


A Hybrid Model for Fluorescein Funduscopy Image Classification by Fusing Multi-Scale Context-Aware Features

Abstract
1. Introduction
- Our model can classify 23 common retinal lesions, unlike traditional methods that group retinal diseases into a limited number of categories. This type of classification better reflects the complexity and diversity of diseases in clinical practice.
- We proposed the CAFF module to enhance multi-scale feature fusion in FFA images. It fixes a major problem with current methods by effectively capturing both shallow and deep features. This makes it easier to identify lesions and fine details at all scales.
- We proposed the IGC module to enhance global context extraction. By adding IGC, the model can focus better on important areas, which is very important for finding small lesions in FFA images. This approach significantly improves classification accuracy and robustness.
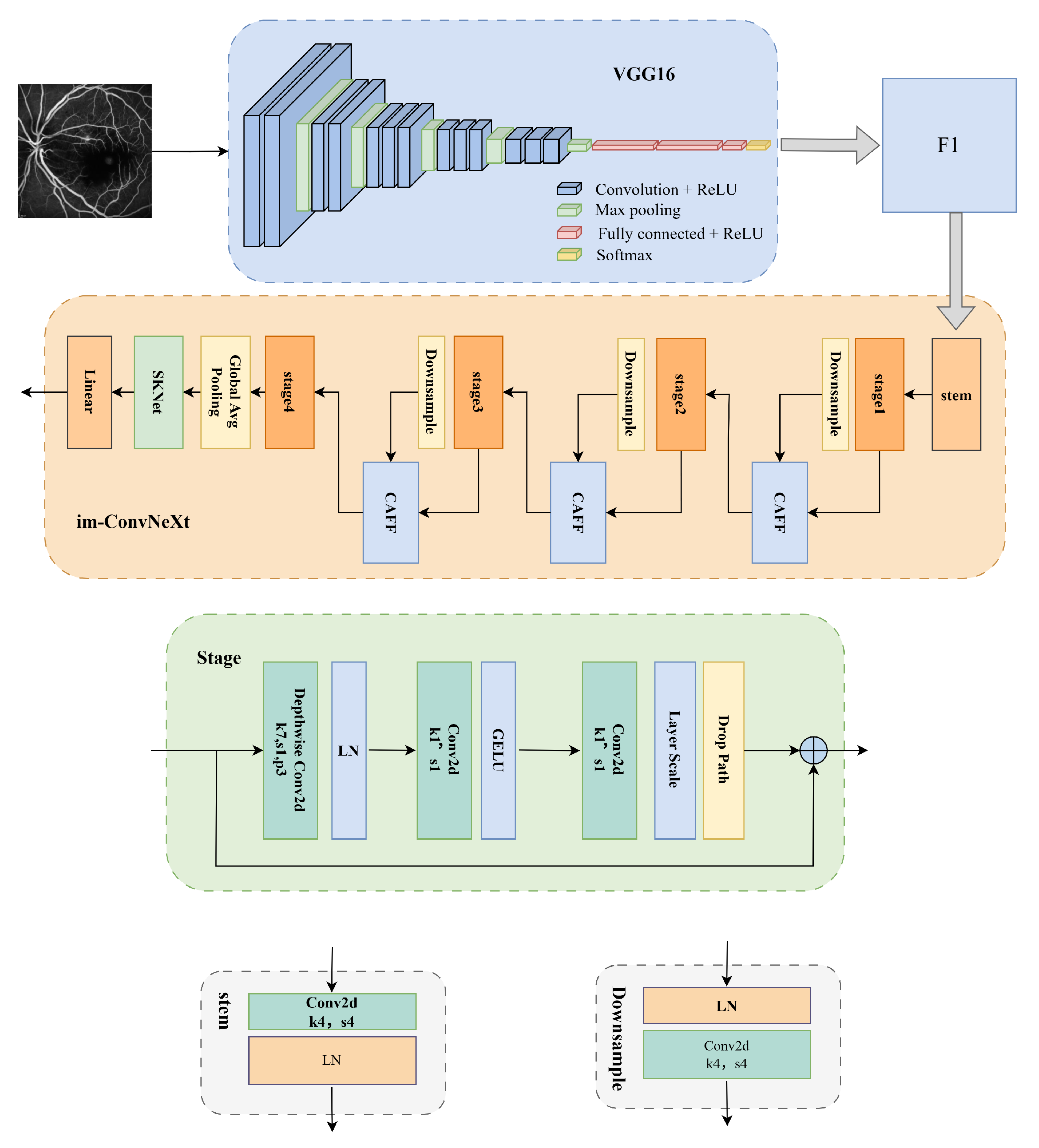
2. Model Architecture Design
2.1. The VGG16 Network
2.2. The Improved ConvNeXt Network
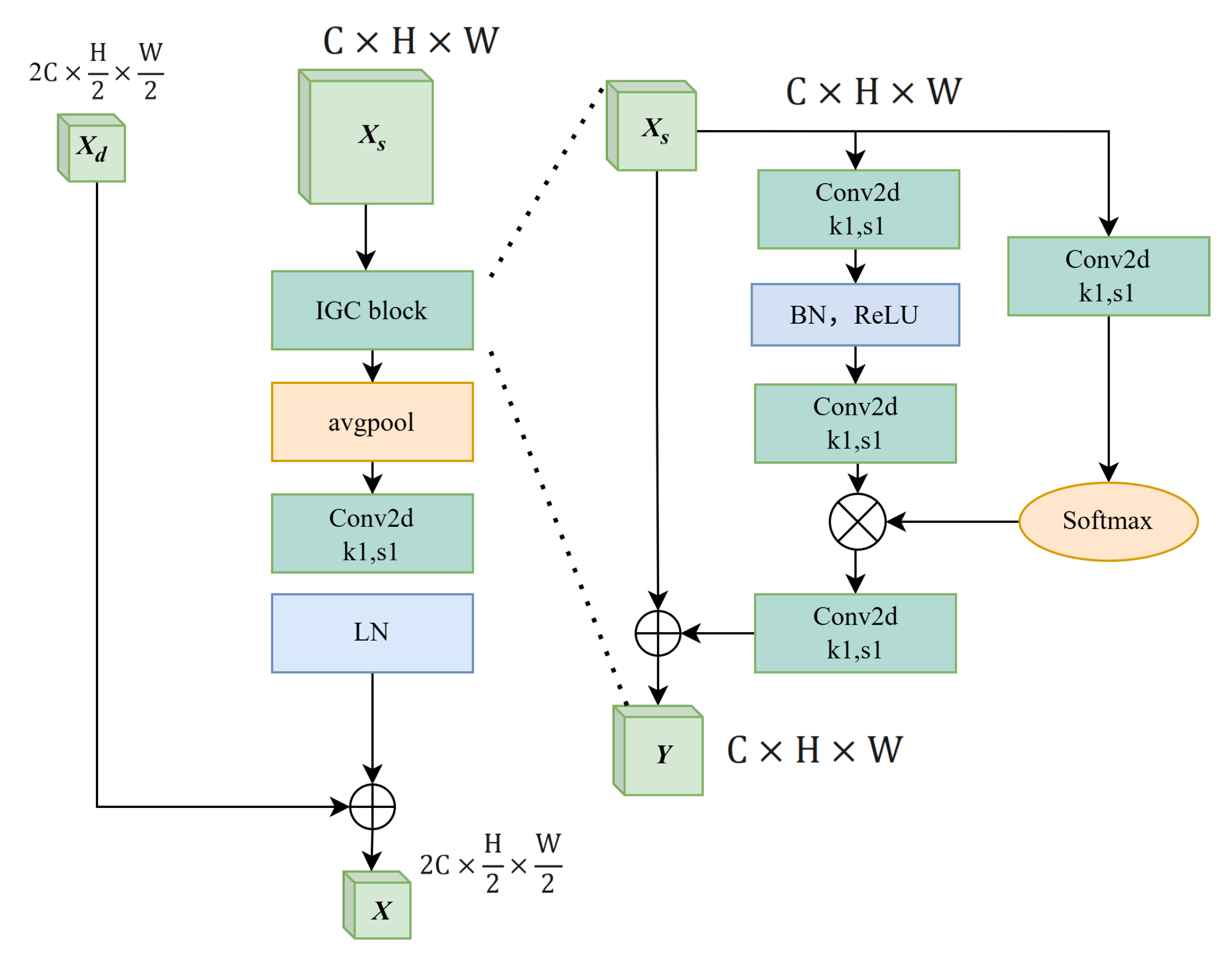
2.2.1. The Context-Aware Feature Fusion Module
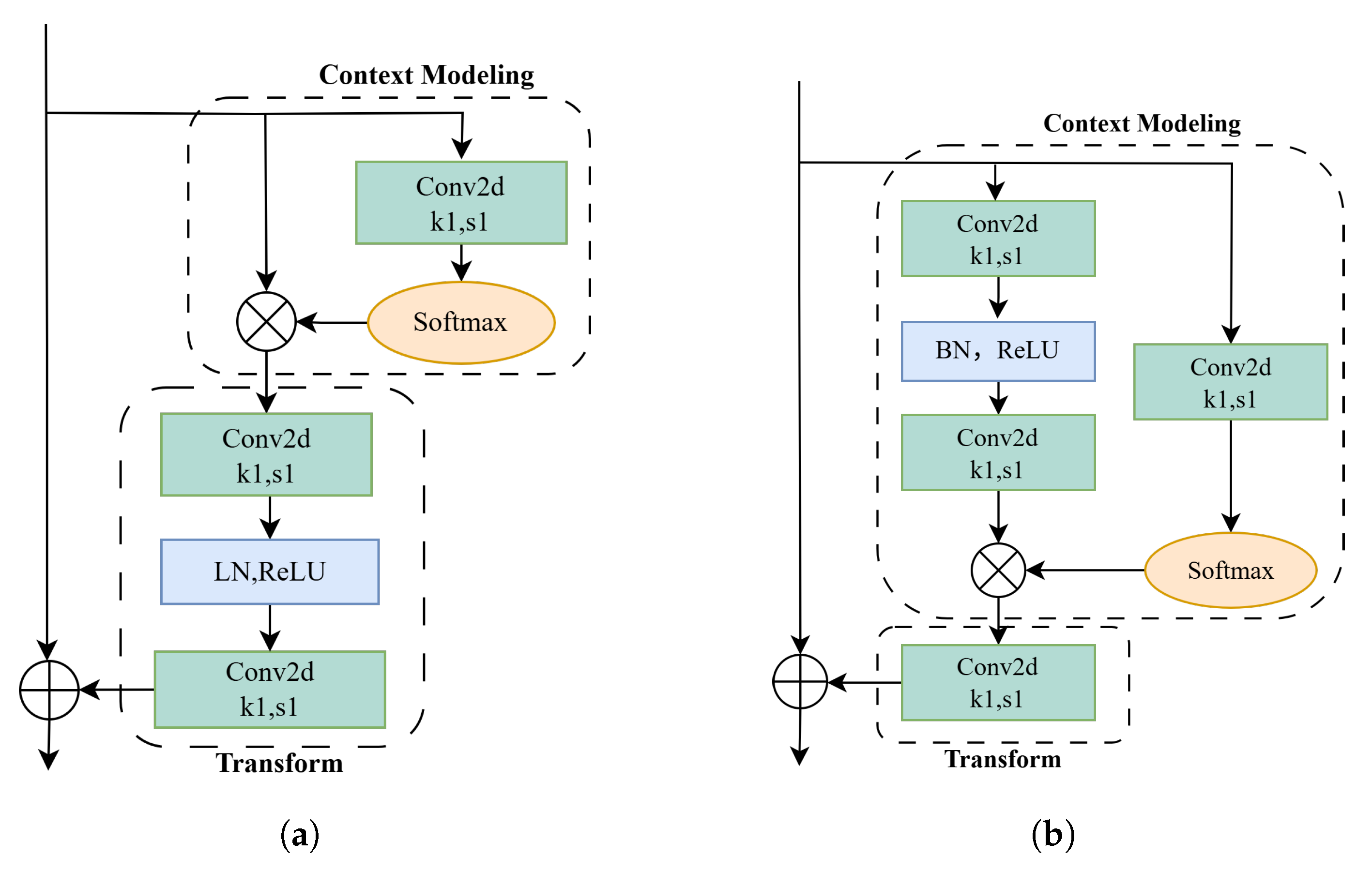
2.2.2. The Improved Global Context Network Module
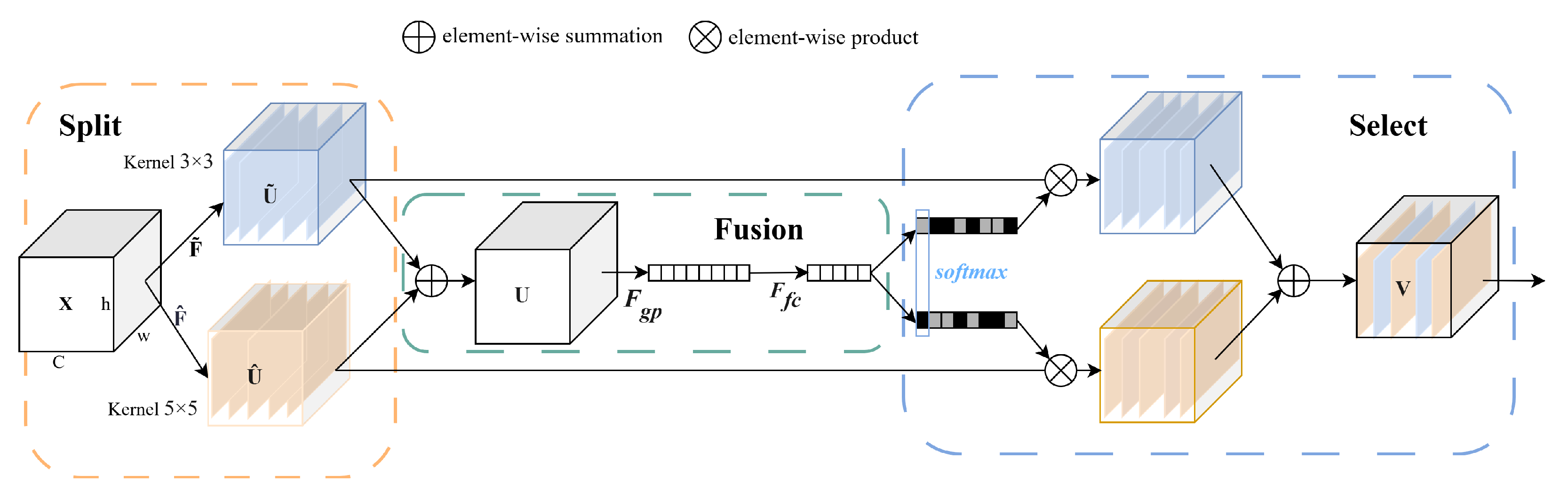
2.2.3. The SKNet Attention Module
2.3. Loss Function Optimization
3. Experimental Results and Analysis
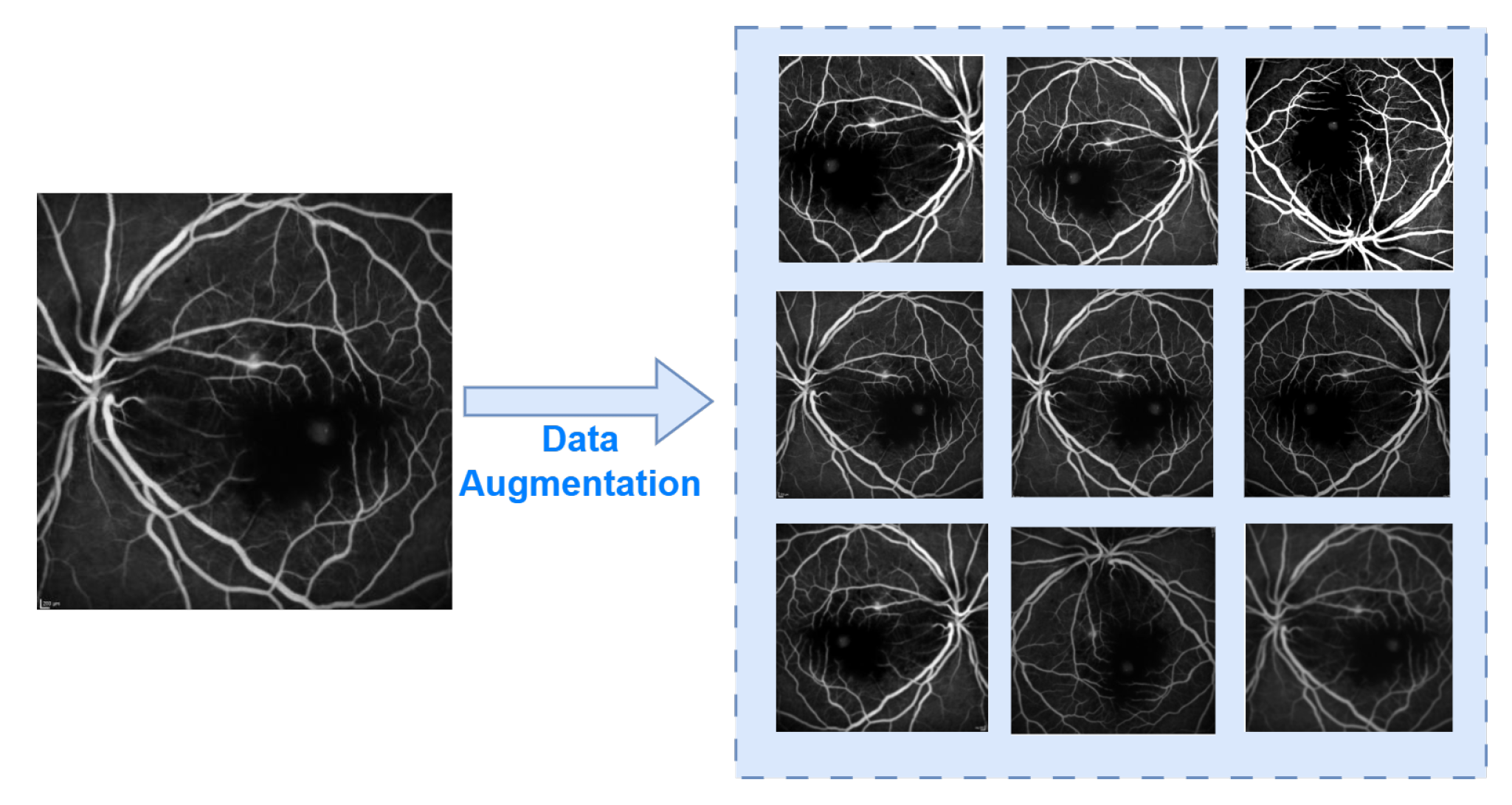
3.1. Dataset and Data Preprocessing
3.2. Implementation Details and Performance Metrics
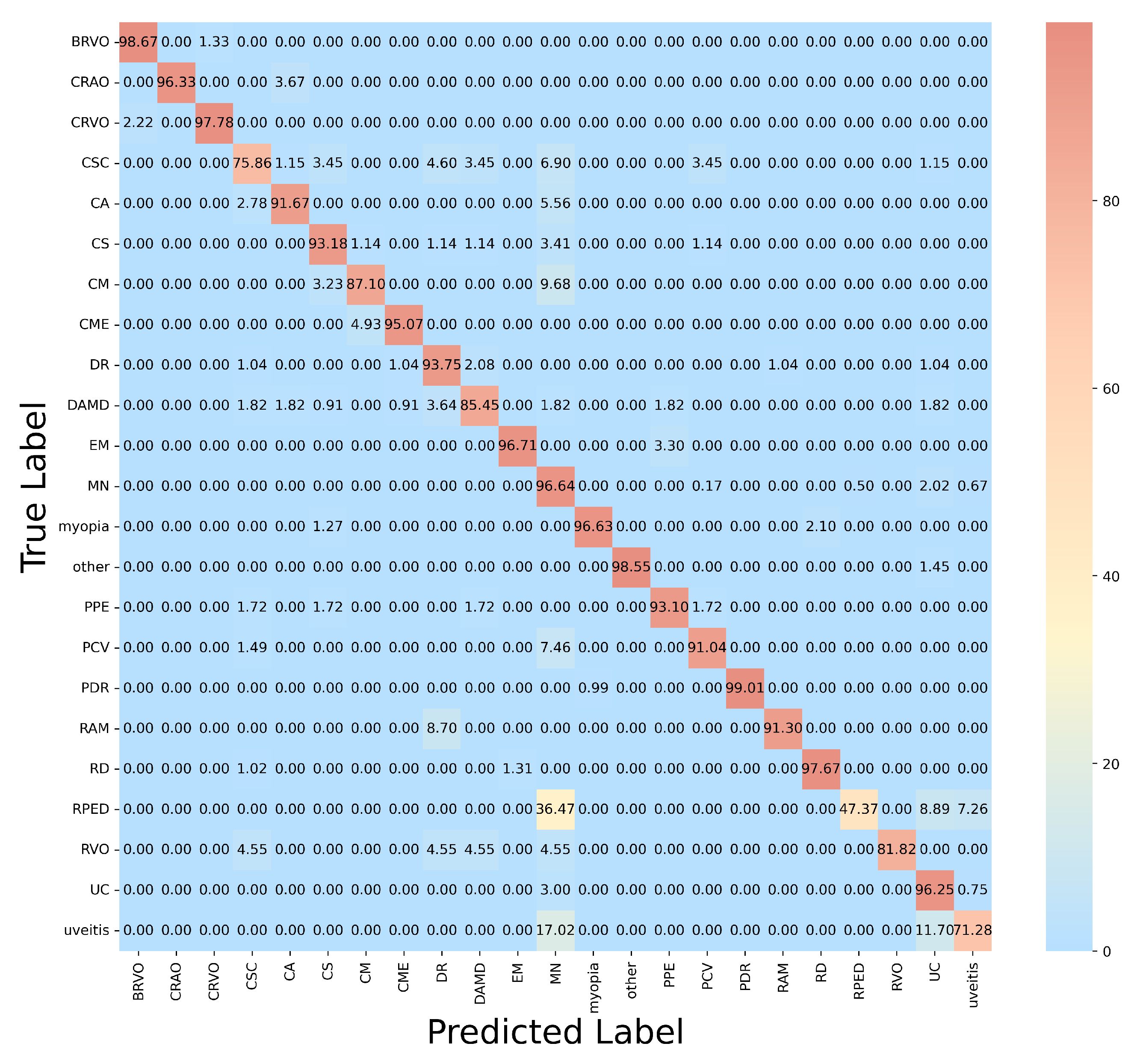
3.3. Experimental Results
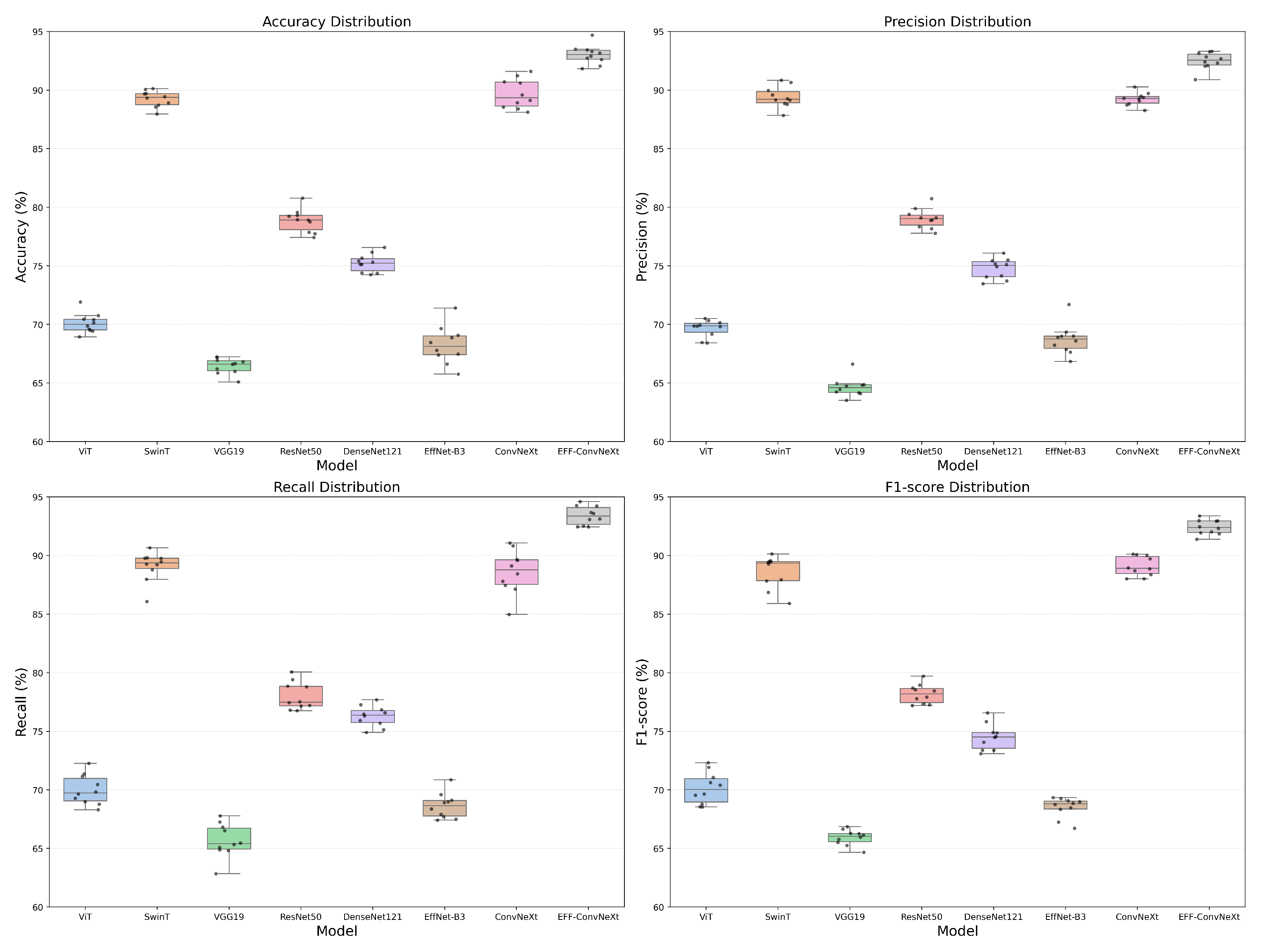
3.3.1. Comparison Between SOTA Baseline Model
3.3.2. Visualization Analysis
3.3.3. Comparison with Different Pretrained Models
3.3.4. Comparison with Previous Attention Mechanisms
3.3.5. Ablation Studies
3.3.6. Comparison with Previous FFA Image Classification Methods
4. Discussion
4.1. Experimental Results and Clinical Relevance
4.2. AI Ethics in Ophthalmology
4.3. Limitations and Future Clinical Applications
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| EFF-ConvNeXt | Enhanced Feature Fusion ConvNeXt |
| FFA | fluorescein fundus angiography |
| CAFF | Context-Aware Feature Fusion |
| IGCNet | Improved Global Context Networks |
| GCNet | Global contextual Networks |
| AMD | age-related macular degeneration |
| AI | Artificial intelligence |
| APTOS | Asia Pacific Tele-Ophthalmology Society |
| im-ConvNeXt | improved ConvNeXt |
| ViT | Vision Transformer |
| SwinT | Swin Transformer |
| NLNet | Non-Local Neural Networks |
| SENet | Squeeze-and-Excitation Networks |
| SKNet | Selective kernel Networks |
| BN | batch normalization |
| LN | layer normalization |
| FL | Focal Loss |
| BRVO | branch retinal vein occlusion |
| CRAO | central retinal artery occlusion |
| CRVO | central retinal vein occlusion |
| CSC | central serous chorioretinopathy |
| CA | chorioretinal atrophy |
| CS | chorioretinal scar |
| CM | choroidal mass |
| CME | cystoid macular edema |
| DR | diabetic retinopathy |
| DAMD | dry age-related macular degeneration |
| EM | epiretinal membrane |
| MN | macular neovascularization |
| PPE | pachychoroid pigment epitheliopathy |
| PCV | polypoidal choroidal vasculopathy |
| PDR | proliferative diabetic retinopathy |
| RAM | retinal arterial macroaneurysm |
| RD | retinal dystrophy |
| RPED | retinal pigment epithelial detachment |
| RVO | retinal vein occlusion |
| UC | unremarkable changes |
| FDA | US Food and Drug Administration |
| MHRA | Medicines and Healthcare products Regulatory Agency |
| GMLP | Good Machine Learning Practice |
| PCCP | Predetermined Change Control Plan |
References
- Wong, W.; Su, X.; Li, X.; Cheung, C.M.G.; Klein, R.; Cheng, C.-Y.; Wong, T.Y. Global prevalence of age-related macular degeneration and disease burden projection for 2020 and 2040: A systematic review and meta-analysis. Lancet Glob. Health 2014, 2, e106–e116. [Google Scholar] [CrossRef]
- Curran, K.; Peto, T.; Jonas, J.B.; Friedman, D.; Kim, J.E. Global estimates on the number of people blind or visually impaired by diabetic retinopathy: A meta-analysis from 2000 to 2020. Eye 2024, 38, 2047–2057. [Google Scholar] [CrossRef]
- Hogarty, D.T.; Mackey, D.A.; Hewitt, A.W. Current state and future prospects of artificial intelligence in ophthalmology: A review. Clin. Exp. Ophthalmol. 2019, 47, 128–139. [Google Scholar] [CrossRef]
- Cheng, Y.; Guo, Q.; Xu, F.J.; Fu, H.; Lin, S.W.; Lin, W. Adversarial exposure attack on diabetic retinopathy imagery grading. IEEE J. Biomed. Health Inform. 2025, 29, 297–309. [Google Scholar] [CrossRef] [PubMed]
- Ji, Z.; Ma, X.; Leng, T.L.; Rubin, D.L.; Chen, Q. Mirrored X-Net: Joint classification and contrastive learning for weakly supervised GA segmentation in SD-OCT. Pattern Recognit. 2024, 153, 110507. [Google Scholar] [CrossRef]
- Alwakid, G.; Gouda, W.; Humayun, M.; Jhanjhi, N.Z. Deep learning-enhanced diabetic retinopathy image classification. Digit. Health 2023, 9, 20552076231194942. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Wang, Z.; Chen, Y.; Zhu, C.; Xiong, M.; Bai, H.X. A Transformer utilizing bidirectional cross-attention for multi-modal classification of Age-Related Macular Degeneration. Biomed. Signal Process. Control 2025, 109, 107887. [Google Scholar] [CrossRef]
- Das, D.; Nayak, D.R.; Pachori, R.B. AES-Net: An adapter and enhanced self-attention guided network for multi-stage glaucoma classification using fundus images. Image Vis. Comput. 2024, 146, 105042. [Google Scholar] [CrossRef]
- Xu, Q.; Zhang, J.; Qin, T.; Bao, J.; Dong, H.; Zhou, X.; Hou, S.; Mao, L. The role of the inflammasomes in the pathogenesis of uveitis. Exp. Eye Res. 2021, 208, 108618. [Google Scholar] [CrossRef]
- Wildner, G.; Diedrichs-Mhring, M. Resolution of uveitis. Semin. Immunopathol. 2019, 41, 727–736. [Google Scholar] [CrossRef]
- Li, Z.; Xu, M.; Yang, X.; Han, Y. Multi-label fundus image classification using attention mechanisms and feature fusion. Micromachines 2022, 13, 947. [Google Scholar] [CrossRef]
- Yan, Y.; Yang, L.; Huang, W. Fundus-DANet: Dilated convolution and fusion attention mechanism for multilabel retinal fundus image classification. Appl. Sci. 2024, 14, 8446. [Google Scholar] [CrossRef]
- Kwiterovich, K.A.; Maguire, M.G.; Murphy, R.P.; Schachat, A.P.; Bressler, N.M.; Bressler, S.B.; Fine, S.L. Frequency of adverse systemic reactions after fluorescein angiography: Results of a prospective study. Ophthalmology 1991, 98, 1139–1142. [Google Scholar] [CrossRef] [PubMed]
- Cole, E.D.; Novais, E.A.; Louzada, R.N.; Waheed, N.K. Contemporary retinal imaging techniques in diabetic retinopathy: A review. Clin. Exp. Ophthalmol. 2016, 44, 289–299. [Google Scholar] [CrossRef] [PubMed]
- Pan, X.; Jin, K.; Cao, J.; Liu, Z.; Wu, J.; You, K.; Lu, Y.; Xu, Y.; Su, Z.; Jiang, J.; et al. Multi-label classification of retinal lesions in diabetic retinopathy for automatic analysis of fundus fluorescein angiography based on deep learning. Graefes Arch. Clin. Exp. Ophthalmol. 2020, 258, 779–785. [Google Scholar] [CrossRef]
- Gao, Z.; Pan, X.; Shao, J.; Jiang, X.; Su, Z.; Jin, K.; Ye, J. Automatic interpretation and clinical evaluation for fundus fluorescein angiography images of diabetic retinopathy patients by deep learning. Br. J. Ophthalmol. 2023, 107, 1852–1858. [Google Scholar] [CrossRef]
- Gao, Z.; Jin, K.; Yan, Y.; Liu, X.; Shi, Y.; Ge, Y.; Pan, X.; Lu, Y.; Wu, J.; Wang, Y.; et al. End-to-end diabetic retinopathy grading based on fundus fluorescein angiography images using deep learning. Graefes Arch. Clin. Exp. Ophthalmol. 2022, 260, 1663–1673. [Google Scholar] [CrossRef]
- Veena, K.M.; Tummala, V.; Sangaraju, Y.S.V.; Reddy, M.S.V.; Kumar, P.; Mayya, V.; Kulkarni, U.; Bhandary, S.; Shailaja, S. FFA-Lens: Lesion detection tool for chronic ocular diseases in Fluorescein angiography images. SoftwareX 2024, 26, 101646. [Google Scholar] [CrossRef]
- Lyu, J.; Yan, S.; Hossain, M.S. DBGAN: Dual branch generative adversarial network for multi-modal MRI translation. ACM Trans. Multimed. Comput. Commun. Appl. 2024, 20, 235. [Google Scholar] [CrossRef]
- Palaniappan, K.; Bunyak, F.; Chaurasia, S.S. Image analysis for ophthalmology: Segmentation and quantification of retinal vascular systems. In Ocular Fluid Dynamics: Anatomy, Physiology, Imaging Techniques, and Mathematical Modeling; Springer: Berlin/Heidelberg, Germany, 2019; pp. 543–580. [Google Scholar]
- Shili, W.; Yongkun, G.; Chao, Q.; Ying, L.; Xinyou, Z. Global attention and context encoding for enhanced medical image segmentation. Vis. Comput. 2025, 41, 7781–7798. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Liu, Z.; Mao, H.; Wu, C.-Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A ConvNet for the 2020s. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11976–11986. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 9992–10002. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. MobileNetV2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar] [CrossRef]
- Cao, Y.; Xu, J.; Lin, S.; Wei, F.; Hu, H. GCNet: Non-local networks meet squeeze-excitation networks and beyond. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar] [CrossRef]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar] [CrossRef]
- Gu, A.; Dao, T. Mamba: Linear-time sequence modeling with selective state spaces. arXiv 2023, arXiv:2312.00752. [Google Scholar] [CrossRef]
- Li, X.; Wang, W.; Hu, X.; Yang, J. Selective kernel networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 510–519. [Google Scholar] [CrossRef]
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef] [PubMed]
- Chattopadhay, A.; Sarkar, A.; Howlader, P.; Balasubramanian, V.N. Grad-CAM++: Generalized gradient-based visual explanations for deep convolutional networks. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision, Lake Tahoe, NV, USA, 12–15 March 2018; pp. 839–847. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11531–11539. [Google Scholar]
- Zhu, B.; Hofstee, P.; Lee, J.; Al-Ars, Z. An Attention Module for Convolutional Neural Networks. In Proceedings of the Artificial Neural Networks and Machine Learning–ICANN 2021: 30th International Conference, Bratislava, Slovakia, 14–17 September 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 167–178. [Google Scholar] [CrossRef]
- Panahi, O. Deep Learning in Diagnostics. J. Med. Discov. 2025, 2, 1–6. [Google Scholar]
- Piccialli, F.; Di Somma, V.; Giampaolo, F.; Cuomo, S.; Fortino, G. A survey on deep learning in medicine: Why, how and when? Inf. Fusion 2021, 66, 111–137. [Google Scholar] [CrossRef]
- Wang, F.; Casalino, L.P.; Khullar, D. Deep Learning in Medicine—Promise, Progress, and Challenges. JAMA Intern. Med. 2019, 179, 293–294. [Google Scholar] [CrossRef]
- Goktas, P.; Grzybowski, A. Shaping the Future of Healthcare: Ethical Clinical Challenges and Pathways to Trustworthy AI. J. Clin. Med. 2025, 14, 1605. [Google Scholar] [CrossRef] [PubMed]
- U.S. Food and Drug Administration; Health Canada; MHRA. Good Machine Learning Practice for Medical Device Development: Guiding Principles. U.S. Food and Drug Administration. 2021. Available online: https://www.fda.gov/media/153486/download (accessed on 3 July 2025).
- U.S. Food and Drug Administration. Marketing Submission Recommendations for a Predetermined Change Control Plan for Artificial Intelligence/Machine Learning (AI/ML)-Enabled Device Software Functions. U.S. Food and Drug Administration. 2024. Available online: https://www.fda.gov/media/174698/download (accessed on 3 July 2025).
- Liu, X.; Rivera, S.C.; Moher, D.; Calvert, M.J.; Denniston, A.K. Reporting guidelines for clinical trial reports for interventions involving artificial intelligence: The CONSORT-AI extension. Nat. Med. 2020, 26, 1364–1374. [Google Scholar] [CrossRef]
- Martindale, A.P.L.; Llewellyn, C.D.; de Visser, R.O.; Dodhia, H.; Watkinson, P.J.; Clifton, D.A. Concordance of randomised controlled trials for artificial intelligence interventions with the CONSORT-AI reporting guidelines. Nat. Commun. 2024, 15, 1619. [Google Scholar] [CrossRef] [PubMed]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Rate | Category | Rate | Category | Rate |
|---|---|---|---|---|---|
| BRVO | 10 | DR | 8 | PCV | 6 |
| CRAO | 10 | DAMD | 7 | PDR | 10 |
| CRVO | 10 | EM | 10 | RD | 10 |
| CSC | 3 | EM | 10 | RPED | 8 |
| CA | 10 | MN | 1 | ROV | 10 |
| CS | 8 | myopia | 10 | UC | 5 |
| CM | 10 | other | 10 | uveitis | 6 |
| CME | 10 | PPE | 10 |
| Model | Average (%) | Average (%) | Average (%) | Average (%) | Inference Time (t/s) |
|---|---|---|---|---|---|
| ViT | 70.15 | 70.06 | 70.37 | 70.18 | 0.004 |
| SwinT | 89.36 | 89.43 | 89.36 | 88.29 | 0.004 |
| VGG19 | 66.86 | 64.52 | 65.33 | 65.98 | 0.003 |
| ResNet50 | 78.64 | 78.65 | 78.52 | 78.39 | 0.003 |
| DenseNet121 | 75.41 | 74.81 | 76.24 | 74.12 | 0.004 |
| EffcientNet-B3 | 68.40 | 68.43 | 68.29 | 68.26 | 0.005 |
| ConvNeXt | 89.38 | 89.36 | 89.03 | 89.30 | 0.005 |
| EFF-ConvNeXt | 92.50 | 92.46 | 92.56 | 92.30 | 0.007 |
| Lesion Category | (%) | (%) | (%) | (%) |
|---|---|---|---|---|
| BRVO | 98.02 | 97.79 | 98.67 | 98.23 |
| CRAO | 96.98 | 95.66 | 96.33 | 95.99 |
| CRVO | 97.33 | 97.58 | 97.78 | 97.68 |
| CSC | 75.86 | 78.19 | 75.86 | 77.01 |
| CA | 94.44 | 93.67 | 91.67 | 92.66 |
| CS | 90.91 | 93.10 | 93.18 | 93.14 |
| CM | 86.56 | 86.15 | 87.10 | 86.62 |
| CME | 96.72 | 97.86 | 95.07 | 96.45 |
| DR | 93.54 | 94.91 | 93.75 | 94.32 |
| DAMD | 86.72 | 92.16 | 85.45 | 88.68 |
| EM | 98.79 | 89.79 | 96.70 | 93.11 |
| MN | 95.33 | 97.98 | 96.64 | 97.30 |
| myopia | 95.82 | 94.66 | 96.63 | 95.63 |
| other | 98.33 | 97.98 | 98.55 | 98.26 |
| PPE | 94.67 | 96.43 | 93.10 | 94.74 |
| PCV | 92.33 | 91.04 | 91.04 | 91.04 |
| PDR | 99.59 | 99.24 | 99.01 | 99.12 |
| RAM | 91.83 | 91.45 | 91.30 | 91.37 |
| RD | 97.90 | 97.67 | 97.67 | 97.67 |
| RPED | 48.72 | 47.67 | 47.37 | 47.52 |
| RVO | 81.82 | 82.08 | 81.82 | 81.95 |
| UC | 95.67 | 97.23 | 96.25 | 96.74 |
| uveitis | 73.08 | 72.57 | 71.28 | 71.92 |
| Model | Average (%) | Average (%) | Average (%) | Average (%) | Inference Time (t/s) |
|---|---|---|---|---|---|
| im-ConvNeXt | 92.03 | 92.05 | 92.13 | 92.37 | 0.005 |
| SwinT | 89.36 | 89.43 | 89.36 | 88.29 | 0.004 |
| swinT+im-ConvNeXt | 91.78 | 91.86 | 91.77 | 92.02 | 0.008 |
| ResNet50 | 78.64 | 78.65 | 78.52 | 78.39 | 0.003 |
| ResNet50+im-ConvNeXt | 92.12 | 91.08 | 91.68 | 92.18 | 0.007 |
| VGG16 | 63.91 | 64.12 | 63.93 | 63.98 | 0.003 |
| VGG16+im-ConvNeXt (ours) | 92.50 | 92.46 | 92.56 | 92.30 | 0.007 |
| Model | Average (%) | Average (%) | Average (%) | Average (%) | Inference Time (t/s) |
|---|---|---|---|---|---|
| baseline | 90.96 | 90.95 | 91.10 | 90.93 | 0.005 |
| +CBAM [35] | 87.83 | 87.86 | 87.65 | 87.12 | 0.005 |
| +ECA [36] | 91.84 | 91.98 | 91.80 | 91.91 | 0.005 |
| +SimAM [37] | 91.06 | 91.05 | 91.06 | 91.18 | 0.005 |
| +SE [29] | 91.56 | 91.24 | 91.43 | 91.23 | 0.005 |
| +GC [27] | 89.43 | 89.36 | 89.48 | 89.46 | 0.005 |
| +IGC | 92.50 | 92.46 | 92.56 | 92.30 | 0.005 |
| Type | Configuration | VGG16 | CAFF | SKNet | Loss Opt. | Average (%) | Average (%) | Average (%) | Average (%) | Inference Time (t/s) |
|---|---|---|---|---|---|---|---|---|---|---|
| Additive | Baseline | 89.38 | 89.36 | 89.03 | 89.30 | 0.005 | ||||
| + VGG16 | ✓ | 90.10 | 90.36 | 89.68 | 90.16 | 0.006 | ||||
| + VGG16 + CAFF | ✓ | ✓ | 91.81 | 91.80 | 91.26 | 91.75 | 0.006 | |||
| + VGG16 + SKNet | ✓ | ✓ | 91.05 | 91.03 | 91.17 | 91.02 | 0.006 | |||
| + VGG16 + Loss Opt. | ✓ | ✓ | 90.96 | 90.86 | 91.10 | 91.98 | 0.006 | |||
| Ablative | − Loss Opt. | ✓ | ✓ | ✓ | 92.05 | 92.19 | 91.97 | 92.03 | 0.007 | |
| − SKNet | ✓ | ✓ | ✓ | 91.81 | 91.82 | 91.68 | 91.78 | 0.006 | ||
| − CAFF | ✓ | ✓ | ✓ | 90.96 | 90.95 | 91.10 | 90.93 | 0.006 | ||
| − VGG16 | ✓ | ✓ | ✓ | 92.03 | 92.05 | 92.13 | 92.37 | 0.006 | ||
| Completed model | ✓ | ✓ | ✓ | ✓ | 92.50 | 92.46 | 92.56 | 92.30 | 0.007 |
| Model | (%) | (%) | (%) | (%) | Recognition Time t/s |
|---|---|---|---|---|---|
| Pan et al. [15] | 76.14 | 76.18 | 76.38 | 76.21 | 0.004 |
| Gao et al. [17] | 63.91 | 64.12 | 63.93 | 63.98 | 0.004 |
| Gao et al. [16] | 74.57 | 74.75 | 75.25 | 73.98 | 0.003 |
| FFA-lens [18] | 88.53 | 88.38 | 87.63 | 87.88 | 0.008 |
| EFF-ConvNeXt | 92.50 | 92.46 | 92.56 | 92.30 | 0.007 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Chen, C.; Chen, Z.; Wu, L. A Hybrid Model for Fluorescein Funduscopy Image Classification by Fusing Multi-Scale Context-Aware Features. Technologies 2025, 13, 323. https://doi.org/10.3390/technologies13080323
Wang Y, Chen C, Chen Z, Wu L. A Hybrid Model for Fluorescein Funduscopy Image Classification by Fusing Multi-Scale Context-Aware Features. Technologies. 2025; 13(8):323. https://doi.org/10.3390/technologies13080323
Chicago/Turabian StyleWang, Yawen, Chao Chen, Zhuo Chen, and Lingling Wu. 2025. "A Hybrid Model for Fluorescein Funduscopy Image Classification by Fusing Multi-Scale Context-Aware Features" Technologies 13, no. 8: 323. https://doi.org/10.3390/technologies13080323
APA StyleWang, Y., Chen, C., Chen, Z., & Wu, L. (2025). A Hybrid Model for Fluorescein Funduscopy Image Classification by Fusing Multi-Scale Context-Aware Features. Technologies, 13(8), 323. https://doi.org/10.3390/technologies13080323