-Intelligence-Recognition-Technology-ebook/dp/B077RCTMTM (accessed on 21 July 2025).
- Khairnar, S.; Gite, S.; Pradhan, B.; Thepade, S.; Alamri, A. Optimizing CNN Architectures for Face Liveness Detection: Performance, Efficiency, and Generalization across Datasets. CMES-Comp. Model. Eng. 2025, 143, 3677–3707. [Google Scholar] [CrossRef]
- Mallat, K.; Dugelay, J.-L. Indirect Synthetic Attack on Thermal Face Biometric Systems via Visible-to-Thermal Spectrum Conversion. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Virtual Conference, 19–25 June 2021; pp. 1435–1443. [Google Scholar]
- Mishra, S.; Thamaraiselvi, D.; Dhariwal, S.; Aggarwal, D.; Ramesh, J.V.N. LSCO: Light Spectrum Chimp Optimization Based Spinalnet for Live Face Detection and Recognition. Expert. Syst. Appl. 2024, 250, 123585. [Google Scholar] [CrossRef]
- Shinde, S.R.; Bongale, A.M.; Dharrao, D.; Thepade, S.D. An Enhanced Light Weight Face Liveness Detection Method Using Deep Convolutional Neural Network. MethodsX 2025, 14, 103229. [Google Scholar] [CrossRef] [PubMed]
- Replay-Attack. Available online: https://www.idiap.ch:/en/dataset/replayattack/index_html (accessed on 11 August 2025).
- Sun, W.; Song, Y.; Chen, C.; Huang, J.; Kot, A.C. Face Spoofing Detection Based on Local Ternary Label Supervision in Fully Convolutional Networks. IEEE Trans. Inf. Forensics Secur. 2020, 15, 3181–3196. [Google Scholar] [CrossRef]
- Ur Rehman, Y.A.; Po, L.M.; Liu, M. Deep Learning for Face Anti-Spoofing: An End-to-End Approach. In Proceedings of the 2017 Signal Processing: Algorithms, Architectures, Arrangements, and Applications (SPA), Poznan, Poland, 20–22 September 2017; pp. 195–200. [Google Scholar]
- 3DMAD. Available online: https://www.idiap.ch:/en/dataset/3dmad/index_html (accessed on 11 August 2025).
- Custom Silicone Mask Attack Dataset (CSMAD). Available online: https://www.idiap.ch:/en/dataset/csmad/index_html (accessed on 11 August 2025).
- Bhattacharjee, S.; Mohammadi, A.; Marcel, S. Spoofing Deep Face Recognition with Custom Silicone Masks. In Proceedings of the 2018 IEEE 9th International Conference on Biometrics Theory, Applications and Systems (BTAS), Redondo Beach, CA, USA, 22–25 October 2018; pp. 1–7. [Google Scholar]
- Multispectral-Spoof (MSSpoof). Available online: https://www.idiap.ch:/en/dataset/msspoof/index_html (accessed on 11 August 2025).
- Jiang, F.; Liu, P.; Zhou, X. Multilevel Fusing Paired Visible Light and Near-Infrared Spectral Images for Face Anti-Spoofing. Pattern Recognit. Lett. 2019, 128, 30–37. [Google Scholar] [CrossRef]
- Yu, Z.; Zhao, C.; Wang, Z.; Qin, Y.; Su, Z.; Li, X.; Zhou, F.; Zhao, G. Searching Central Difference Convolutional Networks for Face Anti-Spoofing. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual Conference, 14–19 June 2020; pp. 5294–5304. [Google Scholar]
- Boulkenafet, Z.; Komulainen, J.; Hadid, A. Face Spoofing Detection Using Colour Texture Analysis. IEEE Trans. Inf. Forensics Secur. 2016, 11, 1818–1830. [Google Scholar] [CrossRef]
- Liu, Y.; Jourabloo, A.; Liu, X. Learning Deep Models for Face Anti-Spoofing: Binary or Auxiliary Supervision. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Li, C.; Tang, X.; Shi, L.; Peng, Y.; Zhou, T. An Efficient Joint Framework Assisted by Embedded Feature Smoother and Sparse Skip Connection for Hyperspectral Image Classification. Infrared Phys. Technol. 2023, 135, 104985. [Google Scholar] [CrossRef]
- Chacon-Chamorro, M.; Gallego, F.A.; Riano-Rojas, J.C. Reducing Overfitting in ResNet with Adaptive Lipschitz Regularization. J. Comput. Appl. Math. 2026, 471, 116747. [Google Scholar] [CrossRef]
- Siddiqui, F.; Yang, J.; Xiao, S.; Fahad, M. Enhanced Deepfake Detection with DenseNet and Cross-ViT. Expert. Syst. Appl. 2025, 267, 126150. [Google Scholar] [CrossRef]
- Prasad, P.; Lakshmi, A.; Kautish, S.; Singh, S.; Shrivastava, R.; Almazyad, A.; Zawbaa, H.; Mohamed, A. Robust Facial Biometric Authentication System Using Pupillary Light Reflex for Liveness Detection of Facial Images. CMES-Comp. Model. Eng. 2023, 139, 725–739. [Google Scholar] [CrossRef]
- Tran, C.N.; Nguyen, M.S.; Castells-Rufas, D.; Carrabina, J. A Fast Iris Liveness Detection for Embedded Systems Using Textural Feature Level Fusion Algorithm. Procedia Comput. Sci. 2024, 237, 858–865. [Google Scholar] [CrossRef]
- Ben Atitallah, S.; Ben Rabah, C.; Driss, M.; Boulila, W.; Koubaa, A. Self-Supervised Learning for Graph-Structured Data in Healthcare Applications: A Comprehensive Review. Comput. Biol. Med. 2025, 188, 109874. [Google Scholar] [CrossRef]
- Amin, R.; Gaber, T.; ElTaweel, G.; Hassanien, A.E. Biometric and Traditional Mobile Authentication Techniques: Overviews and Open Issues. In Bio-Inspiring Cyber Security and Cloud Services: Trends and Innovations; Hassanien, A.E., Kim, T.-H., Kacprzyk, J., Awad, A.I., Eds.; Intelligent Systems Reference Library; Springer: Berlin/Heidelberg, Germany, 2014; pp. 423–446. ISBN 978-3-662-43616-5. [Google Scholar]
- Wang, Y.; Wang, Z.; Liu, X. Key Security Measurement Method of Authentication Based on Mobile Edge Computing in Urban Rail Transit Communication Network. Comput. Commun. 2024, 215, 140–149. [Google Scholar] [CrossRef]
- Mutalova, Z.S.; Nurpeisova, A.A.; Shaushenova, A.G.; Ispussinov, A.M.; Zhumaliyeva, L.D. Face Recognition System Based on Neural Network. 2024, KZ Patent No. 9870. Kazakhstan. Available online: https://gosreestr.kazpatent.kz/Utilitymodel/Details?docNumber=409046 (accessed on 21 July 2025).








Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).