

Transforming Neural Networks into Quantum-Cognitive Models: A Research Tutorial with Novel Applications



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
1.1. Quantum Neural Networks
1.2. Neuromorphic Computing
1.3. Objectives of This Tutorial
1.4. Organisation of the Article
2. Motivation
2.1. General Background
2.2. Menneer–Narayanan Quantum-Theoretic Concept
3. Quantum Tunnelling Effect
3.1. Theory
3.2. Practical Applications of Quantum Tunnelling
3.3. The Relationship Between QT and Menneer–Narayanan Quantum-Theoretic Concept
4. Benchmarking Neural Network Models
4.1. Feedforward Neural Networks
4.2. Recurrent Neural Networks
4.3. Bayesian Neural Networks
4.4. Echo State Networks and Reservoir Computing
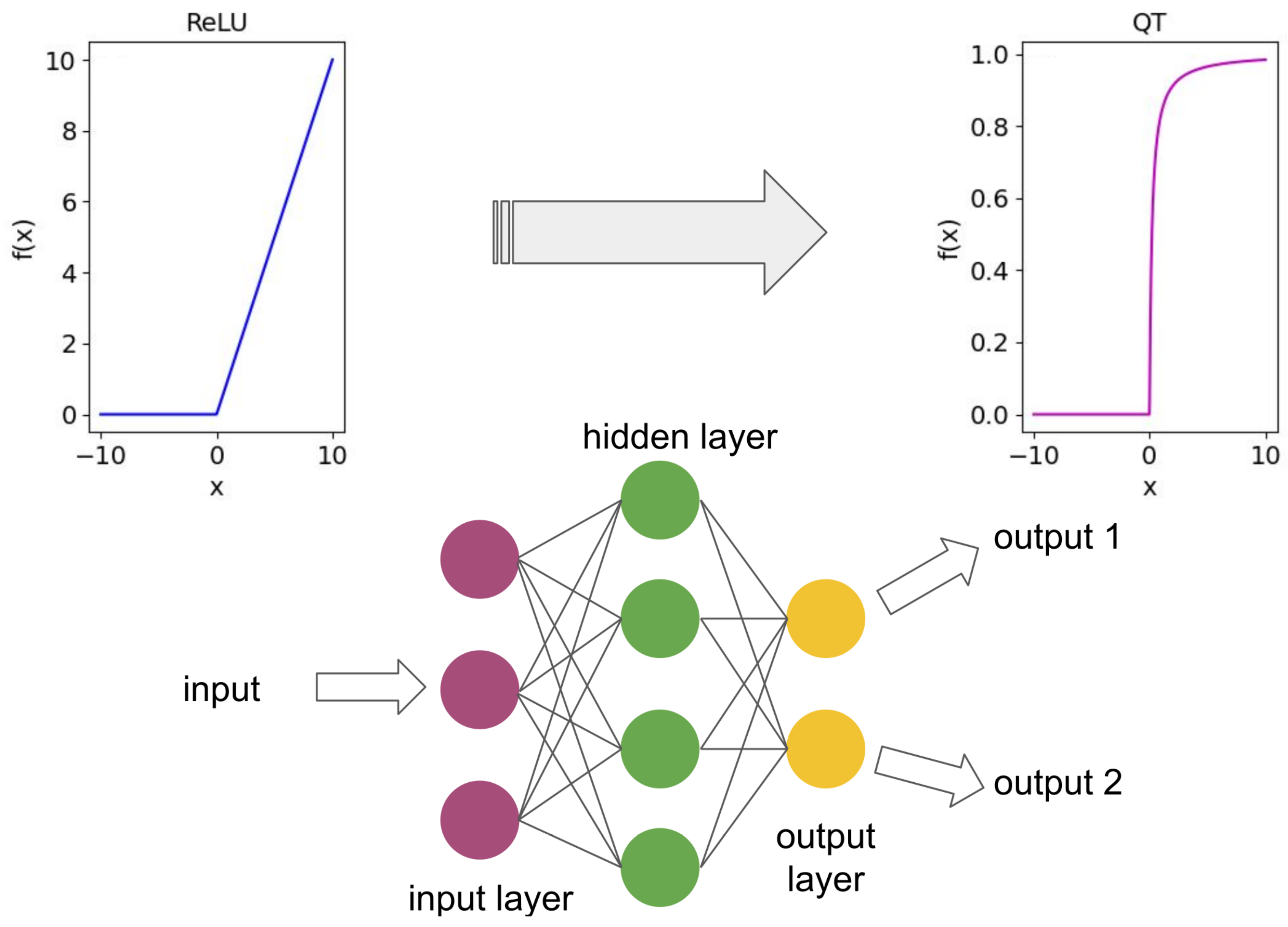
4.5. From Classical to Quantum: Transforming Computational Models
5. Results and Discussion
5.1. QT-Feedforward Neural Network
5.2. QT-RNN for a Sentiment Analysis Task
5.3. QT-Bayesian Neural Network
5.4. QT-ESN and Mackey–Glass Time Series Forecast Task
6. Potential Applications of QT-Based Models in Neuromorphic and Cognitive AI
Cognitive Human–Machine Teaming
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| BNN | Bayesian Neural Network |
| BPTT | Backpropagation Through Time |
| CNN | Convolutional Neural Network |
| ESN | Echo State Network |
| FNN | Feedforward Neural Network |
| MGTS | Mackey–Glass Time Series |
| ML | Machine Learning |
| MNIST | Modified National Institute of Standards and Technology database |
| NC | Neuromorphic Computing |
| QT-BNN | Quantum-Tunnelling Bayesian Neural Network |
| QT-ESN | Quantum-Tunnelling Echo State Network |
| QT-FNN | Quantum-Tunnelling Feedforward Neural Network |
| QT-RNN | Quantum-Tunnelling Recurrent Neural Network |
| QCT | Quantum Cognition Theory |
| QNN | Quantum Neural Network |
| QT | Quantum Tunnelling |
| RNN | Recurrent Neural Network |
| ReLU | Rectified Linear Qnit |
| STM | Scanning Tunnelling Microscopy |
References
- LeCun, Y. Security Council Debates Use of Artificial Intelligence in Conflicts, Hears Calls for UN Framework to Avoid Fragmented Governance. Video Presentation. 2024. Available online: https://press.un.org/en/2024/sc15946.doc.htm (accessed on 4 January 2025).
- Gunashekar, S.; d’Angelo, C.; Flanagan, I.; Motsi-Omoijiade, D.; Virdee, M.; Feijao, C.; Porter, S. Using Quantum Computers and Simulators in the Life Sciences: Current Trends and Future Prospects; RAND Corporation: Santa Monica, CA USA, 2022. [Google Scholar] [CrossRef]
- Gerlich, M. Perceptions and acceptance of artificial intelligence: A multi-dimensional study. Soc. Sci. 2023, 12, 502. [Google Scholar] [CrossRef]
- Walker, P.B.; Haase, J.J.; Mehalick, M.L.; Steele, C.T.; Russell, D.W.; Davidson, I.N. Harnessing metacognition for safe and responsible AI. Technologies 2025, 13, 107. [Google Scholar] [CrossRef]
- Gerlich, M. AI tools in society: Impacts on cognitive offloading and the future of critical thinking. Societies 2025, 15, 6. [Google Scholar] [CrossRef]
- Sourdin, T. Judge v Robot? Artificial intelligence and judicial decision-making. UNSW Law J. 2018, 41, 1114–1130. [Google Scholar] [CrossRef]
- Motsi-Omoijiade, I.D. Financial Intermediation in Cryptocurrency Markets—Regulation, Gaps and Bridges. In Handbook of Blockchain, Digital Finance, and Inclusion, Volume 1; Lee Kuo Chuen, D., Deng, R., Eds.; Academic Press: Cambridge, MA, USA, 2018; pp. 207–223. [Google Scholar] [CrossRef]
- Governatori, G.; Bench-Capon, T.; Verheij, B.; Araszkiewicz, M.; Francesconi, E.; Grabmair, M. Thirty years of artificial intelligence and law: The first decade. Artif. Intell. Law 2022, 30, 481–519. [Google Scholar] [CrossRef]
- Khrennikov, A. Quantum-like brain: “Interference of minds”. Biosystems 2006, 84, 225–241. [Google Scholar] [CrossRef]
- Atmanspacher, H.; Filk, T. A proposed test of temporal nonlocality in bistable perception. J. Math. Psychol. 2010, 54, 314–321. [Google Scholar] [CrossRef]
- Busemeyer, J.R.; Bruza, P.D. Quantum Models of Cognition and Decision; Oxford University Press: New York, NY, USA, 2012. [Google Scholar]
- Pothos, E.M.; Busemeyer, J.R. Quantum Cognition. Annu. Rev. Psychol. 2022, 73, 749–778. [Google Scholar] [CrossRef]
- Maksymov, I.S.; Pogrebna, G. Quantum-mechanical modelling of asymmetric opinion polarisation in social networks. Information 2024, 15, 170. [Google Scholar] [CrossRef]
- Maksymov, I.S.; Pogrebna, G. The physics of preference: Unravelling imprecision of human preferences through magnetisation dynamics. Information 2024, 15, 413. [Google Scholar] [CrossRef]
- Maksymov, I.S. Quantum-inspired neural network model of optical illusions. Algorithms 2024, 17, 30. [Google Scholar] [CrossRef]
- Maksymov, I.S. Quantum-tunneling deep neural network for optical illusion recognition. APL Mach. Learn. 2024, 2, 036107. [Google Scholar] [CrossRef]
- Abbas, A.H.; Abdel-Ghani, H.; Maksymov, I.S. Classical and quantum physical reservoir computing for onboard artificial intelligence systems: A perspective. Dynamics 2024, 4, 643–670. [Google Scholar] [CrossRef]
- Penrose, R. The Emperor’s New Mind; Oxford University Press: Oxford, UK, 1989. [Google Scholar]
- Georgiev, D.D. Quantum Information and Consciousness; CRC Press: Boca Raton, FL, USA, 2019. [Google Scholar]
- Brooks, M. Can quantum hints in the brain revive a radical consciousness theory? New Sci. 2024, 261, 40–43. [Google Scholar] [CrossRef]
- Chrisley, R. Quantum Learning. In New Directions in Cognitive Science, Proceedings of the International Symposium, Saariselkä, Lapland, Finland, 4–9 August 1995; Pylkkänen, P., Pylkkö, P., Eds.; Finnish Association of Artificial Intelligence: Helsinki, Finland, 1995; pp. 77–89. [Google Scholar]
- Kak, S.C. Quantum Neural Computing. In Advances in Imaging and Electron Physics; Elsevier: Amsterdam, The Netherlands, 1995; Volume 94, pp. 259–313. [Google Scholar] [CrossRef]
- Schuld, M.; Sinayskiy, I.; Petruccione, F. The quest for a Quantum Neural Network. Quantum Inf. Process. 2014, 13, 2567–2586. [Google Scholar] [CrossRef]
- Horodecki, R.; Horodecki, P.; Horodecki, M.; Horodecki, K. Quantum Entanglement. Rev. Mod. Phys. 2009, 81, 865–942. [Google Scholar] [CrossRef]
- Chitambar, E.; Gour, G. Quantum resource theories. Rev. Mod. Phys. 2019, 91, 025001. [Google Scholar] [CrossRef]
- Ezhov, A.A.; Ventura, D. Quantum Neural Networks. In Future Directions for Intelligent Systems and Information Sciences; Kasabov, N., Ed.; Physica-Verlag HD: Heidelberg, Germany, 2000; pp. 213–235. [Google Scholar] [CrossRef]
- Wan, K.H.; Dahlsten, O.; Kristjánsson, H.; Gardner, R.; Kim, M.S. Quantum generalisation of feedforward neural networks. Npj Quantum Inf. 2017, 3, 36. [Google Scholar] [CrossRef]
- Beer, K.; Bondarenko, D.; Farrelly, T.; Osborne, T.J.; Salzmann, R.; Scheiermann, D.; Wolf, R. Training deep quantum neural networks. Nat. Commun. 2020, 11, 808. [Google Scholar] [CrossRef]
- Zhao, C.; Gao, X.S. QDNN: Deep neural networks with quantum layers. Quantum Mach. Intell. 2021, 3, 15. [Google Scholar] [CrossRef]
- Hiesmayr, B.C. A quantum information theoretic view on a deep quantum neural network. AIP Conf. Proc. 2024, 3061, 020001. [Google Scholar] [CrossRef]
- Yan, P.; Li, L.; Jin, M.; Zeng, D. Quantum probability-inspired graph neural network for document representation and classification. Neurocomputing 2021, 445, 276–286. [Google Scholar] [CrossRef]
- Pira, L.; Ferrie, C. On the interpretability of quantum neural networks. Quantum Mach. Intell. 2024, 6, 52. [Google Scholar] [CrossRef]
- Peral-García, D.; Cruz-Benito, J.; García-Peñalvo, F.J. Systematic literature review: Quantum machine learning and its applications. Comput. Sci. Rev. 2024, 51, 100619. [Google Scholar] [CrossRef]
- Choi, S.; Salamin, Y.; Roques-Carmes, C.; Dangovski, R.; Luo, D.; Chen, Z.; Horodynski, M.; Sloan, J.; Uddin, S.Z.; Soljačić, M. Photonic probabilistic machine learning using quantum vacuum noise. Nat. Commun. 2024, 15, 7760. [Google Scholar] [CrossRef]
- Lukoševičius, M.; Jaeger, H. Reservoir computing approaches to recurrent neural network training. Comput. Sci. Rev. 2009, 3, 127–149. [Google Scholar] [CrossRef]
- Tanaka, G.; Yamane, T.; Héroux, J.B.; Nakane, R.; Kanazawa, N.; Takeda, S.; Numata, H.; Nakano, D.; Hirose, A. Recent advances in physical reservoir computing: A review. Neural Newt. 2019, 115, 100–123. [Google Scholar] [CrossRef]
- Nakajima, K. Physical reservoir computing–an introductory perspective. Jpn. J. Appl. Phys. 2020, 59, 060501. [Google Scholar] [CrossRef]
- Gauthier, D.J.; Bollt, E.; Griffith, A.; Barbosa, W.A.S. Next generation reservoir computing. Nat. Commun. 2021, 12, 5564. [Google Scholar] [CrossRef]
- Maksymov, I.S. Analogue and physical reservoir computing using water waves: Applications in power engineering and beyond. Energies 2023, 16, 5366. [Google Scholar] [CrossRef]
- Kent, R.M.; Barbosa, W.A.S.; Gauthier, D.J. Controlling chaos using edge computing hardware. Nat. Commun. 2024, 15, 3886. [Google Scholar] [CrossRef]
- Kendon, V.M.; Nemoto, K.; Munro, W.J. Quantum analogue computing. Phil. Trans. R. Soc. A. 2010, 368, 3609–3620. [Google Scholar] [CrossRef]
- Kim, P. MATLAB Deep Learning with Machine Learning, Neural Networks and Artificial Intelligence; Apress: Berkeley, CA, USA, 2017. [Google Scholar]
- Maksimovic, M.; Maksymov, I.S. Quantum-cognitive neural networks: Assessing confidence and uncertainty with human decision-making simulations. Big Data Cogn. Comput. 2025, 9, 12. [Google Scholar] [CrossRef]
- McNaughton, J.; Abbas, A.H.; Maksymov, I.S. Neuromorphic Quantum Neural Networks with Tunnel-Diode Activation Functions. arXiv 2025, arXiv:2503.04978. [Google Scholar]
- Landau, L.D.; Lifshitz, E.M. Mechanics, 3rd ed.; Course of Theoretical Physics; Butterworth-Heinemann: Oxford, UK, 1976; Volume 1. [Google Scholar]
- Messiah, A. Quantum Mechanics; North-Holland Publishing Company: Amsterdam, The Netherlands, 1962. [Google Scholar]
- Griffiths, D.J. Introduction to Quantum Mechanics; Prentice Hall: Englewood Cliffs, NJ, USA, 2004. [Google Scholar]
- Nielsen, M.; Chuang, I. Quantum Computation and Quantum Information; Oxford University Press: New York, NY, USA, 2002. [Google Scholar]
- Feynman, R.P.; Leighton, R.B.; Sands, M. The Feynman Lectures on Physics, Vol. 3: Quantum Mechanics; The New Millennium Edition; Basic Books: New York, NY, USA, 2011. [Google Scholar]
- Schrödinger, E. Die gegenwärtige Situation in der Quantenmechanik. Naturwissenschaften 1935, 23, 807–812. [Google Scholar] [CrossRef]
- Brody, J. Quantum Entanglement: A Beginner’s Guide; MIT Press: Cambridge, MA, USA, 2020. [Google Scholar]
- Menneer, T.; Narayanan, A. Quantum-Inspired Neural Networks; Technical Report 329; Department of Computer Science, University of Exeter: Exeter, UK, 1995. [Google Scholar]
- Narayanan, A.; Menneer, T. Quantum artificial neural network architectures and components. Inf. Sci. 2000, 128, 231–255. [Google Scholar] [CrossRef]
- McQuarrie, D.A.; Simon, J.D. Physical Chemistry—A Molecular Approach; Prentice Hall: New York, NY, USA, 1997. [Google Scholar]
- Esaki, L. New phenomenon in narrow germanium p − n junctions. Phys. Rev. 1958, 109, 603–604. [Google Scholar] [CrossRef]
- Kahng, D.; Sze, S.M. A floating gate and its application to memory devices. Bell Syst. Tech. J. 1967, 46, 1288–1295. [Google Scholar] [CrossRef]
- Chang, L.L.; Esaki, L.; Tsu, R. Resonant tunneling in semiconductor double barriers. Appl. Phys. Lett. 1974, 12, 593–595. [Google Scholar] [CrossRef]
- Ionescu, A.M.; Riel, H. Tunnel field-effect transistors as energy-efficient electronic switches. Nature 2011, 479, 329–337. [Google Scholar] [CrossRef]
- Modinos, A. Field emission spectroscopy. Prog. Surf. Sci. 1993, 42, 45. [Google Scholar] [CrossRef]
- Rahman Laskar, M.A.; Celano, U. Scanning probe microscopy in the age of machine learning. APL Mach. Learn. 2023, 1, 041501. [Google Scholar] [CrossRef]
- Binnig, G.; Rohrer, H. Scanning tunneling microscopy—from birth to adolescence. Rev. Mod. Phys. 1987, 59, 615–625. [Google Scholar] [CrossRef]
- Feng, Y.; Tang, M.; Sun, Z.; Qi, Y.; Zhan, X.; Liu, J.; Zhang, J.; Wu, J.; Chen, J. Fully flash-based reservoir computing network with low power and rich states. IEEE Trans. Electron Devices 2023, 70, 4972–4975. [Google Scholar] [CrossRef]
- Kwon, D.; Woo, S.Y.; Lee, K.H.; Hwang, J.; Kim, H.; Park, S.H.; Shin, W.; Bae, J.H.; Kim, J.J.; Lee, J.H. Reconfigurable neuromorphic computing block through integration of flash synapse arrays and super-steep neurons. Sci. Adv. 2023, 9, eadg9123. [Google Scholar] [CrossRef]
- Yilmaz, Y.; Mazumder, P. Image processing by a programmable grid comprising quantum dots and memristors. IEEE Trans. Nanotechnol. 2013, 12, 879–887. [Google Scholar] [CrossRef]
- Marković, D.; Grollier, J. Quantum neuromorphic computing. Appl. Phys. Lett. 2020, 117, 150501. [Google Scholar] [CrossRef]
- Abel, S.; Chancellor, N.; Spannowsky, M. Quantum computing for quantum tunneling. Phys. Rev. D 2021, 103, 016008. [Google Scholar] [CrossRef]
- Chen, Z.; Xiao, Z.; Akl, M.; Leugring, J.; Olajide, O.; Malik, A.; Dennler, N.; Harper, C.; Bose, S.; Gonzalez, H.A.; et al. ON-OFF neuromorphic ISING machines using Fowler-Nordheim annealers. arXiv 2024, arXiv:2406.05224. [Google Scholar] [CrossRef]
- Georgiev, D.D.; Glazebrook, J.F. The quantum physics of synaptic communication via the SNARE protein complex. Prog. Biophys. Mol. 2018, 135, 16–29. [Google Scholar] [CrossRef]
- Georgiev, D.D.; Glazebrook, J.F. Quantum tunneling of Davydov solitons through massive barriers. Chaos Soliton. Fract. 2019, 123, 275–293. [Google Scholar] [CrossRef]
- Georgiev, D.D.; Glazebrook, J.F. Quantum transport and utilization of free energy in protein α-helices. In Quantum Boundaries of Life; Poznaṅski, R.R., Brändas, E.J., Eds.; Advances in Quantum Chemistry; Academic Press: Cambridge, MA, USA, 2020; Volume 82, pp. 253–300. [Google Scholar]
- Georgiev, D.D. Quantum propensities in the brain cortex and free will. Biosystems 2021, 208, 104474. [Google Scholar] [CrossRef]
- Georgiev, D.D. Causal potency of consciousness in the physical world. Int. J. Mod. Phys. B 2024, 38, 2450256. [Google Scholar] [CrossRef]
- Shor, P.W. Algorithms for quantum computation: Discrete logarithms and factoring. In Proceedings of the 35th Annual Symposium on Foundations of Computer Science, Santa Fe, NM, USA, 20–22 November 1994; pp. 124–134. [Google Scholar] [CrossRef]
- Everett, H.I. The Many-Worlds Interpretation of Quantum Mechanics: The Theory of the Universal Wave Function. PhD Thesis, Princeton University, Princeton, NJ, USA, 1956. [Google Scholar]
- Everett, H. “Relative state” formulation of quantum mechanics. Rev. Mod. Phys. 1957, 29, 454–462. [Google Scholar] [CrossRef]
- Wheeler, J.A. Assessment of Everett’s “relative state” formulation of quantum theory. Rev. Mod. Phys. 1957, 29, 463–465. [Google Scholar] [CrossRef]
- Vaidman, L. Many-Worlds Interpretation of Quantum Mechanics. In The Stanford Encyclopedia of Philosophy; Fall 2021 ed.; Zalta, E.N., Ed.; Metaphysics Research Lab, Stanford University: Standford, CA, USA, 2021. [Google Scholar]
- Khan, A.; Ahsan, M.; Bonyah, E.; Jan, R.; Nisar, M.; Abdel-Aty, A.H.; Yahia, I.S. Numerical solution of Schrödinger equation by Crank–Nicolson method. Math. Probl. Eng. 2022, 2022, 6991067. [Google Scholar] [CrossRef]
- Maksymov, I.S. Quantum Mechanics of Human Perception, Behaviour and Decision-Making: A Do-It-Yourself Model Kit for Modelling Optical Illusions and Opinion Formation in Social Networks. arXiv 2024, arXiv:2404.10554. [Google Scholar]
- Lukoševičius, M. A Practical Guide to Applying Echo State Networks. In Neural Networks: Tricks of the Trade, Reloaded; Montavon, G., Orr, G.B., Müller, K.R., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 659–686. [Google Scholar]
- Haykin, S. Recurrent Neural Networks for Prediction; Wiley: Chichester, UK, 2001. [Google Scholar]
- Jaeger, H. A Tutorial on Training Recurrent Neural Networks, Covering BPPT, RTRL, EKF and the “Echo State Network” Approach; GMD Report 159; German National Research Center for Information Technology: St. Augustin, Schloss Birlinghoven, Germany, 2005. [Google Scholar]
- Jiang, J.; Lai, Y.C. Model-free prediction of spatiotemporal dynamical systems with recurrent neural networks: Role of network spectral radius. Phys. Rev. Res. 2019, 1, 033056. [Google Scholar] [CrossRef]
- Zhang, J.; He, T.; Sra, S.; Jadbabaie, A. Why Gradient Clipping Accelerates Training: A Theoretical Justification for Adaptivity. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 30 April 2020. [Google Scholar]
- Jospin, L.V.; Laga, H.; Boussaid, F.; Buntine, W.; Bennamoun, M. Hands-on Bayesian neural networks–A tutorial for deep learning users. IEEE Comput. Intell. Mag. 2022, 17, 29–48. [Google Scholar] [CrossRef]
- Liu, S.; Xiao, T.P.; Kwon, J.; Debusschere, B.J.; Agarwal, S.; Incorvia, J.A.C.; Bennett, C.H. Bayesian neural networks using magnetic tunnel junction-based probabilistic in-memory computing. Front. Nanotechnol. 2022, 4, 1021943. [Google Scholar] [CrossRef]
- Gawlikowski, J.; Tassi, C.R.N.; Ali, M.; Lee, J.; Humt, M.; Feng, J.; Kruspe, A.; Triebel, R.; Jung, P.; Roscher, R.; et al. A survey of uncertainty in deep neural networks. Artif. Intell. Rev. 2023, 56, 1513–1589. [Google Scholar] [CrossRef]
- Wasilewski, J.; Paterek, T.; Horodecki, K. Uncertainty of feed forward neural networks recognizing quantum contextuality. J. Phys. A: Math. Theor. 2024, 56, 455305. [Google Scholar] [CrossRef]
- McKenna, T.M.; McMullen, T.A.; Shlesinger, M.F. The brain as a dynamic physical system. Neuroscience 1994, 60, 587–605. [Google Scholar] [CrossRef]
- Korn, H.; Faure, P. Is there chaos in the brain? II. Experimental evidence and related models. C. R. Biol. 2003, 326, 787–840. [Google Scholar] [CrossRef]
- Marinca, V.; Herisanu, N. Nonlinear Dynamical Systems in Engineering; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Maass, W.; Natschläger, T.; Markram, H. Real-time computing without stable states: A new framework for neural computation based on perturbations. Neural Comput. 2002, 14, 2531–2560. [Google Scholar] [CrossRef] [PubMed]
- Jaeger, H.; Haas, H. Harnessing nonlinearity: Predicting chaotic systems and saving energy in wireless communication. Science 2004, 304, 78–80. [Google Scholar] [CrossRef]
- Cybenko, G. Approximation by superpositions of a sigmoidal function. Math. Control Signals Syst. 1989, 2, 303–314. [Google Scholar] [CrossRef]
- Haykin, S. Neural Networks: A Comprehensive Foundation; Pearson-Prentice Hall: Singapore, 1998. [Google Scholar]
- Maksymov, I.S.; Greentree, A.D. Coupling light and sound: Giant nonlinearities from oscillating bubbles and droplets. Nanophotonics 2019, 8, 367–390. [Google Scholar] [CrossRef]
- Ramachandran, P.; Zoph, B.; Le, Q.V. Searching for Activation Functions. Available online: https://openreview.net/forum?id=SkBYYyZRZ (accessed on 23 March 2025).
- Hendrycks, D.; Gimpel, K. Bridging Nonlinearities and Stochastic Regularizers with Gaussian Error Linear Units. Available online: https://openreview.net/forum?id=Bk0MRI5lg (accessed on 23 April 2025).
- Lin, T.; Wang, Y.; Liu, X.; Qiu, X. A survey of transformers. AI Open 2022, 3, 111–132. [Google Scholar] [CrossRef]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010; Teh, Y.W., Titterington, M., Eds.; Proceedings of Machine Learning Research. Volume 9, pp. 249–256. [Google Scholar]
- Zhou, V. RNN from Scratch. 2019. Available online: https://github.com/vzhou842/rnn-from-scratch (accessed on 21 February 2025).
- Abbas, A.H.; Maksymov, I.S. Reservoir computing using measurement-controlled quantum dynamics. Electronics 2024, 13, 1164. [Google Scholar] [CrossRef]
- Mackey, M.C.; Glass, L. Oscillation and chaos in physiological control systems. Science 1977, 197, 287–289. [Google Scholar] [CrossRef]
- McNeese, N.J.; Demir, M.; Cooke, N.J.; Myers, C. Teaming with a synthetic teammate: Insights into human-autonomy teaming. Hum. Factors 2018, 60, 262–273. [Google Scholar] [CrossRef]
- Lyons, J.B.; Wynne, K.T.; Mahoney, S.; Roebke, M.A. Trust and Human-Machine Teaming: A Qualitative Study. In Artificial Intelligence for the Internet of Everything; Lawless, W., Mittu, R., Sofge, D., Moskowitz, I.S., Russell, S., Eds.; Academic Press: Cambridge, MA, USA, 2019; pp. 101–116. [Google Scholar] [CrossRef]
- Henry, K.E.; Kornfield, R.; Sridharan, A.; Linton, R.C.; Groh, C.; Wang, T.; Wu, A.; Mutlu, B.; Saria, S. Human–machine teaming is key to AI adoption: Clinicians’ experiences with a deployed machine learning system. Npj Digit. Med. 2022, 5, 97. [Google Scholar] [CrossRef]
- Greenberg, A.M.; Marble, J.L. Foundational concepts in person-machine teaming. Front. Phys. 2023, 10, 1080132. [Google Scholar] [CrossRef]
- Tzafestas, S.G. Human–Machine Interaction in Automation (I): Basic Concepts and Devices. In Human and Nature Minding Automation: An Overview of Concepts, Methods, Tools and Applications; Springer: Dordrecht, The Netherlands, 2010; pp. 47–60. [Google Scholar] [CrossRef]
- Wu, L.; Zhu, Z.; Cao, H.; Li, B. Influence of information overload on operator’s user experience of human–machine interface in LED manufacturing systems. Cogn. Technol. Work 2016, 18, 161–173. [Google Scholar] [CrossRef]
- Yan, S.; Tran, C.C.; Chen, Y.; Tan, K.; Habiyaremye, J.L. Effect of user interface layout on the operators’ mental workload in emergency operating procedures in nuclear power plants. Nucl. Eng. Des. 2017, 322, 266–276. [Google Scholar] [CrossRef]
- Laurila-Pant, M.; Pihlajamäki, M.; Lanki, A.; Lehikoinen, A. A protocol for analysing the role of shared situational awareness and decision-making in cooperative disaster simulations. J. Disaster Risk Reduct. 2023, 86, 103544. [Google Scholar] [CrossRef]
- Lim, G.J.; Cho, J.; Bora, S.; Biobaku, T.; Parsaei, H. Models and computational algorithms for maritime risk analysis: A review. Ann. Oper. Res. 2018, 271, 765–786. [Google Scholar] [CrossRef]
- Pei, Z.; Rojas-Arevalo, A.M.; de Haan, F.J.; Lipovetzky, N.; Moallemi, E.A. Reinforcement learning for decision-making under deep uncertainty. J. Environ. Manag. 2024, 359, 120968. [Google Scholar] [CrossRef]
- Zhu, D.; Li, Z.; Mishra, A.R. Evaluation of the critical success factors of dynamic enterprise risk management in manufacturing SMEs using an integrated fuzzy decision-making model. Technol. Forecast. Soc. Chang. 2023, 186, 122137. [Google Scholar] [CrossRef]
- Brachten, F.; Brünker, F.; Frick, N.R.; Ross, B.; Stieglitz, S. On the ability of virtual agents to decrease cognitive load: An experimental study. Inf. Syst. E-Bus. Manag. 2020, 18, 187–207. [Google Scholar] [CrossRef]
- Carvalho, A.V.; Chouchene, A.; Lima, T.M.; Charrua-Santos, F. Cognitive manufacturing in Industry 4.0 toward cognitive load reduction: A conceptual framework. Appl. Syst. Innov. 2020, 3, 55. [Google Scholar] [CrossRef]
- McDermott, P.L.; Walker, K.E.; Dominguez, C.O.; Nelson, A.; Kasdaglis, N. Quenching the thirst for human-machine teaming guidance: Helping military systems acquisition leverage cognitive engineering research. In Proceedings of the 13th International Conference on Naturalistic Decision Making, Bath, UK, 20–23 June 2017; Gore, J., Ward, P., Eds.; pp. 236–240. [Google Scholar]
- Madni, A.M.; Madni, C.C. Architectural framework for exploring adaptive human-machine teaming options in simulated dynamic environments. Systems 2018, 6, 44. [Google Scholar] [CrossRef]
- Yearsley, J.M.; Busemeyer, J.R. Quantum cognition and decision theories: A tutorial. J. Math. Psychol. 2016, 74, 99–116. [Google Scholar] [CrossRef]
- Liang, P.P.; Zadeh, A.; Morency, L.P. Foundations & trends in multimodal machine learning: Principles, challenges, and open questions. ACM Comput. Surv. 2024, 56. [Google Scholar] [CrossRef]
- Shougat, M.R.E.U.; Li, X.; Shao, S.; McGarvey, K.; Perkins, E. Hopf physical reservoir computer for reconfigurable sound recognition. Sci. Rep. 2023, 13, 8719. [Google Scholar] [CrossRef]
- Haigh, K.Z.; Nguyen, T.; Center, T.R.M. Challenges of Testing Cognitive EW Systems. In Proceedings of the 2023 IEEE AUTOTESTCON, National Harbor, MD, USA, 28–31 August 2023; IEEE: New York, NY, USA, 2023; pp. 1–8. [Google Scholar]
- Wang, Y.; Widrow, B.; Hoare, C.A.R.; Pedrycz, W.; Berwick, R.C.; Plataniotis, K.N.; Rudas, I.J.; Lu, J.; Kacprzyk, J. The odyssey to next-generation computers: Cognitive computers (κC) inspired by the brain and powered by intelligent mathematics. Front. Comput. Sci. 2023, 5, 1152592. [Google Scholar] [CrossRef]








Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Maksimovic, M.; Maksymov, I.S. Transforming Neural Networks into Quantum-Cognitive Models: A Research Tutorial with Novel Applications. Technologies 2025, 13, 183. https://doi.org/10.3390/technologies13050183
Maksimovic M, Maksymov IS. Transforming Neural Networks into Quantum-Cognitive Models: A Research Tutorial with Novel Applications. Technologies. 2025; 13(5):183. https://doi.org/10.3390/technologies13050183
Chicago/Turabian StyleMaksimovic, Milan, and Ivan S. Maksymov. 2025. "Transforming Neural Networks into Quantum-Cognitive Models: A Research Tutorial with Novel Applications" Technologies 13, no. 5: 183. https://doi.org/10.3390/technologies13050183
APA StyleMaksimovic, M., & Maksymov, I. S. (2025). Transforming Neural Networks into Quantum-Cognitive Models: A Research Tutorial with Novel Applications. Technologies, 13(5), 183. https://doi.org/10.3390/technologies13050183