1. Introduction
With the continuous development of network technology and information digitisation, digital communication occupies an important position in daily life, which puts forward higher requirements for information security in cyberspace. In order to protect the medium can be transmitted safely, at first, researchers protect the information by taking encryption. Among the types of media include text [
1], pictures [
2,
3,
4], and video [
5]. However, encryption algorithms, while protecting the medium for transmission, expose the encrypted medium to potential attackers and make it vulnerable to targeted attacks [
6]. To solve the above problem, steganography has received a lot of attention.
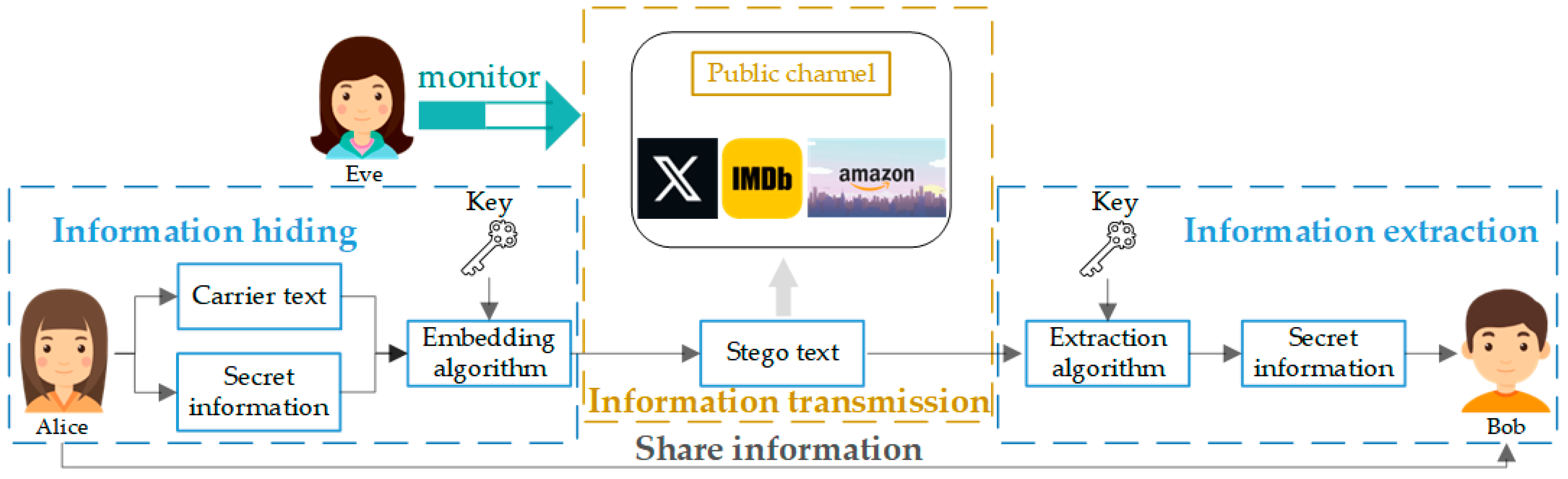
Steganography is a technique of embedding secret information in a digital medium with the aim of achieving covert communication of information [
7]. Among them, text, as one of the commonly used carriers in digital communication, has led to numerous cases of malicious theft of text information due to the openness of the network. Text steganography is a text-based information hiding technology, which can realise the covert transmission of secret text in the open channel, and has gradually become a research hotspot in the field of information network security [
8]. In recent years, with the development of natural language processing (NLP) and language models, generative text steganography has received extensive attention [
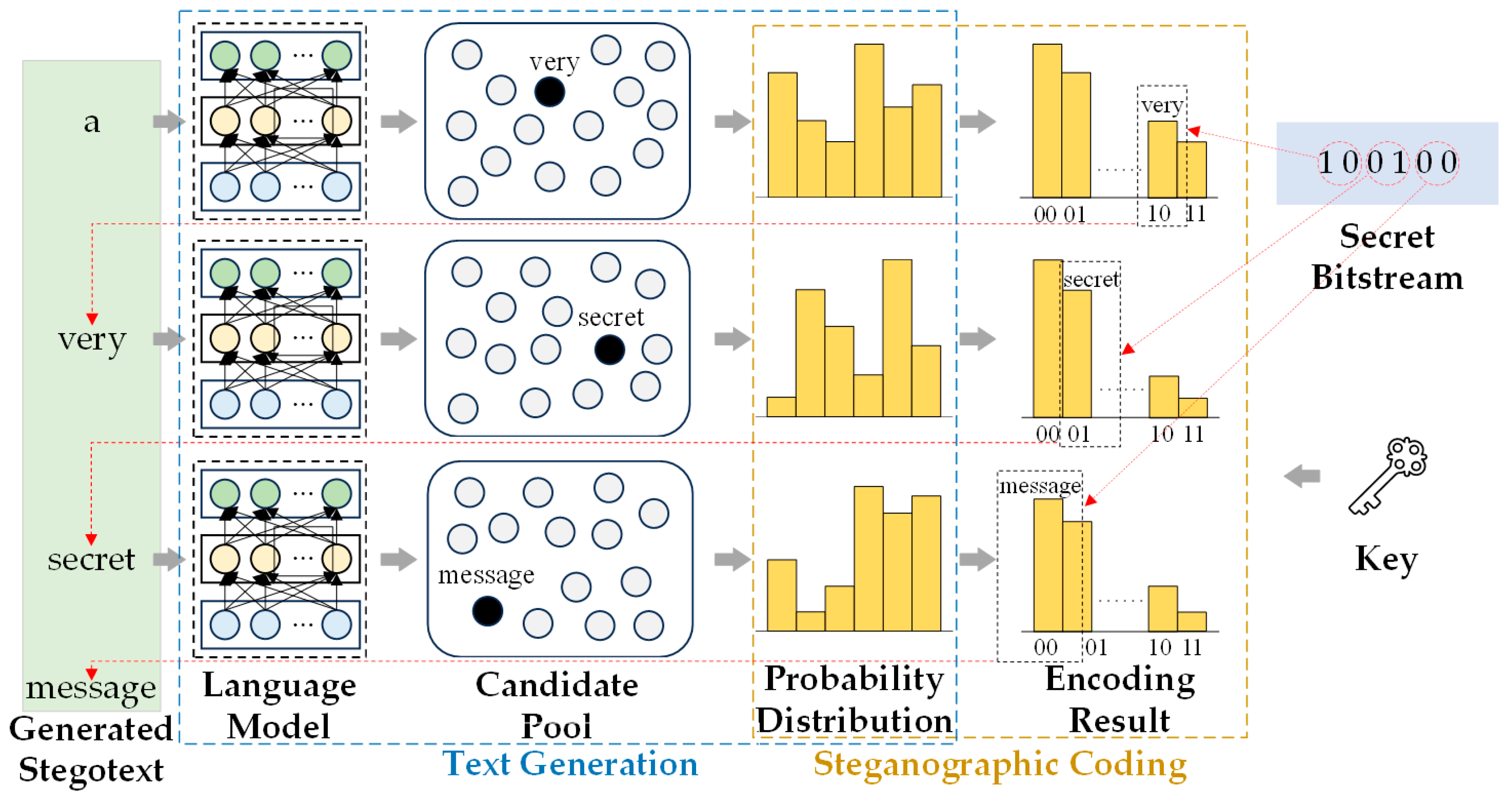
9]. It uses the language model as the text generator, and constructs the correspondence between the predicted word and the secret information bit stream through the encoding strategy, so as to realize the stegotext generation while embedding the secret information.
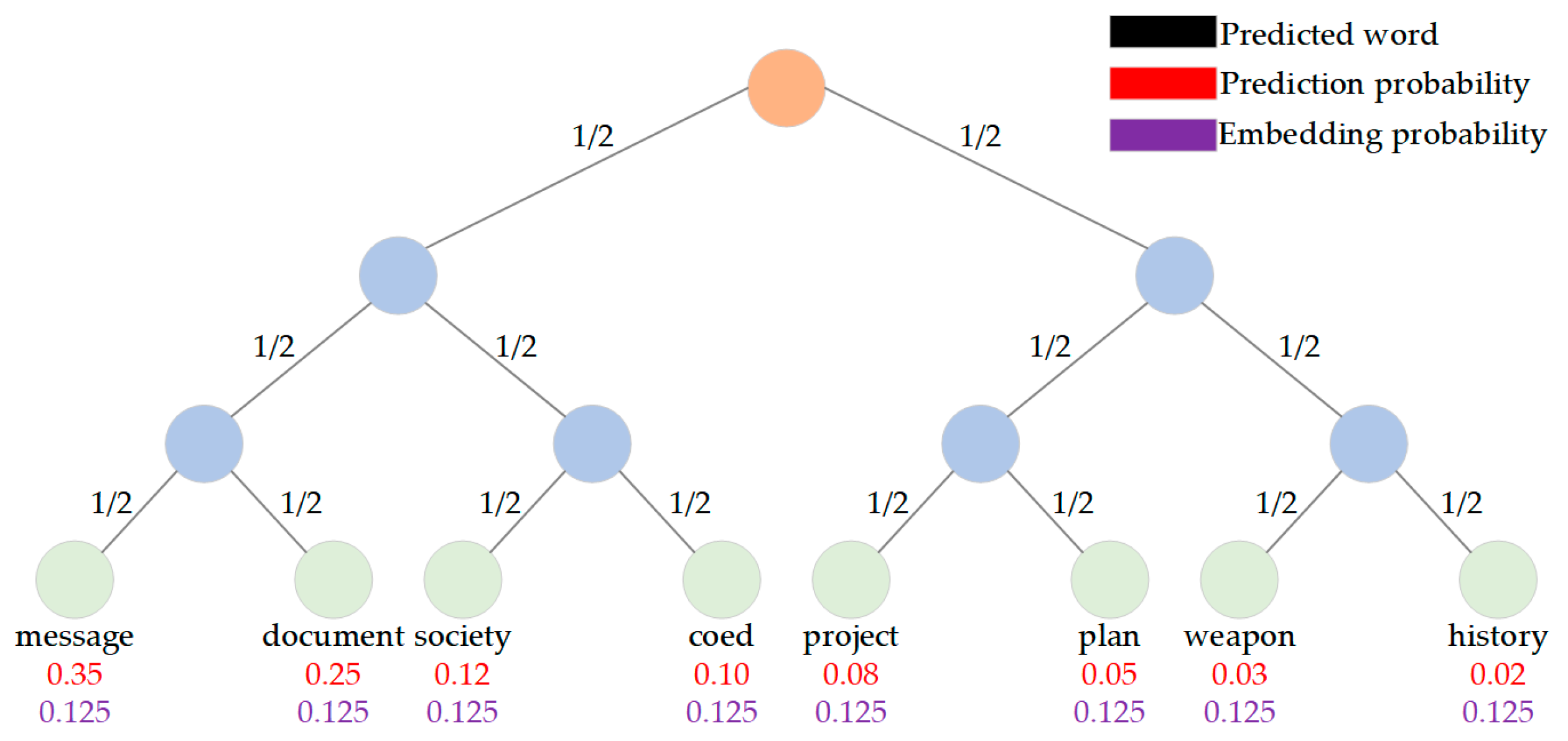
However, generative text steganography generates stegotext through the probability distribution of the output of the language model [
10]. This means that the generation of words at each step is determined by the words nearby the word and the secret information, rather than by the semantics and the current context [
11]. If the language model selects a word that violates the context at the current time step, it will lead to a deviation in the semantics of subsequent text generation. The above problems of deviation between stegotext and context content and sentiment affect the imperceptibility of stegotext, making it easier to be detected and difficult to realize covert information transmission.
To solve the above problems, it is important to find a way to increase the semantic and emotional information we can obtain from the context. Therefore, this paper extracts the central text and emotional features in the current context information as the input of LLM to constrain the generation of stegotext, ensure that the text content meets the context requirements, and improve the quality, imperceptibility and security of stegotext.
In summary, the contributions of this work can be outlined as follows.
Proposes a controllable generative text steganography framework based on LLM. The LLM is used as the
stegotext
generator without extra training, and the controllable g
eneration of
stegotext
is realized by only using the cue word template, avoiding the complex training process of the traditional deep neural network
(DNN)
model.
For the first time, named entity and sentiment analysis are integrated into the process of generating stegotext. By identifying and extracting the central text and emotional features of the current context, the generation of stegotext is constrained. On the basis of information hiding, the consistency between the stegotext and the current context is guaranteed.
Extensive experiments on different models. Compared with the mainstream advanced algorithms in recent years, the framework proposed in this paper has significantly improved in all aspects, indicating that the framework has better performance in text quality, concealment and security.
The rest of this paper involves the following parts:
Section 2 introduces representative text steganography.
Section 3 presents the background of text steganography.
Section 4 describes the overall framework and design details of the proposed model in this paper.
Section 5 is indicated the results and analysis through a series of experiments. Finally, the full text is summarized in
Section 6.
2. Related Works
Existing text steganography is mainly divided into three categories [
12]: text modification-based steganography, text search-based steganography and text generation-based steganography.
Steganography based on text modification mainly hides secret information by using text features or modifying content, such as modifying syntactic structure [
13], synonym substitution [
14], and using document redundancy information [
15]. The embedding capacity of this method is small, and the security is not enough. Under the attack of specific steganalysis algorithm, it can hardly hide the existence of secret information [
16]. Steganography based on text search does not modify the text, and selects the information that meets the requirements as the stegotext by constructing a specific text database [
17]. The text generated by this method is directly related to the constructed text database, and the generated content cannot be transformed with the context. Text generation-based steganography uses generation algorithms to automatically generate stegotext, subject to the constraints of secret information and encoding strategies. This method hides secret information in the process of stegotext generation, makes full use of the redundant space of the text, and improves the hiding capacity [
18]. At the same time, with the improvement of the degree of freedom in the process of generating text, the stegotext can be transformed according to the different context, and it is more in line with the natural text [
19], which has become the research focus in the field of text steganography.
According to the different generation algorithms, steganography based on text generation can be divided into three categories: rule-based, Markov model and neural network model [
20]. In the early steganography of development, researchers mainly designed a rule to generate texts under its constraints [
21]. The method is simple to generate, and does not consider the relationship between text sentences, resulting in poor quality of stegotext. In order to solve the problems of single content and insufficient sentence association of stegotext generated by the above methods, Markov model was used as the language model to generate stegotext [
22]. However, due to its own limitations, steganography based on Markov model has a poor dependence on long sequences, resulting in poor stegotext quality and difficulty in avoiding the detection of steganalysis algorithms [
23].
In recent years, with the continuous development of NLP and deep learning (DL), generative text steganography based on neural network models have been proposed. By using the neural network model as the generation model, the hiding capacity, text quality and security of stegotext have been greatly improved [
12]. In this method, the trained language model is used to calculate the candidate words and their corresponding conditional probabilities at each moment, and the stegotext is generated under the constraints of secret information and coding strategy [
24].
Fang et al. [
19] first used a neural network model as a language generator by using a long short-term memory (LSTM) network as a language model. In the process of candidate word selection, the coding strategy of block coding is used to group the candidate words. Then, the corresponding group was selected under the constraint of the secret information and the word with the maximum conditional probability was selected as the output. Yang et al. [
25] used recurrent neural network (RNN) as language models. According to the probability distribution of candidate words, fixed-length coding (FLC) and Huffman coding (HC) are used to encode them, respectively. Finally, the candidate words corresponding to the encoding value are selected according to the secret information until the stegotext is generated. Xiang et al. [
26] proposed a character-level steganography based on LSTM. In the process of text generation, word prediction is changed to character prediction, which improves the hiding capacity of stegotext. Yang et al. [
27] used a generative adversarial network (GAN) to generate stegotext, and at the same time used the reward function as the loss function of the generator, which solved the problem that GAN was difficult to generate discrete data. Zhou et al. [
28] used pseudo-random sampling to obtain the target word and its probability based on GAN. Similar words are obtained through the probability similarity function to form a candidate pool, and then the corresponding candidate words are selected to generate stegotext. In order to improve the language model’s understanding of the relationship between sentence order and semantics of text, a text steganography based on encoder-decoder structure is proposed. Yang et al. [
29] used an RNN-based decoder-encoder. By combining reinforcement learning in the training process and encoding the candidate words with FLC, the stegotext with better semantics is generated. On this basis, Yang et al. [
30] introduced gated recurrent unit and attention mechanism to solve the problem of long-term dependence and improve the fluency and semantic relevance of stegotext. Yang et al. [
31] used variational auto-encoder (VAE) as text generation, LSTM and bidirectional encoder representations from transformers (BERT) as encoders and RNN as decoder, respectively. HC and arithmetic coding (AC) strategies are used to improve the security of the stegotext. To solve the problem that the distribution tends to be diversified due to different sentence semantics, Tu et al. [
32] used two independent VAE to model the topic and sequence of the stream model and the discriminator. By learning the latent content of the topic and combining the sequence knowledge and the learned topic content into the text generation process, semantically consistent high-quality text is generated.
In recent years, pre-trained models have been widely used in the field of text steganography because they can generate high-quality, coherent and more contextual text. Ziegler et al. [
33] used GPT-2 as the language model, while selecting AC in the encoding strategy, and generated texts that were more in line with the statistical language model. Based on GPT-2, Pang et al. [
34] reconstructed softmax by introducing an adjustment factor. It improves the conditional probability of low frequency words, inhibits the conditional probability of high frequency words, avoids text degradation, and improves the quality and security of stegotext. With the breakthrough of Large Language Model (LLM), researchers have applied it to the field of text steganography. LLM has a powerful text generation ability through the training of large-scale text data, which can generate texts with higher readability, semantics and security. Therefore, it gave birth to the emergence of text steganography based on LLM. Wang et al. [
35] used LLM to generate stegotext for the first time. By using LLaMA-2 as the generative model, higher quality texts are generated. Qi et al. [
36] used LLaMA-2 and baichuan-2 as language models for English and Chinese, respectively. By grouping the words with the same prefix relationship in the candidate pool, the random number generator is used to ensure that the sender and the receiver select the same word, which solves the problem of segmentation ambiguity and generates high security text. The comparison of their advantage and disadvantage is shown in
Table 1.
All the above generative text steganography can embed secret information in the stegotext generation process. However, it too pursues the quality of part of the text, ignoring the situation that the generated words deviate from the context semantics in the process of text generation. With the increase of the length of the secret information, the length of the generated text increases, which leads to the generation of semantically confusing text, and the verification affects the security of the stegotext.
6. Conclusions
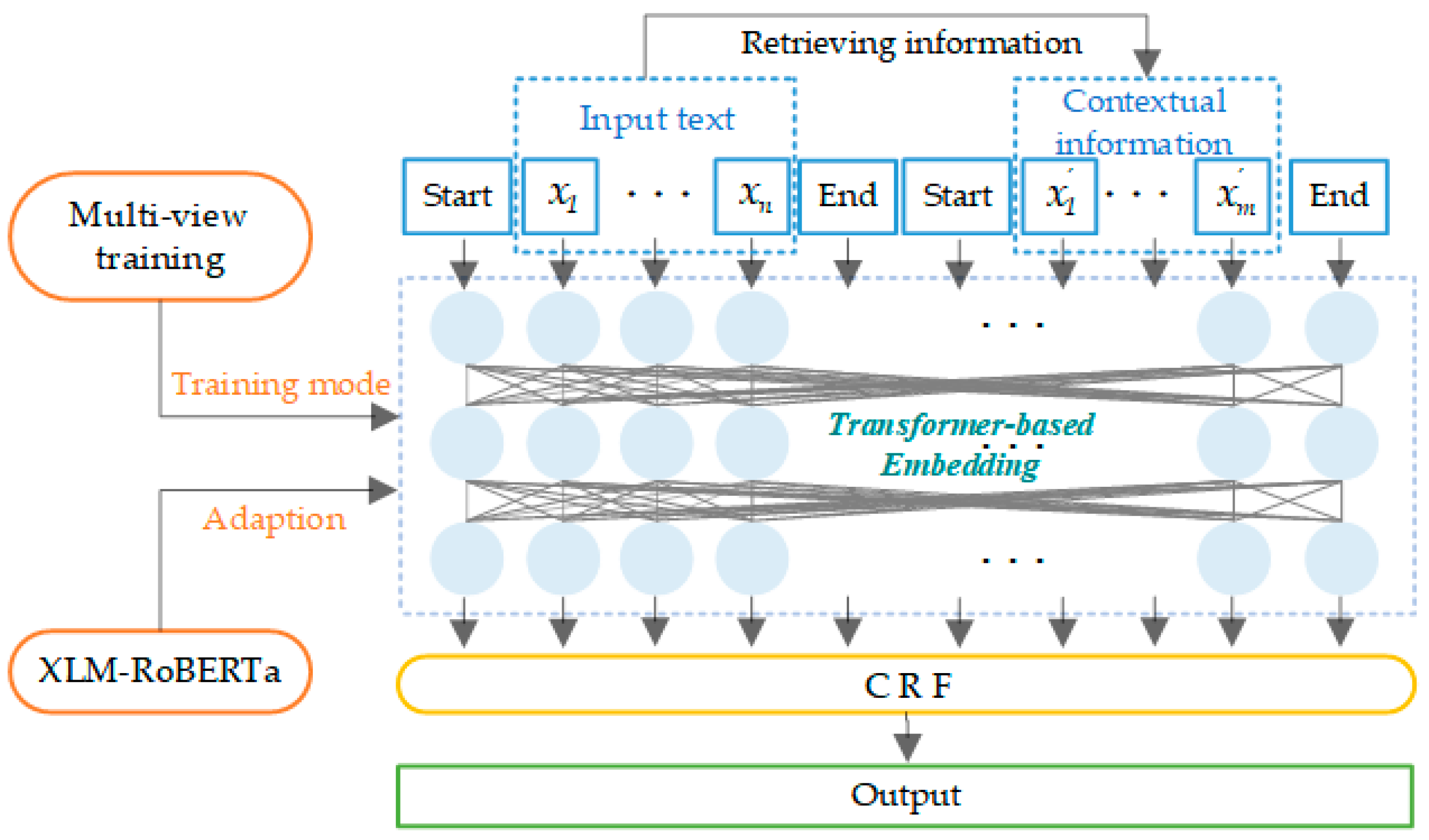
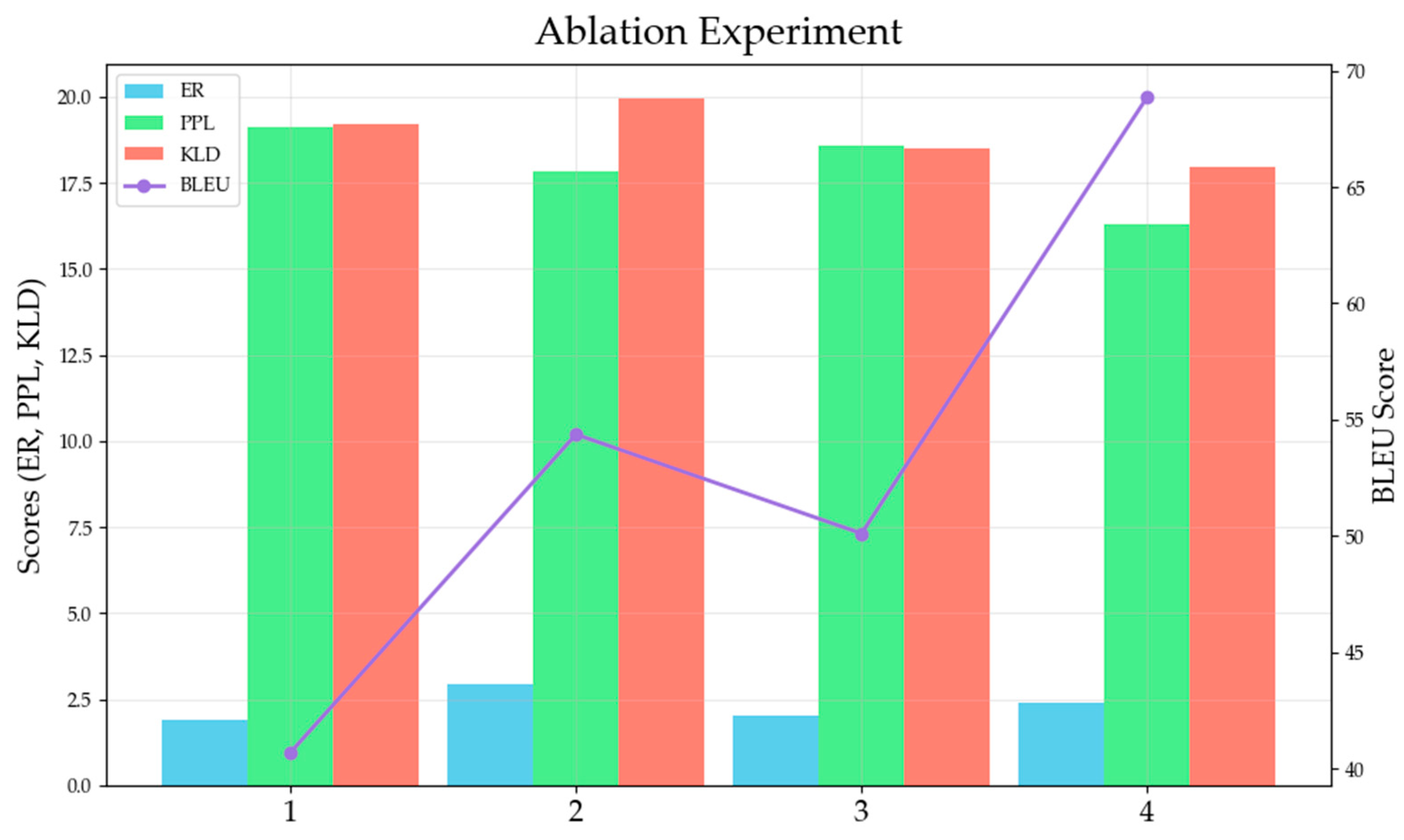
In this paper, we focus on generative text steganography based on LLM and propose an emotionally controllable text steganography based on LLM and named entity. In this method, an entity extraction module composed of RaNER and a sentiment analysis module composed of StructBERT are designed to extract the central text and sentiment features from the current context information respectively. It is then used as the input of the large model, which ensures the controllable generation of stegotext. Compared with the existing mainstream algorithms under the public data set, the results show that the proposed method is effective in hiding capacity, concealment and security. Specifically, the LAMA-3 (3B) model which combines the entity extraction module and the sentiment analysis module has an embedding rate of 2.383 bit per word, a PPL of 16.304, a KLD of 17.952, and a BLEU of 68.864. Ablation experiments show that the entity extraction module and sentiment analysis module designed in this paper can effectively improve the hiding capacity, invisibility and security of stegotext.
Although the proposed method performs better overall, we recognize that there are still challenges with our method. The method currently achieves good performance in terms of semantics, but there are opportunities for improvement in terms of hiding capacity and security. Therefore, in the future research, one is to try to adopt the optimized steganographic coding strategy to improve the hiding capacity of the generated text. Secondly, the relationship between the distribution of real text and the distribution of stegotext can be considered, and the secure transmission of stegotext can be achieved by reducing the statistical gap between them. In addition, LLM itself brings huge computational overhead and has higher requirements for computing hardware. The introduction of entity extraction module and sentiment analysis module further increases the computational overhead. Whether the model can be improved to run on smaller devices becomes another direction for future research.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}